https://github.com/cuishuang/rustchinaconf2024-slides
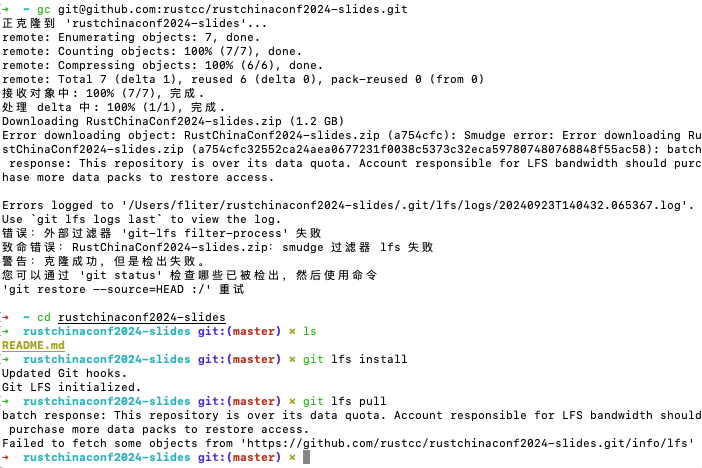
其他人也有这问题:
https://github.com/rustcc/rustchinaconf2024-slides/issues/1
https://github.com/git-lfs/git-lfs/blob/main/docs/spec.md
看起来是lts配额不够了
setting–> billing
https://rustcc.cn/2024conf/schedule.html
1.人人可用的Rust-Rebecca Rumbul
https://openuk.uk/profiles/dr-rebecca-rumbul/
Rebecca 是 Rust 基金会的执行董事兼首席执行官,该基金会是一个全球性非营利组织,负责管理 Rust 语言、支持维护者并确保 Rust 未来安全、可靠和可持续。她拥有政治与治理博士学位,曾在世界各地的政府、议会和发展机构担任顾问和研究员,倡导开放和透明,并开发改善数字参与的工具。除了全职和顾问角色外,丽贝卡还是英国广告标准局的非执行董事和理事会成员,以及 Hansard Society 的受托人。
https://tictec.mysociety.org/tictec-archive/2018/speaker/rebecca-rumbul.html
https://www.turing.ac.uk/people/external-researchers/rebecca-rumbul
https://www.youtube.com/watch?v=37tGgi3OT3E
https://www.linkedin.com/in/rebecca-rumbul-96a5441a/?originalSubdomain=uk
有啥过人之处??
大家好,我希望你们在这个活动中过得非常愉快。我很抱歉无法与你们一起,但我希望不久的将来能加入你们。我是瑞贝卡·拉姆布尔,Rust基金会的执行董事兼首席执行官。今天,我想和大家谈谈Rust对所有人的意义,以及Rust基金会如何打算支持语言的维护者和开发者,无论是在中国还是全球范围内。
关于Rust基金会的一些信息:我们是一个独立的非营利组织,我们的职责是维护Rust编程语言及其生态系统。这意味着我们要支持、维持并拓展Rust编程语言的使用范围。我们希望通过战略投资、虚拟和面对面的合作、培训和教育、课程提供,以及推广、协作、治理和技术基础设施,确保Rust语言达到最佳状态。这样,你们这些用户可以尽可能高效且愉快地使用它。
我相信我不需要向大家强调Rust编程语言的优点,但还是想简单总结一下:Rust真的非常快,且是一种内存安全、内存高效的语言。它的一大特点是没有运行时和垃圾收集器,并且能提供关键服务的性能。它可以在嵌入式设备上运行,且容易与其他语言集成。Rust还拥有出色的文档、友好的编译器(带有有用的错误消息)、一流的工具、集成的包管理器和构建工具,此外还有类型检查、自动格式化等众多支持功能。我希望你们和我们一样,热爱使用Rust。
我对Rust在中国的采用情况感到非常欣喜。特别让我惊喜的是,许多开发者正在发现这门美妙的语言,并加入我们的国际社区。看到Rust在中国公司中越来越多地被使用,真是令人振奋,比如华为使用的Dance和Bio项目。教育系统也开始关注Rust,为中国学生提供优质的教育材料,编写了专门的Rust教材,这对于开发良好的课程和建立扎实的Rust基础非常重要。
我也很高兴看到中国各地有这么多新的Rust聚会。我知道上海、北京和其他地方已经举行了很多这样的活动,我希望这些聚会能不断壮大。值得注意的是,中国的Rust社区是世界上按国家规模排名第三的Rust社区。在每年的Rust调查中,6.09%的Rust用户来自中国,仅次于美国和德国,用户数量超过了英国和荷兰。这真是太棒了,看到这么多中国开发者有效地使用Rust,真的是好消息。
Rust的全球采用也在迅速增长。在过去的三年中,全球Rust用户数量已经增长到2500万,事实上,这个数字可能已经接近3000万或3500万。Rust在过去六年中一直是开发者最喜爱的语言,这真是令人惊叹。越来越多的开发者开始使用Rust,并逐渐爱上它。去年,Rust还首次被开发者投票选为最想要掌握的语言。这一点非常重要,因为它不仅表明人们热爱Rust,而且公司也迫切希望雇用熟练的Rust开发者。
Rust的另一个伟大之处在于它的内存安全特性,这也是目前开源软件中的关键安全解决方案之一。Rust在供应链安全倡议中发挥着重要作用,因为它避免了像C++等语言中的许多内存问题。Rust基金会的愿景是确保Rust继续增长、保持高效,并且生产力强。我们希望Rust被视为一种普遍安全、可靠、可持续的语言,能够被个体开发者、组织和政府信任。我们要确保Rust由资源充足的团队来维护,并得到充分支持,同时我们希望这个社区是包容且多样的。
我们不仅希望美国和欧洲的开发者使用Rust,我们希望全世界的人都能使用它。正如我之前提到的,Rust的采用正在增长,我们希望这种趋势继续保持。我们希望Rust因为其安全性和内存安全特性,成为首选的编程语言。我们也希望那些从Rust中受益最多的公司,能够成为Rust的长期投资者和利益相关者,加入Rust基金会并帮助我们制定语言的发展方向和策略。
我们在基金会内通过安全倡议投资Rust,以确保Rust生态系统的安全。这包括自动化Rust生态系统的工具和功能,防止像“typo squatting”这样的问题,确保你们的应用程序是安全的,并且可以在全球范围内使用。我们还推动了Rust与C++的互操作性计划,帮助填补Rust和C++之间的差距。我们希望那些拥有大量遗留代码的公司,依然可以使用Rust来提高代码的安全性,即使无法重写所有代码。
另外,我们还启动了一个安全关键联盟,旨在将安全关键行业的公司聚集在一起,确保Rust适合在安全关键领域使用。如果你在安全关键行业工作并希望加入这个联盟,请浏览我们的网站。我们非常期待你加入,并与我们分享你的见解。
我们还在开发Rust的规范,提供基础的回滚机制,使全球的开发者能够使用相同的标准来编写代码。我们有一个社区资助计划,旨在帮助维护者专注于他们热爱的项目。这个资助计划为活动、差旅以及为期六个月到一年的奖学金提供资金,确保个人能够在他们真正热爱并感兴趣的Rust项目领域工作。
我们还在开发官方的Rust在线课程,帮助开发者学习Rust,或学习特定的领域如嵌入式开发等。展望未来,Rust的使用量一直在增长,每年都有数十亿次crate下载。我们也在持续调查新的项目,来支持并发展整个Rust社区。
如果你对Rust基金会如何继续推动Rust的发展有任何想法,请随时与我们联系。我们也正在与全球各地的政府合作,推动Rust和内存安全的相关演讲和倡议。政府在推动安全代码的使用方面有巨大的影响力,我们正与这些政府密切合作,确保他们了解Rust所能提供的好处。我们还希望与更多的中国和亚洲公司合作,了解你们的需求,以及我们如何帮助你们更顺利地采用Rust。
我们期待在2025年与中国企业合作,参与更多的活动。我们非常希望能有机会到中国,亲自见面。所以,我今天的主要信息是:请参与进来。Rust正在快速增长,这是一个令人非常兴奋的语言生态。我们非常希望你能以某种方式加入我们。Rust项目急需更多的维护者,加入我们,参与Rust的各个项目团队,并贡献你的领导力。
请订阅Rust的每周邮件列表,了解全球Rust社区的最新进展,获取有关最新RFC的信息,并找到参与开发的机会。我们非常希望能有更多的中国公司加入Rust基金会,成为我们的成员。我们的成员帮助我们制定策略和投资方向,并影响我们如何开展工作。更多中国公司加入将使亚洲在Rust基金会的工作中拥有更显著的声音,并为我们的治理带来更多的影响力。
非常感谢大家的参与。我希望大家度过一个精彩的活动,也希望明年能亲自见到你们。再次感谢!
2.携手共建繁荣的Rust OS内核软件生态-田洪亮
好的,我会按照您的要求整理这段内容,保持原有内容不遗漏,不总结,而是原原本本地进行整理,使其变得合理通顺。以下是整理后的内容:
- 携手共建繁荣的Rust OS内核软件生态 - 田洪亮
https://www.bilibili.com/video/BV1aDt1eCEHT/
大家好,我是来自蚂蚁集团的田洪亮。非常高兴能够参加Rust China Conf,一起加入到我们这个社区里面,一起扩大我们Rust中文的这个社区生态,一起推广Rust在中国的使用。
大家可能听说过支付宝的一个广告语,叫”因为信任,所以简单”。正是秉持这个理念,我们蚂蚁集团在安全和可信技术方面投入了非常多的资源和人力。这也是为什么我们很重视Rust语言,因为Rust可以从根本上帮我们解决内存安全问题,同时它的语言特性可以让我们把代码、把系统写得更加安全可靠,使得我们可以有一个更加可信的IT世界,一个数字世界。
我们也在积极推广Rust语言在蚂蚁里面的使用。同时,我们也在做一些开源社区的努力,包括待会会介绍的新站社区。这是一个由蚂蚁发起,同时联合很多机构一起发起的开源社区,致力于打造高安全、可信的操作系统和基础设施。主要包括两个项目:一个叫星战内核,还有一个叫星战机密算。今天我非常荣幸有机会能跟大家分享星战内核方面的一些进展。
[演讲设备调试过程省略]
最近有一个热点事件,就是Linux Rust和Linux的maintainer宣布退休了。原因是他在一个Linux开发者会议上讲如何优化Linux的文件系统方面的元数据时,遇到了非常强烈的反对意见。他的十页PPT只讲到五页,讲的时间就用完了。所以后来他说这个太累了,已经放弃了。虽然他在相关领域做了可能好45年,但现在放弃继续往Linux上推广Rust。他最后写道,他仍然坚信Rust是OS、是内核开发的未来。如果Linux不能彻底地Rust化,那么一定会有别的内核去Rust化,更好地把Rust用起来。
这也是为什么我们两年之前开始做星战的时候就有想到,Linux有它的C的代码是非常宝贵的财富,但也是Rust化的一个非常大的阻力。因为那么多的maintainer,那么多现有的代码都是用C写的,Rust只能是这个第二公民(secondary citizen)。所以这也是为什么我们从两年前开始就去做了一个新的内核,叫ArceOS(新站)。我们致力于把它打造成为业界最安全的操作系统。现在已经开源了,在Atheneos这个GitHub组织下。
在座的可能有部分同学是做OS的,所以这个话题会非常契合你。但即使你不是做RustOS的,我觉得这个话题也会让你有一些收获。大家都在去”rewrite everything in Rust”,那你想想你的目标系统用Rust写的时候,它跟C到底有什么本质区别,到底有没有真正可以用Rust语言去带来非常多的额外好处,你有没有去从头重新思考(rethink)你的目标系统该怎么构建。
除此之外,大家都会面临在Rust的系统里面如何少用unsafe,以及我们下面会介绍Rust的内存模型会有什么一些局限,然后我们怎么克服。还有一个非常有趣的话题,叫type-level programming,这是一个比较高级的Rust语言特性,可能很多写了不少Rust代码的同学也没有用过这个叫type-level programming的技巧。以及,大家面向一个领域去推广、让大家去用Rust的时候,如何让你有更好的tooling,更好的工具链,使得Rust开发者可以有更高的生产力。
既然我们的目标是做最安全的操作系统,那安全(secure)首先你要内存安全(memory safe)。如果你连memory safe都没有的话,就谈不上安全。传统来说,你要写一个OS的话,你用比如说C或C++这种不安全的语言,那之后你觉得为了让这个不安全的语言写出来的代码能够内存安全,那么你就要用形式化证明方法。形式化证明方法如果你是用定理证明方法的话,那这个开发成本是很高的,比如说你1万行代码,你可能要写20万行代码才能去验证。所以对于大的代码库来说,是很难验证的。另外一方面,有一些自动化验证方法,它们会对于你的内存的性质或者你的代码的特性有局限,所以对于我们工业界的生产级别的代码来说,你很难去完全靠形式化证明来证明它的内存安全。
所以,我们在Rust这个论坛上,当然要用Rust去写OS。但是,仅仅是用Rust写OS,这件事情并不会让这个OS立马就安全。因为在一个RustOS里面,你有很多原因不得不用unsafe。因为我们这里所说的OS是内核,内核态的话,你需要去跟体系结构、跟CPU、跟设备去做交互。那这很多时候你都需要用到unsafe的东西,去插入一些汇编,去操作CPU寄存器,才能去真正完成这个内核的功能。
所以我们去统计了Rose for Linux、Redleaf、CS3210(这后面两个是顶会的学术系统),它们的unsafe的用量。我们统计了一个指标叫unsafe density,unsafe density就是统计每千行Rust代码里面你的unsafe这个关键词用的量。我们把这些OS的每个crate的unsafe density这个数做了个排序,然后就是说目前现有的这三个RustOS,它们的代码库有31%到71%的这些crate、这些模块都是在用unsafe。所以,unsafe的量用得这么大,那么我们怎么能相信这么一个用了这么多unsafe代码的RustOS内核,它真的是内存安全的?
所以,我们就提出了一个叫frame kernel(框内核)的新的OS架构。这个架构某种意义上它可以认为是要一个内存安全的,或者说是language safe、language OS的一个理想形态。为什么它是理想型呢?就是整个OS它都在内核态,在单一地址空间里面,它完全用一个safe的语言去写,比如说是Rust。这里的特别之处在于什么呢?在于我们强制要求整个OS,它的所有unsafe代码都限制在了蓝色的这个框里面。那这一部分负责什么?它负责把所有最底层的OS的这些不安全的、非常低级的这些代码,把它封装抽象成为高级的安全的抽象。那这些抽象可以供这个框里面的灰色部分使用,那这一部分是完全用safe的Rust去写的代码,来实现OS的绝大多数的功能。
在这个架构里面,这个蓝色部分它是一个代码量很少的一部分,而灰色部分是来实现这个OS的所有主要的功能,包括所有的驱动程序和大部分驱动程序。所以因此我们就可以做到两个非常重要的好处:
一个就是因为我们已经把unsafe限制到了蓝色的这个所谓的特权的OS框架部分,那这一部分它是只有它可以保证整个内核的内存安全性,所以我们只要去验证、形式化证明这个蓝色部分代码。这个代码量是跟微内核差不多的,那就证明这部分的性质就可以。我们可以保证一个非常大的、一个可能10万或者几10万、上百万行的内核,它的内存安全性。
另外一个好处就是,我们Rust有一个口号,叫”fearless concurrency”。我们认为这么一个架构之后,我们可以使得内核开发这个事情变成fearless。因为传统来说内核开发它是软件工程里面一个门槛相对来说比较高的。因为你用C写,或者你用unsafe Rust,你会非常容易导致内核出问题。而内核又很庞大,任何一个地方出了问题,内核就崩了。所以一个新手,或者是一个硬件公司(你熟悉你的硬件,但你不熟悉内核),很容易就一个很小的问题就导致整个内核都出问题。所以传统来说内核开发的门槛是高的,但是我们做了这种划分之后,大部分开发者可以完全用safe的语言去写、用safe Rust去写,那它这个门槛以及开发者的生产力都会提高。
我们比较一下这个所谓的框内核跟传统大家都知道的宏内核(比如说Linux就是宏内核)、微内核(像比如说seL4就是微内核)。框内核跟微内核、宏内核怎么去看呢?框内核的话,它集合了宏内核的性能,因为宏内核的所有代码都是在特权态,它的通信开销最低。而这个框内核它的内存安全的,所谓的这个trusted computing base(TCB,可信计算基),就是决定这个系统安全的那一部分,就是灰色这部分,这部分量跟微内核是相当的。所以说有了这个框内核之后,我们可以做到宏内核的性能和微内核的安全性。这个是Rust语言给我们带来的好处,如果你不用Rust语言去写的话,传统来说你必须要用微内核这种方式,你去用硬件的方法去做隔离,那样就会带来很大的开销。
稍微再更细节点,就是我们如何去根据框内核架构去做这种功能划分的。我们把整个OS的资源跟功能分成了五类:CPU、内存、做这个多任务、系统里面的各种事件,以及设备。我们把这五类不同的重要的资源,根据我们要保证整个内核的内存安全性完全依赖于特权的framework,我们决定到底什么样的资源是应该留在这个特权的framework里面(它需要用unsafe),以及什么样的一些功能可以安全地推到这个完全safe写的、所谓的deprivilege(就是去掉权限的)这种OS服务部分。
比如说,我们作为内核,我们需要操纵CPU寄存器。那什么样的CPU寄存器需要放在我们所谓的特权部分呢?比如说内核态的所有CPU寄存器的操纵,因为如果这部分寄存器如果操纵坏的话,那你的CPU就跑飞了。但是相反,那代表用户态程序的CPU状态的话,如果我们改坏了、我们的safe code等会改坏了,那也没有关系,因为那只会导致应用程序出问题,它不会导致我们内核出问题。
所以我们做这种划分之后,诸如此类这种划分,我们决定比如说内存我们会分成typed和untyped,就是带类型和不带类型的内存,这个后面我再讲。比如说任务的话,任务之间的切换,这个涉及到底层的切换栈、保存恢复CPU状态等等,还是很unsafe、很low level的,所以说切换是我们需要放到特权部分的。但是任务的调度完全可以用safe Rust代码去写,而它也不会影响内存安全性等等。就是诸如这些,稍微举几个例子来做这个划分。
我们实现了一个我们提出这个内核架构的、也是第一个实现这个内核架构的一个具体的内核叫ArceOS。它是业界第一个框内核。它是一个跟Linux兼容的内核,目前实现的大概有170个Linux系统调用(Linux大约有345-350这么左右的调用,我们已经实现了不少了,但是还有差距)。现在有7万行Rust代码,它的TCB大概是这里红色部分。这个红色的叫我们的OSD,这个crate占整个代码库的20%的量。这个红色部分是我们的TCB,它比red leaf跟CS3210的比例降低了很多。我们的代码当然是完全都已经开源的。
所以大家可以看到,我们整体有一个框架和架构,它的核心部分是这个所谓的OSD。我们已经publish到crates.io上了,以方便说星战社区以外的其他的内核开发者,他们也可以去用。这个OSD简单来说,我们希望它成为内核安全开发的一个标准库。当然因为我们不是Rust官方,所以我们只能说是unofficial,但是我希望它能成为这么一个标准,帮大家能够更安全地去开发Rust的内核。
好的,我会按照您的要求整理内容,使其变得合理通顺,同时不遗漏任何内容。以下是整理后的内容:
大家可以看到,我们整体有一个框架和架构,它的核心部分是所谓的OICD。我们已经将它发布到CHRISTYIO上了,方便星占社区以外的其他内核开发者也可以使用。这个OSD,简单来说,我们希望它成为内核安全开发的一个标准库。虽然我们不是RUS官方,所以我们只能说是非官方的,但我希望它能成为一个标准,帮助大家能够更安全地开发Rust内核。
OSD的难点在于我们要实现四个互相制约的设计目标:
- 保证OSD的能力足够强,基于它提供的API和抽象,你可以实现任意复杂的OS功能。
- 确保整个内核的内存完整性完全由OSD保证,也就是我们的TCB能够保证不会出现未定义行为。
- 我们限制了unsafe的使用,但需要确保这不会给整个内核带来非常大的性能影响。我们需要确保基于OSD写出来的OS一样可以非常高效。
- OSD占整个内核的比例要尽可能少。
虽然OSD是给内核开发的,但我相信大家在做各自的系统时,都会遇到如何限制unsafe的问题。内核是一个使用unsafe非常多的场景,所以如果我们可以做到的话,我相信在你的系统里,你一样可以找到合理的抽象,使得绝大多数代码都是safe的,同时保证它的高效。
具体来说,我们发现之前的Rust内核很难避免使用unsafe,因为Rust的内存模型有些局限。这个局限是什么呢?就是safe Rust缺少对我们在内核里面称为externally modifiable memory(外部可变内存)的支持。
我相信在座各位对Rust都有基本了解,所以背景部分只要点一下就好了。在Rust里,我们是用引用来代替指针的。引用的Rust语义是什么意思呢?就是说这个引用所指向的内存地址,只有Rust这边的代码和编译器可以去改它。
但问题是,内核里面有很多特殊的内存,我们称之为externally modifying memory。这些内存你用引用是没法表示的。为什么呢?比如说,我们内核会把一个内存页映射到用户态应用,这就意味着用户的应用程序可以在内核执行期间也一起去改它。
或者比如说所谓的memory mapped IO,就是在系统里面有一些特殊的内存区间,如果你对这些区间进行内存访问,系统总线会把这些IO的内存访问请求都转给设备。从而你可以通过内存访问来操纵设备。这种内存叫memory mapped IO。这一部分的内存实际上是由硬件控制的,不是由内存条控制的,所以这一部分的内容也是可能会在Rust语言之外变化的。
还有比如说DMA(直接内存访问),也是外设可能会直接对内存做操作。所以这些内存实际上跟Rust的引用语义是彻底冲突的。
比如说,在red leaf这个系统里面,如果想去操作英特尔的XGBE网卡驱动的某一个寄存器,它需要用到unsafe的pointer volatile read/write这个API才能去操作。也就是说,他们选择用unsafe来表示如何操作externally modifiable memory。
在cc的工作里面,他们试图用一个叫mapped pages的抽象,使得你可以安全地访问任何一个物理地址。在这段代码里,它把一个叫mea base的物理地址转成了一个叫borrow的map pages的抽象。通过这个东西,你可以去拿到这个T的引用。但这个抽象实际上是unsound的,所谓的unsound就是说这个抽象在某些情况、某些用法时候会有内存的问题。
这里问题是什么呢?就是这个borrow的map pages或者map pages,它的T是可以由你的safe代码去换的。但显然,有些T是不可能从我们称为外部可变的内存里安全地拿出来的。因为你拿出来这个T就是reference T,意味着你可以从一个外部可变的内存拿出来一个Rust认为是不会被改的值,但这显然是一个错误的假设。
所以我想给大家展示一下,在Rust的内核开发时,我们会遇到Rust的安全部分的内存模型实际上有一些局限。这就是为什么我们试图去扩展Rust的内存模型。
我们提出了一种方法,把所有内存分成了typed memory和untyped memory,即带类型和不带类型的内存。Rust语言的safe部分实际上只能安全地管理或操作typed memory。对于untyped memory,这是我们新提出来的,之前是不太好操作的。
所谓typed内存,就是说如果一个内存里的内容是由Rust类型系统管理的,也就是说这块内存里的内容是有确定的类型的,或者Rust类型系统要依赖于这个内存里的内容。举个例子,比如说Rust内核的所有代码数据段,然后堆栈,它们一定都是被Rust的类型系统管理的。然后比如说我们内核里会有页表,如果页表改坏的话,会影响Rust类型系统的正确性,所以我们认为页表也是typed的。
而untyped内存就是跟Rust内存安全没关系的。比如说我们前面说的所有externally modifiable memory,它们内存里的内容,Rust的类型系统其实是管不了的,也不能管,也不能依赖它。
所以为了扩展Rust类型系统,我们在OS这边提供了对于不同类型的untyped memory的额外抽象,使得你可以安全地访问它们。而且这些安全的抽象显然就不能提供引用的方式来访问它。我们认为正确的方式是你应该把untyped的memory当做外部内存来访问。
所以我们这些安全的抽象,它基本上都实现了我们叫VMIO的接口,它都是基于read/write的方式来从untyped memory这边写入或者读回数据。
除此之外,为了让OSD有足够强的表达能力,使得你可以在OSD上面开发各种各样的OS功能,我们提供了各种各样非常基础的、底层的OS开发所需要的资源和能力。比如说如何处理中断,如何进入到用户态,如何操作用户态,还有一些基础的东西,比如说各种锁,还有高性能的并发数据结构。
我们有一个叫SREBOOK的书,里面有一个用100行safe Rust就可以写一个hello world的kernel的例子,以展示OSD的这些API如何让你可以用安全的Rust来开发内核。
另外一个挑战就是,我们对于内核安全是有非常高的要求的。所以除了我们在设计层面要减少TCB以外,我们还非常关心如何向别人说明我们的设计真的没有内存安全问题,以及如何增强我们自己对于我们设计的信心。
所以我们要说明OSD的所谓的soundness。soundness你可以简单理解成为内存安全或者类型安全,但是soundness的含义实际上是超过或者包含内存安全和类型安全的。大家通常说的内存安全,其实意思是说没有所谓的未定义行为(UB)。没有UB的话就是所谓的sound。
我们想去说明这个OSD是sound的,其实是比较困难的。因为第一,Rust语言这边对UB是没有精确定义的。同时,内核开发是非常底层的,非常容易出现底层的问题。同时,我们需要证明OSD上面的任意代码都没有问题。
所以我们的办法就是把所有UB分成两大类:一种是所谓language UB,就是Rust语言这边的UB;另外一种是环境层面带来的UB。
结果就是说,我们整个内核里面有28个crate,这里面只有三个crate用了unsafe。所以只有11%的crate是unsafe的,整个代码库里它占的比例是20%,比之前的工作要小很多。而且因为我们提供这套API可以使得你可以去写各种内核功能,所以随着我们这个内核的逐渐变大,这个TCB的比例还会变得更小。
所以OSD就是我们如何去限制unsafe,如何能够以非常小的TCB就可以表达非常复杂的功能。这是我们追求的一点。
另外一个我觉得很好玩的点,就是如何更好地把Rust类型系统用起来,使得你可以保证更多的性质。我们在开发过程中做了一个我觉得可以复用的东西,叫type flag。这个type flag跟可能大家用过的beat flag的crate功能很像,但是它是在type level。
我举一个例子。刚刚我们说到在做安全的内核开发的时候,需要去处理untyped memory,或者说外部可改变的内存。为了方便地去访问那些外部的内存,我们提出了一个抽象叫c pointer。这个c pointer简单来说就是它可以表示指向某一个untyped memory。
比如说这里举的例子,这个common config它是一个c pointer,它指向了一个叫IOMEM(就是MMIO)的区域的一个安全的指针。这个指针指向的类型是called vert l o p c i come common config这么一个类型。有了这个c pointer之后,我们就可以方便地安全访问这个untyped memory。
这个c pointer一共有三个泛型参数:T和M是你指向的那个数据类型,M是你这个untyped memory的类型。R是用来表示这个指针的权限的。指针除了说它的范围容易误用以外,还有一个容易误用的点就是这个指针到底是不是可以用来读,是不是可以用来写,然后是不是这个指针可以安全地交给别人去用。
所以在我们这个c pointer的实现里面,你看就是我们有些特殊语法。下面的这个c pointer,它有一个read和write两个方法。这里有一个看着很神奇的attribute,叫require。这个表面上的意思就是,如果一个c pointer,它的这个泛型参数R(R是一个我们叫type level的traits)如果R这个权限里面大于read,也就是R相当于是表示权限的类型,R它包括read的这个权限,那么这个c pointer就具有read的方法。
如果说下面那个require R大于write,就相当于说如果R这个表示权限的泛型参数具备write权限的话,那么这个类型才会带write方法。
通过这种方式,还有比如下面一个,如果是require duplicate,DUP就是是不是你可以去复制,可以类似于clone。是不是可以去复制这个c pointer。这个也是,也就是说如果你c pointer的这个权限里面带这个DUP权限的话,那么你才可以去复制。
所以实际上这个pattern在我们的代码库里面,除了指针,我们对于比如说文件,它可以用什么权限,也都是用type level的办法去把权限编码进去。
这件事情的实现实际上是一个蛮好玩的东西。我们底下是用了一个我们做的一套新的抽象,或者是API叫type flag。我们以后应该会发布到crates.io上。
那么什么叫type level flag呢?就是我们通常来说,我们所谓的编程是我们对值做编程,我们对两个值加减对吧。然后我们的type表示的是这个值的可能取值。但是所谓type level programming就是你的编程的时候,对象不是值,而是类型。就是你可以在类型之间做,比如说加法,比如说与或非等各种操作。
所以我们完全可以就是在type level实现这套flag。这个好处就在于说,你在type level实现flag之后,你可以直接在编译期就可以确保,比如说这个flag是不是满足什么样的要求,从而你完全没有任何运行时的开销。
比如说上面的beat flag,这个权限有read、write、duplicate三个权限,本来是你需要用三个值,三个beat来表示的。那用你用type flag这个宏之后,你可以直接用在类型层面上去定义一个三个类型叫read、write、dup。它们之间的逻辑组合就可以表示各种各样的权限。
继续类比,如何去造出来这个权限呢?如果是用value的话,你可以调用普通的方法对吧,你可以调一下构造函数之类的。如果是type level的话,你可以调我们这个t rise宏来去造出来这个具体类型。比如说t rise叹号方括号就是一个空的权限。然后如果说你t rise这个宏里面只写个read的话,那就
我已经按照您的要求整理了内容,使其变得更加合理通顺。以下是整理后的内容,我尽量保留了原文的所有信息:
本来你需要用三个值,三个bit来表示权限。但是使用type flag这个宏之后,你可以直接在类型层面上定义三个类型,叫read、write、execute。它们之间的逻辑组合就可以表示各种各样的权限。
继续类比,如何去创造这个权限呢?如果是用value的话,你可以像普通的方法那样调用构造函数之类的。如果是type level的话,你可以调用我们的TypeFlags宏来创造出具体类型。比如说TypeFlags![]就是一个空的权限。然后如果说你TypeFlags这个宏,然后里面只写个Read的话,那就是一个只表示具备read权限的Right。
包括你可以去判断,如果是那个value表示的flag的话,那你可以去判断两个value之间是不是有包含关系。那两个类型之间,两个用来表示flag的类型,也可以去判断它们之间的包含关系或者等等关系,从而你可以在编译的时候就知道这种关系。包括了那个就是一个用type表示的flag,你可以去把它转成value表示的。所以你也可以做运行时检查。
有了这套API,你就可以做各种各样的事情。你可以把各种各样的permission、access right编码成为一些type level的flag,从而在静态编译的时候就可以查出各种各样的问题,而且不要任何的开销。
最后一部分是想讲一下,我们如何能够去提升Rust的内核开发者的生产力。因为大家面向各个领域的Rust开发时,你可能都有一些特殊的需求。那如何使得Rust开发更加顺畅呢?
传统来说,大家都非常熟悉的流程是,如果你开发Rust应用的话,你用cargo new一下,然后cargo run一下,这个应用程序就跑起来了。但是内核开发会非常麻烦,就是大家都知道,如果你想把一个内核的第一行代码跑起来,你可能就需要好几千行代码,可能需要几周,或者一个月时间(如果你不熟的话)。所以Rust的内核开发实际上还是有不少门槛的。这个工具链cargo实际上你是不太好直接用的。
所以我们做了一个叫cargo-osk的工具,这个cargo-osk也publish到crates.io上了。你install之后,你可以得到一个cargo的额外参数,叫cargo osk。比如你可以new出来一个新的内核项目,然后你打cargo osk run,这个内核项目就可以直接运行。我们会帮你编译好,然后跟OS链接到一起,然后起一个虚拟机,帮你把所有流程都cover。这样你只用三行命令,你就可以直接就开始你想做的内核开发了,可以大大降低内核开发的门槛。
包括了传统来说,在内核里面做单元测试也是一个很麻烦的事情。所以呢,像你做应用程序开发的话,你就是cargo test就搞定了。那我们有osk之后,你cargo osk test,你就可以直接就做你的内核的单元测试。
我们这个星璇内核就是基于这个osk开发的,使得我们社区的开发者的生产力、幸福水平大大提升。这个cargo osk的工具当然也不只是可以给星璇内核使用,我们也非常欢迎其他的Rust OS开发者去用这个osk来开发你心目中的那个内核。
为什么我们要去做这个osk呢?其实我们发现一个很大的痛点,就是做OS开发或者是做Rust嵌入式开发时,你的很大一个痛点是你很难去重用别人项目的crate。就是我们普通的应用程序开发,大家都会基于一个Rust标准库std。但是在OS和嵌入式场景里的话,我们大家的公共基础是那个no_std环境,就只有core和alloc两个crate可以用。所以不同的Rust OS之间会有很多重复造轮子的问题。
所以我们去做osk和osd,其中一个目的也就是说,以后大家的OS可以都用这个osk和osd去开发,这样大家可以共享很多东西,从而有一个更好更丰富的Rust OS生态。
好,那感谢大家。这个是我的演讲,谢谢大家。
3.用Rust构建高性能的生成式AI应用-王宇博
感谢大家的介绍,下面我想花一些时间,和大家分享一下通过Rust构建高性能的生成式AI应用。我现在在亚马逊云科技,负责大中华区开发者关系的相关业务,希望我们能通过更多的内容、平台和社区,和Rust开发者一起共同成长。
在我开始介绍之前,我想先做一个小调查。我想问一下在座的各位Rust开发者,有没有已经在使用Rust进行AI应用开发的?如果有的话,请举手让我看一下。嗯,我看到还是有一些的。
第二个问题,我想问问大家,有没有使用一些生成式AI的工具,比如Copilot,或者亚马逊的一些工具,来帮助大家进行代码开发?哦,这个好像更多一些。好,谢谢大家的参与。
今天,我就想围绕生成式AI应用的开发,给大家介绍一下如何通过Rust帮助开发者进行更加高效的开发,以及我们如何使用Rust开发生成式AI应用。
在开始正式介绍之前,我想引用英国著名的科幻作家亚瑟·克拉克的一个定律:“任何足够先进的技术,初看都与魔法无异。”这句话用在生成式AI领域其实非常合适。大家可以回想一下两年多前,在2022年时,市场上讨论的主流热点话题是什么?当时我们谈论得更多的是元宇宙,讨论如何通过一系列技术设施,包括AR/VR设备,来帮助大家创建虚拟现实或增强现实的环境。
但是,从2022年下半年,尤其是在ChatGPT出来之后,整个技术市场发生了非常显著的变化。原本AI的热潮已渐入尾声,但ChatGPT的出现把它拉了回来。从去年开始,生成式AI在开发者中获得了越来越多的关注,也影响了越来越多的企业将生成式AI应用于其业务场景中。
当然,生成式AI被行业和开发者接受是有一个过程的。当时,大家只是觉得它很有趣,可以与之对话、聊天,甚至用Stable Diffusion生成一些图像。后来,我们看到生成视频的工具也逐渐出现。渐渐地,大家发现生成式AI确实能够提升开发者的生产效率,也能帮助行业应用做得更快、更好。
简单总结一下生成式AI的发展趋势:从去年开始,大家对生成式AI的理解还处于懵懂阶段,讨论的话题多是“什么是生成式AI”。但我相信大家现在已经非常了解了。通过一系列的算法、模型和数据,我们可以基于多模态大模型生成全新的内容。
与此同时,我们也开始探讨个人职业的发展。在生成式AI的领域,作为开发者,我们如何抓住这波浪潮?有一些工作可能会被替代,但也有一些新的职位,比如提示词工程师,可能会越来越受到市场的青睐。我们如何选择不同的大模型,帮助行业应用落地?这些是我们需要思考的问题。
去年,更多的开发者和企业还在研究和探索生成式AI,而到了今年,形势发生了变化。越来越多的企业和开发者将生成式AI应用到实际场景中。比如,现在的聊天机器人对上下文的理解和用户输入的语义把握越来越准确,也能更真实地回应用户需求。金融、制造、教育等行业也在探索适合其应用场景的模型。
在构建大模型的过程中,我们如何在不同大模型之间进行权衡?市面上有很多大模型,包括国际上私有的和开源的模型,国内的大模型也是百花齐放、百家争鸣。我们如何选择一个合适的模型,在满足应用需求的基础上提升性能和准确率,同时降低成本?这是生成式AI落地过程中,越来越多企业和开发者需要考虑的问题。
还有很多开发者和企业在思考如何在构建生成式AI时控制风险,确保应用的安全性。我相信Rust开发者在这方面会有更多心得和体会。
在不同阶段,大家对生成式AI落地的方式和思维也发生了很多变化。这张图是Gartner的总结,它呼应了我刚才提到的观点:生成式AI从一个“魔法”变成了最具颠覆性的创新,影响了80%的职业。我们提到过,很多开发者在思考生成式AI时代下的职业发展路径。生成式AI如何加速个人成长、职业发展和个人成功?同时,越来越多的新兴职业也在涌现。
这不仅仅是对开发者群体的影响,对于整个社会的影响也是深远的。这组引用来自麦肯锡2023年6月的调研报告,报告指出生成式AI的主要落地场景包括客户运营、市场营销和销售、软件工程和研发领域。而在这四大领域中,有两个是集中在开发者群体的。所以,生成式AI将对开发者产生非常显著的影响。
开发者是生成式AI开发的核心生产力。AI能否取代开发者?每个人可能都有不同的想法。但从开发者体验的角度来看,开发者是生成式AI流程中的关键环节。
生成式AI可以加速开发者的开发体验,优化工具链。比如,智能开发助手可以帮助开发者节省精力,将更多精力集中在架构设计等其他领域。生成式AI还可以提升生产力,改善代码的可维护性,增加代码注释,提升代码的可读性。它还可以简化工作流程,帮助开发者持续改进和创新。
生成式AI与开发者是密不可分的,二者的有机融合能够推动应用的发展。在开发者体验上,生成式AI可以提升开发速度和开发者的幸福感。通过更好的工具,减轻开发负担,解放繁琐的工作,开发者的满意度和幸福感都会有所提升。
此外,生成式AI还可以提升开发速度。结合云计算平台,开发者可以更快地进行编码和调试,提升代码质量和可维护性。对于Rust开发者来说,应用的安全性也是一个非常重要的关注点。尤其是内存安全漏洞,这是开发者非常关注的一个点。
通过生成式AI工具,开发者还可以更快熟悉现有代码,缩短学习曲线。生成式AI可以提供更定制化的学习平台,帮助开发者更好地上手现有代码库。
最后,生成式AI还可以帮助开发者解决技术债。举个例子,虽然跟Rust无关,是Java相关的案例:亚马逊有大量基于Java 8的历史代码,通过我们的工具将其快速升级到Java 17,性能和效果提升显著。我相信随着技术的发展,类似的工具也可以帮助开发者将C或C++代码自动转换为Rust代码,减少技术债。
为了缩短开发者的入门时间,另一点是解决技术债务。这里我想举一个例子,虽然不一定与Rust相关,但这是一个与Java相关的案例。在亚马逊,我们有很多历史遗留的代码,早期很多代码是基于Java 8构建的。通过我们自己的工具——MSONQ,我们成功地将这些基于Java 8的代码快速升级到了Java 17,极大提升了速度、性能和效果。
我相信,随着技术的不断发展,我们甚至可以将C或C++的代码,通过类似的工具自动生成Rust代码。这对于开发者来说是一个理想的场景,因为它能够帮助我们节省更多时间,用于识别代码库中的技术债务。当然,这只是一个简单的例子。
接下来,我们来看一下生成式AI如何帮助开发者提升体验。我相信大家对此也有自己的看法和实践。这里引用了麦肯锡的一份关于开发者领域的报告,希望通过这份报告,展示生成式AI如何提升开发者的满意度。借助生成式AI,我们可以看到开发者的幸福感、满意度,以及对整体工作状态的满意度都得到了显著提升。
与传统的人力劳动相比,生成式AI的加持能够显著提高工作效率和质量。根据Gartner的调研报告,生成式AI能够将开发者的生产力提升约30%。我引用这些报告的例子,主要是为了说明全球范围内生成式AI的浪潮对开发者的影响和冲击。我也希望开发者们能够借助这波生成式AI的东风,进一步提升自身能力。
关于生成式AI如何融入生产环境,我们从亚马逊云科技的角度抽象出了三个维度,以帮助开发者更好地进行开发。每个开发者的技术水平和所在企业的行业差异较大,生成式AI的落地场景也不尽相同。因此,我们为不同的开发者和场景提供了相应的解决方案。
第一个维度是快速便捷的API调用方式。我们提供了一整套的工具和服务,既包括亚马逊云科技的,也涵盖其他云厂商和创业公司的工具。这些工具能够帮助大家实现各种应用,例如我们有M3Q,其他公司如微软、Google,甚至OpenAI和最新发布的Cursor工具也为开发者提供了强大的支持,帮助实现更自动化、智能化的开发。
第二个维度是模型构建和集成。许多Rust开发者可能专注于数据和算法领域,可能希望构建自己的大模型,或是为企业构建基础模型。在这种情况下,我们需要考虑模型的构建、应用集成、数据架构、安全部署等问题。生成式AI只是整体技术架构中的一部分,企业还需要结合具体的应用场景来进行完整的技术架构设计。
第三个维度是针对那些既是Rust开发者又是数据科学家的用户(尽管这类用户并不多)。我们为这类开发者提供了丰富的工具和能力,帮助他们更好地训练、部署和调优模型。
生成式AI可以参与开发流程的各个阶段,例如在前期的计划和设计过程中,我们可以将业务目标分解为提示词,输入生成式AI工具,从而帮助优化设计目标和技术需求。接下来是代码开发、审查、监控和测试,生成式AI在这些环节都能发挥重要作用,包括自动生成代码、进行内存安全检查、扫描程序错误和合规性等。
有时生成式AI生成的代码可能并不容易理解,这时工具会提供相应的文档和代码示例,帮助开发者更好地设计应用。因此,生成式AI贯穿了整个开发流程,帮助广义上的开发者群体,包括程序员、架构师、产品经理和DevOps等角色,充分利用生成式AI带来的好处。
随着生成式AI的崛起,安全功能越来越多地嵌入到开发流程中,推行所谓的“安全左移”。这一理念也可以很好地集成到当前的开发环境中。
接下来,我将介绍Rust在机器学习开发中的一些特点。这与Rust本身的特性密切相关,因为Rust是一门高性能的编程语言。近年来的调查显示,Rust的性能仅次于C。亚马逊云科技的许多服务,例如EC2、S3、CloudFront和Route 53,都是用Rust开发的,以提升整体性能。
安全性方面,Rust在内存安全和防泄漏机制上表现优异,同时具有更好的控制性、灵活性和跨平台支持能力。当然,在机器学习领域,Python仍然占据主导地位,许多库和包都是基于Python编写的。不过,Rust的机器学习生态系统也在不断发展,越来越多的库和工具正在兴起,帮助Rust开发者更好地进行机器学习开发。
在传统机器学习方面,有很多库和包可以帮助Rust开发者实现传统的机器学习任务。尽管如今大家谈论更多的是大模型和海量参数,但许多应用场景中,传统的机器学习方法仍能取得非常好的效果,所需数据量较少,模型训练也更简单。例如,分类、聚类和模型评估等传统方法在很多场景下依然非常有效。
以SmartCore为例,这是一个基于Rust的机器学习库,支持传统的监督学习和非监督学习方法,如线性模型、随机森林、贝叶斯模型、K-Means聚类和PCA等。
在深度学习领域,Rust也有许多库和包。例如,Hugging Face的Tch-rs是一个基于Rust的深度学习库,能够帮助开发者快速使用模型构建应用。Hugging Face本身也在使用Rust开发其机器学习库和模型。
大模型同样是当前的热门话题。Rust也有一些库可以帮助开发者进行大模型的构建,如LLaMA、Rust-BERT等。此外,Stable Diffusion的图像生成也可以通过Rust的库来实现,例如Diffusers-rs,它是基于Torch和Rust构建的图像生成库。
尽管Python在机器学习领域占据主导地位,但Rust也有自己的优势。如何兼顾Python的生态系统和Rust的性能优势呢?这里我们有一个开源项目叫PyO3,它能够将Rust和Python紧密集成,帮助开发者在两者之间进行互相调用,从而构建更优化的机器学习应用。
接下来,我们谈一下生成式AI工具如何助力Rust开发。其实,很多开发者已经开始使用不同的工具来帮助Rust开发。例如,亚马逊的MSONQ开发者工具可以帮助生成Rust代码。我们有一个示例,它通过MSONQ生成了一个Rust程序,列出了所有的S3存储桶的名称。这是一个简单的演示,展示了如何通过生成式AI工具来帮助Rust开发者快速构建代码。
MSONQ功能非常全面,能够帮助开发者生成代码、添加注释、进行代码审查和转换等。我们还有一些benchmark测试,显示MSONQ在多个测试中表现出色,性能领先于其他产品。
而且 Amazon Q 的 Q Developer 不需要注册亚马逊云科技的账号,只需要通过一个 Build ID。这个 ID 甚至不需要绑定信用卡,就可以体验。我们的 M4Q 服务非常简单和便捷,可以在大家都非常熟悉的 VS Code 以及其他的开发工具,比如 JetBrains 等等上使用。我们的 M4Q 是一个非常好的云端智能代码编写工具。通过生成式 AI 工具,我们可以帮助 Rust 开发者快速构建应用。当然,我知道大家有很多其他的工具可以选择,这个领域确实有非常多的选择。大家不妨多体验,看看哪个工具更适合自己。
最后,我想再次分享一下 Rust 的开发。刚才我也提到,亚马逊云科技有很多应用和服务都是基于 Rust 开发的。我们希望能够把这些经验分享出来,帮助大家更好地进行 Rust 开发。大家都知道,开发一个应用,尤其是开发一个机器学习应用,不仅仅是开发一个模型就结束了,它是一个非常庞大的体系和过程。在这个过程中,我们积累了很多经验,可以分享出来,帮助大家快速构建云端应用。
首先,我想介绍一下我们的 SDK。自 2021 年发布以来,经过了很多次迭代,越来越多的开发者利用我们的 Rust SDK 进行开发。它帮助开发者构建 Rust 应用所需的底层资源,包括计算、存储、网络资源、数据平台,以及上层前端的网络负载、流量、网关等。
接下来,我想演示一下我们的 MSONQ。比如说,我是一个有经验的 Rust 开发者,想在云平台上进行更多开发。可以看到,这里有一个演示,就是我们在控制台中集成的 MSONQ。我可以提问,比如 “如何在云上构建一个 Rust 应用?” 它会告诉我,构建 Rust 应用需要分几个步骤,包括开发环境的配置、服务的选择、如何构建 Rust 相关的代码环境、如何编写代码,还有一些代码示例。它还会指导如何进行测试、部署,并解释应该部署在哪些服务上,比如是否部署在虚拟机上,还是无服务器架构上。最后,它还会提供一些链接,供大家进一步参考和学习。这就是我们基于云平台,构建 Rust 应用的一种方式。
当然,展开来说,这个话题可以讲很多内容。由于时间关系,今天我们就不深入讨论。如果大家有需要,可以进一步了解。云计算和生成式 AI 在某种程度上是类似的。云计算从十多年前开始,逐渐改变了开发者、企业和行业的构建方式。而生成式 AI 则是最近几年兴起的技术,可以进一步帮助开发者更好地进行构建。
如果大家对亚马逊云科技的服务有更多兴趣,可以到我们的展台,与我们的技术专家交流,探讨如何通过生成式 AI 来帮助 Rust 开发者更好地开发应用。
最后,我想做一个总结。生成式 AI 是当前非常热门的话题,作为开发者,我们应该如何应对呢?首先,我相信学习是最重要的。在软件开发中,我们提倡持续迭代、持续部署。对于开发者来说,持续学习同样重要。通过不断探索和尝试,才能在这个过程中脱颖而出。
其次,选择合适的工具也至关重要。我建议大家根据自身的需求、行业特点和具体的业务场景,选择最合适的工具进行开发,这样才能事半功倍。
最后,我希望能听到开发者对我们产品和服务的反馈,帮助我们更好地迭代产品,为全球更多的开发者提供优质服务。我希望今天的介绍对大家有所帮助。我的演讲到此结束,谢谢大家!
!!!
4.Rust程序的不同链接方式在交易系统中的典型应用-乔丹
大家好,我是非凸科技的乔丹,今天要讲的内容和前面两位讲者的风格完全不一样。我今天要讲的是 Rust 程序在交易系统中不同链接方式的典型应用。
首先,解释一下为什么我们要讲这么具体的一个题目。前面两位,比如蚂蚁和 Amazon,他们都是行业中的巨头,而我们虽然发展很快,在行业内也算成长得不错,但在整个 Rust 社区里,还是算比较初创的团队。我们面临的问题和他们完全不一样。我相信在 Rust 的开发者社区中,像我们这样,或者比我们更小的团队,面临的问题和解决方法,和蚂蚁、Amazon 这些大公司是截然不同的。
Rust 社区的工具链非常好,比如 Cargo,帮我们封装了很多底层问题,这些问题在用 C++ 或者传统语言时必须自己处理。大型公司可能有专门的效率团队或基础设施团队来解决这些问题,但像我们这样的小团队,就需要自己一点一点搞清楚和优化。所以今天的分享希望能对类似我们,或者比我们更早期的团队有所帮助。
首先,给大家一个前情提要。大概在去年的 2023 年 Rust China CP 大会上,我们在一个分论坛上分享了非凸科技如何使用 Rust 来做投研系统的全站开发。当时介绍了很多内容,我今天拿出其中的一页来说明。在一个量化交易的投研团队中,在 Rust 之前,我们的配置大概是这样的:研究员(比如 ALICE)一般会使用 Python 编写代码,表达如何从历史交易数据中找到最关心的特征,以及当某些情况发生时,如何进行交易来盈利。而开发团队(比如 BOB)则会在 ALICE 准备好代码后,使用 C++ 将这些逻辑翻译成低延迟、稳定运行的在线程序,用于实盘交易。
在非凸科技,我们去年给大家介绍了如何让 ALICE 和 BOB 真的坐到一起,而不是各自使用不同的语言。我们的方法是让分析师也写 Rust,开发工程师也从 C++ 转到 Rust,这样大家就可以写同一份完美的 Rust 策略代码。
不过,随着业务的发展,策略部分和交易框架部分不可避免地需要由不同的团队来维护。接下来,我想给大家介绍一下行业背景。交易框架(Trading Facade)究竟是什么?所谓的策略代码(Perfect.rs)就是决定何时下单、何时撤单,而交易框架则类似于互联网应用的应用框架,负责处理底层的请求、数据等。策略和交易框架部分需要不同的团队来维护,它们有各自的风格和权限控制范围。
从我们需要分开团队来维护同一份 Rust 代码的起点开始,我们做的第一件事就是将原来的项目分解成两个 Crate,这两个 Crate 通过 Workspace 的形式仍然放在同一个代码仓库中。这是我们早期的状态,这两个 Crate 分别叫 strategy 和 facade,它们有相同的权限范围,拉取的分支和 Commit Log 也是混在一起的。虽然我们尝试用 Rust 工具链提供的工具将这两个模块分开维护,但并不理想。
在 Rust 中,Crate 有多种类型。比如最简单的 bin 类型,一般用于生成可执行文件;lib 是静态库;cdylib 则是用于动态库导出 C API。我们最初的方案是将整个项目拆分成两个代码仓库,比如在策略模块的代码仓库里,只有一个文件 lib.rs,里面有三个函数:一个叫 team_one_top_secret,这是策略团队的最高机密,不希望外界知道其实现细节;另外两个函数 update_feature 和 start_strategy 则是策略团队和框架团队约定的接口。
在早期状态中,facade 项目通过依赖 strategy 项目的 Git 地址和 Tag 来实现连接。这种方式的问题在于,代码是公开的。如果要编译,Cargo 会将 strategy 的代码下载下来,使用 facade 项目指定的工具链版本一起编译并静态链接成一个二进制文件。这意味着 strategy 的机密代码会被暴露给 facade 团队。
于是,我们进行了优化,使用了 cdylib 的形式来分发策略逻辑。这样我们可以只分发动态库,而不公开源代码。cdylib 是 Rust 原生支持的,虽然我们写的是 Rust,但通过 C ABI 分发时,Rust 的语言特性就无法使用了,比如泛型、Rust 的标准库类型等。这种情况下,我们不得不将函数的返回值简化为基础类型,如 i32,虽然不太灵活,但仍可以工作。
不过,使用动态库的形式会带来一些性能损失。为此,我们转向了 Rust 原生支持的 rlib 静态库形式。rlib 是 Rust 的静态库类型,除了机器码之外,还包含 Rust 编译器需要的元数据。这样我们就可以在不公开源代码的前提下,通过 rlib 完成静态链接。
在这种方式下,strategy 项目中的代码保持不变,而 facade 项目也可以继续使用 Rust 的标准库特性,调用方式保持原样。整个过程是静态链接,性能没有损失,同时也没有 FFI(外部函数接口)的开销,一切都是安全的 Rust 代码。
不过,这种方式也有问题。Rust 的 API 并不稳定,不同版本的编译器生成的 rlib 可能无法相互兼容。比如,一个 struct 在一个版本下的内存布局可能是 100 字节,而在另一个版本下可能变成了 108 字节。这种情况下,如果两个项目使用了不同版本的编译器,可能会导致运行时出现不可预料的错误。
为了解决这个问题,我们可以通过公司内部规定,要求所有团队使用相同版本的编译器。但这带来了额外的维护成本,每次发布新版本时,需要为所有可能的工具链版本编译 rlib,并分发给其他团队。
最后,关于动态库的性能损耗问题,我做了一些测试。在我们的具体场景下,动态库的性能比静态库慢 5%。虽然这个差异不大,但在追求极致性能的场景中,静态库仍然是更好的选择。
总结一下,rlib 的方案是我们目前的最佳实践,特别适合我们这样的小团队。对于大公司来说,可能没有必要使用这种方案,因为他们有完整的编译集群和权限控制。对于我们这样的初创团队,这可能是一个不错的选择。当然,这种方案也有局限性。
谢谢大家!
!!!
5.字节跳动在Rust服务端方向的实践与思考-吴迪
大家好,今天非常荣幸能够站在这里为大家分享字节跳动在Rust服务端方向的一些实践和思考,也希望能够为大家带来一些收获。
自我介绍
我目前是字节跳动服务框架Rust方向的负责人,主要负责公司内部服务端Rust生态的建设以及业务的推广与落地。今天的分享主要分为三个部分:
- 我们是如何看待Rust这门技术的,以及为什么选择它。
- 我们在Rust的落地成果及实践中的一些经验。
- 对未来技术演进趋势的思考,以及为什么Rust符合我们的技术发展趋势。
最后会有一个Q&A环节,大家可以提出问题。
为什么选择Rust?
我们选择Rust的原因要从团队目标说起。我们的团队目标是承担公司内部的降本增效工作。这是我们最重要的目标,大家应该也能理解。此外,我们也希望做出一些独特、有意义的事情,承担引领公司技术发展的一部分责任,并希望通过技术上的变革带来业务上的创新。今天将主要围绕降本增效这个话题,具体来说就是我们经常听到的“微服务性能优化”。
微服务性能优化是一个范围极大的话题,涉及到多种技术的共同优化。对于Rust来说,优化的重点在于语言迁移,即如何对单体服务及计算逻辑进行性能优化。我们之前对外有过一些分享,感兴趣的朋友可以在会后交流,PPT也会发到大家手中。
在我们做技术演进或语言优化时,不管是内部还是外部,大家经常会问我们:
- 为什么选择Rust?
- 为什么不选C++或者其他新兴语言,比如Zig、Carbon,甚至Vlang?
我们当时做了一些对比。字节内部使用Go语言,Go的学习成本相对较低,但随着我们规模的扩大,Go的性能和稳定性问题逐渐显现,尤其是因为Go有垃圾回收(GC)和运行时(runtime),这导致了稳定性上的抖动。
接下来谈谈C++和Rust。两者的学习难度都比较高,性能和稳定性方面不再赘述,都是很强的。但在安全性和协作性上存在巨大差异。C++的内存安全问题大家应该都很熟悉,像链表这样的基础数据结构,在C++中想要写一个完全没有崩溃风险的实现是非常困难的。而在Rust中,由于其所有权和借用检查机制,这些问题几乎不会存在。
此外,协作性是另一个关键点,尤其是在大规模的软件项目中。C++虽然有一些现代的包管理工具,但并不统一,不同团队可能使用不同的工具链,如Bazel、CMake等。这就导致了我们在改动或引用C++项目时,往往直接复制源代码,而没有统一的包管理或版本管理。这也使得C++团队之间的协作变得非常困难。
相比之下,Rust的生态更加统一和安全。我们在代码评审时,更多关注的是业务逻辑,而不需要担心空指针、崩溃或并发安全问题。这样极大地减轻了代码评审的负担,也提高了工程效率。因此,虽然Rust和C++的学习成本相近,但Rust的使用成本更低,尤其是在协作性和安全性上。
最终,我们选择了Rust。根据我们的实践,将Go服务迁移到Rust后,性能提升了一倍以上,保守估计可以降低三分之一的资源成本。字节内部Go服务的资源消耗是非常巨大的,因此这些收益是非常可观的。
落地成果及实践经验
目前,Rust在字节内部的落地情况是:线上有400多个服务,使用的CPU数量达到400多万,Pod数达到100多万。这些数据已经是经过优化后的结果。
这里分享一些直观的图表。比如,某一个服务从Go迁移到Rust后,CPU利用率显著降低,服务的延迟和可用性也得到了明显提升。这样的结果增强了我们对Rust的信心。
还有一个非常有意思的案例。当时我们在直播业务中有一个容灾服务,旨在当线上服务出问题时,流量会切换到容灾服务。我们同时部署了Go和Rust两个版本的容灾服务。有一天,线上推荐系统故障,流量被切到容灾服务。结果Go版本的容灾服务可用性降到了52%,基本等于不可用。而Rust版本的服务依然保持了四个9的SLA。这是一个非常直观的内部案例,展示了Rust在关键场景下的稳定性和优越性。
实践经验总结
在冷启动阶段,我们总结了几点:
- 天时地利人和:选择了正确的技术方向,并在合适的时机引入Rust。如果我们早在2015年Rust刚推出1.0版本时就引入,可能很难推行,因为当时Rust的成熟度和业界的发展趋势还不适合。而现在,Rust已经成为了一个上限非常高的技术方向。
- 长期趋势:我们并不只是关注Rust当前的应用量或具体的性能提升。我们更多的是看重Rust作为未来技术发展方向的潜力。从软件工程到性能优化,Rust都符合我们的需求。
- 抗压和找活能力:在冷启动阶段,我们遇到过没有业务支持的困难,需要自己去“找活干”。这段时间非常痛苦,但坚持下来就能看到成果。
此外,团队的支持也是至关重要的。我的领导曾经对我说:“既然选择了这个方向,我们就要轰轰烈烈地干一场。不管成败,至少我们努力过。”
OK,那我们现在进入启动阶段。作为一个基础架构团队,我们需要在生态系统上进行大量的投资和建设。因为如果我们希望Rust语言能够在内部被业务方接受和使用,生态系统的建设是至关重要的。这是业务方真正落地使用Rust的关键点。因此,我们需要做到生态先行,并且敢于进行技术投资。
很多时候,业务方在选择技术时会考虑他们想使用的库是否已经存在。如果存在,他们就能直接使用,而不是等到需要时再让我们开发,因为开发周期可能是以月为单位的。例如,开发一个库可能需要几个月,开发一个框架甚至可能需要半年。而这无法满足业务方的时间需求,因为业务迭代的周期通常以月或季度来计算。
因此,在这个过程中,我们需要进行生态和技术的投资与探索。同时,我也想分享一点——在Rust的学习过程中,大家可能经常听到Rust是一门非常安全的语言。那么这种安全性是什么呢?它主要指的是内存安全,能够防止空指针和并发安全问题。这些是大家在网上常见的说法。但是,这种安全性究竟对软件工程带来了什么意义呢?
安全性对于软件工程中的协作效率提升至关重要。首先,我们可以完全信任他人的代码,无论是我们内部的业务逻辑,还是使用社区的开源库。我们知道Rust是一门安全的语言,不会轻易引发诸如内存泄漏之类难以排查的问题。而在我们使用C++的过程中,升级库版本经常会引发巨大的问题。常常有人质疑库的可靠性,担心升级后会引入新问题,导致我们不得不自证代码的安全性。而在Rust中,这些问题得到了很好的解决,代码审查时只需关注业务逻辑,这大大降低了心智负担,提升了协作效率。
在实际使用中,一些团队提出了一些非常好的想法。例如,他们在所有业务代码中禁用了unsafe和unwrap,并强制要求所有代码必须处理所有异常。这大大提升了线上服务的稳定性,并取得了良好的效果。我们下午的分享中会具体提到这些内容。
在此,我也给大家一些建议。如果你们的产品需要对外交付,建议同样采用这些实践,因为它们确实能够在很大程度上提升代码和服务的稳定性。
不过,有一个可能让大家失望的点是,Rust的生态并没有其他编程语言那么完善。相比之下,Rust仍在发展中。因此,我认为,今天在场的各位都是Rust社区的先行者,我们需要敢于自己去建立一些轮子。Rust的社区库有时并不够完善,无论是在接口的易用性还是性能方面。所以,我们需要敢于fork库,进行修改并贡献回社区。例如,我们自己fork了一些库,如rust-protobuf和snappi,并通过PR的方式提交给社区。虽然有些库维护得不太积极,但我们仍要敢于自己从头构建轮子。
在推广和应用Rust的过程中,我们不能像使用其他语言那样,直接在社区找到现成的库来使用。Rust社区的现状并不是这样。因此,我们需要以目标为导向,敢于自己造轮子。例如,我们曾有人质疑我们为什么要自己开发vol框架。实际上,我们调研了所有的thrift框架,发现没有一个能用,所以我们最终才决定自己开发。再比如,std::string在异步场景下的优化并不多,特别是在避免拷贝和内存分配方面。我们最终自研了一个fast string库,解决了这一问题。如果大家遇到类似问题,可以尝试使用这个库。
另外,我们优先使用stable版本的Rust。我们曾经在使用nightly版本时遇到过一次编译错误,虽然Rust社区很快修复了问题,但当时排查问题非常痛苦。因此,建议大家在没有特殊需求时,尽量使用stable版本。
接下来,我想谈一下我们对未来技术演进趋势的一些思考,以及为什么我们认为Rust是适合未来技术发展的方向。首先,从技术演进趋势来看,我们认为未来的方向是性能和成本的极致优化、开发体验的易用性以及功能的完善。大家可能更关注的是性能成本的优化。我们认为未来的计算资源一定会走向异构化,现在可能大家更多关注的是x86-64平台,但未来可能会出现多种架构的混合,例如x86、ARM64和RISC-V等。而Rust作为一个以LLVM为后端的语言,在异构计算上有着天然的优势,能够很好地应对这种趋势。
第二点,我们认为未来的方向是软硬结合,系统与技术结合。比如,CXL、FPGA、DPU、RDMA等技术,未来都可能会成为性能优化的关键。而Rust作为一门与C语言一样能提供接近裸机控制力的语言,能够很好地应用这些技术。在其他语言中,由于它们有不受控制的运行时和GC,应用这些底层技术会非常困难。而我们认为Rust未来可以作为一种底层计算语言,为Python、Node.js、Java和Go等语言提供计算能力,通过FFI等跨语言调用技术暴露计算能力。
我们预期的Rust全景图可能分为几个层次:Rust基础层、基建层和业务层。我们会通过FFI将基础层和基建层的能力暴露给不同的业务使用。
最后,我简单介绍一下我们未来的规划。我们会提供更好的错误提示和调试体验,更完善的文档和指南;我们会着手开发一些呼声较高的功能,如APC网关和泛化调用;并且我们会继续优化性能,特别是IPC和Protobuf的编解码优化。
总结一下,我们都是技术的先行者,需要关注一些有技术深度的事情,这对个人、团队和公司都有着显著的价值。对个人而言,这是技术的成长和竞争力的提升;对团队而言,能够吸引志同道合的人才,并建立技术壁垒;而对公司而言,则是降本增效和技术革新的体现。我们在实践中看到,很多业务如果没有Rust的高性能,是无法实现的。
最后,我想说,Rust就像是开发3A游戏一样,虽然难度大、周期长,但它有着更高的技术上限和更长远的发展前景。希望大家能够在这条路上互相扶持,共同前行。
这就是我今天的分享内容,非常感谢大家!
!!!
6.调试Rust应用程序的技巧和窍门-Vitaly Bragilevsky
你好,大家好。抱歉,我想在翻译上可能会有一些问题,但我会用英语来进行讲解。对不起,我没有时间学习中文。不幸的是,我只会用英语进行这次演讲。是的,我在JetBrains工作,担任开发者布道师。我还在RustRover项目中工作,今天我将谈论调试Rust应用程序的技巧,这就是这次演讲的主要内容。
讲座结构:
这次讲座分为四个部分:
- 我将从当前的调试经验开始,介绍大多数Rust开发者目前在做的调试工作。
- 然后我会介绍交互式调试,这是一种更好的调试体验。
- 第三部分是关于一些高级调试策略的。
- 最后,我会向大家提供一些建议,帮助你提高调试效率。
当前的调试实践
我们进行了一项调查,名为“开发者生态系统调查”,其中有很多Rust开发者参与。我们问他们通常如何调试Rust代码。结果显示,超过50%的Rust开发者使用println!或debug宏进行调试,少于30%的开发者使用IDE调试,约10%使用终端调试工具。
然而,println!调试有很多问题。首先,它引入了额外的代码,这些代码是纯粹为了调试而存在的,不是项目中的正常代码。其次,println!输出的信息量大,可能包含成千上万行无关信息,需要人工筛选分析。每次如果你需要额外的调试信息,还需要重新编译并运行程序,分析新的输出。这种过程可能要重复数小时甚至数天。
交互式调试
相比之下,交互式调试提供了更好的体验。你可以设置断点,暂停程序,查看变量值,逐步执行代码。这个过程不再需要繁琐的打印语句和重新编译。Rust有两个主要调试工具:gdb和lldb,它们在不同的系统上表现不同。虽然你可以直接在终端中使用这些工具,但这样做很难,因此使用图形用户界面(GUI)工具会更加方便。在RustRover和VS Code中都有相关的调试界面,VS Code的CodeLLDB扩展也能提供类似功能。无论你选择哪个工具,交互式调试都是一种高效的调试方式。
基础调试策略
在RustRover或VS Code中,你可以通过点击“调试”按钮开始调试会话。设置断点后,程序会在断点处暂停,你可以查看变量、调用栈等信息。Rust编译器非常智能,可能会删除一些不必要的变量,即使在调试模式下也是如此。因此,某些变量可能在调试时不可见。
调试中的重要操作包括“Step Over”(跳过函数)和“Step Into”(进入函数),通过这些功能,你可以选择逐步查看代码的执行情况。此外,你还可以进入标准库函数,查看其中的实现细节。
内存布局和高级调试
调试中你可以查看内存布局。在某些情况下,内存中可能存在问题,例如常见的十六进制显示“DEADBEEF”代表内存问题。通过内存视图,你可以看到数组和其他数据结构在内存中的排列,有助于排查低级代码中的内存错误。
此外,你可以在调试过程中修改变量。例如,如果你在调试时发现某个变量b的值是2,但实际上你需要它是100,你可以直接在调试会话中修改这个值,而不需要重新编译或运行程序。调试器允许你修改可变变量的值,并继续执行程序。
你还可以检查线程和调用栈,尤其是在处理多线程应用时,这一点非常重要。通过查看调用栈,你可以了解程序中每个函数的调用顺序,帮助你定位问题。
反汇编视图
如果你需要更深入地了解程序的执行情况,调试器还提供了反汇编视图。通过反汇编,你可以查看程序的汇编代码,帮助你优化性能,尤其是在发现Rust编译器生成的代码不够高效时。
断点的强大功能
断点不仅仅是简单的暂停程序。你可以为断点设置条件,使程序仅在满足特定条件时暂停,或者使用非暂停断点打印某些表达式的值,而不影响程序的正常运行。通过这些功能,你可以在程序快速运行的同时获取调试信息,而不污染代码。
调试时的注意事项
调试的目标是理解程序的行为,尤其是在出现错误时。一个好的做法是将代码隔离,创建一个测试用例,专门调试该测试。调试不仅仅是找到错误,而是通过实验来理解代码的行为。通过断点和变量检查,你可以看到程序运行的每一步。
在长时间调试时,建议记录你的发现。调试超过20分钟时,你可能会忘记之前发现的问题,因此记录下来有助于避免重复工作。
学习调试工具
调试器是一个复杂的工具,虽然println!调试简单,但学习如何使用交互式调试器将极大提高你的工作效率。每次调试代码,你都会变得越来越熟练。
我鼓励大家使用交互式调试,希望未来有更多人使用IDE进行调试,而不是依赖println!。当然,如果你使用RustRover进行调试,我会非常感激。
最后,感谢大家的参与!让我和大家来拍张自拍吧!谢谢大家!
