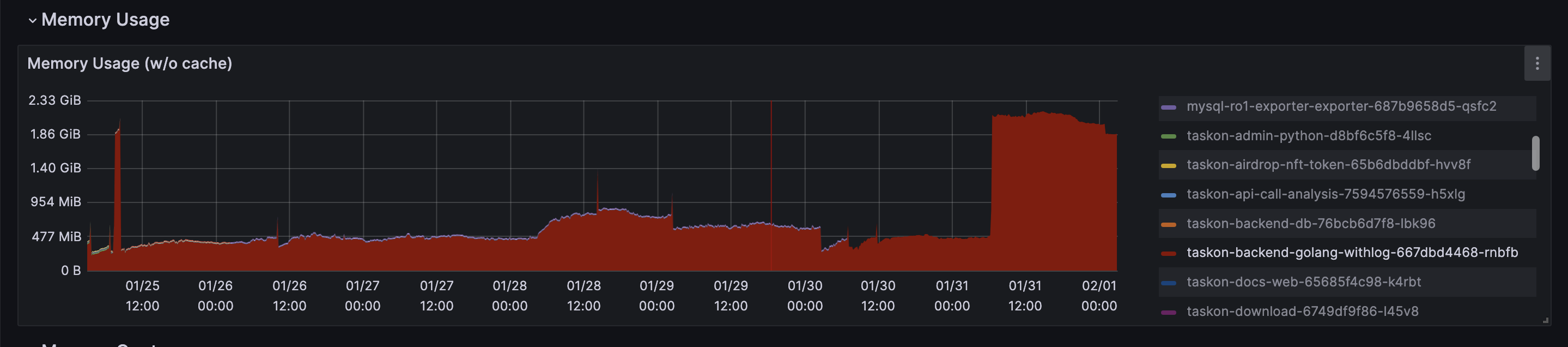
同事反应,从grafana上看到,taskon-server服务在昨天中午突然有内存突增,而且一直没有下来.
你帮我看下为毛生产taskon后端内存昨晚从480M突然飙升到2.2G?现在还是1.8G.系统倒是很平稳,没啥问题,响应也非常块
之前有个下载操作,这个动作会导致短期内存突增(获取数据生成excel), 然后在3G多的时候就OOM了.
但后来把download服务抽离了出去,成了一个独立服务,之后就很少再有内存瞬间突增的情况
而且这里的这个内存突增是持续的,即涨上去了没降下来—但这样也有好处,分析下当前内存占用就一目了然了….
然而采集当前的pprof看了下(这里的pprof是用的信号来做到,用到的时候打开,不用时关闭,参考而不是开放一个端口,随时都能拉取…这种玩法倒是很新颖,参考 Go信号监听)
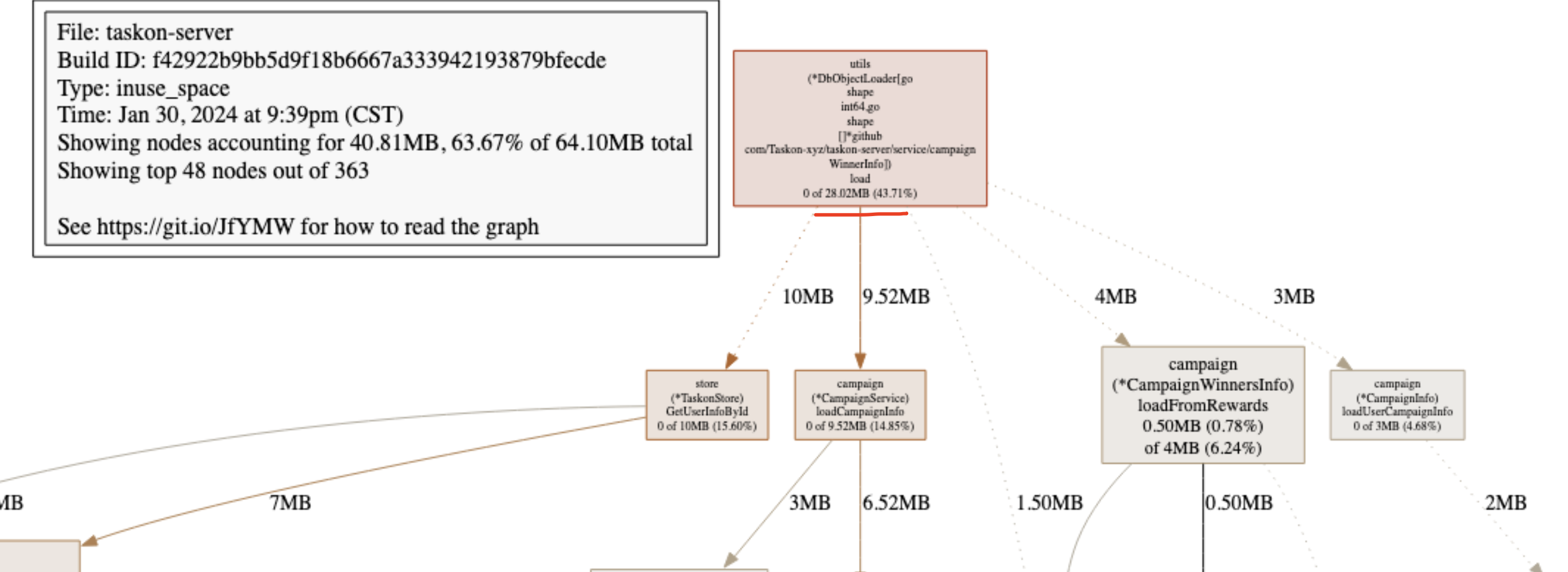
