https://rustcc.cn/article?id=926f8f73-912c-4860-a4e8-979b8d73b4ba
在 Rust 中,生命周期(Lifetime)是一个关键的概念,用于管理引用的有效期,确保引用不会比它们指向的数据活得更久。

难道不能通过编译器推断出来吗?
大多数场景可以,但有的情况不行.
大部分时候生命周期是隐含并可以推断的,正如大部分时候类型也是可以推断的一样。类似于当因为有多种可能类型的时候必须注明类型,也会出现引用的生命周期以一些不同方式相关联的情况,所以Rust需要我们使用泛型生命周期参数来注明他们的关系,这样就能确保运行时实际使用的引用绝对是有效的。
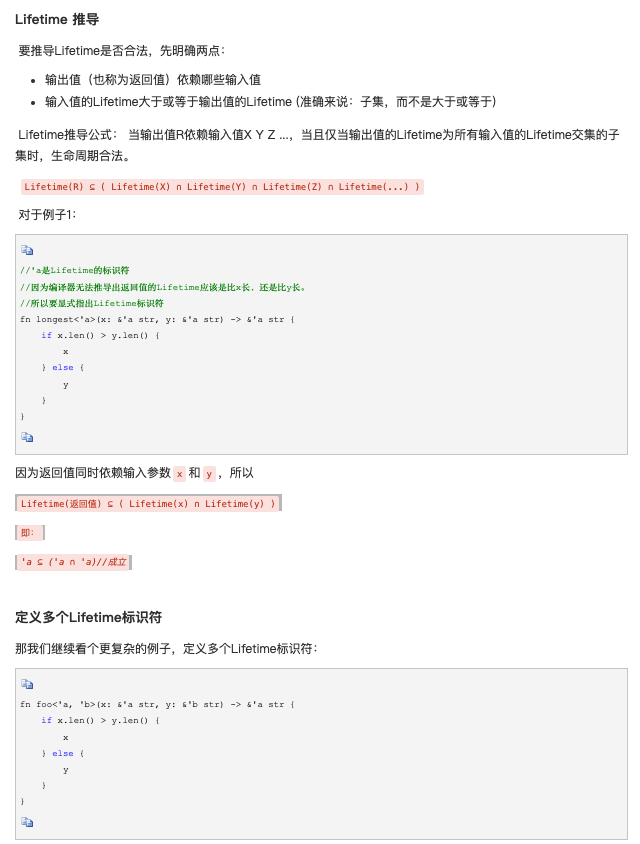
Lifetime推导公式: 当输出值R依赖输入值X Y Z …,当且仅当输出值的Lifetime为所有输入值的Lifetime交集的子集时,生命周期合法。
值得一看:
https://www.cnblogs.com/johnnyzhao/p/15329975.html
https://kaisery.github.io/trpl-zh-cn/ch10-03-lifetime-syntax.html
1 | &i32 // 引用 |
rust为什么需要生命周期? 编译器不能推断出来的吗?举个例子说明
Rust 的生命周期(Lifetime)是一种编译时检查,确保引用始终指向有效的内存。生命周期对于防止悬垂指针和确保内存安全非常关键,尤其是在多个引用和复杂作用域的情况下。
Rust 编译器确实会尝试推断引用的生命周期,但并非所有情况都能自动推断。特别是在涉及多个引用时,编译器可能无法确定哪个引用的生命周期应该被用来约束其他引用的生命周期。在这些情况下,Rust 需要显式的生命周期注解来帮助编译器理解引用之间的关系。
为什么需要生命周期
- 避免悬垂引用:确保引用不会指向已经被释放的内存。
- 多引用场景:在函数或结构体中使用多个引用时,需要清楚地表达它们之间的关系。
- 泛型代码的正确性:在泛型代码中,生命周期参数确保代码在不同的使用场景中仍然安全。
示例
假设有一个函数,它接受两个字符串切片的引用,并返回其中一个:
1 | fn select<'a>(first: &'a str, second: &'a str) -> &'a str { |
在这个例子中,select函数需要生命周期参数'a。这是因为它返回的引用可能是first或second中的一个,而编译器需要确保返回的引用不会比传入的任一引用活得更久。
不使用生命周期注解的话,编译器无法确定返回的引用与传入的两个引用之间的生命周期关系,因此可能无法保证返回的引用总是有效的。
通过显式指定生命周期'a,我们告诉编译器:所有这些引用都应具有相同的生命周期,并且返回的引用不能比任何一个参数的引用活得更长。
生命周期注解不会改变任何引用的实际生命周期,而是用于帮助编译器理解并验证引用的合法性。这是 Rust 静态借用检查的核心部分,是其能够提供内存安全保障的关键原因之一。
请举几个rust为什么需要生命周期更容易理解的例子
Rust 的生命周期(lifetime)是一个相对复杂但极其重要的概念,它有助于确保内存安全和避免悬挂引用(dangling references)。生命周期在 Rust 中用于追踪引用的有效期。理解生命周期的关键在于理解 Rust 如何通过编译时检查来管理内存和引用。以下是几个使生命周期更容易理解的例子:
函数中的引用参数:
设想一个函数,它接受两个字符串引用并返回其中一个。Rust 需要使用生命周期来确保返回的引用在函数外部仍然有效。1
2
3fn choose<'a>(first: &'a str, second: &'a str) -> &'a str {