7. 扣子AI平台Rust信息安全实践 - 刘博洋
大家好,我是刘博洋,来自字节跳动Flow AI部门,担任安全架构师。今天我带来的议题是“扣子AI平台的Rust信息安全实践”。很高兴能在这里与大家分享一些经验和心得。
首先,我确认今天没有走错会场(笑),虽然我是安全架构师,但今天分享的是与编程语言相关的实践。这是因为这些年在Rust上的一些实践让我感受到了极大的收获,因此也很荣幸能在这里与大家分享我的心得。
今天的分享分为四个章节:
- 扣子AI平台的介绍
- 我们在Rust上的选择考虑
- 我们的收获
- Rust团队的建设
扣子AI平台介绍
扣子平台是新一代的AI智能体开发平台,允许开发者无论是否具有编程经验,都可以快速地使用低代码方式在平台上开发自己的AI智能体应用。这些应用可以基于大模型开发。大模型的API非常原始,如果你想基于大模型构建更高级的应用,可能需要使用一些框架(如LangChain或LangGraph)并编写大量代码,还需要对Prompt进行优化和评测。而使用扣子平台后,开发者可以以极低的代码量、非常接近自然语言的方式组合功能。
平台提供了类似插件、Prompt、知识库以及各种认证方式,开发者可以快速地将开发好的智能体发布到社交网络、聊天软件,甚至是自己的渠道或API,供第三方使用。
扣子平台与Rust的关系
我们从第一天立项时就意识到,这样的平台安全性极为重要。因此,整个安全体系的实现都是基于Rust开发的。
1. 认证体系
扣子平台主要面向海量AI智能体应用,涵盖企业用户与消费者用户。对于企业用户,平台支持单点登录系统,并与企业的员工身份集成。对于消费者用户,平台支持通过浏览器进行Cookie认证。此外,平台还支持API应用,如API Key、Personal Access Token,开发者可以通过这些方式快速开发和调试API,同时支持OAuth应用。
例如,开发者可以将智能体嵌入到单页面应用、手机APP,或通过用户授权操作平台上的资源。对于开发者在平台上开发的智能体,他们可以将其发布出去,供第三方使用,如机器人公司开发的机器狗应用,可以通过平台快速赋能。
2. 插件与工具的安全性
在大模型的开发中,有一种场景叫Function Call(插件或工具),它赋予大模型调用第三方API的能力。在市面上看到的大多数调用实际上是不安全的,因为开发者通常需要将API密钥嵌入大模型中。然而,通过多种诱导攻击,密钥可能会泄露。
我们为此设计了专门的OIDC身份认证,基于零信任的身份认证机制。无论开发者希望智能体访问Gmail、Calendar,还是AWS的存储资源,都可以通过授权的方式接入平台,平台通过OIDC协议与第三方API进行打通,密钥轮转机制极大地减少了密钥泄露的风险。
3. 权限体系
权限体系设计对于平台至关重要。根据OWASP2021年的数据,后台服务系统中排名第一的漏洞是越权漏洞。这是由于没有设计好权限体系,导致系统后期频繁修补。我们在平台设计之初就考虑了这一问题,设计了完善的权限体系,做了完整的威胁建模。
权限体系包括:
- 强制访问控制:系统约束与管理员的约束
- 自主访问控制:资源所有者对资源的自主授权
因为平台是多用户系统,资源的协作与权限管理非常重要。
为什么选择Rust?
- 安全性:Rust是内存安全和线程安全的语言,尤其是线程安全,对服务端开发至关重要。相比于其他语言,Rust减少了许多内存与并发问题。
- 严格的类型系统:Rust的Option类型和错误处理机制,帮助团队养成良好的编程风格,减少了空指针异常等问题。
- 无畏并发:Rust原生支持async/await,解决了过去在Go或Java中高性能并发编程的复杂性。
- 广泛应用:Rust在信息安全领域有着广泛的应用,许多密码学基础设施都是基于Rust开发的。
Rust的实际应用
我们在平台中编写了大约10万行Rust代码,涉及六到七个微服务。整个架构分为接入层、应用层和权限引擎层,完全基于微服务架构,提供REST接口和内部RPC接口。
开发中的一些实践
OpenAPI Generator
我们使用OAS3.0标准定义API,并通过OpenAPI Generator生成Rust代码。这极大减少了API开发中的工作量,比如参数校验、上下文约束等,都是通过框架自动生成的。这使得开发人员只需专注于API的定义,而实现过程已经由框架完成了七八成。访问控制引擎
我们使用了AWS开源的Cedar访问控制引擎,它是完全用Rust编写的。Cedar的设计理念与Rust非常契合,具有高安全性、强表达力和优异的性能。此外,Cedar还支持定理证明,能够验证访问控制引擎设计的正确性,避免安全漏洞。
其次是错误处理。错误处理其实是一个老生常谈的话题。在以前的编程语言中,我们已经积累了大量的错误处理经验,比如如何定义异常、在哪些地方捕获异常、以及哪些异常应该抛给上游。在Rust里面,其实没有传统意义上的异常机制,但Rust提供了更好的错误处理机制。虽然没有通过异常的方式来处理错误,但在我们的实践中,尤其是后端服务的开发中,我们发现并不会遇到特别复杂的异常场景。
对于一些库的开发,我们使用了thiserror这个开源库,它可以很方便地帮助我们包装错误。不过,这里有一个小问题:如果源错误是同一种类型,而你想将其封装成两个不同的类型,thiserror是不支持的。后来我们发现了另一个开源库可以支持这种需求,但我们还没有尝试。
在我们的应用程序中,我们直接使用了anyhow,它非常方便,能够快速帮助我们传播错误。当你不需要处理特定的错误类型,或者无需根据错误的分类做更细节的处理时,使用anyhow是一个非常简便的方式,可以迅速传播错误。
接下来,我想重点讲一下我们的测试。首先,使用Rust之后,Rust编译器本身就能帮助开发者减少大量潜在的错误,比如未处理的空指针和多线程未加锁问题——只要Rust代码通过编译,就不会有这些问题了。Rust编译器实际上已经帮助我们消除了大量常见的编程问题。
作为一个安全系统,我们对安全问题的容忍度是零,因为即使出现一个小小的安全漏洞,可能都会导致系统的安全故障,而这些故障可能比其他类型的稳定性问题更严重,甚至影响到用户的数据安全或隐私保护。因此,我们对代码质量的要求非常严格。
在Rust中,有两类官方定义的测试。第一类是单元测试,直接写在研发代码中,能够快速测试小范围功能。第二类是集成测试,它们被写在一个单独的tests目录中,并且每个测试会被编译成独立的进程。
我们的测试理念是,首先测试应该易于开发。开发人员不应该有太大的心智负担,能够快速编写测试用例。曾经我做过一些复杂系统的测试,编写测试用例实际上非常困难,尤其是在复杂的环境中,构建测试上下文可能比编写功能本身还复杂得多。这种情况下,如果没有通过KPI强制研发人员写测试,大家往往会选择不写测试,导致质量问题留给QA或用户去发现。这样一来,产品质量就会较差,最终只能通过投入更多资源来解决问题。
其次,测试应该易于执行。开发完测试后,开发者应该能够立即运行它。然而,通常在分布式场景或后台微服务开发中,测试用例可能依赖数据库、缓存、消息队列,甚至其他服务的API。很多时候,想要在本地执行这样一个测试是非常困难的,甚至在依赖公共环境时,经常会出现测试用例之间相互影响的问题,比如一个测试用例改变了另一个测试用例的数据,导致测试结果不稳定。
为了应对这些问题,我们采用了一些技术手段。第一个是testcontainers,它利用容器技术快速启动依赖的中间件,如数据库或缓存。这样,测试可以本地启动容器进行测试,不需要连接到远程环境。第二个是wiremock,它可以快速模拟依赖的REST API,避免真正连接到远程服务。第三个是Rust生态中的mockall库,它可以帮助我们快速模拟函数或依赖的其他服务。
这里有一个小技巧:我们使用ctor和dtor技术来在进程启动前后执行一些初始化和清理工作。比如,测试容器的启动和销毁都放在ctor和dtor里,这样我们不需要在每个测试用例中手动管理这些资源。不过值得一提的是,Rust在测试的setup和teardown阶段的支持还不算特别方便,所以我们只能通过这种方式封装。
至于外部依赖的初始化,我们通过环境变量的方式来决定连接生产环境还是测试环境的数据库,这样就能在测试代码中使用测试环境的容器数据库。
通过这些手段,我们可以做到在本地编写完代码并按下回车后,十秒到二十秒内就能跑完所有测试用例。这样,研发人员不仅能消除一些低级的代码问题,还能捕获逻辑上的错误。
在我们微服务的集成过程中,测试也会执行cargo audit,检查最近的CVE漏洞,并执行cargo test来回归所有测试用例。此外,我们还会使用grcov来收集测试覆盖率数据。我们微服务的测试覆盖率普遍在80%以上,这样高的覆盖率有效地降低了生产环境中出现问题的概率。
从我个人的体感来看,使用Rust后,因为代码质量较高,平时遇到的代码问题非常少。只要代码通过编译并跑完测试,基本上就可以达到较少的bug。
最后,我简单讲一下团队建设。我们写Rust的团队是在今年年初才开始的,除了我有一些经验外,其他同事都是纯新人。虽然我个人的Rust水平还在不断提升,但我发现新人在一个月内就能上手。第一周我们会学习Rust的一些基本概念,第二周会做一些练习,比如在LeetCode上做LRU缓存题目,这涉及到生命周期和指针管理。第三周我们会学习异步编程,比如async和await,第四周基本就可以上手实践了。
实际上,Rust的学习成本并没有想象中那么高。对于后端服务开发而言,不涉及底层系统和嵌入式开发,学习Rust的难度是可以接受的。我们大量使用了社区中的成熟库来构建微服务,同时通过代码评审(Code Review)来相互学习,整个团队在四周内就能熟练上手。
最后我要强调的是,重视代码质量非常重要。通过Code Review,大家可以相互学习,营造一个良好的团队氛围。这样,从零开始,一个团队在四周内就能顺利起步。
这是我今天的分享,非常感谢大家!我们还有时间接受一两个问题,大家有问题想问的吗?
(听众提问)
“我想问一下您对于Rust在国内后端服务领域的发展有什么看法?相对于嵌入式开发,是否后端服务是Rust的一个更有前景的方向?”
(回答)
我认为目前已经有很多趋势表明Rust在后端服务中的前景非常广阔。之前在华为的经历中,我也看到有大量的后端服务采用Rust。这主要是出于成本考虑,尤其是对一些新项目而言,Rust的高并发支持、安全性和性能表现非常出色。
对于公司而言,Rust能带来巨大的经济效益。相比其他高级语言,比如Java,Rust对CPU和内存的消耗更小。Java应用,尤其是高并发的分布式系统,内存占用往往是几十GB甚至上百GB,而Rust至少可以减少一个数量级。
当然,现在还是一个起步阶段,尤其是存量项目的迁移成本较高。不过,越来越多的新项目已经在尝试使用Rust,我相信这是一个非常有希望的方向。
(主持人)
非常感谢刘老师的分享!如果大家有后续问题,刘老师今天下午也在现场,欢迎随时交流。
8.LlamaEdge:面向开发者的轻量级、跨平台大模型基础设施-刘鑫
好啊,那我们开始吧。今天很高兴有这个分享的机会。刘老师谈不上,大伙可以叫我SAM。在GitHub上,大家也可以找到我,因为我们是开源项目,所以大家都能看到我们的工作。如果今天现场有问题,当然非常欢迎提问。如果后续有一些深入的思考,我们也欢迎访问我们的项目页面,提出你的问题,甚至可以加入我们的微信群,后面会有微信的二维码。
今天我分享的题目是面向开发者的轻量级跨平台大模型基础设施。这个题目稍微有点大,因为一谈到基础设施,通常我的个人感觉是,这类技术应该是重量级的公司提出的一些解决方案,才能称得上是基础设施级别的系统。但是我们有志向往这个方向发展,最近几年我们也在不断演进,特别是随着大模型的兴起,我们的软件堆栈也在逐渐向这个方向扩展。
在我们通常开始做一件事之前,我们首先会考虑它的目的是什么。我们这个开源项目,实际上是面向大模型的应用开发。刚才我在题目中提到“面向开发者”,其实更准确的定位是面向应用开发者,即基于大模型的应用开发者。比如说,如果我想搞一个最简单的聊天机器人(Chatbot UI),然后分发给我的粉丝、用户或朋友,他们可以利用大模型来帮助他们解决一些日常问题,或者当作玩具来玩。
应用开发的关键就在于基于大模型的应用开发。开发过程中会面临很多挑战,今天结合我们大会的主题,我列举一些要点。大会的主题是Rust语言社区,所以我会特别结合Rust来讨论这些问题。
当我们接触到大模型的开发时,通常会遇到几个问题。比如说,你可能会和朋友讨论,你在用什么样的加速器?有的人会说,我用的是4090的GPU;有些企业更专业,可能会有专用的AI加速芯片。实际上,几年前,随着深度学习模型的出现,很多创业公司甚至大公司开始研发专用的AI加速芯片。
第一个问题就是硬件层面的问题。你会问,我的应用应该跑在什么样的加速平台上?有的时候,别人会问,你的应用能不能跑在手机上?其实,这涉及到手机的计算性能是否足够。硬件层面的问题是我们在大模型开发中多多少少需要考虑的。当前的硬件平台有CPU和GPU,CPU可能有x86和ARM架构,GPU又面临很多选择。这个时候你可能会思考,如何让我的应用软件在不同的硬件平台上运行一致,并兼容各种硬件平台。
第二个问题是互操作性和集成问题。我们刚才提到了硬件层面的问题,接下来你可能会想到软件架构,比如我们熟悉的PyTorch,或者TensorFlow,甚至ONNX等加速平台。这里我们需要考虑,如何将新旧的系统和大模型的工具、加速库进行集成。
第三个问题是安全性问题。安全性不仅仅是Rust语言提供的内存安全,也包括运行时的安全保障,比如沙盒环境,确保软件在运行时的安全性。
第四个问题是效率问题。无论是大模型还是早期的深度学习模型,通常都涉及大量数据的预处理和后处理。在生产环境中,速度至关重要,尤其是在数据量非常大的情况下。
最后一个问题是部署和维护问题。开发完之后,我们肯定希望让别人使用,这就涉及到如何在不同的平台上部署和维护。Python开发中常见的依赖管理问题,比如不同依赖库版本冲突,都是让人头疼的问题。
接下来,我要介绍LlamaEdge。为了契合今天的主题,我们从语言层面来讨论这个问题。我们使用Rust和WebAssembly(WASM),将它们的各自优势结合起来,帮助应用开发者减轻负担。
Rust的优势不言而喻,首先它的高性能毋庸置疑,内存安全也非常突出,尤其适合现代语言的开发。WebAssembly的优势在于跨平台兼容性,它可以在各种操作系统上做到一次编译、全平台运行,同时启动速度非常快,尤其适用于AI推理场景。
接下来,我简要介绍一下LlamaEdge的架构。这个架构可以分为四层,最底层是WASM的运行时,我们称之为WasmEdge Runtime。第二层是基础库层,它提供了基本的运算功能和大模型相关的支持,比如Prompt构建、OpenAI API的兼容性等。第三层是服务层,向外提供HTTP服务。最上面的一层是应用层,应用层通过标准的API进行访问。
整个系统通过WASM的插件系统实现了与硬件和框架的解耦。到目前为止,我们已经开发了19个插件,其中绿色部分是与大模型相关的插件。这些插件不仅支持C++,也支持用Rust进行开发。
LlamaEdge通过一个标准接口(WASI-NN)暴露所有插件的功能。这个标准接口非常简单,只有五个API。通过这个接口,前后端可以无缝通信,确保系统的兼容性和扩展性。
好的,我将按照你的要求整理这段内容,使其语句通顺且保持原意不变。
我们来看一下基础库的层面。基础库实际上包括三个部分,第一个是endpoints这个crate。这个crate主要负责的是API的定义,因为我们需要兼容OpenAI的API,所以在endpoints层面,主要是定义API的类型,以及如何支持不同的类型。最重要的一点是,它需要实现序列化和反序列化,并且遵循OpenAI API的规范。通过这个crate,你可以获得与OpenAI完全兼容的一整套API。
此外,这个库既可以用于WASM的开发者,比如你可以把它编译成WASM在你的项目中使用,也可以用于本地开发。如果你不想用WASM,只是做本地开发,也可以将它用起来。
接下来,我有一个想法。因为我们这个库是用Rust实现的,那么有没有可能通过社区的力量,用Protocol Buffers(PROTO)来定义这套规范呢?大家都知道,PROTOC可以生成各类语言的代码,这样可能会让它的应用范围更广。当然,虽然这在我们的计划里,但眼下还没有做。但我觉得这是一个很有意义的方向。
第二个库是一个非常基础的库,叫chat_prompts。在大模型的应用中,通常我们会收到一个用户查询(user query),然后模型返回一个响应(assistant response)。这个过程就是一种消息交互,也就是我们所说的对话。你需要维护这个对话的状态,在更复杂的场景中,比如函数调用(function call),交互会变得更加复杂,甚至可能涉及更多的模板。
我们在这里的做法是完全通过Rust实现的,而不是像其他人那样使用字符串模板或其它形式的模板。我们希望这个chat_prompts库不仅支持普通的聊天生成,还能够支持更高级的功能,如RAG(Retrieval-Augmented Generation)等。因此,我们通过trait的方式向外暴露API。
目前,这个chat_prompts库支持大约130多个开源的大模型。你可以在crate的README文件中看到所有的prompt模板(prompt string)。即使你不用这个库,这些模板对于你用Python写自己的项目也是非常有帮助的,可以为你节省大量时间。而且我们还在不断更新这些模型,比如今天上午我还在更新。你可以在Hugging Face上找到相关内容,如果有兴趣的同学可以去看看,提出意见,帮助我们改进。
这个架构通过trait的方式向第三方开发者暴露API,允许他们构建自己的应用。例如,如果你发现我们预设的十个prompt模板不适合你的需求,你可以扩展它,基于chat_prompts库扩展自己的模型模板。
在我们的技术栈中,最核心的库是la_core。这个库主要负责两个任务:一是定义prompt字符串,二是定义与OpenAI相关的兼容性数据结构。la_core库将这些功能整合并向外暴露一组API。通过这组API,你可以定义自己感兴趣的API server。
接下来,我会介绍API server层。你可以完全根据自己的需求定义API server。我们现有的API server其实只是一层很薄的封装,只需要处理请求的转发即可。当然,如果你希望构建一个更健全的系统,可以整合刘老师介绍的那套方案。
这个库与前面两个库略有不同。它只能编译成WASM的target,只服务于WASM环境,这点可能会稍有不同。
接下来,我想介绍一下API server这一层。API server主要是为了保证OpenAI API的兼容性。例如,你基于ChatGPT开发了一个应用,发现它非常成功,赚了很多钱,但也需要支付大量的token费用。如果你想找一个开源的替代方案,并自己部署API server,API server层就需要遵循OpenAI API的规范。
API server还支持定制化功能。比如,如果你需要一些OpenAI未提供的API,我们也可以基于现有API构建一套定制化的API,来满足用户的需求。
WASM带来的另一个好处是可移植性。一次开发后,你可以在各种平台上部署WASM的二进制文件。过去,我们需要编译不同版本的原生代码,虽然可以通过GitHub的CI工具来解决这个问题,但依然不如WASM的“一次开发,随处部署”来得轻松。
目前,我们提供了四类已知的API server,包括la_api_server,它支持chat completion、embedding等基础服务,这些服务都会从endpoints层面暴露出来。我们还提供定制化的绿色部分,用于计算token truncation,OpenAI并没有这个功能。第二类是RAG API server,然后是stable diffusion和whisper,这些可能大家都比较熟悉。如果你有兴趣,可以基于这些API server做扩展,我们非常欢迎,因为它们都是开源的。
这里有一个简单的to-call示例。上面黑色部分是终端部分,展示了如何启动一个API server。你可以直接在Hugging Face上找到这个命令。左边是request的结构,比如你要调用的函数名称、参数等信息,右边是response。这套API完全符合OpenAI的标准,你还可以根据需要调整,使用支持to-call的大语言模型。
我今天分享的内容比较多,大家可以慢慢消化。我们有一个口号:Developer First, Rust First, WebAssembly First。我们希望以开发者为优先目标,在系统实现上优先选择Rust,并通过WASM提供安全、稳定且便于部署的方案。
感谢刘鑫老师的分享。现在有同学要提问吗?好的,把话筒递给那位同学。
提问者:您好,刘老师。我想问一下,LlamaEdge和Ollama这两个工具看似都在解决类似的问题,能不能对比一下它们的差异?比如说性能或者模型更新速度上,因为Ollama的模型更新速度非常快,我也看了您分享的链接,感觉速度也很快,想了解一下这方面的区别。
刘老师:好的,我一个一个回答。首先,关于模型更新速度,可能你觉得Ollama更新得很快,但我想挑战一下这个观点。Ollama确实非常受欢迎,尤其是在国内,它的知名度可能比我们高很多,因为我们在宣传方面做得不够,比如我们在油管或者B站上的视频和教程相对较少,这可能是我们需要改进的地方。
Ollama的模型更新速度其实和我们差不多。为什么这么说呢?除非你和某个模型的创作者(creator)有直接合作关系,可以在模型公开之前拿到原始模型,否则大家的更新速度其实是相似的。另外,即使你提前拿到了模型,Llama.cpp作为底层库也需要支持这些新模型。而目前大部分在本地跑大模型的项目底层都是基于Llama.cpp。
即使你拿到了模型,如果Llama.cpp不支持新的架构,你还得自己改代码。如果你改了自己的版本,可能就不再是官方版本了,别人也无法使用。这也是我们的一个制约因素。
我们和Ollama各有合作伙伴,比如我们最近会和零幺模型合作,Ollama也有他们的合作伙伴。在Llama.cpp层面,我们不希望自己改一个版本,因为Llama.cpp是开源的,我们希望所有人都基于它的官方版本来做开发。
我觉得在本质上,LlamaEdge和Ollama没有太大差别。Ollama类似于Docker,如果你熟悉Docker,可能会觉得上手很快。但在更大型的生产环境,尤其是K8S这样的场景下,Ollama的表现可能有限。我们与Docker有合作,推出了WASM Container Image,这在未来可能会提供更好的整合。
我们希望为开发者提供更好的服务,帮助他们降低开发和运行成本。如果你使用ChatGPT,发现token费用太高,我们的项目可以为你提供一个性价比更高的替代方案。
感谢大家的提问,由于时间关系,今天只能提一个问题。后续有问题可以随时联系我,头像就是主持人提到的那个穿新衣服、头发稍长的头像,欢迎大家随时交流!
9. 大模型推理引擎 InfiniLM - 王豪杰
https://www.bilibili.com/video/BV1JctSeeE15/
开场介绍
大家好,我是来自清华大学的王豪杰。今天非常荣幸有机会在这里给大家分享一下我们团队做的一个工作——大模型推理引擎 InfiniLM。首先,简单介绍一下大模型的发展历史背景。由于大家对这块内容可能比较熟悉,我就简略地说一下。
大模型的发展背景
整个人工智能领域的发展可以追溯到上世纪50年代,最早的阶段主要是符号智能,即通过领域专家总结规律和知识,形成知识库来解决一些简单的问答。到80年代至90年代,逐渐有了通过带标注的数据训练神经网络,解决一些泛化性更强的任务,比如图像分类。2018年以后,整个领域逐渐向通用智能发展,最为显著的事件是2020年左右,ChatGPT的出现引爆了这个领域。它通过大量无标注的数据(通常是爬取自互联网)进行预训练,自动发掘通用知识,因此它的泛化能力相比之前的智能系统要强大得多,甚至在某些方面更接近人类智能。
通用智能的发展主要依赖于自监督的预训练方法,之后通过领域微调来让模型在特定任务上表现更好。大模型通常不对数据做预分类或预感知,通过简单清洗后形成特定格式,经过预训练后可以回答不同领域的问题,如翻译、医学知识、数学计算,甚至是代码编写。
大模型的主流应用方式
目前,大模型的主流应用方式是通过预测下一个字符(decoding)的模式来构建语言模型任务。其核心原理是将自然语言处理任务转化为序列生成任务,无论是翻译、判断,还是文生图、图生文,基本原理都是逐个 token 生成的模式。
InfiniLM 的开发历程
我们团队从去年开始开发了一个 demo,半年多前,我们发现基于一些通用的推理引擎存在局限性,因此专门开发了面向大模型的推理引擎 InfiniLM。目前,相比于一些开源系统,我们在性能上有一定的优势,并且适配了多种不同等级的大模型,包括桌面端或手机上使用的十亿级大模型、云端部署的百亿/千亿级大模型,以及 MOE 架构的万亿级大模型。
在开发过程中,我们进行了大量的优化工作,包括内存模型量化、服务层优化,以及不同硬件的支持。我们最大的特色之一是,使用一套代码可以运行在各种平台上,包括英伟达、寒武纪、摩尔线程、天数等云端芯片,以及桌面 GPU、CPU,甚至是手机平台。这一切得益于 Rust 语言的原生特性,只要能编译通过,组件就能在不同的平台上运行。
技术细节与开源发布
在开发 InfiniLM 的过程中,我们也发现了一些大模型领域的通用工具。我们将这些工具独立出来并发布到社区中,包括分词器 Tokenizer、上下文资源管理 Context Pool、对于 GGUF 格式的支持工具、平台无关的数据类型定义工具,以及硬件驱动绑定和环境配置工具等。大家可以在 GitHub 上关注我们的项目以及社区资源。
模型架构与推理过程
大模型的主流架构是 LLaMA 或类似 LLaMA 的结构,其核心由 input embedding 层、attention 层、MLP 层、normalization 层等组成。模型通常由多个 layer 组成,比如一些典型的大模型可能有 32 或 48 层。经过这些层的计算后,最终生成面向用户输出的 token。
在模型表示方式上,目前 Hugging Face 提出的 JSON + SafeTensor 格式是最常用的,因为 Hugging Face 提供了大量的大模型,因而这一格式被广泛使用。然而,这种格式需要依赖许多配置文件,稍有遗漏就可能导致模型无法运行。
相比之下,LLaMA.CPP 提出了一种更加合理的方式——GGUF 格式,它将所有的模型参数和权重打包在一个文件中,这使得模型的组织更加紧凑,便于管理。我们也开发了一个支持 GGUF 格式的 Rust 库,提供了对 GGUF 文件的解析和使用方法。
推理中的采样方法
大模型输出的 token 实际上是一个概率分布,模型并不会给出确定性的答案,而是根据概率选择可能的输出。常见的采样方法包括:
- 确定性采样:选择概率最大的词,但结果缺乏多样性。
- 随机采样:从所有词中随机抽样,创意性强,但有可能选到错误的词。
- Top-K 采样:从概率最大的 K 个词中随机抽样,兼顾多样性和准确性。
- Top-P 采样:从概率和为 P 的前几个词中随机抽样。
- Beam Search:选择概率最高的生成路径,确保输出序列的正确性,但占用资源较大,通常不适用于高延迟敏感的场景。
多轮推理与性能优化
在多轮推理过程中,大模型通常会一次生成一个 token,然后通过多轮推理生成较长的序列。大模型的 attention 机制会计算所有前面生成的 token,并随着序列长度的增加,计算量越来越大,导致推理速度变慢。
为了优化这一过程,我们采用了以空间换时间的方法,减少重复计算,从而提升推理效率。
好的,下面是整理后的内容,确保其通顺且不遗漏任何信息。
比如说,前面有一个输入序列 “there was”,这三个词我已经计算过了,已经完成了它们的矩阵乘法计算。在这种情况下,我就不需要再重新计算一次,而是把它们存储在一个叫做 KV Cache 的地方。注意,这里的 KV Cache 不是数据库中的 KV 键值对,而是指 QKV(Query, Key, Value)矩阵中的 KV。在 KV Cache 中,我们将之前所有的计算结果保存下来。当我在处理新的 token 时,我可以直接拿来之前的计算结果,只需要计算当前新生成的这个词的结果即可。这样一来,我就能将整个矩阵乘法的复杂度降低到 $O(1)$,因为每次只需计算一个词。虽然在序列拼接时,它的复杂度可能仍然是 $O(N)$,但相比 $O(N^2)$ 或 $O(N^3)$ 的复杂度,已经节省了非常多的计算资源和时间。
因此,当我们讲到这个 KV Cache 的原理时,大家可以发现大模型推理过程其实有两个截然不同的阶段。第一个阶段是当用户输入提示词时,系统需要把这个提示词的所有部分完整地计算出来,这个阶段会涉及非常庞大的矩阵乘法计算。比如说,用户输入的提示词长度为 100,那么矩阵乘法的维度就是 100。第二个阶段是当大模型逐个生成 token 时,每次生成一个 token,这时的矩阵乘法维度是 1。也就是说,这两个阶段的性能特征截然不同。我们通常把第一个阶段称为 PREFILL 阶段,即预填充阶段,而第二个阶段称为 DECODE 阶段,即解码阶段。
针对这两个阶段,业界现在也有很多优化方案。例如,我们可以将 PREFILL 阶段和 DECODE 阶段分别放在不同的机器上执行,这样可以更有效地整合资源。此外,也有许多研究工作针对这些优化进行深入探讨,这里就不展开讲了,大家可以自行关注相关领域的研究。
接下来,讨论到 AI 对话时,如何使用这些技术。比如说在写一个故事时,用户可能会输入 “There was a girl named Lily” 这样的提示词。这时候,模型会将用户输入的这段话作为提示词,并做一个标记,表明这段话是用户输入的。接下来,AI 会根据不同的采样方式(如随机采样或 beam search)逐个生成 token,直到生成一个模型认为合适的结束词,并将结果返回给用户。当然,实际应用中也可以使用流式生成的方式,每当生成一个或几个词时就返回给用户,这样用户可以更早地看到预期的结果,提升用户体验。
AI 对话本身也有一些复杂的模板。比如,一些带有尖括号或特殊符号的词汇,对于人类来说可能没有实际意义,但对于大模型来说,它们是输入提示或不同处理方式的标志。因此,现在有很多 AI 对话的模板引擎,比如 Python 模板引擎 Jinja2。通过这些模板,我们可以组织对话的形式,从而实现更高效、更高质量的输出。
在实际应用中,AI 对话不仅仅是处理单一的用户问题,更多时候涉及多轮对话,甚至多个会话同时进行。对于服务提供商来说,可能还需要管理多个用户的不同对话。在这种情况下,如何高效管理 KV Cache 就成为了一个需要解决的问题。举个例子,KV Cache 本质上是一个大模型的记忆过程。假如我们已经进行了十轮对话,现在想回到第五轮的对话继续生成新的内容,我们就可以通过 KV Cache 回溯到第五轮,让模型忘掉之后的对话,并从第五轮重新生成结果。
对于多个用户的 AI 对话服务来说,如果我们每张加速卡只能服务一个用户,那对于服务提供商在算力层面来说是不可接受的。因此,我们希望尽可能高效地利用算力资源。在这种情况下,我们需要做批量处理,也就是 batching。我们实现了 batching 方法,参考了之前的 OS 文章中提出的 Continuous Batching 原理。其核心思想是,从资源请求池中选取若干个对话,将它们组成一个批次,每次处理一批对话,比如 16 个或 32 个。处理完之后,再开始处理下一批。通过这种批量处理方式,我们可以更高效地利用加速卡的带宽和计算资源,提升整体资源利用率,进而用一张卡服务更多的用户。
同时,不同用户的对话长度也是不一样的,因此我们还会使用 padding 等方式,确保一致性,从而实现高效的输出结果。
当我们讨论完单卡推理优化后,接下来就是如何做分布式推理。所谓分布式,就是将计算分布到不同的加速卡上。目前主流的方式包括数据并行和模型并行。当然,也有流水线并行和 ZeRO 并行等方法,虽然这些在推理中用得相对较少。处理并行时要考虑如何切分计算任务,切分方式的不同会导致不同的负载情况和通信开销。我们在张量切分时,遵循了完整与部分合并的原则。也就是说,对于某个硬件上的张量,它可以是完整的,也可以是部分的。如果是部分张量,我们需要通过跨卡的 reduce 操作,将部分张量合并为完整结果。
对于矩阵乘法的切分,无论是横切还是纵切,影响的都是计算出矩阵的部分或完整结果。切分完成后,我们需要使用 all-gather 或 all-reduce 操作,将不同卡上的信息汇集,从而得到最终一致性的矩阵结果。
在多张卡并行时,另一个需要考虑的问题是如何管理资源。假设我们只有一张卡,那么所有资源都在同一个 stream 上操作,不会出现错误。然而,当我们有多个卡、多个 stream 和多个任务时,如果资源放置在错误的上下文中,可能会导致加速卡崩溃。因此,我们引入了资源绑定的抽象。每个资源都会绑定到特定的上下文生命周期中,生命周期外不能访问该资源。通过 Rust 的生命周期管理机制,我们可以在编译阶段保证资源的正确使用,避免运行时出现错误,同时不会引入额外的运行时开销。
接着,我们讨论如何在多卡上做更加大规模的模型切分。对于 MLP 层,我们通常会按照 Intermediate Size 切分,将其切分为若干份,每张卡负责一部分,计算完成后通过 all-reduce 操作合并结果。对于 Attention 层,我们发现每个 head 的计算是独立的,因此可以将不同的 head 切开,最后通过 reduce 操作合并结果。
最后简单介绍一下我们的项目背景。我们团队来自清华大学等多个单位,由老师、学生和工程师组成。我们的研究方向是人工智能系统,前面提到的 InfiniTensor 是我们其中一项研究成果。我们的目标不仅是在英伟达的加速卡上实现高性能推理,还要在国产加速卡上实现性能可移植性,目前我们已经支持了包括英伟达、寒武纪、摩尔线程、昆仑芯、天数智芯等多种加速卡。我们还在开源社区举办了人工智能系统相关的训练营,计划每半年举办一次,普及人工智能知识,旨在面向高校和开源社区培养人才。
以上就是今天汇报的全部内容,感谢大家的聆听。
问题环节
提问 1:
选用 Rust 作为推理引擎的编程语言是出于什么考虑?Rust 在推理引擎应用场景下相较于其他语言有哪些优势?
回答:
最初选择 Rust 其实是因为我们想尝试用 Rust 来写一下,但在实际做起来后,我们发现 Rust 的很多语言特性能够在编译阶段保证代码的正确性,而不需要在运行时做额外的检查。比如我们提到的资源绑定抽象,不需要在运行时通过各种判断来避免错误,而是通过 Rust 的生命周期限制,把资源严格绑定在某个上下文中。只要编译通过,运行时就不会出错。类似的例子还包括可以通过语言特性在编译器中进行错误检查,而不是在运行时通过 try-catch 等机制去处理错误。
提问 2:
你们团队的 AI 编译器和推理引擎之间有配套关系吗?
回答:
我们团队的第一个开源项目是 InfiniTensor,最早是一个经典 AI 编译器,后来我们扩展了它,支持了多种平台。最初我们在 InfiniTensor 系统中集成了大模型推理,但后来发现大模型推理和经典 AI 编译器有较大的不同。大模型推理是一个非常动态的过程,每次生成新的 token 时,形状都会变化,同时它不需要非常复杂的图优化。因此我们决定开发一个专门针对大模型推理的引擎。
提问 3:
你们在项目中是否对 CUDA 或其他底层 API 进行了封装?
回答:
是的,我们在项目中做了一些系统层的通用优化,例如 KV Cache 管理和服务层优化。每个硬件的 API 都不同,所以我们最早对每个硬件库进行了封装。目前,我们也正在尝试提出一些标准化接口,能够适配不同的硬件平台。
提问 4:
现有推理引擎如 TensorRT 等也有类似的优化技术,如果快速总结你们的优势是什么?
回答:
我们不能说有绝对的优势,但有一些特色。首先,我们原生支持多种不同的加速卡,比如英伟达、寒武纪、摩尔线程等,实现了系统层和硬件层的良好切分。其次,Rust 的编译期错误检查特性能够帮助我们减少运行时的开销。
感谢大家的提问和参与,今天的分享就到这里。
10. Rust在MPS能源网络中的应用 - Jason Thon
各位老师,下午好!我是来自GGGSN云技术团队的研发负责人。今天我要讲的主题是我们如何通过Rust加快商业化产品应用的迭代速度以及提升服务的稳定性。这个分享更多是方法论上的内容,可能不会涉及特别具体的技术细节。我的主题是“Rust语言在MPS能源网络中的应用”。
演讲结构
我的演讲分为四个部分:
- 背景介绍:我会介绍一下我们的背景,帮助大家更好地理解。
- 解决方案:基于背景提出的一些问题及解决方案。
- Rust应用:我们是如何在解决方案中应用Rust的。
- QA:留一些时间给大家提问。
公司与产品介绍
我们公司叫国广圣能,是一家总部位于上海的能源科技公司,主要致力于构建移动能源网络MPS。我们的产品已经投入运营,名为Mobility Powers Fly,这是一款高端旗舰产品,已经在上海的K11和嘉兴服务区部署。
这是一个视频展示了我们的产品场景:当车主在没有充电桩或充电桩损坏的情况下,我们的产品如何帮助他们解决问题。这个产品集成了许多先进技术,比如L4级自动驾驶、线控底盘和预控制器,都是高端新能源车才会用到的零部件。我们的电池技术由我们的创始人与亿维锂能联合研发。
面临的挑战
我们正在面对一个全新的硬件平台,这个平台前所未有,存在许多技术挑战。比如:
- 异构性:我们面对几万台车、几百万台车,每台车可能有几百个不同的软件版本,这些版本提供了完全不同的功能。作为上层的Cloud平台,需要有很强的抽象能力。
- 复杂性与规模增长:由于引入了移动属性,能源调度的复杂度呈指数级增长。我们还需要接入不同供应商、运营商,订单数量短时间内爆炸式增长。
- 快速迭代与资源短缺:作为创业公司,我们人少、钱少、技术少,但市场变化非常快,我们必须以不变应万变,保持业务系统的稳定。
面临的“三角难题”
我们面临着一个不可能的三角:少量的资源投入、拉垮的基建水平、快速的迭代。我们需要在资源有限的情况下提供一个让客户满意的产品。经过评估,我们发现Rust可能可以解决这些问题,事实证明,Rust确实在这方面有独特的优势。
Rust的解决方案
我们怎么用Rust解决这些挑战呢?
目标
- 支持100倍的业务提升:去年我们接入了20几台车,但今年已经增长了100倍,接入了2000台车。
- 可信赖的基础设施:我们的客户都是大B客户,央企、国企,他们需要稳定可靠的系统。
- 面向未来:我们要预留空间,能应对未来的技术发展。
为什么选择Rust?
- 高性能且安全:Rust保证了系统的稳定性和安全性,避免了频繁宕机与bug。
- 高效的语言:Rust的高效性体现在需要良好的编程习惯和DevOps流程支持。
- 务实的设计:Rust的泛型和宏设计帮助应对高复杂性场景。
我们的成就
- 没有P0级别的bug:系统上线后几乎没有需要操心的地方,运行非常稳定。
- 十倍的ROI:人力资源的投入与实际产出之间有了十倍的提升。
- 为未来做好准备:我们为未来更复杂的场景与更大的规模已经打好了基础。
Rust的具体应用
- 架构设计:我们整个软件架构中,黄色部分都是使用Rust编写的。整个基础设施都是基于Rust,基于K8S生态,事实证明,Rust帮助我们快速完成商业化迭代,并交付了一个让客户满意的产品。
- AIOT接入:我们使用Rust的FFI(Foreign Function Interface)接入各种异构设备,尤其是车载C语言写的控制器,这样无需跨部门合作,简化了流程。
- 高性能状态机设计:Rust的泛型设计优秀,能帮助我们更优雅地设计状态机架构。
- 数据引擎:我们开发了一个可插拔的存储引擎,支持各种数据库如Postgres、MySQL。引擎还提供了watch API,用来监控设备的实时状态。
- 智能调度器:我们的调度器支持AI推理,处理复杂的动态分布式图模型,Rust在这方面提供了很多优秀的实践供我们参考。
- WebAssembly设想:未来我们计划使用WebAssembly做流计算引擎,帮助交付团队快速完成不同项目的需求。
QA环节
Q1:如何保证没有P0级别的bug?
我们通过良好的编程习惯(Good Behavior)来保证代码质量,譬如单元测试、测试流程等。经过完整的测试流程,功能性故障应该控制在P0级别以下。
Q2:你们的能源网络业务具体是什么?
我们的产品主要解决了充电桩建设中存在的固有矛盾,比如电网扩容成本高、停车场持有成本高等问题。我们的产品将车位和充电桩解绑,且不需要对电网扩容。
Q3:如何判断应聘者是否具备良好的编程习惯?
通过面试时的Coding Review,观察应聘者是否能测试其代码、保证代码运行正确。这能反映出他是否具备良好的编程习惯。
非常感谢大家的时间,欢迎大家随时提问和交流!
各位老师,下午好。
我是来自足下科技的AI工具链工程师朱震东,主要负责Rust与AI工具链相关的研发工作。今天要分享的主题是《使用Rust加速构建边缘LLM应用》。可能和前面几位老师分享的基于基础架构的内容有所不同,我今天将主要讲述应用端的一些内容。
我的分享将分为三个部分:
- 背景介绍:为什么我们要构建这样的应用,为什么选择Rust。
- 实践过程:我们是如何构建这个应用的。
- 经验分享:在开发过程中遇到的一些问题和经验。
应用背景
首先,为什么要构建一个边缘计算的LLM应用?
大家对大模型(LLM)的了解,可能更多的是来自于像ChatGPT或国内的其他提供商(如“确问”等)。但其实,我们的电脑也是有能力直接运行大模型的。我们之所以要这样做,主要有以下几个原因:
隐私性:使用云服务时,如果处理涉及隐私的数据,可能不希望这些数据传输到云端。在本地运行大模型,可以确保数据不被泄露,这对企业用户尤为重要。
趋势:越来越多的设备正在增加AI加速芯片,像英特尔的Core Ultra系列、AMD的7840、高通的X Elite等,都在其SOC中集成了NPU(神经网络处理单元)。我们认为未来个人设备,甚至手机,都会具备运行大模型的能力。
成本:运行大模型的成本较高,尤其是使用云服务时,成本主要来自GPU设备、电力和机房运营。如果能把这些成本分摊到每个用户的设备上,能够大幅降低企业的运营成本。
Rust的选择
在调研过程中,我们选择了Rust作为开发语言,主要有以下几个原因:
高性能和高开发效率:Rust的性能与C/C++在同一梯队,但其语法和生态让开发效率更高,特别是在应用程序的构建中,Rust能够很好地平衡性能和效率。
高质量的工具链:与C/C++相比,Rust的工具链更加统一和便捷。Rust的包管理工具Cargo极大简化了依赖管理和构建流程,节省了大量开发时间。
Rust与AI的结合潜力:尽管Rust在AI领域的生态尚未完善,但我们认为探索Rust与AI的结合是非常有前景的,这也是我们坚持选择Rust的原因。
实践过程
我们开发了一款名为“Z Chat”的端侧Agent,用于帮助用户解决常见问题。产品的背景如下:
在与客户的交流中,我们发现客户由于不熟悉我们的产品,经常会提出大量重复性的问题。例如,如何接入摄像头、编译为什么会崩溃等。这些问题虽然已经在文档中回答过,但用户往往没有仔细查阅,导致我们的人力无法应对。
因此,我们决定利用大模型的自然语言处理能力,开发一个能自动回答问题的系统。该系统采用了热门的RAG(Retrieval Augmented Generation)技术,也就是“检索增强生成”。
为什么不直接使用现有的大模型?
公有知识与私有知识的差异:大模型在预训练时没有包含我们产品的知识,我们需要让模型了解我们的产品知识。
数据安全:一些企业用户出于安全考虑,不愿将代码或数据上传到云端,这使得本地运行大模型成为必要。
降低使用门槛:通过自动化系统,用户不仅可以快速解决问题,还可以生成代码、查询API等,降低了使用我们的产品所需的技术门槛。
系统构建
系统的构建分为几个步骤:
数据准备:我们将产品文档(如Markdown、PDF文件)和C++代码(如头文件)等内容切成小块,并存入知识库。这些数据将作为LLM的外部知识来源。
嵌入向量生成:我们将这些文本块通过嵌入模型(embedding model)转化为向量(vector),然后将向量存入向量数据库(vector database)。此过程相当于为大模型提供了一个外部的“记忆库”。
用户查询处理:当用户提问时,系统会首先抽取问题的语义,并在向量数据库中找到相关的文本块。接着,系统将用户的问题和找到的相关数据一并发送给LLM。通过这种方式,大模型不再是“闭卷考试”,而是能够“翻书”作答,提供更准确和相关的回答。
实时更新:向量数据库需要定期更新,因此我们设计了一个机制,确保每次启动时都能检测并更新数据。如果用户允许连接外网,还可以直接访问我们的数据库。
然后再跟用户进行交互式的对话,因为这样的话,速度肯定没有这套系统来得快。
摆在我们面前的另一个问题是,现在我们有了这一套RAG系统,但我们如何判断这套系统的效果好不好?或者说,当我们进行优化时,怎么知道这些优化是正向的还是负向的呢?因此,我们需要一个可以衡量RAG系统效率的工具。
这里,我参考了一篇论文,叫《IJS: Automated Evaluation of Retrieval-Augmented Generation》。这个库有Python版本,不清楚它是官方还是非官方实现,但在Rust上是没有的,所以我自己手动实现了一个。大家可以看一下这个代码,它与右边的图是对应的。
首先,看一下右边的图。我们有一个抽象的概念,叫Evaluator,它相当于是一个整体的评估者。我们把它需要的一些元素交给它,比如数据集(DATASETS),这些数据集是用来评估的,而不是用来训练的。然后,我们指定使用哪个LLM(大语言模型),以及哪些任务(test)。接着,我们定义LLM的参数,例如温度(temperature)、重复惩罚(repeat penalty)等。将这些参数交给Evaluator后,可以看到左边的代码,我们注册了三个任务(test),然后调用Evaluator.evalue_all()方法。这个Evaluator会遍历每个任务,计算每个任务的结果和得分,最后通过特定的报告生成器(reporter)生成报告,并记录到表格中。
通过这样一套系统,你可以自由组合数据集、LLM和各种参数,然后自动得到一个较优的组合。这是一个完整的迭代循环。
使用情况展示
目前我们实现了一些使用形式,左边的页面展示了我们CLI的形式。可以看到,在接入z chat之后,我问它“足下科技是一家怎样的公司?他们的业务是什么?”这是一个典型的咨询类问题。右边展示的是一个代码方向的问题,我问它“如何部署PingPong?”(PingPong是我们最基本的应用程序)。可以看到,它不仅能根据资料回答咨询类问题,还可以根据文档中的代码回答技术问题,帮助你解决代码相关的难题。
除了CLI,我们同样提供了GUI的使用方式。两个问题和上一个页面完全一致,只不过这次是通过VS Code插件呈现的。这个插件直接嵌入我们内部的软件z studio中,这样推广的难度更低。用户在使用时,可能并没有特别想用这个工具,但既然它已经在侧边栏上,如果需要,就可以随时打开使用,推广的门槛因此降低了。
之所以我们还提供CLI,是因为有些情况下,客户可能在服务器上工作,或者是在一些特定环境(例如运行中的车上),他们不方便打开多个窗口或使用VS Code,命令行对他们来说会更方便一些。
开发中的经验分享
现在,我想分享一些开发过程中遇到的经验和问题。
首先,如果你想开发一个端侧部署的应用,首先要考虑的是支持多种不同的推理后端。我们首先对推理后端进行抽象。可以看到左边的代码,这是一个pop trait,我命名为LOM Model。对于任何推理后端,我其实只关心两件事:第一是complete,这表示非流式的生成;第二是complete_stream,这是流式生成,类似OpenAI的方式。大多数LLM只需要关心这两部分。
这是最简单的形式,代码展示的是一个简化的版本,便于大家理解。你可能会问,为什么需要为prompt单独搞一个类型,而不直接用String?这是因为我们考虑了一些特殊情况,例如有些场景需要对prompt进行模板化处理。举个例子,对于API查询类的问题,你可能只需要修改中间的一些内容,大部分模板无需改动。此外,考虑到有时需要传递结构化的数据(如tool call),直接使用String并不方便进行后续的抽象和修改。
为什么要支持多种后端?因为大模型领域发展迅速,推理方式层出不穷。今天可能是Llama.cpp比较流行,明天可能就是Wasmer、Candle或Burn占据主导。因此,我们在开发应用时,尽量不要把自己绑定在某一种推理引擎上。此外,这种方式还可以让我们接入一些云端的LLM。虽然我们主要使用Rust来做边缘计算,但这并不妨碍我们接入云端的大模型。
反常识的Tokenizer问题
接下来,我想分享一个比较反常识的问题——Tokenizer。可能有些对机器学习有了解的朋友知道,Token本质上是将一大段文本转换为一组小的单位。在大多数情况下,它把一段文本转换为词,比如左边的英文文本,大多数Token是按照单词分割的。但在中文中,有时一个字会被拆成两个Token。这是因为它并不是基于UTF-8字符或词进行拆分的,而是基于字节。因此,如果你没有考虑这个问题,虽然不会报错,但可能会让你困扰很长时间。
正确的做法是,确保在整个RAG链路中使用的所有Tokenizer,包括LLM内部的Tokenizer,都是一致的。这样才能保证系统的正确性。我推荐大家使用北京智源的BGE-large-zh-v1.5,它是MIT协议的,商用免费。
系统大小与打包问题
大家可能关心系统的整体大小。包括推理引擎、向量数据库等内容(不包含模型和数据资源),整个应用的大小只有41MB,非常小。
在部署和打包时,不同的Linux版本可能存在glibc版本不一致的问题。这个时候,大家可以使用Zig工具,将glibc降级到2.17版本,这样可以保证应用在大多数系统上都能正常运行,而应用的大小几乎不受影响。
问答环节
问题1:朱老师您好,您刚才提到您手搓了一个RAG评估系统,从Python迁移到Rust,能否大致介绍一下用了多长时间?
答:我实现的是一个简化版本,没有实现所有task,只实现了主要框架和几个关键task,大约花了一到两周时间。其实最关键的是设计,因为大家都知道Python是动态语言,而Rust是静态语言。比如task部分,如何在同一个数组中放入不同类型的任务?这是一个工程上的难点。但一旦架构设计好,后续填充任务就非常自由了。
问题2:我们公司有一些Python项目,部署和后期维护有些问题,打算全部转成Rust,您有什么建议吗?
答:我建议关注一下PyO3库,它可以在Rust中调用Python。你们可以先从部分边缘功能开始迁移,而不是一次性全部转移到Rust上,这样工作量会小一些。也可以先在Rust中调用Python,或反过来,逐步过渡到纯Rust实现。
好,提问环节时间有限,大家可以私下与朱老师交流。再次感谢朱振东老师的分享!
12. Rust AI 生态下的机器学习框架与多层级编译技术 - 鲍国庆、石恒
大家好,我是石恒,我们是来自上海交大和燧原科技的联合研究团队。今天很高兴有机会和我的同事,包国庆博士一起,给大家分享我们团队的一些相关工作。我们主要专注于 AI 计算系统中的系统优化和编译优化技术。从 2022 年初开始,我们团队就在使用 Rust 进行一些底层基础组件和工具链的开发。近期,我们的工作已扩展到了框架层和编译器层的相关研究。
今天的分享主要分为几个部分,我负责前面的介绍和讨论部分,主要讨论我们在 Rust 生态下看到的 AI 计算系统目前的构建现状和趋势。技术细节部分将由包博士详细讲解,我们近期完成的两个研究项目。
首先,我们来看一下 AI 计算系统的大致架构和生态形式。我简单给大家画了一张结构图,最上层是应用层,包含大家熟悉的深度学习算法、传统科学计算和 HPC 计算负载。最下层是计算加速设备,包括不同架构的加速器芯片、存储颗粒、片间和片内的互联技术。
计算系统的任务是将上层的计算负载翻译为能够在硬件上高效执行的机器代码,而这些机器代码的标准是由硬件的指定微架构(ISA 层)和硬件抽象层(HAL 层)共同决定的。由于这个过程较为复杂,AI 计算生态自然发展为多层级的架构形态。
深入来看,最贴近硬件抽象层的部分要做的工作是将复杂的硬件概念抽象成易于开发的软件概念。这部分通常通过编程模型(Programming Model)来实现,开发者可以通过 DSL(领域专用语言)扩展这些抽象概念。另一种方法是为编译器提供工具链或编译目标,例如 LLVM 项目中的 NVPTX 后端为英伟达 GPU 生成 PTX 代码,AMDGPU 后端则为 AMD GPU 生成代码。
再往上,我们需要对核心计算单元进行高性能实现。通常有两种实现方式,一种是开发者基于编程模型进行人工编写,另一种是由硬件厂商提供的库(Vendor Library),如 Intel 提供的 MKL 库和英伟达的 cuBLAS 库。这一层的工作主要由硬件厂商负责。除了人工编写库,另一种方法是通过编译器技术自动化生成代码,如多面体编译或循环合成,这类技术在 TVM、MLIR 等开源项目中使用。
再往上是 AI 框架层和 DSL 层,它们承担了生态中核心的角色,支持不同宿主语言的用户群体。Rust 在这个过程中发挥了怎样的作用呢?目前 AI 计算系统并不需要实现所有组件,只需打通一条垂直路径,比如从编程模型到 Vendor Library,再到框架,或者从框架到编译器,再到编译器后端。
我们对 Rust 社区的现状做了一些调研,发现 Rust 社区更喜欢基于已有的主流生态工具或产品进行替代实现,例如 NumPy 的 array programming 实现,Rust 社区提供了 ndarray 和 nalgebra。另一种开发形式是通过 language binding 的方式,将主流生态下的 C++ 库绑定到 Rust 环境中,比如 OCL 和 Rust-CUDA 分别将 OpenCL 和 CUDA 库绑定到 Rust 环境。
然而,大部分工作目前仍集中在上层框架和 DSL 层,底层编译器层的工作较少,只有对 MLIR 编译器框架的少量 binding 工作。因此,底层优化仍是一个有待开发的领域。
接下来,包博士将分享我们团队近期的两项工作。首先是我们在开源项目 Candle 中做的系统优化和开源贡献工作,这个项目涵盖了框架层和 Vendor Library 层的工作。其次是我们基于 MLIR 后端,开发了一个计算图层级的编译器,用于 AI 计算的训练和推理优化。这个工作已被今年的 ASE 会议接收,后续可能会开源。
鲍国庆博士的分享
大家好!接下来我将加快节奏,分享的内容比较多,请大家见谅。
第二部分内容是关于 Rust 在 AI 框架中的应用,主要以我们最近的 Candle-vLLM 项目为例。vLLM 是艾瑞克团队最近开发的一个开源项目,主要用于大模型推理。通常 vLLM 的上层使用 Python,底层使用 C++ 和 PyTorch。我们的项目目标是将 vLLM 移植到 Rust 平台,底层使用 Candle 框架,这也是一个 Rust 平台的框架。
我们在 Candle 上搭建了一个 ML 引擎和一个 Chat Server。该 Chat Server 支持同步、异步、批量和单个请求,不同请求的响应方式也不同,包括流式响应和完成响应。Chat Server 已支持加载标准的 Save Tensor 格式,同时也支持将加载的张量转换为 GGML 或 GGUF 量化格式,以便在消费级设备上进行推理。我们计划后续直接支持加载 GGUF 格式的量化文件。
LLM 引擎分为三个部分,最重要的是推理服务(Inference Service)。与其他框架最大的不同在于,我们引入了分片注意力(Paged Attention)机制。大模型推理时,KV Cache 的管理至关重要,它需要将之前的 KV 和当前的 KV 组合存储。随着长文本推理的进行,连续的显存块需求越来越大,显存利用率也逐渐降低。为了解决这个问题,分片注意力机制引入了分页机制,可以将 KV Cache 存储在非连续的存储块中,并通过管理器调度这些非连续存储块。
此外,我们还引入了一个序列推理引擎来管理批量推理请求。推理引擎生成每个 token 的输出后,我们进行了采样(Sampling),支持主流的 Top-K、Top-P 采样方法,并使用 Rust 实现了重复惩罚器(Repeat Penalizer),以解决大模型推理中的重复生成问题。
我们的 Candle-vLLM 框架提供了一个完整的推理架构,支持启动 Chat Completion 的 UI,并兼容 OpenAI API。我们在 A100 显卡上运行了 Llama 3.18B 模型,使用 BF16 精度,推理速度可以达到每秒 60 多个 token。量化后,推理速度可以提升到每秒 70-80 个 token。对于批量请求,速度可以达到每秒 500-600 个 token,性能与 vLLM + PyTorch 相当。
我们刚才提到了我们正在做的一个Chat Service。在Rust中,开发这个Chat Service相对来说比较简单。根据不同的请求类型,我们可以在响应中返回不同的内容。在Python中,我们有一个INNM的态度(注:可能是指某种模式或接口),可以根据不同的请求返回不同的类型,比如流式响应(streaming)或完成响应(completion)。
Completion指的是当推理全部完成后再将结果一次性返回给用户。而在Rust中,我们可以启动这样一个函数,比如叫做chat_completion。在这个函数中,我们不需要编写太多代码,只需要将HTTP请求自动转换为我们定义的ChatCompletionRequest结构体。通过设置的方式,Rust可以自动帮我们完成这种转换。
在这个结构体中,我们可以获取用户发送的prompt,然后对其进行检查和编码(encoding)。编码之后,我们就可以将数据发送到我们的推理引擎(inference engine)进行推理。推理完成后,系统会根据不同的请求类型进行响应:如果是流式响应(streaming),我们会使用Rust中的事件机制,通过流式的方式将每个结果发送给用户;如果是完成响应(completion),则会等到推理完成后再一次性返回结果。
接着我们来聊一下如何在Rust中实现流式传输(streaming)。在Rust中实现流式传输相对容易,因为Rust本身有Stream特性。我们只需要实现Stream这个trait。在这个trait中,我们可以将每个token打包成一个chunk,然后通过事件机制发送出去。发送时,我们会使用Event将数据打包到Response的Body中,最终传输给用户。
在这个过程中,我们并不需要手动将数据序列化为JSON格式。每当我们生成一个token后,它就会被打包并发送出去。在流式传输的过程中,我们还处理了一些异常情况,比如客户端断开连接等。总的来说,Rust简化了整个开发流程。
在开发Chat Service时,Rust的异步特性(async/await)以及像Tokio、async-std等库,使得我们能够非常快速地搭建Web服务。同时,由于我们需要进行并行推理,所以还涉及到数据的并行处理。为此,我们使用了一个叫rayon的库,它可以帮助我们并行化处理数据。我们只需要调用数组的并行迭代器(par_iter),就可以自动并行处理数据,而不需要手动管理多线程。处理完的数据还会按顺序返回。
在Rust中,我们还使用了Serde库,它可以自动完成数据的序列化和反序列化工作。比如在chat_completion中,我们并没有手动序列化或反序列化JSON数据,Serde自动帮我们处理了这些转换。此外,Rust中的Stream特性也帮助我们简化了流式应用的开发。
另一个有趣的部分是,我们在项目中使用了一个叫utoipa的库。这个库可以帮助我们为HTTP服务生成文档。通过在接口函数中定义标签,可以自动生成请求和响应的文档。如果请求失败,还会提示正确的请求方式。这使得开发更加高效和便捷。
接下来,我想介绍一下Rust在我们AI研究中的一些应用,特别是在机器学习编译中的应用。我们最近的一篇论文被2024年ASE(国际软件工程会议)接收。在这篇文章中,我们展示了如何使用Rust加速机器学习前端编译。最终的效果是,我们可以将TensorFlow、PyTorch、ONNX、Keras等多种框架的模型,通过Rust编写的前端,转译成可以在多种设备上执行的代码。
这个转译过程不需要开发者手动编写算子(OP)。在Python层,我们对模型进行追踪,然后通过一个叫PyO3的绑定库,将很多Python的请求传递到Rust层。在Rust层,我们会进行类型推导和中间表示(IR)的生成,最终在不同的设备上执行代码。我们的实验结果显示,与SOTA(State-of-the-Art)方案相比,使用Rust后,编译和执行速度都有显著提升。
在这个项目中,我们使用了PyO3库,它可以非常方便地将Rust层的代码绑定到Python层。我们可以通过PyO3将Rust的Tensor数据绑定到Python中,甚至可以支持Python中的kwargs(任意长度和类型的参数)。在Rust中,Option和PyDict可以很好地处理这些可选参数。
一个有趣的部分是,Rust有生命周期(lifetime)的概念。这在处理跨语言数据传递时非常有用。比如,我们可以在Python中访问Rust中的数据,并根据需要将其转换为Python的ndarray类型。这种生命周期管理使得我们可以避免像C++那样的内存泄漏问题。
实现这些功能时,我们在Rust中抽象出了一个Tensor结构体。这个结构体可以持有不同设备上的数据缓冲区,比如CPU、GPU等。数据缓冲区可以是不同类型的,比如FP32、FP16等。通过简单的几行代码,我们就可以抽象出不同设备和数据类型的Tensor,这极大地加快了我们的开发速度。
最后,我想谈一下如何在Rust中构建跨语言项目。我们的项目分为三层:最上层是Python,中间层是Rust,底层是C++模块。在Rust中,我们使用了一个叫maturin的工具。通过这个工具,我们可以用一行代码来构建项目。maturin会先构建Rust工程,再链接C++模块,最终生成一个可以直接在Python中导入的.so文件。
这个跨语言的开发流程非常顺畅,maturin帮助我们自动管理Rust和C++之间的依赖关系,最后将所有内容打包成一个可以在不同平台上安装的Python包。此外,我们还使用了bindgen工具,它可以将复杂的C++头文件转换为Rust代码,使得我们可以直接在Rust中调用C++库。
调试方面,Rust中的lldb工具可以帮助我们从Rust代码调试到C++代码,非常方便。这也是Rust在跨语言开发中的一个巨大优势。
总结一下,今天我们介绍了Rust在机器学习框架和编译中的应用。我们还讨论了如何在AI研究中使用Rust来优化性能,以及Rust在跨语言开发中的优势。非常感谢大家的聆听!
问题环节
观众提问:老师您好,我有一个问题。您在PPT中提到,可以最小化Python中的全局解释器锁(GIL)。请问您是如何处理这个问题的?
鲍国庆博士:您提到的GIL问题,主要是在多线程环境中,Python的GIL会影响性能。我们在实际项目中,大多数多线程任务都放在Rust层来处理,而Python层主要作为接口层,不会承担大量的并行任务。因此,我们在Rust中通过数据并行或任务并行来解决性能问题,而Python层则尽量保持简单,只负责调用接口。
观众:所以可以理解为,Python层是单线程的,主要的并行逻辑都在Rust层处理,对吗?
鲍国庆博士:对,没错。Python层只提供简单的接口,主要的并行任务都在Rust层处理。
主持人:非常感谢鲍博士的精彩分享!