但是抓了一下,看了下内存,就用了20多M….
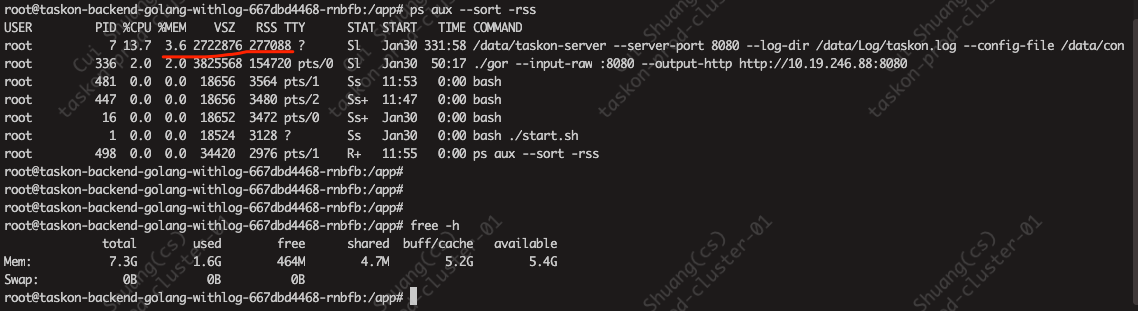
然后用ps aux --sort -rss 也是20多M
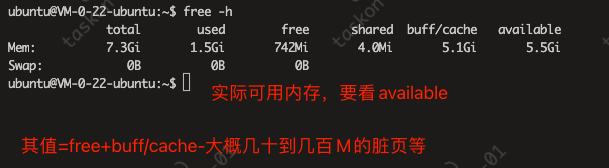
但是free -m查看,确实1G多
实时的pprof显示就占用20几M,和下面ps aux看到的一致; 但是free看到的确实是1G多,和grafana上的一致
瞬间有大量goroutine,会有这个问题(参考我之前的博客)…但看了下goroutine,也不多…但其实呢,现在是不多,但有可能之前某个瞬间很多,单向递增,撑大了,回缩不回去了—-但应该内存不会差这么多,这个可以通过重启服务,看看是否降下去来验证
要是go1.14好像有个内存回收的问题,但我们的go版本都很新了(Go 1.21,目前是2024.02.01,1.22还要十天半个月才发,所以线上用1.21已经相当新了)
你重启过taskon server 吗.现在内存突然掉到了480M了?
