https://space.bilibili.com/431719015/channel/collectiondetail?sid=2037355
老炮学Rust,实验 -> 结论 -> 再实验 -> 结论。 如果你的观点和实验结果不同,你又找不到实验的破绽,请别上头,立刻自我否决,虽然这很难受。 如果我的实验打破了你的固有错误观念,要么找出实验破绽,要么观念更新,要么胡拉乱扯的模糊我的观点。这


1、Rust:hello world 好 感叹号,要不带这个感叹号,我就不入坑了
整理后的内容
1、Rust:hello world 好 感叹号,要不带这个感叹号,我就不入坑了
https://www.bilibili.com/video/BV1JC4y1N76S/
这是Rust的第一节课,我们来看一下Rust的一个运行机制,还是从那个hello world开始,直接执行一下。我们看一下这个程序,它最终的结果是:已经把S2C下面的main.rs编译到target目录,debug目录下面的一个可执行程序(CH2)。这个应用程序已经被编译成二进制了,可以直接执行。这就是Rust带给我们的一个原因:为什么要使用Rust呢?它带来了极致的性能提升。
仔细观察,这里有一个感叹号,我们来看一下这个函数是在哪里定义的。其实它已经不完全是一个函数了,更像是一个宏(类似于C++的宏)。不过这个宏比C++的好一点,但也好不到哪里去,还是非常复杂。
如果没有传递参数的话,它会调用print!宏,什么都不会输出。如果有参数的话,它就会用print!宏来处理。我们来试一下带感叹号的调用,看看它调用的是什么方法。调用的是IO模块下的一段代码。我们把这一段代码拿出来分析一下。假如我们想打印一个数字,我们可以不用宏,自己写。然后这个$符号是宏里面的一个标记。感叹号是宏调用的一部分,我们传递的参数会被写到参数列表里。
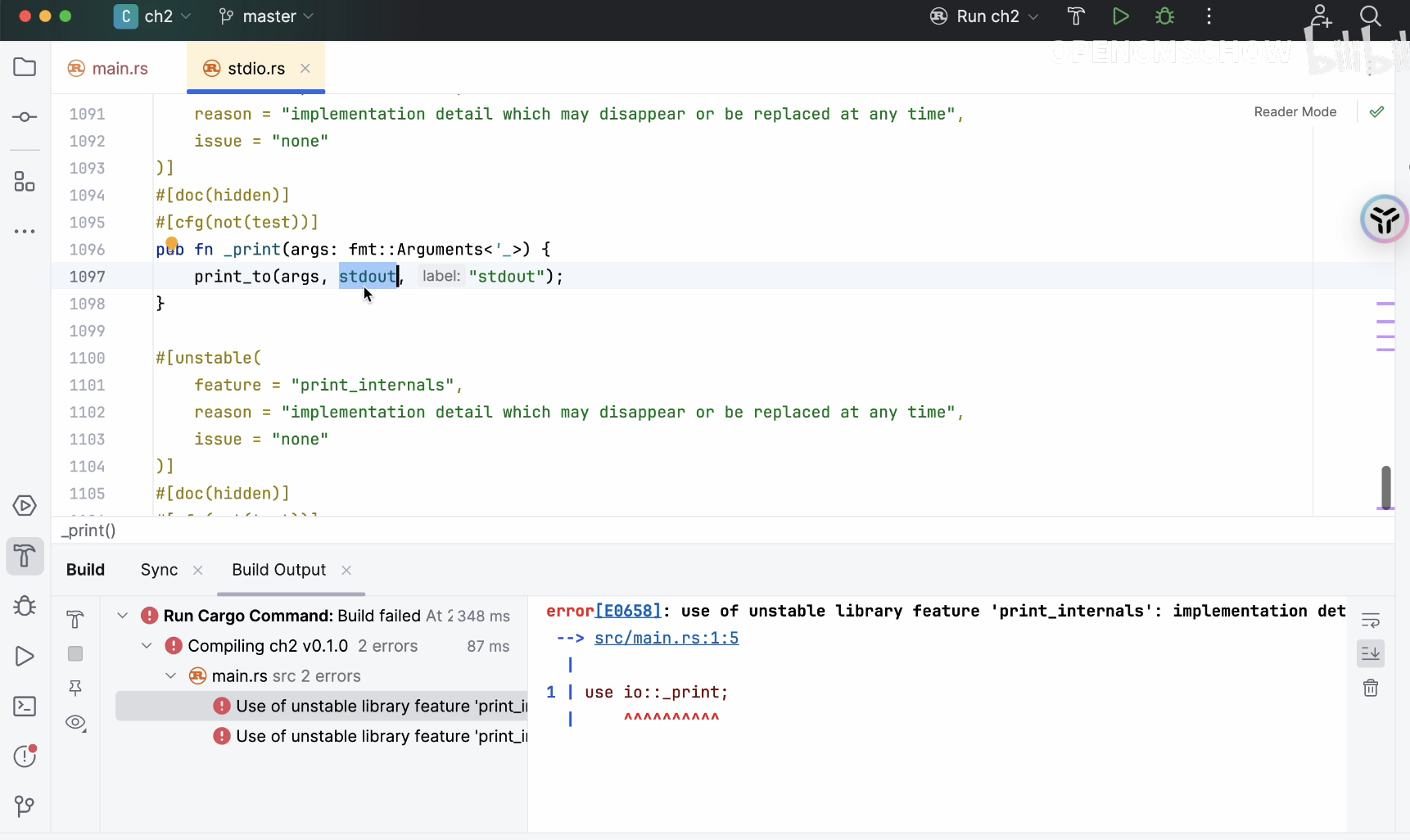
接下来它提示我们IO是一个下划线红色的标记,表示它没有找到这个模块。我们引入std::io模块,现在已经引入成功了。系统提示这个方法不稳定,比如尝试使用这个方法会得到“不稳定”的提示,不允许直接使用。那我们就来看一下这个不稳定的方法是怎么写的。因为它可能会改变,所以加了个下划线。
我们继续看它内部调用了一个print_to方法,打印到stdout。这里给了一个label和一些参数。我们的参数已经传递进来了,如果成功的话,它会return,否则每次都会执行相同的操作。