13.Rust在内容资产管理系统的应用-丁鑫栋
hello,大家好,我叫丁鑫栋,大家也可以叫我就叉D,或者XD,我名字的缩写。然后我是特赞科技的CTO,今天主要讲的是Rust在内容资产管理系统(DAM)中的应用。
我会先简单介绍一下我们这个产品里为什么用Rust,讲讲一些落地的情况。因为前面几位老师其实已经对AI相关的一些框架、性能等讲得比较细了,所以我这边会相对轻松一些,更多是分享应用和落地的情况。接着我会讲我们这个内容管理系统里AI到底在做什么,重点是内容处理部分。最后,我会分享我们在构建这个应用时前后端的技术栈,如何做到多端运行和跨平台的一致性体验,以及我们团队在Rust方向上的一些展望。
首先,什么是内容资产管理?内容资产管理的全称是Digital Asset Management(DAM),有时也叫Content Management。它解决了企业和个人拥有大量内容时如何管理和检索这些内容的问题。内容可以是营销素材、个人作品、灵感素材等。你需要一个系统去管理这些内容,还要能够检索它们。而检索的范围不仅仅是文件名或基础元数据,还包括内容的主体、图片中的文字、视频中的声音,甚至是更深层次的含义,比如情绪、场景等。我们需要对这些内容进行预处理,生成索引,才能更好地进行搜索。
管理这些内容不仅仅是存储文件本身,还有提取出来的各种信息(元数据)。这是一个内容管理系统的核心功能。比如,当我们要搜“极客风格的海报”时,系统不仅会搜索图片中的主体,还会检索背后深层次的信息。
我们公司叫特赞(Tezign),由Tech和Design组合而成。公司目前有两款产品:一款面向企业,另一款面向个人,主要是服务创作者的内容资产管理系统。我们公司的Rust开发团队约占1/10,主要集中在面向C端的DAM上。这个C端DAM的需求是非常个性化的,因此我们定位了三个核心:AI First、Local First 和 Cross-platform。Rust的选择主要是为了满足多端一致性的体验,以及性能和安全性的考虑。
说到为什么我们选择Rust,其实公司早期的技术栈主要是Python和Java,要推行Rust面临两个问题:一是技术栈转型复杂,二是Rust开发人员稀缺。我们目前在新系统中逐步使用Rust来替代老系统。我个人之前也是用Python和Node.js比较多,大概三年前开始接触Rust,觉得这门语言很好,所以决定采用它。
我们选择Rust的原因,除了前面提到的一致体验,还包括性能和安全性。管理企业和个人的内容资产时,数据量往往非常大,有些设计师可能拥有几百万的素材,这就要求系统能够高效并行处理这些内容。尤其是在端侧或本地运行时,性能尤为重要,这也是我们选择Rust的一个重要原因。
我们的内容管理系统本质上是一个多模态数据库,Rust在系统应用构建中的生态逐渐成熟,有很多现成的库可以用,这也是我们选用Rust的另一个原因。
接下来讲讲内容处理。我们把素材放入系统后,首先会做两件事:第一步是提取基础信息,比如文件大小、类型,主体、声音、文字等。第二步是使用大语言模型对素材进行深层次的解读,比如素材的情绪、风格等。提取的这些信息会和原文件一起打包存储,以便后续检索和分享。这样,当素材被分享时,解析出来的元数据也会一起打包,确保在不同平台上都能一致性地使用和搜索。
在内容处理的过程中,我们希望实现跨平台的体验,也就是说,视频和音频处理既能在本地运行,也能在云端运行。我们使用Rust的条件编译特性,为云端和本地提供一致的API。比如,视频处理使用FFmpeg时,我们可以编译出两个版本,一个是动态链接库的,一个是二进制的。本地更偏向于使用二进制文件,因为这样更稳定,云端则更适合动态链接库的方式。
在本地处理时,我们会打包一些本地命令行工具,比如FFmpeg,用来进行视频剪辑、音频提取、缩略图转换等操作。Rust的binding方式虽然可行,但有时会遇到动态链接库的问题,而二进制方式则更直接,但错误处理起来相对麻烦。
关于AI部分,我们使用了多种推理库,包括ONNX、TensorRT等。每个库都有各自的优缺点,比如Llama CPP虽然通用,但它是用C++写的,Rust很难通过binding直接使用。相比之下,TensorRT与PyTorch的结合比较好,功能也较为全面,但需要自己实现一些优化。
我们还对比了不同推理框架在CPU和GPU上的性能表现,发现有时GPU加速并不明显,主要是因为模型加载到显存的过程占用了大量时间。我们使用Kindle和Llama CPP进行推理时也发现,长文本的处理性能会有较大差异,因为Kindle没有内置的KV缓存,需要我们自己实现。
我想分享一下我们的技术栈。我们采用了一个多端技术栈,缩写为PRRTT,源于一个硅谷的明星项目Space Drive。它由Prisma、Rust、React、TypeScript 和 Tauri 组成,我们用这五样东西来构建整个系统。
我们使用了 Prisma,如果大家使用过 Node.js,应该会比较熟悉。Prisma 是一个非常优秀的数据库框架,提供了数据库迁移、ORM 等功能,并且这些功能都已经帮你封装好了,它本身是用 Rust 编写的。所以,Prisma 是一个非常好用的工具。
当我们使用 Rust 的时候,你需要先构建好数据库的 schema,然后生成数据库客户端的代码。这里有一个框架叫 Prisma Rust Client,它可以帮你生成数据库调用的代码,并且提供了良好的数据库操作体验,非常方便。
另一个我们使用的工具是 ISPC,它是一个服务端使用 Rust,前端使用 TypeScript 的 Type Safe 端到端框架,有点像 TRPC,整体的使用体验也不错。
接下来,我们主要做内容存储,采用了 OpenDAL,这是中文社区的 “漩涡大佬” 开发的一个项目,叫 Databend,它也是一个非常好用的工具。
回到前面提到的 PRTT,这个缩写来自于 Space Drive 项目的团队,他们在 README 中解释了为什么使用这样一个框架。Prisma 其实在这里起到了非常重要的作用,而 Space Drive 的核心开发者之一 Brandon Novac,在构建 Space Drive 时对 Prisma Rust Client 贡献了许多代码。
另外一个贡献者是 Oscar Bonham,他是 ISPC 核心贡献者之一,也是 Space Drive 的核心开发者之一。这两位开发者在 Prisma 和 ISPC 上贡献了大量代码。不过,Oscar 几个月前离开了 Space Drive 项目,可能会对项目的后续迭代产生一些影响,但目前的版本依然是可用的。
再说回 SPC 框架,它的使用体验有点类似于 TRPC。在服务端定义好接口后,前端可以生成对应的查询(query)和变更(mutation)代码,并在前端引用。比如,我创建了一个文件夹的接口,定义了一个 FilePathCreatePayload 类型,并在服务端定义了一个 mutation。前端则可以通过生成的类型进行类型检查,并使用 mutation 时确保参数和类型匹配,这样可以确保类型安全。
对于内容存储部分,我们大量使用了 OpenDAL。它支持很多种语言的绑定,以及多种存储类型。我们的需求是将内容存储在本地磁盘、网络磁盘(NAS)以及云存储(如对象存储和文件存储)中。因此,我们需要一个框架来统一处理这些存储方式。
OpenDAL 让本地文件存储变得非常简单。通常我们使用标准库的 std::fs 来读写文件,但如果用 OpenDAL,则可以使用它提供的 API 进行文件的读写操作。它的一个特点是能够以一种原生的方式操作本地存储接口,比如文件的读取和写入。
不过我们也遇到了一些无法用 OpenDAL 完成的场景。我们原本的设想是,用 OpenDAL 代替类似于 POSIX 文件系统的所有存储操作,但发现有些场景并不适合。例如,当我们使用 FFmpeg 或 Whisper 处理媒体文件时,它们生成的文件需要进行元数据的回写操作,这个过程需要标准 IO 流的寻址,而并不是所有存储系统都支持这种寻址方式。只有本地磁盘支持这种操作,而 OpenDAL 在这些场景下无法处理。因此,我们只能在本地磁盘上完成这些操作,然后将处理结果通过 OpenDAL 存储到目标存储介质中。
除此之外,我们大部分情况下还是使用 OpenDAL。我们有两层架构:在后端,我们写了一个派生宏,给所有需要 IO 操作的结构体注入了存储 IO 的方法,这样它就可以像 std::fs 那样进行文件操作;在客户端,我们使用了 Tauri 的特性,定义了一个自定义协议 storage:// 来访问不同存储介质上的文件,从而实现了多端一致的体验。
Tauri 是一个跨平台的应用框架,它允许你使用一套代码生成桌面端应用,如 Windows、Linux、Mac 应用。它和 React Native 不同,Tauri 的客户端 UI 是基于网页的,外层框架是 Rust 编写的。这对我们来说非常合适,因为我们希望我们的 UI 可以兼容网页端、桌面端和移动端。
在 Tauri 中,我们实现了一个自定义协议,在访问资源时,使用 storage:// 协议来对应云端、本地或网络磁盘中的文件。这样可以根据存储类型动态地获取内容并显示结果。
接下来展示一些效果。可以扫描二维码观看我们实现的一个简单的 demo。视频展示了我们系统的操作界面,所有拖入的素材都会被处理提取描述信息,并显示在右侧。同时,还有一个 Jobs 列表,展示了不同素材的处理任务。我们还使用 Whisper.cpp 进行语音转文本。比如,我们可以搜索 “室内场景”,系统会根据提取的描述和元数据进行匹配,返回相关内容。
最后总结一下我们构建的系统架构。我们分为四个部分:左边是内容处理的微服务,包含 AI 和非 AI 的处理模块;中间是 Content Lake,即我们的内容数据库;右边是内容分发网络。目前,内容处理微服务大部分是用 Rust 重构的,占比超过 80%;存储部分约有一半是用 Rust 实现的,依赖的是 OpenDAL;内容分发网络和数据库的部分刚刚开始构建。
在回答观众提问时,我提到,我们使用 Quadrant 向量数据库和 SQLite 来处理本地的需求,这套组合可以处理数百万级的素材。对于更大规模的素材量(千万到亿级),我们会在云端使用 Accuren 和 MySQL,并结合 ElasticSearch 进行全文检索。
我们计划在未来构建一个多模态数据库,优化性能目标提升 10~20 倍,支持更大规模的素材处理(10亿到20亿素材)。
14. GreptimeDB Edge 基于Rust的嵌入式时序数据库 - 杨颖文
大家好,今天由我为大家带来关于GreptimeDB Edge版本的分享。GreptimeDB Edge是一个基于Rust的嵌入式时序数据库。本次分享的主要内容包括GreptimeDB的整体架构、其在边缘设备端的应用挑战、以及我们在实际案例中所做的一些优化工作,最后介绍GreptimeDB Edge的边缘一体化解决方案。
分享结构
我今天的讲稿大致分为以下几个部分:
时序数据库的价值与挑战
我们将首先讨论时序数据库的价值,特别是在边缘端设备中的应用场景。然后,我会介绍实现这一数据库的主要挑战。GreptimeDB的整体架构
我会简要介绍GreptimeDB的存储引擎,这是后续优化工作的基础。新能源车企的边缘端数据库优化案例
我们会结合在新能源汽车行业的落地案例,详细讲解我们在边缘端设备上的优化经验。GreptimeDB Edge的边缘一体化解决方案
最后,我会总结GreptimeDB Edge在边缘设备中的整体解决方案,以及嵌入式时序数据库在此方案中的角色。
时序数据库的价值
时序数据库的核心价值在于对边缘设备产生的数据进行存储和分析。以新能源汽车为例,车内有一个名为CAN总线的通信网络,用来连接和传输车内各个元部件的通信数据。通过存储这些数据,车企可以在后期对车辆进行故障排查和升级优化。
传统的数据存储方式是将CAN总线的数据以原始文件的形式存储。这种方式虽然简单,但存在两个问题:
磁盘空间占用大
原始文件格式的数据会占用大量存储空间。无法直接分析
数据只能存储,无法对其进行实时分析。
引入时序数据库后,这些问题得以解决。通过数据库的分析能力,部分故障排查和诊断工作可以在车端完成,而不必完全依赖云端。同时,数据库还可以对数据进行压缩存储,减少磁盘空间占用。
边缘设备的存储挑战
在边缘设备(如车载设备)上实现数据库时,面临着诸多挑战:
存储空间有限
边缘设备的存储空间通常很小,可能只有数百GB,而且还必须为其他应用预留存储空间。因此,必须通过压缩和优化,充分利用有限的存储资源。传输成本高
边缘设备必须将数据上传到云端进行进一步的分析,而网络流量是需要付费的。通过数据库压缩传输数据,可以有效降低传输成本。敏感数据的本地存储
有些用户数据较为敏感,不适合传输到云端。在这种情况下,数据库需要在本地进行存储和管理。
实现难度
在边缘端部署数据库的难点在于设备的资源限制:
计算资源有限
边缘设备的CPU、内存等硬件资源是固定的,无法进行扩展。数据库必须在有限的资源下高效运行,避免占用过多CPU和内存,影响其他应用的正常运行。多样化的使用场景
汽车的运行状态多样化,如静止、行驶、开启自动驾驶等,不同状态下的数据量和负载差异巨大,要求数据库能够适应变化。
GreptimeDB的存储引擎架构
GreptimeDB的核心架构基于经典的LSM-Tree(Log-Structured Merge Tree)。其主要组件包括:
- MemTable:内存中的写入缓冲区,暂存写入的数据。
- WAL (Write-Ahead Log):用于记录内存中的数据变化,防止数据丢失。
- SSTable:持久化存储的数据文件,内存数据在特定条件下会被转换成紧凑的SSTable格式。
- Manifest:维护数据库的文件元数据,描述数据库的结构和状态。
边缘设备上的优化工作
在将GreptimeDB部署到边缘设备时,我们针对CPU、内存、闪存等资源进行了大量优化。
CPU资源占用优化
我们使用了内置的分析工具来监测CPU占用,发现数据库的大部分时间耗费在协议解析和数据写入上。通过优化协议解析和数据处理流程,我们大幅降低了CPU的消耗。
例如,我们启用了更轻量的通信协议,并减少了不必要的任务重叠。此外,我们通过限流机制,平滑地将数据写入磁盘,避免CPU峰值过高。
内存优化
为了减少内存占用,我们对 MemTable 的结构进行了优化。通过分析内存分配模式,我们对低基数列启用了字典编码,并选择了LZ4作为主要的压缩算法,以在压缩率和CPU占用之间取得平衡。
闪存IO优化
闪存的寿命有限,因此我们在数据写入时对IO进行了优化。我们通过减少数据flush的频率,并采用更高效的编码方式,降低了对闪存的写入量,从而延长了设备的使用寿命。
协议优化
在边缘设备中,SDK和数据库通常部署在同一台设备上。因此,我们实现了共享内存的通信机制,绕过了传统的网络协议传输,直接在SDK端生成数据库需要的内存数据结构,这样大大减少了协议解析的开销。
实际效果
经过优化后,我们在高通平台上对GreptimeDB进行了测试,结果显示其性能明显优于基准数据库。在限制写入负载的情况下,GreptimeDB的CPU使用率更低,整体性能更高。
未来工作
虽然我们已经完成了大量优化工作,但在实际的边缘设备中,负载变化极大,因此我们仍在探索动态的限流机制,以进一步控制CPU占用。此外,我们还与学术机构合作,研究如何在Rust的异步接口中引入更多的动态优化手段。
通过一系列的优化,我们成功将GreptimeDB部署到资源受限的边缘设备中,并使其在有限的资源下稳定高效地运行。GreptimeDB Edge不仅能够有效存储和分析时序数据,还能通过协议和存储优化,显著降低CPU、内存和闪存的占用,为边缘计算提供了强有力的支持。
我们自己提供了一些分析内存占用的工具,可以帮助我们分析在运行过程中内存分配的情况。通过这些工具,我们可以分析C层的日志包,了解数据的流向和处理过程。
在使用METABLE时,我们发现之前的老版本结构存在一些问题。比如,早期版本的膨胀效应比较明显,尤其是在某些特定的时间点,数据的处理效率较低。基于该问题,我们结合边缘端的数据特征,重新实现了一个新的时间序列结构。这个结构利用了时间序列的特点:每一个时间线可以看作是一个设备在特定时间点不断产生的数据。数据是随时间递增、连续有序的,基于这个特性,我们采用了一种更紧凑的结构来存储数据,类似线性结构。
在数据写入时,数据首先进入一个active buffer,当达到一定数量后,我们会对数据进行排序,并将其转化为一个open buffer。最后,数据会通过压缩编码写入到SSD文件中。经过这样的优化,在825度的品牌测试中,我们的CPU利用率表现优异,达到了3.2G的分数。同时,在IO使用方面,我们也做了优化,尤其是针对闪存设备。前面提到,WAL(Write-Ahead Log)与数据写入速度成正比,数据量越大,IO开销越高。幸运的是,经过优化后的数据存储结构采用了紧凑编码,极大降低了对IO的占用。
在合并操作方面,除了合并操作本身带来的一些小开销外,整体效率得到了显著提升。对于manifest文件(元数据),由于文件本身较小,我们可以通过合理设计减少其产生的开销。至于compression(压缩),因为边缘设备的数据量不是非常大,我们不需要频繁进行压缩操作,直接将数据上传即可。这样一来,compression可以在终端设备上关闭,不会影响整体使用体验。
另外,我们对WAL做了一些优化,提供了按表开启或关闭WAL日志的功能。对于数据量大且不那么重要的表,我们可以选择不写日志;而对于重要的数据和用户关心的数据,我们则会开启WAL日志,确保系统在断电时的一致性。其实大多数边缘设备在正常情况下是保持通电状态的,断电的异常情况较少发生,即便不写WAL日志,也能够被接受。
此外,我们还实现了优雅关闭机制,确保在系统退出时,数据能被安全地刷入存储设备。由于我们对数据进行了压缩处理,相同的数据占用的存储空间也相对较小。例如,在进行1000万条数据测试时,经过压缩后的数据占用87MB,而传统的存储方式可能需要近1GB。这种存储方式极大减少了对存储设备的消耗。
我们还在安卓平台上探索了基于匿名共享内存的通信机制。通过共享内存的方式,避免了传统的文件映射操作,减少了IO的使用。在安卓平台上,我们采用了ashmem共享内存方案,并通过JNI传递共享内存的文件描述符,从而实现了高效的通信流程。
接下来,我简单介绍一下我们在Rust和C++之间的技术选型经验。最早我们是用C++实现的,但在交付过程中遇到了很多问题。比如,如何交付源码依赖?不同用户有不同的构建系统,这导致了各种兼容性问题。用户可能不愿意将我们的代码与他们的代码一起编译,而且C++的依赖管理也非常繁琐。因此,我们最终决定用Rust重写SDK的核心部分。通过Rust的Cargo工具进行依赖管理和编译,解决了很多问题。Rust的内存安全特性也帮助我们避免了像内存泄漏、双重释放这样的编码问题。最终,我们通过一个简单的C接口,将核心功能封装在Rust中,并为用户提供了简易的C++接口。
在车端方案方面,我们的边缘设备相当于一个分布式系统的METABLE,负责将车端的写入数据缓存并以紧凑格式上传到云端,便于后续的长期数据分析。由于车端和云端共享一套代码,数据格式一致,数据的导入和使用更加高效。
最后,我想简单介绍一下我们公司。我们专注于互联网、新能源汽车和可观测领域,提供数据库解决方案。我们的核心数据库项目是开源的,大家可以在GitHub上找到并贡献代码,欢迎大家尝试使用我们的产品。
今天的分享就到这里,谢谢大家。接下来是提问环节。
提问环节:
提问1:
老师,您提到数据库的插入性能,那么相比传统数据库的写入性能如何?尤其是在边缘设备上,插入和查询并发时性能表现如何?另外,数据库的分析能力如何,比如支持哪些聚合函数或分布函数?
回答1:
感谢你的提问。关于插入性能和查询并发性能,我们在公众号上有详细的性能报告,你可以搜索”Greptime”查看。由于时间有限,无法逐一回答所有问题,欢迎会后联系我深入探讨。
15. 以 Rust 构筑云计算的新引擎 - 郑予彬
大家好,我是来自亚马逊云科技的郑予彬,现任亚马逊云科技开发者关系团队的成员,负责相关工作。首先,我想问一下在座的各位,有多少人使用过亚马逊云科技的云服务?麻烦举个手。看起来还是有不少人使用过。第二个问题是,有多少人在云上进行开发工作?也请举一下手。好的,看来云上的开发工作也做得不少。
今天我分享的主题是“以 Rust 构建云计算的新引擎”。其实,虽然我有多年的编程经验,但在 Rust 方面,我也算是一个初学者。但为什么要在这里分享这个主题呢?因为 Rust 对于亚马逊科技,特别是 AWS 来说,至关重要。我给大家一些背景信息——我们大多数的服务,包括底层的虚拟系统、服务系统以及调度系统,都是基于 Rust 开发的。而且,我们也是 Rust 基金会的核心会员。
那么,为什么 AWS 如此重视 Rust 的研发?为什么我们内部有如此多的明星服务,到今天还基于 Rust 进行性能和安全性的更新?我相信这与 Rust 语言本身的一些特性有紧密的关系,比如它的高性能驱动和严格的安全要求。这些特性与云计算的需求是紧密相连的。Rust 在性能和安全性方面能够为云上的构建者提供双重引擎的加持。
Rust 已经成就了 AWS 的许多核心服务。我们的研发团队也基于 Rust 开发了许多开源项目,并通过不断翻新这些项目,交付给外部用户。
今天的分享内容有几个部分。首先,我不会详细介绍我们具体的开源项目实践,因为我觉得那不是今天的重点。我的主要目的是想和大家分享 Rust 技术为什么和云结合起来可以实现双倍的迭代,为什么它能够为云上的构建者提供更高的性能和安全性。其次,我会分享亚马逊云科技如何通过 Rust 为云上的构建者提供服务,Rust 又能带来哪些独特的体验。最后,我会简单提到我们在云上基于 Rust 的一些应用案例。
首先,谈谈 Rust 语言的一些优势。我有个小问题:在座有超过三年使用 Rust 编程经验的朋友吗?请举个手。看起来还是有不少人。那么,有没有使用 Rust 少于一年,或者正在学习 Rust 的朋友呢?嗯,大多数人都在学习中。这也是正常的,因为今天 KOS 上也有很多人提到,Rust 的学习曲线较长,但大家不要放弃。一旦掌握了它,你将获得其他语言难以提供的“超能力”。这种能力其实是一种加速度。
在大多数编程语言中,开发者往往追求生态系统的完善、用户体验的友好性、底层硬件的控制力度、安全性和自动化等特性。很多语言在底层控制和安全性上往往难以兼顾。比如,C++ 语言可以直接控制内存,但交互体验可能较差,编译过程中的细颗粒度配置也可能导致安全隐患。而 Python 语言虽然在机器学习等领域广泛应用,但它的底层实现往往并不透明。
相比之下,亚马逊云科技的许多明星服务,比如 Lambda、S3 以及 CodeBuild,底层都是基于 Rust 开发的。Rust 的优势在于没有传统的垃圾回收机制,也没有运行时带来的内存管理开销。这使得它在高性能上表现出色。同时,Rust 的所有权系统在编译时对内存进行严格检查,确保了底层的安全性。
正因为这些优势,越来越多的云厂商和开发者开始尝试使用 Rust,尤其是在云原生应用中。今天的演讲中,大家多次强调了 Rust 虽然学习门槛较高,但它在新的开发环境中,尤其是 AI 时代和云上开发中,能够帮助开发者更专注于创新。
接下来,我展示一段简单的代码。这段代码是用 Rust 实现的求和函数。它没有使用裸指针,这在安全性上已经超越了很多传统语言。Rust 中使用的惰性迭代器,也不会在未使用时占用过多内存。这与云原生的理念非常契合。大家知道,亚马逊云资源的最大特点是弹性扩展和按需分配,比如 Lambda 和 S3 的事件驱动机制,它们在事件到来时分配资源,事件结束后自动回收资源。这样的机制有助于节省资源消耗,提升性能。
这段代码虽然简单,但它并不完善,尤其没有涉及多线程技术。接下来展示的另一段代码引入了一些新的概念,比如 Rayon 库,它可以自动处理超线程的创建、内存分配和任务分配。这在传统语言中需要大量代码实现,而在 Rust 中只需一个库即可解决。此外,我们使用的 parallel iterator 可以更加高效地进行并行遍历,并且结合惰性属性,更好地控制内存分配和资源消耗。
回到云计算的主题,云平台的底层计算资源非常丰富。我们会根据不同的使用场景,提供不同的计算资源,比如针对推理、培训、密集 IO 的资源。开发者可以基于不同的计算芯片或资源,选择合适的语言进行应用开发和资源配置。与传统的数据中心相比,云平台提供了更多高性价比的选择。你不需要购买各种硬件设备,只需选择合适的云资源即可。
最后,回到 Rust 与云计算的结合。AWS 非常喜欢 Rust,尤其是在底层基础架构和明星服务中,我们大量使用 Rust 进行开发。每年我们也会基于自己的项目,帮助 Rust 学习者和开源项目实现他们的创新。
Rust 与 AWS 的结合不仅在技术上高度契合,文化上也非常吻合。安全性是亚马逊的首要任务。我们的安全文化强调,安全凌驾于一切之上。无论是追求高性能还是快速上线,所有这些都必须基于安全性。亚马逊的开发模式也很独特,我们采用“双披萨团队”,即每个团队不超过 14 人。每个团队中都有一名安全员,负责全程监控项目的安全性。
可以说,Rust 在 AWS 中的广泛应用,很大程度上是因为它的安全性和高性能能够满足我们的严格要求。内存安全是长期讨论的话题,许多系统崩溃都与此相关。对于云计算供应商来说,内存安全尤为重要。
在很多应用中,内存安全问题是非常普遍存在的,约有70%的应用都会遇到这一问题。对于云供应商来说,内存安全问题显得尤为重要。
我们知道,内存安全问题对互联网的核心平台来说至关重要,特别是在提供交付服务时。如果内存安全问题未能得到妥善处理,不仅仅是你的某个服务会出现安全隐患,整个应用系统都有可能面临崩溃的风险,甚至会带来致命的后果。为了帮助开发者解决这些问题,我们在技术博客中提供了一些最佳实践和解决方案,具体讲解如何在云上进行内存安全方面的实践。
接下来,我们来谈谈 Rust 和亚马逊云科技的关系。首先是高性能。对于亚马逊云科技来说,安全是一个前提和基础。然而,对于很多组织来说,高性能的业务交付、能够快速为最终客户提供价值和体验,是他们追求的核心目标。因此,高性能也是亚马逊云科技非常重视并交付的服务之一。这也是为什么亚马逊云科技选择与 Rust 合作,基于 Rust 提供服务。
无服务器架构(Serverless)一直是云原生架构中的重要话题。在 AI 热点出现之前,无服务器架构一直是讨论的核心,因为它被认为是真正的纯云原生架构,能很好地体现云计算的价值。无服务器架构中的计算是事件驱动型的。当事件发生时,系统会迅速分配底层的计算资源,并与云上70%或更多的服务进行深度集成,例如存储服务、数据库服务、API 调用服务、消息队列服务等。当事件结束后,系统会自动释放资源,实现真正的弹性扩展。无服务器架构的计费方式与传统的计算资源消费不同,它是按事件消耗进行计费的。因此,我们认为无服务器架构是云原生架构的精髓,也是高性能的体现。
值得一提的是,AWS Lambda 已经迎来了十周年,而 Lambda 是基于 Rust 开发的。如今,我们仍在不断更新基于 Rust 的高性能与安全性。很多 Rust 的性能测试,特别是冷启动和热启动的对比,都是基于无服务器架构完成的。通过这些测试,我们可以看到不同语言的运行时性能对比。
我们来看看一个基于 Rust 运行在 AWS Lambda 上的代码示例。这段代码是一个典型的 Lambda 应用,使用 Rust 编写的 HTTP 服务,可以输出 JSON 格式的数据,并通过 Lambda 运行。首先,我们引入了 lambda-http 库,这使得我们能够轻松地将 Rust 应用部署到 Lambda 上。此外,代码还引入了其他库,比如用于处理路由请求的库、序列化和反序列化 JSON 格式数据的库等。Rust 生态系统的丰富性以及这些库的强大抽象功能,极大地简化了代码的配置和描述工作,提高了代码的可复用性和调用效率。
为什么使用 Rust 和 Lambda?这是因为 Lambda 的事件驱动方式与 Rust 的设计理念非常契合。Lambda 使用事件驱动的方式分配资源,而 Rust 则通过抽象层简化了底层实现和资源配置。这使得在成本和高性能上,Rust 与 Lambda 的结合发挥了极大的优势。
在这段代码中,index 函数返回了一个 JSON 对象,并且 greet 函数接受了一些路由参数。main 函数定义了两个路由,最后使用 run 启动了 web 应用。可以看到,index、greet 和 main 函数都是异步的。Rust 对异步编程的支持,使得它特别适合处理 IO 密集型任务和高并发场景,而这是与 Lambda 无缝契合的。
接下来是一些具体的操作示例,通过 index 返回 JSON 格式数据,并且展示了 Rust 的异步编程在 Lambda 上的高效性。Rust 对于异步编程的支持,使得它在 IO 密集型任务和高并发任务中表现出色,而 Lambda 的事件驱动模型与之完美契合。
我们还进行了许多性能测试,包括冷启动和热启动的对比。在冷启动时,Rust 的表现非常出色,远远优于其他语言。虽然某些语言(如 Kotlin)在特定配置下表现更好,但这是由于配置的差异,比如 Kotlin 使用了更大的内存(2GB),而 Rust 使用的是默认的 128MB 内存。即便如此,Rust 在热启动的表现依然是无可挑剔的。
最后,为什么亚马逊云科技如此青睐 Rust?这是因为 Rust 的安全性、高性能以及与无服务器架构的契合,使得它成为 AWS 服务的核心语言之一。AWS 的许多基础设施服务,如 Lambda、Firecracker、Bottlerocket 等,都是基于 Rust 开发的。
我们还为开发者提供了 Rust SDK,帮助大家更方便地在云上构建应用。无论你是 Rust 的新手还是资深开发者,AWS 提供的 SDK 都可以大大简化开发工作,并且这些 SDK 都是免费的,大家可以在 AWS 的官网上下载使用。
总之,Rust 与 AWS 的结合无疑能够帮助开发者构建高性能、安全、可扩展的云原生应用。我们热切期待与更多开发者合作,共同推动 Rust 和云计算技术的发展。
16.基于 Rust 打造高效且可靠的多模态数据库 - 徐天
接下来我们进入下一个议题,由来自风清科技的查询引擎研究专家徐天老师为我们带来分享。
大家好,我叫徐天,来自风清科技。我今天给大家带来的主题是“基于 Rust 打造高效且可靠的多模态数据库”。
首先简单介绍一下自己,我目前在风清科技负责图数据库查询引擎的研发工作,之前也曾在星环科技工作,长期从事数据库和大数据领域的查询优化相关工作。今天,我将向大家介绍如何利用 Rust 实现高效且可靠的图数据库查询引擎。
一、什么是多模态数据库?
多模态数据库能够支持多种数据模型,帮助解决复杂的数据管理需求。我们认为,多模态数据库可以为包括大模型等复杂数据场景提供更加便捷的计算和存储能力。在多模态数据库中,我们以图数据库作为核心载体。今天的主题主要围绕图数据库的查询优化来展开。
二、图数据库的优势
相较于关系型数据库,图数据库主要解决的是复杂关联关系的存储和查询问题。例如,社交关系、银行客户关系等场景中,实体之间往往存在着复杂的关联关系,而图数据库能够更好地描述和查询这些复杂关系。
图数据库的查询语言通常不同于关系型数据库的 SQL。图数据库的查询语言包括 Cypher、GQL 等标准,我们公司主要实现了 Cypher,并且在此基础上进行了优化。
三、图数据库查询优化的示例
我们来看一个图数据库中的查询示例。例如,指定一个人,找到与他有三度关系的朋友,然后再找到这些朋友所在的城市、学校和公司。这是一个典型的多跳查询。如果使用传统的关系型数据库,查询语句会非常复杂,往往需要写多个 JOIN 操作。而在图数据库中,查询语句则可以更加简洁。
此外,图数据库的查询语言能够更好地处理环路问题(即实体之间的双向关系),并且可以在查询中添加过滤条件。例如,在查询某人的工作和学习地点时,如果这两者不在同一个城市,我们可以使用过滤条件来排除不符合的结果。
四、基于 Rust 实现图数据库查询引擎
接下来,我将介绍我们如何使用 Rust 来实现图数据库查询引擎。
首先,为什么选择 Rust?Rust 兼具高性能和内存安全的特性,特别适合构建数据库这样复杂的系统。在选择 Rust 之前,我们也考虑过它的生态和学习曲线。经过调研和实际开发,我们发现 Rust 生态已经足够成熟,能够支持我们构建高效的查询引擎。至于学习曲线,我个人的感受是,Rust 的上手难度并不高,比 Java、Scala 等语言稍微晚两到三周左右。
五、查询优化的主要步骤
查询优化主要分为三个步骤:
解析器的实现
我们使用了 Rust 的nom库来实现解析器。首先,通过词法分析将查询语句拆分为一个个 token(单词),然后通过语法分析将这些 token 组成一个抽象语法树(AST)。nom库的优势在于它能够很好地支持图查询语法的解析。执行计划的生成和优化
在解析完查询语句后,我们需要生成一个执行计划,并对其进行优化。优化器的工作是减少不必要的计算,选择最优的执行路径,以提高查询效率。执行层的优化
在执行层面,我们使用 Rust 实现了多个算子(operators),这些算子能够高效地处理图数据库中的各种查询操作。Rust 的并发处理能力使得我们可以充分利用多核 CPU 来提升查询性能。
六、总结
总的来说,Rust 是一个非常适合构建高性能数据库系统的语言。通过使用 Rust,我们实现了一个高效且可靠的图数据库查询引擎。未来,我们会继续优化查询引擎的性能,并且扩展更多的功能,以支持更加复杂的数据场景。
一开始解析的情况下,它是不会去判断上下文关系。第二个就是语义问题,解析出来生成的对象必须语义明确。你不能说这个对象就代表 A 或者 B,这就是 AST(抽象语法树)。
接下来我介绍一下怎么去做解析,以及如何构建查询计划。解析主要分为两步:生成 AST(抽象语法树)和转换逻辑执行计划。AST 是一种中间层,如果你了解过编译器原理,可能会比较清楚这一步的操作。通过 AST,我们可以将查询语句逐步转化为逻辑执行计划,然后进一步转化为物理执行计划。
逻辑执行计划其实就是对 AST 的一个翻译。在这个过程中,我们会结合上下文信息,进行一些校验。例如,从原数据信息中提取 label(标签)等内容,进行类型校验、权限校验等操作。比如说,用户是否有权限进行查询或者修改,语法边界是否正确等,这些都会在逻辑执行计划中进行处理。
我们再回顾一下之前提到的例子,比如指定一个人,进行三跳查询,关联他的所在城市、工作和学习地点。每一次关联,相当于执行一个 JOIN 操作。执行计划中,三次关联会对应三个 JOIN 操作。
这里有个特殊的点,比如说某个人的名字叫做 Andy,那么我们能不能将这三次关联中的某一个操作推到右边?我们可以通过这样的优化,减少右边的计算量。通过下推过滤条件,减少 JOIN 操作中的数据量。以此方式,我们可以把左边的查询结果实时传递给右边,进行过滤操作,从而减少整体的计算量。
刚刚提到的优化方法,我们可以通过遍历 AST 树,发现可以优化的节点,然后基于这些优化点,进行 rewrite(重写)操作。我们的优化器设计采用自顶向下的递归方式,在遍历树的过程中,逐步发现可以优化的部分,并进行替换操作。我们将这些优化规则写成规则集,在遍历时逐一检查是否符合优化条件,并执行优化动作。
刚才我们提到了 filter 下推(过滤条件下推),它可以有效减少 JOIN 中的数据量。进一步优化可以通过传递左边的查询结果到右边,减少不必要的数据传递。这种方式称为 apply(应用)操作,它类似于嵌套循环 JOIN,将左边的结果逐条传递给右边进行计算。
在图数据库中,常见的优化技术还包括 Hash Join 或者 Bloom Filter(布隆过滤器),这些技术可以实时地将左边的结果传递给右边进行过滤,从而进一步减少计算量。如果这些优化还不够,我们可以直接把左边的结果传递给右边,实现 apply 操作。
apply 操作的实现方式是,先将左边的数据提取出来,放入上下文信息中,然后在计算右边数据时,使用这些上下文信息进行计算。我们在实现过程中,通过执行层的支持,构建了一个带有环形结构的执行器,将左边的结果实时传递给右边,从而实现高效的查询计算。
这种环形结构可以有效减少右边的计算压力,因为右边不需要再去处理大量数据,只需要处理左边传递过来的少量数据。最后,我们将结果进行合并,这样可以减少多余的计算步骤,提高查询效率。
当然,这种优化也有一定的限制,比如当数据量较大时,链式调度可能会带来性能瓶颈。不过,在数据量较小的情况下,这种优化能够大幅提升查询性能。
接下来,我们讨论如何进行进一步优化。例如,我们可以通过去关联化(de-correlation)优化,将关联查询转化为更加高效的直线型查询。这种优化并不是总是适用的,但在某些特定条件下,可以大幅提升性能。例如,当后续的查询语句中包含聚合操作或去重操作时,去关联化能够减少中间结果的计算步骤。
我们参考了一些学术论文,设计了相应的优化规则。最终,物理执行计划会通过 RBO(基于规则的优化)和 CBO(基于成本的优化)确定最优的执行计划树,然后选择合适的算子和算法来执行。
物理执行计划生成后,我们会计算每个算子的输入输出,并根据这些信息确定算子的位置和参数。最后生成的执行计划会经过执行器来执行。
在执行层面,我们采用了多线程模型,并设计了多种算子来处理具体的查询任务。我们的并发模型能够有效地处理多线程任务,并保证查询的高效执行。
关于缓存引擎,我们实现了多种缓存策略,包括拓扑缓存和属性缓存。拓扑缓存主要缓存图中的点和边信息,属性缓存则缓存实体的属性信息。此外,我们还实现了事务的 MVCC 缓存和索引缓存。
最后总结一下,我们在一年时间内,通过 Rust 实现了一个高效且可靠的多模态数据库系统。在性能和功能上,我们达到了业内一线水平。这得益于 Rust 的性能优势、内存安全性以及丰富的生态系统。同时,也感谢各位同行的博客和分享,降低了我们的开发门槛。
我们还在持续进行性能优化,未来计划基于列存进一步提升查询性能。再次感谢大家的聆听,有什么问题欢迎提问。
提问环节:
观众 1:最后提到的 POS 系统中,有没有遇到什么坑点?为什么没有选择其他系统如 Auction?
徐天:我们在调研时发现 POS 的性能表现更好,尽管我们也遇到了一些坑,但这些问题大多已经有解决方案。不过 POS 的维护者可能没有足够的时间来处理所有问题,所以我们考虑进行二次开发来解决这些问题。
观众 2:关于图数据库的存储结构,具体是如何实现的?在底层是如何存储实体和边的?
徐天:我们的图数据库将点和边存储为一个集合,每条边都存储一个时间戳,用于表示两个实体之间的关系。对于复杂的关系,图数据库会通过缓存引擎进行优化,提升查询性能。不过,存储层仍然是我们近期需要进一步优化的部分。
这总结的太敷衍了..
16.基于 Rust 打造高效且可靠的多模态数据库-徐天
观看视频
下一个议题是来自于枫清科技(Fabarta)查询引擎研究专家徐天老师的演讲。接下来有请徐天老师为我们带来关于 Rust 实现高效图数据库查询的内容。
演讲者自我介绍
大家好,我叫徐天,来自枫清科技(Fabarta),目前负责公司图数据库查询引擎的研发工作。我们的公司专注于为企业提供自媒体平台的解决方案。我个人主要研究数据库查询引擎及其优化方向,曾就职于星环科技,现已从 Scala 转向 Rust,热爱 Rust 和数据库技术。
多模态数据库的背景
在数据驱动的时代,多模态数据库能够支持多种数据模型,解决复杂的数据管理需求。我们相信多模态数据库不仅能够为大模型等提供便捷的计算和存储支持,还能在企业级别的应用中展现出强大的性能。我们选择以图数据库为多模态数据库的核心载体,今天我将主要分享如何实现高效的图数据库查询。
图数据库的定义与优势
相较于关系型数据库,图数据库主要解决的是复杂的关联关系问题。比如社交网络中的关系、银行客户之间的关联等。图数据库的优势在于它能够更好地描述实体之间的复杂关系,并提供更高效的查询能力。
图数据库的查询语言包括 SQL、Cypher、Gremlin 和 GQL,其中 GQL 是最近刚推出的标准。我们公司实现了 Cypher,并通过 Rust 进一步优化了图数据库的查询性能。
图数据库的查询示例
图数据库能够处理复杂的关联查询,比如某人的朋友、朋友的朋友及其所在的城市。这种多跳查询在关系型数据库中需要写大量的嵌套查询,而在图数据库中,可以使用更简洁的语法直接实现。图数据库的查询还可以避免环的出现,并且能够高效地处理多跳关联关系。
Rust 在数据库中的应用
接下来我们讨论一下为什么选择 Rust 来实现图数据库查询。首先,Rust 兼具高性能和内存安全,并且有良好的并发处理能力。我们选择 Rust 时,主要考虑了它的生态系统和学习曲线。
虽然最初我们担心 Rust 的学习难度,尤其是针对一些之前使用 C++ 和 Java 的开发者,但实际经验表明,Rust 的入门学习时间仅比 Python 或 Java 慢两到三周。Rust 的生态已经足够成熟,能够支撑我们实现一个高效的查询引擎。
查询优化的实现
图数据库的查询优化分为三个部分:
解析
我们使用 Logos 词法分析器库来进行词法解析,并使用 LALR 来生成抽象语法树(AST)。虽然 Rust 的某些解析库不支持定制化的需求,但 Logos 表现出了较好的性能。逻辑执行计划的优化
逻辑执行计划是对 AST 的翻译,这一步会对上下文信息进行校验,并从原数据信息中提取标签和类型等信息。我们通过过滤条件的下推优化来减少中间步骤的计算量,从而提高查询效率。物理执行计划的生成
物理执行计划最终决定了每个算子的执行方式。我们通过分析数据的输入输出,选择合适的物理算子,并进行并行化优化。
算子与并发模型
我们实现了一种带有环的执行器模型,允许左边的数据传递到右边进行计算。Rust 的并发模型使得我们能够实现高效的计算调度,并通过缓存机制进一步提升查询性能。
我们使用了模板化的缓存引擎,主要包括错误缓存、事务的 MVCC 缓存以及索引缓存等。
总结
在短短一年时间内,我们通过 Rust 实现了一个高效的图数据库查询引擎,不论在功能上还是性能上都达到了业界一流水平。Rust 的性能优势、内存安全和强大的生态系统为我们的开发提供了很大帮助。我们还参考了许多同行的经验,尤其是在 Rust 社区的分享中获得了很多启发。
最后,我们还在持续优化列存储的性能,未来将继续探索更多的优化空间。谢谢大家!
提问环节
问题 1: 您提到的 POS 在使用时有没有遇到什么坑?为什么没有选择 Auton?
回答: 我们在调研时发现 POS 的性能表现更好,不过确实遇到了一些问题。此外,POS 的 issue 数量较多,官方处理速度较慢,因此我们可能会考虑进行二次开发来解决这些问题。
问题 2: 图数据库存储到 KV 层时是如何编码的?
回答: 我们的存储是点和边重集等一。每一条边都会存一个唯一的值,类似于时间戳的方式进行存储。对于复杂的关系,我们会引入缓存引擎来优化查询性能,尤其是在查询具体属性时,缓存能够极大地提升性能。
17.基于 SIMD的高性能 JSON库sonic-rs-刘强
接下来的时间我们将交给字节跳动的研发工程师刘强,刘老师。刘老师您好,您在吗?
刘强:大家下午好!我是来自字节跳动的 Rust 开发工程师刘强。我主要的开发工作偏向于节省库的开发。今天我将给大家介绍一个基于 SIMD 优化的高性能 JSON 库——索尼卡S。
介绍背景
首先,我们为什么要造一个新的 JSON 序列化/反序列化库?大家可能会觉得 JSON 序列化库已经很多了,比如 C++ 社区中的 RapidJSON 等等。然而,之所以我们决定重新造一个 JSON 库,主要是基于以下几个原因:
业务需求:在字节跳动的内部微服务体系中,有大量的 JSON 序列化和反序列化需求。而这些 JSON 操作已经成为微服务性能的瓶颈,带来了较大的性能开销。
技术迁移:我们有很多服务是从 Go 迁移到 Rust 的。在 Go 中,我们使用了
SonicaGo这个高效的 JSON 库。然而,当我们尝试将其迁移到 Rust 时,发现现有的 JSON 库无法在性能上达到SonicaGo的水平。语言差异:Go 和 Rust 在处理 JSON 时的方式存在差异,特别是对接上的一些要求不尽相同。因此,为了解决性能问题和语言差异,我们决定开发一个新的 Rust JSON 库,即 索尼卡S。
索尼卡S 特点
我们开发的这个 JSON 库具备以下几个特点:
高性能:基于 SIMD(Single Instruction Multiple Data)优化,这是一个高性能的 JSON 序列化/反序列化库。它在字节跳动内部的 Rust 微服务和网关中已经大规模落地。
基础接口:支持最基本的序列化/反序列化编解码接口,满足业务对 JSON 操作的需求。
生态适配:我们适配了
KOVO和Water生态,尤其是在字节跳动内部大量使用的FastString,这个库在编解码方面有很好的适配。接口对齐:我们的接口与
SonicaGo和serde_json库对齐,方便业务从 Go 迁移到 Rust。
SIMD 简介
接下来我将介绍如何在 Rust 中使用 SIMD 进行优化。
顾名思义,SIMD 是单指令多数据(Single Instruction Multiple Data)。最简单的例子就是我们将一段代码编译成汇编指令,可以看到 SIMD 指令能用更少的指令处理更多的数据。例如,SIMD 指令可以通过两条指令处理 32 字节的数据,这也是 SIMD 高效的原因。
在 Rust 中,SIMD 优化主要通过以下两种方式实现:
手写 SIMD 算子:我们可以手写一些 SIMD 优化的算子,以提高性能。
编译器自动优化:有时候编译器会自动将代码优化为 SIMD 指令,而不需要我们手动编写底层代码。
Rust 中的 SIMD 开发
在 Rust 中进行 SIMD 开发时,需要使用架构相关的接口。这些接口位于 std::arch 模块中。然而,这里有一个坑,就是一定要加上条件编译。因为 SIMD 是与 CPU 架构相关的,如果没有加条件编译,有时代码虽然能够编译通过,但在运行时可能会出现未定义行为(UB)。
为了避免这种问题,我们可以使用第三方库 packed_simd,这个库将条件编译和接口封装在一起,提供了一个更安全的 SIMD 编程接口。
可移植性问题
使用架构相关的接口会带来一个可移植性问题。比如,如果我们在 x86_64 架构上写了 SIMD 代码,想要在 ARM 架构上运行,还需要重新编写代码。为了解决这个问题,Rust 标准库提供了 std::simd 接口,但目前这个接口还没有稳定。
因此,在 索尼卡S 中,我们自己做了一些封装,定义了我们需要的基本 SIMD 算子,如 load、store、compare 等,并在不同架构下实现这些算子。这样我们在编写 SIMD 代码时,只需要基于这些封装的算子,而不需要处理架构相关的细节。
运行时 CPU 特性检测
很多时候,我们需要在运行时检测 CPU 的特性,以便在不同的硬件架构上选择最合适的 SIMD 函数版本。在 Rust 中,我们可以通过 cfg_if 配合 target_feature 来进行运行时 CPU 特性检测,并派发到不同的 SIMD 函数。
然而,这里也有一些坑。例如,这些函数无法完全内联。为了优化性能,我们应尽量对最外层的函数进行派发,而不是对每个 SIMD 指令都做派发,否则效率可能还不如标量代码。
SIMD 代码的测试
在 Rust 中编写 SIMD 代码时,绕不过的一个问题就是如何测试这些代码。我们采用了以下几种测试方法:
边界测试:将我们的编解码结果与
serde_json进行对比,以确保覆盖足够多的边界用例,发现潜在的问题。内存检测:使用
sanitizer工具,检查内存泄漏、越界访问等问题。UB 检测:使用
cargo-miri,检测未定义行为(UB)。不过,cargo-miri对 SIMD 接口的支持有限,因此我们需要为 SIMD 函数写一个回退函数,绕过cargo-miri的限制。
当你遇到类似的接口时,虽然这些接口本身是接受的,但CARAMIRI(暂称)却会直接报错。通常的做法是,给生命(或者说定义)的那个X加一个回调函数,让它绕过cover unit的层次。我觉得这是RUS生态里可能需要加强的一个地方。
当我们写完代码后,刚好绕过了color mui的测试,似乎听起来就没有测试的必要了。因此,接下来我们来讲讲索尼FS中使用的一些SIM优化技巧或技术。这些优化算法很多都来自开源社区,或者一些论文,索尼在此基础上进行了引用和改进。
首先,第一个优化是如何用SIM跳过空格。其实,如果大家对SIRI有了解,一开始学习SIRI编程时就能写出这种代码。比如,用LVX2指令和比较字符的指令来写,测试集显示它比单一方法有十倍的提升。然而,当我们进一步使用更高效的SIM指令时,比如使用虾头指令,我们发现性能提升到了20倍,指令数量减少一半,性能提升约两倍。
在索尼class中,我们在前面SIM使用的基础上又做了更多优化。JSON文本有很多空格,但这些空格通常是不连续的,比如隔一个字符有一段空格。在处理这些空格时,我们可以利用数据的特点,将SIM的bitmask缓存起来,这样下次就不用重复计算。我们还可以用fast bus来处理有少量空格的情况,加上这些优化后,在pyed JSON数据集的测试中,性能提升了10%-15%。
第二个优化是如何用SIM加速浮点数解析。浮点数解析是JSON解析中的一个热点,尤其是提取浮点数的有效数字(如123.45678中的12345678)。这个操作性能较弱的原因是,每次都要从内存读取一个字节,然后根据ASCII码进行计算。通过SIM加速,我们可以将数字读入向量,减去ASCII码‘0’,并逐层累加,最终将结果转为U64。这种方法只需一次内存读写,性能大幅提升。
不过,当遇到小数点时,这种方法会出错,因此我们将整数部分和小数部分分开处理。通过这种方式,SIM优化可以应用到大量浮点数解析的场景中。
第三个优化是如何用SIM加速按需解析JSON。在很多业务场景下,我们不需要解析整个JSON,只需判断某个字段是否存在。完全解析整个JSON会带来不必要的性能和内存开销,因此我们提供了按需解析接口。通过SIM得到JSON结构的bitmask,跳过不需要的字段,并处理字符串中的结构化字符和转义字符。我们借鉴了SIRIJSON的算法,通过无分支判断方式找到JSON中的转义字符。
在此基础上,我们还处理了JSON括号的bitmask。通过SIM找到括号字符,再与前面的结果进行逻辑运算,排除字符串中的干扰项。最终,我们能够高效地处理JSON对象,并通过括号匹配算法跳过不需要的部分。这种方法参考了XSPCE 2022年的一篇论文《JSONSK》。
不过,这个算法有一个前提:输入的JSON必须是合法的。如果JSON中有非法字符,算法可能会出错。
接下来,我们来看一下这些SIM优化算法在索尼应用中的性能表现。我们使用了JSON解析为STRUCT的benchmark数据,这些数据来自Sole JSON的作者。我们的加速比基本达到了两倍以上,比SERT JSON更好,主要原因是我们使用了SIM技术,并减少了中间结构的转换。
我们还测试了将JSON解析为动态类型(如自定义的Value)。在这个场景下,加速比达到了3-5倍,主要得益于内存池的优化。内存池优化减少了内存分配的开销,同时也加快了内存释放。
序列化性能方面,我们的加速比约为两倍,主要体现在序列化字符的部分,序列化数字的效果则与SERT JSON相当。
最后,我们来看一下按需解析的性能。我们采用了SIM优化的括号匹配算法,与GJSON相比,性能提升了五倍。值得注意的是,我们的接口是unsafe的,因为它假设输入的JSON是合法的。
尽管我们已经做了很多优化,但仍有一些问题需要解决。例如,SERT的生态目前无法实现零拷贝的解析,特别是在解析字节数组时,我们缺乏一种优雅的方式来实现这一点。此外,我们还需要提升跨平台的能力,支持动态的CPU探测,确保性能不会受到影响。
展望未来,我们计划支持更多的JSON相关功能,如JSON class和JSON schema,使索尼GX更加易用。
最后,关于今天提到的项目:这些项目都是开源的,如果大家感兴趣,可以在GitHub上查看。包括双TIFS项目、索尼克项目、Cloud We Go、MOL,以及Rust的HTTP框架等。
今天的分享就到这里了,大家有什么问题吗?
18. 构建 Apache Arrow 的高扩展性嵌入式存储引擎 - 郭子兴
接下来的这个议题呢是来自于奇绩创坛,被投企业的创始人郭子兴。郭老师演讲嘉宾在吗?在现场吗?好的好的。他带来的这个主题是构建 Apache Arrow 的高扩展性嵌入式存储引擎。好,那下面的时间交给郭子兴郭老师。我们现在开始。
郭子兴:
Hello,大家好。我是这次分享的演讲嘉宾,我叫郭子兴。今天我想和大家分享的是我们正在用 Rust 开发的嵌入式数据库。看到这个标题,可能大家都在想:“又是一个用 Rust 做数据库,对吧?” 没错,现在市面上确实有很多人在用 Rust 来做数据库。这是因为不管是存储还是查询的生态环境,现在都非常成熟。
但是呢,这次我会尽量跟大家分享一些不太常被提到但又有意思的小细节。我的主要目的是分享 Rust 如何用于数据库和存储系统的构建,不管是抽象层面,还是具体实践。在这个过程中,我们遇到了一些突破,也有一些 Rust 编程语言的经验和设计思考。我希望通过今天的分享,能为大家带来一些启发。
自我介绍:
我叫郭子兴,之前在字节跳动做基础架构工作,主要是 Rust 相关的基础设施。在这之前,我也参与过一些数据处理和存储的工作。目前,我正在创业,使用 Rust 来开发我们的产品。我们希望能基于一个嵌入式数据库,提供面向未来的数据处理和存储的新方式。
接下来,我会分以下几个部分来分享:
- 背景介绍:为什么我们要做这个项目?
- 数据库的抽象和逻辑:在 Rust 实践中遇到的一些问题。
- 项目构成和未来方向。
背景介绍
首先,我会简单介绍我们希望通过这个数据库实现的目标。标题中提到的 Apache Arrow,可能有些人并不是特别了解。这里我会简单解释一下。
对象存储:
对象存储是一种非常重要的数据基础设施。相较于例如 Amazon S3 等平台,对象存储提供了大容量、低成本的存储方案。与其他存储方案(如 EBS)相比,对象存储的成本通常低 10 倍左右。此外,对象存储的共享性也非常强,能够方便地进行数据读写。这种特性能够大大降低分布式数据库的开发与维护难度。
我们看到越来越多的数据库正在原生支持对象存储作为其存储层。例如,接下来要分享的嘉宾来自 Right To Wave,他们的产品也对 S3 和对象存储提供了很多支持。而除了 RightToWave,还有 InfluxDB 以及其他国内外数据库,也在考虑将对象存储作为其原生存储层。这是因为对象存储可以提供低成本、大容量的存储方案。
Apache Arrow 和 Parquet 生态:
与此同时,Apache Arrow 和 Parquet 生态也在迅速崛起。Apache Arrow 是 Apache 基金会下的一个项目,提供了一种通用的、开源的数据和文件列存储格式。它的价值在于提供了一个稳定、通用的存储格式,且在此基础上,还提供了很多列存储格式下的优化。例如,Arrow 有非常高的压缩率,能比一些行业内的存储格式压缩效率高 10 倍。
Arrow 还提供了基本的性能优化手段,比如 Zero-Copy。通过这种格式,用户可以高效地处理数据。而且,基于 Arrow 的格式,很多工具都在发展并形成了一个生态系统。例如,科学计算、数据存储、查询等工具都围绕 Arrow 进行开发。这使得 Arrow 可以应用在数据密集型应用当中。
不可变性:
Arrow 有一个重要的特性就是它的数据是不可变的。这一特性非常适合用于对象存储,因为对象存储本身就是基于不可变的理念。Parquet 官方也支持对象存储,例如 S3 和 R2。
项目背景
我们看到,越来越多的新兴数据库开始原生支持对象存储。同时,很多工具也围绕 Apache Arrow 和 Parquet 生态进行发展。因此,我们希望能够结合这两种趋势,构建一个基于 Arrow 生态下的数据密集型应用的基础存储层。
目前,很多数据库内部已经具备了这种能力,比如 RisingWave 和国内的一些数据库公司。但这些数据库并没有提供一个类似 RocksDB 的嵌入式数据库。而嵌入式数据库可以被用来构建很多其他应用。因此,我们希望能够构建一个围绕 Apache Arrow 和 Parquet 生态的嵌入式数据库,并且原生支持对象存储。
这种数据库可以让用户方便地构建类似 RisingWave 或 RealtimeDB 的数据密集型应用。它的优势是,你可以把数据存储在各种公有云或私有云上,不用担心供应链问题。同时,你也可以按需选择 Arrow 生态下的其他数据处理工具,比如 RAPIDS 加速计算库。
项目进展
目前,我们的项目已经开源,首个版本已经发布在 GitHub 上,项目名称是 TaroDB。
实践中的问题
接下来,我会分享我们在构建 TaroDB 时遇到的一些具体问题。因为我们这是 RustConf,不是数据库会议,我会尽量简化数据库相关的技术细节,专注于与 Rust 相关的问题。
问题 1:Rust 中的抽象表达
TaroDB 是一个嵌入式数据库,我们通过库的形式提供接口。Apache Arrow 支持 Schema 的结构化数据存储,因此我们可以用类似 ORM 的方式声明数据结构。此外,它还支持标准库中的容器类型,例如 HashMap。我们设计了一套抽象表达来支持 API 的实现,这样可以更好地利用 Rust 的类型系统和所有权机制。
问题 2:列存储与引用类型
Arrow 是列存储格式,因此我们不能像标准库中的容器那样,直接返回一个整体的引用类型。我们需要为每个字段返回单独的引用。为此,我们设计了 Record 和 RecordRef 类型,通过关联类型的方式进行数据获取和写入。
问题 3:与 Arrow 的交互
Arrow 的核心类型是 RecordBatch,它是一组带 Schema 的数据,按列组织。我们基于 RecordRef 类型实现了对 RecordBatch 的封装,使其能以类型安全的方式与 Rust 的类型系统进行交互。这样,我们可以避免在运行时进行不必要的类型转换。
Rust 类型系统的瓶颈
在实现这些功能时,我们遇到了 Rust 类型系统的瓶颈。特别是在处理生命周期和类型转换时,Rust 的类型继承机制并不是很完善。Rust 通过 Reborrow 和 Type Coercion 机制来处理子类型关系,但这在某些场景下仍然有一定的局限性。
总的来说,我们在构建过程中遇到了一些挑战,但也通过 Rust 的类型系统实现了高效、安全的嵌入式数据库。这是我们项目的一些初步进展,也希望能为大家提供一些启发。
接下来的演讲内容将会更加深入探讨 Rust 的生命周期管理和类型转换问题。
整理后的内容如下:
它本身不具有这种子类型的关系,但实际上某些部分类型是存在子类型的,其中包括 lifetime 类型。比方说,对于具有包含关系的 lifetime 来说,较长的生命周期可以被认为是较短生命周期的子类型。虽然 Rust 官方并没有正式将其定义为子类型,但它表现出了类似子类型的行为。
在 Rust 中,有两种机制来处理这种子类型与自动转换的协变关系:一种叫 Reborrow,另一种叫 Type Coercion。接下来,我会深入介绍这些机制,以及它们如何影响我们在设计中的一些决策。
我这里举一个简单的例子:假设我们定义了一个容器类型,这个容器返回它内部字段的引用。在这个过程中,我定义了两个不同的类型,一个是简单的 &str 引用,另一个是 CustomRef,它捕获了一个生命周期。
当你编译这个程序时,会发现 &str 的 get 接口可以正常工作,但 CustomRef 却无法返回。编译器会报错,提示你返回的数据类型的生命周期与 field 的生命周期不匹配。为什么 &str 可以,而 CustomRef 不可以呢?
原因在于,当容器的 get 方法返回 &str 时,Rust 通过 Reborrow 机制进行了生命周期的缩短。它将容器的引用(&'r Container)通过 Reborrow 缩短为一个较短的生命周期,使其与 field 的生命周期一致。由于 &str 的生命周期比容器的生命周期更短,编译器能够自动完成这种转换,类似子类型的协变效果。然而,这种转换无法应用于捕获了生命周期的 CustomRef。
你可以尝试定义一个泛型版本的 CustomRef,并将其生命周期参数化。在这种情况下,Rust 也会应用 Type Coercion,即认为捕获了较长生命周期的类型是较短生命周期类型的子类型,并进行转换。然而,Rust 当前不支持在类型参数上进行这种转换,这也是我们在定义 get 方法时遇到的 Rust 类型系统的局限性。
因此,我们不得不使用 unsafe 来强制将捕获了较长生命周期的 Ref 类型缩短为较短生命周期的 Ref 类型。
另一个值得注意的设计点是,我们的系统混合了本地存储和远程存储。因此,与 Rust 其他一些性能数据库(如 sled、RocksDB)不同,我们采用了异步接口。对于传统数据库,它们通常选择同步接口,这点很容易理解,因为 Rust 的异步生态设计对于文件读写并没有太多帮助。
我们可以参考 tokio 这个知名的 Rust 异步运行时,来简要介绍异步文件 I/O 的实现。与网络 I/O 不同,文件 I/O 无法通过异步代理,因此它走的是类似 spurious bottleneck 的逻辑。虽然文件 I/O 操作也是处理 &[u8],但它会进行一次缓冲区复制,将数据复制到一个具有所有权的类型中,然后进入同步过程,执行具体的文件操作。最终,返回文件操作的结果。在这个过程中,线程的调度会被阻塞,这意味着在文件 I/O 密集的场景下,使用异步可能反而会带来性能的下降。
Rust 的异步运行时通常基于 poll-based 的调度模型,然而社区中也有一些基于 io_uring 的新方案。尽管这些方案能一定程度上缓解一些问题,但目前它们还没有完全成熟。
在去年 RustCon China 的演讲中,我提到过 Rust 当前的异步生态在某些方面并没有为 io_uring 准备好。这是因为 Rust 的 Future trait 设计假设异步操作只有在 poll 被调用时才会发生。如果 poll 不被调用,那么 Rust 假设没有任何异步操作会发生。这个设计假设导致了在某些场景下(如取消 Future 或超时控制)无法安全地处理异步操作。关于这个问题,如果大家感兴趣,可以去哔哩哔哩上查看我之前的分享视频。
作为一个嵌入式数据库,我们不能假设用户会使用哪种 I/O 模型(如 poll-based 或 io_uring)。因此,我们无法设计一套同时兼容这两种模型的代码。尽管如此,我们还是采用了异步接口。一方面,我们的存储系统混合了本地存储和远程存储,而远程存储的访问成本比本地存储要高得多。在这种情况下,异步接口可以提供更好的远程存储访问性能。另一方面,我们希望支持多种运行时环境,比如未来在浏览器环境中,我们不能长时间阻塞线程,因此需要异步 API 来调用浏览器的文件系统。
关于我们的读写路径设计,我们采用了基于 Stream trait 的模型,并使用了一种叫做 Level Compression 的 LSM 树结构。你可以将它理解为分层存储策略。所有数据按 key 的字典序存储在磁盘中,我们只需要通过元数据找到需要迭代的文件,并按顺序进行迭代即可。在这里,我们有不同的文件类型,每种文件类型对应一个具体的 Stream trait 实现。
为了避免使用 trait object 带来的运行时开销,我们使用了一种叫做 enum dispatch 的方式来调度不同的 Stream 实现。通过这种方式,我们可以在运行时有效地分发到具体的 Stream 实现,避免了 trait object 带来的性能问题。
由于 RecordBatch 是所有数据的底层结构,我们不希望在常规读写过程中暴露 RecordBatch 作为底层实现。因此,我们需要使用一个自引用结构来确保 RecordBatch 的所有权不会泄露给用户。然而,我们又需要从 RecordBatch 中返回一个 RecordRef,因此我们通过 unsafe 代码来强制转换 RecordBatch 的所有权。
以上,我介绍了我们在抽象类型表达、写路径和读路径实践中的一些问题,以及 Rust 类型系统的局限性和我们的解决方案。接下来,我简单介绍一下我们未来的计划。
我们目前的版本还处于非常基础的 0.0.0 阶段,未来我们希望支持更多的存储后端,包括 S3 和其他远程存储。同时,我们也希望能更好地支持 Apache Arrow 生态,尤其是在处理大数据应用时,Arrow 的列式存储格式可以提供更高的压缩率和更快的查询性能。
我们还计划支持更多的异步数据应用场景,并提供 Python bindings,方便更多开发者使用。
这是我的个人微信二维码和我们项目的主页。如果大家对这个项目感兴趣,欢迎加入讨论。无论是对数据存储应用感兴趣,还是对 Rust 的某些技术细节感兴趣,都欢迎大家来找我交流。谢谢大家!
提问环节:
观众: 你好,刚才看到你提到准备支持更多的远程存储,是否考虑使用 Apache Arrow 的格式?
郭子兴: 是的,我们确实考虑过,目前也在评估中。Apache Arrow 官方支持对象存储和开放格式,对我们来说是一个不错的选择。
观众: 你们这是一款嵌入式数据库,为什么选择 Arrow 的格式呢?
郭子兴: 其实现在很多 OLTP 数据库正在往 HTAP 或者 OLAP 的方式演进。比如 PostgreSQL 就在尝试将大数据引擎作为插件插入其架构。未来,随着数据量的增长,数据库的需求会逐渐向 AP 方向发展。在这种场景下,列存储格式的优势非常明显:一方面,它的压缩率高;另一方面,它可以通过类型化的方式加速计算。这就是我们选择 Arrow 作为通用列式存储格式的原因。
观众: 谢谢,我明白了。
郭子兴: 谢谢大家!