我回复: 除非紧急情况(服务不可用啥的),我这不会不通知就重启的[奸笑]
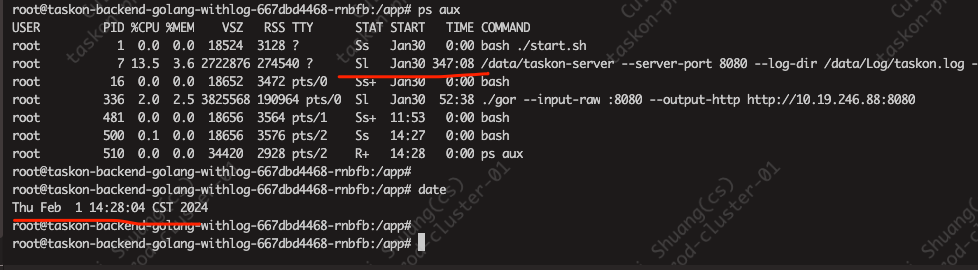
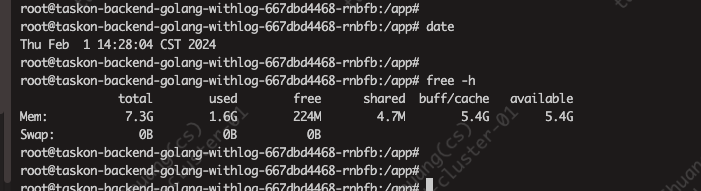
但free看着还是差不多
那是监控统计的问题?
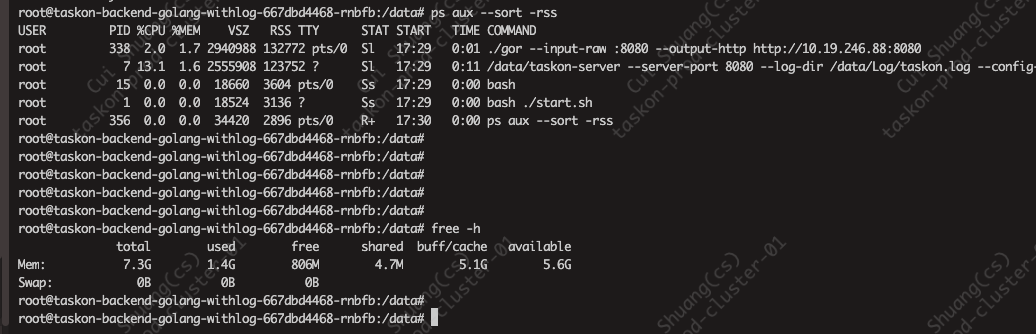
重启之后,free -h 还是占得差不多
看着服务本身占用的内存很少..