if first.len() > second.len() { first } else { second }
}在这个例子中,
'a指示了first、second和返回值之间的生命周期是相同的。结构体中的引用:
当结构体中包含引用时,Rust 需要知道这些引用的生命周期,以确保结构体不会比其内部的引用存活得更久。1
2
3
4struct Book<'a> {
name: &'a str,
author: &'a str,
}这里,
'a保证了Book实例不会比它所引用的name和author存活得更久。生命周期省略规则(Lifetime Elision Rules):
Rust 有一些默认的生命周期推断规则。例如,如果一个函数有一个输入生命周期和一个输出生命周期,Rust 会假设它们是相同的。1
fn get_first_word(s: &str) -> &str { /*...*/ }
在这里,Rust 推断输入和输出引用具有相同的生命周期。
结构体方法中的生命周期:
当结构体方法使用了结构体中的引用时,生命周期参数确保方法的使用不会导致悬挂引用。1
2
3
4
5impl<'a> Book<'a> {
fn get_author(&self) -> &'a str {
self.author
}
}get_author方法返回一个与Book实例相同生命周期的引用。
通过这些例子,你可以看到 Rust 中生命周期的用途是确保引用在使用它们的上下文中保持有效,从而避免悬挂引用和其他常见的内存安全问题。这是 Rust 强大的内存安全保证的核心部分。
详细一点的完整的例子呢
当然可以。让我们通过一个更详细的例子来探索 Rust 中生命周期的概念。这个例子将包括定义结构体、实现方法,并在其中使用生命周期注解。
示例:图书管理系统
假设我们正在为一个图书管理系统编写代码。我们有一个 Book 结构体,其中包含书名和作者名,这两个字段都是字符串切片(&str)。我们还想实现一个函数,该函数接受两本书作为参数,并返回其中作者名字较长的那本书的引用。
步骤 1: 定义带有生命周期的结构体
首先,定义一个包含引用的 Book 结构体。由于结构体包含引用,我们需要为这些引用指定生命周期。
1 | struct Book<'a> { |
步骤 2: 实现比较书籍作者名长度的函数
接下来,我们实现一个函数,它比较两本书的作者名长度,并返回作者名较长的那本书的引用。
1 | fn longer_author<'a>(book1: &'a Book, book2: &'a Book) -> &'a Book<'a> { |
在这个函数中,'a 生命周期参数确保返回的 Book 引用不会超出 book1 和 book2 输入参数的生命周期。
步骤 3: 使用这些定义
最后,让我们看看这些定义是如何在实践中被使用的。
1 | fn main() { |
在这个例子中,我们创建了两个 Book 实例,并使用 longer_author 函数来确定哪个书的作者名字更长。由于 Rust 的生命周期注解,编译器能够确保在 longer_author 函数中返回的 Book 引用在 main 函数中仍然有效。
这个例子展示了如何在结构体、方法和函数中使用生命周期来确保内存安全。生命周期注解帮助 Rust 编译器理解不同引用之间的关系,以防止悬挂引用和其他内存安全问题。
太复杂了,不要用struct,用字符串或者向量,举一个完整的例子呢
了解了,让我们用一个简单的例子来解释 Rust 中生命周期的概念。我们将使用字符串切片(&str)作为参数的函数来展示生命周期的应用。
示例:比较两个字符串切片的长度
