何为自引用结构体?
自引用结构体是一种在其定义中包含至少一个指向同类型结构体的指针的数据结构。这种结构体能够存储和管理具有层次或链式关系的数据,例如链表、树、图等数据结构。自引用结构体是递归数据结构的基础,因为它允许一个实例引用另一个同类型的实例。
如果经常刷力扣,可以马上想到链表和二叉树
单链表节点的自引用结构体
单链表是一种常见的数据结构,由节点(Node)组成,每个节点包含数据部分和指向下一个节点的指针。下面是一个单链表节点的C语言自引用结构体示例:
1 | typedef struct Node { |
在这个例子中,struct Node *next;是一个自引用,因为它是一个指针,指向了Node类型的另一个实例。
二叉树节点的自引用结构体
二叉树是另一种常见的数据结构,每个节点最多有两个子节点:左子节点和右子节点。以下是二叉树节点的C语言自引用结构体示例:
1 | typedef struct TreeNode { |
在这个例子中,struct TreeNode *left;和struct TreeNode *right;都是自引用,因为它们指向了TreeNode类型的其他实例。
自引用结构体通过这种方式创建的链式或层次关系,使得数据结构的遍历、搜索和管理变得更加灵活和高效。
让我们用Rust和Go语言来实现上述的例子,包括单链表节点和二叉树节点的自引用结构体。
Rust 示例
单链表节点
在Rust中,链表通常通过enum来实现,以便能够表示空节点的情况。以下是单链表节点的Rust实现:
1 | type Link = Option<Box<Node>>; |
二叉树节点
二叉树的节点可以用类似的方式实现,每个节点可能有左子节点和右子节点:
1 | type TreeLink = Option<Box<TreeNode>>; |
二叉树节点
二叉树的节点可以用类似的方式实现,每个节点可能有左子节点和右子节点:
1 | type TreeLink = Option<Box<TreeNode>>; |
二叉树节点
二叉树的节点可以用类似的方式实现,每个节点可能有左子节点和右子节点:
1 | type TreeLink = Option<Box<TreeNode>>; |
Go 示例
单链表节点
在Go中,定义单链表节点的结构体相对直接,使用指针来实现自引用:
1 | type ListNode struct { |
二叉树节点
二叉树节点的Go实现也类似,每个节点包含数据和两个指向子节点的指针:
1 | type TreeNode struct { |
Rust和Go语言都提供了强大的类型系统和内存安全保证,这使得在这些语言中实现自引用结构体变得更加安全和方便。在Rust中,使用Option<Box<T>>来表示可能存在或不存在的节点,这种方法在内存管理上非常有效,因为Box<T>提供了对堆上数据的所有权。而在Go中,通过直接使用指针(如*ListNode和*TreeNode)来实现自引用,这反映了Go在内存管理上的简洁性和灵活性。
Rust中的Pin结构体,在异步编程中扮演着关键角色。在深入了解Pin之前,理解其背景和基本概念是非常重要的。大多数Rust结构体默认是可以移动的,这归功于Rust的所有权系统,其中Move特质(trait)自动为所有类型实现,除非该类型已经实现了!Move。