19.foyer 使用混合缓存轻松增强基于 S3 的存储引擎 - 孟爻
大家好,欢迎各位参加今天的分享。我是孟爻,分布式存储研发工程师,也是 Hybrid Cache 库 Foyer 的作者。今天我将向大家介绍一个基于 Rust 语言开发的混合缓存库——Foyer,以及它是如何帮助我们轻松增强基于 S3 的存储引擎性能的。
自我介绍
首先,我简单介绍一下我自己。我的名字是孟爻,目前在 RisingWave 做分布式键值存储引擎的研发工作,主要负责系统性能优化。我之前有参与过 TiKV 数据库存储引擎的开发。今天的分享会主要围绕 Foyer 这个项目以及它的应用展开,尤其是它如何帮助我们降低 S3 的访问成本。
分享内容
今天我将从以下几个方面来进行介绍:
- 什么是混合缓存
- Foyer 的设计与应用
- Foyer 的未来发展
什么是混合缓存
混合缓存的背景其实是基于一个趋势:在过去的十年中,云上的数据库和数据仓库架构发生了很大的变化。最早,数据主要存储在本地硬盘上,随着数据量的增加,大家开始使用冷热分离的架构,再到近几年,很多数据完全存储在对象存储(如 S3)上。这种转变的主要原因是数据量快速增长,而云服务器的内存并没有相应增加,导致内存变得越来越宝贵。
例如,AWS EC2 的主流机型,在过去十年里,CPU 和内存的比例几乎没有变化。随着数据量的增加,服务器的内存资源显得愈发稀缺。这就意味着我们需要在相同的内存条件下处理更多的数据量,这对系统的内存管理提出了更高的要求。
面临的问题
当我们使用 S3 等远程对象存储时,会遇到一些问题。首先,S3 的访问延迟很高;其次,虽然 S3 的存储成本低,但它的访问成本相对较高。很多企业会尝试通过使用 S3 来降低存储成本,但最终却发现访问成本大幅增加,甚至超过了存储成本。
为了解决这个问题,很多系统引入了本地缓存层。通过将数据缓存到磁盘上以减少对 S3 的频繁访问,我们可以在性能和成本之间找到一个平衡点。然而,这种做法也带来了复杂性,因为系统中同时存在内存缓存和磁盘缓存,开发者需要管理多层缓存。
现有的三种主流解决方案
手动实现缓存管理:比如 StarRocks 这样的数据库系统,开发者手动实现了一个缓存管理系统。虽然这种方式可以高度定制,但开发成本高,维护复杂。
使用 RocksDB:RocksDB 是一个非常成熟的嵌入式数据库,它也可以作为缓存系统使用。不过 RocksDB 并非专门为缓存场景设计,因此在缓存场景下会存在一些问题,比如缓存命中率低、空间放大效应严重等。
使用 CacheLib:CacheLib 是由 Meta 开发的一个专门为缓存场景设计的库,虽然它非常适合缓存场景,但它是用 C++ 开发的,与 Rust 生态的兼容性较差。此外,CacheLib 在生产环境中常常会遇到一些内存管理问题,也存在一定的长尾延迟。
Foyer 的诞生
Foyer 的诞生就是为了填补 Rust 生态中缓存系统的空缺。Foyer 是一个用 Rust 语言编写的混合缓存库,旨在解决现有缓存系统的痛点。Foyer 的设计借鉴了 CacheLib 和 Caffeine 等知名项目的设计理念,但它在实践中做了许多优化,特别是在性能和可观测性方面。
Foyer 的架构设计
Foyer 的架构由内存缓存(in-memory cache)和磁盘缓存(disk cache)组成,Foyer 负责管理内存与磁盘缓存,并协调它们之间的数据交互。
内存缓存
Foyer 的内存缓存是一个分片缓存(sharded cache),它会根据 key 的哈希值将数据分配到不同的 shard 中。每个 shard 使用一把锁来控制并发访问,确保线程安全。
磁盘缓存
Foyer 的磁盘缓存则支持多种存储介质,无论是本地磁盘还是远程对象存储(如 S3),它都可以处理。磁盘缓存中的数据会被划分为多个等大小的区域(region),Foyer 会周期性地管理这些区域。
性能优化
Foyer 在性能优化方面做了许多工作:
大 IO 与小 IO 的区分:Foyer 为大数据块和小数据块设计了不同的引擎,以充分利用磁盘性能。比如,Foyer 会将小数据块合并写入磁盘,以减少 IO 次数,提升整体吞吐量。
并行化管理:Foyer 对磁盘上的 region 管理进行了并行化处理,所有涉及数据生命周期管理的主线程都是解耦的,用户可以根据需求动态调整并行度。
避免锁竞争:Foyer 在某些场景下会使用轻量级的
spinlock来减少锁竞争,提升并发性能。内存索引优化:Foyer 使用压缩的内存索引来减少内存占用,并通过批量写入的方式优化磁盘的写入性能。此外,Foyer 还通过合并写操作来减少对磁盘的磨损,延长磁盘寿命。
即插即用的缓存算法
Foyer 提供了即插即用的缓存算法。用户可以根据不同的工作负载选择不同的缓存算法,比如 LRU、LFU 等。Foyer 通过抽象缓存算法为 Eviction Trait,用户只需要实现这个 trait 就可以定制自己的缓存算法。
可观测性
Foyer 提供了非常强大的开箱即用的可观测性。得益于 Rust 生态中的优秀库(如 tokio-tracing),Foyer 可以很方便地集成各种监控指标和追踪系统。用户只需要几行代码就可以接入这些功能。
特别值得一提的是,Foyer 的 tracing 功能可以在几乎无额外开销的情况下捕获慢请求的完整生命周期。这对于调试性能瓶颈非常有帮助。
用户友好的 API
Foyer 提供了非常用户友好的 API。无论是配置缓存算法,还是启用监控功能,用户都只需要几行代码就能实现。Foyer 的 API 设计遵循 Rust 语言的惯用法,易于集成到现有的 Rust 项目中。
总结
Foyer 是一个高效、灵活且易于使用的混合缓存库,它的设计充分考虑了性能、可观测性和用户体验。通过使用 Foyer,我们能够显著降低对象存储的访问成本,同时提升系统整体性能。
我们捕获了一个列为 token rap type chedule,当时的 QPS 为 100 万。即使在 100 万的 QPS 情况下,我们也能在几乎没有开销的情况下,捕捉到这种长延迟现象。最后,我想提到一下,方位提供了非常用户友好的 API。其实,之前我们讲到集成算法和可观测性时,也提到过很多东西仅需几行代码就可以实现。在这一部分中,已经提到了很多易用的 API。接下来,我再看看我们在内部使用 FORET 和原来的 BLOCATCH 意图。上面是提到前期的部分,现在说到后期,只需要做很少的修改,大部分机器都是兼容的。
说到这里,我们来看一下 Fry 在实际生产环境中的一些真实案例。目前,方瑞已经在两个比较有名的开源项目 resume 和 CHROMA中落地。CHA 是一个社区用户,但我对他们的场景并不是特别了解。这里主要介绍一下 Rest live 是如何使用方源的。
在讲 RASM 的用例之前,我们先讲一下 REACBOOK 是什么。它是一个可靠的媒体流表,其存储引擎是基于 S3 的分布式 L3train。上一位老师刚才也提到过,L3 这个数据结构的 s table 是没有更新操作的,因此非常适合在 S3 上存储。Rest road 的全量数据也是保存在 S3 上的,而每个计算节点上有一个 BLOCATCH 来优化性能和开销。
方瑞在 rescue 中直接替换了原有的内存 BLOCATCH,并提供了一个 higher catch 能力。启用了 higher catch 后,RESM 的性能和 S3 的使用成本都有了很好的优化。虽然 RESM 是一个数据库,它希望将优化做到极致,因此在使用方瑞时,也对 L3TCH 进行了一些专门的优化。
首先,compassion 操作是通过调整数据结构来优化写放大和空间放大的。compassion 过程会删除旧的 s table 并写入新的。然而,在分布式 L3TRI 上,这种 connection 操作对 catch 并不友好,每次 connection 后都会导致严重的 catch miss。为了解决这个问题,最简单的方式是在 compassion 更新了 s table 后,写入数据之前,先执行 catch refu,将新的 s table 插入 catch 中,避免 catch miss。
之前我们只有内存中的 catch refu,这会导致内存中很热的 s table 被替换掉,而这些被替换掉的 s table 可能后续并不会用到。现在有了 SOER,我们可以将 connection refuel 的 s table 直接写入到 DISCATCH 中,而不会影响内存中的热 s table。这个问题本质上是因为内存资源变得越来越宝贵了。我们可以看到,方瑞开启 BYY 的 catch refu 后,hybrid catch 的命中率从原来的 20% 提升到了接近 100%。效果非常不错。
第二个问题是如何选取读取 S3 上 s table 文件的大小。RESNEAL 作为一个流式单位,它的上游通常是 CDC,这种场景下的 I/O 更接近 OLTP 而非 OLAP。因此,当读取一个块时,只有其中很少一部分数据会被真正使用,而其他部分都是额外拉取的浪费数据。选择 I/O 大小非常难,因为选的太小,碎片会减少,catch 利用率高,但对于 S3 的访问成本非常高;选的太大,S3 的访问成本低,但 catch 利用率也低,整体性能和成本都不理想。
这个问题本质上还是因为内存资源的限制。有了方瑞的 hybrid catch 后,DISCATCH 的大小可以是内存 catch 的十倍、百倍,甚至一千倍。因此,restroom 可以大胆地使用较大的 LC 来优化成本。同时,hybrid catch 还提升了性能。以下是一个例子,展示了方瑞使用 hybrid catch 前后,S3 访问的 QPS 下降了 80% 到 90%,防御成本也降低了 80% 到 90%。性能方面,对于状态较大的查询(如 Q20、Q7 场景),性能提升接近 250%,而对于计算密集型场景,回退不超过 5%。
以上是 Fry 在 RES6 中的用例。目前在 cloud 上,方瑞也已落地。我希望未来方瑞能在 BORBB 或 RAG 领域做出更多贡献。
最后说一下方瑞的未来发展,其实还是比较清晰的。首先,我们已经有了几个长期使用的客户,接下来我们将继续在已有优势的领域精进。比如,我们希望在可插拔的算网上支持更安全的接口。因为 multi lex 接口与 RUS 的内存安全有些冲突,大部分结果都存在这个风险。因此,我们希望提供一个更安全的接口,让用户可以更好地定制。
性能优化方面,我们希望提供一些 lock-free 支持,并优化 realtime,避免 schedule 拖累 catch。在可观测性方面,我们可能会提供一些算法内部参数的可观测性。此外,用户优化 API 上可能会提供自动化调参能力。虽然方瑞使用起来已经比较简单,但要调出最佳参数仍然不易。我们希望能在这些方面解决大家的问题。
今天的分享就到这里。上面是方瑞项目的 GUID,大家如果感兴趣,可以点 star 下载试用。下面是我们的 get f d,也可以关注我。左边是我的微信,如果想讨论 PH、性能或调优相关工作,可以联系我。右边是 PSLAVE 的公众号和社区群。如果对影视库感兴趣或有流场景需求,也可以看看是否适合。谢谢大家。
提问:
提问者:现在这个可拔插的算法是内部定制的,还是开发者可以使用?
回答:目前是方瑞内置的,常用的几种算法都已内置。未来我们希望开发者也可以使用。虽然
trap已经提供了相关支持,目前的问题是alt deer这个问题在RUS中不太好解决。为了避免选择ISM接口时出问题,第一步我们会尽可能缩小safe的范围,确保进程安全后再开放给用户试用。提问者:方便问一下,方瑞自带的缓存和缓存的最小力度是什么?比如说是否支持读取部分内容?
回答:方瑞作为一个通用缓存是可以支持的,它与 S3 没有本质关系,和普通的 Rust 缓存一样,只要你提供
K和B,就可以使用。
20.Occlum LibOs 异步网络框架 - IO_Uring 工程实践 - 李泽寰
https://www.bilibili.com/video/BV1H4s1eJEyi/
我们欢迎蚂蚁集团高级开发工程师李泽寰,为我们分享 Occlum LibOS 异步网络框架 及 I/O_uring 工程实践。Occlum 是蚂蚁集团开发的 TEE 操作系统,旨在让普通应用获得机密计算能力。Intel SGX 硬件特性提供了可信执行环境 (TEE),但其 IO 性能存在瓶颈,因为执行 IO 操作时需要进行额外的内存拷贝和上下文切换。为了解决这一问题,Occlum 采用了 I/O_uring 技术,并在其基础上设计了一套异步网络框架,支持异步和同步网络系统调用,无需修改应用程序代码即可提升性能。
接下来我们欢迎李泽寰工程师为我们介绍…
李泽寰:
大家好,我是李泽寰,现任蚂蚁集团高级开发工程师,2022 年毕业于上海交通大学,目前是 Occlum 和 Rust SGX SDK 开源项目的核心开发者。今天我为大家介绍的是 I/O_uring 工程实践 和 Occlum 异步网络框架。我们开发的 Occlum 是一个基于 TEE 的操作系统,旨在为普通应用提供机密计算能力。
Occlum 是蚂蚁集团开发的开源项目,专注于 机密计算,尤其是 可信执行环境 (TEE)。然而,现有的 TEE 环境在 IO 性能 上存在瓶颈,主要源自上下文切换和内存拷贝的开销。为了解决这个问题,我们采用了 I/O_uring 技术,设计了一套异步网络框架,支持异步和同步系统调用,且无需修改应用程序代码即可提升性能。
项目背景
我们团队致力于 机密计算,其核心场景是 可信执行环境 (TEE)。Intel SGX 是目前最常用的 TEE 技术,它提供了一个受信任的运行环境,确保应用程序的代码和数据在运行时得到保护。
然而,TEE 环境在执行 IO 操作 时存在一个固有的 瓶颈。执行 IO 操作需要多次上下文切换,尤其是在 host 和 enclave 之间的切换,这种切换的开销非常大,接近普通上下文切换的 70 倍。此外,每次 IO 操作还需要进行多次内存拷贝,进一步降低了性能。
为了提升 IO 性能,我们引入了 I/O_uring 技术。这是一种 Linux 内核的新特性,旨在优化异步 IO 操作。通过共享内存的方式,I/O_uring 减少了上下文切换的次数,并提供了更高效、低延迟的 IO 操作。
可信执行环境 (TEE)
简单介绍一下 TEE 的概念。TEE(Trusted Execution Environment,可信执行环境)是由 CPU 或 GPU 等硬件提供的一种隔离环境,它能够确保应用程序的代码和数据在运行时受到保护。Intel SGX 是目前最流行的 TEE 技术,它允许应用程序在隔离的 enclave 中运行,宿主操作系统无法访问 enclave 中的代码和数据。
但是,TEE 环境的开发非常复杂,因为它类似于一个裸机环境,缺少标准库、开发工具等支持。因此,我们开发了 Occlum,一个基于 TEE 的用户态操作系统,它为普通应用程序提供了类似操作系统的支持,让开发者可以像在普通操作系统上一样编写应用程序。
我们的目标是让所有开发者都能轻松使用 TEE。Occlum 是完全用 Rust 开发的,旨在为 TEE 环境中的应用提供系统级别的支持。
TEE IO 性能瓶颈
TEE 环境的 IO 性能瓶颈主要体现在上下文切换和内存拷贝的开销。每当应用程序需要执行 IO 操作时,必须从 enclave 切换到宿主操作系统,再从用户态切换到内核态执行系统调用。这不仅带来了额外的上下文切换开销,还需要多次内存拷贝。
I/O_uring 技术简介
为了解决这些性能问题,我们引入了 I/O_uring 技术。I/O_uring 是 Linux 内核中的一个新特性,它允许应用程序通过共享内存的方式与操作系统交互,从而减少上下文切换和内存拷贝的次数。
在 I/O_uring 的设计中,应用程序和操作系统共享一块内存,所有的系统调用请求都可以直接在这块共享内存中处理。这种方式大大降低了 IO 操作的开销,提高了 IO 的并发性和性能。
I/O_uring 在 Rust 生态中的应用
在 Rust 生态中,已经有多个针对 I/O_uring 场景的运行时库,比如 tokio-uring 和 rio。其中,tokio-uring 是一个基于 tokio 的异步运行时库,它对 I/O_uring 进行了封装,简化了开发者的使用复杂度。
不过,这些运行时库主要是为新应用设计的,而我们在实际应用中还需要处理大量的存量应用,比如 Redis、Nginx 等。对于这些应用,我们不太可能完全重写它们的代码以适配 I/O_uring。
为此,我们设计了一种机制,可以在不修改现有应用代码的情况下,利用 I/O_uring 提升性能。我们的解决方案是通过模拟传统的 socket 接口,内部使用 I/O_uring 进行数据传输,从而隐藏了底层的实现细节。
异步框架设计
我们的异步框架设计主要有以下几个部分:
- 异步框架调度机制
- Socket 状态机
- 多路复用
- 异步读写
通过这些设计,我们能够将异步 IO 操作的性能提升到一个新的高度。我们的框架伪造了一个 POSIX socket 接口,应用程序可以像使用传统 socket 一样进行读写操作,但底层实际上是通过 I/O_uring 进行数据传输的。
性能优化的挑战
虽然 I/O_uring 提供了显著的性能提升,但它也有一些不足之处。首先,并不是所有的网络协议都能够直接支持 I/O_uring。其次,I/O_uring 的高性能依赖于 CPU 资源,因为需要有一个轮询线程不断检查 I/O_uring 的提交队列和完成队列,这会增加 CPU 的负载。
此外,I/O_uring 的异步模型也对调度机制提出了新的挑战。我们尝试过两种调度方法,一种是用户态调度,另一种是基于 Linux 内核的调度。最终,我们选择了基于 Linux 调度的方案,因为它更加稳定和高效。
以上是我们在 I/O_uring 工程实践中的一些经验分享,希望对大家有所帮助。
异步运行时与高性能关联
在丰富的应用场景中,无栈协程并不是最佳解决方案。因此,异步运行时与高性能不能直接挂钩。你可以将其与 engines(引擎)或特定的网络场景挂钩,但并非所有场景都能一概而论。举个例子,大家非常熟悉 Tokyo,它的最佳落地场景实际上是在网络中,这也是 Tokyo 最核心的优势所在。
实习生的内核实验
我们有一个清华的实习生进行了一项有趣的实验。他在内核中实现了一个异步运行时,将 Rust 的异步运行时引入,并且对 有栈协程 和 无栈协程 进行了性能比较。结果发现,两者的性能没有太大差异。虽然 有栈协程 的 上下文切换 确实快一点,但这种差距只在一些老旧的 CPU 上显现出来,比如 RISC-V 那些没有良好分支预测和乱序执行能力的处理器。在现代的 Intel X86 处理器上,分支预测和乱序执行的效果已经非常出色,反而掩盖了上下文切换带来的性能差异。因此,总体来看,有栈协程 和 无栈协程 的区别并不大。
线程调度经验
我们在实践中发现,单线程承载多个协程时,随着协程数量的增加,线程可能会积累大量数据和态势信息。此时,需要在 VCPU 负载 之间进行权衡。特别是在网络场景中,线程可能频繁切换,而这些切换带来的缓存失效影响并不大,因为缓存开销较小。然而,在 Tensorflow 等分布式机器学习任务中,缓存命中率非常重要。如果线程在不同的 核心 之间频繁切换,性能开销会非常大。
无栈协程的缺点
切换时机限制:无栈协程的切换只能在 yield 点发生,无法随时打断。这在处理网络 I/O 任务时,响应速度可能不够快。
线程休眠与唤醒的开销:无栈协程的线程在没有任务时会进入 park 状态,陷入内核态。唤醒时的 unpark 开销较高,因此需要在 自旋等待 和直接休眠之间找到平衡。
异步运行时的状态机设计
我们实现了一个状态机来封装 executor system,用于管理 socket 的状态。比如,定义四个状态:Init、Connect、Connected 和 Listen。当进行 receive message 操作时,可以清楚知道当前线程的状态,是否需要等待或切换状态。所有操作都异步化,并由底层的 BCI 替代执行。
I/O 多路复用
我们使用了 观察者模式 和 事件驱动模型 来实现 I/O 多路复用。当发起 poll 或 epoll 调用时,如果有数据可用,直接返回;如果没有数据,则注册一个观察者。当后端的 callback 检测到数据到达时,它会唤醒注册的观察者,实现异步通知。
异步写入与性能优化
我们在内存中为异步写入保留了一块缓存区。当用户线程写入数据时,只需将数据写入缓存区即可,后续操作由后台线程处理。这与 Linux 的行为类似,数据写入 socket buffer 后即返回,不进行阻塞操作。
此外,通过预先注册接收消息操作,当新数据到达时,后端线程会将数据写入缓存区,用户线程可以直接读取,避免了不必要的系统调用,极大提升了性能。
性能测试结果
我们对 OpenXI 和 Open I/O_uring 进行性能评估,发现多线程情况下的性能提升显著,能够达到 1.5 倍至 2 倍。在 Redis 的真实场景中,性能提升也非常明显,尤其是在偏向网络的应用中,性能提升可达 4 倍。
I/O_uring 的局限性
轮询线程开销:I/O_uring 需要在内核和用户态各配置一个轮询线程。虽然用户不一定感知到内核的轮询线程,但多个运行时实例同时运行时,轮询线程可能会影响应用的整体性能。
I/O 带宽限制:I/O_uring 提供的 I/O 带宽存在上限,实际应用时需要根据场景合理配置轮询线程的数量。
安全漏洞:大部分 I/O_uring 安全漏洞都来自 LUV,例如 Google 禁用了内部的 I/O_uring 使用。
后续优化方向
未来的优化方向包括:
- 提供预分配缓存:通过 providing buffer,可以预先映射内存,减少映射开销。
- 支持零拷贝:I/O_uring 支持零拷贝操作,进一步提升 I/O 性能。
- 忙轮线程优化:多个 I/O_uring 实例可以共用同一个轮询线程,减少资源开销。
招聘与总结
我们团队使用 Rust 进行开发,项目包括 Occlum 和 Payrider 等,涉及操作系统、计算基础设施等。团队目前正在招聘,欢迎有志之士加入我们的 Rust 开发团队。
提问环节
问题 1:Occlum 与常见的 Linux 嵌入式操作系统有何区别?
回答:Occlum 是在用户态提供一个进程的抽象,用于支持机密计算环境,而 Linux 不能作为一个进程运行在 SGX 环境下。因此,在 SGX 这样的环境中,Occlum 必须提供一个操作系统。未来,我们还计划开发一个基于虚拟机的 VM-based OS,类似于 Linux,但不会提供容器等复杂功能。
问题 2:Occlum 支持的硬件环境有哪些?
回答:Occlum 依赖于硬件提供的 SGX 抽象,因此只能在支持 SGX 的硬件上运行。不过,我们的 hypervisor 可以将 SGX 抽象扩展到其他架构上,如 RISC-V、ARM、SEV 等,使得 Occlum 可以在这些芯片上运行。
结束语
感谢大家的提问与参与!
21.利用 Embassy 模块化硬件产品 - 陈昱衡
接下来我们欢迎鹿仔科技创始人兼CTO陈昱衡,为我们分享利用 Embassy 模块化硬件产品。Embassy 依托 Rust 将异步特性引入单片机编程中,相对传统的开发方式有诸多优势。本次分享将通过几个产品模块的例子来介绍 Rust 和 Embassy 在不同产品中的应用,以及如何利用 Embassy 来实现模块化产品开发。接下来我们把时间交给陈昱衡。
各位 Rust 开发者和爱好者们,大家好,我是来自鹿仔科技的陈昱衡。今天我将分享一下如何利用 Embassy 去模块化我们的硬件产品。我将通过以下四个方面带大家了解我们是如何把 Embassy 应用到产品中,并且让它加速我们的整个研发流程。
首先,介绍一下我们公司。我们公司成立于 2021 年,坐落在重庆的明月湖畔,由于业务需求,我们把硬件研发中心设立在东莞,同时在苏州设立了一个软件研发中心。我们专注于生产用于生命科学实验的软硬件仪器和平台。现在,我们已经有很多产品使用 Rust 进行开发。接下来,我将介绍我们东莞研发中心的一些单片机应用。
为什么使用 Embassy?
我们最开始基于 C 语言开发的一些产品,出现了内存问题,导致返厂或售后问题。于是我们开始思考是否有一种更安全的方式推广我们的产品。于是我们选择了 Rust。Rust 的内存安全特性为我们解决了很多问题,但早期我们仍然遇到了一些困难,比如生态较小、底层库不稳定、需要重复造轮子等问题。最终,我们决定采用模块化的方式进行开发,以提高开发效率和产品的稳定性。
Embassy 是什么?
Embassy 是一个轻量化的异步嵌入式框架,它依托 Rust 的异步特性,提供了两个核心库:一个是 Executor(运行时),另一个是 HAL(硬件抽象层)。它支持多种硬件平台,比如 ESP32 的 Networking、STM32 的 LoRa、蓝牙等。Embassy 的核心思想是通过异步编程提升单片机编程的效率和安全性。
模块化开发的优势
我们的设备通常由多个模块组成,比如传感器读取生物电信号、气压数据、温湿度数据等,然后通过处理模块进行决策,最终通过执行模块输出结果。我们通过 Rust 实现每个模块的功能,并在每个模块上增加一个 MCU(微控制单元),虽然增加了一些成本,但极大地提高了模块的复用性和产品的稳定性。
使用 Embassy 进行模块化开发
我们选择了 Embassy 和 Arctic 这两个嵌入式操作系统。Arctic 的核心是通过中断系统快速调度任务,而 Embassy 则通过 Rust 的异步特性实现高效的任务切换。Embassy 将所有任务编译成状态机的形式进行切换,这样虽然增加了代码体积,但提高了任务切换的效率。同时,Embassy 提供了统一的硬件抽象层,方便我们进行模块化开发。
数字电源控制系统的应用
我们开发了一个数字电源控制系统,核心是 STM32 的主控芯片,通过串口、PWM 等方式进行控制。我们通过硬件系统实现降压、升压等功能,再通过反馈环路进行闭环控制。Embassy 提供了一个统一的库,管理外设地址、DMA 映射和中断信息,极大地简化了开发过程。
异步任务的实现
在 Embassy 中,我们通过定义异步任务来实现多任务处理。通过配置时钟、使用任务调度器,我们可以实现高效的异步任务执行。Embassy 提供了很多同步机制,比如 Signal、Channel、Mutex 等,方便我们在任务之间传递数据。同时,对于一些不支持原子指令的平台,Embassy 提供了 protocol::atomic 库,模拟原子操作,确保数据访问的安全性。
DMA 的应用
在我们开发的电源系统中,DMA(直接内存访问)被广泛应用。我们使用 DMA 实现异步的 I²C 数据传输、ADC 采集等功能。Embassy 的 DMA 支持异步读取数据,并且通过配置 DMA 通道和缓冲区,我们可以轻松实现高效的数据传输。
模拟外设的实现
Embassy 提供了很多外设驱动,但某些高级功能,比如差分 ADC(模数转换器)读取、Oversampling(过采样)等,需要我们自己定义和实现。通过 Embassy 的灵活性,我们可以轻松扩展外设功能。
信号处理系统的应用
我们还开发了一个基于 AD724 芯片的信号处理系统,用于采集和处理微小信号。通过 Embassy 的 DMA 和 ADC 支持,我们可以高效地采集和处理信号,并通过 Rust 实现高效的信号处理算法。
实时性的保证
虽然 Embassy 是一个协作式多任务处理框架,但通过使用软件中断(SWI),我们可以实现抢占式的任务调度,保证系统的实时性。在一些高实时性要求的控制系统中,比如电流控制、功率控制等,我们使用高优先级的中断来确保任务的及时执行。
总结
通过 Embassy,我们成功实现了模块化的硬件开发,极大提高了开发效率和产品的稳定性。Embassy 提供的异步编程模型和硬件抽象层,很好地解决了我们在单片机开发中的诸多问题。我们未来也将继续基于 Embassy 开发更多的产品。
多种处理方式,在一些实时控制中,我们可以通过这种形式使其实时性更高。刚刚提到的内容是一个简单的高阶电源管理系统的实现。接下来,我们将通过一个微小信号处理系统,基于ADI的一块AD724芯片,继续深入了解我们的核心应用。
在一些仪器中,我们会处理大量的生物电信号或气压信号。这些传感器给出的信号值非常低,通常只有20毫伏左右。我们需要通过一套硬件放大电路、软硬件滤波等手段对这些信号进行处理,最终再将数据读出。读出后的数据可以上传到服务器或通过串口传输。基于AD724,我们设计了一个模块,这个模块可以应用于多个项目中。
介绍 AD724
AD724 是由ADI公司生产的一个八通道、低功耗、24位的Σ-Δ型DAC,最高支持2kHz的采样率。同时,它支持双极性输入,每个通道都可以独立配置。我们之所以选择这款芯片,是因为它内置了一个PGA(可编程增益放大器)和一个高精度的基准电压源。通过使用AD724,我们可以省去外部的仪表放大器和基准电压源,这样可以简化电路设计并减少信号干扰。
我们通过SPI接口对AD724进行配置和数据读取。首先,我们发送8比特的命令(CMD),接着通过返回的两到三位数据对寄存器进行配置。由于Embassy中的异步SPI需要通过DMA实现,我们的代码首先书写了这一部分,以实现异步SPI。然而,对于某些不支持DMA的外设(例如L4系列的SPI3),我们可以通过阻塞的方式使用DOIN和IC来实现异步操作。我们在项目中也实现了这一点。
IO复用问题
在使用AD7124时,存在一个IO复用的问题。我们的SPI数据传输口,同时需要作为读取信号的发送口。然而SPI已经占用了这个外设的所有权,在这种情况下,我们需要通过一些方式来实现GPIO的复用。例如,可以使用safe方法,简单一点的方式是通过pack来实现。更极端的方式是直接读取内存值,因为我们只需要知道读取信号是否已经拉低。为此,我们甚至可以使用汇编语言来实现相关操作。
多任务共享外设
在多任务共享外设的情况下,我们使用了互斥锁(MUTEX)来实现对GPIO的访问控制。对于SPI或I²C等外设,我们还使用了共享总线(share bus)的实现方式。如果有兴趣,可以进一步查阅相关资料。完成这些配置后,我们就可以开始实现驱动。这部分反而是最简单的,我们只需要根据数据手册逐行实现。由于SPI配置涉及到一些寄存器列表,我们实现了一个虚拟的寄存器列表,以减少读取次数。这个列表包含了内存值、大小以及读取属性。
我们还基于Rust的错误处理机制,设计了自定义错误处理类。SPI操作中的错误将被传递到这个类中进行处理。Rust的文档生成功能也非常方便。通过这一整套流程,我们实现了一个高精度的采样驱动。
其他EMC应用
我们还在其他项目中使用了Embassy框架。例如,我们使用RP2040实现了一个高精度的位移控制框架。通过RP2040硬件的PIO(可编程输入输出),我们可以将其用作一个简单的控制器,实现快速IO操作,并用于电机控制。除此之外,我们还使用ESP32实现了一套无线自组网的应用层系统。
ESP32是一个较早支持Rust的芯片,乐鑫公司提供了两套库。第一套是ESP-IDF库,它基于FreeRTOS的Rust绑定,实现了标准库(STD)支持,能够应用于更多的网络协议(如网络和蓝牙)。另一套是Espressif的long-asynchronous库,它基于异步编程模型,但目前对WiFi的支持较少。根据项目需求,用户可以选择不同的库进行开发。
总结与思考
关于单片机应用的安全性问题,业界一直存在争议:单片机是否应该使用Rust?传统的单片机工程师更倾向于直接操作硬件,而在Rust中,很多操作需要使用unsafe块。不过,我们在开发过程中发现,大多数外设操作并不需要unsafe,除非遇到IO复用等问题。在这些情况下,我们可以通过unsafe代码解决问题。
例如,在embedded-sdmmc库中,SPI接口是临时借用的,这样可以避免完全占用SPI所有权,从而更好地实现IO复用。这种方式或许更适合单片机开发。然而,Rust的生态目前还处于早期阶段,尤其在单片机开发领域。许多API变动频繁,原厂的支持也较少。我们需要更多的社区支持,才能让更多的厂商和开发者愿意使用Rust。
未来展望
尽管Rust在单片机领域的应用还处于初期,但随着社区的发展和更多应用框架的出现,我们相信Rust在嵌入式系统中的前景会越来越广阔。
我的演讲到此结束,感谢大家的聆听。如果有问题的话,欢迎交流。
主持人:感谢陈昱衡老师的精彩演讲!接下来是提问环节,我们有请两位观众向陈老师提问。
观众1:陈老师,您好!我有两个问题。第一个是关于单片机上SPI和I²C的实现问题,刚才您也提到了相关内容。第二个问题是,您是否对比过C和Rust在单片机上的资源消耗情况,比如CPU和内存的消耗?另外,单片机上调试的流程如何?谢谢。
陈老师:好的,我先回答第二个问题。Rust编译出来的代码体积确实比C大一些,尤其是我们使用了Embassy框架后,代码体积会进一步增加。Embassy通过静态化处理所有任务,会占用更多堆栈空间。这也是为什么我们强调模块化开发,这样可以绕开Rust的一些弊端。虽然资源占用较大,但在当前的SoC资源下,处理单一任务(如传感器数据读取)已经足够了。
至于单片机的调试,我们使用probe-rs,这是一个调试器,可以下载并调试代码,也可以集成到VS Code中进行调试。最终编译出来的就是一个hex文件,传统的调试方法也可以使用。不过,由于异步任务的存在,调试起来确实比传统的嵌入式开发要复杂一些。但因为任务较为单一,所以调试难度并不大。
主持人:谢谢这位观众的提问,请工作人员为观众发放赠书。下一位观众请举手。
观众2:陈老师您好!我是来自英飞凌的。刚才您提到使用STM32系列产品,能否具体说明一下型号?另外,我想了解一下Rust的标准库支持不够完善时,是否会使用C语言库进行混合编译?
陈老师:我们使用了多个STM32系列产品,从L系列到G系列都有应用。根据不同的业务需求,简单的任务可以使用G0系列产品。
关于Rust与C的混合编译,我们最初确实尝试过Rust与C的绑定,但后来发现,如果我们选择Rust开发,为什么还要继续依赖C呢?我们更希望使用纯Rust的开发方式,特别是Embassy引入了异步编程模型,这是C语言不具备的。我们选择Rust不仅仅是为了安全性,也因为它在某些方面提供了C无法实现的优势。
!!!
22.OS 训练营的教学演进和人才培养 - 李明
下来我们欢迎清华大学开源操作系统社区负责人李明老师,为大家分享 OS 训练营的教学演进和人才培养。
本次讲座旨在总结回顾清华大学开源操作系统训练营过去 5 年的发展历程,特别是其在智能汽车、AI 大模型、智能硬件等前沿领域的合作与拓展。同时,通过数据分析与案例解读的方式,深入剖析最新训练营平台 OpenCamp.cn 的学员情况及学习路线。
李明:
谢谢陆嘉的精彩介绍!嗯,刚才我坐在最后一排,PPT 看不清楚,我能体会那种看不到的感觉。所以我想第一时间把讲稿分享到群里,大家可以在群里打开,方便看一些数据。
我是来自清华大学开源操作系统社区的负责人李明。其实这已经是我第二次来到这个会场了,去年我们也做了演讲,介绍 OS 训练营。
在我介绍 OS 训练营内容之前,先做个调查:现在在校生请举手?哦,全都是工程师啊!好,前面两个讲得非常技术,内容很“干货”,我这部分偏教育,大家可以稍微放松一点。我的演讲分为四部分:回顾、总结、计划、展望。
首先,回顾一下我们 5 年的历程。从 2020 年到 2024 年,开源操作系统训练营最早是 5 年前由陈毅老师和向文老师发起的。当时,清华操作系统课每年只有 100 多人上课,写操作系统的人更少。两位老师希望影响更多高校学生学习 Rust 写操作系统,所以在 2020 年暑假举办了第一期训练营,当时有 50 个同学报名。
大家可以看到右边的图片,这是一个学生学习两个月的日记,记录了每天的学习内容,至今还能在 GitHub 上访问。疫情影响下,线下训练营没能扩大,所以转到了线上。我是 2022 年夏季加入,与陈老师、向文老师一起商量,将训练营完全转为线上。
过去 5 年我们做了 7 期训练营,从最初的 50 人,到今年上半年报名人数超过 2900 人。前三届只有 200 到 400 人,到了去年秋冬季就有 1500 人,今年秋冬季预计会超过 3000 人。Rust 学习群体基础越来越好,特别是在 2021 年,全国大学生系统能力大赛的两个赛道——内核实现和内核功能挑战——与训练营形成相辅相成的关系。
接下来,讲解一下 OS 训练营的学习方式。大家可以看这张图,经过几期的调整,浓缩成了四个阶段:
- 导学阶段:两周时间,面向高校和企业工程师开放。统计数据显示,本科生占了一半,研究生占 20%,其余是工程师。
- Rust 编程阶段:零基础学习 Rust,提供 100 道练习题。大约一半的学员能完成。
- 操作系统学习阶段:学习体系结构和操作系统。这个阶段淘汰率较高,只有 5% 的学员能通过。
- 项目阶段:提供实战性项目,涵盖八个方向。今年还引入了企业命题,让企业带领项目。
最后是 实习阶段,大约 3% 的学员能进入实习,实习分为清华、亦庄和济南的基地,暑假和寒假提供实习机会。
接下来是 训练营的数据总结。到目前为止,已有 7096 名学员注册,覆盖了 1200 多所高校和 1061 家企业。我们还拓展了多个训练营,包括自动驾驶、AI 大模型、奥莱操作系统等。
其中,奥莱操作系统是我们今年的第一次拓展,基于 C 语言,效果不错,第一期有 700 多人报名。起源实验室则基于 Rust 写大模型推理引擎,第一期就有 1000 多人报名。飞腾公司推出了与树莓派对标的“非同派”,训练营中我们用 Rust 操作系统控制智能小车。
计划部分:我们推出了 “十城百校”计划,推动训练营在重点城市的高校推广。今年训练营平台上有 106 位高校联系人,帮助组织学习小组和俱乐部。企业也可以发布实习岗位,我们今年暑假发布了 6 个岗位,27 人申请,10 人通过。
我们还推出了 卓越人才培养计划,欢迎企业发布带薪实习岗位,并提供有挑战性的研发任务。所有训练营学员报名时都提交简历,企业可以筛选。
最后是 展望:我们希望继续为高校和企业培养更多人才,目标是培养具备专业技能、解决实际问题、提出创新想法、团队协作能力的学生。同时,我们还将大力拓展与企业的合作,搭建高校与企业之间的桥梁。
我的分享就到这里,谢谢大家!
!!!
23.定制 Rust 标准库实践在 ARMTrustZone(OP-TEE) 平台构建 Rust 开发环境 - 庄园
接下来我们热烈欢迎 CertiK Skyfall 团队安全研究员庄园老师,为我们分享《定制 Rust 标准库实践:在 ARM TrustZone (OP-TEE) 平台构建 Rust 开发环境》。
本次演讲以 OP-TEE 平台为例,探讨了在资源和功能受限的系统上为开发者提供 Rust 开发环境的挑战和经验。演讲还将介绍如何利用系统原生能力定制 Rust 标准库,拓宽应用开发的可能性,并分享在实践过程中遇到的具体问题及解决方案。接下来让我们把时间交给庄园老师。
大家好,我叫庄园,先自我介绍一下。我是 CertiK 公司的安全研究员,我所在的团队是 Skyfall 团队。我们主要从事传统安全和区块链安全相关的漏洞研究,也会基于先进技术提供 Web3 安全解决方案。我在团队中主要负责 TEE(可信执行环境)相关的隐私计算工作,同时也是 Apache Teaclave 开源社区的 PPMC 成员,以及 Teaclave TrustZone SDK 项目的主要维护者。
今天分享的题目是《定制 Rust 标准库实践:在 ARM TrustZone (OP-TEE) 平台构建 Rust 开发环境》。听起来题目很长也很复杂,主要是讲解关于 TrustZone 的内容。包括:
- 什么是 TrustZone?
- 为什么需要 TrustZone?
- OP-TEE 是什么?它与 TrustZone 的关系是什么?
- OP-TEE 为什么需要 Rust?
- 为什么需要 Rust 标准库?
在座的各位可能是 Web3 的从业者,或许听说过 CertiK 安全公司,也有可能对隐私计算和 TEE 感兴趣,或者是在往届的 RustConf 中听过 Teaclave 社区及其他社区的介绍。或者你是做嵌入式系统开发的,希望了解为一个新的目标平台移植标准库相关的工作和问题。希望本次分享能为大家提供一些参考。
因为我们是 Web3 的安全公司,对于安全公司来说,用户资产的保护是核心问题。我们以这个场景为例来展开后面的内容。
首先,对于 Web3 资产来说,资产是通过钱包管理的。就像我们使用支付宝一样,当发起转账时,系统会验证用户的签名。用户通常有一对公钥和私钥,发起转账时,用户会用私钥对转账内容进行签名,然后将签名发送到区块链网络,网络验证签名是否由该用户的私钥生成。如果用户的私钥泄露,任何人都可以用它来转走用户的资产,因此私钥的保护非常重要。
在移动端,私钥可能存储在设备的文件系统中。如果设备上安装了恶意软件,它可能窃取用户的私钥。私钥保护是 TEE 的常见使用场景之一。TEE 可以抵御客户端的安全风险,比如恶意软件。通过在 TEE 中生成、存储和使用私钥,可以大大降低恶意软件攻击的风险。
ARM TrustZone 是 TEE 的一种实现。今天我们有其他讲座提到过 Intel 的 SGX,它是 Intel 针对 TEE 的实现。对于 ARM 芯片,ARM 提供的 TEE 实现叫做 TrustZone,它提供了硬件级别的隔离。我们可以想象它是一块专门处理安全任务的硬件。TrustZone 提供硬件隔离,但我们还需要在硬件之上运行软件来实现功能,这里的软件包括 TrustZone 的操作系统和应用程序。
与 Intel SGX 相比,ARM TrustZone 的优势在于 ARM 芯片在移动端的市场占有率非常高,达到90%以上。因此,基于 ARMv7 或 ARMv8 的设备普遍支持 TrustZone。在移动端,使用 TrustZone 作为钱包的解决方案更加合适。
各个厂商都有自己的 TrustZone 实现,比如三星的 TrustZone OS 叫做 TEEgris,高通的叫做 QTEE。而开源的 TrustZone OS 实现中,使用最广泛的是 OP-TEE。它是开源的 TrustZone 操作系统,且提供了丰富的样例程序。
右下角的图展示了 TrustZone 将设备分为 Normal World 和 Secure World 两部分。在 Normal World 中运行的系统比如 Android,提供用户需要的功能。在 Secure World 中运行的则是 TrustZone OS 比如 OP-TEE,在其上可以运行可信应用(TA)。
以 Web3 密钥保护为例,我们可以在 Secure World 中写一个 TA 来实现生成密钥、验证交易和生成签名的功能。OP-TEE 的可信应用可以由开发者自己开发,称为 OP-TEE TA。由于 TA 运行在高安全级别的环境中,我们需要确保它的安全性。
传统上,OP-TEE TA 是用 C 语言开发的。但是,C 语言容易出现内存安全漏洞,比如内存破坏攻击,且开发效率较低。如果我们能用 Rust 开发 TA,Rust 的内存安全特性可以避免内存破坏攻击,同时提供更友好的开发接口。这就是 Teaclave TrustZone SDK 的目标,它是 Apache 基金会孵化项目之一,也是 Teaclave 隐私计算开源社区的项目之一。
我们主要基于开源的 OP-TEE OS 来进行开发。Teaclave TrustZone SDK 由 CertiK 和 OP-TEE 社区共同维护,它是目前 OP-TEE 社区官方推荐的 Rust 开发环境。使用 Rust 开发 OP-TEE TA 可以保证内存安全,并且我们为开发者提供了更友好的 API。比如,针对 Web3 密钥管理的 TA,现在可以使用 Rust 开发,代码更加安全、简洁。
使用 Rust 开发 OP-TEE TA 时,可以尝试使用第三方库,比如用于加密的 ring 库。然而,很多第三方库依赖于 Rust 标准库(STD)。如果直接移植这些库,我们还需要递归移植它们的依赖,因为它们也可能依赖 STD。因此,我们尝试为 OP-TEE target 增加对 STD 的支持。
在支持 STD 之后,我们可以利用 OP-TEE 提供的安全接口,比如随机数和安全存储。在增加 STD 支持后,使用第三方库如 ring、serde 和 rustls 变得更加方便。
Teaclave SDK 提供了两种开发模式:no_std 和 std。这样设计的原因是,TEE 的设计理念是尽量减少可信计算基(TCB),即使应用功能较少,使用 no_std 就能满足需求。此外,将所有功能都放到 TA 中也没有意义,TEE 中只应运行最关键的安全代码。因此,SDK 为开发者提供了两种模式,方便开发者根据项目实际情况选择。
刚才我们讲了背景知识,比如 TrustZone 和 OP-TEE 是什么,为什么需要 Rust 以及 Rust 的 STD。接下来进入比较细节的部分,分享我们最近在 Teaclave SDK 上完成的 STD 升级过程。我们将过程分为三步:实现、编译和测试。
第一步是从零开始实现。我们首先克隆 Rust 源码,并在 Rust 的 libstd 中新增一个 OP-TEE target。每个 target 都有自己的模块实现,比如 I/O、进程、线程等。对于某些 target-specific 的内容,我们需要自己实现,而对于通用的模块,比如 Mutex、RwLock 等,我们可以直接使用现有的实现。
接下来,我们在 libstd 的 PAL 层增加了 OP-TEE target 的目录。这个目录中应该包含什么内容呢?PAL 层中有一个 unsupported 目录,里面列出了所有可以为新 target 实现的模块。我们可以先把这些模块拷贝到 OP-TEE 目录中,再逐个实现它们的接口。
由于 OP-TEE 是一个资源受限的系统,内存只有 20 多兆,且只支持单线程,因此无法像 Linux 或 Android 那样提供完整的 STD。但我们可以为 OP-TEE 提供部分 STD,以满足第三方库的使用需求。
在 unsupported 目录中拷贝的模块,我们可以大致分为三类:
- 第一类是
args、env和fs相关的模块。OP-TEE 不支持文件系统,因此我们暂时选择不支持这些模块。 - 第二类是
alloc。OP-TEE 的原生libc也支持alloc,因此我们可以调用 OP-TEE 的原生libc实现来支持alloc。 - 第三类是
thread_local。OP-TEE 是单线程的,因此不支持thread_local,但我们发现HashMap依赖于thread_local,因此我们在 Rust 中进行了实现。
接下来我们通过具体例子,说明 alloc 和 thread_local 的实现。
第一个例子是 alloc 的实现。我们从 unsupported 目录中拷贝了 alloc 模块,并实现了其中的接口。在 OP-TEE 中,我们调用了 Rust 的 libc 中的 malloc,而这个 malloc 最终会调用 OP-TEE 支持的 libutils。
在右边的图中,我们实现了一个关于 OP-TEE 的 alloc 例子。对于 OP-TEE 来说,它的 alloc 应该怎么做呢?我们在 OP-TEE 的 alloc 实现中调用了 Rust 的 libc 的 malloc,这个 malloc 会调用我们移植过的一个 Rust libc,而这个 libc 也提供了 OP-TEE 的支持,最终是一个 libc 的绑定。
接下来的例子,我们参考了其他产品来实现一些模块,比如刚才提到的 thread_local。在实际运行过程中,发现 thread_local 被 HashMap 依赖,但 OP-TEE 的 libc 中没有 thread_local 的相关接口。thread_local 需要做的操作包括创建、设置、获取以及销毁线程内部的资源。我们参考了另一个单线程的 target,叫做 ZKVM,并实现了一个内存中的 thread_local。我们刚才说的两个分类,都是在尽量支持 Rust std 库中能支持的模块,但这里还有一个特例。
对于 TEE 来说,安全性永远是最重要的。我们需要区分 OP-TEE 的一些 API 是否安全。比如 OP-TEE 的 time API,它的底层时间数据来源于不可信的系统事件(如 Linux 系统的系统时间),而系统时间是可以被修改的。因此,我们希望给开发者一个提示:在调用 time API 时,时间数据的来源是不可信的。为了提醒开发者注意这个问题,我们没有在 std 中实现这个 API,而是在 Teaclave TrustZone SDK 中提供了相关接口,以便开发者知晓这个 API 的数据来源是不可信的。
接下来我们已经完成了 Rust 源码中为 OP-TEE 新增 target 的 std 库实现,下一步是希望在编译运行于 OP-TEE 上的应用时,使用我们本地修改过的 OP-TEE 的 std 代码。比如在交叉编译时,我们通常用 rustup target add 来安装一个 target(如 aarch64),这一步会下载官方预编译的 std 库。然后我们用 cargo build,指定 target 为 aarch64 来编译程序。现在我们希望在编译运行于 OP-TEE 上的程序时,使用我们本地编译的 std 代码。
要实现这一点,流程分成两步。第一步是新增 OP-TEE target 的配置文件,可以通过以下三步完成:首先生成一个配置文件,然后修改配置文件,最后使用配置文件。OP-TEE 基于 ARM 架构(32 或 64 位),所以我们可以先生成一个基础的 target 配置模板。可以通过 rustc --print target-spec-json 来生成模板,然后根据 OP-TEE 的特性修改配置文件,比如将 linker 改成 ld.lld,将 singlethread 设置为 true,因为 OP-TEE 是单线程的。最后一步是编译时通过 RUST_TARGET_PATH 来指定这个配置文件的路径。
生成了 target 的 JSON 配置文件后,下一步就是编译 OP-TEE target 的程序,并构建 std 库。我们尝试了两种方法,分别是 xargo 和 cargo -Z build-std,并进行了对比。
第一种方法是使用 xargo。它的使用方法比较简单,首先用 cargo install xargo 安装 xargo,然后新增一个 Xargo.toml 文件,指向我们修改过的 std 源码路径。接着用 xargo 代替 cargo 来构建程序。这种方式的优点是,xargo 项目从 2016 年就开始开发,使用过程中没有发现什么 bug,使用方法也比较清晰。但缺点是,官方从 2020 年后就不再更新 xargo,可能与最新版的 cargo 特性不兼容,而且需要安装额外的软件。
第二种方法是 cargo -Z build-std,这是 cargo 自带的编译配置,也是官方推荐的 build-std 方式。使用方法也非常简单,首先导出 Rust 源码路径,在 cargo build 时加上 -Z build-std 选项即可。它的优点是使用 cargo 自带的功能,无需安装额外工具。不过我们遇到一个 bug,导致没有选择这种方法。这个 bug 是当我们通过 patch 替换依赖库时,patch 操作并不会生效。结合我们的场景,比如刚才提到的 alloc 例子,我们移植了一个 Rust 的 libc,并为 OP-TEE 新增了 target,最终会调用 OP-TEE 原生的 libc。我们期望在构建 std 时依赖我们修改过的 libc,但由于 patch 不生效,导致编译时仍然使用上游的 libc,无法通过编译。这个问题已经有人在 GitHub 上提交了 issue,但目前还没有进展。因此我们暂时选择了 xargo 方案。
最后一步是测试。我们使用了 mir 来跑 std 库中的测试用例,通过 skip 跳过 OP-TEE 不支持的模块。
回到我们的主题,通过对 std 的支持,我们可以使用更多第三方库,比如 ring、完整的 serde、rustls 等等,从而支持构建更加复杂的可信应用。比如我们最早提到的 Web3 钱包的场景,通过 SDK 和 std 支持,我们实现了一个 Web3 钱包的示例,包含密钥生成、账户地址派生以及为交易签名等功能。右下角是我们提供的命令行界面,地址已经放在幻灯片上,大家有兴趣可以参考并实现自己的 Web3 应用。
如果大家对隐私计算、TrustZone 或 OP-TEE 开发感兴趣,可以参考我们的 Teaclave TrustZone SDK。我们最近发布了 0.3.0 版本。如果对为其他系统移植 std 和 libc 感兴趣,也可以参考我们之前移植的代码,链接已经放在幻灯片上。如果对其他隐私计算项目(比如 Intel SGX 的 Rust SDK)感兴趣,也可以关注我们的 Teaclave 隐私计算开源社区。幻灯片应该会分享给大家,有问题也可以随时联系我。
提问环节
观众 1:你好,我比较感兴趣你 PPT 开头讲的 Web3 钱包应用。你提到密钥生成是在 TEE 环境中完成的,但 TEE 里没有文件系统的能力。那么密钥生成完之后,是否需要把它拿到外部环境?
讲者:OP-TEE 有一个 secure storage,可以提供类似文件系统的功能。虽然功能有限,但可以存储文件。存储的内容最终保存在普通操作系统(如 Linux)中,但它是加密的,相当于在那边做了加密存储。
观众 1:那么程序重新启动时,还是可以读取之前存储的内容吗?
讲者:是的,程序可以重新读取内容。
观众 1:如果操作系统重装了,或者硬件替换了,但没有替换 CPU 和 TPM,这里面的内容还存在吗?
讲者:加密文件存储有不同选择,可以选择存储在 Linux 文件系统中,或者存储在另一个芯片中。如果存储在芯片中,即使操作系统重装也不会影响。
观众 1:那是否最好还是将私钥保存在外部冷存储中?
讲者:不一定非要外部冷存储,比如 RPMB(Replay Protected Memory Block)也可以。
感谢观众提问。接下来还有一位观众提问。
观众 2:你在演讲中提到已经支持一些椭圆曲线签名。未来是否会支持其他签名方式,比如 passkey?
讲者:是的,我们内部正在做这方面的尝试,包括 BTC 的签名等其他方式。
感谢老师的精彩演讲。
23.定制 Rust 标准库实践在 ARMTrustZone(OP-TEE)平台构建Rust开发环境-庄园
用豆包整理的~—-看起来不太行
- 定制 Rust 标准库实践在 ARMTrustZone (OP-TEE) 平台构建 Rust 开发环境 - 庄园
https://www.bilibili.com/video/BV11NsUecELW/
首先,欢迎 CERTICSKYFALL 团队安全研究员庄园老师为我们分享定制 rust 标准库实践,在 arm trust zone op tee 平台构建 rust 开发环境。本次演讲以 OPTEE 平台为例,探讨了在资源和功能受限的系统上,为开发者提供 rust 开发环境的挑战和经验,也将介绍如何利用系统原生能力,定制 rust 的标准库,拓宽应用开发的可能性,并分享在实践过程中,遇到的具体问题及解决方案。接下来让我们把时间交给庄园老师。
大家好,我叫庄园,我先自我介绍一下,我是 thirty 公司的安全研究员,我所在的团队是 surface,该团队会做一些传统安全,还有区块链安全相关的漏洞研究,也会做一些基于先进技术的 web three 的安全解决方案。我在我们团队主要是做 TEE 相关的隐私计算相关的事情,同时我也是阿帕奇 tek live 开源社区的 PPMC,是 t cleave 插送 SDK 的主要维护者。我们今天分享的题目是定制 rust 的标准库实践,在 transform op tee 平台构建 rust 开发环境,听起来好像很长也很复杂,主要是要讲到关于 transform 是什么,为什么需要 transform 以及 OPTEE 是什么,它和 transform 的关系是什么,我们 OPTEE 为什么会需要 rust,我们为什么还需要 rust std。
在座的各位可能是 web three 的从业者,可能听说过香水这个安全公司,也有可能是对隐私计算,对 pee 感兴趣,或者是在往届的 RASCCOT 里面听过关于 tic live 社区以及其他社区的介绍,或者是做嵌入式系统,希望能够了解我们为一个新的 target 去移植标准库,相关的我们要做什么,会遇到什么问题,以及我们是怎么解决的。希望我们本次分享可以为大家关心的这些话题提供一点有用的参考。
因为我们是一个 web three 的安全公司,对于安全公司来说,用户资产的核心保护是一个非常核心的问题。那么我们就以这一个例子为例,来讲解后面的内容。首先对于 web three 的资产来说,他的资产也是使用钱包管理的,就像我们在外铺里面去使用支付宝一样。发起转账的时候,不一样的地方在于我们的交易是去验证用户的签名。用户他都会有一对公私钥,用户在发起转账的时候,会用私钥对这个转账的内容进行签名,然后发到区块链网络上,网络去验证这个转账是不是用户授权的,是不是合法的,就是来验证这个签名是不是这一个用户私钥签的。所以说呢用户私钥是非常重要的,用户私钥如果是泄露的话,那就直接相当于任何一个人都可以拿他的私钥来去把他的钱转走,就相当于他的资产也就损失掉了。
那么用户的私钥我们应该要怎么去管理呢?如果是刚才说到的,我们是用钱包的 app 来进行这个转账操作的,如果是用钱包的 app 来进行管理的话,他可能会存在它自己的存储里面,比如说存在一个文件里面。那对于移动端来说,如果有恶意软件安装在这个设备上,它就很有可能会窃取用户的私钥。所以私钥保护呢是一个可信执行环境,也就是 TEE 的一个常见的一个经典的使用场景,它可以抵御钱包在客户端存在的安全风险,比如说刚才提到的恶意软件等等安全风险。如果我们在另外一块隔离的安全区域,也就是 TEE 里面去生成存储,还有使用我们的私钥,那就可以大大降低 LINUX 与安卓系统上面的恶意软件去攻击,去窃取资料的这个风险。
那么 arm transform 呢它是 TEE 的一种实现,我们今天也有别的 talk 提到了,比如说 INTEXJX,它是另外一种是 INTEL 对于 TEE 的实现。那么对于 arm 的芯片来说呢,arm 公司它的它提供的实现就叫做 trust st,它是能提供了硬件层面的隔离,我们可以想象成它是提供了一块安全的处理用户的安全程序的一块硬件。那么我们在这个硬件之上呢,还要运行我们的软件,才能实现我们需要的功能。那么软件呢就包括传送的 OS 和传送的 app。
arm x slow 和 INTEXJS 相比呢,arm 的芯片在移动端的占有率是非常非常高的,大概是 90% 以上。所以呢现在基于 arm v7 或者 A8 芯片的设备,现在都是支持传送的。所以在对于钱包在移动端的解决方案的这个实现,我们实现在 transform 上面是更加合适的。
对于各个厂商都会有自己的传送的实现,我们知道我们手机上有可能会有三星手机,然后有苹果手机。对于三星来说,他自己的传送 OS 的实现叫做 t grace,高通也有自己的传送实现叫做 qte。那我们对于开源的 TRASOS 的实现呢,有一个使用最广泛的一个开源的实现,叫做 OPTEE,它是开源的 O 插送的 OS,并且它还提供了一些丰富的样式的程序。我们的右下角这张图,就是说传送把设备分成了 number word 和 SECURREWORD 两个部分。在 number word 我们运行着我们的 rituals,就比如说我们的安卓系统,它可以提供各种各样我们用户需要的功能。在 SECURWORD 里面呢,就是运行我们的 transform 的 OS,就比如说是开源的 OPTEOS。然后在 OOS 之上呢,我们就可以运行 OOPTE 的 TA,也就是可信应用。就拿刚才的 web three 的例子,就刚才我们提到的 web three 密钥保护的例子来说呢,我们如果去实现这个解决方案的话,我们就相当于是在 secure word 里面写了一个 TA,去实现我们刚才需要的生成密钥验证交易,还有生成签名的这些功能。
但是我们刚才提到了 OPTEE,它我们可以自己去开发 OPTEE 的可信应用,就叫做 OPTEE 的 TA 它的开发,因为它是相当于运行在一个更高等级的环境里面的程序,我们更需要保证它的安全性。对于它原来的时候呢,是使用 C 语言来进行开发的。首先大家都知道,C 语言很容易出现内存安全漏洞,比如一些内存破坏的攻击,并且对于开发者来说,使用 C 语言去开发程序,效率实在是比较低,不够友好。所以如果我们能够用 rust 来进行开发,首先 rust 的内存安全特性,就可以去避免这些内存破坏的攻击,并且我们还可以提供更加丰富的上层的接口,来供大家供研发人员去使用。
所以这个就是 tick live 传送 SDK 的无提格雷五传送,S dk,是给在 OPTEE 平台上,开发可信应用的开发人员来使用的,他是阿帕奇基金会的孵化项目,也是 T 克雷姆隐私计算的开源社区的项目之一。我们主要是在开源的,刚才提到的开源的 OPTEOS,开源的 TEO SOPTE 上来做的实现,目前呢主要是由 thirty,也就是我们还有和 OPTEE 社区,共同来维护的。这个提格 live 传送 SDK 呢也是 rust,也是也是 opp tee 社区,现在官方推荐的 rust 的开发环境。而我们的优势就是我们使用 rust 去开发 opp tee 的 TA 可以保证内存安全,另外我们还给开发者提供了更好的,更友好的生存服装,就比如说我们刚才提到的,web3 的密钥管理的那个 ta,我们现在就可以用 rust 来进行开发了。
我们在 rust 里面,首先写代码会更加的方便,然后也可以保证内存安全。另外一个好处呢,就是我们也可以尝试去使用 rust 的那些第三方库,比如说 rain 加密,用来加密的 rain 啊等等。那我们在使用第三方库的时候,就会遇到一个问题,我们第三方库比如说 rain 它是依赖 STD 的,如果是直接去 port 这个 rain 的话呢,我们还要去递归去 port 它哎 rain 的那些依赖,因为他们也可能是依赖 STD 的。所以呢我们就想尝试着去为 OPTEE 这个 target,去支持 STE。在支持 CD 之后呢,我们可以看右下面的那张图,在我们 NOVA stt 的时候,我们也可以有 opp t t 的一些安全接口,是可以使用的,比如说 random 还有 secret storage 之类的。但是我们在增加了 STT 的支持之后,我们可以更方便的使用第三方库,就比如说 ring,还有完整的 third,还有 TLSRUS 等等。
我们在 SDK 里面提供了 NO std 和 SD 两种开发模式。这样的考虑是,因为我们对于 TEE 的设计理念来说,我们需要尽量的去把,尽量的去达到最小的可信计算机,也就是 XC 的 computing base。如果是我们的应用的功能是比较少的,我们用 nos tt 就可以满足的话,那我们就可以使用 NSTT,不用去 enable std。是因为如果我们把所有的功能都放到 T1 中,那 T1 这个隔离其实也就没有意义了。我们应该在 TEE 中,保证最关键的那些安全的代码,是在第一中运行的。所以呢我们为 I 额 SDK 的开发者,SDK 使用者,也就是可信应用的开发者,提供了 STD 和 nos t 两种开发模式,这样开发者可以在开发的时候,根据项目的实际情况,然后来决定到底使用哪种模式。
我们刚才说了,说的都是一些背景,比如查送呃 OTEE 是什么,我们为什么需要 rust,以及我们为什么需要 rust std。然后下面的内容呢就是比较细节的内容了,就是我们最近在 TIKLISDK,也是完成了一次对 STA 的升级。我们下面的内容主要是分享怎么从理论开始,对一个 target,就比如说对 OPTEE 这种资源受限的系统,来实现一个 STD。我们把这个过程分线分成了实现编译和测试三步。
首先第一步,因为从零开始嘛,我们第一步肯定就是先去克隆一下 rust 的源码,然后我们要做的呢就是在 rust 的 PA,然后层去新增一个 target,就比如我们这个例子,我们是新增了一个 OPTEE 的 target。这些 target 呢他们都有单独的依赖的,单独的自己的模块的实现。就比如说这个左边那张图,PL 层我们可以实现 I/O process thread 等,这些都是对于 target pacific 相关的内容,然后他还有一个 common 的依赖,就是比如 new text rw blog 这些,这些对于我们的 opt e 这个 target 来说,是不需要自己实现的,我们用 common 里面去实现好的这些模块就可以了。
那我们刚才说到,在 PL 层里面新增了一个 opp tee 的 target,opp tee 的目录,相当于。那这个目录里面的内容应该是放什么东西呢?在 PAL 层里面还有一个 unsupported,就是右面这张图,on spoi 里面相当于放了我们所有在实现一个新的 target 的时候,可以去实现的模块。目前这些文件呢它都只是一些接口,我们我们要做的呢,就是去先把先把这些文件可以先,拷贝到 opp t t 的目录里面,然后再去修改这些文件,去实现每一个文件里面,去去实现每一个文件里面的接口。因为刚才也说了,OPTEE 它是一个受限的系统,它的内存大概只有 20 几兆,然后它也不支持多线程,它是只能单线程的,所以它是和嵌入系统是比较类似的。OPTOS 呢也并不可以像 LINUX 安卓一样,提供一个全面的一个 STD,但是呢我们 VOPTEE 提供一个部分的 SDD,它也是有意义的,也是可以满足对应的第三方库来使用的。
刚才我们说的,从 unsupported 里面拷贝的那些模块,我们在这个表里面的最左边那一栏,大概分成了三类。第一类就是 ARSENVFS 这些相关的,我们把它分成了一类,因为刚才说的 OPTEE 它是不支持文件系统的,所以 opp 奇 E 原生的那个 C 也是不支持的。那因为我们考虑现在在 rust 里面,也没有去调用这些模块相关的需求,所以我们目前就选择了不支持。
第二个分类就是 ELOP,就是第二行。对于 i lock 这种模块来说呢,OPTEE 的原生 lib c 是支持的,它是其在它的原生类 BC 叫 live utils,它是提供了包括 block 之类的这些接口。那么这些我们就需要在 rust s TV 里面去支持,去调用原生的 lab c 的接口就可以了。
第三个分类就是比如说 swag local key。OPTEE 刚才也说了,因为它是单线程的嘛,所以它是不支持的。但是我们在实际的测试过程中发现,我们的比如 HASHMAP 这个这种重要的模块,它是依赖所和 P 的。所以我们就在 RUSS01 中中做了实现。
下面呢就是对我们这两种,一个是 i love 和 spring lol key 这两个做了实现的例子,来详细的说明一下我们是怎么做的。第一个是 ALLOP 的实现和 rust lipse 的移植。这个可能字比较小,大家可能看不太清,这个大概的意思就是说我们先从 unsupported,on supported 里面先拷贝过的那些文件,比如说 i log,然后它里面的接口现在是返回了一个 NM,我们现在要做的就是实现这个接口。我们在右边那张图里面去实现了一个,对于 opp c e 来说,它的 ALOG 应该要怎么做。我们在 OPTEE 的 ALOP 里面呢,去调用了 rust 的 lab c 的 MALLOG,然后这个 block 会调用我们 port 过的一个 rust lipc,这个 live c 也是提供了 OTEE 的支持,最终是一个 LIPC 的 bending,然后这个班的呃,然后最后掉到的呢就是这个 OPT 原生的 LIPC,就是 C 语言写的那个库,教 LBUTS。
我们第二个例子就是去参考了其他产品,来实现一些模块。就比如说我们刚才说的 thread local key,它我们在实际运行过程中发现它是被 HASHMAP 所依赖的,但是 OPTEE 的 LIPC 里面是没有 SR,local p 相关的接口的。那 threal key 他需要做的呢,它是线程内部去维护自己的资源的一个 PY6 的 mapping,他需要做的操作呢,就比如说是 create set get,还有 destroy 这些。所以我们参考了同样是 PL 另外一个单线程的 target 叫 ZKVM,那个 target 我们去参考了他的实现,但实现了一个 in memory series real i。
我们刚才说的…
的 OPTEE 的 target std 的库的实现。那下一步呢就是我们期望我们再编译一个运行在 OPTEE 上面的应用的时候呢,用的是我们自己的 STD 的代码。
比如说上面这个例子,我们知道我们平时用 RT,在进行交叉编译的时候呢,我们就是先那个步骤,就是先用 rs up for train 来安装一个,比如说 arm64 的 target,这一步呢也会下载官方预编译好的,对这个 target 的 STD 的库。然后另外我们在开发完成之后呢,就用 color build,然后去指定这个 car,这个 target 是比如是 ARQ64,然后去编译这个程序。
那么我们现在想做的呢,是我们在编译一个运行在新增的 target 的,就是 OTTE 上面的程序,并且期望这个程序使用我们本地编辑的,刚修改过的 OPTE 的代呃,OPTE 的 STD 代码。那这个如果要实现这个的话,流程是分成了两步。
第一步呢,就是我们去新增这个 o p t e target 的配置。对于新增一个 target 层,可以是用这三步比,第一步就是生成一个配置文件,第二步是修改这个配置文件,第三步就是使用这个配置文件。那对于 OPTEE 来说呢,它首先它是基于 arm32 或者是六四的,那我们就先生成一个 base stic 的模板,用可以用 rust 的 C 来生成,这就用这个 mini 来生成。然后第二步呢就是基于 OPTEE,他自己的 feature 去修改这个配置文件,比如说我们把 link 改成了 link,Flaver,改成了 ID,或者还有我们把嗯 single thread 是什么 true,因为它是单线程的嘛。第三步就是我们在编译的时候,需要指定这个创建的配置文件的路径,就是用 export 这个 rust target pass 来指定就好。
那我们现在有了一个新增的 target 的 JSON 文件之后,下一步就是去编译这个 o p t e target 的程序,就是去编译我们的 ta,编译 ta 呢编译 ta 并且 build std 呢,我们现在有两种大家用的比较多的方式,第一种就是用 SAO,第二种就是用 cargo 杠 z build std。然后这两种方式呢我们都尝试了,然后并且也做的比较,你也最后也会一会也会说,我们最后选择了哪种方式。
首先第一种方式就是用 SAO,它的使用方法也比较简单,右边这张图就是先用 cargo 安装,然后新增一个 tom czara 的点 ZORDER 淘某的文件,然后去指向我们刚才去修改过的那个 STT 的,SSTD 的源码路径,这可能也比较小,可能看不清呃。第三第三步就是去用 ZAR 狗去替代卡狗来六的,然后他这种方式的好处就是,这个项目其实是 16 年就开始开发了,我们在使用的过程中也没发现有什么 bug,然后使用方法也是比较清晰的。但它的缺点是,2020 年之后官方就没有再更新了,它有可能是和最新版的 PARO 的特性是不兼容的。另外呢还是需要安另外安装一个软件,就是 cargo 这一个 cargo 这一个软件。
第二种方式就是 cargo 杠 z build std 这种方式。右上角那个图是怎么用,就是我我大概说一下,就是嗯先 export 的一个 rust 源码的一个路径,然后在看过 build 的时候多加一个选项,就是杠 z build std,然后来进行 build。它的优点就是 cargo,它这个是 cargo 它自带的编译配置,然后也是官方现在推荐的 build std 的方式,它的使用步骤也是比较简单的。我们本来是优先选择这种方法的,但是我们在实际的额用的时候发现了有一个 bug。然后这个 bug 也就导致了我们没有选择这种方法,这个 bug 是它我们在使用 patch 点 create IO 的时候,尝试去替换里面的依赖库的时候,他这个替换是不会生效的。
结合我们的场景,就是我们在刚才提到了 ELOP 那个例子,我们是 port 了一个 rust 的 LIPC,在那个 live c 里面新增了那个 target 叫 OTTE 的 target,他最终会去调 opp t e 的呃,原生的那个 lib c 的库。这个 RUS 这个 LIPC 呢是我们改过的,LIPC 也是呃,我们期望在 std build 的时候,去 STD 去依赖的这个类型。但是由于这个 patch 不生效的问题,导致我们在 build 我们自己的 STD 的时候去,没有办法去递归的替换所有的 ABC,他仍然会去额 up,会去下载 upstream 的那个 NPC,所以这个也是编译不过的嘛。然后这个这个一直有我们在练哈佛上,已经发现已经有人提了,但是目前还是没有什么进展,所以我们还是暂时用的 ZARA 的那种方法。
啊最后一步就是测试了,我们用的是 mirror 测试哦,这个也也也也没有什么可以仔细介绍的,主要就是去跑一下 STD 里面那些 test case,然后可以用 skip 去跳过那些,我们之前对 UPTE 不支持的那些模块。
回到我们的主题,我们是现在通过了 SDG 指持之后呢,我们就可以使用更多的第三方库了。嗯这个也是刚才的那个图,就包括我们可以使用 rain 啊,完整的 third 啊,还有 rules 等等,这样就可以支持我们去构建,更加复杂的科技应用。就回到我们最早提的那个场景,就是我们的 web three 的钱包,它去密钥保护的这个场景,我们基于我们刚才的做的 SDK,以及 STT 支持,实现了一个 web3 的钱包的示例,它包含了密钥生成,还有派生账户地址,还有为一切 H 交易签名等功能。然后右下角是我们提供的一个 command line interface,然后这个地址也已经放在这个 slice 上了,大家有兴趣的话可以去参考一下,去实现自己的 web3 的相关的应用。
然后如果大家对于隐私计算,对于 transform 或者是 OPTEE 呃,去开发核心应用来感兴趣的话,大家可以去参考我们的 tick live transform SDK,我们也是在最近发了一个 release 版本,0.3.0 的版本。如果大家是对为了其他的特定的系统呃,移植 SDD 和 lip c 感兴趣的话,可以去参考我们之前移植的 SDD 和 lip c 的代码,是把把链接不也放在这里了。如果大家对其他的隐形项目,隐形计算项目感兴趣,就比如说对我们的呃,intel s k s 的 rust 的 SDK 感兴趣,也可以去关注我们的 tip live,隐私计算的开源社区,然后这个 slice 应该会,之后应该会分享给大家吧,你有分享哦。
好的,那如果大家在使用过程中有什么问题的话,也可以给我们提一手,那非常大家会非常欢迎大家进 TPR。
然后最后就是一个总结了。在我们 rust op tee,可进应用的开发场景之下呢,我们定制了 SCD,给开发者提供了更加丰富和强大的功能支持。我们分享了我们为 opp tee 来定制,run ste 的流程和步骤。然后在 RUSDSTD 启用之后呢,我们是集成到了 tick live transon SDK,作为一个我们支持的非常重要的 feature,并且开源了 web3 的钱包的设计程序。
然后我的分享就结束了,谢谢大家。
好啊,感谢老师的精彩演讲啊,接下来我们进入提问环节,我们邀请两位观众向音乐老师提问,欢迎大家举手看。
你好,我比较感兴趣,就是你这个呃 PPT 开头的时候,不是讲了一个那个 web3 钱包那个应用吗,然后我记得当时在一开始的时候就提到,是把密钥生成,也是要坐在这个呃 TEE 的环境里面的,对然后但是他这样,但是 TEE 的这个环境里面,又没有这个 FS 的这些能力,所以那么这个密钥生成完以后,还是需要把它拿到外部的这个现实环境里边来,是吧。
嗯这个地方有一个在这张图,我找一下,在这张图的右下角,在 OPTEE 呢,它有一个 supreme storage,它可以提供一个类似于文件系统的功能,当然也不是那么全面的功能,但是它可以存文件,读文件,还有可以类似文件,然后他存的这个东西呢,最终是存在了我们的瑞士 OS 里面,比如说 LINUX 里面存成了一个文件,但它是加密的,相当于在那边做了一个加密存储哦。
那那么也就是说,如果这个程序再重新启动的时候,它还是可以再进到这个环境里面,再重新读取到他之前存储过的内容。
是的是的是的呃。
呃那如果说呃如果如果是这个,假如说这个操作系统呃,我们重新重装过操作系统,或者是呃因为一些什么其他原因,我们可能这个替换掉替换过一些硬件,但是没有替换 CPU 和那个 GPM 这样的硬件,这个里面的这些内容,我这个时候我重新再安装我的钱包,硬的时候,我里面的内容还不该存在嗯。
这个是我们这个加密的文件存储,它有一些不同的选择,就是我们可以选择存在我们 LINUX 里面的文件,系统里,也可以存在另外的一个存储的芯片里面,这样的话如果是 LINUX,它重装了也不会影响另外一个芯片的内容,所以所以就是里面生成了以后,最好还是要把那个私钥呃,通过外部一个冷存储把它保存下来。
嗯也也不一定是外部的冷存数,比如说 RPMV 啊之类的都可以。
好感谢观众提问,请会场的志愿者为观众发放赠书,欢迎大家继续提手举手提问。
我看到最后就是现在已经是支持一些,就一边专官的签名,就是以后有走向,就是搞一些 pass key,或者说是其他医院以外的一些,就是签名的方法吗?