global::S是什么呢?这是第二个参数,也就是stdout。第一个参数是我们传递的值,第二个是stdout,第三个参数是label。我们看到了传递进来的第一个参数是x,第二个是stdout,第三个是label。每次调用这个方法时,都会执行相同的代码。
我们把代码打印出来看看它调用的是什么方法。我们注释掉不需要的代码,然后它调用的就是这个方法。根据之前的推断,fmt用的是第一个参数,也就是传入的值。第二个参数是global::S, 调用的是stdout,执行完之后会生成一个实例,再调用它。
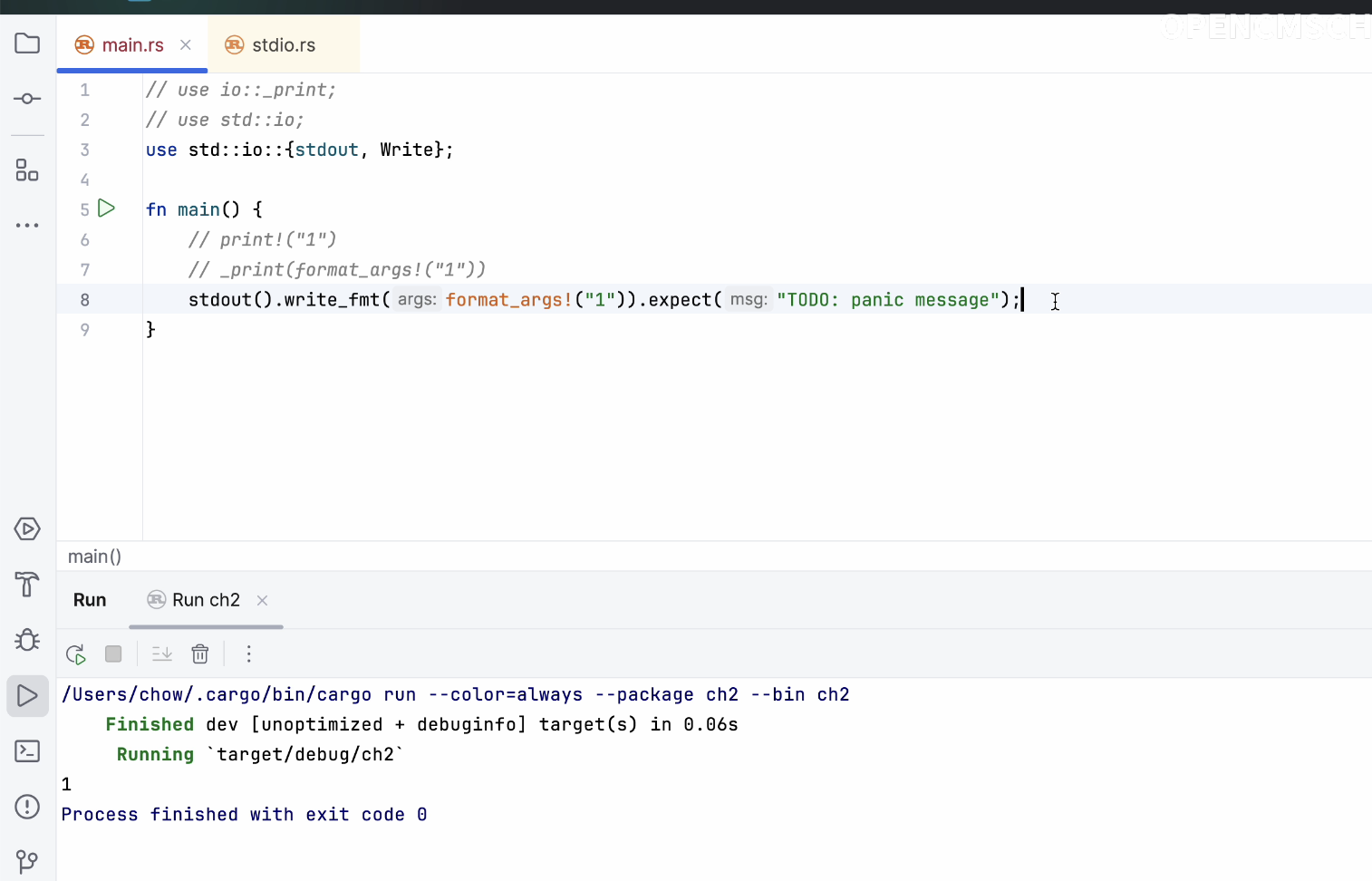
现在我们的stdout引用是错的,我们重新引入std::io模块。fmt会返回一个值,但我们不需要返回值,我们直接调用write_fmt,传入这个值,然后抛出一个异常。好,我们把不需要的代码删掉,这样也能打印出数字1。
但这里还有一个宏,怎么能把它去掉呢?我们来看一下这个宏。Compiler在编译的时候做了一些处理,这是我们无法修改的。没有调用实际的Rust的写法,所以这一部分已经交由编译器解决了,我们这边无法干预。
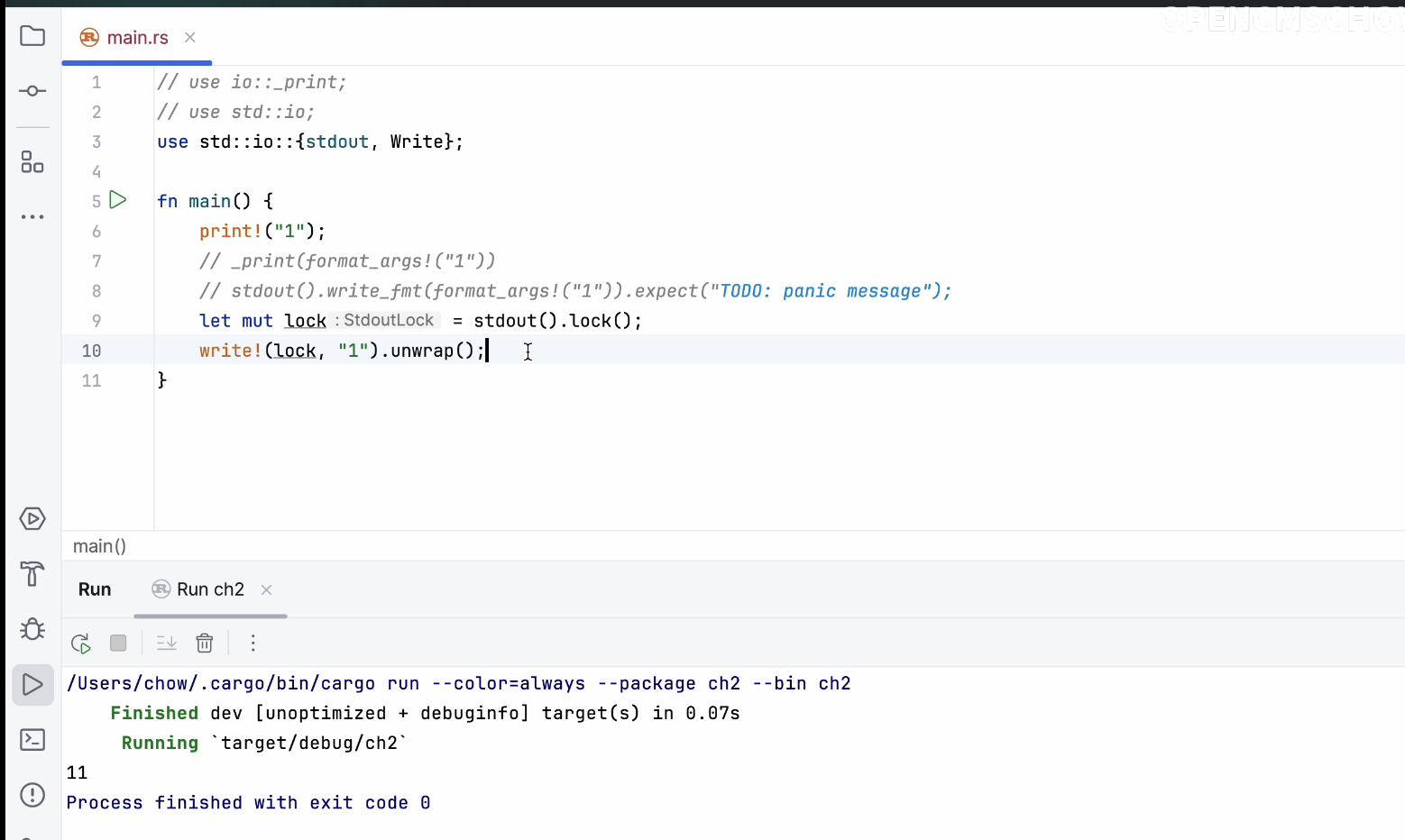
这是最终的结果。我们再看看有没有什么注释说明。注释解释说这是打印输出,然后执行了flush操作。其实这个操作有锁机制。如果我们使用锁的话,程序会是这样的状态。我们这样写,第三行和上面代码是一样的。我们删掉引用后,下面的代码可以没有分号,但上面的代码必须有分号。
返回值的代码我们都加上,没有返回值的代码我们也统一加上。这样这行代码应该也能输出数字1。
完全理解了!现在Rust带给我们的就是:将程序转换成二进制的可执行文件。Rust提供了一些宏来帮助我们开发,比如这个感叹号宏。虽然写起来和C++的宏一样复杂,但写好之后调用起来很轻松。最终的结果是Rust提供了一个极快的底层调用速度。
好,到这里就结束了,拜拜!
评论区:
1 | use std::io::{self, Write}; |
一宏不用(打印hello world)的方案
只要学会 & &mut drop copy clone move 内存的变化,和用生命周期分享内存,几乎和其他语言就没区别了