Pin用于标记某些数据结构为“不可移动”。在Rust标准库中,通过定义一个空的结构体并为其实现!Move特质,可以明确指示这个结构体实例一旦被创建就不能被移动到内存中的其他位置。然而,这并不意味着标有!Move的结构体就物理上不能被移动;它更像是一个编译时约束,用于确保数据的内存安全性。
理解Pin的重要性在于,当你将数据“钉”在内存中时,你可以安全地存储指向这些数据的指针或引用,而不用担心数据会被移动导致指针失效。这对于异步任务管理尤为重要,因为它们可能在执行期间被挂起和恢复,且它们的状态必须被保持在固定的内存位置上。
当我们谈到可移动性时,如果结构体的所有成员都是可移动的,那么这个结构体也是可移动的。反之,如果有任何一个成员是不可移动的,整个结构体也将变为不可移动。这是Pin如何保证数据固定不动的方式之一。
在实践中,Pin通过限制对被“钉”数据的直接可变访问来工作。即使你有一个指向某个数据的可变引用,如果这个数据被Pin保护,你不能简单地通过这个可变引用来移动数据。这确保了,一旦数据被“钉”下,就无法通过标准手段被移动,从而保持了引用的有效性和数据的稳定性。
例如,考虑一个场景,你有一个Pin<Box<T>>,这表示你有一个Box指针,它指向的数据是不可移动的。这对于确保异步操作中数据位置的稳定非常有用,因为异步操作可能需要在数据不变的情况下暂停和恢复执行。
Pin的设计哲学反映了Rust对内存安全和并发编程的深思熟虑。通过使用Pin,开发者可以在保持代码安全和高效的同时,管理复杂的异步任务。这也意味着,当你在Rust中操作异步代码时,理解和正确使用Pin变得至关重要。
总结而言,Pin在Rust中是一个强大的工具,它通过限制数据结构的可移动性,来保证内存安全性和异步代码的正确执行。通过标记数据为“不可移动”,Pin使得管理指向这些数据的引用变得安全可靠,这对于高效且错误少的并发编程至关重要。
Rust杂谈:简单粗暴理解Pin和Unpin
大家好,今天花几分钟时间给大家来讲解一下Rust的Pin和Unpin。主要是结合一些个人的经验,来帮助大家更好地去掌握Rust的异步编程。初学Rust的同学可能会被这几个Pin啊、Unpin啊搞得很晕,我这边结合一些我自己的经验来给大家讲解一下我是怎么去学习Pin和Unpin的。
这边主要是三个概念:
- Pin
- Unpin
- !Unpin(代表没有实现Unpin)
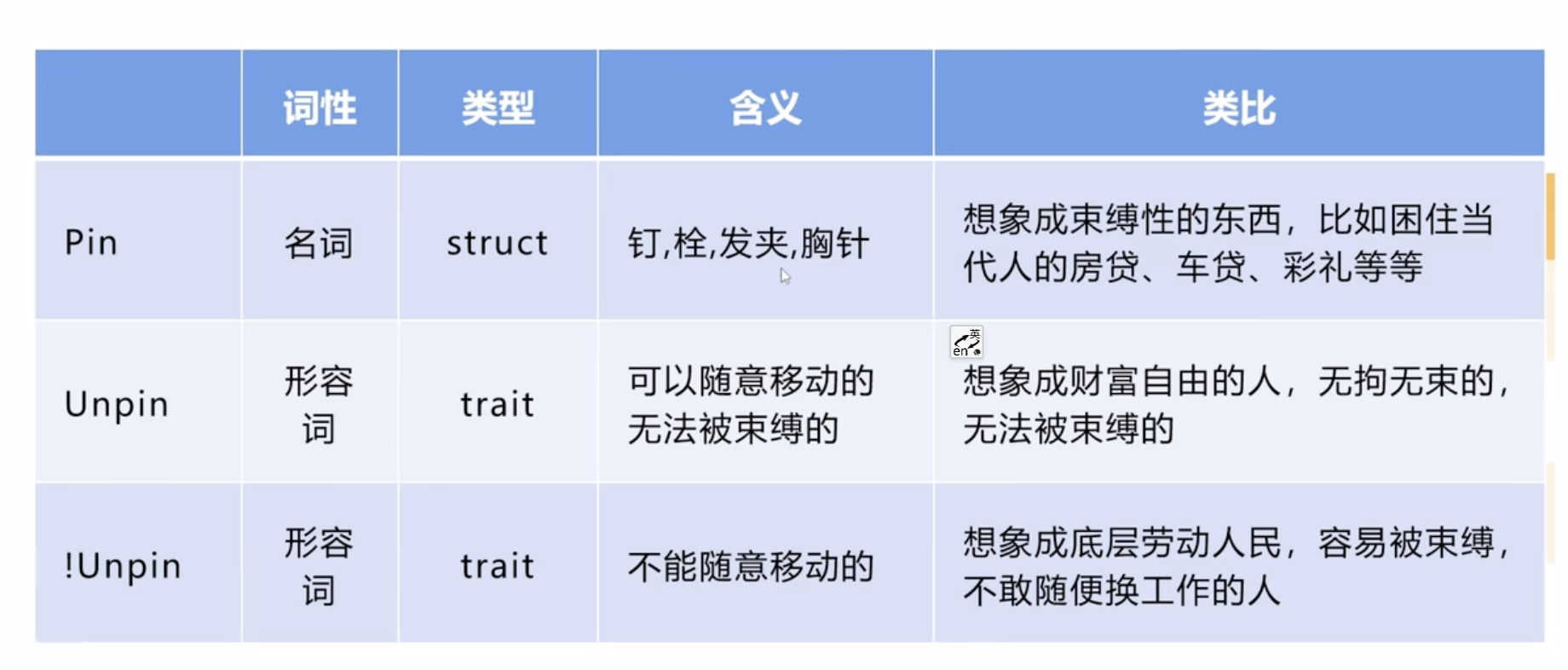
我们需要从词性上去区分它们:
- Pin是个名词,虽然它在英语里也有动词的作用,但在Rust的场景中它是个名词。在Rust中,Pin是一个struct。
- Unpin以及!Unpin都是形容词,你可以理解为形容一个类型的特征,它们是trait。
它们的直接含义:
- Pin的意思是别针、发夹等,基本上就是说可以把东西固定的东西。在Rust中,Pin用来把一些结构给Pin住,不让它移动。这主要是针对那些Future中含有自引用结构的情况。