但是又看了这个集群上面另一个pod:
free -h , reward看着用的更多
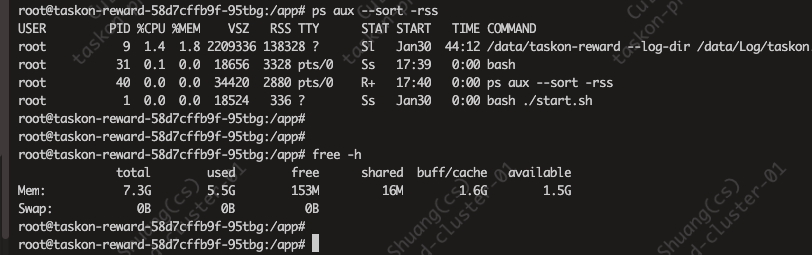
但reward的展示 ,完全又和free的对不上
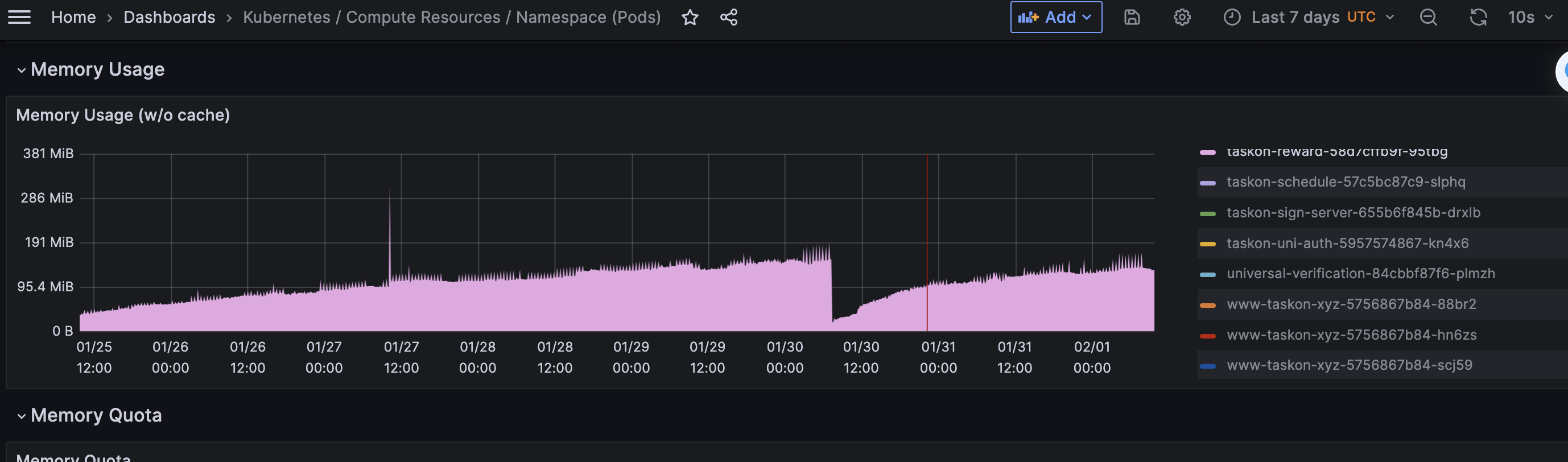
需要研究下pod里面free的内容,和Prometheus采集的指标两个的关系
以及pod里面的free,和进程实际占用的内存的关系
从 Kubernetes Pod 内存占用谈 Linux 内存管理
https://www.google.com/search?q=pod+%E4%B8%ADfree%E9%AB%98
番外:
unix查看占用内存最高的进程
查看占用内存最高的进程,有以下几种方法:
- 使用 ps 命令查询每个进程的内存使用量:
1 | ps aux --sort -rss |
这条命令会按照内存使用量从大到小排序显示各个进程的详细信息。
- 使用 top 命令实时监控:
1 | top |
在 top 命令中,显示内存信息的位置会默认高亮,可以直接看到占用内存最大的进程。
- 使用 smem 查看内存占用情况:
1 | smem -t |
smem 专门用于查看内存分布情况,会直接显示内存占用最大的进程名称。
- 使用 pmap 命令查看指定进程的内存映射情况:
1 | pmap -x PID |
可以替换 PID 看不同进程的内存使用明细。
- 计算/proc/{pid}/status 和 smaps 文件的数值:
1 | cat /proc/{pid}/status | grep VmPeak |
可以精确查看某个进程的内存峰值占用和私有内存占用。
所以一般来说,ps/top可以快速查看,smem专注内存,pmap看具体映射,/proc更详细查看内存情况。根据实际需要选择不同命令查看内存最大进程。
1 | apiVersion: apps/v1 |
这个内存限制是多少?