Rust能帮助你节约20%左右的硬件资源,更好的使用多核心处理能力,对富硬件的产品有利,部署的服务器越多,越需要它,单片机理论上也是可行的,但是没有直接用c和指令操作节约,但Rust好像一个照妖镜,内存管理模型,内存顺序模型,共享 独占概念不清楚的很快就会迷茫,但捅破窗户纸又很容易出来
- 科目一基本上是把语言上的概念搞明白,我会通过之前的经验,尽量通过易错问题探讨让大家在用Rust的时候可以表达基本意愿
- 科目二的时候我会重写链表和树,达到语意好用级别,进来往Rust语言特色上靠,差不多算合格程序员
- 科目三就是用Rust解决我的实际需求,写一套和大家共享笔记的软件,本地快速记录加网络共享,灵感来自git
再往后就需要接受市场检验了
2、Rust 结构体和函数 感觉漫步在控制森严的黑暗森林
Summary
本视频讲解了如何在Rust中使用结构体和函数,并介绍了Rust的内存管理、值传递和引用传递等关键概念。通过实例展示了如何定义和操作结构体,特别是关于可变和不可变引用的区别,以及Rust在编译期的严格约束和提示如何帮助避免常见错误。
Highlights
- 🔧 结构体与函数定义:本节讲解了Rust中的结构体定义方式,展示了如何给结构体添加字段以及调用函数。
- 💾 内存与值传递:Rust中的变量通过传递指针或值进行内存管理,强调了传递后无法继续使用原有变量的重要性。
- 🔄 引用与可变性:介绍了Rust中不可变引用和可变引用的区别,尤其是如何通过传递地址修改结构体中的值。
- 🛡 编译期约束:Rust在编译期通过严格的提示系统,确保代码正确性,避免内存错误,增强了并发编程的安全性。
Keyword
Rust、结构体、函数
Rust 结构体和函数:感觉漫步在控制森严的黑暗森林
在这节课中,我们将学习Rust中的结构体和函数。Rust与C语言类似,也有struct的概念。我们首先定义一个结构体,通常使用大写字母命名,比如S,它包含一个字段A,我们决定让它成为一个String类型的字段,另一个字段B是一个u32类型的无符号32位整数。
接下来,我们使用let来定义一个变量S,并通过S {}的形式来创建这个结构体的实例。对于字段A,我们给它赋值为字符串”AB”,而对于B,我们赋值为32。这里出现了一个问题:我们需要传递的是一个String类型,但我们传递了一个字符串字面量的引用。经过几次尝试,我们选择了第二种方法,因为这种方法使用了一个静态方法,并且这种静态方法在缓存中得到了优化,速度非常快。


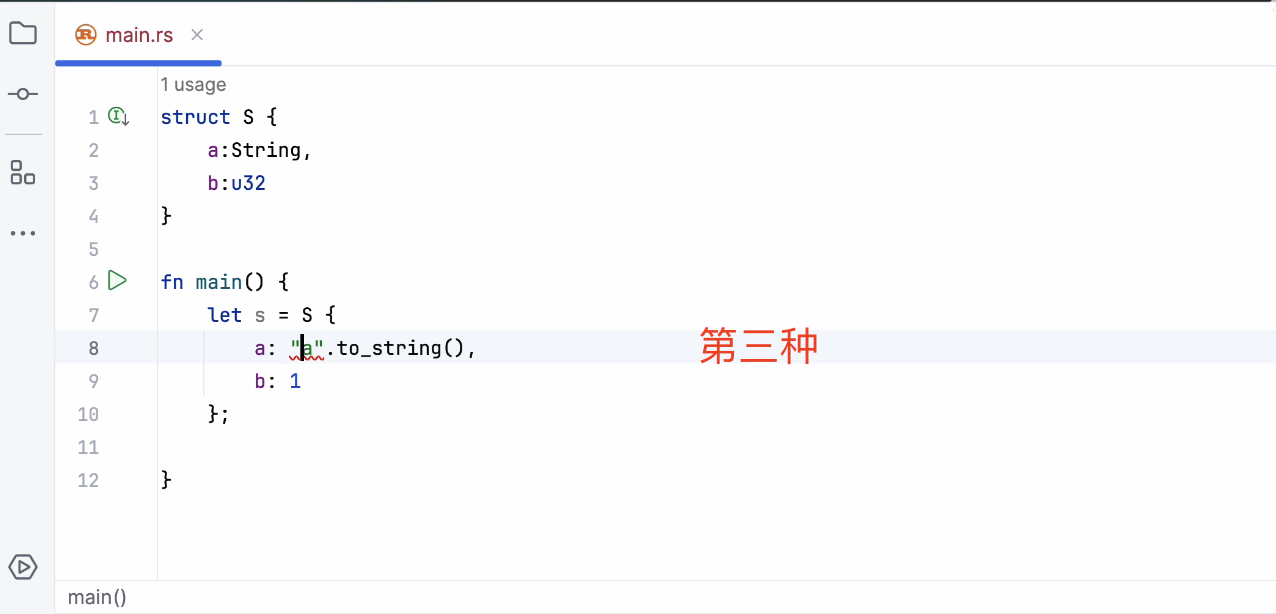