假设我们想编写一个函数,该函数接受两个字符串切片作为参数,并返回长度较长的那个字符串切片。
定义带有生命周期参数的函数
首先,我们定义一个函数,它比较两个字符串切片的长度,并返回长度较长的那个。为了保证返回的字符串切片在函数外部仍然有效,我们需要使用生命周期参数。
1 | fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str { |
在这个函数中,生命周期参数 'a 表示 s1 和 s2 的生命周期,并且返回值的生命周期也与 'a 相关联。这意味着返回的字符串切片不会比 s1 或 s2 存活得更久。
使用这个函数
现在我们可以使用这个函数来比较两个字符串切片的长度了。
1 | fn main() { |
在这个例子中,我们创建了两个 String 对象,然后将它们转换为字符串切片(&str)并传递给 longer 函数。由于我们使用了生命周期参数,编译器可以确保 result 变量在其使用范围内引用的字符串切片是有效的。
通过这个简单的例子,您可以看到 Rust 中生命周期参数是如何用来确保引用的有效性,从而避免内存安全问题,如悬挂引用。这是 Rust 强大内存安全保证的重要组成部分。
为什么需要<’a>? 不加会怎么样呢
在 Rust 中,生命周期参数(如 <'a>)用于指定引用的有效期。这是 Rust 为了确保内存安全和防止悬挂引用而引入的一项特性。当我们在函数签名中使用生命周期参数时,我们实际上是在告诉编译器:这些参数和返回值之间有某种生命周期的关系。
在您给出的例子中:
1 | fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str { |
生命周期注解 <'a> 表明了参数 s1 和 s2 以及返回值都共享同一个生命周期 'a。这意味着返回的字符串切片将不会比输入的字符串切片存活得更久。
不使用生命周期参数会怎样?
如果我们不在 longer 函数中使用生命周期参数,编译器将无法理解返回的引用(字符串切片)与输入参数的生命周期之间的关系。这可能会导致编译错误,因为 Rust 无法保证返回的引用在其使用上下文中是有效的。
尤其是在处理引用时,如果 Rust 无法确定引用的有效性,它会默认阻止可能存在的不安全操作。
举个不使用生命周期参数的例子:
1 | fn longer(s1: &str, s2: &str) -> &str { |
这段代码会导致编译错误。Rust 编译器无法推断返回的引用与输入参数的生命周期关系,因此无法保证返回的引用在使用时仍然有效。编译器需要明确的生命周期注解来保证代码的内存安全。
总结来说,Rust 中的生命周期注解不是多余的,而是为了确保代码的内存安全性和避免悬挂引用。这是 Rust 语言设计中的核心特性,用于保护程序在运行时不会遇到由于错误的内存访问引起的未定义行为。
rust中Lifetime Bound是什么?’a: ‘b,T: ‘a,T: Trait + ‘a都是什么意思?举例说明
在 Rust 中,生命周期(Lifetime)是一个关键的概念,用于管理引用的有效期,确保引用不会比它们指向的数据活得更久。生命周期限制(Lifetime Bound)是在类型系统中用于指定引用或泛型类型的生命周期的约束。
'a: 'b
这表示生命周期 'a 至少和生命周期 'b 一样长。在这种情况下,可以将生命周期 'a 的引用赋给生命周期 'b 的引用,但反过来不行。这常用于函数签名和结构体定义中,以确保某些引用不会在其他引用失效之前失效。
示例:
1 | fn foo<'a: 'b, 'b>(x: &'a str, y: &'b str) { |
这里,'a 是至少和 'b 一样长的生命周期。这意味着 x 的生命周期至少与 y 一样长。