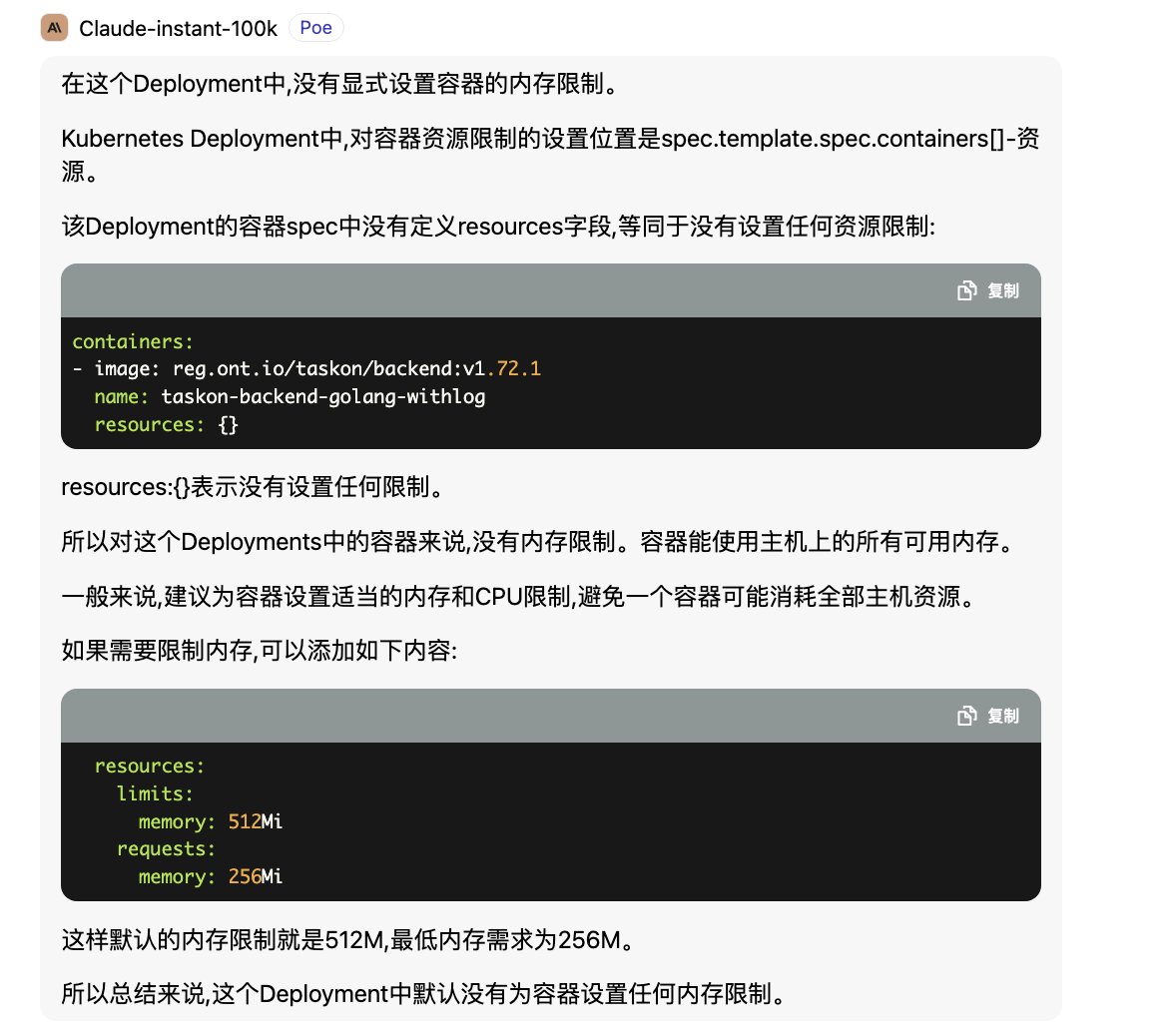
在这个Deployment中,没有显式设置容器的内存限制。
Kubernetes Deployment中,对容器资源限制的设置位置是spec.template.spec.containers[]-资源。
该Deployment的容器spec中没有定义resources字段,等同于没有设置任何资源限制:
1 | containers: |
resources:{}表示没有设置任何限制。
所以对这个Deployments中的容器来说,没有内存限制。容器能使用主机上的所有可用内存。
一般来说,建议为容器设置适当的内存和CPU限制,避免一个容器可能消耗全部主机资源。
如果需要限制内存,可以添加如下内容:
1 | resources: |
这样默认的内存限制就是512M,最低内存需求为256M。
所以总结来说,这个Deployment中默认没有为容器设置任何内存限制。
In Kubernetes, you can deploy applications without specifying memory limits by omitting the resources.limits.memory field in the container specification. By doing so, the container will not have an upper bound on memory usage, and it can use as much memory as it needs within the available resources of the node.