创建好结构体之后,我们可以使用println!宏来打印结构体的字段。比如,我们可以通过S.A来访问结构体的字段并打印出来。然而,这里出现了一个错误,因为Rust要求我们传递的是字符串的引用,而不是直接传递字符串字面量。我们回退并修改了代码,使其能够正常工作。
接着,我们讨论了如何定义函数。Rust中的函数定义很简洁,我们定义了一个叫做print_s的函数,用于打印结构体的内容。在这个函数中,我们使用了println!来格式化输出,打印出结构体的A和B字段。
然后,我们修改了结构体的字段值。比如,我们通过S.A = format!("{}{}", S.A, 1)来为A字段追加一个1。然而,这样的修改再次引发了错误。Rust提示我们需要将结构体声明为可变的(mut),并且还涉及所有权的转移问题。Rust的所有权机制非常严格,当某个变量的所有权被转移后,原来的变量就不能再被使用了。
为了绕过这个问题,我们引入了引用(&)和可变引用(&mut)。通过传递结构体的可变引用,允许我们修改其字段的值。我们尝试了在print_s函数中传递结构体的可变引用,并成功地在函数中修改了B字段的值。每次调用print_s函数时,B的值都会加1。
我们接着讨论了Rust中所有权的传递问题。如果我们将一个变量的所有权转移给了另一个函数,那么在所有权被转移后,原来的变量将失效,无法再使用。因此,如果我们希望在函数调用后继续使用结构体,我们需要通过引用来传递变量,而不是直接传递变量本身。
接下来,我们定义了一个名为modify的函数,这个函数接收结构体的可变引用并修改其字段。如果我们不接收函数的返回值,那么所有权将会丢失,导致后续对结构体的任何操作都无效。通过这种方式,我们理解了Rust的所有权和借用规则。
Rust中的所有权机制分为三种权限:
- 引用权:我们可以通过引用(
&)来只读访问变量的值,但不能修改它。 - 可变引用权:通过可变引用(
&mut),我们可以修改变量的值。 - 完全所有权:当我们拥有变量的所有权时,可以自由地修改或转移这个变量。
最后,我们总结了Rust的并发优势。Rust的所有权系统确保了数据的安全性,防止了数据竞争问题。通过严格的所有权和借用规则,Rust在编译时就能检测出潜在的问题,从而避免了运行时的错误。
这就是Rust结构体和函数的基本概念。Rust通过所有权、引用和借用机制,为程序的安全性和性能提供了强有力的保证。希望大家通过这节课能够对Rust的结构体和函数有更深的理解。
好了,拜拜!