嗯是的,我们也在目前内部也在做这个尝试,包括呃 BTC1 的签名啊,其他的这种。
好啊,谢谢谢谢老师的精彩演讲啊,感谢大家感谢大家啊,我们我们本次演讲的提问环节到此结束,感谢观众的理解和支持。
嗯好谢谢大家啊,有问题也可以再加我。
24. 基于 Rust 构建高性能安全的开源EDA工具 - 陶思敏
https://www.bilibili.com/video/BV1orsmemE81/
接下来我们欢迎鹏城实验室的工程师、数字芯片设计开源平台 iEDA 开发人员陶思敏为我们分享《基于 Rust 构建高性能安全的开源 EDA 工具》。iEDA 项目是一个开源的数字电子设计自动化(EDA)研发平台,旨在提供一个开放的基础底座和后端工具。2023 年,iEDA 开始使用 Rust 语言开发部分文件解析模块和点工具,并与 C++ 混合编程,集成到整个芯片后端物理设计工具链中。Rust 的使用使得代码管理更加模块化,并有助于将模块贡献到开源社区,解决了编译依赖问题,并提升了部分模块的性能。
接下来让我们把时间交给陶思敏老师。
陶思敏老师:
各位同学、各位老师,下午好!非常荣幸第一次能够来参加 Rust 社区的大会。我是来自鹏城实验室的工程师陶思敏,也是今天第一次来这个大会。来到这里,我了解到做 Rust 的人,大部分是做区块链或者 Web3 相关的项目。今天,我们的论坛是关于嵌入式开发的部分。我想问大家,在做嵌入式或者区块链开发的时候,是否有设计芯片的需求?因为我们这个开源 EDA 工具其实主要是为了辅助芯片的设计。如果你们在做区块链加密等项目时,有定制化芯片的需求,比如 RISC-V 芯片,那么我们这个 EDA 工具能够帮助你们更好地设计芯片。
今天的主题是《基于 Rust 构建高性能安全的开源 EDA 工具》。我们开源的 EDA 工具主要是为了辅助开源芯片的设计。接下来,我将介绍我们做的一些工作。
我们的 iEDA 项目是由鹏城实验室、计算所、北京开源芯片研究院三个单位联合发起的项目。今天的主题分为以下四个部分:
- EDA 的趋势和挑战
- 我们 EDA 的开源之道
- iEDA 中的 Rust
- 我们的 EDA 培训计划“水利计划”
第一部分:EDA 的趋势和挑战
EDA(电子设计自动化)工具,大家可能在做嵌入式开发时听得比较多的可能是板级的 EDA 工具,比如设计 PCB 板的立创 EDA 等等。今天我们讲的是芯片数字设计中的 EDA 工具,它的全称是电子设计自动化。随着芯片设计的复杂度和规模的增加,特别是工艺的进步,EDA 工具需要处理的数据规模也越来越大。
在 EDA 的设计能力和芯片设计者的预期之间,存在一个“gap”。这是因为随着工艺的演进,系统级芯片(SoC)集成度越来越高。一个芯片可能同时集成 CPU 和其他 IP 模块,工艺数据量大增,需要处理的数据规模也随之增长。为了完成从 RTL(寄存器传输级)到 GDS(流片数据)的设计,整个工具链面临着越来越高的性能要求。
大家可能听说过 28nm、14nm、10nm,甚至更先进的 7nm 和 5nm 工艺。理论上,每代工艺的性能应该提升两倍,但实际上,因为 EDA 工具的设计能力和设计周期的限制,无法完全达到这种提升。
另一个趋势是芯片设计逐渐“上云”。很多像云存储或高效计算的服务已经走向云端,而 EDA 工具也不例外。芯片设计的整个过程可以在云上完成。在云端设计可以提升如绕线等环节的效率。比如在绕线阶段,使用开源 EDA 工具 On-Overload 实现了六倍的性能提升,甚至在某些连接点的优化上达到了三十倍的提升。
然而,随着 EDA 工具上云,安全稳定的运行成为了一大挑战。EDA 工具属于工业软件,往往需要长时间的稳定运行,有时一个设计过程需要运行几天甚至一周。如果出现内存问题,会导致整个芯片设计的失败。因此,传统的 EDA 公司通过大量的测试案例来保证发布版本的安全稳定性。
另一个挑战是 EDA 软件的复杂性。传统的 EDA 工具主要使用 C++ 开发,但 C++ 的依赖管理非常复杂,尤其是“菱形依赖”问题。在开源 EDA 工具中,依赖管理变得更加困难。因此,C++ 在这方面的表现不够理想,尤其是在开源项目中,代码编译和依赖管理的问题尤为突出。
我们 iEDA 项目的初衷是搭建一个易扩展、模块化、可插拔的智能 EDA 平台。2021 年我们开始开发,2023 年正式对外发布。我们发布的版本也获得了国内 EDA 顶会 ISPD(国际物理设计研讨会)物理设计赛道的认可。
iEDA 的定位是成为学术界和产业界互动的桥梁和平台。当前国内 EDA 行业发展迅速,涌现了许多初创公司。我们鹏城实验室作为科研单位,致力于做开源智能 EDA 平台,希望成为连接产业界和学术界的桥梁。
iEDA 的软件架构
我们的架构包括文件层、数据库层、管理层和 EDA 算法层等。我们的目标是从 RTL 生成 GDS,最终让芯片代工厂拿到 GDS 数据去流片完成芯片的生产。
我们 iEDA 当前主要对接“毕生一芯”项目的设计需求。“毕生一芯”是一个开源 RISC-V 处理器的项目,旨在培养芯片设计人才。毕生一芯的学员们也在使用我们的工具进行设计,并成为了我们的开发人员之一。
当前,我们 iEDA 工具从第五期开始,已经用于时序分析工具来评估芯片性能。后续第六期将引入功耗分析工具和物理设计工具。
整理后的内容:
我们 iEDA 项目,刚开始开发时就考虑从开发语言的层面来降低运行风险。当时我们看到 Linux 引入了 Rust,而我们在 2021 年、2022 年开始开发时,也听说 Rust 不太好用,语言比较难写。不过,到了 2023 年,随着 ChatGPT 的发布,我们发现通过 ChatGPT 能生成很多 Rust 代码,因此觉得可以开始使用 Rust。之前如果要自学 Rust 确实难度很高,但去年我们引入 Rust 后,结合 ChatGPT 生成代码,降低了入门门槛。
我们认为 Rust 在模块管理方面做得很好,类似于 Python 的模块化管理,通过发布 Crate 可以实现模块化的解耦设计,这是我们觉得 Rust 比较好的地方。EDA 工具逐渐上云,而上云后需要处理高并发编程需求,我们发现 Rust 非常适合这种场景。今天我们也看到很多用 Rust 做云 SDK 开发的基础设施,因此我们未来也计划借助 Rust 的云基础设施,搭建开源的 iEDA 工具。
Rust 在复杂软件的依赖管理方面表现优异。作为开源硬件工具,我们希望代码编译简单,避免用户在下载代码时需要安装大量依赖包。Rust 的 Crate 模块化管理可以很好地解决这一问题。
除了 iEDA,目前开源 EDA 工具领域也有其他项目在使用 Rust。比如欧洲的下一代互联网组织发起了名为 LioRED 的项目,完全使用 Rust 开发。他们认为互联网的底层需要芯片,而芯片设计离不开 EDA 工具,所以他们也在推进开源芯片和 EDA 项目。LioRED 是一个完全用 Rust 开发的 EDA 工具,大家可以去了解一下。此外,Rust 社区中还有一些用 Rust 开发的点工具,这些工具也能在 crates.io 上找到。
我们在 2022 年计划引入 Rust,并希望未来构建一个 EDA 的云平台,利用 GPU 加速和云上的计算能力,加速 EDA 工具的开发。EDA 工具运行时间较长,利用云平台和 GPU 加速可以显著提高效率。去年 9 月,我们正式将 Rust 作为开发语言,并从文件模块等底层基础设施重构部分代码。我们使用 Rust 的抽象语法树(AST)技术,构建了 netlist、SDF 等芯片设计常用的标准文件解析工具,并通过 Rust 的 FFI 机制与算法模块进行交互,最终将这些基础设施集成到 iEDA 工具链中。
我们还在用 Rust 构建新的点工具,比如最近使用 Rust 开发了一个电压降分析的点工具,主要用到了 Rust 中的数值计算库。EDA 工具中经常需要进行数值计算,比如电分析时需要解电方程等,因此我们非常需要 Rust 中的数值计算库。我们还将开发的一些 Crate 发布到 Rust 社区中,让更多对 Rust 感兴趣的人可以使用我们发布的 EDA 基础设施。
未来,我们希望将 iEDA 放到异构云平台上进行加速。如果 Rust 社区有好的云开发 SDK,这对我们来说非常有帮助。EDA 领域虽然比较小众,但它是一个多学科交叉的领域,涉及微电子、数学和算法。EDA 工具需要理解微电子知识、数学算法和软件性能优化,因此具备这些背景的人才非常稀缺。我们 iEDA 作为一个开源平台,提供了开源的算法和工具,并且已经通过流片验证。
引入 Rust 后,我们发现 Rust 的学习曲线非常高。我们在 2021 年、2022 年开始开发时,虽然想用 Rust,但发现难度太大。直到 2023 年,ChatGPT 的出现降低了门槛,去年我们正式开始用 Rust 进行开发。iEDA 提供了包括 11 款 EDA 点工具在内的基础设施,整个平台架构和流程已经成熟,并经过多次流片验证。
为了让更多人参与到开源 EDA 平台的开发中,我们发起了 EDA 培养计划——“水利计划”。李明老师提到的操作系统训练营与我们的计划有些类似,但我们的规模较小。之前我们主要是内部培养,2023 年 7 月首次对外开放线上培养计划,主要是为了培养 EDA 人才。
水利计划包含四门课程,主要涉及 C++、EDA、AI 和 Rust。因为我们不仅在做传统 EDA 工具,还在探索智能化的芯片设计工具,因此需要 AI 的参与。同时也需要关注性能和安全问题,因此 Rust 也是我们课程的一部分。这些课程主要是实践类课程,基于 iEDA 平台进行学习。
我们在 Rust 课程中设置了核心内容的学习。7 月份对外发布的水利计划,虽然 EDA 是个小众领域,但也有 50 多人报名,主要来自一些专注 EDA 的学校。我们 EDA 人才培养计划的课程视频已经上传到了哔哩哔哩(B站),感兴趣的可以在 B站搜索 iEDA 的视频号,查看这些课程。我们希望让更多对 EDA 感兴趣的人加入开源 EDA 开发中。
未来,我们也希望将 iEDA 工具放到云平台上,让大家可以在云端进行芯片设计。同时,Rust 作为系统级语言,我们也希望它能进一步推动 EDA 工具的发展。
好的,以下是整理后的第一部分内容:
讲者报告
能够给我们带来高性能、安全性以及应用性的特性。对,右边是我们开源的一个交流群,位于右下角。大家如果对EDA感兴趣的话,可以扫码加入我们的交流群。我们会在群里发布一些消息和活动,欢迎大家加入。我的报告到此结束,请问大家有没有什么问题?谢谢老师,请各位观众有问题举手发言。
观众提问
观众A:卧槽,我刚刚看你们这个项目,最开始应该是用C++吧,去年开始重构了。我有几个问题,就是你们在用Rust重构的时候,和C++相互调用、编译,还有在迁移过程中,遇到什么难点吗?有没有提供一些开源工具?
讲者:哦,好的。因为我们当时重构时,觉得可能Rust能够提供更好的模块化管理。在重构时,我们是从一些耦合度较低的模块开始,比如文件解析模块。因为文件本身与算法的耦合度较低,它只是提供数据。因此我们和C++互操作时,尽管有一些难度,但需求并不高,主要是要从二进制层面获取内存数据。
我们使用了shift和SSI的提示来操作内存,把Rust的主文件存储的内容转换成C++的内存数据,通过FFI机制进行交互。Rust中的数据结构需要转换到C++中的等效结构,像struct转换为C++中的struct。这种转换过程会有不便之处,尤其是C++中的容器(如map)与Rust不太容易对接。因此我们最后主要通过vector或数组的形式来传递数据,降低了转换难度。
Rust在与C++交互方面确实需要改进。我们希望在新开发需求中,能更多地使用Rust进行原生开发,但完全重构成本较高。我们可能会在一些新需求上慢慢地使用Rust,但不会对已经较为稳定的部分进行完全重构。
主持人:感谢观众提问,志愿者请发放证书。还有其他问题吗?
观众B:老师,我也是从事EDA领域的。今天很荣幸听到您的报告。我有两个问题。第一,iEDA项目中的一些工具性能和商业化工具相比(如Synopsys、Cadence),差距有多大?第二,您提到的SPLS库,我之前也用过,发现它与C++中的线性代数库相比,无论丰富性还是性能上都有很大差距。请问您们有没有做过相关的性能对比?
讲者:谢谢提问,看来您还是比较专业的。关于第一个问题,我们的工具和商业工具的差距肯定还是有的。我们定位是学术界与产业界的桥梁,并不是为了PK商业工具。EDA在国内是一个较新的行业,尤其是近几年才逐渐发展起来。我们希望通过iEDA项目为产业界和学术界提供一个桥梁,输送更多的EDA人才。
关于性能,我们的工具更多是用于教学或低端芯片设计。如果是高端芯片设计,商业工具肯定是优先选择。我们的目标并不是与商业工具竞争,而是为学术界和初创的产业界提供一个可用的开源平台。
关于SPLS库的性能问题,确实在数值计算方面,Rust还不够成熟。我们也期望Rust在科学计算领域能有所突破,特别是在AI和EDA的数值计算上。如果Rust能在这一块改善,对我们来说会有很大帮助。目前我们在C++和Rust混合开发,尽量结合使用现有的工具。
主持人:感谢观众提问,志愿者请发放证书。还有其他问题吗?
观众C:老师您好,我不是EDA领域的,但对工业软件和Rust的应用很感兴趣。请问现在你们使用Rust主要是做文件解析的部分吗?仿真部分还是用C++来做的吗?未来会不会考虑用Rust来重构仿真部分?
讲者:谢您的提问。我们目前确实在尝试用Rust做文件解析,但仿真部分主要还是用C++开发。仿真对性能要求很高,目前还在调研中,Rust是否能达到性能需求还不确定。我们有学生在尝试用Rust进行仿真开发,但最终能否实现,还需要进一步验证。
观众C:我自己在写仿真软件时,发现用C++可以灵活使用指针,而Rust会有很多编译器限制,有时程序甚至无法通过编译。我尝试使用ECS架构去解决这个问题,类似游戏引擎的模式。你们有没有考虑过这种方式?
讲者:感谢您的建议。确实,EDA工具主要需求是性能和安全。我们会在发布前进一步尝试,如果Rust能够达到预期,也不排除将仿真部分用Rust来开发。您的建议很有启发,谢谢!
主持人:感谢观众提问,还有同学要提问吗?
观众D:老师好,我想了解一下,iEDA项目最初是为什么选择从C++转向Rust的?最初的驱动力是什么?
讲者:感谢提问。我们在2021年、2022年项目启动时,确实考虑过使用Rust或Go。但当时觉得Rust难度太大,最终选择了更为熟悉的C++。到了2023年,我们的原型已经完成,之后的工作主要是完善一些比如文件系统的功能。当时因为大模型的兴起,以及一些老师(如张汉东老师)的宣传,我们决定尝试使用Rust。
观众D:那到目前为止,从C++到Rust的重构,在开发成本、性能、可靠性上,差距有多大?
讲者:我们开发后发现,大部分模块的性能可能略低于C++,但有些模块性能比C++更好。这可能与我们团队刚接触Rust有关。另外,Rust在数据转换上也有一些开销,影响了性能发挥。但我们相信随着Rust的发展,它在云开发、科学计算等方面的进步,会让我们受益更多。我们希望Rust能帮助我们降低软件稳定性测试的成本,因为我们作为开源项目,测试投入的成本较高。
主持人:感谢提问!
25.RMK使用 Rust 语言构建高性能键盘固件 - 顾浩波
https://www.bilibili.com/video/BV12FsUeeEzQ/
主持人:
下一位演讲者,我们来欢迎RMK作者、Rust嵌入式开源贡献者顾浩波老师,为我们分享“RMK使用Rust语言构建高性能键盘固件”。RMK是一个使用Rust语言构建的高性能键盘固件库,支持多种芯片,如STM32、nRF、ESP32、RP2040等,并实现了蓝牙加USB双模支持。本次演讲通过构建键盘固件的实例,介绍了Rust在嵌入式场景的应用,包括相关工具、优缺点等,并分享了使用Rust进行嵌入式开发的经验。接下来让我们把时间交给顾浩波老师。
顾浩波:
Hello,大家好啊!我首先做一下自我介绍,我叫顾浩波。我现在主要是在Rust的嵌入式社区做一些开源的开发工作,我的工作主要是RMK,它是一个使用Rust构建的高性能键盘固件库。
我这次的分享主要分成三个部分。第一个部分是针对Rust在嵌入式应用开发生态环境的一个概览;第二部分是简单介绍一下RMK到底是什么;最后一个部分是一个简短的总结。
首先我们来看一下第一个部分,Rust嵌入式应用开发的生态环境。我这次的分享会主要集中在Rust的MCU(微控制器)应用开发这个层面。MCU的话大家可能比较熟悉,它的Flash可能一般只有100多KB或者几百KB,RAM可能也就几十KB,系统资源非常紧缺。在这种情况下,我们在Rust里面能够使用的只能是no_std,也就是说我们不能使用堆内存分配器,也不能使用像Vec这样的一些方便的数据结构。
第二个关键词是“应用开发”。我这次的分享更加偏向于使用Rust开发嵌入式应用,而不是操作系统等底层内容。
首先我想回答一个很多人都关心的问题:为什么要用Rust去开发嵌入式应用?这里我分享一下我个人的经验。可能与大家传统意义上对Rust的印象有所不同,比如说Rust的内存安全性对我来说不是主要的关注点。因为在嵌入式开发中,大部分时候是没有内存分配的,很多时候我们都是在栈上进行内存操作。因此,内存安全性并不是我个人最关心的点。
我更喜欢Rust的四个特点:
工具链:Rust的工具链配置非常方便。举个例子,如果我用C开发,想开发RISC-V或者ARM的应用,我可能需要配置GCC、GDB,再加上配置OpenOCD和环境变量,这些东西非常复杂。但是用Rust的话,基本上只需要
rustup加上cargo就可以搞定,所以Rust在嵌入式开发中的工具链非常方便。开发体验:使用Rust开发嵌入式应用的体验要比C好很多。很多使用C的开发者可能习惯使用老旧的工具,比如Keil,这些工具的开发体验并没有那么好,而Rust使用现代的工具,比如VSCode和Rust Analyzer,开发体验更好。
async/await特性:在嵌入式应用开发中,Rust的async/await异步编程模型非常好用。相比于C语言中的实时操作系统(RTOS),Rust的异步框架,比如embassy,可以减少上下文切换的开销,实现更高的性能。抽象能力和类型系统:Rust的抽象能力和类型系统非常完善,能够让我们在开发中更轻松地进行代码抽象,使得开发更加方便。
接下来,我想介绍一下Rust嵌入式开发中的一些典型范式。
这个图展示了Rust嵌入式应用开发的生态,核心部分是第三层的“Embedded HAL”(硬件抽象层)。它抽象了MCU中的外设和协议,比如SPI、GPIO等。Rust的嵌入式工作组将这些通用的部分抽象为traits,因此在上层开发时,Embedded HAL就充当了一个纽带,将具体的MCU API与平台无关的驱动程序连接起来。
举个例子,如果我们使用SPI去驱动一个屏幕,我只需要基于Embedded HAL提供的SPI trait来实现屏幕的驱动,这样这个驱动程序就可以在任何实现了Embedded HAL的MCU上运行,无论是STM32还是RP2040。
在这种编程范式下,应用层的代码会变得非常少,绝大部分平台无关的代码都可以放在驱动层,这使得移植工作变得非常简单。在不同的MCU之间进行移植,即便是不同架构的MCU,比如RISC-V和ESP32,也可以非常轻松地完成。
然而,Rust的嵌入式生态也有一些问题。由于嵌入式开发本身的复杂性,不同厂家的MCU存在严重的碎片化问题。除了通用的外设和协议之外,各个厂商的一些特色外设还是比较难抽象出通用的东西,因此在一些地方还需要进行单独的开发。这也是当前Rust嵌入式生态中存在的不足之处。
枪支应用开发的范式
接下来我想讲的是现在枪支应用开发的一个范式,实际上我原本想强调的是 Rust 的异步生态环境。不过,这个部分之前鹿仔科技的陈老师已经提过了,可能大家已经有了一些大概的认识,所以我就不再细说了。
RMK 介绍
接下来我将介绍 RMK 及其如何使用 Rust 构建键盘固件。首先,什么是 RMK?简单来说,它就是一个运行在键盘中的软件。大家可能打字时会看到文字自动出现在屏幕上,实际上这是因为键盘固件在检测键盘的每个按键物理上被按下的状态,并通过软件处理,将其转换成电脑或其他设备(如 iPad)可以识别的数字信号。这就是键盘固件在整个流程中的作用。
现在的键盘固件已经变得非常复杂,具备很多功能。举个例子,键盘可以通过按键控制音量,或者通过按键切换功能层。例如,默认按键可能是 ABCD,按下某个键后,再按同样的按键时,它就变成了 1234。还有一些定时功能和宏功能,进一步增加了固件的复杂度。
RMK 的特点
RMK 是 Rust 编写的,具备以下几个重要特点:
高性能:根据我的测试,从按下按键到主机接收按键信号的时间,平均大约是 2 毫秒。这个性能在商业化键盘中也处于前列。如果是蓝牙模式,时间约为 10 毫秒,因为蓝牙本身有一个 7.5 毫秒的轮询间隔。
易用性:得益于 Rust 的特性,用户不需要懂 Rust,只需通过一个 Toml 文件配置键盘的硬件信息(如行列数、按键功能等),RMK 就能自动生成可运行的键盘固件。
低功耗:RMK 基于 Embassy 开发,Embassy 允许系统在等待任务时自动进入低功耗模式。因此,开发者无需特别关心低功耗问题。举个例子,我用 2000mAh 电池的键盘可以持续使用四五个月。
RMK 的组成
RMK 包含两部分:右边是平台相关的驱动层,左边是应用层。驱动层负责矩阵扫描、存储和通信等平台相关的工作。应用层负责初始化 MCU、USB 和蓝牙通信,然后将这些初始化后的硬件交给通用中间层的 traits 进行处理。
Rust 的抽象能力
在 RMK 中,我利用 Rust 的抽象能力,将键盘的矩阵扫描抽象成一个 trait。键盘有很多种形式,有些键盘的每个按键对应一个 IO,有些是矩阵形式,还有些通过 USB 接收器进行矩阵扫描。通过抽象,这些复杂的处理方式被简化为统一的接口。开发者只需实现对应的 trait 方法即可,大大提高了代码的复用性。
键盘去抖动的实现
键盘去抖动是一个常见问题。在 RMK 中,我将去抖动算法抽象为 trait,用户可以根据需要选择不同的算法。相比于 C 语言中通过宏定义指定算法的方式,Rust 的类型系统能够在创建矩阵时强制要求选择去抖动算法,这样开发过程中的可读性和安全性更高。
异步特性的应用
在 RMK 中,我将键盘扫描任务和主机通信任务分成两个异步任务。扫描任务负责检测按键状态并生成键盘报告,通信任务则等待报告并将其发送给主机。通过 Rust 的异步特性,两个任务可以并发运行,避免了传统 C 语言中阻塞式的事件循环。
相比于 RTOS,Rust 的异步切换效率更高,因为任务之间的上下文切换开销更小。而 RTOS 切换上下文时需要保存更多的状态信息,因此效率较低。
Rust 的过程宏应用
在 RMK 中,我利用 Rust 的过程宏,将 MCU 的初始化代码抽象成模板。用户只需在配置文件中指定 MCU 和键盘的行列数等信息,过程宏就能自动生成复杂的初始化代码。这种方式大大简化了开发过程,尤其是在需要适配不同板子的嵌入式开发中,非常有用。
Rust 的工具链
Rust 提供了非常强大的工具链,比如 cargo 和 rust-analyzer,这使得我能够轻松地识别不同的架构(如 RISC-V 和 Cortex-M)。例如,我最近在尝试将国产高性能芯片 HPM 集成到 RMK 中。通过实现 USB 和 GPIO 的底层接口,我只用了大约半个小时就完成了移植,并且运行没有任何问题。
总结
Rust 在嵌入式应用开发中的表现已经非常好,但仍有提升空间。Rust 的社区驱动架构设计非常优秀,嵌入式工作组为 MCU API 提供了统一的接口标准(traits)。然而,Rust 的嵌入式开发仍然存在一些痛点,例如缺乏成熟的嵌入式 GUI、工具链对多目标工程的支持不足、原厂对 Rust 的支持不够、以及库的维护问题等。
Rust 的生态在某些方面还不够成熟,尤其是在支持国产芯片方面仍有很大改进空间。然而,Rust 强大的抽象能力和现代化的开发体验,使得它在嵌入式开发中具有很大的潜力。
整理后的内容
他可能不对外开放,但也有一些其他情况,不过其他基本上全都是社区驱动。也就是说,社区驱动的话会带来很多问题。比如说,第四个问题:有很多库,当时可能有人在维护,但随着时间推移,如果维护者不再使用这个库,他们就不再维护。这也是当前 Rust 生态环境中较为欠缺的地方之一。虽然 Rust 的碎片化问题可能没有 C 语言那么严重,但整个生态的成熟度相对来说还是有差距的。
如果你只使用一些大厂的芯片,比如 STSTM3,这些芯片的支持是相对成熟的,已经达到了生产级别的标准。但如果你使用的是国产芯片或其他一些冷门芯片,那么情况就比较困难了。
第四点,我个人觉得 Rust 在嵌入式应用开发方面,仍然欠缺一些好的入门材料。虽然现在很多人对 Rust 在嵌入式开发中的应用很感兴趣,但不论是英文文档,还是相对较少的中文资料,都不太利于 Rust 嵌入式生态的发展。这是我个人在 Rust 嵌入式生态中遇到的痛点。
基本上今天的分享就到这里,感谢大家!感谢老师的支持,感谢老师的精彩分享。请问有没有现场观众想要提问?
观众提问:
您好,顾老师!我想问一下,在做键盘固件驱动的时候,硬件抽象这一块是怎么处理的?抽象是由核心处理完成的吗?还是我们自己做了一些定制?另外,抽象的程度大概到什么水平?
顾老师:
这个问题可以分为两个部分。首先,第一个部分是通用的抽象,比如 GPIO、SPI 之类的,这些在社区里已经有比较成熟的抽象了,我们在使用时只需要直接调用这些抽象层的接口就可以了。在应用层开发的时候,例如 MCU 初始化时,我只需要初始化相应的 SPI 实例,然后把它填到固件的输入中就可以了。
第二部分是业务相关的抽象,比如键盘矩阵的抽象、去抖动的抽象等,这些需要根据具体的业务来做相应的抽象设计。抽象的层次基本上是根据业务需求来决定的。
再举个例子,比如蓝牙部分,我也很想做一个抽象,但很难做到,因为蓝牙部分通常是由原厂提供的库,有些库甚至封装了 RT 内部的实现,这就让抽象变得困难。因此,这也是目前 Rust 硬件抽象层面遇到的问题之一。
不过,具体到实际应用时,不管是通用的抽象还是业务相关的抽象,我觉得只要设计清楚,开发起来还是相对方便的。
观众追问:
你提到我们切换了硬件的器件部件,调整很快,那硬件抽象层在这个过程中是否也发生了变化?
顾老师:
没有,因为键盘的核心部分主要使用的就是 USB、GPIO 和 SPI 这三部分,它们都是非常通用的。比如 USB,我使用了 embassy 的 easy USB driver,它也是一个 trait,直接实现了 USB 这个 trait,然后把实例传入就可以运行了。所以,移植过程中基本上没有做什么额外的工作,只是对芯片做了一些初始化,其他基本没变。
不过,有一点我之前没有提到,就是 embassy 这一层的抽象通常是由原厂来做的,但因为目前没有现成的实现,所以我们自己实现了这部分。这其实工作量是很大的。如果社区里已经有适配好的芯片,那用起来会很快;但如果没有适配好的芯片,就会变得非常复杂。
观众提问:
移植过程中遇到的难点是什么?还有,ARMK 中是否使用了 unsafe 的代码?另外,有没有集成一些新的库调用?
顾老师:
先回答第一个问题,移植过程中最大的难点其实就是 MCU SDK 的开发。如果遇到没有 SDK 的 MCU,那就会很复杂。但如果有 SDK,移植过程中基本没有太多的难点。你可以翻一下我们的仓库,支持很多不同的 MCU,比如 ESP32、STM32、RP2040 等等,虽然这些芯片都不太一样,但移植的整体成本其实很低,只要实现了对应的 trait,移植的成本几乎可以忽略不计。主要的难点还是在 SDK 上。
第二个问题是关于 unsafe 的使用。ARMK 中的 unsafe 代码非常少,因为大部分外设的抽象已经做得比较完善了,不需要我们再去处理底层细节。在统计中,我发现整个 ARMK 中的 unsafe 代码不超过五处。
第三个问题是关于 C 语言库的调用。我们只在蓝牙部分使用了 C 语言库,因为蓝牙部分的库通常不开放源代码,所以只能调用原厂提供的库。其他部分基本上都是用 Rust 实现的。
观众提问:
in beirus 提供的硬件抽象层非常科学,很多应用都能用到,它是否有商业化应用?是否已经定义了通用的硬件抽象层的函数?
顾老师:
是的,现在通用的硬件抽象层基本上是由 Rust 官方的嵌入式工作组定义的。这个抽象层的定义已经比较通用了,今年年初才刚刚定稿,虽然整个生态还很新,但这些定义一般不会再变了。
观众提问:
我们公司有一款小众芯片,在 Rust 上没找到对应的工具链,连 CPU 架构也找不到。我们还能继续用 Rust 开发吗?如果芯片原厂不支持,有没有什么渠道可以推动社区完善工具链?
顾老师:
这个问题比较底层。首先,你需要看一下芯片的架构是否被 Rust 支持。如果目标架构在 Rust 的 target 列表中,那就意味着已经有支持了。如果没有,那可能需要芯片原厂来推动这个事情。
我听说给 Rust 增加一个新的 target 并没有那么难,但我个人没有尝试过。如果 target 已经支持了,应用开发层面就主要是寄存器的读写问题。芯片原厂提供 SVD 文件后,可以通过自动化工具生成 Rust 的寄存器结构体,用 safe 的方式去操作寄存器。
观众提问:
您觉得从产品的角度看,芯片厂商需要提供什么样的 SDK,才能让硬件开发变得更容易?
顾老师:
我认为芯片厂商只需要提供兼容社区主流硬件抽象层的 SDK 就可以了。对于我们应用开发者来说,底层实现并不是我们关心的重点,我们只关心是否有对应的 trait 实现。如果有实现,开发过程就会变得很容易。
当然,抽象层的功能越多越好,最好能和 C 语言的 SDK 看齐。
感谢大家的提问和参与,今天的分享就到此结束!
!!!
26. Rust 标准库介绍以及嵌入式场景应用 - 王江桐


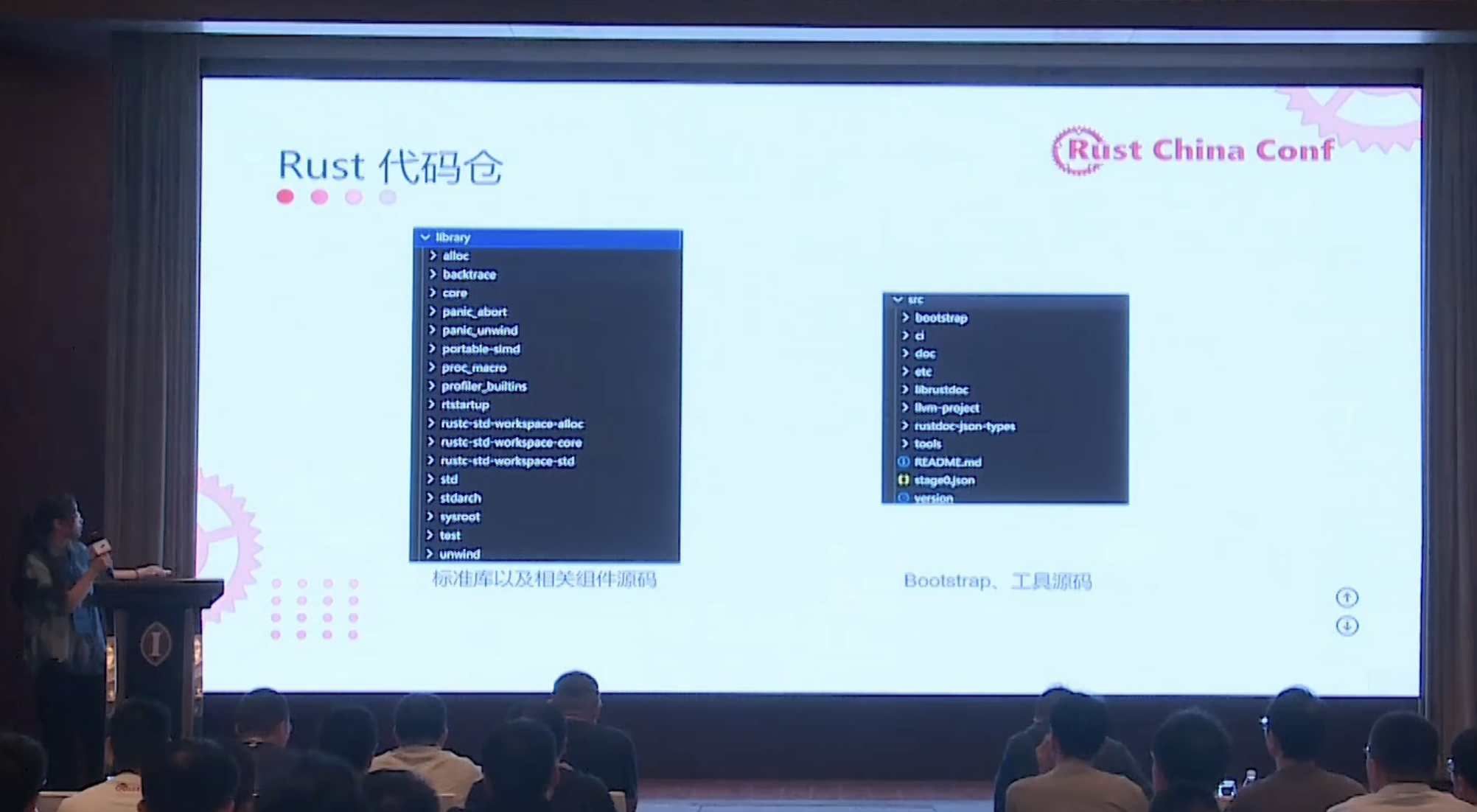
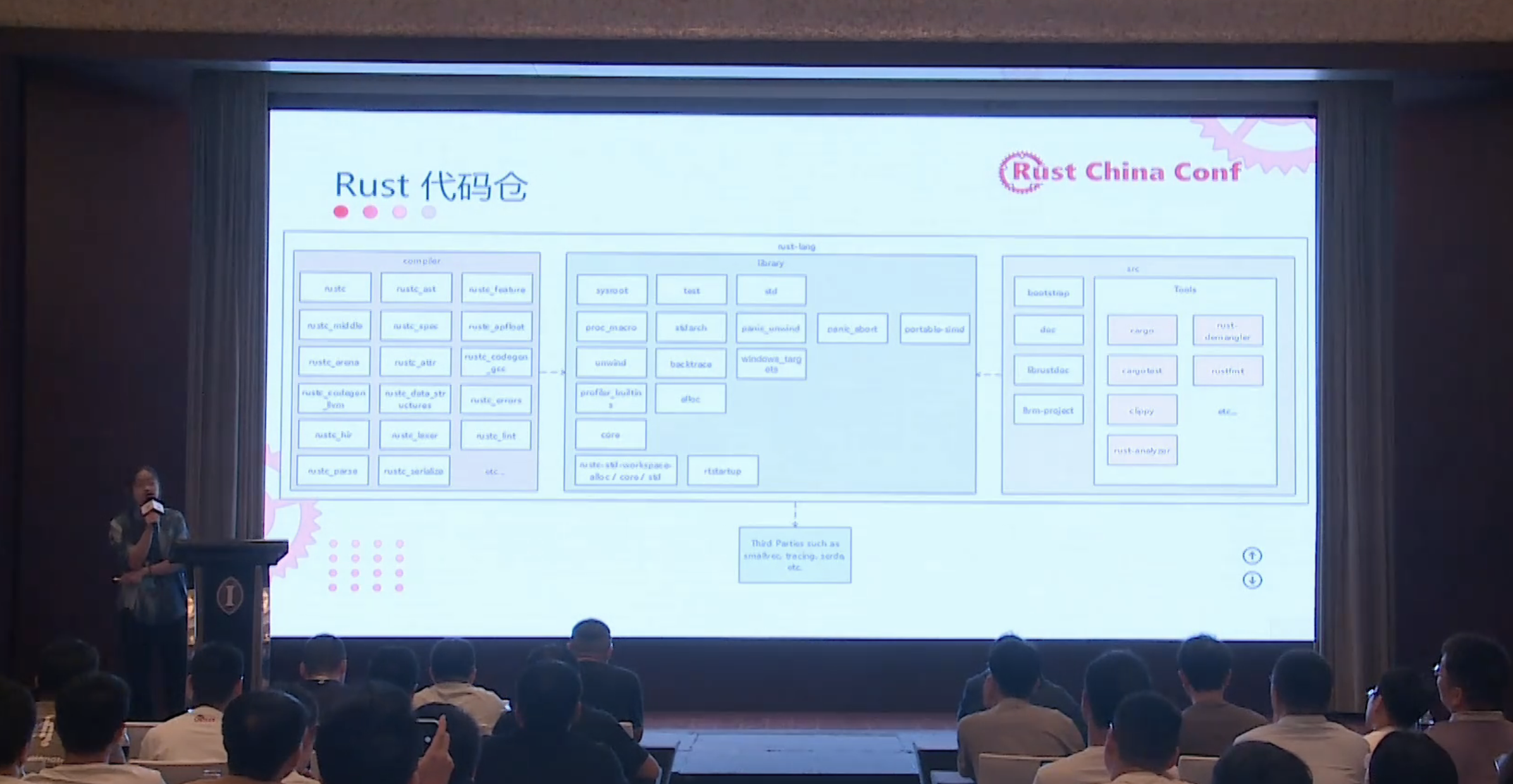



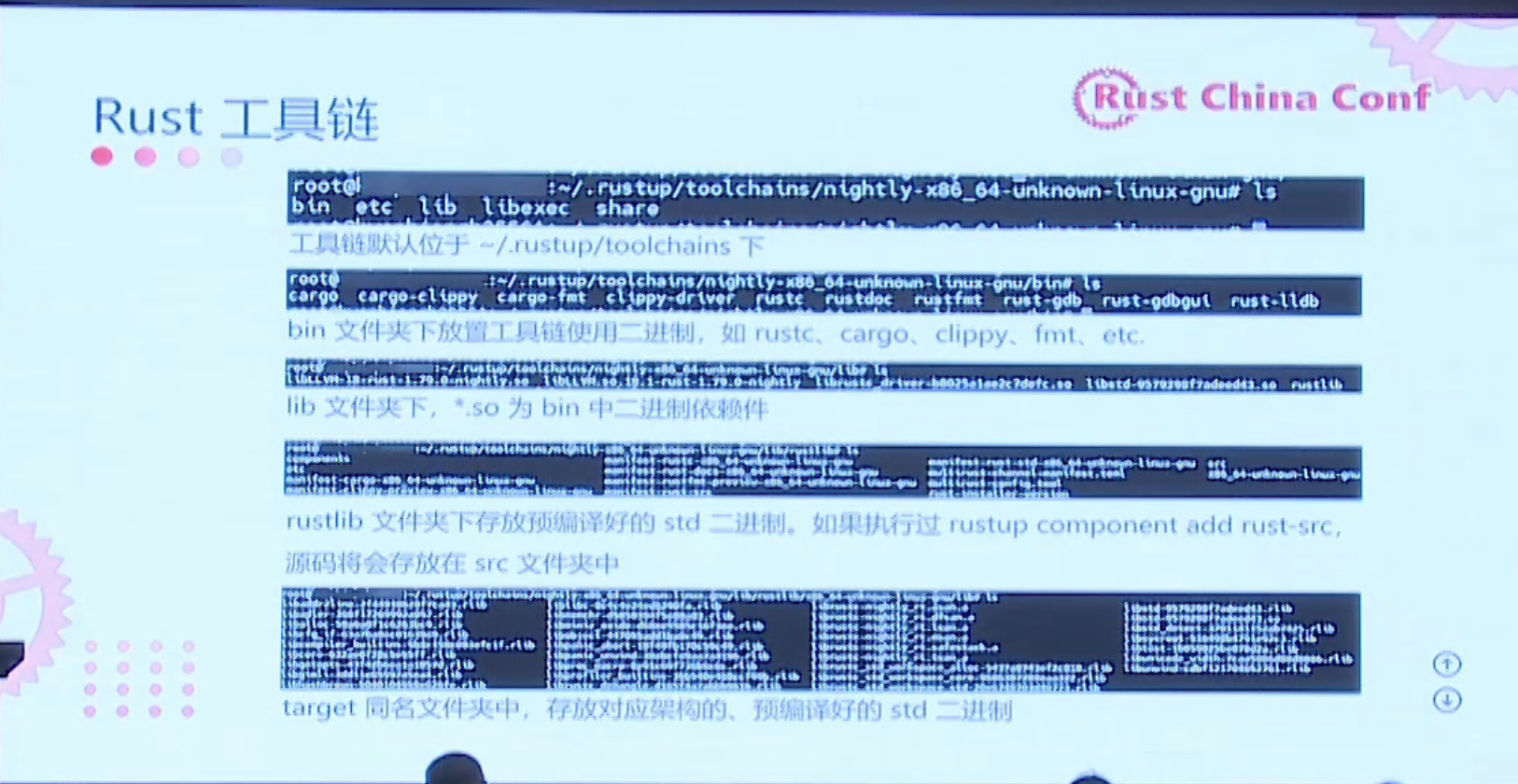
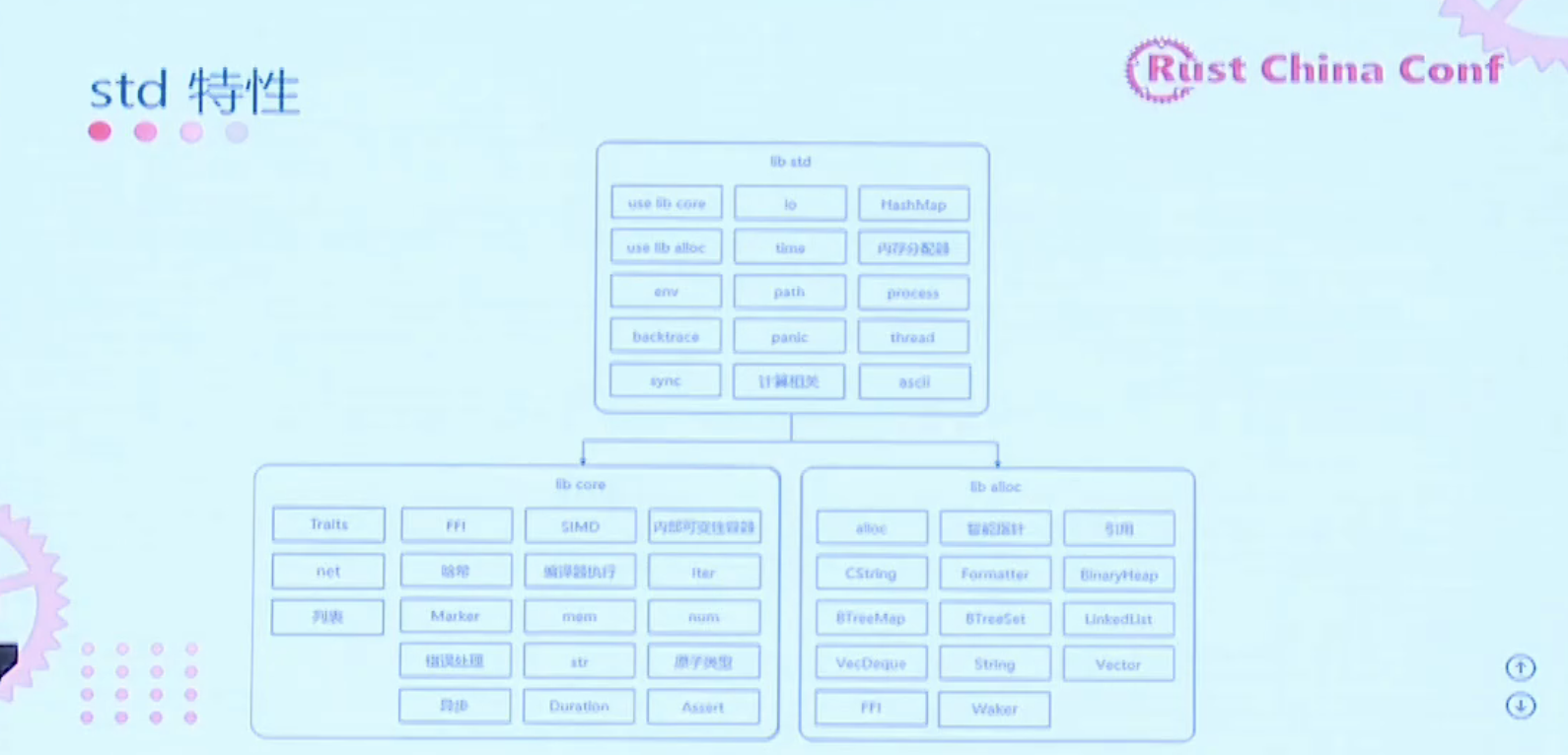
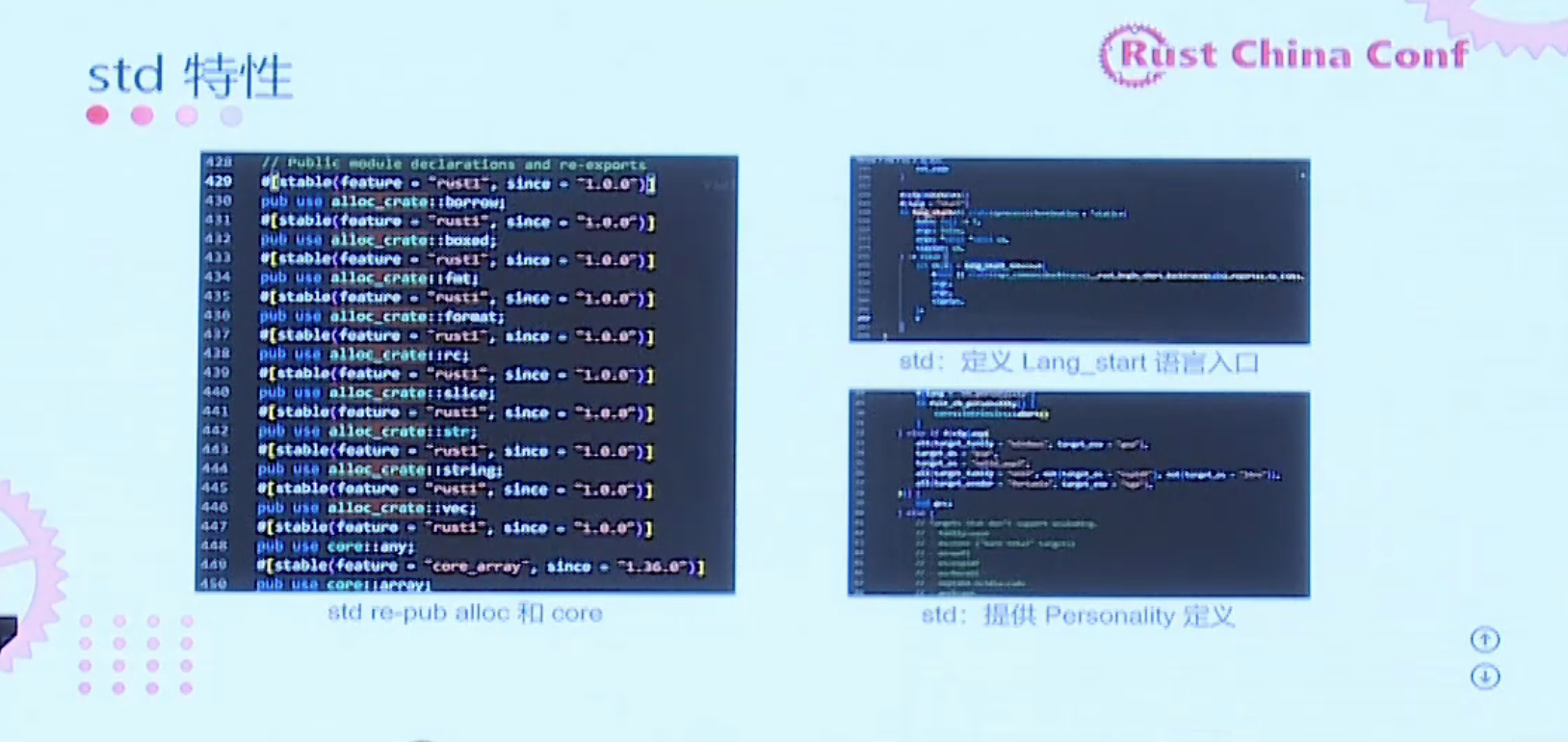




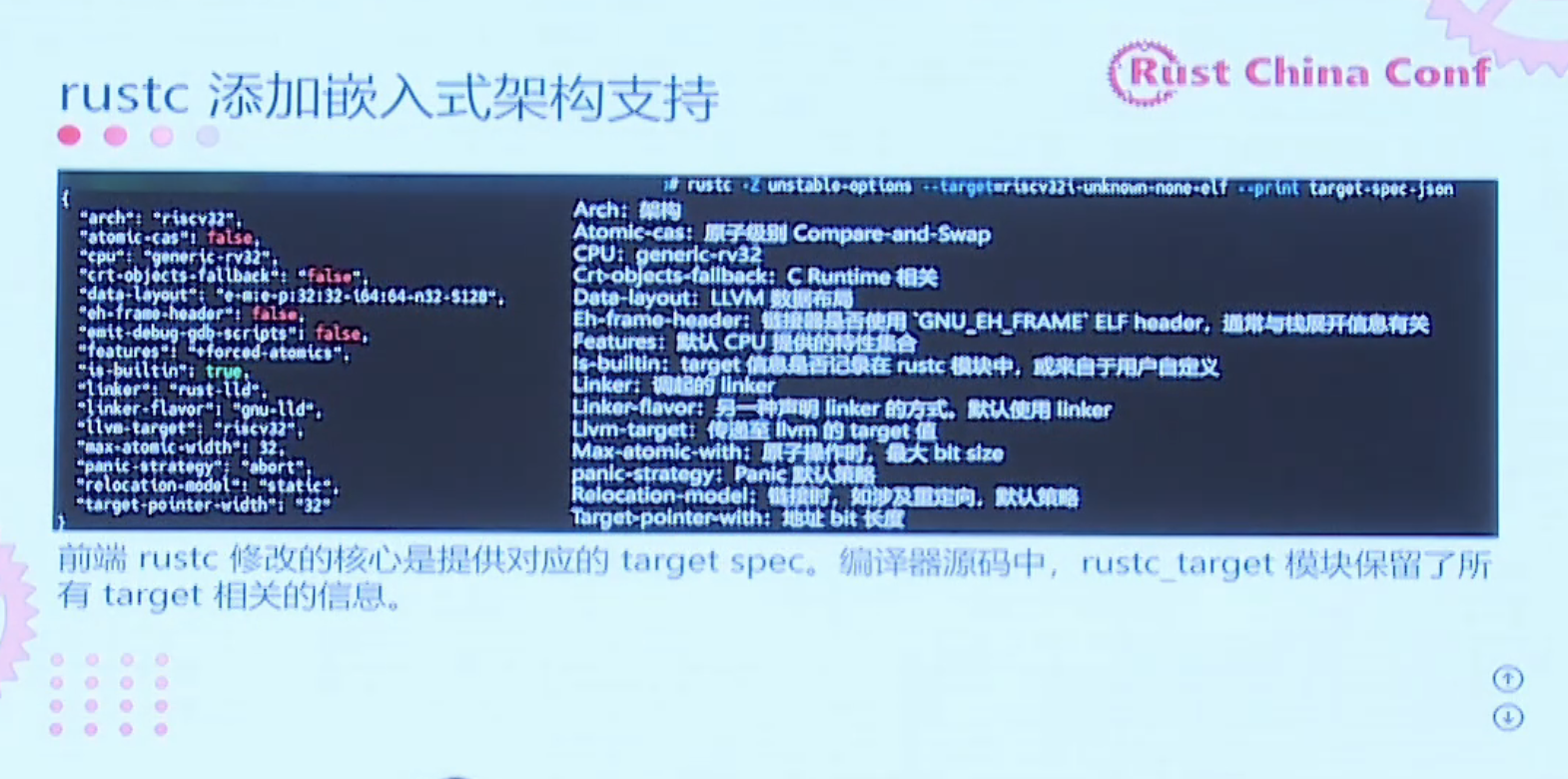
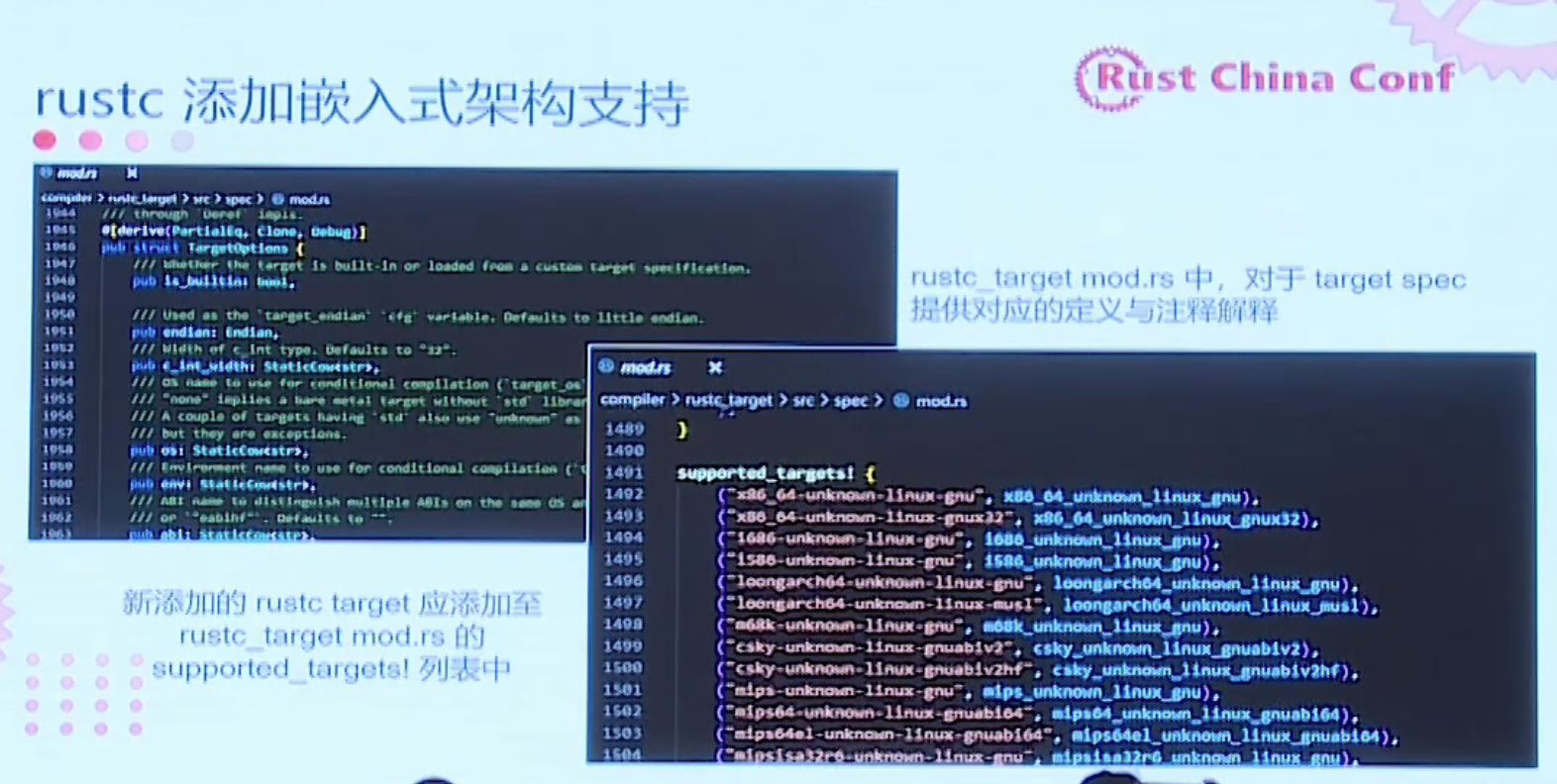


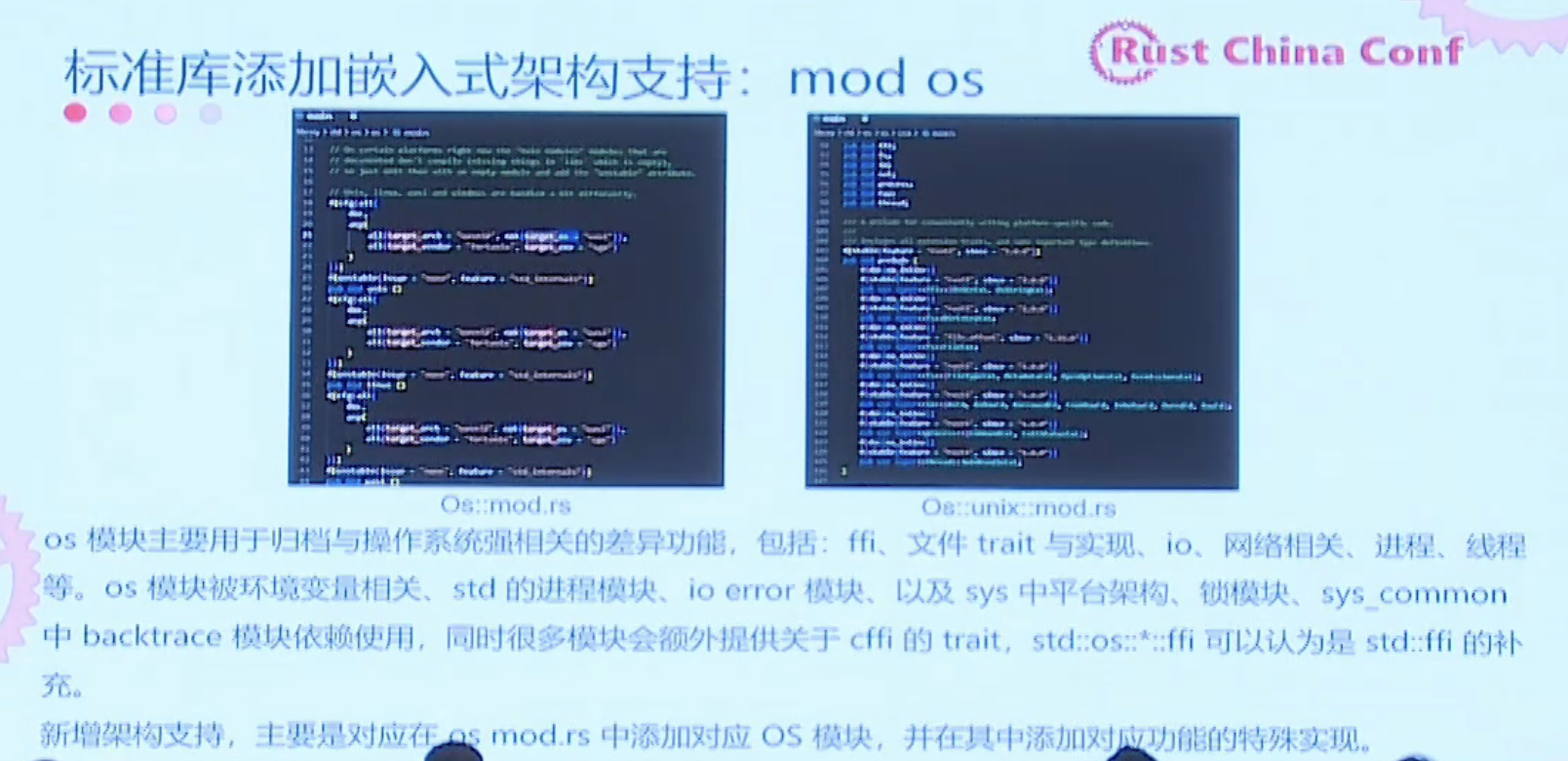
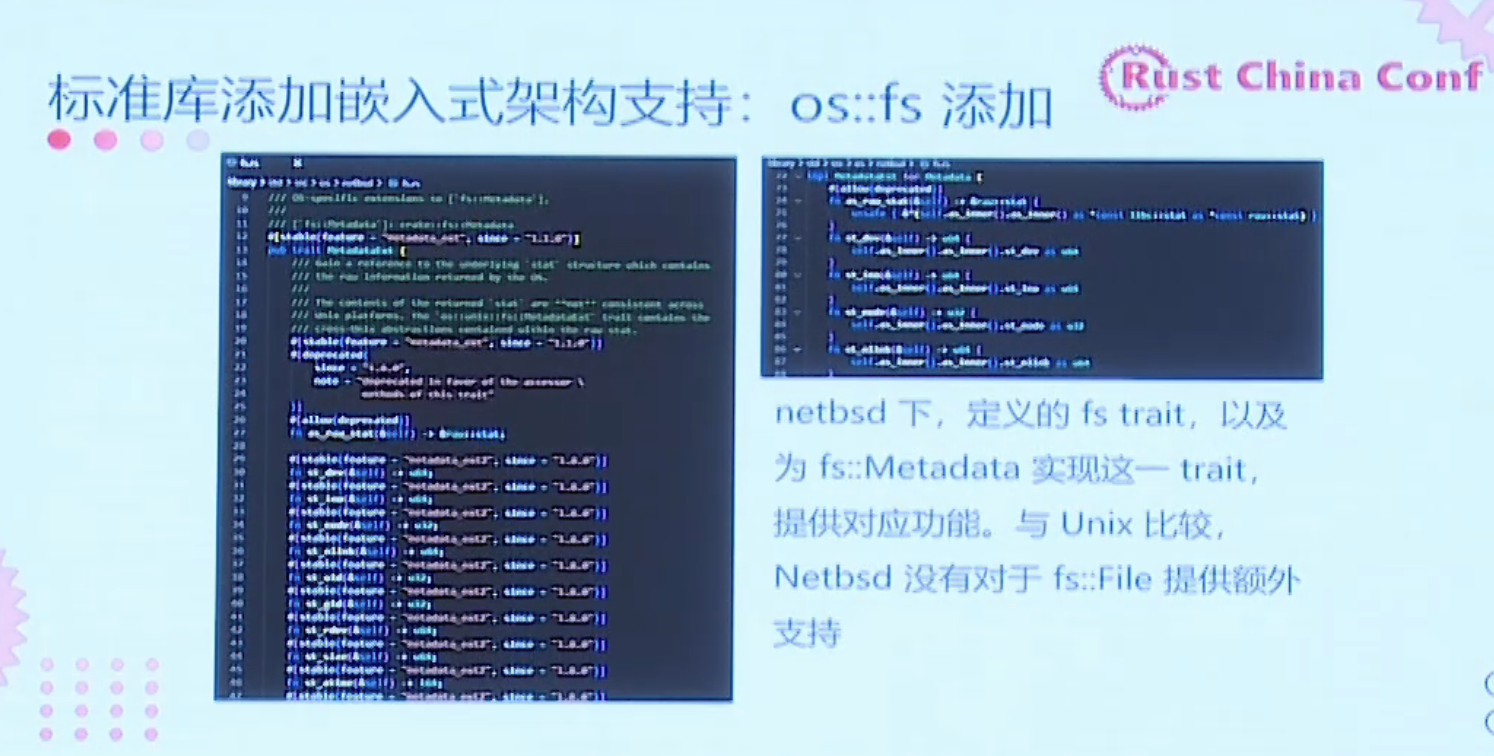


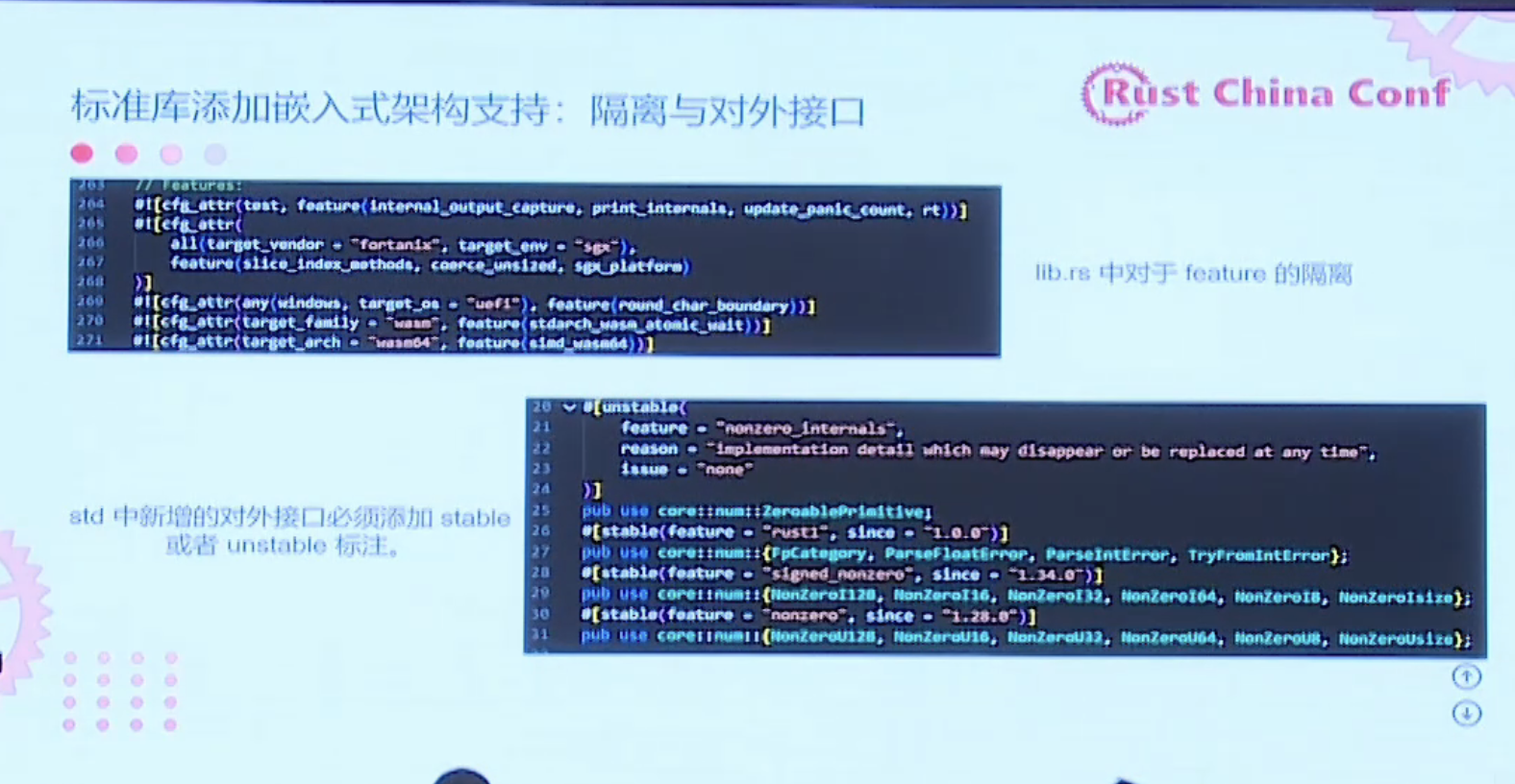


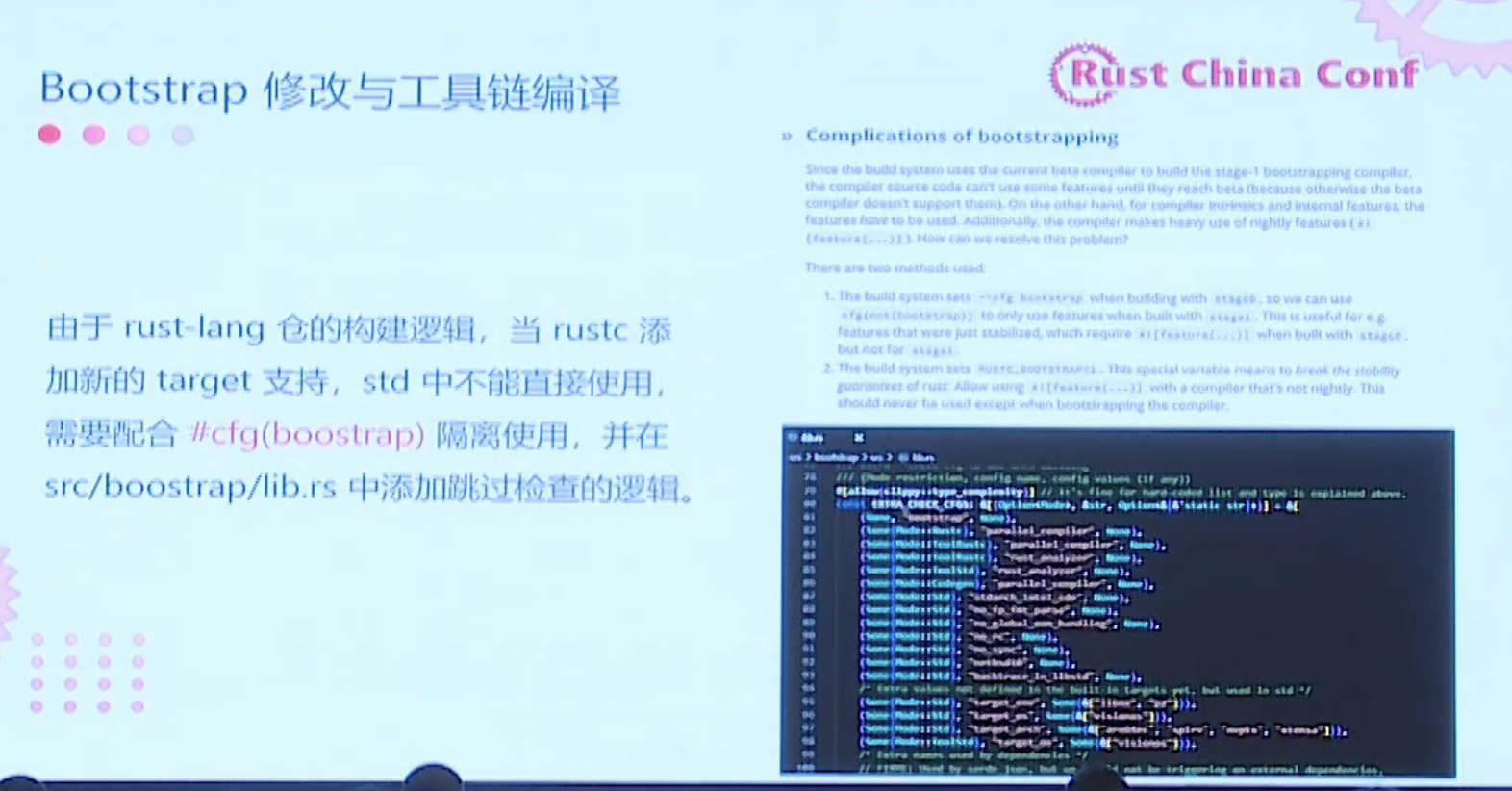

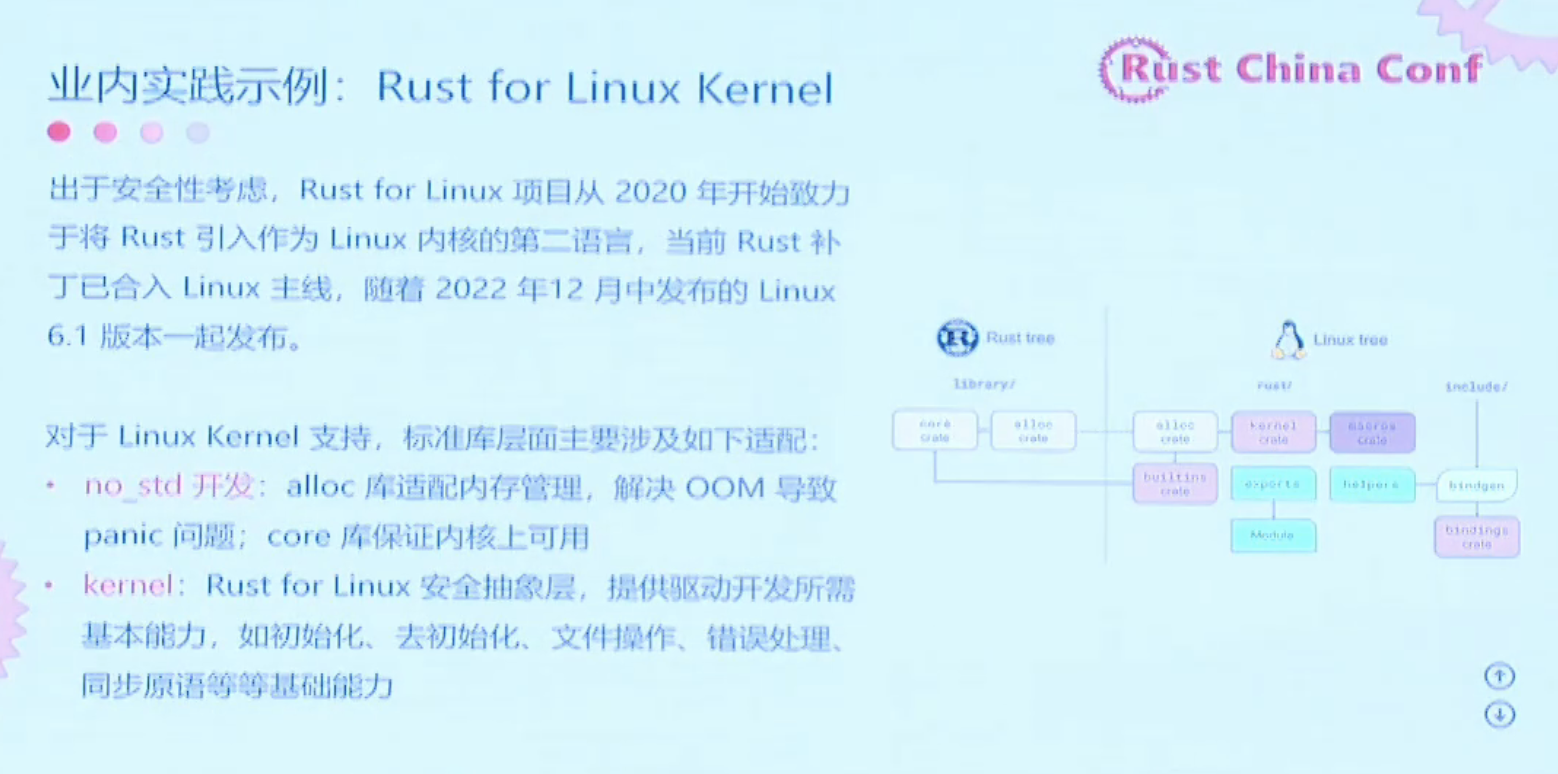

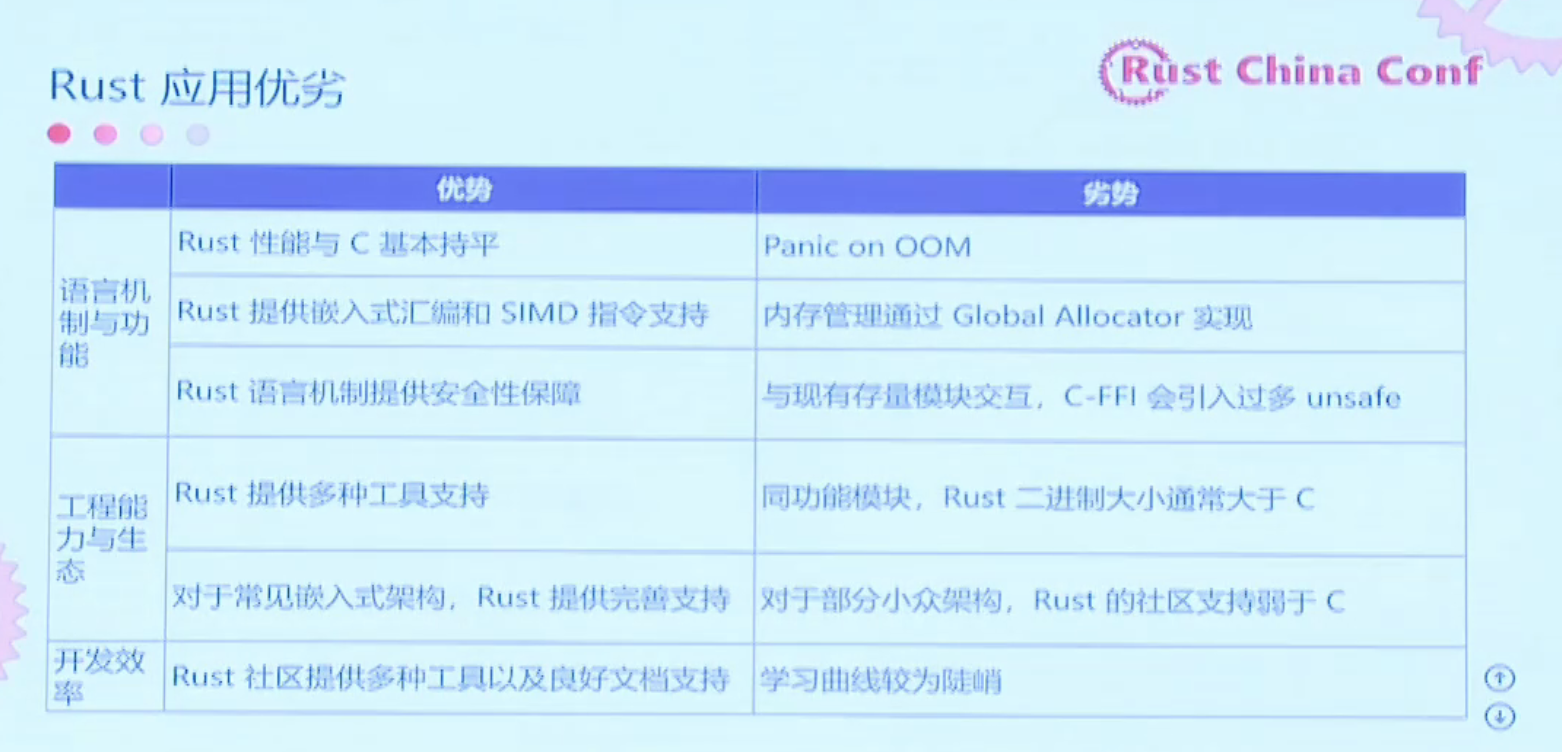
rustc: 编译器前端
llvm: 编译器后端
大家上午好,非常荣幸能够有这次机会在这里与大家分享关于 Rust 标准库的介绍以及 Rust 在嵌入式应用中的一些概要。本期分享主要会由三个主题组成:Rust 标准库简述、添加嵌入式架构支持、以及 Rust 在嵌入式使用情况的简述。本次介绍可能相对会偏基础一些,也算是为后面的议题抛砖引玉。
首先是关于标准库的简述。Rust 这门语言,包括它的编译器,这些都是完全开源的,它在 GitHub 上有自己的仓库 Rust Lang,这个仓库几乎包含了所有与 Rust 相关的部分,包括编译器源码、标准库的代码、Rust 相关工具的代码(如我们常用的 Cargo、Clippy 等工具),以及整个工具链的构建工具和配置文件。构建工具的入口在不同系统上有不同的格式,通常以 bootstrap.py 脚本为入口。
Rust 的标准库通常被大家熟知为三部分:core、alloc 和 std。实际上,标准库的组成部分很多,如果我们对 Rust 的仓库进行划分,核心可以分为三个部分:编译器(compiler),即 Rustc 前端部分;库(library),核心是 core、alloc 和 std,但它实际上分为很多 crate;最后是源码(src),包括 bootstrap 构建入口、Cargo 工具代码、LLVM 工程等。如果你的本地没有配置 LLVM,从头编译时会以子模块的方式拉取 LLVM,并从零开始编译 LLVM,最终将这些工具集成到工具链中。
说回标准库,标准库核心分为三部分:alloc、core 和 std。它们的职能区分如下:alloc 主要处理与内存相关的结构体;core 是 Rust 通用的、与架构弱绑定的结构体;std 提供了所有标准库的基础功能实现,同时会复用 alloc 和 core 中的功能。通常在非嵌入式场景下,我们直接使用 std,但你也会看到 core 中的写法,实际上它们指向同一个来源,只不过 std 额外提供了与架构较强绑定的功能实现,例如线程和 I/O。
Rust 支持很多种架构和平台,通常这些支持分为多个 tier(层级),当前嵌入式场景的很多架构支持仍然停留在 tier 3 的部分。这意味着,在嵌入式开发中,很多功能官方无法保证完全可用,甚至无法保证功能能够编译通过。
Rust 的构建流程是自举的(bootstrapping)。官方编译流程可以通过 bootstrap.py 脚本启动,最终调用 Cargo 来编译 Rust 仓库。仓库本质上是一个大型的 Cargo 工作空间(workspace)。我们也可以直接通过 Cargo 对一些部分进行编译。
通过 bootstrap.py 脚本,我们可以编译完整的 Rust 工具链,包括 cargo、rustc、rustdoc、rustfmt 等工具。如果我们想为 Rust 添加嵌入式支持、或自定义 Rust 工具链,可以通过官方提供的工具将自定义化的内容构建出来。至于将这些内容回馈社区、通过社区发布等,那是另一个话题,本期暂不涉及。
工具链的构建也可以通过 config.toml 文件进行相关配置,官方提供了很多支持,允许我们进行高度个性化和适配项目需求的配置。Rust 工具链的文件夹结构默认位于 toolchains 目录下。如果我们自定义工具链,可以仿照官方的文件夹结构,方便进行调测和配置。
回到标准库,核心仍然是 core、alloc 和 std 三部分。虽然在 GitHub 仓库的库目录下有很多 crate,但它们最终会通过 reexport 的形式在 std 中暴露出来。alloc 的核心特性是内存分配相关的内容;core 包含 Rust 核心特性;而 std 则在此基础上提供了与架构强绑定的特性,比如线程和 I/O。
标准库中 std 部分还提供了语言相关的定义,比如 lang items 定义语言入口,或者 personality 定义错误处理相关内容。在嵌入式场景中,我们通常使用 no_std,原因是 std 中许多与架构强绑定的特性在嵌入式设备上无法使用,或者当前 Rust 可能根本不支持该架构。因此,很多情况下我们需要自行定义相应的内容。
那么,如果我们要为 Rust 添加新的嵌入式架构支持,比如添加一个新的 target,并打通完整的链路,大概需要做哪些准备?
首先,rustc 必须支持该 target 的编译。编译器支持分为两部分:前端 rustc 的支持和后端 LLVM 的支持。由于本次分享的重点是 Rust 相关内容,LLVM 的支持暂不讨论。前端支持相对简单,特别是对于交叉编译。核心在于我们需要在 rustc_target 模块中添加对应 target 的配置,基本上这一步完成后,前端编译器的支持就已经做完了。当然,这基于后端必须已经支持该架构。
接着通过 rustc 命令查询 target 的配置,比如以 riscv32i 架构为例,我们可以查看该 target 的配置项,包括架构、数据布局、链接器等信息。这些配置在 rustc_target 模块的 spec 目录下定义了所有 rustc 当前支持的 target 特性。官方提供了详细的注释,便于开发者了解每个属性的作用。
完成模块添加后,将新增的 target 添加到 supported_targets 列表中,基本上一个新的 target 就配置完成了,这个过程非常简单。由于 core 和 alloc 的特性与架构没有强关联性,所以添加新 target 的大部分工作就是配置 rustc 前端。至于 bootstrap 构建入口和相关配置,我们之后会详细讨论。
如果我们还希望为 std 做一些架构支持,可能会涉及更多修改。标准库中与架构强绑定的代码主要集中在三个模块:os、sys_common 和 sys。os 模块定义了与操作系统相关的隔离实现,主要为 trait 结构体及相关逻辑。sys_common 和 sys 的定义类似,但它们之间有相互依赖的关系,sys_common 依赖 sys,而 sys 也依赖 sys_common。它们的区别在于 sys_common 是较为公共的部分,而 sys 尤其是 sys 中的 PAL(platform abstraction layer,平台抽象层),则是更细粒度的架构相关实现。
就是说每个架构可能会有一些不一样的区分,所以在嵌入式开发时,我们可以根据自己新增的 target,如果有需要的话,做相应的扩展和新增。这与 sys_common 是类似的,因为它处理的是比较公共的部分,所以公共的部分走公共逻辑,而对于不公共的部分,我可以根据不同的架构做对应的隔离。因此,当我们为新的架构做支持时,只需要在原有标准库的基础上,针对需要区分的部分做细化处理。
不过,需要注意的是,PAL(平台抽象层)模块的设计模式可能会略有不同。虽然每个架构支持的功能可能不同,比如有些架构支持文件系统,有些则不支持,但 PAL 的设计方式是,如果某个功能不被支持,它会默认走 unsupported 模块中的实现。虽然这个模块叫 unsupported,但它实际上包含一些默认实现。比如 ones 的软件实现实际上就在 unsupported 模块里面。也就是说,默认情况下系统是有一套支持的。
因此,当我在 sys 中添加架构支持时,首先需要在 PAL 模块中为新的架构增加对应的 tag。这样做的时候,虽然每个架构的模块支持是相同的,但每个模块要么使用自己的实现,要么使用 unsupported 的实现。以 UEFI 为例,如果没有实现某个功能,它会默认走 unsupported 的实现。剩下的部分,比如内存分配器 alloc,可能与操作系统的接口对接不一样,但只需要调用相应的接口即可。而 unsupported 模块中会有一些默认实现,其他部分的设计方式大致相同:有需要支持的就实现,没有的话就用默认的实现,这种设计相对朴素。
关于 personality,默认是没有的。也就是说,在嵌入式场景下,如果我自定义标准库并为嵌入式设备提供支持,而没有实现某些功能,它会要求在模块里声明相应的 personality。与此同时,在 lib.rs 文件中,你可以根据情况添加对应的 feature 隔离。Rust 对于 feature 的管理是非常严格的,尤其是对外接口。因此,每当新增对外接口时,必须添加 stable 或 unstable 标注。对于要废弃的 feature,可以标注为 deprecated。
如果你在嵌入式场景下想使用一个稳定版的 rustc,但又想使用一些新的特性,你可以自行修改这些特性。不过这也取决于具体需求。官方推荐沿用当前版本的特性,但如果有自定义需求,依然可以对这些特性进行相应的修改。