看了下貌似没有限制就是没有限制而不是有个默认限制
所以应该取决于OS了
感觉taskon就四台机器,一台上面也差不多够分一半
这个集群4个node,每台机器4C8G
上面跑着很多个集群
但是某个pod在哪台机器上(node),不一定…
分析:
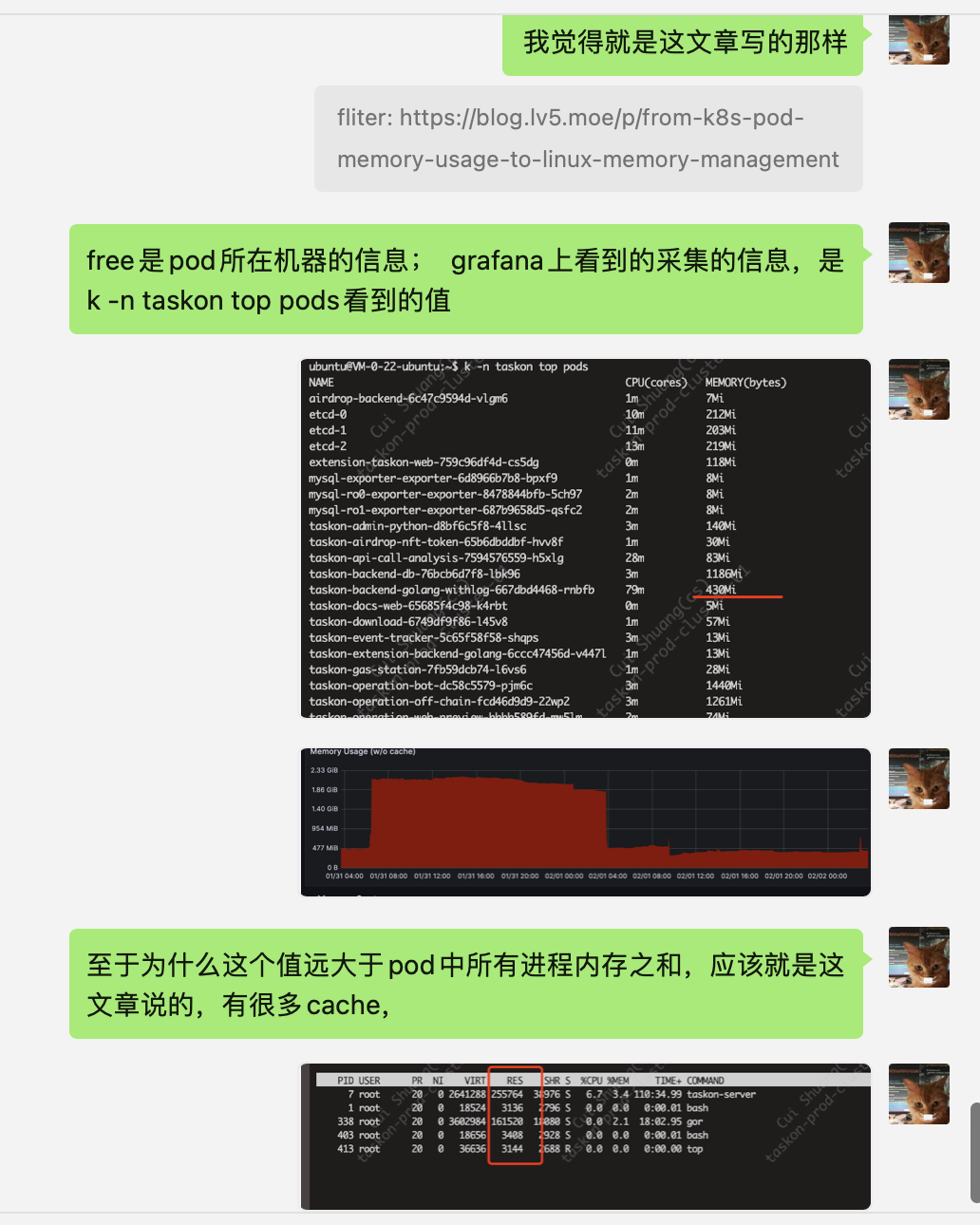