评论:
同感,只能说能用引用尽量用引用,我用c写函数传结构体都会下意识地传指针,但用稍微高级一点的语言时就不会这样,在rust/c++里,直接传值可能导致堆里同一数据被多个变量引用,也就可能导致该数据被重复释放。rust好歹还会提醒你,c++可能会崩掉
释放两次胜似抢劫,好似你和同伙上高速服务区上厕所,你把车停8号车位,你同事先完事儿开走了,你出来后把别人停在8好车位的车开走了,美其名曰: 腾车位给下一位顾客用
二者的区别和联系,一句话就可以讲清:
引用是类型,借用是操作;借用产生引用,引用记录借用的范围。
3、Rust 列表 该死的【访问控制】 让你直呼C太好写了
Summary
这段内容讲述了如何在 Rust 语言中实现一个链表结构,重点介绍了如何处理链表节点的访问控制和递归打印。讲解了使用 Box 类型避免循环引用问题,以及如何通过实现打印方法来调试链表。
Highlights
- 🧩 链表结构的定义:定义了一个包含泛型
T的节点结构体Node,每个节点有一个值和一个指向下一个节点的指针。 - 🔄 避免循环引用:使用
Box封装节点以避免循环引用的问题,并介绍了如何通过Optional类型处理节点的初始化。 - 🛠️ 链表节点扩展:提供了一个方法来扩展节点,通过递归调用来处理链表节点的添加和打印操作。
Keywords
- Rust
- 链表
- 递归
整理后的内容如下:
3、Rust 列表 该死的【访问控制】 让你直呼 C 太好写了
https://www.bilibili.com/video/BV1Wc411k73c/
在 Rust 中实现一个列表,写起来真的让人头疼,尤其是访问控制这块,真是让人怀念 C 的简单。
首先,我定义了一个结构体 Node,这个结构体使用了泛型,这比较好理解。结构体里有一个 value 字段,类型是 T,还有一个 next 节点。这样定义起来其实很简单,接下来我们通过 Box 来封装节点,避免循环引用的问题。
接着,我们创建了一个根节点 root:
1 | let root = Node { value: 0, next: None }; |
创建好根节点后,我们继续创建第二个节点 second,然后手动将 root.next 指向 second 节点:
1 | let second = Node { value: 1, next: None }; |
写完这里后,我发现每次手动设置节点实在是太麻烦了,于是决定写一个方法来扩展节点。我们给 Node 实现一个 push 方法,用于向链表中添加新的节点:
1 | impl<T> Node<T> { |
写好 push 方法后,我们可以很方便地向链表中添加节点了:
1 | root.push(2); |
接下来,我又写了一个 print 方法,用于打印链表中的所有节点值:
1 | impl<T: std::fmt::Display> Node<T> { |
这样我们就可以顺序打印链表中的节点了:
1 | root.print(); // 输出:0 -> 1 -> 2 -> 3 |
然后,我把之前那些丑陋的代码都删掉了,使用这个递归的 print 方法,链表中的节点会按顺序打印出来。
不过,写完后我还是觉得有点麻烦,尤其是每次都得手动调用 push,而且这些递归调用也让我有点头疼。最终,我还是成功实现了链表节点的添加和打印。代码虽然不复杂,但整个过程还是非常纠结。
拜拜。
评论区:
喜欢拿仿射类型语言写链表的都是人才,各种意义上的。
要从皮开始吃瓜,都吃过了就知道榨汁更好[doge]
除了rust还有哪个通用affine typed lang?idris2?
月亮的脸i
还得是c语言,链表就一行void* next;
2024-01-04 05:30
程序转圈圈
Rust是只螃蟹呀,只有左右,没有前后
2024-01-04 07:09
叫声是哔哔哩
Rust可以比C还简单,因为有变量遮蔽、没有右左法则。首先就是右左法则,C语言中分析复杂类型声明要右左法则(我还好奇为啥不是左右法则[tv_黑人问号]按左右阅读顺序不行吗)Rust就是简单的尖括号封装;另外是变量遮蔽,旧的变量名不再使用的话可以分配给新变量,C语言是在语句块内必须给不同变量分配不同名字,不能用旧的变量名声明新变量。综上所述,光光右左法则还是尖括号封装,就决定Rust甚至比C简单[tv_斜眼笑][tv_亲亲]
2024-03-20 09:49
回复
chenyinheng30
c可以用类似contain_of的宏只要设计一个包含指向关系的结构体和插入、查找、删除函数,其他的任意结构数据类型只要组合这个就能用。
故人千寻
rust标准库里没有链表就是因为rust作者认为链表是坨shit
2024-01-02 17:34
2
回复
24K_SaltedFish
[doge]因为这玩意是真的没办法让cpu做寄存器,SIMD,预测执行优化
2024-01-02 23:05
1
回复
凛酷Rebellion
回复 @24K_SaltedFish :我猜你想说数据预取,因为预测执行是可以的
2024-01-05 08:51
回复
大佐-煤吸
看场景吧,本质上树和图都属于链表实现,难道没场景吗?看来数据结构在你面前就是一坨shit
2024-01-07 15:18
1
回复
wdNmdqa
谁说标准库没链表
4、Rust cargo add 没意思,就当看编辑器技巧
通过 cargo add rand 引入依赖,并使用依赖函数 rand::random生成随机数
编辑器技巧: 编辑器会自动将: rand::thread_rng().gen() 推荐到random(),很好用
整理后的内容如下:
4、Rust cargo add 没意思,就当看编辑器技巧
https://www.bilibili.com/video/BV1TN4y1W7vE/
快速入门,第四节课。我们学 Rust 肯定要使用一些 外部 的包,这里我们进入官方给的第一个例子,就是 rand 随机数生成包。来看一下这个包是怎么引入的,以及引入的包是如何调用的。
首先,我们要写入包的话,需要调用 cargo add 来添加随机数生成包 rand。这样就可以将这个包引入到项目中了。引入之后,我们就可以调用它了。当前这个库的一个典型用法是调用 rand::thread_rng().gen() 来生成一个随机数。我们可以将生成的随机数赋给 x,例如:
1 | let x = rand::thread_rng().gen::<u8>(); |
这里,我们可以看到,实际上可以使用 rand::random() 来代替 rand::thread_rng().gen(),这两个是等价的,所以可以用 random() 来简化代码:
1 | let x: u8 = rand::random(); |
这个 random 函数内部其实调用的是 thread_rng().gen(),所以我们可以直接用 random() 来替换它。然后我们打印一下 x 的值:
1 | println!("{}", x); |