T: 'a
这表示类型 T 中的所有引用都必须至少活得和 'a 一样久。这通常用于泛型类型,确保类型 T 中的数据不会比 'a 更早失效。
示例:
1 | struct MyStruct<'a, T: 'a> { |
在这个例子中,MyStruct 包含了一个对类型 T 的引用,而 T 的所有引用必须至少和 'a 一样长。
T: Trait + 'a
这表示类型 T 必须实现指定的 Trait,且 T 中的所有引用必须至少活得和 'a 一样久。
示例:
1 | fn print_it<'a, T: Display + 'a>(value: &'a T) { |
这里,print_it 函数接受一个实现了 Display trait 的类型 T 的引用,并且这个引用的生命周期至少和 'a 一样长。
总结
生命周期限制在 Rust 中非常重要,用于确保程序的内存安全。通过这些限制,编译器可以保证引用不会在它们指向的数据失效后继续存在,从而避免悬垂引用和其他内存安全问题。
举一个需要用到’a: ‘b的例子
在 Rust 中,使用 'a: 'b 形式的生命周期约束是为了表明生命周期 'a 至少和 'b 一样长。这种约束通常在更复杂的生命周期场景中使用,例如当一个结构体或函数需要确保某些引用的生命周期相对于其他引用更长或至少一样长时。以下是一个使用 'a: 'b 的例子:
示例:结构体中嵌套引用
假设我们有一个结构体 Context,它包含一个引用,以及另一个结构体 Processor,它在方法中使用 Context 的引用。我们想确保 Processor 的 Context 引用至少与 Processor 实例本身具有相同的生命周期。这就是 'a: 'b 生命周期约束派上用场的地方。
1 | struct Context<'a> { |
在这个例子中:
Context结构体包含一个生命周期为'a的引用。Processor结构体有两个生命周期参数:'a和'b。它包含一个对Context的引用,该引用的生命周期为'b。我们使用'b: 'a来表明Processor对Context的引用的生命周期'b至少与Context中数据的生命周期'a一样长。process方法在Processor实例上调用,它使用存储在context中的数据。
这种生命周期约束确保了 Processor 实例中的 Context 引用在 Processor 实例存在的整个时间内都是有效的。这样的设计对于管理嵌套引用、防止悬垂引用等场景非常有用。
如果我故意标错’a: ‘b
如果在 Rust 中故意标记错误的生命周期约束,例如使用 'a: 'b 而实际上 'a 的生命周期比 'b 短,这将导致编译错误。Rust 编译器的生命周期检查确保引用在任何时候都不会失效,以保证内存安全。
在您提到的情况下,如果 'a 实际上比 'b 短,但您错误地声明了 'a: 'b(表示 'a 至少和 'b 一样长),编译器将无法找到满足这些约束的有效生命周期,从而导致编译失败。
示例
考虑以下代码:
1 | struct Context<'a> { |
在这个例子中,data 的生命周期在内部作用域结束时结束,这导致 context 中的引用变成悬垂引用。由于 Processor 的定义中 'b: 'a 意味着 context 引用的生命周期 'b 至少和 Context 中数据的生命周期 'a 一样长,编译器会发现 context 的生命周期实际上短于其内部数据的生命周期,从而导致编译错误。
总结
错误的生命周期约束会被 Rust 编译器捕获,因为它们违反了 Rust 强大的借用检查规则。Rust 的这种设计是为了确保内存安全和防止悬垂引用等问题。
那编译器能识别出来,为什么还需要我显式指定??