- Unpin是个形容词,可以理解为”可以随意移动的”。它没有包含自引用类型,可以随便移动,没办法被束缚。
- !Unpin则代表不能随便移动的,也就是它含有自引用结构。如果移动的话,那个自引用关系就乱掉了,可能就导致内存错乱。
我采用了一个类比的方法去理解这三个概念:
- Pin就像是束缚,你可以想象成一些束缚性的东西,比如困住我们当代人的一些房贷、车贷、彩礼等。它是个枷锁,是个名词。
- Unpin和!Unpin是形容我们当代的人,它在对人做分类:
- Unpin代表财富自由的人,无拘无束的,没办法被束缚的。
- !Unpin可以理解为一些普通的打工人,底层的劳动人民,容易被束缚,不能随便换工作等。
Pin既可以Pin住Unpin的对象,也可以Pin住!Unpin的对象。但是如果你把Pin作用在Unpin的结构上,它实际上是没有效果的。就相当于说Unpin的人就是财富自由的人,很有钱了,用什么房贷车贷来困住都困不住。

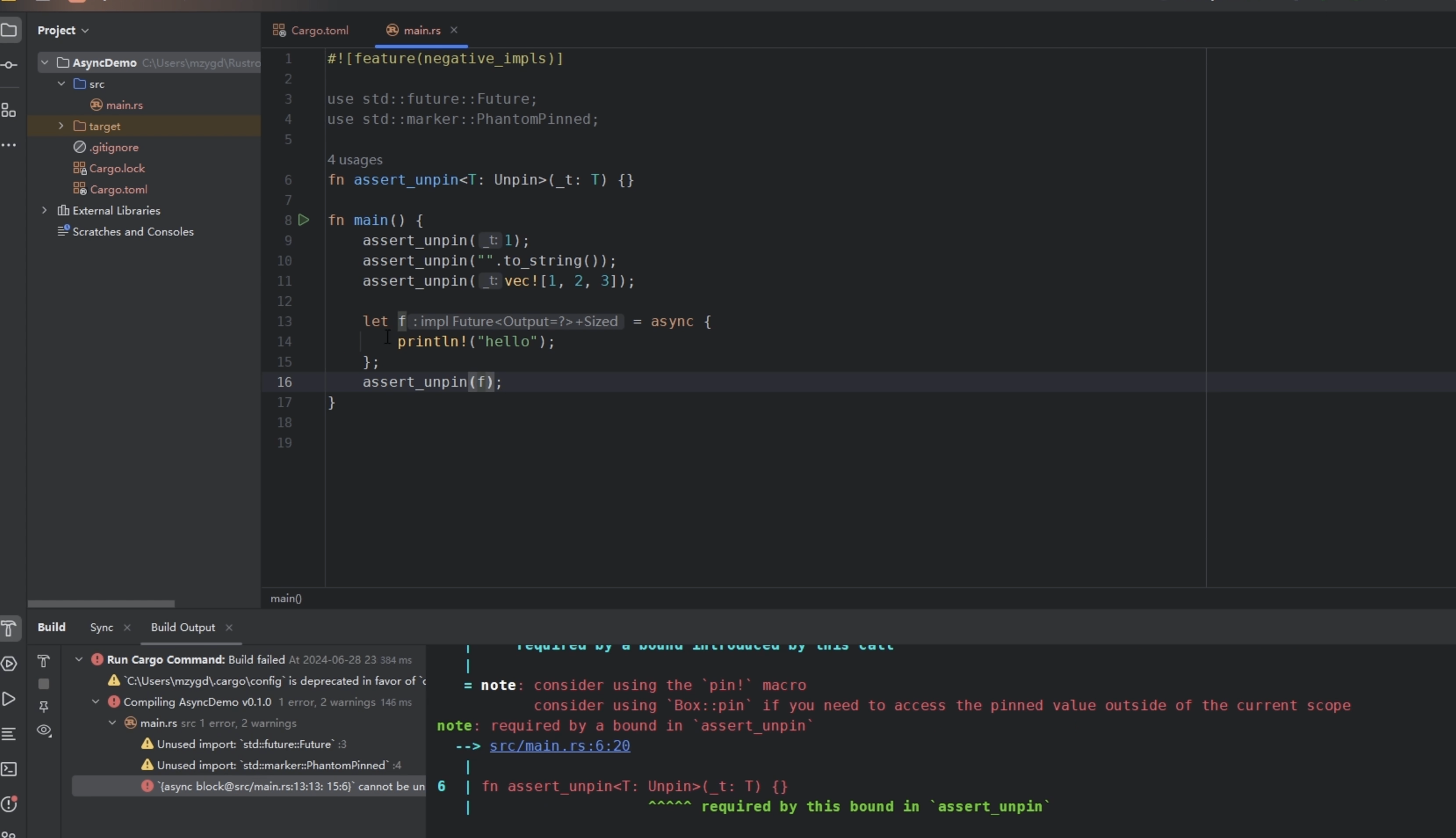
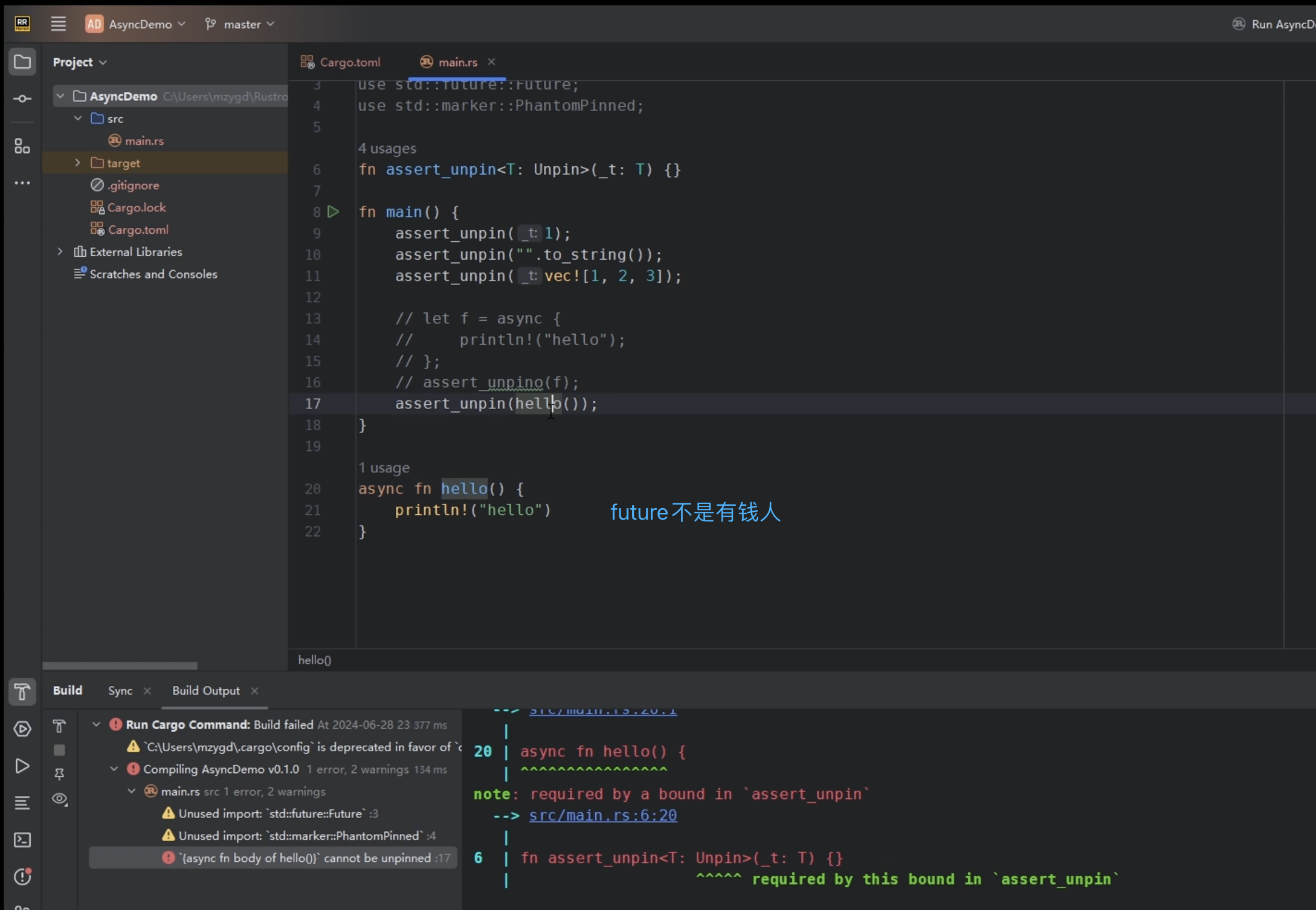
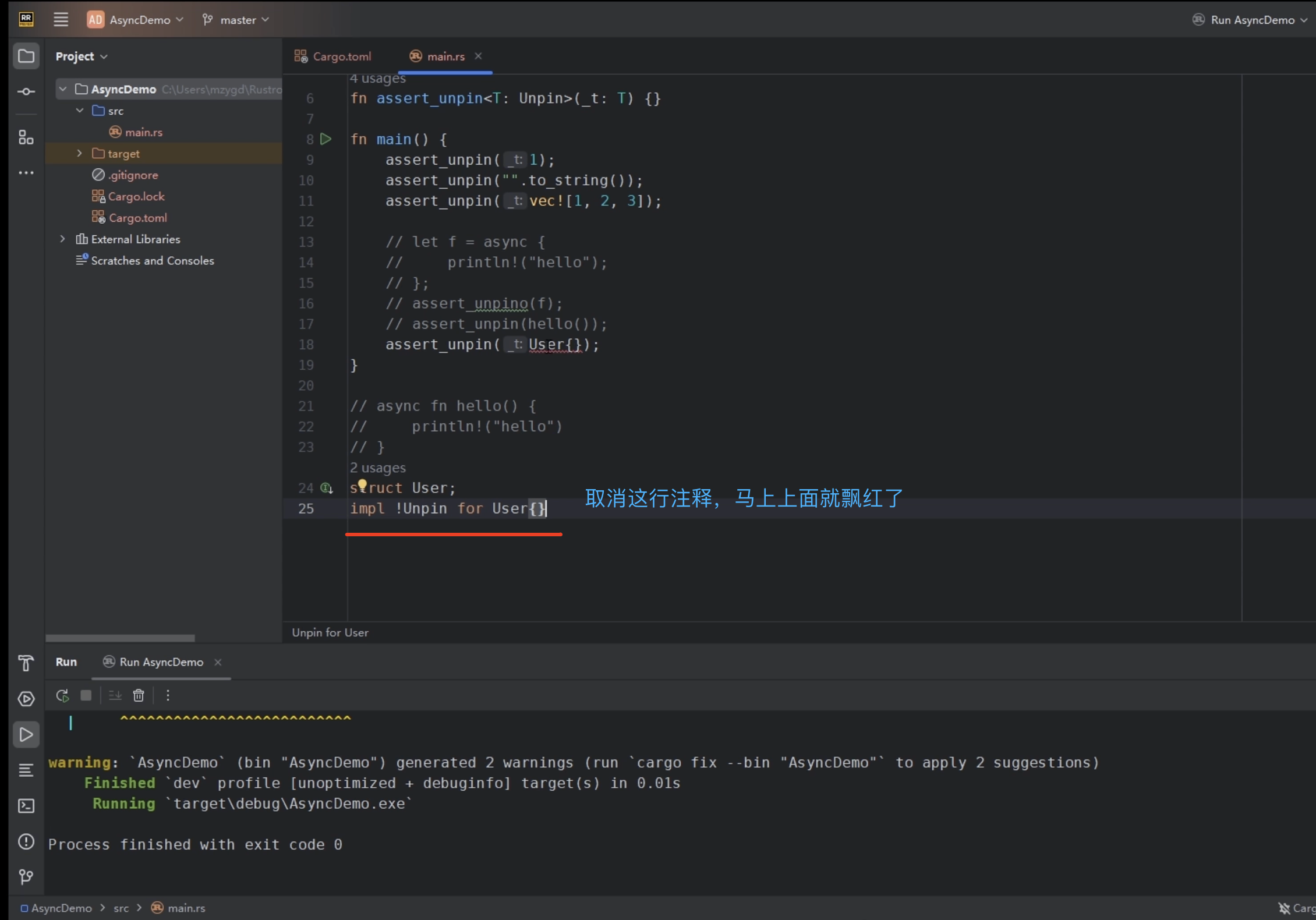
在Rust的世界里,绝大部分类型都是Unpin的,也就是说绝大部分类型都自动实现了Unpin。但是也有一些特殊的例外,主要是下面四个点:
- 用async block生成的Future,它一定是!Unpin的,不管你有没有存在自引用关系。
- 异步函数返回的Future,和第一点类似,也是!Unpin的。
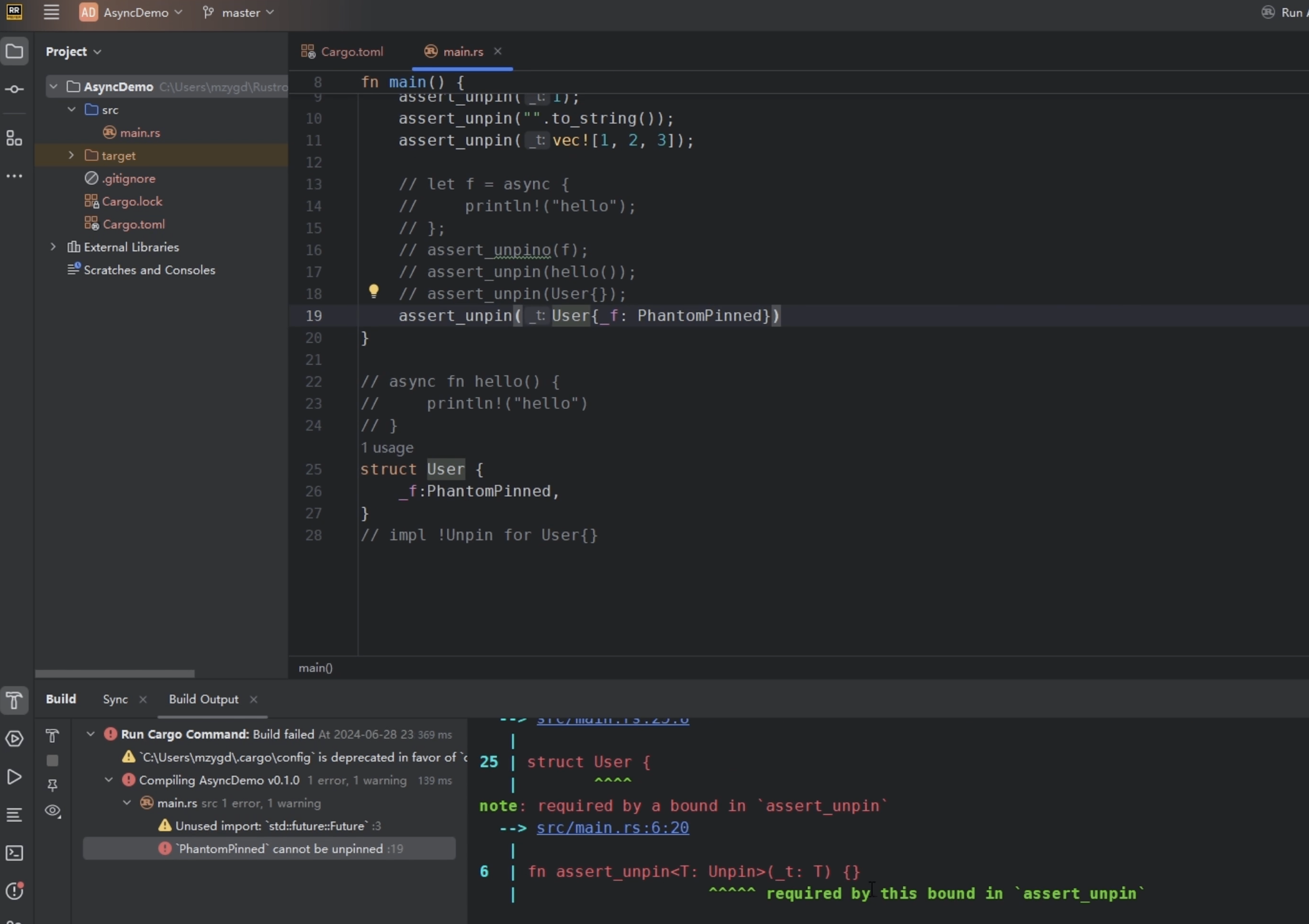
- 通过std::marker::PhantomPinned人为显式地将某个类型标记为!Unpin。
- 包含PhantomPinned字段的类型也会自动变成!Unpin。
我们可以去试一下这四个点:
1 | fn assert_unpin<T: Unpin>() {} |
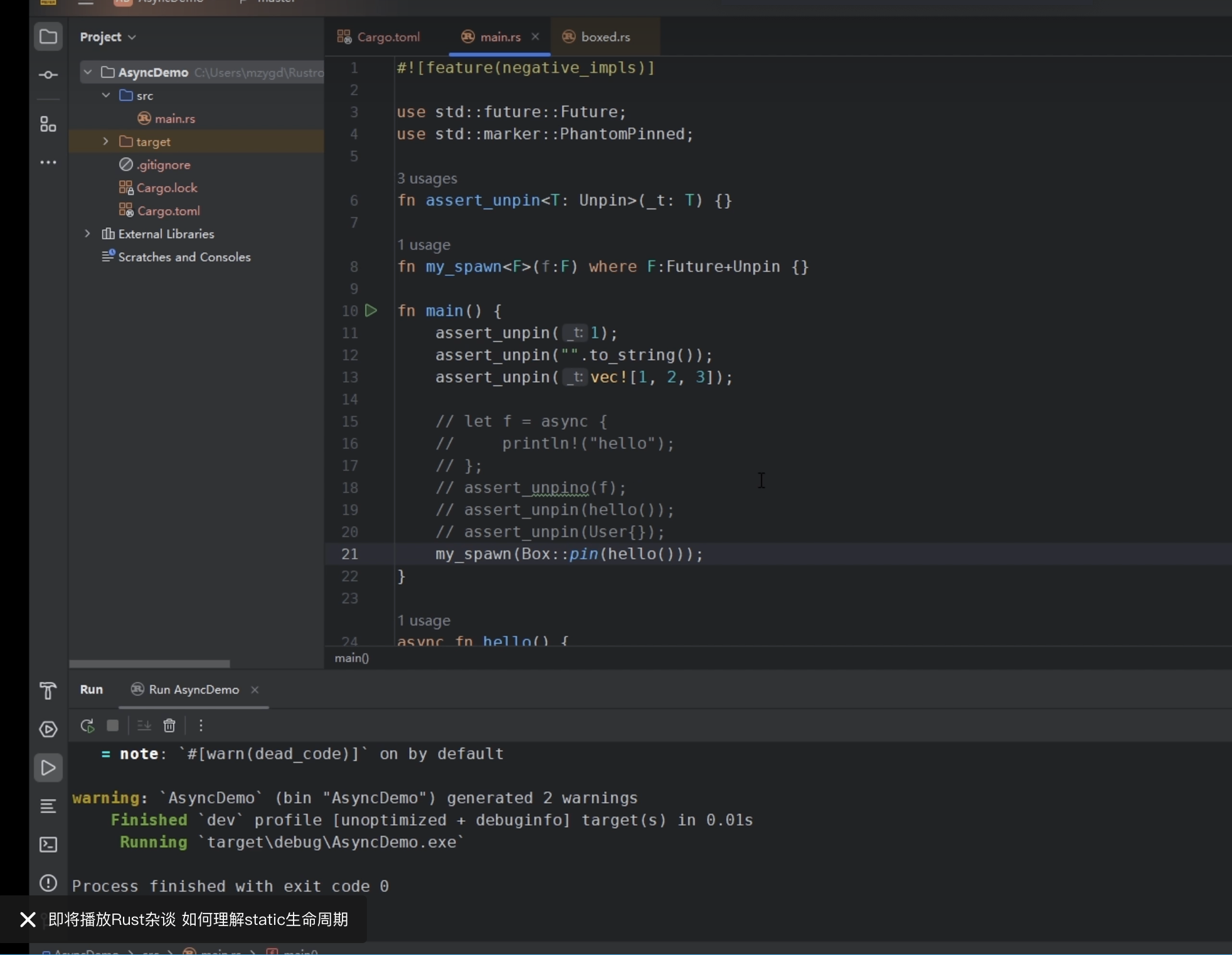
有些异步的运行时实现要求你传入的Future必须是Unpin的,但我们的异步函数和异步块生成的Future都是!Unpin的。那怎么可以传进去呢?答案是需要用到Box::pin。例如:
1 | fn my_spawn<F>(f: F) |
Box::pin的原理很简单,它就是把Future通过Box移动到堆上,然后返回一个指向堆上Future的指针。这个指针是可以随意移动的,因为移动指针并不会影响堆上的Future对象。
下面的评论:
pin住等于无法直接取&mut T,因为他是一个结构体,这样比如一些不安全的操作,mem::swap就无法对pin住的东西移动(编译器报错),然后对于pin<&mut T>来说由于pin还有&mut 都实现了deref
这样就无法取到T的数据(为什么,以后做视频),特别是在异步的时候实现future的时候,要展开成状态机,分配给线程来完全任务,需要大量移动,自引用的时候涉及到一些mem::swap,这个在标准库中很常见,比如说option的操作,所以用个这个保证安全。
Pin唯一的作用是阻止你获得&mut T