以上是关于标准库的修改。修改完成之后,建议自己跑一下测试,看看整条链路是否打通。我们之前遇到过一些 tier 3 支持的架构,可能会有问题。例如,标准库中 core 模块默认认为某个架构上的 char 是 u8 类型,但实际上在该架构上它可能是 i8。虽然 core 和 alloc 模块一般不需要太多修改,但由于架构处于 tier 3,可能还是需要根据实际情况稍作调整。
构建 Rust 工具链时,bootstrap.py 提供了构建的入口,它有非常强大的功能。例如 dist 命令可以生成 tar 包进行发布,官方的发布流程也是通过这个方式实现的。此外,bootstrap.py build 与 cargo build 的功能类似,但由于 bootstrap 作为构建入口,它提供了更多的自定义功能,例如可以指定构建某个阶段或某个部分。构建完成后,生成的文件会放在 build 目录下。如果需要调试或手动组装工具链,可以在 build 目录中自行拼装。
由于 Rust 仓库是自举的(bootstrapped),会出现一些问题。比如,当你新增一个嵌入式架构或 feature 时,上一版本的编译器可能不认识这些内容。因此,需要使用 cfg(bootstrap) 进行隔离,以便在不同编译器版本之间切换时避免特性冲突。此外,bootstrap/lib.rs 中也有类似白名单的机制,允许你跳过某些检查,从而确保版本间特性切换时的兼容性。
接下来是关于 Rust 在嵌入式使用的简要概述。根据 2023 年的调研数据,Rust 在嵌入式领域的使用相对较少。虽然相比 2022 年有所增长,但与其他领域(如服务端、云计算、分布式应用)相比,嵌入式应用依然较少。可以期待 2024 年的数据有更好的表现。
当前一些知名应用包括 Linux 内核中的 no_std 开发,它为操作系统提供了驱动开发的初始能力。Android 出于安全性考虑,也在 TPM 固件中应用了 Rust。此外,OpenHarmony 也引入了 Rust,用于提高内核的安全性并解决并发冲突。这些应用与 Rust 的三大核心优势(安全性、并发性和性能)密切相关。
总的来说,Rust 在性能上与 C 持平,并且它的汇编和 SIMD 支持为性能保障提供了帮助。最重要的是,Rust 提供了出色的安全性,这对嵌入式领域来说至关重要。Rust 可以从语言层面消除许多安全问题,减少开发和测试中的人力投入。
然而,Rust 在嵌入式领域也有一些劣势。首先是由于内存不足时的 panic 行为,这对于嵌入式设备的高可靠性要求来说是一个问题。虽然可以通过第三方库或 unstable 接口来避免 panic,但这些解决方案尚未稳定。此外,Rust 的内存管理依赖于全局分配器(global allocator),这在嵌入式设备上可能需要更多的自定义化。
另外,由于嵌入式设备上可能存在大量的旧代码,与现有代码的交互会引入较多的 unsafe 代码,这对安全性是一个打击。最后,Rust 的二进制大小通常比 C 大,这对于资源有限的嵌入式设备来说是一个挑战。
尽管如此,Rust 提供的安全性、多样的工具支持和嵌入式架构支持,依然使其成为一个有吸引力的选择。希望未来社区能够提供更多解决方案,特别是在资源管控严格的嵌入式领域。
以上就是本期分享的所有内容。感谢大家!
27.抖音:超大规模,抖音直播的Rust技术落地实践-赵鹏
抖音直播中的 Rust 技术分享
大家好,我是来自抖音直播的赵鹏。今天主要是想和大家分享一下我们在抖音直播中落地 Rust 技术的一些经验。相信很多朋友对 Rust 这门语言非常感兴趣,也希望能够在自己的公司或部门中推广使用它。然而,在推广和使用过程中,大家可能会遇到不少问题,如何解决这些问题也是今天分享的重点之一。可能以前很少有朋友和大家分享这些内容,今天我就借此机会和大家聊一聊我们在抖音直播的实践。
我们已经在抖音直播中应用 Rust 技术有一段时间了,整体来说,Rust 的应用相对成熟,取得了一些不错的成果。接下来,我会分享一下我们是如何引入 Rust 的,并且在这个过程中遇到了哪些问题,又是如何解决这些问题的。
自我介绍
首先,我简单做个自我介绍。我在很早之前就开始在 GitHub 上做一些开源项目,对各种编程语言和开源软件都非常感兴趣,也做出了一些贡献。之前我使用过很多编程语言,主要包括 C++、Go、Python,还有一些比较小众的语言,比如 Lua 和 PHP。所以,对这些语言的优缺点都有一定的了解。在公司里,我做过很多技术领域的工作,涉及存储、架构设计、业务系统、以及机器学习系统等方面。
正因为这些经验,我逐渐意识到 Rust 在某些特定领域里的优势,尤其是在一些特殊场景下,Rust 能够规避其他语言的一些缺点。这也是我们在抖音直播中引入 Rust 的背景和逻辑。
目前,我主要负责抖音直播中的新技术和架构设计工作,Rust 团队基本上由我来负责,此外我也负责与其他部门的 Rust 基础设施对接。如果其他部门想要尝试 Rust,我们也会进行一些分享和交流。
今天分享的主要部分
今天的分享主要分为四个部分:
- 抖音直播中 Rust 的应用现状:我们目前在 Rust 上取得了哪些成果。
- Rust 落地过程中的收获与挑战:我们遇到了哪些问题,又是如何解决的。
- 混合编程模型的技术实践:详细介绍我们在推广过程中使用的混合编程模型,解决了哪些具体困难。
- 个人感受:分享一下我个人在这个过程中的一些感想与体会。
Rust 在抖音直播的应用现状
抖音直播作为国内直播领域市场份额最大的产品,有一些独特的技术特点。首先,它对于延迟的要求非常高。与图文或短视频产品不同,直播对延迟的要求极为苛刻,尤其是在主播与观众互动时,延迟过高会极大影响用户体验。
其次,抖音直播有着超高的流量和并发量。例如,在一些热点事件中,一个直播间可能同时有上千万的观众在观看,这对我们的服务器成本和技术架构提出了极大的挑战。
最后,抖音直播的稳定性要求也非常高。一旦出现问题,不仅是技术上的挑战,还可能引发舆论等影响。因此,稳定性是我们非常看重的部分。
基于这些技术特点,我们发现之前使用的 Go 语言并不能很好地满足这些需求。Go 的垃圾回收机制在高并发时容易抖动,导致延时难以保证。而在成本方面,Go 的系统性能与 C++ 等系统编程语言相比也有较大差距。同时,Go 的稳定性也存在问题,历史上曾出现过几次影响较大的事故,底层原因往往是并发读写和空指针等问题导致的崩溃。
这些问题促使我们不得不重新考虑,是否可以从编程语言的层面做出调整。于是,我们开始调研 Rust。
Rust 落地的时间线
我们在 2022 年开始调研 Rust,并发现它非常适合推理过程中的场景。经过探索,我们找了一个 demo 项目进行实践,结果非常好。Rust 不仅在成本上实现了 100% 的吞吐量提升,还能减少 50% 的资源使用。经过试点项目的成功验证,我们逐渐消除了对 Rust 的疑虑。
2022 年 10 月,我们上线了第一个真实的业务服务。随后,我们的进展非常迅速,多个业务开始同时跟进。到 2023 年,我们达到了一个重要的里程碑:上线了一个业务逻辑非常复杂的大型服务。这标志着我们不仅可以用 Rust 做底层设施,还可以处理复杂的业务服务。
2024 年 6 月,我们又达到了另一个里程碑:将抖音直播中资源占用量最高的服务(Top1)用 Rust 完成了重构,并已经灰度上线。
Rust 服务的覆盖范围
目前,我们线上已经有 20 多个服务在跑,并且这些服务类型非常广泛,涵盖了数据库、基础服务、HTTP API、RPC 服务、缓存服务、长连接网关,甚至是复杂的业务服务。可以说,我们在 Rust 的服务类型覆盖面上,应该是国内最全的之一。
目前,Rust 服务已经承担了每秒 4000 万 QPS 的流量,资源占用也达到了几十万核的规模。我们所在的抖音直播各个二级部门都已经有 Rust 开发者,并且有 Rust 服务在线上运行。这也从侧面反映了我们在 Rust 落地上的投入和决心。
Rust 的性能收益
Rust 带来的性能收益非常显著。平均来说,我们的服务吞吐量提升超过 100%,资源成本减少 50%。在一些极端情况下,吞吐量甚至提升了 300% 到 700%。内存使用方面,减少了 70% 到 90%,不过在微服务架构中,内存并不是最关键的资源。
延迟方面,Rust 的改进尤为突出,尤其是在我们直播的分发系统中,这个系统要求在 50 毫秒内完成大量的业务逻辑处理。以前 Go 语言在高峰期时会出现 P99 延迟升高,导致直播间推荐数量减少,进而影响业务指标。而 Rust 的引入显著减少了延迟和抖动。
开发者的学习与适应
在我们部门,目前已经有 20 多个 Rust 开发者。值得一提的是,很多开发者是在 Rust 技术落地后从零开始学习的。对于大家可能担心的 Rust 学习曲线问题,我可以提供一个参考数字:如果有成熟的开发者带领,加上线上业务的实际开发经验,一个从零开始的开发者大约两周就能上手开发功能,两个月左右可以独立维护一个服务。
此外,部门内部的研发流水线,包括研发、上线、测试、维护等环节,已经非常稳定。这里也要特别感谢公司基础设施部门的支持,他们提供了强大的工具链支持,使得我们业务部门能够顺利落地 Rust。
总结
希望通过今天的分享,能够给大家带来一些启发和帮助。如果大家在公司中想要推广 Rust,可以参考我们的经验。越是靠近业务端,Rust 的性能收益就越明显。Rust 的高性能和低延迟,能够为业务带来显著的提升。
再次感谢大家的聆听,希望未来有更多的公司能够成功落地 Rust 技术。
第二部分:Rust 落地中的技术问题与解决思路
在实践过程中,我们遇到了不少技术问题,接下来我将逐一分享我们是如何应对这些问题的,以及我们的一些考量。
选型问题
在引入 Rust 的初期,首先需要进行选型,选择哪些服务适合用 Rust 进行重构。我们在这方面的总结和大家的思路基本一致:逻辑简单、迭代较少的服务是最适合的。因为最初 Rust 的人才储备不足,如果需求的快速迭代开发量很大,肯定会赶不上业务的需求。
此外,还有一个重要的考量标准:资源占用量大的服务更适合用 Rust 重构,因为 Rust 的直接收益主要体现在成本的降低上。
ROI 的考量
在我们推进 Rust 重构时,老板提出了一个非常现实的问题:**如何评估用 Rust 重构的 ROI(投资回报率)?**特别是投入新的开发人员,重新编写已经在线上运行的服务,是否值得?
对于这个问题,我想分享几点感受。ROI 的评估不仅仅是简单的资源成本和收益的数字比较。研发成本的降低是一个非常重要的因素。在最初的预想中,我们认为一个开发者可能需要两个月左右的时间才能上手 Rust,但实际情况比预期要好得多。正如我之前提到的,两周就可以上手,两个月内开发者就能独立上线一个服务。这给了我们更多信心,证明了开发的成本要低于预期。
另一个重要的点是,Rust 服务的后续维护成本非常低。Rust 在编码时,通过对错误处理(例如 Option 和 Result)的严格要求,把很多潜在问题在开发阶段就解决了。因此,服务上线后出现问题的概率也大大降低,后期需要的人力投入明显减少。
历史问题的解决
我们还发现,Rust 在某些场景下能解决以前投入大量人力却无法解决的问题。举个例子,在我们的分发链路中,以前没有使用 Rust 时,曾投入十几个人,耗时一年以上,仍无法彻底解决晚高峰时的性能抖动问题。即使使用了 Go 语言的多种技术方案,包括内部研发的 Go 编译器优化,依然效果不佳。而使用 Rust 重构分发链路后,性能抖动问题得到了显著改善。这些隐性的收益也应该被纳入 ROI 的计算中。
推广中的阻力与应对
在 Rust 推广过程中,我们逐渐意识到,并不需要所有代码和服务都使用 Rust。Rust 适合的部分可以用它重写,不适合的部分则可以继续使用原来的编程语言。这是一个务实的选择。
举个例子,有些服务由于迭代速度快或业务逻辑复杂,并不适合用 Rust 重构。对于这种情况,我们采用了混合编程的方式。比如,框架层和 I/O 相关的部分可以继续使用原来的语言,而中间的业务逻辑部分则用 Rust 编写。我们使用 FFI 技术或进程间通信(IPC)来实现不同语言之间的交互。
人才培养与项目实践
Rust 的推广需要有经验丰富的开发者带领,同时要有实际的项目进行练手。在我们公司,最早推广 Rust 时,很多开发者表示愿意参与,但缺乏实际的项目。我们通过技术沙龙的形式,吸引了很多对 Rust 感兴趣的同事,并逐步提供了一些实际项目给他们练手。这种做法对于 Rust 的推广非常有效。
业务部门的落地
在业务部门推广 Rust,相比基础部门(例如数据库或系统组件开发),要容易得多。因为业务逻辑相对简单,且开发者对业务逻辑非常熟悉,他们只需要学习一些 Rust 的基础语法和适配工作即可。这使得 Rust 在业务部门的落地更加顺利。
维护成本与事故率
Rust 服务一旦上线,后续的维护成本非常低,且能有效避免很多线上问题。我们最近遇到的一次底层配置相关的事故,Rust 服务的影响明显比 Go 服务小很多。这是因为 Rust 的错误处理机制更加完善,避免了很多潜在的线上崩溃问题。
灰度上线与发布策略
为了保证服务上线的安全性,我们采用了非常严格的灰度发布流程。上线前,我们会先进行自测和 QA 测试,然后在离线环境中引流实际的线上流量进行回放,验证错误率,确保所有问题都解决后,才逐步放量发布。
Rust 推广中的谨慎态度
在推广新技术时,谨慎比追求性能收益更重要。新技术在推广初期,其副作用会被极度放大。如果因为引入新技术导致线上事故发生,整个技术推广可能就会失败。因此,我们在 Rust 推广初期非常谨慎,确保上线的每一步都非常稳妥。
混合编程的进一步拓展
混合编程的技术可以进一步拓展,用来简化链路。例如,我们在一个 Rust 重构的服务中,将前端的 HTTP API、后端的微服务、以及底层的存储设施等多个服务压缩到一个 pod 里。通过 FFI 技术和进程间通信实现不同编程语言的交互,并提高了系统的容灾性。
Rust 推广的务实主义
Rust 的推广不应追求极端的“Rust 全覆盖”。我们的目标应该是务实地选择适合 Rust 的场景,而不是强行将所有服务都用 Rust 重写。Rust 适合的部分应该用 Rust,不适合的部分则继续使用其他语言。这种务实的态度能帮助我们在大公司中更好地推广 Rust。
生态建设与开源贡献
新技术推广过程中,前期可能缺少很多工具和基础设施。我们在推广 Rust 时,很多基础工具是我们团队自己开发并贡献的。为了推动 Rust 的生态发展,前期的开源贡献精神非常重要。
人才培养与团队构建
最后,人才的培养是 Rust 推广的关键。通过实际项目练手,以及有经验的开发者带领,能够为团队提供良好的人才培养机制。
未来展望
我们团队在 Rust 推广中的目标分为三个阶段:
- 落地:Rust 已经在多个服务中成功落地。
- 成为团队的第二编程语言:Rust 已经成为团队的常用语言之一,适合的服务直接使用 Rust。
- 社区贡献:我们希望未来能够将一些社区关注的点回馈给开源社区。
我们正在寻找资深的 Rust 开发者加入,共同推动这个项目的发展,并为开源社区做出贡献。
这是我们在 Rust 推广过程中总结的一些经验与思考。希望这些内容能对大家有所帮助。谢谢!
28.在线途游:RustPixel开源项目及游戏行业应用-周欣
今天我想分享一下我个人的开源项目叫 Rust Pixel,以及公司内部推广 Rust 的一些粗浅认知。之前汉东老师也分享过一些关于 Rust 在国内 IT 行业的应用情况,特别是在游戏行业。根据汉东老师分享的榜单来看,Rust 在游戏行业一直归类在“其他”中,似乎很少被提到,确实目前使用的也比较少,应该还没有广泛铺开。
我个人写 Rust 的时间还不到两年,关于 Rust 的优秀之处,大家可能已经听到过很多。今天我会以一个初学者的视角,分享一下我学习和使用 Rust 的一些踩坑经验,希望对大家有所帮助。
我也想给 Rust 的初学者们一些信心。我是 70 后,不知道在场的有多少 70 后?我估计应该不超过十个吧?可以举手示意一下。诶,好像一个都没有?哈哈对,所以我觉得如果我还能写 Rust,那么大家肯定也没有问题。
好了,进入正题。我先分析一下游戏行业常用的编程语言。其实,游戏行业的技术栈是非常杂的,主流的编程语言在我们的项目中都用得比较多。
首先是 C++,大家都知道它是一个灵活且高性能的系统语言。我们使用的各种游戏引擎,比如 Unreal 和 Unity,它们的底层语言其实都是 C++。
接下来是 C#。我不知道为什么这个语言在游戏行业用得很广泛,主要是因为 Unity 使用它作为官方语言。
JavaScript 是我们绕不过去的,因为它是 Web 的宿主语言。现在的微信小游戏和一些 H5 游戏,只能用 JavaScript 来写逻辑。
TypeScript 是 JavaScript 的一个升级版,它对 JavaScript 类型系统的不足做了一些增强。TypeScript 也是国产 Cocos 游戏引擎的上层语言。
再说一下后端语言。我们使用 Python,它的主要特点是简单灵活,开发效率特别高。还有 Java,因为它有丰富的语言生态和强大的类型系统。
然后是 Go 语言,它语法简单,适合高并发和快速迭代的场景。
还有一个比较特殊的语言是 Lua,这个语言在其他互联网行业用得更少,但在游戏行业里比较常见。Lua 主要是从《魔兽世界》开始流行的,当时暴雪把 Lua 作为《魔兽世界》的脚本引擎。选 Lua 是因为它非常短小,解释器或虚拟机只有几百 KB,而且与 C++ 游戏引擎的亲和力非常高。
然而,这些语言各有痛点。比如 Python 虽然编程方便,但性能不行。JavaScript 过于灵活,缺乏严格的类型系统,在写一些复杂的游戏业务逻辑时还是有很多痛点的。
此外,跨平台能力也是一个大问题。尤其是手游和 PC 游戏,我们希望一套代码能在服务器、iOS、安卓,甚至 Windows 和浏览器上运行和部署。除了 C++ 之外,其他语言的跨平台支持都不太好。
不过,C++ 这个语言在游戏行业里也是让人又爱又恨。虽然它是系统编程语言,游戏引擎也都是用它构建的,但我们线上业务不太敢用 C++ 来写,因为太容易崩溃了。即使是有几十年经验的 C++ 程序员,也不敢轻易把自己刚写出来的后台服务上线运行,崩溃的可能性太大,安全性不足。
大约两年多前,我接触到了 Rust。作为一个有几十年编程经验的老程序员,第一次看到 Rust 时真的是眼前一亮。Rust 和 C、C++ 一样,属于系统编程语言,甚至可以用来开发操作系统、驱动程序和底层系统。最近几天有关这方面的分享也很多。所以,Rust 具有更高的性能和更底层的访问权限,可以直接操作硬件资源。
同时,Rust 在安全性、跨平台等工程能力上也达到了很高的水平。可以说,Rust 是编程语言中的“六边形战士”。基于这些原因,我出于兴趣开始写一个 Rust 的小游戏引擎。
最开始的时候,我也看了现成的 Rust 游戏引擎,比如 Bevy。但对于当时的我来说,Bevy 太复杂了,所以我决定从头开始构建一个比较小的游戏引擎,这样我能更深入地学习 Rust。
我现在的这个项目已经开源了,简单介绍一下:它是一个 2D 像素风格的游戏引擎,我们称之为“快速原型工具”,适合创建 2D 像素风格的游戏。甚至可以用一套代码来开发终端里的应用。它支持三种渲染模式。
第一种是 文本模式,即在终端中使用 ASCII 字符和 Unicode 表情符号进行绘图。
第二种模式是 操作系统窗口模式,基于 SDL 构建,使用了一种复古的 PETSCII 图形符号,类似 ASCII。可以把它理解为像素画或字符画。当然,这里面的内容是可以自定义的,扩展美术范围。
第三种是 Web 模式,与 SDL 模式类似,核心逻辑被编译成 WebAssembly,通过 WebGL 和 JavaScript 进行渲染。
接下来是一个演示:代码逻辑端是一套,但展示端有两种模式,一边是终端模式的字符画,一边是图形模式的字符画。下方显示的是 cargo pixel,这是我写的一个 Cargo 扩展。我觉得 Cargo 相比 CMake 有一个很大的优势,它有各种好用的工具链,比如包管理和 Cargo 本身。
Rust Pixel 实现了游戏引擎最基本的功能,包括游戏主循环、资源管理器、事件定时器等。项目中还包含一些常见的游戏算法和工具,附带了很多小游戏的 demo。同时,它也展示了如何把核心逻辑包装成 FFI 和 WebAssembly。项目中有很详细的示例,也提供了一个写终端应用的模板。
这是一个简单的演示:我用 Rust 写了一段代码,可以将动图转换成字符画的序列帧。这里是一个塔防游戏的 demo,接下来的 demo 是基于终端字符模式的俄罗斯方块。
这个是一个调色板工具的 demo。我之前提到过这个工具是为美术同学设计的,他们经常需要在各种色彩空间中选择合适的颜色组合。我帮他们做了一个终端应用工具,可以看到这个工具支持一些常用的颜色选择器和渐变生成算法。
好了,演示到这里。接下来我想讲一讲在学习和应用这个小项目过程中,遇到的一些初学者问题和踩坑经验。
首先是 生命周期。这可能是 Rust 初学者面临的第一个大坎。当初我在写游戏引擎时,把游戏中的 model 和 render 定义为引用,并放在 Game 这个主类里。但后来我也不确定为什么要这么做。我发现生命周期有一个特别棘手的特性,就是它具有传播性。如果一个结构体里显示声明了生命周期,那么在引用链上的所有地方都需要声明生命周期。这种传播性让我望而却步。
我记得有一次在晚宴上跟做操作系统的星战哥们交流,他说:“我现在能不用生命周期就不用生命周期。”他通过另一种方法,直接把结构体包含进来。我觉得这也是一件好事。
以下是我对你提供的第二部分内容的整理,保持了前后的格式一致,确保内容的连贯性和完整性:
在任何引用到这个结构体的引用链上,也都需要声明生命周期。所以生命周期的传播性让我在写代码时有些望而却步。我记得有一次在晚宴上和做操作系统的星战哥们交流,他也提到:“我现在能不用生命周期就不用生命周期。” 他通过右边的方式直接将结构体包含进来。我觉得这也是件好事。
Rust 有一个特点,就是在编写程序的过程中,你必须思考你的数据、结构和接口应该如何组织才是最合理的。如果有不合理的地方,可能就会遇到生命周期等类似的问题。但如果设计合理,其实是可以避开这些问题的。
这也涉及到全局数据的设计模式。我们知道在应用程序中,经常会涉及到全局的数据引用。我也在 Rust 论坛和其他技术论坛上查询过如何在 Rust 中使用全局数据。因为 Rust 的设计比较严格,如果不使用 unsafe 代码,它对全局数据的要求相当高,特别是要考虑并发性和数据竞争。
目前常见的 Rust 全局数据模式是用锁包裹数据,然后通过 lazy_static 的方式在程序运行初期进行初始化和加载。不过,更推荐的方式是左上角的这种模式:在程序入口时创建全局数据,然后在整个调用链和应用程序中一直传递这个 context。虽然这种方式显得有些丑陋,但我的引擎目前两种方式都有用。使用锁和解锁可能会稍微牺牲一些性能,但我不想写 unsafe 代码,因此使用了 Mutex 来包装事件和定时器。当然,大家可以对此进行讨论。不过,对于大多数全局数据,我使用的是 context 上下文设计模式,在各个调用链路上始终传递它。
在写事件回调时,我遇到了另一个麻烦。Rust 中定义通用的回调函数其实并不容易,对于初学者来说可能会是一个障碍。上面那个例子展示了 Bevy 在处理时间回调时使用的一种方式。我们可以看到它用了 ARC(线程安全的计数器)、锁、dyn(动态分发),以及生命周期等,几乎在一条语句里全用上了。当时我觉得有些头疼,所以我设法暂时绕过了这些问题。我用了最基本的 HashMap,定义了一个全局数据,然后在游戏的每一帧中检查全局数据的一些标志位,以此来触发事件和定时器。
接下来是关于 Trait 的问题。Trait 非常好用,它体现了一种现代编程语言的设计,比如 Go 和 Rust 都不推荐使用继承,而是推荐使用组合。编程时,我们其实经常是面向接口编程,而在 Rust 中,这就是 Trait。不过,Trait 虽然好用,但对于从面向对象编程转过来的人来说,它有个问题:它只能实现行为继承,而不能继承数据。这个问题该如何解决呢?我后来想到了一种方法:定义一个 base 的结构体,包含所有公共数据,然后在通用的 Trait 中要求实现一个 get_base 方法。这样在后续的 set_data 函数中,就可以调用 get_base,从而间接实现了数据的继承。
最后,我想说一下外部渲染。我的小引擎支持“一套代码,三端渲染”,所以在做 Web 渲染时有几个技术选型的问题:到底是让 Rust 直接操作浏览器进行渲染,还是让 Rust 写好图形缓冲区交给浏览器显示?第三种方式是让 Rust 只负责核心逻辑,将核心数据通过 WebAssembly 的共享缓冲区交给浏览器的 JavaScript,由 JavaScript 进行渲染。我查阅了一些资料并做了性能测试,发现第三种方式是最好的。Rust 负责核心数据,JavaScript 调用 WebGL 进行渲染,这种方式既灵活,性能又高。
大家可以看到性能数据的对比:由 JavaScript 渲染的方式可以达到 1200 FPS(在一个简单场景中)。相比之下,第二种方案性能稍逊。
最关键的一点是,第三种方案避免了编程时常提到的人体工程学问题。大家可以看到,用 Rust 调用浏览器中的 requestAnimationFrame 时,写出来的代码对初学者来说障碍很多。可能写库的同学经常会接触这种代码,但对于初学者来说,概念还是比较复杂的。什么是内部可变性?所有权该不该转移?回调函数是动态分发还是静态分发?这些概念都需要学习。
因此,我最终也是通过一些“曲线救国”的方式绕过了这些障碍。这就是我作为一个初学者在写 Rust 时遇到的一些问题和踩坑经验。
接下来,我想谈谈 Rust 在我们公司技术体系中的推广。刚才赵鹏分享了抖音中 Rust 的应用情况。作为游戏公司,我们目前对 Rust 的应用还比较浅,主要用于以下几个方面:
第一个是 欢乐钓鱼大师。大家刚才看到的视频中,钓鱼的过程是一个真同步的战斗系统,底层的定点数学库是用 Rust 编写的。
第二个是在一些休闲游戏中,我们使用了 Rust 来编写智能推荐算法。因为这些休闲游戏运行在微信小游戏中,实际上是运行在浏览器里,对性能的要求比较高。JavaScript 无法满足这种性能要求,所以我们用 Rust 编写核心逻辑,并编译成 WebAssembly,从而显著提升了性能。
在一些棋牌类游戏中,比如麻将,我们使用 Rust 来编写 胡牌算法 和 算翻算法。麻将的搜索空间比围棋还要大,特别是加上赖子后,计算量非常大。用 Rust 编写胡牌算法,比之前使用 Python 写的算法快了至少两个数量级。
另外,在扑克游戏中,我们使用 Rust 编写了 AI 陪玩算法。我们还使用 Rust Pixel 完成了前端界面的快速原型开发。在游戏的前端界面还未搭建出来时,我们可以用终端界面调试算法逻辑。
除此之外,一些与安全相关的核心算法和代码,我们也使用 Rust 重写,并以库的形式提供,以保护源码的安全。
总结一下,我认为 Rust 更适合用于对 CPU 性能、内存效率和低延迟有极致要求的应用场景,尤其是那些需要一次编写、稳定运行、不频繁迭代的底层模块。在这些应用中,Rust 的性能优化和安全性优势可以得到充分发挥。一些底层的安全相关库也适合用 Rust 来构建。
这是对快速原型的简单演示。通过这种方式,我几乎可以一个人先调试算法,编写逻辑。写好的逻辑可以被包装成 FFI 或 WebAssembly,甚至后续直接用于真正的游戏上线。
最后展望一下我们对 Rust 生态的持续发展。首先,我个人的引擎会继续学习 Bevy 等优秀 Rust 游戏引擎的思想。不过,使用 Rust 写 UI 还是有点麻烦,我可能会尝试一些声明式的 UI 构建方式。另外,Rust 的过程宏是一个利器,虽然难学,但非常好用。
我的个人愿景是结合 AIGC(人工智能生成内容),开发一款像素复古风格的互动冒险游戏,有点类似之前的 MUD 模式互动冒险游戏,适合用 Rust Pixel 来制作。
在公司技术体系内推广 Rust 时,我们会采取渐进式、非侵入式的策略,逐步替代部分 CPU 敏感的核心算法和安全相关的底层代码。同时,Rust 对人才的要求也比较高,我们会持续培养相关人才。如果有想做游戏的同学,也可以联系我。我的 GitHub 地址和联系方式都在那里。
谢谢大家!
这是第二部分内容的整理,保持了前后的格式一致,内容没有遗漏。
29.Solana如何跨过Quic这一道坎 - 李学斌
大家好,非常荣幸能在这里与大家分享。这是我第二次讲解关于Rust的内容。其实上个星期,我才第一次在深圳分享过关于Rust的内容。在此,我首先要向朱前辈表达敬意,因为我是80年代,也就是七七几年的时候学的工程。作为老工程师,我学习Rust时感触颇多。20多年前,我也是做MUD的,面对着那些SQL去做事情。
其实我本身并不算是Solana链内的人,但自从Solana链到达亚洲后,我开始深入参与,查看代码,指导他人进行开发,一直持续了4年。到现在为止,我始终保持着学习的心态,也正是因为Solana,我才开始学习Rust。我已经有了三四年查看Solana代码并指导他人学习的经验。在过去的20年里,我的主要工作是在电信层面上,比如网络通信基础设施等。我发现,在众多的区块链中,有一个链是由高通的工程师开发的,这就是Solana。
接下来,我将介绍如何从电信和通信层面来看待Solana链上需要解决的问题。我今天的讲题是“Solana如何跨过Quic这一道坎”。实际上,在座的有比我更有经验的专家,他们对Quic的技术处理更加深入。稍后大家可以听听他们的分享,尤其是关于Quic的一些技术细节。
现在我想直接进入正题,讨论为什么区块链需要使用Quic。在开始之前,我想问一下在座的朋友,有多少人已经接触过区块链技术?请举手让我看看。哦,还有一些。那么,再问一下刚才举手的朋友,有多少人接触过Solana呢?还好,还是有一些的。
首先,区块链一直以来给人们的印象是,它主要解决共识问题。区块链技术已经存在了十多年,我们不会花十多年时间只为了解决一个共识问题。实际上,区块链在这十年中已经逐步进化,解决了更多问题。
最早的区块链技术是由比特币提出的,它带来了很多创新。首先,它在经济模型上提供了一个可行的共识机制。在比特币之前,数字货币已经有了大约15年的发展历程,但没有一种方法能够找到一个真正分布式、值得信赖的方式。直到比特币的出现,利用密码学和挖矿模型,才让这个分布式系统得以成立,并且通过钱包建立身份,矿工负责处理交易,最终形成一个去中心化的账本。这个时间点之后,我们才开始谈论区块链如何解决去中心化金融的问题。
然而,这只是一个开端。比特币的出现让人们意识到,通过挖矿可以盈利,利用身份进行交易可以获得信任,密码学保证了交易的真实性。随着区块链的发展,智能合约的概念逐渐流行,尤其是以太坊(Ethereum)提出了智能合约的概念。以太坊的目标是建立一个“世界电脑”,让用户能够在上面执行更多复杂的交易和合约。
然而,以太坊并不是一开始就成功的。以太坊的创始人Vitalik在早期访问中国时,很多人还认为他是个骗子。直到2014年到2017年期间,以太坊经历了多次失败和尝试,才逐渐被市场接受,并推动了ICO(首次代币发行)的热潮。市场对这种基于区块链的赚钱机会逐渐认可,它也成为了区块链发展的主流力量之一。
以太坊推动了从工作量证明(Proof of Work)到权益证明(Proof of Stake)的过渡,虽然它并不是第一个实现这一过渡的区块链。在比特币的工作量证明机制中,每个节点都必须解决一个非常复杂的数学题目,这导致了大量的资源浪费。尤其是在欧洲,几年前能源协会就提出,区块链技术如果要继续发展,必须保证它是绿色的,不能浪费过多的能源。
权益证明(Proof of Stake)是一个解决资源浪费的替代机制,Solana从一开始就采用了这种机制。然而,Solana并不是简单地采用了权益证明,它还引入了历史证明(Proof of History)的概念。历史证明在电信行业中是一个基本的概念,Solana通过引入时间验证函数(Verifiable Delay Function)来确保在一个时间点发生的事件是按顺序加密的。只要你的计算机和我的计算机在性能上没有超过十倍以上,你就可以证明在短时间内确实经历了一个流程。
Solana的目标是解决时间同步问题,并将全球大规模同步作为其核心任务之一。所有的Solana验证节点都需要尽可能快地获得全局同步数据,而这正是Solana的核心挑战。由于Solana团队的背景来自电信行业,他们对大规模分布式网络有着深刻的理解,因此他们目标是每秒处理成千上万的交易,而不是仅仅满足每秒几十或几百个交易。Solana的目标是与Visa这样的支付系统竞争,确保其每秒能够处理大量交易。
Solana的设计目标导致了它与传统的矿机用户产生了冲突。矿机用户认为,Solana的要求过高,普通用户无法负担起这样高性能的硬件和环境,因此觉得Solana是不公平的。然而,我们需要理解的是,Solana的公平性已经转移到了参与的门槛上,即权益证明的机制。传统的工作量证明机制,虽然公平,但无法满足大规模并发的需求。而Solana则通过提高并发性,解决了这个问题。
接下来,我们可以看看以太坊虚拟机(EVM)的设计。EVM一开始设计得非常好,遵循比特币的路线,但它有一个问题:当交易量增大时,不管你是做简单的支付,还是做复杂的智能合约运算,所有人都必须排在同一个队列中。
我昨天在 Rust 大会的时候拍了一张照片,发给了我在 Solana 其他生态系统的伙伴们,告诉他们中国有很多优秀的 Solana 工程师。于是他们问我能不能帮忙推荐一些中国的工程师给他们。
所以我想说,大家如果有兴趣,稍后我回到台下会发一些资料。如果你们想尝试一下,参加面试的话,随时可以来找我,我可以帮你们引荐。
接下来,我们来做一件最简单的事情:在 Solana 上写一个 Hello World。这个过程其实是怎样的呢?首先,不管你是用 C 语言还是 Rust,程序都需要一个入口点。在 Solana 中,这个入口点被注册为一个 entry point,这个入口点必须指向一个公钥,因为每一个公钥都代表了一个账户。在 Solana 中,如何找到你的账户和程序,其实都是通过公钥来做的。
另外,如果你要修改任何数据,都会有一个“对账”过程,这个过程必定会涉及公钥来作为索引的数据结构。在验证数据时,公钥会按照某种顺序排列和检查,确保在同一个阶段内处理所有事务。然后,你还可能需要比较一些价格,类似于之前提到的情况。
Solana 中的指令非常简单,是用 Boss(Binary Object Serialization Service)串联的方法来实现的。这个方法早期由 Near 链定义,Near 是最早使用 Rust 编写的链之一。几年前的 Rust China 大会上,Links 的朋友们就介绍过 Boss 的概念。整个过程非常简单:你用 Rust 语言写下指令,执行交易,交易完成后,你可以在链上看到数据,但不会在账本上看到。这是因为在链上记录的数据是一对对的“耳刊”(账本条目),并没有对区块链本身做出修改,只是在账本中留下了一条记录。
接下来说到 Solana 的核心问题:如何实现全局最快速的同步,如何同时处理最多的请求。这是 Solana 的关键所在。与其他区块链不同,Solana 的瓶颈在于网络带宽。如何解决网络传输问题,正是 Solana 面临的最核心问题。
Solana 面临的最大压力是每笔交易的成本非常低。以当前的价格计算,每笔交易的费用只有几美分到十几美分之间。然而,智能合约中存在 MEV(最大可提取价值)的机会,这意味着你可以通过价格差获利,金额可能高达上万美元。因此,很多人愿意发出上百万笔交易指令,争取抢先完成交易。这导致网络带宽并不是用来处理高价值合约,而是被大量投机者的请求所占用。
我们看到,在 Solana 的架构中,最容易出现问题的地方是从 LPC 到 Validator,再到其他节点的传输。因为 Solana 是一个扩散式网络,没有基于中心化的架构。如果使用中心化架构,交易信息会被其他人看到,可能会导致“抢跑”,这对普通用户是不公平的。Solana 不希望出现这种情况,但代价是验证器的 Leader 需要处理极大的数据量。
Solana 也因此遇到了 DDoS(分布式拒绝服务)攻击。由于 UDP 协议没有办法防止 IP 仿冒(IP Spoofing),这就导致了 Solana 多次崩溃。但这些崩溃并不是因为共识层的问题,而是网络层的压力过大。
因此,Solana 引入了 QUIC 协议。QUIC 相当于给网络带宽打了一个“领牌”,允许验证请求的来源是否真实。这样一来,如果某个客户做了坏事,你可以阻止他;如果他没做坏事,你可以根据他的信用评分给予优先处理。这能够确保重要的交易顺利完成。
Solana 很早就开始研究 QUIC 协议了。2018 年,在 Tokyo 的 QUINN 发布后,Solana 团队在 2019 年就表示要引入 QUIC。然而,Solana 使用的某些加密技术与当年的 QUINN 存在依赖性差异,因此直到 2022 年才真正实现。在这个过程中,我们也发现 QUINN 的异步处理性能并不理想,需要同步和异步的结合,才能实现最佳效果。
到了 2022 年中,Solana 已经通过 QUIC 解决了很多问题,但新的挑战又出现了。我们以为交易量下降后 QUIC 的引入是成功的,但 2023 年 12 月,随着 Solana 价格上涨,大量投机者涌入,导致网络再度拥堵。在 2023 年 4 月,很多人无法提交交易,因为交易量实在太大了。即便是最好的数据中心也被交易请求完全填满。
我们也发现,有些智能合约会耗尽处理器的性能,导致 CPU 成为瓶颈,而不是网络带宽。即便引入了 QUIC,某些情况下网络依然会被压满,导致失败。我们不得不处理巨大的缓冲区(Buffer)问题,而 QUINN 的单流处理并不能很好地应对这种情况。因此,我们需要不断升级 QUINN 版本,并优化认证机制。
后来,我们也在 Solana 的 Leader 节点中优化了认证过程,减少了重复认证的情况,并使用 Tokio 的 RUSTOS 实现异步处理。我们还将 QUINN 分叉,进一步提升其性能。通过这些改进,Solana 能够在全球范围内实现每秒 3.5 万笔交易的处理能力,这不仅仅是实验室数据。
不过,我们也发现在 Solana 中,C 语言的性能在某些情况下优于 Rust。为了进一步提升效率,Solana 引入了来自高频交易所的工程师,他们使用 C 语言开发了名为 Fire Dancer 的模块,直接利用 CPU 的 SIMD(单指令多数据流)指令集来提升性能。虽然 Rust 在安全性和依赖性上表现良好,但在极限性能上,C 语言仍然具有优势。因此,Solana 目前采用了 Rust 和 C 语言并行开发的策略。
未来,Solana 将不再依赖通用的 QUIC 协议,而是会开发一个名为 STL 的新传输层协议,专门为 Solana 网络服务。这个协议将优化单播和握手机制,并全面使用 Express Data Path 来直接控制网卡,从而进一步提升性能。
Solana 的目标不仅仅是为几万人提供去中心化交易服务,它还将面向物联网(IoT)设备。这些设备对延迟的要求非常高,因此我们还需要改进 RPC 端口的快照功能,确保及时同步数据。
我们也在中国重新建立了 Solana 社区。在深圳、上海、杭州等地,我们组建了新的开发者群体,分享 Solana 的开发经验。我们鼓励大家学习 Rust 语言,并提供了很多工作机会。如果你对 Rust 和 Solana 感兴趣,可以加入我们的社区,参与到 Solana 的发展中来。
我的分享就到这里,谢谢大家!