k -n taskon top pods
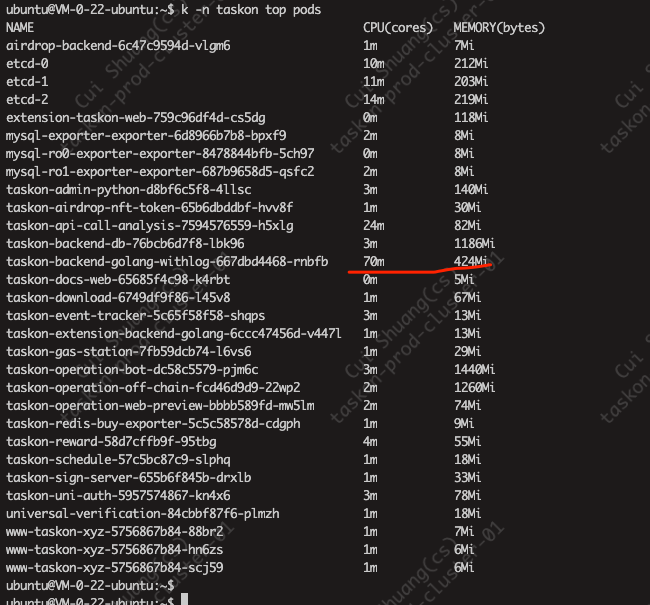

free看到的可能是整个node的信息
top看到的是进程信息,和ps aux一样
kubectl top pods 看到的内存大小,介于两者之间..