cpp 很少见到 pin 是因为可以自己定义 move 行为吗,cpp 的 coroutine 也不需要 pin 是因为编译器直接把协程函数的变量扔堆上去了吗
作者回复: C++ 一方面是可以自定义 move 行为,另一方面它也不像 Rust 追求绝对的 safe code,很多代码可能都是 IFNDR 的。而 C++ 的 coroutine 会自己处理 frame state,一般是直接分配在堆内存上,因此也不用要求地址不变。
哪里来的这么复杂,pin住等于无法直接取&mut T,因为他是一个结构体,这样比如一些不安全的操作,mem::swap就无法对pin住的东西移动(编译器报错),然后对于pin<&mut T>来说由于pin还有&mut 都实现了deref
这样就无法取到T的数据(为什么,以后做视频),特别是在异步的时候实现future的时候,要展开成状态机,分配给线程来完全任务,需要大量移动,自引用的时候涉及到一些mem::swap,这个在标准库中很常见,比如说option的操作,所以用个这个保证安全。
好的,我会按照您的要求,原原本本地整理这段内容,使其变得更加合理通顺,同时不会遗漏或省略任何内容。以下是整理后的内容:
Rust 里的 Pin 是在钉什么?
Pin是Rust里面一个非常独特的概念,我们一般情况并不会直接与它打交道,直到我们开始写async。我们这个视频里面并不会聊为什么async需要Pin,我们单纯就来聊聊Pin是什么,为什么需要有它。
在谈这个问题之前,我们首先要知道,Rust对一个值的默认赋值操作是移动。这里有一个简单的类型叫AddressTracker,它有一个方法show_address可以打印出当前self的地址。接下来有一个方法take_address_tracker,它接受了一个AddressTracker类型。注意此时这个tracker并不是以引用的方式去接收的,而是以一个own的方式去接收。那这个时候当我们调用这个take_address_tracker的时候,这个tracker会被以移动的方式移动到这个实参中。
下面我们来运行一下这个测试用例,看一下这个tracker的地址将会发生什么变化。可以看到两次打印的地址并不是一样的,也就是说这个地方的tracker跟这个函数里的参数的tracker地址并不相同。Rust里面的移动操作默认是将值的内存按位去做拷贝,这个与C++里面可以自定义移动操作的行为不同。Rust里面的移动操作是完全由编译器生成的,我们没有办法去自定义它。这也就要求我们一般的类型中不能有包含自身引用的字段,不然的话在移动的时候,这些自身引用的地址并不能得到修复。
如果我们给这个AddressTracker套一个Box,此时再来运行一下,可以发现地址就不会发生变化了。因为Box是堆内存分配,在移动的过程中,我们只会将这个指针移动过去,这个堆内存并不会发生变化。所以在大部分场景下,移动操作都是没有任何问题的。如果一个类型包含自身引用,那这个时候移动操作就不适用了。
这里我有一个例子,有一个类型叫做InlineBuffer,它里面有一个u8的数组,接下来又有一个指向这个数组的slice。我们来看这个set_contents方法,我们会将传入的这个buffer拷贝到自身的这个data数组中,同时将slice指向自己data有数据的部分。那么此时slice指向的就是一个与自身地址相关的地址。