30.跨语言智能合约开发:Sails框架的Rust实践与创新-航标
然后很高兴来到这个大会的现场,给大家带来Sails框架的一个介绍。首先,其实和刚才李老师介绍的SANA一样,我们的Via Network也是一个使用Rust作为智能合约开发语言的智能合约平台。不过,VA和SANA不一样的地方在于,它使用的是WASM作为虚拟机。而我们的Sails框架就是一个用来简化WASM智能合约开发的框架。
其实它推出的时间并不是特别长,所以我们可能还是会介绍一些比较基础的实践,以及它在这个过程当中为大家介绍它解决问题的思路。今天的分享主要分为四个部分:
- 首先,我会简要介绍一下Via Network的基本情况;
- 其次,我们会介绍如何在Via上进行编程,以及它所面临的一些挑战;
- 第三部分是Sails框架是如何改善我们在Via上编程的开发者体验;
- 最后,我们会展示一个使用Sails开发的Fungible Token智能合约实例。
Via Network与WASM智能合约的关系
首先,这是我们网络的架构图。可以看到,我们的网络大致分为三个层次。最底层,我们采用了Parity开发的Substrate框架,用于构建区块链,它提供了底层的点对点网络支持。我们可以在其中实现自定义的共识机制,同时它支持无分叉的Runtime升级。因此,当我们改动链上的代码时,不需要进行硬分叉。
在Substrate的基础之上,我们使用了它的Pallet来构建智能合约协议。它实现的是Action Model(Actor模型)的智能合约。在这个模型中,合约之间的通信是通过消息传递的方式,且消息可以是异步的,我们也可以并行执行这些消息。这意味着我们可以实现交易的并行处理。
相比主流的EVM智能合约平台,WASM的执行速度更快,提升了一个数量级,几乎接近原生的执行速度。同时,你可以使用传统的编程语言来编写智能合约,不仅限于Rust,虽然Rust目前的开发体验最好。因此,你可以使用Web2的语言来开发Web3的应用,实现“Write in Web2 languages, Deploy to Web3”。
与传统智能合约相比,Via上的智能合约有一些独特的特性,比如支持交易的延迟执行,交易也可以不由用户触发,而是自主执行。我们可以利用这些特性构建复杂的链上游戏。
在Actor模型中,网络的抽象是:无论是用户还是合约,都用Actor的概念表示。Actor之间通过消息传递通信,且没有显式的状态共享。你可以看到,这里没有全局的状态。当一个Actor接收到消息时,它可以产生不同的行为,比如返回回复消息、将消息转发给其他Actor,或者创建新的Actor。右边的图表明,Actor模型与后端开发中的微服务模型非常相似。如果将图中的“Blockchain”替换为“Cloud”,这个模型就非常容易理解。你可以将智能合约理解为运行在区块链上的微服务。
Via上的智能合约也被称为Program,实际上它是一种将状态保存在链上的程序。
Sails框架的功能
Sails框架提供了三个主要功能:
- 样板代码的生成:在编写WebAssembly合约时,我们会使用到很多外部函数的声明(
extern C),这些函数是合约中固定名称的函数,需导出到WebAssembly。 - IDL文件生成:编译合约时,会生成合约的IDL文件,它对外暴露的接口进行描述。通过IDL文件,能直观看到合约所提供的可调用函数。
- 自动生成多语言客户端:基于生成的IDL文件,Sails可以自动生成多语言客户端。例如,大部分的DApp都需要一个前端,Sails可以为合约自动生成TypeScript的客户端类,前端开发者只需导入该类即可,省去手动编写这部分代码的工作。此外,合约之间相互调用时,也需要使用Rust客户端,这同样可以通过IDL自动生成。
Via上的智能合约编写及挑战
下面我们来了解一下在Via上编写Actor智能合约的一些基本概念和挑战。这张图展示了Via合约的大致结构,它分为链上的Binary和链下的Metadata两个部分。这是合约项目编译后的两种产物。
- WASM Binary:定义了一些固定的入口函数,用于完成内部状态的初始化以及对外部消息的处理。合约的内部状态是完全私有的,只能通过message handler来改变状态。
- Metadata:描述了合约所能接收的消息的定义,相当于合约的Public Interface(接口描述)。
在Via上,消息通信是异步的请求-回复模型。发送的消息可能在下一个区块,甚至再下一个区块才能收到回复。智能合约标准库提供了一些异步API,并可以使用async/await语法简化异步API的使用,使其具备类似同步代码的观感。不过,合约中还是需要混合使用同步和异步函数,这可能会带来一些不便,例如无法在同步函数中调用异步函数。
由于智能合约的编译目标是WebAssembly,它是一个“no_std”环境,因此无法使用依赖Rust标准库的库。在合约环境中,没有标准的IO操作(如文件或网络读写)。对于合约而言,唯一的IO是消息的接收与发送。GSTD库是Via上开发智能合约时使用的精简版Rust标准库,它包含了类似于Rust标准库的基础类型,如Vector、String、HashMap等。对于基础逻辑的实现,代码与标准Rust代码几乎没有区别。同时,它还提供了与链上环境相关的类型定义,如合约地址等。
代码复用的挑战
在编写智能合约时,我们经常遇到如何复用代码的问题。在主流的面向对象编程语言(如Solidity)中,我们通常通过继承来复用代码。Solidity中,合约B可以继承合约A,并自动获得A合约上的方法。Rust并不支持继承,更多鼓励使用组合(Composition)的机制。比如,这里有两个结构体,我们可以在“汽车”结构体中添加一个“引擎”成员,但汽车并不会自动获得引擎上的方法。这给我们从Solidity到Rust移植代码带来了一定不便。
稍后,我们会介绍Sails如何通过宏来模拟继承机制。
另一个挑战是,如何在不同语言中与WebAssembly进行交互。
像 Rust 这种语言去移植代码,会带来一些不便。因此,待会儿我们会介绍 Sails 框架如何通过宏来模拟继承机制。另一个挑战是,在不同的语言当中,如何与 WebAssembly 进行交互。
大部分的合约都需要一个前端,因此我们需要为我们的合约编写 JavaScript 代码。刚才我们也提到过,如果需要跨合约调用,则需要手动编写 Rust 代码。如果你是开发桌面端或移动端应用,那么可能需要在 Unity 或 Swift 中编写相应的合约调用库。因此,你需要为同一个合约维护多种不同语言的代码,这实际上是非常耗费精力的事情。而且如果合约逻辑更新,你还需要手动更新这些不同语言的实现,这会带来一些潜在的错误。
接下来,我们来看一下 Sails 框架如何简化合约开发流程。下图是一个对比图:左边展示的是使用传统的 GSDD 标准库(即 Gear Standard Libraries)编写智能合约的方式,右边是使用 Sails 框架编写的智能合约。实际上,它们最后生成的 WebAssembly 二进制在底层没有区别,都是兼容 Gear 协议的。然而,Sails 框架在 Gear 标准库的基础上提供了更高层次的封装。我们只需要在它的框架基础上编写独立的模块化组件,并将这些组件组合起来,就可以得到最终的智能合约实现。
与使用 Gear 标准库的传统方式相比,使用 Sails 框架编写智能合约可以使代码更符合高内聚、低耦合的设计原则。
接下来我们介绍 Sails 框架中的一些概念。Program 实际上是合约的入口,你可以将其视为合约的 main 函数。在 Program 中,你可以注册一个或多个 Service。这里的 Service 实际上是模块化的组件。你可以在组件中实现合约的业务逻辑。Mixing 是组件间组合的一种机制,模拟面向对象语言中的继承和重载机制,实现模块化和代码设计。
路由(Router)则是用于自定义消息如何在框架中分发的机制,它可以自定义 Service 以及 Service 上公开的方法。Event 类似于 Solidity 中的事件(Event),用于表示合约中状态的修改。链下可以通过订阅这些事件,得知链上合约状态是否发生了变化。IDL(接口描述语言)文件是在合约编译时自动生成的,用于描述合约对外公开的方法。
接下来通过一个简单的例子来看一个基本的 Service 实现。这个例子展示了一个包含两个公开方法的结构体。你可以看到它有两个公开方法:greeting 和 grade。这些方法可以是同步的,也可以是异步的,我们只需要在实现的代码块上使用 Sails 框架中的 service 属性。
方法有两种类型:一种是接收不可变引用(immutable reference),称为 Query 方法;另一种是接收可变引用(mutable reference),称为 Command 方法。使用 Command 方法表示合约状态可能会被修改。
下面是一个带有自定义事件的 Service。这个 Service 的定义和之前的相同,但是在返回结果之前,它会向外部触发一个自定义事件。定义事件的方式是通过 Rust 的 enum,并为它实现 Encode、Decode 和 TypeInfo 这几个 trait。然后在 Service 的属性上通过 events 标签指定合约自定义的事件类型。框架会自动为 Service 生成一个 notify_on 方法,我们可以在合约方法中使用它对外触发事件。
Mixing 模拟了面向对象中的继承和重载特性。你可以看到,仍然使用 service 属性,并通过 extends 标签指定要扩展的 Service。这里的 hello_service 就是我们要继承的 Service。如果需要修改某个方法的默认实现,可以通过定义一个同名的公开方法来重载默认的实现。例如,我们可以让 greeting 方法返回中文的 “你好” 而不是英文的 “Hello”。继承关系可以通过箭头表示。
接下来我们为合约添加一个 Program 入口,并将这些 Service 注册到 Program 中。最终,我们将得到一个包含三个 Service 的合约。添加这个入口的方式类似于 Service,它也是一个结构体,我们称之为 entry_point。在其实现的代码块上使用 program 属性。方法的实现实际上是一系列构造器关联函数。如果它返回 self,则被视为合约的构造器。我们可以为合约定义一个或多个构造器,构造器可以接收自定义参数(此处未接收参数)。对于 Service,则返回 Service 类型,如果 Service 有状态,需要在 Program 的构造函数中调用服务的初始化函数。这里的服务没有状态,所以我们直接返回默认实例。
在合约编译时,我们会使用 sails_idl_gen 这个 crate,它会为合约生成接口描述文件。IDL 是一种与编程语言无关的语法,使用 lalrpop 库自定义语法。在 JavaScript 中,我们可以使用 sails-js NPM 包生成 TypeScript 代码,并转换为 JavaScript。而对于 Rust,我们可以使用 sails-client-gen 生成 Rust 客户端代码。这样可以方便进行跨合约调用。比如,如果 A 合约依赖 B 合约,可以为 B 合约自动生成一个客户端库,然后在 A 合约中导入 B 合约的客户端,来实现跨合约调用。
下面是一个 IDL 接口描述文件的简单例子,它描述了我们之前展示的 WASM Program 中的三个 Service。你可以看到,其中一个 Service 具有自定义事件,事件可以在 events 部分看到。其他的 Service 方法中,有些带有 query 标记,表示它们是 Query 方法,保证合约状态不会改变。
最后,这是使用 IDL 自动生成的 TypeScript 客户端库的示例代码。你可以更直观地看到,生成的 Program 是整个库的入口,并自动生成相应的类。每个 Service 上会为 Command 方法、Query 方法以及自定义事件生成对应的 TypeScript 方法。对于 Command,返回的是一个 transaction_builder 对象;对于 Query,则返回一个 Promise。对于事件,需要将回调函数传入 subscribe_to_greeting_event 方法中。
最后,我们通过一个 Fungible Token 的例子来演示如何使用 Sails 实现合约,并使用 Gear IDEA 在线工具部署这个合约。代码实现通过继承 via_fungible_service,它默认提供了转账和转让功能,但不包括销毁和铸造功能。我们通过 Mixing 机制扩展 Service,在扩展的 Service 中添加 mint 和 burn 两个方法。合约入口的构造函数可以接收自定义参数,如代币名称、符号和小数位精度。因为这是一个有状态的 Service,所以我们需要使用初始化函数来管理状态。
最后,编译时会生成 IDL 文件,并提交到 Gear IDEA。你可以在其上方看到自定义类型定义。在 constructor 部分,可以看到合约部署时接收的自定义参数。在 service 部分,可以看到对外暴露的 VFT 服务以及公开的方法,包括自定义的 mint 和 burn,以及继承自 VFT 的方法。
Gear IDEA 会根据提交的 IDL 自动生成合约部署页面,表单会根据构造函数签名自动生成,对应名称、符号和小数位字段。合约部署后,系统也会为服务生成一个交互界面。你可以看到 mint 方法的参数界面,它对应 mint 方法的两个参数。
以上就是 Sails 框架的基本展示。谢谢大家!
31-基于 Rust 编写下一代实时搜索引擎-曾勇
本次大会主要还是来交流分享的,那我们话不多说,进入正题,欢迎极限科技创始人兼CEO、前 Elastic 亚太区布道师和咨询业务负责人曾勇带来的“基于 Rust 编写下一代实时搜索引擎”的主题分享。
为了应对客户面对的万亿数据规模和实时数据新鲜度的需求,极限科技团队开发了基于 Rust 的 INFINI Pizza 搜索引擎。Pizza 搜索引擎通过技术创新和优化,解决了海量数据的伸缩问题,并利用最新算法和数据结构来提升搜索效率。它能够提供实时数据搜索能力,满足高并发、低延迟的核心业务需求,为企业提供可靠的实时搜索基础。大家掌声欢迎曾勇老师。
曾勇:
谢谢主持人,大家下午好。我是极限科技创始人,叫曾勇。非常高兴能够站在这里跟大家分享我们最近在做的一些事情,也感谢大家参加我的这个分享。
我们公司其实是一个创业公司,成立时间也不长,我们是2021年成立的,现在还不到3年时间。我个人的话,算是一个技术创业者吧。我们公司也是以技术性产品为主。
说到 Rust,我自己可能在3、4年前就开始接触了。当时自己玩了一下,写了几个 Hello World,然后因为这个东西确实有点难度,所以隔一段时间就重新学习,可能这个学习曲线还是比较长的。
我们是在大概两年前,决定做一个新的产品,一个新引擎。那个时候我们开始做规划设计,大概是去年正式启动这个项目。项目启动后,陆陆续续在做一些设计的工作。我本人真正大量写 Rust 代码的时间,大概是最近这半年的时间,投入更多一些。所以在这个 CEO 里,我算是玩 Rust 玩得稍微好一点的(笑),但和大家相比,我还是比较初级的。
这次大会也非常荣幸,能够有机会学习交流。接下来,我今天分享的内容是我们正在做的下一代实时搜索引擎,名字叫 Pizza。我会分为四个部分给大家介绍:我们在做的东西是什么,为什么做这个事,我们的一些思路,以及目前的进展,最后简单展望一下。
项目背景:
首先介绍一下项目的背景。我不知道在座的有没有用过搜索引擎的,不是说百度或者谷歌这类面向 C 端的搜索,而是更多面向企业内部的搜索。比如说,你用搜索去解决自己数据的问题。我们说的搜索更多是面向 B 端或者企业内部的一些搜索场景,主要是这么一个范围。
搜索本身这个话题其实很大,我简单罗列了一些常见的搜索产品,当然这些不全。这里有些产品可能不能算是纯粹的搜索引擎,比如有些是多模态数据库,或者是具备搜索能力的系统。它们或多或少具备一定的搜索能力或语义搜索能力,比如时下流行的降序数据库和一些其他产品。
我们用的比较多的,比如 Lucene,这是一个非常成熟的基于 Java 的库。它上面有很多引擎,比如 Solr、ElasticSearch(ES)、OpenSearch 等等,整个生态非常成熟。我自己围绕 Lucene 和 ES 有十多年的工作经验,一直在为中国和全球的客户提供服务,解决各种问题,也遇到许多挑战。
我们一直在寻找完美的方案。站在用户的角度,你首先会考虑是否开源、免费可用。经过过滤后,你会发现有一些免费开源的产品,至少在试用过程中不用花费额外费用,对开源比较友好的产品能成为选择。
其次,如果数据量不大,你可能会希望选择轻量级的产品,容易上手、使用成本低。过滤掉那些比较重的产品后,剩下的多是轻量级的解决方案。这符合 80/20 原则:80% 的场景数据量其实不大,轻量级的方案是理想的。但也有些场景,比如日志场景,数据量很大。
海量数据和分布式方案:
如果数据量会持续增长,那有没有分布式方案能够无缝支持业务增长呢?我们可以看一下,有哪些产品支持分布式架构。过滤后,你会发现不多了。
我个人偏好轻量化的解决方案,所以会直接过滤掉基于 Java 的产品。Java 本身过于庞大,虚拟机需要提前安装,镜像也会很大。这和个人偏好有关,有些人可能觉得没什么关系,这也无妨,大家可以根据自己的需求选择。
数据实时性和更新需求:
有没有可能同时支持高频数据修改或更新?在业务搜索场景下,数据肯定需要变化,不可能一成不变。日常生活中的很多场景都涉及数据的实时性,比如打车、点餐、订票等。这些场景背后都有搜索引擎支持,数据不断变化。
比如点餐时,如果某个菜品卖完了,厨师会立即更新菜单,客户无法再下单。如果数据有延迟,客户体验会很差。如果你是一个大平台,比如在线订票,房间刚挂上去就被秒杀掉了,客户体验不好就会投诉。因此,数据实时性是非常大的挑战。
数据更新也是一样的。比如在 ES 中,文档模型可能会有几百上千个字段,放在一个大的 JSON 里。你需要进行检索,但每次更新,ES 需要整体替换整个文档,无法只更新某个字段,效率非常低。
我自己十多年前在做搜索平台时,就经常需要进行重建数据和切换。十多年过去了,很多客户依然面临这个痛点,经常需要重建数据,因为无法做到实时更新,效率太差。这是一个长期存在的问题,目前没有很好的解决方案。
核心业务 vs. 非核心业务:
在搜索场景中,有些系统并不那么敏感于数据的实时性,因此我们可以分为核心业务和非核心业务。
非核心业务,比如 OTAP 分析系统、BI 决策系统,更多是内部人员使用,关注的是大趋势,不关心个体数据的精度。因此,数据的新鲜度要求不高,延迟也无所谓,丢几条数据也没什么影响。
核心业务则不同。比如在线订票平台,订单数据一条都不能丢,必须实时返回,挑战非常大。并发量也高,用户越多并发就越高。相较于内部系统的员工,核心业务的用户量和并发量都要大得多。
产品的挑战与解决方案:
核心系统对于数据并发、延迟和更新的要求非常高,而非核心系统更多关注吞吐量和查询。很多产品,比如 Rust 中的一些日志系统,更多是针对非核心业务场景,记录日志,成本较低。但今天我要讲的,是针对核心业务场景的解决方案。
我们希望通过 Pizza 搜索引擎,解决客户的痛点,为核心业务提供一个高效、可靠的实时搜索解决方案。
好的,我将按照你的要求,保持内容完整且格式一致,重新整理这段内容,使其更加连贯、通顺。
在相同的数据量情况下,如果这些数据需要频繁更新,尤其是一些互联网业务系统,它的用户量级非常大。比如说,如果你做的是云盘服务,或者是在线听歌服务,每个用户的听歌记录都需要被记录下来,这种情况下,数据量就会非常大。所以,在这种场景下,我们发现现有的解决方案并不够理想,因此我们决定自己来解决这个问题。这也是我们的目标。当然,目前我们还面临一些难题需要解决。
我们和很多朋友聊过,他们认为这个项目的工作量非常大,难度也不小,甚至有人建议我们放弃。不过,我们觉得有时候应该选择去做那些虽难但正确的事情。对于我们而言,这就是一个挑战,但我们希望能够把它做好。因为在国内,还没有人做过类似的事情。
我们这个引擎的名称叫做“英菲尼披萨”。为什么叫“披萨”?这个命名的具体原因我们稍后会详细解释。首先,我们非常清晰地知道自己要解决的问题。我们的产品定位是解决核心场景,尤其是那些需要频繁更新数据的场景,同时还要满足高并发、低延时的搜索需求,并且还要具备业务数据的关联能力和原地更新的能力。这些都是我们需要重点关注的几个方面。
接下来,让我们谈谈我们打算如何做这件事。首先,硬件的发展已经和几年前大不相同了。以前的机器配置远不如现在,现在在阿里云上可以买到上百核的机器,内存也可以达到TB级别。如果是核心业务场景,客户在硬件上的投入是绝对不会吝啬的,基本上会把硬件配置拉满,比如几十核甚至上百核的单台物理机,内存插满,SSD配置成RAID 0,性能需求非常高。
但是,尽管硬件资源很充足,性能却往往无法充分发挥,CPU利用率上不去,内存使用中也会出现各种问题。这是因为现有的一些成熟方案,比如基于Lucene的ElasticSearch(ES),它们是基于Java虚拟机(JVM)的。而Java虚拟机在处理大内存时,会面临垃圾回收(GC)的问题,这会成为一大挑战。因此,很多使用ES的用户都会被建议不要将堆栈内存设置得太大,否则系统可能会变得不稳定,甚至效率低下。尽管硬件资源足够,系统依然可能出现问题,比如响应缓慢或不稳定。
于是,很多客户在一台物理机上运行多个ES实例,导致资源竞争非常激烈,CPU大量时间用于无谓的开销,效率非常低下。这就是我们目前面临的现状。
我们相信,未来几年内,在单机上充分利用大内存的场景一定会变得更加普遍。那么,选择什么样的编程语言呢?答案很明显,是Rust。Rust的内存安全特性可以避免内存泄露问题,这对于处理大内存的系统来说尤为重要。我们做了很多思考,最终选择了Rust作为我们的开发语言。
在硬件资源充足的情况下,比如一台机器有上千核、上TB内存的情况下,我们需要设计什么样的架构?摩尔定律已经失效,CPU的主频停滞不前,多核架构却在不断发展。我们需要一套能够充分利用多核架构的软件架构。
目前,很多软件架构没有很好地适配多核架构,比如ES。在生产环境中,通常会关闭NUMA(Non-Uniform Memory Access)架构支持,因为它不能很好地支持NUMA架构。如果开启NUMA,跨节点访问内存时会带来性能开销。因此,很多人会选择关闭NUMA,以避免性能瓶颈。
我们希望设计出一种更合理的架构,能够实际利用CPU和内存的本地访问特性,避免不必要的资源竞争。我们参考了很多业界的案例,比如C++中的Seastar框架,它在数据库领域取得了巨大的成功。例如,ScyllaDB和RedPanda通过这种架构实现了性能的飞跃,达到了十倍的性能提升。
Rust生态中也有一些类似的尝试,比如TiKV的开发者在Raft中做了一些尝试,但遗憾的是这些项目没有得到长期维护。字节跳动的VIO也是一个类似的架构,我们也在尝试使用它。最终,我们的披萨引擎采用了类似的架构。每个CPU核心都是独立的,数据被细粒度地拆分,每个核心只负责自己的数据。核心之间通过消息传递进行通信,避免锁竞争和上下文切换,从而实现高效和低延时。
基于Rust开发的系统,我们可以将性能优化到微秒级甚至纳秒级,极大地提升了系统的响应速度。
此外,我们的系统需要处理海量数据。很多客户的数据已经接近万亿级别,数据迁移已经花费了很长时间。我们的产品是分布式的,并且是多租户的架构设计。我们在分布式系统的设计上也做了一些思考。
目前,很多分布式系统采用的是Master-Slave架构,Master节点负责元数据管理。然而,随着数据量的增加,Master节点会成为瓶颈。以ES为例,它的每个节点的元数据都是对等的,这样当数据量增加时,元数据的管理压力会非常大,最终会影响系统的可扩展性。因此,很多ES用户不得不将大集群拆分成小集群进行管理,非常痛苦。
我们希望设计一种更加无感的方式。我们采用了多级关系的架构,一个大的集群可以包含多个Region,每个Region相当于一个小范围的自制单位。我们通过这种层级化的管理方式,可以更好地管理元数据的分布,避免单点瓶颈。
在数据分片的设计上,我们也做了一些创新。以ES为例,它的分片是固定的,随着数据量的增加,当一个分片存储满了时,用户不得不重新创建新的索引,增加分片数,这在大规模数据环境下非常低效。而且用户很难提前预知数据量的变化,因此在实际操作中非常麻烦。
我们做了一个全局ID的设计,这对于数据更新来说非常重要。更新某个文档时,需要快速定位到这个文档的位置。我们的ID设计采用了两维的方式,第一维是Ring,第二维是内部自增ID。通过这种设计,我们可以支持非常大规模的数据存储和快速更新。
接下来解释一下为什么我们叫做披萨。我们的数据增长类似于烙饼,不断往里面写数据,直到写满为止。每个Ring的大小是固定的,当一个Ring写满后,就会“出炉”。这种固定大小的设计让性能更加可预测,同时支持水平扩展。
我们还可以将每个Ring拆分成多个Slice,分布在不同的机器上,实现动态拆分和合并,从而支持海量数据的扩展能力。
我们也在研究如何让数据写入和落盘的过程更加高效。我们采用了顺序写入的方式,并且同步写入内存。这意味着我们的系统可以做到实时写入和查询,数据写入后可以立即查询,无需像ES那样做定期的Refresh。
在未来,我们计划进一步优化查询能力,支持向量化检索、大模型推理、原地更新等功能。每个字段的存储类型可以插拔,支持根据需求选择最合适的存储结构。
关于披萨名称的来历和我们未来的展望,大家可以访问我们的网站 披萨.rs,我们也会在GitHub上开源这个项目。目前,我们的核心引擎正在重构中,暂时还没有完全开放,但我们有一个轻量级的WebAssembly版本供大家试用。
最后,我们还开设了一个Discord社区,欢迎大家关注我们。希望未来能有更多的朋友参与到这个项目中。
以上就是整理后的内容,保持了原文的完整性,并且使其更加通顺易读。
32-TiDB Cloud Serverless 的云原生架构进化 - 闫明
<br
<br
主持人:
OK,刚刚曾老师也提到了 TiDB,然后说 TiDB 在 Rust 的领域有很多先进的领先经验。接下来,欢迎 TiDB Cloud Serverless 存储引擎资深研发工程师闫明,带来《TiDB Cloud Serverless 云原生架构演化》的主题分享。相信很多人对 TiDB 都不陌生,它是国产数据库的佼佼者。通过本议题,我们将了解 TiDB Serverless 架构,以及 TiKV 存储层如何实现 Serverless,实现多租户隔离,单集群支持百万级租户。现在有请闫老师,大家掌声欢迎!
闫明:
好,谢谢大家,下午好。今天主要介绍一下 TiDB。刚刚主持人也说了,其实 TiDB,至少对关注过分布式数据库的开发者或者架构师,或多或少都是有一定了解的,甚至有的已经在使用了。
今天分享的主题是关于我们在开源社区 TiDB 架构的基础上,如何在云上实现 Serverless 架构的进化。
分享内容大纲:
背景介绍
- 我们为什么要做 Cloud?
- 做完 Cloud 后,为什么要进一步推进 Serverless 化?
什么是 Serverless?
- Serverless 数据库应具备哪些特性?
Serverless 的实现
- 我们是如何实现 Serverless 的?
- 我们需要关注的几个关键点。
总结
为什么要做 Serverless 数据库?
首先,我们先看看 TiDB 集群的社区版本。TiDB 集群主要包含几个组件:
- TiDB: 上层的计算组件,负责 SQL 解析和一些相关的计算任务。
- TiKV: 核心存储组件,使用 Rust 编写。Rust 在 2015 年发布了 1.0 正式版,而我们在 2016 年就开始采用 Rust 构建 TiKV。Rust 的内存安全性、高性能,以及调用 FFI 时的低性能损耗等优势,使其成为打造 TiKV 的最佳选择。虽然当时 Rust 生态还不完善,分布式系统的 Raft 协议库也没有现成的实现,我们因此造了不少轮子,推动了 Rust 在国内的应用。
- PD: 负责 Region 的调度和分布式事务中的全局时间戳分配(TSO)。
- TiFlash: 提供列存引擎的查询,支持 OLAP 工作负载。
为什么要做 Cloud?
在 2019 年,我们开始尝试做 Cloud。原因是如果用户想要在生产环境中使用 TiDB 社区版,需要准备相当多的资源。例如,TiKV 和 PD 各至少需要 3 个节点。此外,根据业务查询量的不同,可能还需要部署多个 TiDB 节点。这对于用户来说,前期资源准备和成本都非常高。
TiDB Cloud 的优势在于:
- 按需扩缩容:在云上没有资源限制,用户可以根据需求动态扩缩容。
- 高可用:云上的机器严格按照不同的可用区(AZ)划分,保证了高可用性。
- 简单定价:用户可以简单明了地了解定价,并且在遇到问题时有技术支持。
为什么要做 Serverless?
到了 2022 年,我们开始推进 Serverless,主要是因为即使在云上,创建一个 TiDB 集群的成本仍然很高。中小用户即使数据量较小,也需要投入大量资源。Serverless 能很好地解决这个问题,初期没有数据时不收费,按实际使用量计费。
我们的目标是面向全球开发者,数据库集群可能会达到百万量级。社区版的架构在云上无法承载如此大规模的集群。因此,我们采用了 Serverless 架构,实现更高的灵活性和更低的初期成本。
大多数业务负载都有波峰波谷,传统数据库在没有流量时也照常计费,造成了资源的浪费。Serverless 数据库能够根据负载动态调整资源,避免浪费。
Serverless 数据库的特征
Serverless 数据库具有以下特征:
- 全托管,自动扩展:完全不需要人为干预。
- 高吞吐,无限容量:用户在创建数据库时无需指定容量或性能指标。
- 高并发,低延迟:性能优异。
- 无需预留服务器资源:没有请求时,数据库实例不计费。
- 按需扩展,按量付费:弹性扩展,成本优化。
例如,Aurora Serverless 也标榜自己是 Serverless,能够应对不频繁、间歇性的工作负载,并在不到一秒的时间内透明扩展。
Serverless 数据库的核心价值在于:
- 用户不需要关心基础设施。
- 满足多样化的工作负载。
- 提供高性价比服务,按实际使用付费。
TiDB Serverless 的实现
TiDB Serverless 具备以下特征:
- MySQL 兼容:更好地利于现有技术栈的使用。
- 零停机时间:保证服务持续可用。
- HTAP 支持:同时支持事务和分析工作负载。
- 无缝弹性:按需扩展或缩减资源。
- 按量计费:根据实际使用情况收费。
架构实现
我们采用了 Shared Storage 架构。与社区版的 Shared Nothing 架构不同,Shared Storage 架构的存储节点共享同一个对象存储,所有数据都存放在对象存储中。
- Shared Nothing 架构:社区版中使用,每个节点都存有完整的数据副本,适合容灾。
- Shared Storage 架构:在云上,我们所有的存储节点共享同一个对象存储,避免了节点之间的数据传输,降低了跨可用区的流量成本。
在 Shared Storage 架构下,数据只存储一份,所有计算节点从对象存储中恢复数据。这样可以减少跨可用区或跨区域的数据传输,显著降低成本。
TiDB Serverless 的架构图
整个架构可以分为以下几层:
- 网关层:提供统一的访问入口,每个用户映射到自己的计算资源,即 TiDB 实例。
- 存储引擎层:支持行存和列存,数据存放在共享的对象存储中。
- 共享内部服务层:负责将存储引擎中的一些计算任务拆分出来,例如 Compaction 操作。
Compaction 操作:在使用 LSM 树的数据库中,Compaction 是将随机写操作转换为顺序写的关键步骤。采用 Shared Storage 架构后,Compaction 操作可以在远程的无状态服务中完成,降低存储引擎的 CPU 和 IO 负担。
最右边的资源池则负责…
然后再发给这个存储引擎。这样的话,我们就可以大幅降低存储引擎这一层不必要的工作,就是把计算相关的任务全部拆分出来。
最右侧的资源池其实是一个资源池,我们事先会维护这个资源池,主要是用于用户在首次连接时的冷启动优化。因为维护了资源池,当用户第一次连接时,网关会直接从资源池中拿出一个 TDB 的实例,进行绑定。绑定到租户后,就可以正常访问底层存储。
接下来我讲一下我们最终选择了 Rust 的原因。Rust 语言的内存管理非常优秀,外加它强大的编译器,可以节省很多后期调试的工作。
Serverless 需要解决的四类问题:
多租户:Serverless 架构需要承载百万级的租户。我们需要对每个租户的数据做好隔离,确保数据不会互相影响,并且做到多租户的无缝接入。用户使用数据库时,感觉和使用独立数据库是一样的。
爆炸半径控制:假设一个集群中同时服务百万用户,若某个租户的数据或使用方式有问题,甚至存储引擎有 bug,触发了问题,我们需要确保问题不会扩散到其他用户,避免因一个租户的问题导致整个集群不可用。
弹性:弹性包括无状态服务与有状态服务的弹性扩展。我们支持 region 的分裂和合并,保证服务可以随着需求灵活扩展。
安全性:安全性是数据库的基石,包括数据加密、传输加密,以及持久性保障。
多租户的数据分布
在 TKV 中,数据是按照 key range 进行划分的。我们在实现 Serverless 时,每个租户的 key 在编码时会增加租户 ID 前缀,这样可以保证每个租户的数据在逻辑上是完全隔离的。
如果某个租户的数据量非常大,可能会被分成很多 range,这些 region 会均衡分布在所有的 store 上。
底层存储设计的不同
相比社区版本的存储结构,我们的设计有一些不同。每个 region 都是一个独立的 SM Tree,而社区版是将所有 region 放在同一个 SM Tree 中。这会带来一些问题,比如说某个 region 特别热或写入量大时,可能会影响整个 store 的性能。而我们将每个 region 独立管理,避免了这种性能干扰。
SM Tree 结构
SM Tree 的结构类似于社区版,但在最下层我们使用了对象存储。内存中有 Memtable 和 Immutable Memtable,辅助查询的有 bloom filter 和 block cache。磁盘上的数据会缓存到 disco cache 中,但真正的数据是在 S3 上。
每个 level 中的 ssTable 可以理解为一个引用,指向 S3 中的对象。整个 SM Tree 可以看作是元数据,因此非常轻量。
Compaction 问题
在 SM Tree 中,频繁的 compaction 可能导致性能问题。我们引入了 blob table 来存储较大的 value 数据。在 L0 层进行 compaction 时,对于超过 10K 的 value,我们会将其写入 blob table,并在 ssTable 中只存储一个指向 blob table 的引用。这样可以大幅减少 ssTable 的大小,从而减少 compaction 发生的次数。
列存与行存的差异
我们在云上直接用 Rust 实现了一套 column engine。行存是按行存储,整个表的所有列都会被编码成一个二进制的 value 存储到 KV 中,适合 OLTP 场景。而列存则是按列存储,适合 OLAP 场景。列存的优势在于查询效率非常高,特别是在查询宽表时。如果只查询某几列,列存只需要读取对应的列数据,而行存则需要读取所有数据并进行解析。
列存也对 CPU 的 SIMD 指令有很好的支持,可以大幅提高查询和处理能力。并且列存对缓存非常友好,因为 OLAP 场景通常是顺序查询,列存的压缩率也更高。
列存与行存的整合
我们在 SM Tree 中增加了 column SM Tree。数据从 Memtable flash 到 L0 后,将数据按 schema 解析为列数据,并写入 column 文件中。列存也有三层结构,类似于行存的 compaction 机制。
故障隔离
我们可以对特定的租户进行隔离。例如,如果某个租户出现问题,我们可以将其加入黑名单,服务启动时不会加载该租户相关的数据。这样可以避免一个租户的问题影响其他租户。
对于 region 级别的故障,如果某个 region 的数据导致 server panic,我们可以追踪到出问题的 region,在服务启动时跳过该 region,从而确保其他租户和 region 的服务不受影响。
无状态服务的扩展性
TDB 的 gateway 有流量感知功能,当流量增加时,会自动扩容无状态服务的副本数。像 compaction 和 remote core processor 这样的无状态服务,我们采用 K8S 的 HPA(Horizontal Pod Autoscaler)方式进行自动扩容。当 pod 的 CPU 利用率超过一定时间后,HPA 会自动扩容,资源使用率下降时也会自动缩容。
存储节点的扩展性
存储节点的扩容通过 K8S 的 operator 实现。operator 定期采集 region 的资源使用情况,若资源利用率较高,会自动扩容新节点。扩容后,operator 将原有节点上的数据快速迁移到新节点,平衡负载。
由于每个 region 的 SM Tree 是非常轻量的,迁移时只需迁移元数据,新的节点会从 S3 上加载数据。
Region 分裂与合并
当一个 region 写入大量数据时,会触发 region 切分。切分后的 region 仍然是独立的 SM Tree,只是元数据不同。切分后多余的数据会由 remote compaction 来清理,因此不会影响正常的读写。
Region 的合并也是类似的。我们可以将不同层的 SM Tree 文件引用合并,更新元数据即可完成 region 合并。
安全性和持久性
在 Serverless 架构下,数据安全性非常重要。每个租户可以自定义加密证书,S3 也提供加密存储和 ACL 权限控制,确保数据访问安全。组件之间的通信都使用 TLS 加密。
在持久性方面,我们在上传文件到 S3 时,会先进行本地校验,并上传 checksum,确保数据传输过程中的完整性。S3 提供了 11 个 9 的数据持久性保证,因此无需担心数据丢失。
我们还可以在秒级完成集群的全量备份和恢复。
成本优化
在 Serverless 架构下,成本控制是关键。我们会根据不同组件选择最优的实例规格。无状态服务使用 Spot Instance,可以节省 90% 的成本。S3 采用分级存储,30 天后的数据会自动迁移到冷存储,进一步降低成本。
总结
基于新的对象存储架构,我们带来了诸如存算分离、弹性扩展、容量提升、实时备份和数据安全等特性。如果大家对数据库有需求,可以自行创建,免费的版本大家都可以使用。
提问环节
提问者 1:在秒级备份时,如何保证它真正是秒级?是依赖于 S3 自身的迁移,还是依赖于 SM Tree 中的索引映射?
回答:秒级备份主要依赖于 region 的元信息。我们除了存储引擎外,还有一个类似 WAL 的存储引擎,实时将元信息备份到 S3。元信息非常轻量,即使有数百万租户,备份的数据量也在百兆级别,因此可以快速完成。
提问者 2:K8S 的 HPA 策略下,流量突增时扩容较慢,核心服务如何保证不受影响?
回答:我们的 HPA 扩容主要针对无状态服务,例如 compaction 等。这些服务即使延迟一点也不会影响核心的读写操作。
提问者 3:底层存储使用 S3,有没有针对阿里云 OSS 的计划?
回答:目前我们主要在 AWS 上部署,虽然还没有支持阿里云 OSS,但对象存储的接口差别不大,未来可以支持。
由于时间关系,提问环节到此结束。如果大家还有问题,可以私下交流。
33-用 Rust 编写基于 DSL 的路由引擎 - 孙大同
主持人开场:
呃好的嗯,接下来就欢迎由 Kong Gateway 组的首席工程师和 Tech Lead 孙大同带来的《用 Rust 编写基于 DSL 的路由引擎》的主题分享。Kong API Gateway 是世界上最受欢迎的开源 API 网关之一,在 GitHub 上有 3.8 万个 star,以及大量世界 500 强商业用户。Router 是 Kong Gateway 里最重要的组件之一,负责所有下游用户请求的分发,对性能、质量、稳定性的要求极高。本次分享将深入探讨 Kong 团队在成熟开源商业产品中引入 Rust 的心得,取得的成就以及遇到的问题和解决方法。让我们掌声欢迎孙老师!
孙大同:
好,感谢大家,今天过来听我的这个演讲,也感谢组委会辛勤付出,来组织这次活动。我叫孙大同,刚刚主持人也已经介绍了。我来自硅谷的一家创业公司,叫 Kong。简单介绍一下自己,我是 Kong Gateway 组的首席工程师和 Tech Lead。我以前在 Cloudflare 和 OpenAI 工作,2017 年的时候开始写 Rust 项目,这些项目现在还在我的 GitHub 上。2022 年,我是第一个在 Kong 内部上线生产环境的 Rust 项目,也就是今天我要给大家讲的这个项目。最后,如果在场有对飞行感兴趣的朋友,可以来找我聊聊,我自己考了私照和仪表飞行执照。
那咱们不废话了,直接进入正题。
Kong API Gateway 简介
首先,可能不是所有同学都听说过 Kong。我们是一家做 API 网关的公司,目前每天处理大约 4000 亿个 API 请求,拥有 700 多个付费用户,去年我们的年收入已经超过 1 亿美元。在 GitHub 上,我们有 3.8 万个 star,欢迎大家关注我们的项目。
Talk 主要内容
今天的分享主要包括四个部分。内容比较简单,不涉及特别高级的算法或深奥的知识,更多的是讨论如何在成熟的商业项目中引入一项新技术,以及如何让用户接受这种新技术,并实现双赢。
路由引擎重写的原因
首先,谈谈为什么我们要重写路由引擎。这既是一个自下而上,也是一个自上而下的决策。讨论这个问题之前,我们先简单介绍一下 Kong 是如何处理请求的。
旧版路由配置
左边展示的是旧版 Kong 的配置格式。如果熟悉 Kong 的朋友应该知道,路由配置的写法大致是:你指定在什么条件下进行匹配,并列出可能的值。这些条件之间是 “或” 的关系,而不同字段之间是 “与” 的关系。举个例子,路由可以匹配 HTTP 或 HTTPS 协议,而方法必须是 GET 或 POST。
右边是一个流程图,展示了请求进入系统后的处理流程。请求进来后,会首先通过核心组件 Router,它有一个 execute 方法,如果匹配成功,就会继续代理流程,否则就会返回 404。因此,Kong 的 Router 是一个非常关键的部件,因为每个请求都要经过它。它的稳定性和性能对于我们产品至关重要。
为什么要重写路由引擎?
我们重写路由引擎不是因为 Rust 很酷,而是因为我们确实有痛点,主要有四个:
旧算法效率低:我们之前的路由是用 Lua 写的,算法实现得不是很好,重建过程非常昂贵。对于异步非阻塞的网络程序来说,这是个大问题。每次修改配置都需要重建路由,从而导致代理路径上的延迟波动很大,用户感受非常明显。
配置方式有限:之前的配置方式比较固定,用户很难实现复杂的逻辑组合。
无法增量更新:每次修改一条路由,必须重建成千上万条路由,这对用户不太友好。
资源占用高:旧路由引擎的内存占用过高,用户的部署成本显著增加。
两条技术路线的选择
我们考虑了两条技术路线:
继续优化 Lua 实现:这是一个自然的选择,风险低,团队也熟悉 Lua。但坏处是现有实现比较复杂,增量更新非常困难。此外,Lua 有 GC(垃圾回收),内存分配不受控制,经常出现内存碎片化问题。
引入 Rust:我提出了引入 Rust 的建议,虽然公司内没有人使用过 Rust,但我认为 Rust 可以提高开发效率、降低资源占用,并且可以利用 Rust 生态中更好的数据结构。Lua 生态太小,很多生态是 Kong 自己贡献的,但我们团队人数有限,不可能一直这样做。
此外,Rust 的安全性也很重要。路由是处理请求的第一环,面临各种复杂的网络请求,所以路由的安全性和健壮性要求非常高。
为什么设计 DSL?
我们最终决定设计一个 DSL 来解决问题。我们现有的路由配置方式已经像是一个语法树,只是非常蹩脚。我们决定干脆设计一个领域特定语言(DSL),专门解决这个领域的问题。
DSL 的设计
我们设计了一个非常简单的 DSL。比如,定义一个变量,然后在上面进行某种操作,拿它和某个值进行比较。DSL 还支持复杂的操作,比如对 HTTP 头的匹配、IP 地址匹配、变量转换(如将路径转换为小写再比较)。
引擎实现
我们的引擎是用 Rust 重写的核心组件,采用了 Rust 的安全特性。整个引擎是 Kong Gateway 3.0 的默认路由实现,每天处理上千亿次请求,并且是完全开源的。
编写 DSL 解析器
编写解析器并不难,尤其是我们这种简单的 DSL 语言。我们采用了 Rust 的第三方库 Pest,它可以帮助自动生成解析器。我们写了一个 Pest 语法文件,通过过程宏生成一个解析器数据结构。然后,我们将输入字符串传给解析器,它会生成一个 token 流,最终生成一个树形结构。
运行时 Schema 校验
我们的 DSL 是通用语言,所以它的 schema 不是在 Rust 库中定义的,而是在运行时动态配置的。如果用户引用了不存在的字段,我们会报错提示。
Kong 中的 DSL 使用
在 Kong 中,DSL 的使用流程如下:
- 开发人员将 schema 注入到 Kong 中。
- 空网关也将 schema 注入到规则引擎库中。
- 用户通过配置文件定义路由条件。
- 路由引擎根据这些条件匹配请求,并返回匹配结果。
惰性求值与缓存
我们实现了惰性求值和匹配缓存。虽然我们的路由匹配速度很快,但我们希望进一步优化性能。通过缓存某些字段的匹配结果,我们可以避免每次都重复计算,极大地提升性能。
与 Lua 的集成
最后,如何与现有的 Lua 项目集成呢?实际上,这个项目已经应用在 Kong 内部的多个项目中,其中包括 Kong 自己使用的日志系统。通过 C 的动态链接库和 FFI,我们实现了与 Lua 的集成。
如何与已有的项目集成?
如我前面提到的 Kong Gateway,实际上这个项目在 Kong 内部已经有至少三个项目在使用了,而且这些项目都具有一定的代表性。首先,第一个项目是我们 Kong 自己使用的 LOGI。这块其实我们通过 C 的动态链接库和 FFI 进行集成,并没有什么特别高级的技术含量。
其次,我们还有一种需求是在 Golang 上使用这个库。因为 Kong 的 SaaS 控制面是用 Golang 写的,而控制面必须对用户的输入进行校验,因此需要跑我们的校验逻辑。由于 Golang 的正则格式和 Rust 的正则并不完全相同,我们希望它能够使用我们自己实际的验证器。为了实现这一需求,我们也在 Golang 的控制面项目中使用了动态链接库。这对 Golang 来说并不是一个特别大的风险,因为我们的程序本身是安全的。
最后还有一个比较有趣的项目——我们的前端也使用了这个库。前端不仅用于输入校验,还具备一个 playground 功能,可以模拟路由的执行。我们通过 WebAssembly 实现了这一功能,ATC Router 被编译成 WebAssembly 的二进制文件,直接在浏览器中运行。因此,你会发现它的代码高亮和错误检查速度非常快。这并不是主要原因,最主要的原因是我们希望前端的检查规则与生产环境中实际运行的规则保持一致。我们不希望浏览器使用的正则引擎与 Rust 的正则引擎有所不同,避免在生产环境中出现无法运行的正则表达式。
关于 FFI,我们通过一个 feature 来控制它的使用。如果项目中不需要 FFI,你可以禁用这个 feature。在这种情况下,ATC Router 是不包含任何 unsafe 代码的。
取得的成果
首先,我们对 Kubernetes Gateway API 的支持完全基于我们这一套 DSL 和路由引擎来实现。当时 Gateway API 刚发布时,Kong 是第一个完全支持其第一版规范的网关。我们的 Kubernetes Ingress Controller 团队将 Gateway API 的资源转换为 DSL,并直接在 Kong 上运行,基本上实现了完整的支持。与其他项目相比,我们的实现速度非常快,花费大约一周时间就完成了支持。
另外,我们在性能上也取得了显著提升。对于 OpenAPI Spec 的路径路由匹配,这是一个常见需求。以前在 Kong 的旧路由引擎中,这种路径只能用正则表达式来写,尤其是涉及到变量位置的情况,比如 {places} 只能是单个词,不能包含斜线。由于这种复杂性,用户有时会写数千甚至上万条正则表达式,导致性能和内存占用显著增加。旧的正则引擎 PCRE 是非常耗内存的。
在 ATC 中,我们重新编写了生成算法,将其生成类似于一组蓝色的执行结构。虽然看起来比正则表达式要长,但执行速度却非常快。因为不需要运行正则引擎,我们在一个用户的配置下进行了测试,结果显示无论是延迟、内存占用还是 RPS(Requests Per Second),新方法都有显著的提升。特别是在路由条数达到 7 万的时候,旧方法已经无法维持 2500 RPS,而新方法在 8 万条路由的情况下仍能保持同样的性能。这种优化对用户来说非常有价值,尤其是对于大规模部署,节省上百台机器的可能性是存在的。
我们还取得了一些额外的惊喜,例如兼容性问题。通过优先级系统,我们实现了增量重建,并且能够保持兼容性。我们的优先级算法基于 64 比特的优先级数字,高位代表高优先级,低位代表低优先级,从而确保了优先级的可预测性。
最后,关于 WebAssembly,我们的云产品界面上运行的 Rust 正则引擎和解析器实际上也是通过 WebAssembly 实现的。因此,前端报的正则错误实际上是来自 Rust,这确保了线上和浏览器中的验证规则保持一致。
未来改进方向
我们计划对解析器进行进一步优化,具体来说是将树形结构扁平化,以便更好地利用 CPU 缓存和分支预测。我们预计这种方法能带来 10% 左右的性能提升,但这并不会完全反映在业务层面,因为业务中不仅仅只运行路由匹配。我们还考虑引入更多的数据类型支持,但目前还没有明确的需求。
至于 JIT (Just-In-Time) 编译,我们暂时不考虑,因为它的实际提升效果存疑。而且路由匹配只占 CPU 使用的 20%,剩下的 80% 是其他业务逻辑。因此,单独优化路由并不会带来显著的性能改进。
总结
感谢大家聆听我的分享。如果对这个项目感兴趣,欢迎查看我们的 GitHub 项目。如果对我们的公司或网关技术感兴趣,也可以查看我们的官方文档。我们团队目前正在招聘 Rust 工程师,如果你对这方面有兴趣,欢迎通过邮件联系我。
Q&A 环节
提问 1:
“如果后端服务异常被摘除,路由缓存如何处理?”
回答:
路由在一个请求周期内是不会发生变化的。对于后端服务异常的情况,我们通过健康检查和重试机制来处理。Kong 有一个高级的健康检查和重试逻辑,当后端服务出现错误或无法连接时,我们会自动将其列入排除名单,避免向其发送请求。这与路由本身的关系不大,我们的目标是尽量将请求代理到可用的上游服务。
提问 2:
“在 API 网关中,路由匹配之后的改写需求是如何实现的?”
回答:
改写需求有很多种,你可以根据路由匹配的信息进行改写,也可以进行无条件的改写。为了支持基于 URL 的改写,ATC 中的 context 数据结构提供了匹配信息的访问接口,例如正则匹配的具体值和位置。用户可以利用这些信息进行后续的改写操作。
由于时间关系,问答环节到此结束。如果大家还有其他问题,可以私下找我交流。谢谢大家!
34-纯异步血统的 Rust QUIC - 张鹏
接下来欢迎建源科技创始人,前腾讯专家工程师张鹏,为我们带来纯异步系统的 Rust QUIC的实践分享。QUIC 协议是下一代互联网的重要传输协议,它不仅具备 TCP 可靠传输的特性,还融合了密钥升级、连接 ID 管理、抗放大攻击等一系列特性。这些机制相互影响,使得 QUIC 在安全和网络性能上无与伦比。异步 Rust 的抽象,使 QUIC 的实现更加流畅。本次分享将展示如何使用 Rust 处理异步和处理 QUIC 的复杂细节。接下来我们把时间交给他,大家掌声欢迎。
哦,我又回来了,因为下一场分享还是我自己。OK,大家好,我是建源科技的张鹏,非常高兴今天能有机会给大家分享一下,我们使用纯异步 Rust 实现的 QUIC。今天这个分享主要有四个部分:
- 背景简介 - 主要介绍一下我们这个项目的由来。
- 异步 Rust 基础知识回顾 - 主要关注那些容易被忽视的点,这些关注点或许是初学者对异步 Rust 感到困惑的原因所在。
- 异步 Rust 与 QUIC 的结合实践 - QUIC 既是 IO 密集型,又是 CPU 密集型的项目,十分适合异步 Rust 的发挥。
- 性能优化部分 - 聊一聊 GM-QUIC 的性能优化以及接口的易用性。
好,接下来我们进入正题。
第一部分:背景介绍
我本名张鹏,近 10 年一直在研究对等网络。2017 年被收购进了腾讯,之后一直从事对等网络的音视频研发应用。毫无疑问,这些都是通过 C++ 和底层网络打交道。然而,在腾讯呆久了就发现越来越贡献不了什么价值了。对上不能为老板分忧,对下也不能带着大家成长,可能还阻碍了年轻人的发展。所以今年我出来创业,成立了建源科技。
其实问题不在于我个人不够优秀,不够努力。问题在于当前的时间节点和大环境——传统互联网已经到了瓶颈期,已经达到了天花板。说好听点,传统互联网的使命已经完成了。所以,建源科技关注的是下一代互联网。
下一代互联网是什么呢?
没人能说准。是 Web3 吗?这么多年过去了,Web3 也成功地磨掉了我的耐心。但它的理念挺好。我们认为,下一代互联网不一定非得是 Web3,但肯定会有一些先进理念,比如 AI 智能体、数据主权等。并且会使用更现代化的技术,比如 Rust、QUIC、LLM,还有去中心化架构。这些技术能渗透到更多场景,尤其是 Web2 不能良好解决的场景。最终,能在社会上普及并被大众认可的解决方案,就是下一代或者叫新一代信息技术。
无论下一代互联网在哪里,QUIC 是相比于 IPv2 鲜明的下一代特征。QUIC 肯定是下一代互联网的重要传输协议。所以我们率先用 Rust 重新造了一个纯异步版的 QUIC,并开源出来,作为对行业的一个贡献。今天的内容也是围绕这个 QUIC 展开讲的。
第二部分:异步 Rust 基础知识回顾
在介绍异步 Rust 实现 QUIC 之前,还是有必要回顾一下异步 Rust 的基础知识,热一下身。相信不少初学者,甚至一些老手,在初学阶段都有过被异步 Rust “支配的恐惧”。我们再轻松回味一下异步 Rust。
其实很简单,大家看 Rust 语言圣经的经典案例 timer_future,就是一个定时器。乍看很易懂,仔细一看还是很易懂。但要说其中有什么要点,恐怕不少人都没有想过。我们来过一下。这个入门案例其实吃透了,你对异步 Rust 就能理解个八成。
ARC Mutex 和 Waker
首先这有一个 ARC Mutex 护士共享。为什么叫 ARC Mutex 呢?因为后面有跨线程访问。然后这里有一个放 Waker 的地方,这个位置很重要。初学者很可能忽略了如何跟 Waker 打交道。
接着是为 timer_future 实现 poll 方法。这个 poll 方法也很特别,它每次都会重新执行,而且会返回得非常快。无论是简单的 Future,还是复杂的状态机的 Future,它都会很快返回。它不像进程或者协程那样会突然阻塞在某一行,然后整个被挂起,等待系统调用来唤醒它。
如果没有取得结果,它是怎么处理的呢?在这里,如果没准备好,它会把 Waker 注册进来,然后返回 Pending,丝毫不影响 poll 函数的执行完。当 Future 取得进展时,它会再来 poll。这个所谓的“取得进展”,其实是 Rust 异步的核心所在。
驱动 Future 取得进展
所谓的取得进展,简单来说就是:下一次由谁、在何时驱动 Future 取得进展。我们接着往下看。在 timer_future 创建的时候,开了一个线程,会发现原来是在这个线程里,它捕获了 Future 和 Waker。在超时后,执行驱动逻辑,这个逻辑非常简单,就是唤醒 Waker。这也证明了 Waker 是跨线程访问的。
Waker 唤醒就是让 Future 对应的 Task 重新进入运行时的异步运行时队列。对于初学者来说,一开始使用异步 Rust 时,常常想不通的点是:想驱动 Future 取得进展,就去维护一个 Future 对象,然后想何时再次执行这个 Future 对象的 poll。有些人甚至搞一个 while 循环在那里 poll,看似能得到正确结果,实际上这并不是正确的使用方式。
应当关注的是 Waker 什么时候被唤醒,何时唤醒 Future 再次执行 poll。这就是经典的 Reactor 模式。用 Future 语言封装 Reactor,非常优美。Rust 的异步库封装达到了极高的优美程度,尤其是内存分配只有一次,非常高效。
接下来,我们看看异步 Rust 是如何与 QUIC 结合的。
第三部分:异步 Rust 与 QUIC 的结合实践
QUIC 是一个新协议,运行在用户态,有双波序号,可以多路流,0RTT 就可以传输数据,彻底解决了头端阻塞的问题。然而,QUIC 的内部细节十分庞杂,RFC 读起来都晦涩难懂,比 HTTP 还难。
在介绍 QUIC 之前,我们先了解一下何谓可靠传输。
可靠传输
可靠传输其实不难理解。想象一下,发送端到接收端,整个链路就像一个水管。如果水管不漏水,那就很简单,拼命发就行了。但是,现实中水管是漏水的。链路上的路由器会丢包。为了控制发送速度,必须有一个泵,它控制着发送速度。
因为有丢包,每个包都要编号,接收端收到乱序的包会先存着,然后通过 ACK 告诉发送端哪些包需要重传。这个过程叫 ARQ。接收到的包和丢失的包,都要到达接收端,按序重组还原,最后交付给上层。
丢包是必然的,因为只有丢包,才能探测到可用带宽的边界。通过加速、丢包、降速、平稳加速的循环,传输协议最大程度地利用可用带宽。这个过程就像钱学森弹道在大气层打水漂一样,不停执行这个循环,才能利用好带宽。
QUIC 的复杂性
QUIC 不仅仅有可靠传输,每一个路径都有一套自己的可靠传输控制。它有四种数据包,还有另外两个,隐匿术包、汉能 SHIFT 包、0RTT 包和 ERTT 包。QUIC 有三大空间:引擎式空间、HANDSHAKE 空间和 GOR 空间。再加上 20 种帧,密钥升级,每个包都有不同的密钥加密保护等一系列现代传输协议的合体。
如果你不是客户端或服务端,抓包都看不见连续的包号。QUIC 的连接 ID 则不停变化,再加上连接迁移,一个连接可以有多个连接 ID,这使得中间人观察者都无法确认这些不同的 ID 是否属于同一个 QUIC 连接。QUIC 在安全上无可挑剔。
QUIC 的 RFC 9000 里详细描述了流状态机、抗放大攻击、路径验证等复杂机制。每个包的处理机制都不同,有些帧受流量控制,有些不受,有些受拥塞控制,有些不受。
第四部分:GM-QUIC 的性能优化
GM-QUIC 采用了分层架构,不像 QUIC-NE 那样全局检查连接状态。GM-QUIC 将一些逻辑独立成 Reactor。QUIC 的底层 IO 层、协议层、加解密层等都分层设计,每层逻辑独立,使得接口简洁,性能优化也更加明显。
第二部分:异步 Rust 与 QUIC 的结合实践
然后再往上就是 QUIC 协议的加解密层,一直到应用层。有趣的是,暴露在外的接口中的读写操作其实是在最上层发生的,而服务端监听新连接则是在处理“隐匿包”的时候进行的。当路由层找不到关联的 connection 时,这个操作实际上是在差了好几层的地方发生的。而且,QUIC 连接监听新流的创建和接收到流相关的数据也不是在同一层发生的,这让人对网络传输有了新的理解。
OK,分层之后呢,我们就可以拆除很多不同的 reactor 组件了。
由于时间有限,我们不能详细介绍所有内容,这里拿几个例子来说吧。首先是关于密钥的部分。QUIC 使用密钥,包括主密钥和 0-RTT 密钥。有人可能会问,一个小小的密钥真的值得为它设计一个 reactor 吗?答案是肯定的。每个包级别的密钥管理都是一个单独的案例。一方面,密钥依赖于 TLS 握手,随着 TLS 握手的数据,密钥会升级;另一方面,密钥也会被用于加密和解密数据包的收发任务。
发送数据时,如果密钥未就绪,不用等待,直接返回即可。发送操作并不会因为等待密钥而阻塞。如果某个包没有对应的密钥,直接跳过这个包,其他能发送的数据可以继续发送。在接收时,解密数据包的过程就复杂得多了。因为数据包可能是乱序的,有些 handshake 包和 0-RTT 数据包可能在密钥准备好之前就已经收到了,这时只能等密钥就绪后再处理这些包的解密任务。
不过有了 reactor 之后,就可以不管密钥是否准备好,直接开始接收处理任务。如果某个任务需要的密钥还没准备好,任务就会被挂起,等密钥准备好后,再由 Waker 唤醒任务并继续执行。这极大简化了任务的复杂性,包括创建和启动任务的复杂性。很多逻辑都交给了异步运行时来处理。
再来看之前说的收包逻辑,涉及到 QUIC 连接中的 stream 数据流。当收到 QUIC 连接的 stream 数据帧时,stream 数据会被塞入流的接收缓冲区中。如果这个数据并没有让接收缓冲区变得“连续可读”,那么 stream 的处理就结束了。但是,如果接收缓冲区变得“连续可读”,那么就会唤醒 ABBB 层的 Waker,也就是上层的 read_waker。此时,这个包的处理就完成了,函数执行到此结束。
在背后,Executor 会悄悄取出应用层的读取任务,并开始驱动它的 poll 操作,应用层将开始读取数据,直到没有数据可读为止。然后,应用层会将自己的 context 的 Waker 注册到 Waker 中,等待下次有数据可读时被唤醒。当然了,应用层也可以选择只读一部分数据,稍后再读完剩下的,这个过程完全不影响整个逻辑的内在正确性。这种配合非常融洽,设计十分巧妙。
在实现过程中,我们还发现了一个有趣的现象,就是“Pending”状态的意义。熟悉网络编程的人都知道,在 Linux 系统中,read 和 write 系统调用无论是阻塞式还是非阻塞式,返回值为 0 都是一个特殊的结果。在非阻塞的情况下,返回 0 意味着要配合其他机制来判断是否发生了错误。而在阻塞模式下,返回 0 意味着流结束,没有数据可读了。也就是说,返回 0 可能意味着没有数据可读、暂时没有数据可读,或者发生了错误,这三种情况都可能出现。
然而,Pending 状态明确表示了“暂无数据可读”,应用层在调用时不必关注这些复杂的细节。Pending 状态在上层应用层“消失”了,但在底层传输层依然保留了它的作用。这个设计让我感触颇深。
接下来这一页是 GM-QUIC 的多路径同时传输机制,这是我们实现的一个比较巧妙的地方,不过有点复杂。由于时间紧张,后面还有其他内容,所以这一页暂时不讲了。大家有兴趣的话,可以后面关注我们的相关视频讲解。
QUIC 协议还有很多其他复杂的细节,由于时间关系,我们无法一一讲解。QUIC 的 RFC 文档中包含了很多内容,右图展示的是 QUIC 的 20 种帧的流通图,非常复杂细致,可能大家看不清,不过可以参考一下。
通过异步 Rust 的自定义 Reactor 搭配 async 和 await,我们终于能够掌控这个复杂的 QUIC 协议。整体来看,QUIC 就像 Rust 的 logo——一个生锈的齿轮。表面上看起来很简单,但拆开一看,内部其实是一个复杂的齿轮箱。多个小齿轮通过 async 和 await 相互配合,共同组成了一台精密的机器。QUIC 这台复杂又精密的仪器,正是通过这些组件的相互配合得以正确运转。
第四部分:性能优化
接下来进入最后一个部分,聊一聊性能。很多人认为 QUIC 是一个新协议,BBR 协议非常高效,应该能够吊打 TCP。然而事实并非如此。TCP 经过多年的系统内核优化,在底层调用性能上远远优于 UDP。比如 TCP 每次发送数据时,系统调用可以批量处理数据,每次读写都是 4KB 或更多。而 UDP 每次发送数据包的大小只有 1500 字节,加上 TCP 还支持零拷贝技术(如 sendfile 和 readv),所以它的性能要比 UDP 好很多。
QUIC 的性能问题不能完全归咎于协议本身,而是因为 UDP 长期以来被忽视了。为了缩小性能差距,我们使用了 sendmmsg、GRO、GSO 等技术,尽量减少内存拷贝和系统调用。我们还开放了底层的 IO 接口,方便接入 DPDK(一个绕过内核的库),以进一步优化性能。
在 reactor 中,我们大量使用了 Arc<Mutex>。提到 Mutex,很多人可能会担心性能问题。确实,像 timer_future 里那个 shared state,它的共享状态总是会被跨线程访问,因此需要使用 Arc<Mutex> 来保护共享数据。这几乎是最优解。
有人可能会问:为什么不使用 channel 来替代呢?其实 channel 也有数据竞争的开销,它也需要某种程度的锁保护,只不过它的临界区较短。
这又回到了一个根本原则:只要锁的范围足够小,冲突就会越少,性能就会越好。为什么不使用异步锁呢?异步锁在别的地方锁住时会返回 Pending,等待其他地方释放锁后再唤醒。看起来很好,但实际上异步 Rust 中的异步锁性能非常差。使用异步锁时,将 Waker 放入锁的等待队列中,这个队列需要一把同步锁来保护,因此并没有带来更好的性能。
那有没有更好的方案呢?比如无锁队列?无锁队列内部其实也有 CAS(Compare-And-Swap)的自旋锁。虽然节省了系统调用,但会浪费 CPU 资源。
我们认为,遵循原则,尽量将锁的范围缩小,减少冲突,性能就会保持在一个较好的水平。使用锁并非不妥,在底层系统中,Mutex 是不可避免的。某些锁可以替换为自旋锁或者读写锁,确实可以进一步提升性能。而且,Rust 1.62 对性能也进行了很多改进。所以,只要以正确的方式使用锁,性能还可以接受,整体逻辑也比较严谨。如果大家有其他优秀的方案,也欢迎交流指正。
最后一页展示了我们应用的接口。客户端创建和服务端监听新连接的接口都非常人性化。由于天生是异步的,实现 HTTP/3(H3)的开源项目接口也非常容易。流的读写使用标准的 async_read 和 async_write,使用起来毫无压力。与其他 QUIC 实现的接口相比,我们的接口更加简洁易用。欢迎大家尝试使用,如果觉得好用,可以给我们点个 Star。我们的库已经可以与 QUIC-N 连接,并能够正常发送数据。
今天我的分享就到此结束了,感谢大家的倾听和组委会的安排。欢迎大家多多交流,有兴趣的话可以扫码加我好友,也欢迎加入我们的 GM-QUIC 群。OK,现在看看大家有没有问题。
问答环节
提问者 1:
老师您好,因为我最近也在研究 QUIC,想了解一下当前这个库的成熟度和性能表现大概是什么样子?因为我自己也希望用到这个东西,想了解它的成熟度、稳定性和性能表现如何,您后续的规划又是怎样的呢?
回答:
嗯,了解了解。其实这个库我们是在最近一年内开始开发的,尤其是从今年 4 月份开始。直到两个星期前,我们才刚刚实现并调试通过。不过让我们感到惊讶的是,Rust 在某个时间节点突然就能编译和运行了,感觉非常稳定。之后只需补充一些逻辑就可以了。
相比于 QUIC-N,QUIC-N 是一个比较老的库。按照传统的软件工程逻辑,一个项目刚刚实现时,需要经过半年的稳定期来验证。然而,QUIC-N 的 master 分支直接是不能跑的,它最成熟的版本也只有 0.11.2,并且仅支持 HTTP/3 的草案版本 HQ-29。因此,我觉得我们的实现比它要简洁,代表了更高的稳定性。虽然目前还没有经过大量的测试,但我相信经过一段时间后,我们的库会比 QUIC-N 更好。敬请期待。
提问者 2:
老师您好,我想请教一下,您前面提到的用户态基于 UDP 的可靠传输协议普遍 overhead 比较高。您提到了一些方法,比如 sendmmsg 来减少系统调用。我想请问,您有没有考虑过使用像 I/O uring 这样的技术来进一步优化?还有,您觉得 QUIC 的性能还需要哪些发展才能达到与 TCP 性能相媲美的程度?