即通过free看到的内存 > kubectl top pods看到的Pod内存> 进程实际使用内存
把pod中全部进程的内存加在一起,也达不到free或者kubectl top pods得到的内存大小
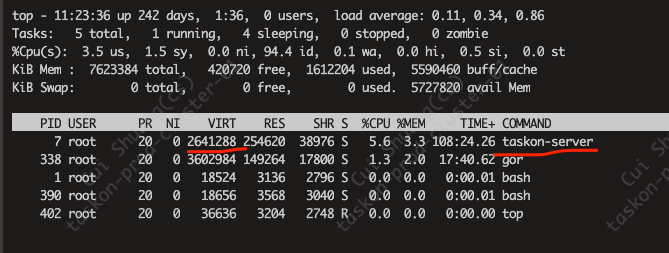
看起来,kubectl top pods 得到的值,就是prom监控的值,是对的上的
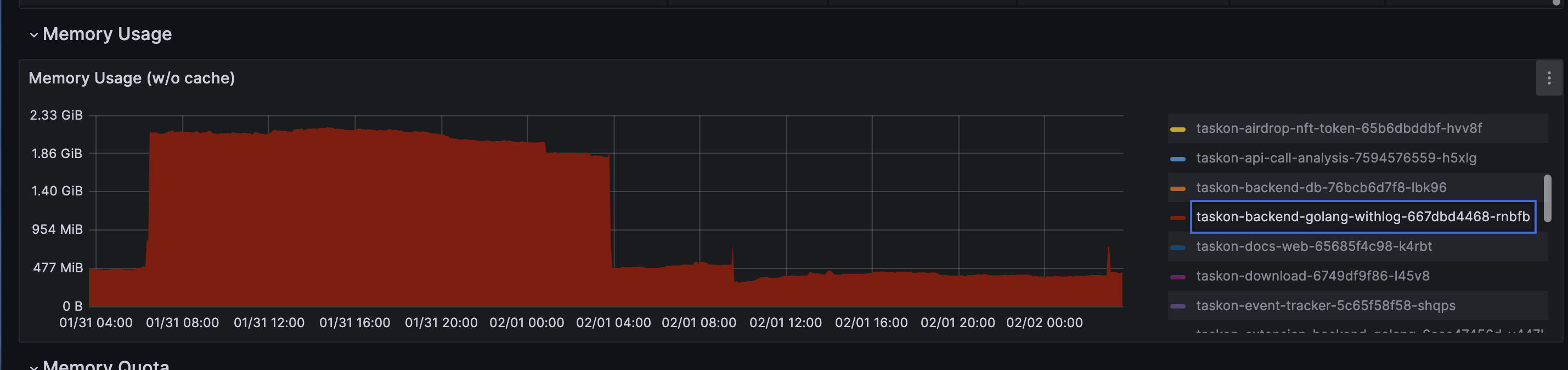
可以不看free,这个应该是整个机器的~
每个pod里 free的值不同,应该是每个pod被调度到了不同的节点上面
pod中所有top、free、cat /proc/memoryinfo结果都是pod所在机器(即node节点)的数据,不是pod自身的数据
所以我先不去关心free, 所以问题就变成了kubectl top pods 得到的值,远远大于pod中各进程所占实际内存之和
可以在这里看某个pod调到了哪个node上面
这里能看具体一个pod的cpu,内存占用
而prom采集的是free中的哪一项?
- total 总内存
- used 已使用内存
- free 空闲内存
- shared 多个进程共享的内存总额
- buff/cache 缓存占用内存
- available 可用内存大小
关于buff和cache的关系,可以看看上面的某篇文章…
两者都是RAM中的数据,简单来说,buffer是即将要被写入磁盘的,而cache是被从磁盘读出来的
Cache:缓冲区,高速缓存,是位于CPU与主内存间的一种容量较小但速度很高的存储器。
Buffer:缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。
详见 一些Linux命令返回值的意义-free命令的buff/cache,以及swap
namespace的隔离也是不全面的,比如/proc 、/sys 、/dev/sd*没有完全隔离。
也就是说在容器中执行一些抓取上面没有完全隔离的目录时,获取的是宿主机上的信息。比如命令free,free主要读取/proc或/sys目录
Docker的设计者也意识到这样确实存在很大不便,于是从Docker在1.8版本以后将分配给容器的cgroup资源挂载到容器内,可以直接在容器内部查看到cgroup资源隔离情况。
在容器内读取cgroup资源限制:
1 | 查看容器核数,除100000 |

从 Kubernetes Pod 内存占用谈 Linux 内存管理
Linux并不会尽可能省内存,而是尽量用起来,提升性能和体验(因为多余的内存放着也是放着,不如让操作速度更流畅卡顿更少一些).所以会尽可能多的缓存和缓冲资源. 但是会有机制,当内存不够用时,会释放这些cache/buffer
原文链接: https://dashen.tech/2017/02/01/Pod的内存问题/
版权声明: 转载请注明出处.