下面有一个测试用例,这个地方我首先在外面声明了一个buffer变量,然后开辟了一个新作用域,创建一个tmp_buffer,并且为tmp_buffer设置了一定内容。接下来我将这个tmp_buffer移动给外面的这个buffer,然后我对tmp_buffer做一个重新的初始化,并且附了一个新的内容。我们来运行一下这个测试用例,可以发现最后一行的这个assert,外面的buffer并不是我们预想的第一次复制的内容,它的内容被后面的这次设置给覆盖了。
这是因为我们第一次复制的时候,这个buffer里面的slice指向的实际上是这个tmp_buffer的一个地址。那么在外面的这个buffer的结构体里面,它的slice指向的仍然是这个tmp_buffer的一个地址。所以我们如果对这个tmp_buffer重新赋予一个新的值,那么外面的这个buffer由于指向的地址相同,也会受到影响。
所以如何避免这个问题,我们就需要引入Pin这个新的类型。我们先来展示一下Pin是如何使用的,然后再来讲解这中间发生了什么。Pin的目的是将一个类型的地址固定住,也就是说当我们在使用这个类型的时候,编译器可以保证这个值的地址不会发生变化。
为了实现这个效果,我们首先给这个类型增加一个PhantomPinned,这是一个marker,它可以标记当前的类型是被Pin住的。它的效果实际上是会给这个InlineBuffer做一个!Unpin的否定实现。关于Unpin的作用,我们后面会去讲。
然后我们去构造一下这个InlineBuffer。接下来我们将这个set_content方法做一个改造,我们这个地方不能接受一个mutable的引用,我们需要将它改成一个Pin住的mut引用。那么它的意思就是说,我们的这个self的指针是可以保证不会发生变化的。当我们看到这个self是以这种方式,以这种类型呈现的时候,我们就可以知道这个self的地址从现在开始到这个变量销毁都不会发生变化。那这个就是Pin的一个保证。
那么接下来的话,self的访问操作就会发生一些变化。由于编译器没有办法保证你接下来会不会对这个self做一个移动操作,因为虽然self的地址不会发生变化,但是你仍然可以用一个其他的值去覆盖掉自己的内容。所以说接下来的所有操作都会变成unsafe的。我们套上一个unsafe的block,通过get_unchecked_mut,我们可以拿到一个自己的引用。那as_slice这个作为只读的操作,我们不需要做修改。
那么接下来set_contents就不能直接被调用了,因为它需要接收的是一个被Pin住的self。那如何构造一个被Pin住的self呢?有两个办法,一个办法是通过Box::pin,它可以创建一个在堆上的InlineBuffer的空间,并且将这个地址Pin住。Pin住的地址,我们没有办法随便拿到它的可变引用,所以说也杜绝了对它的一个复制操作。也就是说这个block里面的复制操作就没有办法通过safe代码去实现了。我先删除掉它。