在 Rust 中,编译器要求显式指定生命周期参数(Lifetime Annotations)的主要原因是因为 Rust 无法总是自动推断出引用之间的关系,特别是在复杂的情况或多个引用交互的场景中。显式生命周期参数帮助编译器理解不同引用之间的持续时间关系,以确保内存安全。
为什么需要显式指定生命周期
消除歧义:在涉及多个引用的函数和结构体中,编译器可能无法确定哪个输入引用与输出引用相关联,或者引用之间应该如何相互关联。显式生命周期标注帮助消除这种歧义。
增强代码清晰度:显式生命周期标注使得代码更清晰,更容易理解。它向维护代码的其他开发者清楚地展示了引用之间的关系。
复杂场景的处理:在更复杂的场景中,例如嵌套结构体、泛型、或生命周期之间的约束(如
'a: 'b),显式生命周期标注是必要的。编译器无法自动推断所有复杂场景的最佳生命周期。灵活性和控制:显式标注提供了更多的控制,允许开发者定义更精细的内存管理规则,这对于高级功能和优化很重要。
生命周期推断和省略规则
尽管在许多简单的情况下,Rust 的生命周期省略规则(Lifetime Elision Rules)可以自动推断生命周期,但这些规则不适用于所有情况。例如,生命周期省略规则主要适用于某些特定模式的函数,但并不适用于复杂的函数或结构体/枚举定义。
总结
显式生命周期标注是 Rust 保证内存安全的关键机制之一。通过要求开发者在复杂情况下提供这些信息,Rust 能够有效地防止悬垂引用和其他内存安全问题,同时还为开发者提供了足够的灵活性去处理复杂的内存管理场景。虽然这增加了学习曲线,但这也是 Rust 提供强大内存安全保证的方式之一。
开发者显式标注生命周期可能有错误,这样不会有问题吗?rust号称安全,不相信程序员,这时候为什么要相信程序员的标注???
Rust 要求开发者显式标注生命周期,并不是完全“相信程序员”的生命周期决定,而是为了使程序员能够明确指出他们的意图。重要的是,即使开发者显式标注了生命周期,Rust 编译器仍然会执行严格的检查来验证这些标注是否正确。如果标注不正确或导致潜在的内存安全问题,编译器将拒绝编译程序。
为何需要显式生命周期标注
明确程序员的意图:显式生命周期标注让开发者可以清晰地表达他们的意图,特别是在复杂的场景中,如多个引用交互的情况。这有助于编译器更好地理解代码的行为。
消除歧义:在复杂的情况下,可能存在多种合理的生命周期选择。显式标注使得开发者可以指定他们认为最适合的生命周期。
编译器的角色
尽管开发者提供生命周期标注,Rust 编译器扮演着关键角色:
编译时检查:Rust 编译器会在编译时检查生命周期标注是否正确。如果生命周期标注导致潜在的悬垂引用或其他内存安全问题,编译器将不会编译代码。
防止错误:如果生命周期标注不正确或者与其他代码部分冲突,编译器会产生错误,阻止潜在不安全的代码运行。
强制合规性:通过强制生命周期标注的一致性和正确性,Rust 确保了代码的内存安全性。
总结
尽管 Rust 要求开发者显式标注生命周期,但这并不意味着编译器盲目信任这些标注。相反,这些标注必须通过 Rust 的严格编译时检查。这种方法结合了开发者的意图表达和编译器的严格验证,既保证了代码的灵活性,又确保了内存安全。Rust 的设计理念是让编译器能够捕捉到几乎所有的潜在内存安全问题,即使这意味着增加了编写代码时的复杂性。
原文链接: https://dashen.tech/2017/01/04/Rust的生命周期为什么有时还需要显式声明/
版权声明: 转载请注明出处.