但是,这里会报错,因为 random 这个函数需要指定一个泛型 T,而我们没有提供它。所以编译器提示我们在 x 后面加上泛型 T。例如,生成一个 u8 类型的随机数:
1 | let x: u8 = rand::random(); |
这样,x 的值就是 0 到 255 之间的随机数(前闭后开区间)。
总结一下,要引入这个 rand 包,首先需要使用 cargo add rand 来添加依赖包。然后,在代码中可以通过命名空间来使用它,例如:
1 | use rand::thread_rng; |
我们可以通过 thread_rng().gen() 来生成随机数。编辑器有个功能,可以帮我们简化代码,将其转换为 rand::random()。因此,下次使用时,可以直接从 rand 命名空间中调用 random() 函数来生成随机数。
这就是包的引入方法。
拜拜。
5、Rust 从给定的字符集生成10位密码https://www.bilibili.com/video/BV1SC4y1N71E/)
让我们用 Rust 从 char_set 这些字符集中,选择任意的十个字符,组织成一个密码并显示在屏幕上。我们实现的思路是通过十次随机的挑选,产生十个字符,将这十个字符收集在一起,形成一个字符串,最后把它打印在屏幕上即可。
具体处理过程如下:我们使用一个从 1 到 10 的循环,这个循环中的横线 _ 表示我们不关心具体的输入值。然后将生成的结果收集起来,使用 collect 函数。由于 collect 是一个泛型函数,默认情况下它并不知道我们要收集成什么类型,所以如果不指定类型,编译器会报错。
我们需要给定一个索引,这个索引是一个随机数。刚才我们已经确定了,随机数的范围是从第 0 位一直到 char_set.len(),即字符集的长度。然后我们收集这些随机选择的字符,结果是一个 U8 类型的集合。
接下来,我们在 map 调用中使用 char::from() 方法,将 U8 类型转换成 char 类型。转换完成后,再进行一次 collect 操作,这样就会得到一个完整的 String 字符串。
最后,我们把生成的密码打印在屏幕上。每次运行程序,生成的密码都会不一样。
好了,拜拜。
33、Rust多线程晦涩?不存在的,晦涩是因为你没搞懂stack内存=就是copy,move也是copy,函数调用也是copy 闭包的&也是copy
有时候你会混淆一个概念,是因为组成它的子概念就是混淆的。就像你知道& &mut是为了编译优化,这本身就是权限锁,你却不由自主得往mutex扯一样,因为前者你就是混淆的,恰好一看了后者,后者用到前者的一些概念,你更迷糊了,如果你一直保持头脑清醒,就没那么多困扰了。
记住:麻烦都是自找的
整理后的内容如下:
打铁啊,我把之前那个单线程的改成了一个双线程的,嗯,写入三线程的吧。我们现在有内线程,有T1,还包括第二个线程。写这个程序的时候,很容易让人产生误解:这个X的地址到底变不变?因为我们这边 print 总是用X的一个共享引用。如果你用的是共享引用,那是不是意味着X不变了?地址是不变的?嗯,你想一下是不是不变?错,其实是变的。
为什么呢?因为X是u8,u8是可以copy的。所以你这个move,实际上是把X从main的stack区拷贝到这个thread的stack区。再讲一下,为什么一个程序要执行,它在内存上的主要体现就是一个stack。这个内存区要反复进行pop和push操作,程序执行时,内存会反复地往里面压入和取出数据。
我们不考虑其他硬件设备或处理器,只从内存的角度来看,它需要一个stack区,而且这个stack要足够高。thread当然可以指定一个高度,根据程序的复杂度,可以指定stack的高度。因为要节约内存,中间这些空的内存是备用的。比如说main先分配了一块stack区,T1又分配了四个G,所以T1要留够给main足够的空间,T1会跳得很远。然后T2再申请内存,它也会跳得很远。这些内存没被使用,是备用的,就像开酒席,你50桌,备个13桌、15桌这样的。这就是thread的一个缺点,它很浪费内存,尤其是stack区域的内存。当然,你可以指定它的大小。
现在,问你一个问题:X这个地址,main的地址和thread中X的地址,T1和T2的地址一样吗?第二个问题:Y的地址和X的地址是什么关系?Y的地址是大于X,还是小于X?还是Y和X差得很远?直接看结果吧。
main的地址处于16F0这个段,T2的段是16F4,T1的段是16F2,你看它们很匀称地排列在这里,而且有各自的内存范围。我们看一下,main的X地址是这个段的B7,再看T2,T2的X地址是07,已经在它的段里面了。T2的Y地址比07大,跑到57了,也就是在它的后面。这表明,X先申请,Y后申请。
所以,在线程里创建的变量会在你的范围里直接使用,因为系统帮你copy了。move其实就是copy,因为X可以copy。接下来我们做个例子,把X换成Box,看看有什么错误,再分析一下Box的缺点。
T1的X地址是07,T2的Y地址是57,你看它们的地址非常相似。为什么?因为它们的跳转距离要做内存对齐,跳转的距离都是相等的大小,因为没有指定,所以是默认大小,这就是线程的秘密。
我们做完之后,X这个变量好像从main线程的地址飞过去了。其实不是,它们有各自的地址,X属于T1的地址,T2有它自己的地址。我们把X换成Box,大家都知道Box是一个指针封装,是一个自销毁的指针封装,所以它不能copy。你copy就要clone,它不能直接copy。如果不clone,默认情况下是copy的,但Box不能copy,你必须明确地去clone。
如果换成Box会怎么样?你就不能move了。move不了会怎么样?move不了会把原值move过来,复用了X的地址。move过来之后,由这个线程来销毁main的heap区的内存。当然不能说是main的heap区,它们的heap区是共享的。由线程来销毁的话,之后你就不能再有了。为什么?你再有就会产生多次销毁。move只能move一次,不能move两次。
如果是copy,就完成了copy。如果是不能copy的,move就真正把所有权放出了。我喜欢叫它“释放权”,你们可能叫“所有权”,都一样。如果你把释放权放出去,相当于两次释放。两次释放会导致什么?会导致你把别人的内存段释放掉。这就是X的地址为什么可以这样想。
线程为什么不报错?因为X的地址在T1和T2的stack区重新申请了,所以它们各自持有并负责销毁。因此,它们是跨段的,处理器可以多点执行,你可以把它当成一个独立执行的函数。
如果你drop外面的U8会怎么样?一个可以copy的变量,drop它会怎么样?你把copy的变量drop掉,这就相当于什么都没做。Rust会告诉你does nothing。也就是说,你多此一举了。因为你传递变量时已经copy了,你drop掉这个copy的内存是完全没有必要的。
解释完了,看起来很简单,但考验的是你Rust的基础。如果你之前学过borrow、immutable borrow、mutable borrow,那现在就可以考验你的基础了。如果扎实,你就不会错,不扎实你就理解不了。你几个概念混在一起,我不相信你能理解。如果你能理解,那你就是神,超越神的存在。把一个简单的问题复杂化后,你理解了,我不信。