那么如果想调用这个set_contents方法,我们可以通过as_mut(),然后再调用set_contents。as_mut()会将这个buffer变成我们这个set_content需要的这个参数类型,我们可以看一下,那它与我们的这个参数签名是一样的。这种方式就是通过分配一个堆内存来固定住这个InlineBuffer的地址。
当然我们还可以在栈上把这个地址固定住。我们回到最开始的实现,我们可以用到一个pin!的宏。好,那么这样的话,也同样可以创建一个我们需要的这样的一个类型。但需要注意的是,这个类型它是不可以被copy的,所以我们在调用方法的时候,最好还是通过这个as_mut()再重新创建一份这个Pin指针,再去调用set_content。
然后我们会发现这个buffer,这个变量已经被move到这个Pin里面了。也就是说当我们创建好了一个在栈上的Pin指针的时候,我们对原来的那个栈对象的那个变量就不能去做操作了。这个时候也可以保证我们不会对原来的对象做一个复制操作,或者取它的内容。这样都有可能会暴露出它的底层的这个自身引用指针。所以这个地方我们也改成Pin的类型,然后运行一下,可以发现我们的测试是可以通过的。
然后我们来说一下这个地方发生了什么。首先我们创建了一个Pin的指针,这个Pin我们可以看一下它的结构,其实它就是单纯对指针做了一个封装,它的内存结构跟这个里面的指针是一样的。然后我们要知道的是,Pin Pin住的是一个指针,而不是一个值,所以说Pin里面承载的只能是一个指针类型,它要么是一个Box,要么是一个引用。
那Pin还有很多的构造函数,比如说这个new。我们首先创建一个String,它是一个slice,然后我们可以创建一个这个slice的一个Pin地址。但是由于这个String slice它并不包含一个自身引用,所以说这个pin_s跟s,其实它的作用是完全一样的。甚至我们还可以通过get_ref()这个方法拿到这个指针本身。
但是当我们尝试对上面的这个buffer做这个构造的时候,我们就会发现其实是编译不过的。比如说我们想去创建这个Pin<&mut InlineBuffer>,然后我们同样是给一个它的指针,这个时候你会发现因为它包含了这个PhantomPinned,它不能被这样子创建。
那这个时候发生了什么呢?由于Pin的这个new它接收的是一个指针,那么它就一定要保证这个指针是一定会被Pin住的。什么意思呢?就是说这个Pin::new想去调用,要不然这个指针它是不需要被Pin住,像正常的String或者int基本类型,它没有包含自身引用,所以说这个地址它Pin不Pin无所谓。那这个时候你可以随便的去对这种指针去调new。
但如果像是我们这种InlineBuffer,当你想创建一个它的Pin指针的时候,由于这个类型它包含了自身引用,我们对它做了这个!Unpin的否定实现,那这个时候这个new它所接收的这个指针编译器就不能确定它是否就一定是Pin住的。
比如说我们这个地方让它能够成功构造,并且我们使用了这个Pin指针。比如说我们把这个地方改成mut,然后这个地方也改成mut,那么我们能拿到一个Pin<&mut InlineBuffer>这样一个指针。然后我们再去对它调set_contents,这个时候set_content就会把这个InlineBuffer的data的地址赋给它的那个slice,自身引用的这个情况就创建了。
此时我们完全可以把这个pin_buffer drop掉,由于这个地方我们是借用构造的,所以说这个buffer我们依然可以自由的去使用,我们仍然是可以对它进行一些像赋值、移动的操作的。那也就是说,我们这个Pin的指针的创建是一个不安全的过程。那编译器自然不能让这个情况发生,也就是说当我们去做这个new的操作的时候,编译器没有办法确定这个指针是否一定是被Pin住,所以它就不会让我们可以编译通过。
那么什么情况是我们可以确定这个buffer是一定,它的地址是一定固定住呢?就是当我们创建一个Box的时候,此时这个box_buffer在销毁之前,它的地址都不会发生变化了,因为它是在堆内存上分配的。所以说我们可以对它创建一个Pin的指针,这个操作是没有问题的。此时这个box_buffer也不能再使用了,因为发生了一个移动,这个Box移动成了一个Pin的指针。
那么另外一种就是我们说的,我们直接创建了一个栈上的一个Pin指针。这个时候原来的buffer也被移动进来了,然后创建了一个临时的变量在内部。所以说这个地方拿到的这个Pin,它也可以保证地址不会发生变化了,因为你再拿不到这个原来的buffer了,你不能对它做任何操作了。你唯一能操作的就是这个已经被Pin住的指针。
所以说这个类型的出现,其实就是保证当我的函数看到这个类型的时候,我接下来的操作一定是安全的。因为我的这个self,它的地址在这个函数能够执行的时候就一定不会发生变化,这个是由编译器去保证的。如果你能创建出这个Pin的指针,那就证明这个地址是被固定住的。
那么这个就是Pin的一个工作原理,其实就是一个类型系统的应用。当然Pin还有一些其他的高级用法,例如structural projection。那么由于视频篇幅的原因,这里就不再展开了。有兴趣的话大家可以去看Rust官方的文档。
那么总结一下,Rust里面会包含两种类型,一种是普通类型,那么它不包含自身引用,实现了Unpin。另外一种是Pin的类型,它包含了自身引用,不实现Unpin,那么一般会包含一个PhantomPinned这样的一个marker。
那么对于普通的类型来说,你的一个Pin指针可以随便的创建,那么这个时候Pin指针跟原来的指针表现的是相同的,也可以随时的去转换成原来的一个指针类型。那这也是Unpin的一个操作。
那么对于Pin类型,我们只能通过某些特定可以证明其地址不再发生变化的方式去创建它的Pin指针。比如说Box::pin,那它在堆内存上创建的时候就已经是被Pin住的。或者是通过这个pin!的宏,可以把一个栈上的变量给它Pin住。那这个时候一旦Pin指针形成,那它就一直会持续到其销毁,保证这个Pin指针不会转换
Pin的本意是 别针/大头针(n), 钉住(v)
Go 和 Rust 中的 Pin 概念虽然名称相同,也都取”钉住/固定住”之意, 也都是固定一段内存????? 但实现及用途大有差异。
Go 中的 Pin:
Go 中的Pin位于runtime包, 是2023-08-08发布的Go 1.21版本新增的特性.