好了,拜拜。
猛錿芐屲-僭越版
你这个例子不够好,覆盖的不全面。你应该自己定义几个 struct。impl clone ,impl drop。还要有几个 struct 是 impl sync 和 send 的。
然后再弄到 thread 里面。有的有 move 有的没 move。这样才全面。不然你这个会误导初学者
2024-02-19 01:56
真不错,这个思路。我还没把大家的思路引到共享内存与并发呢[吃瓜],你这一贴,让大家顺理成章的找到了共享main stack的方法,其实可以先是heap的leak 再到static 最后 到main的stack,这样能让观众顺序渐进的顺理成章的进来
标准库Mutex在多线程情况下不公平,某一线程容易在刚刚释放Mutex后瞬间重新锁上,导致其余线程很难锁定该资源。因此建议还要学习第三方库。第三方写了parking_lot,提供FairMutex,终于能公平(fair)了,parking_lot能解决标准库的锁不公平的情况
34、Rust的借用借用体系为啥不能满足线程间共享内存的需求
Rust的借用体系无法满足多线程间共享内存,哪怕是读,因为自动Drop对对象生命周期的约束,无法确保空悬的存在
呃,之前讲的多线程已经讲了好几节课了,但一直没有切入核心点。其实,多线程的核心就是共享变量来共享内存。简单来说,就是共享这个u8。不过,这并不是现成的。多线程的目标其实是去修改某个地址。我们可以用shared x1和shared x2来标定这个地址。这个地址对应的是一个X,它新开了一块记录地址的内存,用来记录这个u8的地址。这块内存是一个类似于SC区的内存,相当于双级寻址,先找到地址,再通过这个地址获得值。
作为地址本身,它在堆栈中非常容易拷贝。我们可以将它拷贝进来,但你不能不考虑到线程之间的区别。T1和T2是两个CPU可以单独处理的线程,而T1和T2又派生自主线程main。因此,即使main结束了,T1和T2也可以提前结束,也就是说它们的生命周期是独立的。
我们可以提前释放这个地址中的X所指向的内存。但是,如果你共享这个地址,即使你称之为读锁,问题仍然存在:如果被读的内容消失了,这在Rust的单线程处理模式下是可以处理的——你先销毁,再销毁其他内容。但是在多线程中,这种顺序是不一定的。
假设你传入的地址是X1,这个地址指向的是u8,但它的生命周期可能已经结束。于是Rust会提示一个错误:x does not live long enough,意思是X的生命周期不够长。Rust的join函数不仅确保了当前线程加入到主线程并阻塞等待执行结束,它还隐含了一种先后关系,即“happens-before”关系,确保了某些操作在其他操作之前发生。
为了让X的生命周期更长,我们可以使用Box来包裹它。通过Box::new,我们可以把这块内存变成不可修改的堆区内存。假设X2等于Box::new,这样X2就变成了一块不可修改的内存。然后我们可以用&*X1来共享这块内存。
刚才出错的原因主要是因为使用了独占锁。独占锁在释放写权限后,不能再修改内容。因此,它只能共享两个读锁。通过给出地址,这个地址相当于指向堆区的一个不可修改的内存地址。这样一来,它就变成了一个共享地址,可以被多个线程读取。
这和Rc类似,Rc表示这个地址不会被销毁。Rust要求我们必须拿到所有权(ownership),而所有权的获取必须通过unsafe写法来完成。如果我们不使用unsafe,Rust会认为该地址不能被销毁。也就是说,这个地址在程序执行期间会一直存在。
通过使用unsafe,我们可以自己确保这个地址的安全性。不过,如果不使用unsafe代码,Rust的规则会阻止内存地址的销毁。Rust的规则确保了线程间共享的内存地址不会被提前销毁。
为了实现内部可变性,我们可以使用Cell或者RefCell。通过这些类型,我们可以实现内部可变性,从而允许多个线程共享同一块内存。不过,内部可变性引入了数据竞争(data race),因此需要使用锁(mutex)来避免这种情况。
Mutex的概念就是内部可变性的一种实现,它不仅实现了内部可变性,还实现了原子操作。Mutex内部有一个锁(guard),用于在内存操作中确保锁的自动释放。这种封装非常先进,所有的原子操作,包括Mutex和Condvar,都是基于原子变量和内存顺序的。这两个概念用于控制内存操作的顺序隔离。
总之,我们通过这种方法实现了对main线程内存的共享。main线程的内存申请来自堆区,而堆区内存是不连续的。这就像建高速公路时遇到钉子户一样,钉子户不拆,导致这块内存无法被连续使用。因此,我们可以把共享的内存放到其他段,比如第10段,而不是让它占用重要的内存区域。
这就是完整的整理版本,保持了原文的逻辑和内容。
四维汉堡包
主要原因还是因为rust允许子线程在主线程结束后继续运行,这是官方给出的类型签名:
pub fn spawn<F, T>(f: F) -> JoinHandle
where
F: FnOnce() -> T + Send + ‘static,
T: Send + ‘static,
解释(机翻):
事实上,如果线程及其返回值可以比它们的调用程序更持久,我们需要确保它们在调用之后是有效的,并且由于我们不知道它何时返回,我们需要尽可能长时间地保持它们的有效性,即直到程序结束,因此是’static生存期。
2024-02-19 09:08
3
回复
UP主觉得很赞
程序转圈圈
不得不说你是真的厉害,你的理解书的契合度极高,一个变量 通过一个方法生成了独占锁,那么这个变量的所有权就交给操作系统了,如果不使用unsafe只使用标准类型系统,这个独占引用就相当于此刻拥有了静态生命周期,但它所在的内存位置,让后续程序相当难受,特别是大的连续内存申请,好多不必要的需要和它打交道
2024-02-19 09:34
1
回复
程序转圈圈
请教,这句话是否意味着,main死了以后,只是告诉其他线程该死了,其他线程死不死,需要看结束的指令落后当前指令多少。main不负责杀死所线程后才死,而是自己先死,并通知它们死,死的时机是收到命令,也许收到前已经跑了好久了
2024-02-19 09:39
回复
四维汉堡包
回复 @程序转圈圈 :帮你翻了一下书,这是原话:
If the join handle is dropped, the spawned thread will implicitly be detached. In this case, the spawned thread may no longer be joined. (It is the responsibility of the program to either eventually join threads it creates or detach them; otherwise, a resource leak will result.)