通过提案的讨论不难发现, 该API的产生主要归因于CGO. 过往的方式 “在 C 里面申请内存,将 C 的指针返回给 Go,然后 Go 再复制成 Go 对象”,有两次内存复制, 较影响性能.
更多参考 cgo 改进:Go 1.21 新增 runtime.Pinner 类型
Pin()用于内存管理和垃圾回收优化,特别是在处理指向堆内存的指针时。其可以防止垃圾回收器移动对象,优化垃圾回收性能.
具体来说, Pinner.Pin()接受一个指针类型的参数,并会将指针指向的内存区域标记为不可移动—-即使该对象不再被任何变量引用,也不会被回收,直至调用 Pinner.Unpin 取消固定
示例:
1 | import "runtime" |
更多参考 Go语言中的Pinner.Pin
Rust 中的 Pin
与Go中Pin因为”年轻资历浅”而导致的存在感不足相比, 即便在概念繁多的Rust中,Pin也有相当存在感. 尤其在异步编程中,扮演了关键角色, 也因此,几乎任何系统讲解Rust的教程或书籍,都会有Pin的一席之地.
实际上,Pin的直接作用是处理自引用结构体,之所以和异步编程关联万千,是由于async/await是Generator实现的,每个await将被编译为一个匿名结构体 如果在其中有跨await的引用,就会导致生成的匿名结构体 为自引用结构体。
实际上,Rust团队引入Pin就是用来解决Future的问题。
Pin
是一个泛型数据结构,其中包裹的 P 必须是指针
Pin只对!Unpin 生效
而 Unpin 是一个auto trait,即:自动为所有类型实现了此trait,除非:
此struct 实现了 !Unpin
此struct 包含PhantomPinned 类型的字段。
其他绝大部分类型为Unpin,用人话说就是我们前面提到的可以任意move的类型。换句话说,如果我们要用Pin就必须主动为我们的struct标记为!Unpin ,否则他就是默认Unpin。对于Unpin的struct,Pin会走一套独立的impl,由于这种struct可以随便move,Pin的约束对它也不需要生效。
在 Rust 中,Pin 主要用于处理自引用结构和异步编程。
作用:
- 确保某些类型的值在内存中的位置不会改变
- 支持自引用结构的安全使用
- 在异步编程中确保 Future 的内存安全
示例:
1 | use std::pin::Pin; |
总结:
- Go 中的 Pin 主要用于内存管理和垃圾回收优化。
- Rust 中的 Pin 主要用于处理自引用结构和在异步编程中确保内存安全。
这两种语言中的 Pin 概念反映了它们不同的内存管理模型和语言设计理念。Go 的 Pin 更多地关注运行时性能,而 Rust 的 Pin 更多地关注类型系统和内存安全。
https://space.bilibili.com/35891473/search/video?keyword=pin
https://space.bilibili.com/35891473/channel/collectiondetail?sid=2013124
原文链接: https://dashen.tech/2017/02/15/Go和Rust中的Pin-Unpin/
版权声明: 转载请注明出处.