翻译:
如果句柄析构,则派生的线程将隐式detached。在这种情况下,spawn的线程可能无法被join。(程序有责任最终join或它创建或detach的线程;否则,将导致资源泄漏。)
2024-02-19 10:03
回复
四维汉堡包
回复 @程序转圈圈 :至于线程,我不是科班,只能将其理解为一个操作系统提供的概念。也许操作系统会在主线程结束后发信号结束子线程,也许操作系统会继续运行该线程直到线程自己结束,这一切应该取决于操作系统自己的定义。
2024-02-19 10:05
1
回复
程序转圈圈
不仅仅是,主要原因是传入子线程的main线程地址,不能确保在子线程运行期间一直不被释放,缺少生命周期保证
2024-02-19 10:10
回复
四维汉堡包
回复 @程序转圈圈 :我只能说目前我没在文档上发现detach后线程如何结束的保证[吃瓜]
2024-02-19 10:13
回复
程序转圈圈
回复 @四维汉堡包 :我实验的结果是,main线程结束,子现场跟着结束,那怕它执行的是独占的print函数,函数直接被操作系统打断
2024-02-19 10:25
1
回复
程序转圈圈
回复 @四维汉堡包 : 你的细节把控力是真强,这和科不科班没关系,等会我再加一期实验来验证你的猜测。
2024-02-19 10:31
1
回复
cainissa
回复 @四维汉堡包 :系统会解决它,只要能正常退出就行
2024-02-19 21:32
回复
小马TX_Official
做了个实操
如果你在主线程里开了个小线程(这里叫父线程)
再在父线程里开一个子线程
那么只要主线程 main还活着,父线程return不影响子线程继续存活,但此时主线程已经没有join子线程的方法了。这就是为啥thread::spawn要求闭包有static周期,因为不能确保借用的父线程还存活
thread::scope生成的子线程会确保在父线程结束前结束,因而可以有非static的生命周期,并可以借用父线程数据
主线程结束后所有子线程会被操作系统回收
2024-02-19 21:47
2
回复
UP主觉得很赞
程序转圈圈
理解了,就是说,除了main结束会通知系统干掉所有,其他线程在创建后在销毁上是自营的,它们的结束只有一种,执行结束或者错误,因为不可预估,所以会在定义的时候要求static周期,scope的清楚一些,也看到了一些约束,scope里面的变量可能会没发持续到里面线程都执行结束,你的留言很有意思,感谢,稍后我把这部分理解加上,还有四纬的理解,稍后我把这两个都单独验证一下
实际上,linux的线程是通过轻量级子进程实现的,理解这个,很多事情都能理解了
35、为了阻止heap碎片化,我们把共享变量提前到10段地址
Box::leak能够实现 thread1 thread2 共享 main申请的地址,但是对heap的破坏力太强,严重影响了heap的大的连续内存的申请效率(引发多次随机尝试),所以我们提前把需要共享的内存放到10段,提高heap效率。
啊,欢迎回来,我又把之前的代码改了一下。现在换成static,把变量强制放到幺零段(10段)。这么做有什么好处呢?因为如果之前使用的是堆区(heap)的地址,堆区的内存地址是不连续的。堆区地址的不连续性就像高速公路上一样,如果你在上面放了一个Box,就相当于在上面扎了个桩。这样一来,如果你需要申请一段很长的连续内存,堆区可能会跳过这个点,从而导致内存地址不连续。
内存地址不连续不仅影响了申请更长内存块的效率,而且它的存在是永久的。例如,你申请了1万个地址,这1万个地址看起来只占用了1万个空间,但实际上你可能有一个11个单位的空间却无法使用。这是因为这些1万个点已经把内存切割得无法存储更长的地址。内存管理系统需要反复计算哪里可以存下这段内存,这会大大降低申请内存的成功率,尤其是在大内存申请时会不断跳转,增加随机性。
所以,堆区的这种特性对性能影响很大。因此,我们把变量提前放到10段。这样做的好处是什么呢?首先,我们没有给它写权限,所以这个地址是安全的。这里需要注意的是,static变量的地址是属于main线程的,T1线程是从main线程派生出来的,所以X的地址是从main传进来的。他们的地址是一样的,因为X属于main。我们可以验证一下,X的地址确实是一样的。
之前我们讲过,static变量的地址不会被拷贝。它是一个指向内容的指针,而这个指针本身是不能被拷贝的。为什么不能拷贝呢?因为如果拷贝了,就会存在两个指针指向同一个内容,这样会导致同一块内存被多次释放。Rust的规则是,一旦一个变量产生,它就要负责销毁该地址,因此同一块地址不能被两次销毁。这也是Rust的基本规则。
你可能会问,既然之前不能拷贝,为什么现在可以了呢?这是因为这里我们并没有销毁地址,而是直接引用了地址。Rust中,地址的引用规则是,如果你不销毁地址,那么你就可以安全地共享这个地址。这三次引用的地址都是一样的,我们可以通过实际验证来确认。
这三个地址是程序段的地址,它不属于T1线程,也不属于T2线程,而是属于main函数。在main函数执行之前,程序就已经把这些内容放到了10段,所以它们的地址是一样的。这就实现了Rust中的多线程安全共享。
那么,这个地址能修改吗?如果你尝试修改这个地址,实际上是没有意义的。为什么呢?因为一旦你修改了X,这个地址就会变成T1线程中的一个指针,指向T1所管控的内存地址。而一旦T1线程执行完毕,它就会释放这块内存。
如果你能理解到这里,那么你就已经入门了多线程编程。接下来,我们尝试做一个可以改变的static变量,用来共享地址。我们来看一下之前提到的static地址,并把它换成u8,看看它的地址是否一致。这应该可以打破你对多线程的一些误解,尤其是关于内存地址的误解。
好了,继续往下看,后面还有更精彩的内容。如果不介意的话,记得给个赞哦,谢谢!
原文链接: https://dashen.tech/2018/09/07/Rust-经验速转/
版权声明: 转载请注明出处.