回答:
I/O uring 我是知道的,不过它有一个问题。它允许用户态的内存交给内核态或传输层读取数据,但用户态依然可以修改这块内存。这就很危险了,用户态已经把内存交给传输层,而传输层在使用这块内存时,用户态可能还在其他地方修改它。如果出现问题,你会以为是传输层的问题。所以 I/O uring 存在这种风险,虽然它能提高性能,但对使用者提出了更高的安全要求。
因此,我们下一阶段并不优先考虑使用 I/O uring。前面我提到过,我们开放了 IO 接口,方便接入 DPDK。我不知道你是否了解 DPDK,它是 Intel 提供的一个库,能够直接从网卡接收数据,绕过内核,不需要依赖内核来调度和拷贝数据。因此,使用 DPDK 可以极大提升性能。我们会提供一套非 UDP 的收发包接口,你可以为这套实现对接 DPDK。我认为这种方案能让 QUIC 的性能更好一些。
至于 QUIC 的性能,客户端这边应该不存在性能瓶颈,主要是在服务端,特别是需要处理成千上万个连接时。如果使用 DPDK,很多大厂也都在使用它,性能会提升很多。
35-RobustMQ 下一代高性能云原生融合型消息队列 - 许文强
接下来欢迎火山引擎离线消息队列研发负责人许文强,为我们带来 RobustMQ 的主题分享。RobustMQ 的愿景是成为下一代高性能云原生融合型消息队列,目标是基于 Rust 实现,兼容多种主流消息队列协议,并具备完整 Serverless 能力。掌声欢迎徐老师!
许文强:
大家好,我是许文强。今天下午我分享了很多基础软件相关的组件,最开始讲的是搜索引擎,接着是分布式数据库,然后是 COM 网关,最后讲了网络协议 Fake。接下来我要分享的是中间件基础软件中,消息队列方向的一个 Rust 开源项目 RobustMQ。
首先自我介绍一下,我是许文强,来自火山引擎消息队列团队。我个人在这个方向耕耘了很多年。今天我发现一个现象:我们这是一个 Rust 大会,很多人在不同领域的技术上尝试将 Rust 和自己的方向结合,对我而言也是一样的。我在消息队列做了多年,也想尝试 Rust 与消息队列的结合,看看会带来怎样的成长。基础软件这个方向是靠着大家一步步往前推进的,这也是我们参与 Rust 大会并尝试 Rust 的原因。
今天的分享分为四个部分:
- RobustMQ 是什么
- 技术架构详解
- 当前已实现的 MQTT 功能
- 未来展望
1. RobustMQ 是什么?
RobustMQ 是一个完全用 Rust 实现的中间件消息队列开源项目。它是一个消息队列,并且是一个新兴的项目,旨在探索 Rust 在消息队列这个成熟技术领域的应用,看看能产生什么样的化学反应。我们的目标是基于 Rust 打造一个兼容多种协议并具备完整 Serverless 能力的消息队列。
RobustMQ 项目至今大约有一年多的时间,目前已实现了 MQTT 协议 80% 的功能。我们的愿景是希望成为消息队列领域的下一个 Apache 顶级项目。虽然目前的消息队列项目很多,但依然存在一些问题需要解决。
从行业视角来看,消息队列作为一个发展多年的领域,虽然有很多成熟的产品,但目前主流的开源项目,比如 RabbitMQ、Kafka、RocketMQ 和 Pulsar,都是十几年前甚至二十年前的产品。如今,它们在云上的应用已经遇到很多瓶颈。
从用户视角来看,消息队列家族的产品繁多,用户在选型时常常感到困惑。不同的场景需要使用不同的消息队列,比如:在线消息用 RabbitMQ 或 RocketMQ,离线消息用 Kafka 或 Pulsar。而每家公司都需要处理复合场景,导致必须维护多个消息队列,增加了成本。
现有的消息队列在弹性扩展和 Serverless 方面能力较弱,无法实现快速的弹性扩展,导致资源浪费和成本高昂。因此,很多客户选择云产品来降低成本。
从云厂商的视角来看,虽然云厂商的产品看起来高大上,但大多数产品都是基于开源消息队列二次开发的。原生的开源社区产品无法满足大规模客户的需求,因此需要进行大量的二次开发。这就导致了与开源社区的冲突,或者因为原生架构的缺陷,难以继续改动。
在云时代,消息队列被关注的重点是成本,包括人力成本和资源成本。人力成本涉及选型、运维、学习和招聘,而资源成本则涉及扩展和维护多个消息队列。
2. 个人视角
从个人视角来看,我一直对 Rust 很感兴趣。之前我做了很多年 C++,但 Rust 在安全性和性能方面有着突出的优势,尤其是它是少数可以进入内核的语言之一。虽然 Rust 的学习曲线很陡峭,但我认为要真正掌握它,需要在工业级项目中应用它。
另外一个背景是 C++ 替换的需求。在我个人的经历中,不管是在腾讯云还是火山引擎,我们都曾用 C++ 完全重写 Kafka。这是因为在实践中,C++ 的自信引擎在性能和成本上确实有优势。而 Rust 在基础软件领域的表现可能会更好,因此我希望用 Rust 替换 C++,看看能带来什么效果。
3. RobustMQ 的愿景
RobustMQ 的愿景是兼容多种主流消息队列协议,并在架构上具备完整的 Serverless 能力。我们希望通过兼容更多的消息队列协议,简化选型和运维。同时,通过实现完全弹性的架构,在长期内降低成本。
每一个新的基础软件方向都是为了解决现有问题,我们希望 RobustMQ 能解决兼容性和成本的问题,并在这个方向上做得更好。
4. 技术架构详解
RobustMQ 的架构核心是 Serverless,旨在通过拆分架构,达到完全弹性扩展的能力。下图展示了我们的技术架构:
架构的关键词是 多协议支持 和 Serverless。在金融软件领域,常见的架构模式包括存算一体和存算分离。存算一体无法快速扩展,因为扩展时需要搬迁数据,而存算分离则将计算和存储分开,以便计算和存储能够独立扩展。
我们更进一步,将计算、存储和调度分离。分布式集群中一般都会有调度层,因此要实现 Serverless 的第一步就是将计算、存储和调度分层拆开。我们的架构分为四个部分:
- 计算层
- 元数据和调度层
- 存储适配层
- 存储引擎
在存储层,我们设计了一个存储适配层,以适配不同的存储引擎。不同的消息队列在不同的场景下使用不同的存储方式,比如字节内部的存储层使用 HDFS,而开源的消息队列如 RabbitMQ 则使用 AWS 的对象存储。通过存储适配层,我们可以应对不同场景中的各种问题。
5. 元数据存储服务
我们的元数据存储服务基于 Raft 和 RocksDB 构建,具备分布式协调服务的能力。它是一个分布式 KV 存储模块,支持 Raft 协议进行扩容和 leader 切换。架构上支持 RPC 和 HTTP 协议,并通过 gRPC 进行数据同步。
元数据存储具备 Raft Group 的能力,这意味着一个集群中可以有多个 leader,从而提高性能。
(待续…)
它是一个大家可能容易忽略的巨大问题。比如说,以前很多人都会使用 JK 来存储云数据,后来却发现很多文章都在讨论 ZK,那为什么这么多人开始转向 ZK 呢?其实这与元数据存储的性能要求密切相关。元数据的存储需要很高的性能支持,因此我们希望建立一个基于 Raft 和 RocksDB 的云数据存储服务。这项服务其实是一个分布式协调服务,核心是分布式 KV 存储模块,它的内扩容和 Leader 切换都是基于 Raft 协议实现的。
从整个架构上来看,它支持两种协议:RPC 和 HTTP。GRPC 被用来在数据层面完成数据同步。它具备主节点写入、从节点读取的特性,这也是 Raft 提升性能的一个重要能力。同时,为了应对越来越多元数据的需求,它具备 Raft Group 的能力,即在一个集群中可以有多个 Leader,而不局限于每个节点只能有一个 Leader。
此外,这个 Raft 机制还支持集群的自动扩容和缩容,不会对其他组件产生影响。从 Rust 的实现角度来看,它主要依赖一些库来实现分布式协调和多协议的计算层。这也是我们希望进一步提升的地方。
在计算层方面,我们构建了一个基于云数据服务的集群化部署架构。比如说,当我们有三个 Broker 节点时,每个节点都会依赖元数据存储服务来完成节点发现和探活,从而组建集群。Broker 之间支持 TCP 和 GRPC 两种协议,TCP 协议用于数据交互。这里有一个问题与 Quick 协议相关,因为我们希望尽可能提高性能,因此计划在 TCP 的基础上支持 QUIC 协议。
GRPC 协议则用于集群间的管控和数据服务交互。我们希望支持多种协议的解析,目前每个消息队列都有自己的协议,比如标准的 MQTT、 AMQP,开源的 RocketMQ 和 Kafka,以及 PSA 协议等。尽管它们的功能重复度较高,比如消息、延时消息、事务等,但通过抽象层可以做到一套代码实现多种功能。
计算层是完全无状态的,通过 GRPC 协议将数据同步到云端存储。存储模块则有两个核心功能:存储模型的抽象和存储引擎的适配。比如,MQTT、 AMQP、 Kafka 各自有不同的存储模型,我们需要将它们统一抽象处理。第一步是将它们映射到统一的结构,比如在 MQTT 中一个 Topic 对应一个分片,在 Kafka 中一个 Partition 对应一个分片。第二步是存储引擎的适配,它要支持多种云端存储,如本地存储、对象存储和 HDFS 等。存储层不仅要适配 SDK,还要提升性能,尤其是在远端存储性能不足时,可以结合本地写入策略来保证高可靠和高性能。
尽管架构看似简单,但实际上内部需要解决许多复杂的问题。比如写入本地盘的性能非常高,但在使用对象存储或 HDFS 时,由于这些存储的设计并不是针对流式写入和读取的,因此性能提升依赖代码层面的优化,这也是一个非常复杂的工作。
在第四部分,我们将实现一个内置的分布式存储服务,类似于 Apache BookKeeper。这是一种分段式的存储引擎,它可以简化外部组件的依赖。现在很多软件使用对象存储,但在某些场景下无法使用云端对象存储,比如一些金融机构或快递公司不允许数据上云,因此内置的存储引擎能够解决这种场景下的问题。
我们的分布式存储引擎是针对消息队列业务特点设计的顺序存储模型,数据会分段存储在本地硬盘,将来可能会实现分层存储。数据一致性依靠 Raft 协议来保障,这个组件的目的是让架构更加内聚。
总结这四个部分后,我们可以看到,每一层都实现了自己的集群和扩展能力。在这个架构中,计算层是完全无状态的,存储层则依靠独立模块来保证计算层的弹性和独立性。
接下来,我们来看一下已经实现的 MQTT 协议部分。它的架构与之前介绍的计算层架构一致,只是加入了 MQTT 协议的业务逻辑。MQTT Broker 是无状态的,客户端会随机访问一个 Broker 来生产和消费数据。这与很多有状态的消息队列形成了对比,协议上的差异也导致了架构上的不同。
整个集群依赖于云数据存储服务来完成节点发现和探活。当接收到 MQTT 数据时,适配层会将数据写入云端存储引擎。尽管不同协议的逻辑不同,但架构保持一致。MQTT 协议解析和 GRPC 协议用于集群的管控调度,TCP 则用于数据读写。
最后,我们来看一下 MQTT 集群的构建逻辑。每个分布式集群都需要完成节点发现,具体有四步:Broker 启动时向云数据存储服务注册,停止时解绑,运行时上报心跳信息,心跳超时则会剔除节点。心跳的频率设置是一个关键点,如果设置过长,系统可能无法及时发现问题;如果设置过短,系统会变得过于敏感。因此,心跳频率需要根据实际情况进行优化。
网络层是 MQTT 协议中的另一个重要部分。MQTT 的特点是单机连接数极高,比如数十万,常用于传感器和车联网场景。连接数多但每次请求的数据量较小,因此我们基于 Reactor 模型设计了一个高并发的网络模型,通过 Channel 提高并发处理能力。
MQTT 协议中的 QoS(服务质量)是另一个需要关注的点。QoS0 表示消息可以丢失,QoS1 保证消息至少会收到一次,但可能重复,QoS2 则保证消息不会丢失也不会重复。这些服务质量等级会对网络交互产生很大的影响,需要在技术实现时关注这些细节。
最后,我们聊一下开源项目的代码测试。开源项目没有 QA 和测试团队,因此代码测试、功能测试和集成测试尤为重要。代码测试是最基础的一层,功能测试则涉及到 Server 和客户端的交互,而集成测试的核心是确保在测试时 Server 能够正常运行,并且客户端能够连接并进行测试。这部分其实花了我们很多时间。
对于未来的规划,我们希望在 2024 年内实现 MQTT 的生产可用性。目前我们已经完成了功能开发,但在稳定性和性能上还有很多优化工作要做。我们还希望支持更多的协议,并继续探索 Rust 的实践。
这是一个年轻的项目,我们也希望能够吸引更多的小伙伴来参与。如果大家有兴趣,可以关注一下这个项目。谢谢大家。
好的,感谢徐老师带来的精彩演讲。接下来我们进入提问环节。我们有两个问题的机会。
提问 1:
你好,我想问一下,消息队列作为服务化产品,它的存储 IO 能否达到本地硬盘的性能?尤其是像 NVMe 这种顺序写入性能很高的情况下,网盘的性能能到什么程度?
回答:
目前大家对网盘可能存在一些误解。实际上,现在很多云服务都跑在云盘上,云盘的性能并不比本地盘差,甚至可能更好。当前云盘的技术成熟度非常高,因此性能和稳定性上无需过多担心。
消息队列作为存储型产品,对于 IO 和存储的横向扩展能力非常重要。我们通过分段存储的方式来解决存储扩展问题。消息队列的特性是顺序存储,消息一旦写入不会修改,因此支持分段存储非常适合消息队列。通过分段存储,可以轻松实现横向扩展,这一点在云盘中也得到了很好的验证。
提问 2:
我们目前在做数据的 PaaS 服务,使用了很多消息队列,比如 CLS、SLS 和云托管的 Kafka。最近在调研 Redpanda,它有一个 Data Transform 的功能,我想请问你们有没有类似的功能计划?
回答:
Redpanda 是近年来表现非常不错的消息队列产品,尤其是它的 C++ 重写架构。不过从目前来看,云厂商的转向速度比较慢,因此我们不会在短期内跟进类似的功能。但功能上我们可以竞争,比如我们有基于 C++ 的 BMP 实现,可以从功能上追赶甚至超越 Redpanda。
至于 Data Transform,它解决的是 ETL 场景中的消息消费和生产问题。我们也在探索类似的技术路径,但具体的商业化和技术实现还需要一步步探索。我们相信,技术软件的演进是逐步实现的,需要不断探索和尝试。
问答环节到此结束,如果大家还有其他问题,可以私下找徐老师继续交流。
36-基于 Rust 构建企业级工作流和函数引擎的经验分享-刘萌
主持人:接下来进入我们本次大会压箱底的一场,请大家打起精神,这是最后一场。欢迎普联软件架构师刘萌为我们带来“基于 Rust 构建企业级工作流和函数引擎的经验分享”。普联软件技术团队基于 Rust 开发了分布式工作流引擎,集成了 V8 引擎,支持 TypeScript 在线脚本开发和调试。该引擎在公司业务开发团队中得到广泛应用,涉及 iPaaS、API 网关、微服务治理、AI 智能体和 RPA 等领域。接下来有请刘老师,大家掌声欢迎!
刘萌:谢谢主持人的介绍。今天我分享的主题是如何用 Rust 优化企业级工作流和函数引擎的一些经验。工作流和函数引擎其实是工具化的东西,应用场景非常多。希望今天的分享能给大家带来一些启发,并在工作中有所借鉴。
先做一下自我介绍,我叫刘萌。最早我是做 C 语言的,后来做了多年 Java。大概在 2020 年的时候,为了解决 Java 中的一些问题,比如内存使用效率和运行稳定性,我开始接触 Rust。当时我也尝试学习 C++,但发现有些地方比较迷糊。偶然机会接触到 Rust,感觉上手比较容易,所以从 2020 年开始逐步转向 Rust。不过目前我还是同时负责 Java 和 Rust 相关的工作。
现在我主要从事财务核算、多维数据分析以及企业应用和微服务基础架构的工作。我供职于普联软件,这是一家致力于财务、ERP 和企业信息化领域开发的公司。顺便做个小广告,如果大家对推动传统软件行业的进步有想法,可以加我微信,大家交流一下。
引入 Rust 的需求分析
首先,我们在传统企业应用架构中引入 Rust,需要做哪些工作?我们进行了内部需求调研,发现 Rust 并不是适用于所有场景,而是有其特定的应用领域。总结下来,需求大概分为以下三类:
流程引擎现代化:企业架构中普遍存在流程引擎,比如报销单、采购单等流程的审批流转。现有的流程引擎架构老旧,亟需技术上的现代化改造。
降低二次开发成本:企业应用的产品化程度较低,很多场景需要现场实施人员进行二次开发。如何降低二次开发的成本是我们面临的重要问题。我们希望通过零代码或低代码的方式让开发人员少写代码,甚至让前端工程师可以开发一些简单的后端应用。
集成与智能化需求:最近几年超级自动化、RPA(软件机器人)以及 iPaaS(集成平台即服务)等概念兴起,企业需要将不同的应用系统打通、集成。另一方面,智能化需求也越来越强,我们与大模型厂商合作,帮助客户在其企业环境中应用大模型。工作流技术在这些场景中是不可或缺的。
设计目标
基于这些需求,我们制定了一些设计目标:
工作流引擎:需要兼顾审批工作流(BPMN 标准)和微服务编排需求。我们希望 BPMN 只是上层表现层,核心部分需要轻量、跨语言,并且能够集成到服务端、客户端,甚至浏览器中。
DSL 定义的工作流:工作流的定义希望采用 DSL(领域专用语言),因为 DSL 易于使用、管理,并且更容易生成。尤其是通过大模型生成 DSL 要比生成代码简单得多。
函数引擎:在工作流引擎中,我们需要动态的表达式处理能力,最好是使用 JavaScript 或 Python 来实现表达式引擎。未来我们也计划开发类似 ABAP 的语言,函数引擎将是其中的重要组成部分。我们希望这个引擎能够支持在线开发、调试和发布。
平台功能:我们需要一些平台功能,比如 OpenAPI 网关、实体 CRUD 服务、规则引擎、角色引擎、定时调度、分布式部署和可观测性支持。
为什么选择 Rust?
我们选择 Rust 的原因主要有以下几点:
Rust 是系统级语言,轻量且跨语言协作能力强。
WebAssembly(WASM)可以让 Rust 代码运行在浏览器中,这对于前端逻辑编排非常有帮助。
Rust 有丰富的生态系统,比如 Deno 项目可以帮助我们构建函数引擎。此外,Rust 对 Python 和 JavaScript 的解析库也比较成熟,资源选择多样。
Rust 生态逐步完善,虽然不太容易找到合适的项目,但一旦找到,质量普遍较高。
接下来,我将为大家介绍如何设计一个工作流引擎。最早我们从 GitHub 上拉取了很多工作流相关的项目,做了简单的分类:
调度流程:例如 Apache Airflow,适用于数据管道、ETL 或定时器等场景。这类工作流编排控制能力较弱,并发能力也有限。
数据驱动流程(Data Flow):例如 Apache Camel、Nextflow 等,适用于科学计算和集成场景。它的吞吐能力强,但调度流程相对不够动态。
控制流程:类似状态机,通过事件驱动任务逐步跳转。Java 生态中很多 BPM 引擎(如 Camunda、Flowable)都属于这一类。它的动态性和扩展能力强,但响应速度略低。
我们公司有两条业务线在尝试 Rust。一条是财务核算和多维分析,采用的是数据流方式;另一条是应用开发,采用的是控制流方式。
工作流引擎设计
工作流引擎的设计包括以下几个核心部分:
工作流定义:定义工作流的名字、版本号,并编排需要执行的任务(Task)。任务可以嵌套,支持不同的执行路径(如
switch算子)。任务执行:每个任务都有唯一引用,支持表达式作为入参。任务执行时,可以根据前一个任务的输出作为下一个任务的输入。
任务状态管理:任务分为同步任务和异步任务。同步任务递归执行,异步任务则放入队列,由异步执行器处理,从而避免阻塞整个工作流。
任务类型:任务分为三类:流程控制算子、功能任务(如 HTTP 调用、数据库访问)以及用户自定义的 Worker Task。
工作流架构
工作流引擎的架构设计包括以下几个部分:
定义 API:工作流定义存储在元数据层中。任务状态可以保存在内存中或外部存储(如 Redis)中。
状态机跳转:工作流的每个任务状态都会保存到存储中。如果是异步任务,则写入队列,由执行器捕获并继续执行。
动态性支持:在微服务场景中,分布式事务是个难题。SAGA 模式是目前较为接近的解决方案。
任务跳转与状态管理
当一个任务的状态机跳转时,每执行一个任务(Task),都会将该任务的状态保存到存储中。如果任务是同步的,系统会继续推理下一步;如果是异步的,任务会被写入队列,然后异步执行器会捕获任务并继续执行。
动态性设计与SAGA模式
接下来解释一下工作流的动态性设计。在微服务中,分布式事务是一个头疼的问题,目前还没有一个业务无感知的完美解决方案,SAGA模式是比较接近的解决方案。SAGA模式的核心思想是将整个流程编排成一个工作流。
假设有一个API进来,需要完成三件事:买火车票、订航班、订酒店。左边那条线表示正常流程,任务按顺序执行,每个服务都有自己的数据库和事务,干完一个提交一个。而右边那条线展示了失败时的处理逻辑。SAGA模式的工作流,如果不支持动态性,可能会产生很多分支线条,因为当最后一个任务失败时,需要递归地进行补偿。
为了简化工作流定义,我们设计了一些动态控制参数。例如,对于某个任务(如HTTP任务)出现错误时,可以通过onError表达式决定进入哪个错误分支。在错误分支中,我们可以编排常规任务,比如等待一段时间后重试,或者让任务直接失败,甚至进行补偿。补偿时,可以定义当前节点的补偿任务。
通过这种方式,可以减少工作流中复杂的分支线条,体现了工作流的动态性。
函数引擎设计
函数引擎的使用场景非常广泛。比如在工作流中,需要用表达式来扩展工作流能力;在API网关和数据集成时,需要处理来源系统和目标系统的参数转换,完全通过配置过于繁琐,因此可以用JavaScript脚本来灵活转换;在与AI智能体的工作流合作时,如果遇到不支持的功能,可以通过自定义脚本代码进行补偿。
最初我们在选择函数引擎时,主要考虑了Python和JavaScript。虽然Python在数据处理和AI领域应用广泛,但我们为了兼顾前端开发需求,最终选择了JavaScript。另外,Python的在线调试支持较少,而JavaScript则有成熟的Deno和V8等工具。
JavaScript引擎的选择
在选择JavaScript引擎时,我们主要考虑了V8、QuickJS 和 BOA。
- V8:功能最全,性能最好,有很多使用案例,如Deno组织了一个完善的Fast服务解决方案。我们也参考了其他项目(如Blueboot和Legend)的V8使用方法。
- QuickJS:非常轻量,将JavaScript编译成C代码执行,性能可靠。许多数据处理项目使用QuickJS来执行UDF。
- BOA:Rust的原生库,虽然仍处于实验阶段,但无需引入V8或QuickJS等较重的依赖。
表达式引擎与脚本执行
我们将表达式和脚本执行的需求分开处理:
- 表达式:表达式相对简单,一般不需要单步调试。我们主要使用BOA,如果遇到问题,再切换到QuickJS。
- 脚本执行:如果需要在浏览器中调试和设置断点,则更适合使用V8。我们借助V8构建了一个JS Worker环境,用于执行用户定义的脚本。
JS Worker池化与推理机制
JS Worker基于Deno Core,我们对其进行了裁剪,去除了一些不必要的功能,并引入了自定义扩展和调试支持。用户的脚本会被注入到JS Worker中,当需要执行时,通过管道调用暴露出来的全局入口函数。为了避免冷启动问题,我们还对JS Worker进行了池化处理。
工作流与函数引擎的结合
在服务架构中,底层依赖于Axiom、Tokio和Deno等基础组件。工作流引擎和函数引擎提供了定时调度、函数执行和服务函数库等功能。多个运行实例组成集群,状态存储在外部KV存储中(如Redis或数据库)。
数据实体服务
数据实体服务的目标是让开发人员不需要写SQL即可与数据库交互。我们基于Prisma(一个Rust实现的JavaScript ORM工具),构建了一个类似Data Proxy的机制。工作流通过API启动事务,并通过GraphQL或JSON API声明要进行的数据库操作。Prisma引擎将这些请求转换为SQL语句并执行。
角色引擎
角色引擎使用了开源项目GoRuth,它是一个纯Rust实现的角色图引擎。角色图本质上是一个简单的工作流引擎,支持分支和函数定义。角色图转换为JSON格式,并加载到系统中进行在线推理。
未来规划与Rust推广
我们目前的重点是应用组装和开发,包括AI智能体的相关工作。在推广Rust的过程中,我们总结了如下优缺点:
优点
- 编码体验好:学会Rust后,编码体验非常流畅,代码质量相对较高。
- 生态丰富:Rust的周边生态系统较为丰富,代码质量较高。
- 应用开发简单:Rust不仅性能好,应用开发的难度其实不大。
- 适合性能和质量要求高的模块:Rust非常适合对关键模块进行现代化重构。
缺点
- 异步开发挑战大:特别是在异步和同步之间切换时,代码编写非常复杂。
- 内存所有权机制:对代码设计有一定难度,尤其是在处理递归和自定义数据结构时。
- 类型系统复杂:尝试实现类似Java的类型系统时,发现难度较大。
- 基础软件开发专家需求高:开发基础类软件时,对开发者的要求较高。
- Rust推广难度大:客户对Rust的接受度仍然有限,需要更多的推广和教育。
问答环节
问题1:工作流分布式执行的基础设施
分布式执行工作流时,需要KV存储来实现分布式锁。可以使用Redis或TiKV,甚至数据库也可以。关键在于锁机制,确保多个节点推理同一个工作流时,不会发生并发问题。建议使用带队列的KV存储来提升性能。
问题2:AI智能体与工作流的结合
AI智能体与工作流的结合存在两条技术路线。大模型厂商通常不使用工作流技术,而是通过智能体推理和任务分解来执行。而像DAI和FastGPT等开源项目则是走工作流路线。我们目前更多关注与工作流结合的智能化应用,如PDF数据清洗和SQL生成等。
总结
本次分享到此结束,感谢大家的参与。如果有更多问题,欢迎私下与刘老师交流。
37-用 Rust 打造本地优先软件-陈子轩
OK,那我就开始这次演讲。
大家好,我是陈子轩。今天我们要讨论的是“用 Rust 打造本地优先软件”。那什么是本地优先软件呢?在座各位有听过这个概念的吗?如果有的话请举一下手,让我看一下。OK,好像还不是很多人了解这个概念。那我简单解释一下。
本地优先软件的定义
大概 20 年前,我们大部分的软件都是本地的,那时软件产生的数据都存储在用户的本地设备上。我们创作的东西也是存在本地的,这些数据都是属于用户自己的。用户对自己的数字资产有完全的控制权。
但那个时候的软件用起来不够方便,因为我们只能在同一个设备上使用,没法在不同设备之间协作。后来,云计算技术出现了,改变了这一状况。现在,很多软件采用的是基于云端的模式,用户的数据存储在云端服务器上。这样,使用确实方便了很多,数据不会因为设备丢失而丢失,我们可以在不同的设备上无缝访问数据。
但随之而来的问题是,数据的控制权转移到了云服务提供商手中。例如,Notion 曾经删除了所有俄罗斯用户的数据,导致这些用户无法再使用 Notion,即便导出数据后,失去 Notion 的服务支持,数据的使用价值也大打折扣。类似地,某些 IT 服务可能会因为政治压力而限制某些地区的用户,像大疆公司就不得不从某些云服务中迁移出去。
Local-first 的理念
那么,有没有一种方式既能让用户控制自己的数据,又能享受云端带来的便利呢?答案就是本地优先软件(Local-first Software)。这是 2019 年提出的一个开发理念,其核心思想是让终端用户能够掌控自己的数据,同时保留云端软件的便利性。
Git 作为典型案例
一个很好的例子就是 Git。作为开发者,我们都知道 Git 的数据是保存在本地的,但我们也可以使用 GitHub 或 GitLab 这样的服务进行数据同步和协作。这样,数据的存储和控制权在我们手里,而云服务则为我们提供了使用的便利。如果我们需要迁移,我们可以轻松从 GitHub 迁移到 GitLab。但这种体验目前主要局限于开发者,终端用户还没有类似的选项。
本地优先软件的七大设计理念
本地优先软件提出了七个设计理念:
- 本地数据即刻加载:数据存储在本地,不需要等待从云端加载。
- 多端轻松同步:数据可以在多个设备之间轻松同步。
- 网络是一个选项:即便没有网络连接,软件也能正常使用。
- 无缝协作:用户可以与他人无缝协作。
- 长期可用:软件不会因为某些意外(如政治要求或国家间的纷争)而失去对数据的访问权。
- 安全和隐私:用户的数据应该是私密的,只有用户自己能够控制。
- 用户控制数据:终端用户拥有对数据的所有权和控制权。
Martin Kleppmann 在其著作《Designing Data-Intensive Applications》中提到,在本地优先软件中,用户的工作不应该受到其他人电脑的影响。
本地优先软件对开发者的影响
那么,对于开发者来说,本地优先软件会带来什么样的影响呢?举个例子,如果我们要为一个写作软件添加评论功能,在传统的开发范式下,我们需要考虑很多问题:
- 是否支持离线模式?
- 离线数据如何存储?后端数据库的 schema 如何变化?
- 并行编辑如何处理?
- 如何设计 RESTful API?
- 请求出错怎么办?
- 数据同步上去后如果被服务器拒绝,如何处理?
而在本地优先的软件范式下,我们只需要一次修改代码,数据同步层会处理很多问题,如错误处理、API 设计等。而且本地优先软件天然支持离线和并行编辑。
用 Rust 打造本地优先软件
接下来,我简单介绍一下我们如何用 Rust 打造本地优先软件。我们开发了一个高性能的 CRDT 库,叫做 Loro (Loro.dev),它可以帮助开发者轻松构建本地优先软件。CRDT 是 Conflict-Free Replicated Data Type 的缩写,指的是一种无需中心化服务器即可实现数据同步的算法。
在 Loro 中,你可以新建一个文档并进行编辑,然后通过导出二进制数据的方式进行同步。这种同步方式是完全去中心化的,你可以通过任何方式传输这些数据,比如 WebSocket 或 WebRTC。
为什么选择 Rust?
我们选择 Rust 的原因有很多。首先,我个人非常喜欢 Rust 这门语言。其次,Rust 能够满足我们在性能和抽象上的需求。Rust 允许我们在保持代码抽象性的同时,仍然能够获得高性能。
Rust 的类型系统非常强大,它允许我们通过类型表达各种约束条件。比如,A 事件必须在 B 事件之前发生,我们就可以通过零尺寸类型 (zero-sized types) 来实现这一点。这样,我们的代码可以更加安全,重构也变得非常简单。
此外,Rust 的构建工具(如 Cargo)非常强大,生态也非常完善,几乎所有常见的数据结构和工具在 Rust 中都有现成的实现。
Loro 的架构
Loro 使用的是一种叫做 Replicable Event Graph 的算法。这个算法保存了一个有向无环图(DAG)的编辑历史,并根据这些历史记录来计算文档的差异。与传统的 CRDT 算法不同,Replicable Event Graph 不会在内存中长期持有 CRDT 对象,而是根据需要动态构建。
结束语
今天的内容比较浅,希望能引起大家对本地优先软件的兴趣。如果大家想看更多的干货,欢迎访问我们的博客。我们即将发布 Loro 1.0 版本,感兴趣的朋友可以试用。如果有任何问题,欢迎加我微信交流。
谢谢大家!
38 - 全同态加密及在 Rust 中的应用 - 严枭
大家好,下一位朋友是来自清华大学的博士、密码学专家严枭,他带来的演讲主题是《全同态加密及在 Rust 中的应用》。谢谢大家!
这是我第一次在线下讲解这个内容,今天的主题是“全同态加密及其在 Rust 中的应用”。我会分成四个部分来讲解:
- 首先,我会介绍什么是同态加密;
- 其次,介绍全同态加密 BFV 和 BGV 框架的基本原理,以及它们的内在逻辑;
- 第三部分,我会分享我们基于全同态加密的 WebAssembly 项目;
- 最后,介绍全同态加密在实际中的一些应用。
全同态加密(Fully Homomorphic Encryption, FHE)是一个相对较新的领域,尤其是在过去两年,开始逐渐进入工业界应用。为了让大家更好地理解,我会尽量用一些简单的方式来解释。
1. 什么是全同态加密?
首先,什么是全同态加密(FHE)或同态加密?同态加密允许我们在不解密数据的情况下直接对加密数据进行计算。比如,我有一组加密后的数据,在不解密的情况下,依然可以对其进行加法或乘法运算。
举个例子:假设我有两个数字 5 和 10,我希望你们帮我计算它们的和,但同时不希望告诉你们这两个数字具体是多少。于是,我先将 5 和 10 分别通过公钥加密成 X 和 Y,然后将加密后的结果发送给你们。你们可以在加密数据上执行和的运算,得到加密后的结果 Z,然后再将 Z 返回给我。我通过私钥解密 Z,最终得到 15。整个过程中,你们并不知道原始数据是 5 和 10。
再举一个例子:姚期智提出的“百万富翁问题”是多方安全计算中的一个典型问题。假设 A 和 B 都有各自的财产数额,我们希望在不暴露彼此财产数额的情况下判断谁更富有。全同态加密可以通过加密 A 和 B 的财产数额,然后直接在加密数据上比较大小,从而得出结果,而无需知道具体的数额。
2. 同态加密与零知识证明的区别
很多人会问一个问题:同态加密和零知识证明有什么区别?其实它们的核心应用场景不同。全同态加密的目的是在不解密数据的情况下进行计算,而零知识证明的目的是在不暴露数据的情况下证明你知道这个数据。
打个比方,全同态加密相当于解题,而零知识证明则是做证明。在不公布题目的情况下,零知识证明需要证明自己知道如何解答这个问题。
另外,同态加密的底层算法和零知识证明也不同。零知识证明通常使用椭圆曲线加密,而同态加密则基于晶格问题。晶格问题不仅支持加法,还支持乘法运算,并且其安全性较高,能抵抗量子计算的攻击。
3. 晶格问题与全同态加密的实现
现在我们来介绍一下全同态加密是如何实现的。全同态加密的基础是晶格问题,它可以简单描述为:在一个空间中有两个基向量,所有的晶格点都可以通过这两个基向量的整数线性组合得到。
晶格问题中有一个重要的子问题叫“最短向量问题”(SVP),即在给定基向量的情况下,找到离原点最近的晶格点。这个问题在低维度时较为简单,但在高维度时则非常复杂。
基于晶格问题,我们可以构建全同态加密的加密和解密过程。加密时,我们会将数据经过线性变换后加上噪声,从而使其偏离晶格点。解密时,我们需要找到离该点最近的晶格点,这个过程只有拥有私钥的人才能完成,而其他人无法在不知道私钥的情况下找到准确的晶格点,从而确保了加密的安全性。
4. 全同态加密的框架
全同态加密有多个不同的框架,其中比较流行的有 BFV、BGV 和 CKKS。BFV 和 BGV 是第一代同态加密框架,但现在逐渐被淘汰了,取而代之的是 TFHE 和 CKKS。
CKKS 是目前最常用于 AI 应用的加密框架,因为它支持浮点数运算和向量化计算。向量化使得加密数据的计算效率更高。
BFV 和 BGV 的核心公式中,A 是公钥,S 是私钥,M 是明文,E 是噪声。BFV 的明文放在密文的最高有效位,而噪声放在低有效位。BGV 则将二者都放在低有效位。当我们进行运算时,噪声会逐渐增加,如果不加以控制,噪声将占满整个计算空间。这时就需要用到“降噪”操作,将噪声从高位转移到低位。
5. 密钥共享与多方计算
在实际应用中,我们常常需要将密钥分配给多个参与方。例如,我可以将密钥分为 5 份,分给 5 个人,其中任意两个人的密钥组合就可以恢复原始密钥。这种技术叫做“门限密钥共享”。
38 - 全同态加密及在 Rust 中的应用 - 严枭
链接:https://www.bilibili.com/video/BV1yYsbegEF1/
继续整理内容:
老外用得比较多,比如微软买的 CEO 库,它是基于 BSB 和 CDKS 的。IBM 的 H-Lab 是基于 CCTF 的,谷歌也有自己的,它是基于 CLS 开发的,专门适配生态 VLOG。这是之前 C++ 的一些版本。
Rust 这一块主要是 TNF 和 TFHE Rust 的库,是 3A 公司专门做的,主要针对布尔操作以及整个操作的优化库。
AI 这方面,康快和通快的底层也是使用 Rust,然后上传分类使用 Python,专门做 GPU 并行计算。区块链这方面,FHE 现在比较火,比如基于以太坊虚拟机的 SHE 虚拟机,还有我们刚才提到的一个项目,HERS。
我讲一下 AI 应用中如何使用 FHE。AI 的应用场景比较合理,比如现在大模型公司会调试一些参数,如果让他们拿你的数据去调模型,可能会产生所谓的“数字黑洞”问题,即所有数据都集中在公司内部,外界无法获取这些数据。
如何避免这种情况呢?通过加密的方式,可以让你在不暴露数据的情况下,直接进行加密计算。比如做激活函数等非线性函数,这样就不需要暴露数据,同时也能进行计算。这种方式可以在隐私保护和 AI 计算中发挥作用。
FHE 现在研究的一个方向是索引引擎。比如我需要搜索“上海天气”,谷歌会用关键词去索引数据库。但我们能否在不知道索引的情况下,仍然找到数据库中的词条?这是 FHE 当前研究的一个方向。
不仅仅是索引,排名也是一个问题。如果所有数据都集中在某一方,他们很容易掌握市场趋势,这对数据持有方是不利的。
说到区块链应用,刚才提到的两个项目,一个是基于以太坊虚拟机,另一个是基于窝藏虚拟机。我们现在做的 Verence Network,是基于博弈论的一套共识算法。以太坊挖矿效率慢的原因是共识过程节点太多,耗时较长。如果我们通过引入 FHE,可以把完美信息博弈转化为非完美信息博弈,从而提高效率。
我们还采用了盲拍、VRF 等技术,转换成一个小型的博弈,来提升共识效率。我们现在的研究已经有一些论文上线了,大家有兴趣可以去看看。
感谢严博士的分享!我有一个问题,目前全同态加密的计算性能大概是什么水平?
严博士:现在流川比已经做到百毫秒级了,虽然在 AI 中还是需要定型化,因为同态加密处理位级别的操作很快,但大规模计算还不够快。如果是投票等小规模计算,速度已经很理想了,但如果是大文件,还是需要一定的时间和专用硬件来优化。
对,像 ZK(零知识证明)也是经过了时间的优化,FHE 可能还需要一些时间。ZK 现在生成证明的速度虽然比较快,但也还是要看数据量。如果数据量特别大,链上数据需要证明的部分也会相应增加,FHE 还在发展初期。
问:你觉得 FHE 商业化、大规模应用大概需要多久?
严博士:这个很难预测,如果我能预测到 FHE 商业化的时间,我就去买股票了(笑)。不过现在美国对 FHE 非常感兴趣,我们在美国办的一些活动,原本预计几十人参加,结果有几百人报名,说明大家对 FHE 这个赛道的关注度在上升。
目前来看,FHE 还需要几年时间去发展,尤其是与 AI 的结合,AI 需要 FHE 提供隐私保护,但同时并行计算的需求也比较耗时,需要额外的技术来辅助。
问:FHE 主要适用于隐私保护对吗?
严博士:是的,FHE 主要用于隐私保护,尤其是多方计算(MPC)。多方计算允许多个参与方在不暴露各自数据的情况下进行协同计算。ZK 面向的是大规模数据的证明,而 FHE 关注的是计算过程中的隐私保护。
问:性能上 FHE 和普通计算的差距大概是多少?
严博士:现在大概是 1000 倍左右,特别是在一些大文件处理时,FHE 的性能还不够理想。FHE 计算过程中会有递增的噪声,导致性能下降,特别是乘法和加法操作。
问:未来 FHE 的研究方向是什么?
严博士:未来研究的方向可能会有两方面:一是工程优化,比如在硬件层面使用 FFT 或者其他优化手段;二是算法本质的创新,如何在算法层面提升效率,而不是单纯依赖工具。
问:Rust 和 FHE 之间的关系是什么?
严博士:Rust 可以用于写 FHE 应用,比如排序算法。你可以像操作普通数据一样写代码,输入加密数据,输出加密数据。FHE 的库会提供一些类型转换和加密操作。我们现在做的主要是模拟器,后续的目标是将代码编写过程中就能实现加密计算。
这就是严枭博士的精彩演讲内容,感谢大家的参与!
39-GenUI :可拆卸底层的 Rust 前端框架-盛逸飞
下一位演讲者是 GenUI 框架作者盛逸飞,他也是 Makepad 框架贡献者之一,今年21岁。今天他带来的主题是「GenUI:可拆卸底层的 Rust 前端框架」。非常抱歉,这次的 PPT 没有完全准备好,之前我认为第一页不需要改动,所以稍有误会。不过,我非常高兴能为大家介绍 GenUI。
GenUI 是一个类 Vue 的声明式前端框架,当前使用 Makepad 作为渲染底层。我相信未来它可以结合 AI,帮助开发者自动生成前端界面。我目前是 Privoce 的工程师,Privoce 是一家以 Rust 为主,面向互联网产品的创新型初创企业。GenUI 从开发到现在已经有四个月时间了,今天的分享将从四个方面展开:方向、设计理念、进度和未来发展。
首先,简单介绍一下 GenUI。它是一个完全用 Rust 开发的创新型 SSP 前端框架,受 Vue3 和 Makepad 的启发,致力于以更高效的方式用 Rust 进行前端开发。GenUI 结合了 Vue3 的组件化思想和 Makepad 的高性能 GPU 渲染,提供了一种高效的前端开发体验。
设计理念
GenUI 的设计理念分为四个方面:组件化、Rust 脚本、SMP(插件式架构)和生态定位。
- 组件化:采用 Vue 的组件化思想,组件化可以大大提高开发效率,允许将组件从代码中独立出来,方便后续的重复使用和开发。
- Rust 脚本:尽管 Rust 不是传统的脚本语言,但在 GenUI 中,它可以用作类似脚本的角色,通过内置宏和自动生命周期管理,简化了开发者的工作。
- SMP(插件式架构):GenUI 支持插件式开发,允许开发者根据需求调整底层技术。比如,可以选择不同的底层渲染引擎,如使用 Makepad 或 Slink。
- 生态定位:GenUI 并不是一个 GUI 框架,而是一个前端框架,支持跨端使用,包括 Web、嵌入式设备、移动端等多个平台。
进度
目前,GenUI 的开发进度集中在以下几个方面:
- 转换插件:目前主要使用 Makepad 作为转换底层,并计划支持更多的底层技术。
- 内置组件库:GenUI 内置了一个现代化组件库,解决了前端开发中常见的组件问题,同时兼顾灵活性。
- DSL 语法支持:已经完成了 DSL(领域特定语言)的基本构建,包括 Template、Script 和 Style 三部分,并对其进行了增强。
- 动画转换和渲染:支持 Makepad 独特的 Shader 渲染。同时,还支持增量更新、日志功能、配置与环境设置等。
示例
这里展示了两个案例:
- 一个简单的网页布局,模仿了 Boston 的网站布局。
- 一个带有波纹效果的示例,使用了 Shader 进行渲染。
未来方向
未来,GenUI 将重点加强以下几个方面:
- 内置组件库的扩展:继续完善和增强现有的组件库。
- 跨平台支持:进一步增强跨平台的支持,特别是 2D 和 3D 场景的渲染。
- AI 生成前端界面:探索基于 AIGC(AI Generated Content)技术,使用 AI 自动生成前端界面的可能性。
最后,如果大家对 GenUI 项目感兴趣或者有合作意向,可以通过我们的 GitHub 和邮箱联系。目前,我们也在寻找下游的合作伙伴,特别是在游戏、应用和 AI 生成方向。欢迎大家提问,提问者可以领取证书,每人最多提两个问题。
问答环节
提问1:我注意到编译产物是 Makepad 的代码,GenUI 的「可拆卸」具体是如何体现的?
回答:GenUI 的核心思想是 SMP(插件式架构),通过不同的底层可以实现不同的渲染效果。如果你选择 Makepad 底层,它的产物就是 Makepad 代码。如果你更换底层,比如使用 Slink,它的产物会是 Slink 的代码。因此,GenUI 的底层是可以根据需求拆卸和更换的。
提问2:GenUI 的响应式系统与 Vue 的 reactivity 系统类似吗?
回答:是的,GenUI 同样具备强大的响应式系统,尽量减少开发者手动绑定的工作,数据驱动模型会自动渲染界面。
提问3:GenUI 是否支持像 VSCode 那样的 WebView 插件功能?
回答:这种功能取决于具体的组件库支持,如果 Rust 有相关库可以集成进来,GenUI 也可以支持类似的插件功能。
提问4:是否可以支持第三方插件的动态加载,而无需重新编译应用?
回答:目前还不支持这种功能。GenUI 需要重新编译整个应用,以确保插件的正确加载和运行。
以上就是 GenUI 框架的介绍和讨论内容。
40-Rust 带你畅游 2D 图形软光栅 - 唐伟豪
好的,接下来我们把时间交给下一位演讲者。下一位演讲者是 Vue-Skia 和 SwiftUISkia 项目的维护者唐伟豪,他将为我们带来分享,主题是 Rust 带你畅游 2D 图形软光栅。
大家好,我是唐伟豪,很高兴大家今天能来听我的分享。我今天的主题是 Rust 带你畅游 2D 图形软光栅。刚才盛逸飞同学讲了一款专门为 Rust 开发者设计的上层框架 GenUI,这个框架允许底层随意拆卸。而我今天将探讨渲染的底层技术,重点介绍一款基于 Rust 和 Skia 的 2D 图形渲染库。
我将从 Vue-Skia 和 SwiftUISkia 项目的维护者的角度,带大家畅游 2D 图形软光栅的相关知识。接下来我们开始第一个部分。
第一部分:2D 图形软光栅相关背景
如果大家不太熟悉 2D 图形渲染领域,我在这里简单科普一下软件光栅化的概念。软件光栅化其实是计算机图形学中的一个过程,指的是通过软件算法将矢量图形转换为栅格图像,而不是依赖硬件加速。
我们常见的图形处理器 (GPU) 负责将路径和像素转换为栅格图像,最终呈现在屏幕上。但在某些情况下,我们会选择使用软件光栅化,而不是依赖 GPU。这通常是出于某些特定的目的,比如软件光栅化具有一些独特的优势。
软件光栅的优势:
一致性:
软件光栅化不依赖图形硬件,因此可以更轻松地移植到各种场景中,尤其是在嵌入式系统中,比如 LCD 显示屏等。灵活性:
软件光栅化在渲染管线中可以更灵活地定制,不像 OpenGL 等 GPU 渲染管线那样固定。调试与开发:
着色器编程调试比较复杂,而软件光栅化则可以使用经典的软件调试方式,比如简单加断点。
总结一下,软件光栅在移植性、灵活性和调试开发方面具有其独特的优势,也因此它成为了业界长期存在的一种方案。接下来,我为大家准备了一张图,来介绍目前 2D 图形引擎相关社区的概览。
2D 图形引擎社区概览
对于熟悉 2D 图形渲染的小伙伴来说,图中提到的几个引擎应该不会陌生。我列出了目前业界最常用的两个 2D 图形引擎:Skia 和 Cairo。
Skia 和 Cairo:
Cairo:
基于 C 语言编写,诞生于 2003 年,至今已有 21 年的历史。它是一个跨平台的 2D 图形库,支持多种输出设备。Skia:
Skia 是由 Skia 公司开发,后来被谷歌收购的一款基于 C++ 的 2D 图形引擎。它应用广泛,支持多种输入和输出格式,比如 SVG 和 PDF。
这两款引擎都有丰富的社区支持,各种语言的绑定层也非常多。比如,Skia 的 Java 绑定是 Skija,Python 绑定是 Skia-Python,JavaScript 绑定是 CanvasKit,后者通过 WebAssembly 技术实现。
Rust 相关的绑定:
在 Rust 生态下,有两个主要的 Skia 绑定:
Skia-Safe:
这是 Skia 在 Rust 上的官方绑定,支持 OpenGL、DirectX、Vulkan 等多种后端。TiniSkia:
TiniSkia 其实更像是一种移植,而不是绑定。它是基于 Skia 的 API 在 Rust 上重新实现的一个极小子集,专注于 CPU 渲染,体积更小,编译速度更快。
TiniSkia 的 README 中也提到了,它是一款移植到 Rust 的极小 Skia 子集,专注于 CPU 光栅化,强调渲染质量、速度和二进制体积。相比于原版 Skia,TiniSkia 的二进制产物只有约 200KB,而 Skia 原版可能高达 3-8MB。
如何将 TiniSkia 接入上层框架
介绍完了 TiniSkia 之后,接下来我们讨论如何将这款 2D 图形引擎接入上层框架,比如 Vue 或 SwiftUI。我们开发了一款名为 Vue-Skia 的库,它基于 Rust 语言实现,通过 WebAssembly 实现了纯软件光栅化。这个库支持 Vue 的双向绑定语法,可以直接在 Vue 项目中使用类似矩形、多边形等 2D 图形元素。
同样,我们也成功将这套技术移植到 SwiftUI 上,在 SwiftUI 中可以使用 Swift 语言来编写同样的逻辑,并渲染到移动端。
第二部分:Vue-Skia 的架构设计与 SwiftUI 的移植
Vue-Skia 是一款基于 TiniSkia 的 2D 图形软光栅渲染库,它使用 Rust 语言实现了纯软件光栅化,支持多边形填充、描边、文字、图片滤镜等功能。虽然我的本职工作并不是做软件光栅化,但我和几个小伙伴利用业余时间发起了这个项目,希望能开发一款基于 Vue 语法生成 SVG 替代品的工具。
架构设计:
项目底层是基于 TiniSkia 这份极小 Skia 子集,提供了最基本的 2D 图形能力,比如多边形填充和描边。但由于 TiniSkia 没有文字和滤镜的功能,我们在它之上做了一层封装,称为 SoftSkia,它成为了我们统一的底层渲染后端。
在这之上,我们通过 WebAssembly 实现了 Rust 的 FFI 接口,直接调用 SoftSkia,最终接入 Vue 的生命周期管理。
渲染架构的实例
通过 Vue 的语法,我们定义了多边形和滤镜的逻辑。比如,使用 Vue 的声明式语法,我们可以生成一个多边形或者应用滤镜效果,比如高斯模糊和亮度调整。
这样就大致介绍了整个渲染架构。
第二部分:实现 Vue-Skia 的架构设计和 SwiftUI 的移植
我们可以看到,左边是一个微胖子的声明标签,使用的是 Vue 的语法。在这个例子中,我们通过 Vue 语法声明了多个顶点,组成了多条线,渲染出了一个浅绿色的五角形。这是一个多边形生成的语法示例。接下来,我们看到几行代码声明了一个图片滤镜,我们生成了一张图片,这张图片是 Vue 官方的 logo。在这一层中,我们应用了高斯模糊(blur)滤镜,并且还声明了亮度(brightness)和模糊(blur)这两种滤镜效果。最终,这些操作渲染到了软光栅的结果中。接下来,我会以这两个功能为切入点,进一步为大家介绍项目的实现细节。
SoftSkia 的统一渲染架构
刚才提到的浅黄色的统一渲染底层叫 SoftSkia。这一层实现了 2D 图形的渲染功能声明。我们以多边形这个 2D 图形为例,展示了如何声明图形的接口。同时,图片在这个架构中也被当作一种图形。因此,我们不仅声明了多边形,还声明了图片的接口。通过 Rust 中的 trait 特征,我们让每个图形类型去实现各自的绘制方法。比如,多边形的绘制方法和带滤镜的图片的绘制方法。
在 SoftSkia 这一层中,我们为每种图形实现了各自的绘制方法。然后,我们将这些能力暴露给 WebAssembly 的 FFI 接口。中间层叫做 SoftSkia WebAssembly,负责将图形的序列化声明传递给 WebAssembly。这一层同样以多边形和图片滤镜为例,展示了如何在序列化过程中调用 Rust 的 SoftSkia 渲染层。
Vue 生命周期中的图形创建与更新
接下来,我们进入到了 Vue 的生命周期。在 Vue 插件层,我们首先拦截了 Vue 的 onBeforeMount 和 mounted 生命周期钩子,并在这些钩子中调用了 2D 图形的创建 API。简单来说,我们拦截了 Vue 的创建生命周期,再去调用 2D 图形的创建逻辑。
同理,在 Vue 的 updated 生命周期钩子中,我们拦截了 Vue 的更新操作,调用了 2D 图形的更新 API。最后,在 Vue 的 onBeforeUnmount 钩子中,我们拦截了组件的卸载操作,调用了 2D 图形的卸载 API。
总结一下,我们分别拦截了 Vue 的增、删、改操作,并在这些操作中调用了相应的 2D 图形操作。最终,我们实现了以多边形和图片滤镜为例的标签组件。
Vue-Skia 的组件封装
在最上层,我们通过 Vue 插件实现了多边形和图片滤镜这两个 API,并将它们暴露给开发者。开发者可以在 Vue 项目中直接使用这些 API。例如,开发者可以将带有滤镜的图片声明为一个 Vue 组件,直接在代码中使用。最终,两个组件分别是 VPosPolygon 和 VImageWithFilter。
产物对比与 SwiftUI 移植
关于最终的产物,它非常轻巧。在左边的对比中,我们可以看到 Vue-Skia 的 WebAssembly 产物与谷歌 Skia 的 CanvasKit 产物的对比。我们的产物得益于 Rust 语言无运行时的特性,体积非常小。Rust 没有垃圾回收(GC),相较于 Go 语言等有 GC 的语言,Rust 的产物更加轻量。与 Skia 相比,我们的最终产物体积更小,这主要是因为我们使用了一个更精简的后端架构。
具体来说,Vue-Skia 的产物大小为 1.99 MB,而谷歌 CanvasKit 的产物大小为 7.05 MB。
SwiftUI 的移植
不只是 Vue,我们还将 SoftSkia 移植到了 SwiftUI 移动端开发框架上。SwiftUISkia 是一个基于 Rust 和 SoftSkia 的 2D 图形库,它同样使用 Rust 实现了纯软件光栅化渲染。SwiftUISkia 的用法完全基于 SwiftUI 的语法。不过,目前这个项目还处于实验阶段,当前版本是 0.0.4,我们计划在 0.1.0 版本中完善全部功能。
我们通过 Swift 的 FFI 接口调用 Rust 的 SoftSkia 渲染层,实现了图形的增、删、改操作。和 Vue 的实现原理类似,SwiftUISkia 通过 Swift Bridge 实现了 FFI 调用,并封装了多边形和图片滤镜的组件。最终,开发者可以在 SwiftUI 中使用相应的组件。
社区展望与开源共建
最后,我想简单展望一下软件光栅化社区的前景。我认为这个领域的前景非常广阔。在图形学的教育意义上,软件光栅化也有很大的潜力,它可以激发社区诞生出许多实验项目。比如,TiniSkia 本身也是一个实验项目。开源社区中还有很多值得探索的方向,例如更多的渲染后端和上层应用开发框架。
我们经常听到 “用 Rust 重写一切” 的口号,虽然大家都使用 Rust,但来自的领域各不相同。目前 Rust 生态还处于一个百花齐放的阶段,因此无论是对工作还是个人项目,机会都很多。比如,Skia 和 Cairo 都是基于 C 或 C++ 实现的 2D 图形引擎,但我们可以尝试基于 Rust 语言实现一个类似的 2D 图形引擎,这为中国开发者提供了很多机会。
项目开源与贡献
最后,我贴出我们的 GitHub 组织链接:RustQ。这是我们业余时间发起的一个开源组织,已经孵化了很多有趣的项目。今天讲到的 Vue-Skia 和 SwiftUISkia 项目只是其中的一部分。目前,我们有五位贡献者,欢迎大家关注、加入并贡献代码。
我的演讲到此结束。感谢大家的聆听!
茶歇提醒
大家连续听了四场精彩的演讲,接下来是茶歇时间。我们将在 04:05 分继续大会。
41-用 Rust 构建 Internet Computer (ICP) 区块链 - Paul Li**
演讲开始:
喂喂喂,哦好啊,欢迎回来!接下来这场分享由 DFINITY 基金会核心工程师 Paul Li 带来,主题是 “用 Rust 构建 Internet Computer (ICP) 区块链”。谢谢大家!
今天我会分享一下我们如何使用 Rust 来编写 Internet Computer (ICP) 区块链的幕后故事。可能有的人对区块链不太了解,实际上,ICP 不像传统的区块链,它更像是一个去中心化的云计算平台。
在一些页面上,可能会有二维码,大家可以扫描一下,或者拍照保存,里面会有一些相关资料,比如链接到 Google Docs 等等,但总的来说,这些内容涵盖了我们项目的很多信息。
自我介绍:
先简单介绍一下我自己。我现在在 DFINITY 基金会,负责分布式系统和底层共识协议的开发。我们已经使用 Rust 开发了相当长的时间,大概从 2019 年开始用 Rust,而那时 Rust 1.0 刚刚发布。我个人的研究方向是编程语言,特别是形式化语义和函数式编程。
之前我在英特尔实验室(Intel Labs)工作,负责三种编程语言的编译器开发,包括 Haskell、Python 相关的性能优化等。DFINITY 是一家致力于开发 Internet Computer 的基金会,它是一个去中心化的云计算平台。如果用区块链的角度来理解,它可以说是一个可以无限扩展的区块链系统,彻底解决了扩展性(Scalability)的问题。
Internet Computer (ICP) 简介:
Internet Computer 的底层使用了区块链技术,但实际服务的是云计算客户。ICP 的去中心化云平台由全球各地的数据中心提供硬件支持。我们称这些硬件提供商为 “Node Providers”。目前全网有大概 1000 多个节点,虽然云计算平台还处于早期阶段,但对于区块链领域,这已经是一个中型甚至比较成熟的网络。
为什么说 ICP 是可扩展的呢?我们的网络不是一条链,而是由多个不同的区块链组成。可以把每个链看作是一台虚拟计算机,在这个虚拟计算机上,你可以部署自己的程序。实际上,它类似于云服务中的容器(如 Docker),但比 Docker 更加轻量,因为它没有操作系统,只运行应用程序的代码。ICP 的内存是自动持久化的,当服务不再运行时,数据会被移除。我们可以随时添加更多的节点,扩大网络的容量,以满足用户的计算需求。
ICP 技术特点:
目前我们的网络每秒钟可以生成数十个区块,这对于区块链系统来说是一个很高的吞吐量。大多数区块链只能处理有限数量的交易,而 ICP 的水平扩展能力使其能够处理更大规模的吞吐量。
相比其他区块链,ICP 采用了更先进的水平扩展技术,是真正能在规模上扩展的区块链系统。我们相信,通用计算应该像水电和互联网一样,成为公共基础设施,而不应被某个互联网巨头垄断。去中心化的方式可以避免平台垄断的风险,降低开发者在平台上开发应用的风险。
ICP 的底层是基于密码学的,这为系统带来了极高的安全性。除此之外,ICP 还可以确保服务之间的通信安全。现代应用程序经常需要与其他服务进行通信,但传统的云平台需要繁琐的验证过程,而 ICP 可以通过底层的密码学技术自动完成这些验证。
智能合约与签名功能:
ICP 的智能合约不仅可以执行代码,还可以进行签名。传统区块链中的智能合约无法进行签名,因为签名需要一个私钥,而私钥在公共的区块链上是不安全的。而在 ICP 中,我们通过一种分布式签名技术,让每个节点各自持有一部分密钥,最终合成一个完整的签名。这样,智能合约在没有暴露私钥的情况下就可以进行签名,这甚至超越了当前云计算平台的能力。
开发历程:
我们从 2016 年开始开发 ICP,最初的原型是基于 Go 和 Haskell 开发的。虽然我们当时做了很多工作,但最终发现 Haskell 在大型项目中存在瓶颈。尽管团队中有很多 Haskell 专家,但我们还是决定转向 Rust。这个决定非常艰难,因为当时 Haskell 版本的系统已经基本成型。
转用 Rust 是为了吸引更多的开发者。最终,我们在 2021 年上线了基于 Rust 开发的主网,并且开源了这个项目。现在,我们的重点已经转向核心技术的进一步开发和生态系统的建设。
DFINITY 基金会简介:
DFINITY 是一个非盈利组织,专注于开发 Internet Computer。我们目前有大约 300 名员工,其中约 100 到 200 名是开发者。我们主要使用 Rust 进行开发。根据一些第三方统计,ICP 的开发活跃度在区块链项目中排名第一。
结语:
我们的技术栈大致分为三部分:网络节点、智能合约和自动化治理系统。我们的目标是打造一个去中心化的、由社区管理的项目,而不是由某个公司主导的产品。ICP 上的智能合约类似于轻量级容器,开发者可以像使用云计算平台一样轻松地在 ICP 上部署应用。
第二部分即将继续…
或者有些配置参数需要修改。其实,最后的修改都是经过社区投票,也是一种类似于去中心化管理的方式。所以,Internet Computer 应该被看作是一个社区驱动的项目,而不是一个由某家公司开发的产品。
在它上面运行的智能合约,我们称之为 “Canister”。实际上,它就是 WebAssembly 程序加上它的运行状态(也就是内存)组合在一起的东西。我们把它叫做一个 Canister。它就像一个轻量级的容器,开发者可以在这个平台上部署它们的应用。对于开发者而言,使用 Canister 就像使用云计算平台一样简单。你编写的服务可以直接在平台上运行,类似于云计算中的服务。
另外,我们还有一个产品叫 “Candies”,用于做数据交换。这个其实是在去年的 Lost Conference 上发布的。
我们的一位同事刚才提到了开放数据交换协议。在准备这个演讲的时候,我统计了一下我们代码的行数。Rust 代码大概接近 100 万行了,如果加上其他仓库,肯定已经超过 100 万行。所以可以算是一个中大型的项目。这个项目在区块链之外,可能大家都不太清楚,但我们确实有这么大规模的基于 Rust 的项目。
接下来,我想分享一些我们在使用 Rust 的经验,主要集中在构建系统上。首先,我要说的是,Cargo 不是一个完善的构建系统。虽然大家都用 Cargo,但它主要的目的是简化开发流程,让使用更为方便。然而,它在实际应用中,特别是在管理一个中型项目时,存在很多无法满足的需求。
我举个例子:我们有一个 Rust 文件 foo.rs,需要编译到 WebAssembly。编译完成后,它需要进行一些预处理,生成一个 word_model 文件。这个文件会被包含到另一个代码文件中,从而触发下一个编译步骤。这个过程在使用 Cargo 时会非常困难。虽然强行使用 Cargo 也许可以实现,但通常情况下,Cargo 无法处理这种复杂的构建依赖。
Rust 的开发者往往倾向于用 Rust 重新实现系统库,这其实并不好。首先,编译的灵活性会受到限制,而且 Rust 开发者不太关注与系统已有的库之间的兼容性。这也是我们遇到的一个问题。
在 CI 系统中,我们也遇到了一些挑战。最初我们采用的解决方案并不理想,经过多次迭代后,才找到相对满意的方式。复杂系统需求与开发者的易用性之间常常存在矛盾。当开发环境、测试环境和生产环境之间的差异变大时,问题会更加突出。比如,测试报告中的 bug 在本地环境中很难复现。此外,CI 系统的压力也很大,特别是当测试时间长达一两个小时时,这几乎是难以承受的。
我们需要一个能够并发执行测试的集群来分布式运行 CI 任务。然而,随着开发的活跃度增加,CI 系统的压力也会增大,脚本管理也变得越来越困难。我们最初使用的是 Nix,一个包管理工具,但与 Cargo 的结合不太好用,最终我们放弃了它。
后来,我们使用了 Bazel,这是 Google 开发的一套构建系统。Bazel 非常灵活,只要你设置了标准,并且团队成员遵循这个标准,编写构建文件虽然无聊,但它能跑起来,而且效果不错。Bazel 能够通过检测环境变量的变化,来避免不必要的全量重新编译。
不过,Bazel 也有一些缺点,特别是在与 Cargo Check 结合使用时并不方便。不过综合考虑它的优势,目前我们认为它还是非常好的。
在测试环节中,我们引入了 Fuzzing 测试工具。这是一种通过随机输入来自动化测试的工具,特别适合找出逻辑错误或并发问题。我们还进行了一些形式化验证的工作。通过 Model Checking 的方式,我们可以穷举所有可能的输入,验证程序是否满足预设的条件。
形式化验证与 Fuzzing 测试不同。Fuzzing 测试是通过随机生成输入来测试,而形式化验证则是穷举所有可能的输入空间,检查程序的所有状态。我们使用 Model Checking 来验证 Rust 代码的正确性,特别是在并发性问题上,形式化验证非常有效。
总结一下,Rust 在开发大型项目中有显著的优势,特别是在团队合作方面。Rust 对 WebAssembly 的支持也是非常好的。Cargo 虽然适用于小型项目,但大型项目还是需要更专业的构建系统。而更重要的是,招募和培养优秀的开发者是团队成功的关键。
提问环节
提问者 1: 刘老师你好,您刚才提到在 CI 过程中使用了 Bazel。我想请教一下,在开发环境比较多、开发分支比较灵活的情况下,如何保证构建环境的一致性?
Paul Li: 这个问题很好。我们有的开发者使用 Mac,有的用 Linux,甚至有的使用 Windows。Bazel 对这三种环境的支持都很好。在 Windows 上,Bazel 可以通过 WSL 运行。Bazel 的核心是基于 Python 的,所以你可以通过 Python 来配置操作系统、虚拟机、包管理等。
提问者 2: 您提到了大型项目的编译时间问题,Rust 的编译时间一直是个痛点。您是如何解决这个问题的?
Paul Li: 编译时间确实是一个大问题。Bazel 可以通过增量编译来减少编译时间。只要配置好,Bazel 可以复用之前的编译结果,除非外部变量发生了变化,否则不需要重新编译整个项目。你可以通过声明所有可能影响编译的外部变量,来确保增量编译的准确性。
再次感谢 Paul Li 的精彩演讲!接下来,有请 High Tech 中国的技术经理温继辉,为我们分享 Rust 在汽车行业的解决方案。
42-HighTec Rust 汽车行业解决方案 - 温吉辉
大家可以来听一听我们这次会议。今天我要讲的是 Rust 在汽车行业中的应用方案。这是一个讨论的主题,因为大家可能在这两天的会议中听到了很多关于区块链和互联网应用的内容,但实际上 Rust 这门语言,至少在欧洲的一些大厂,比如宝马、奔驰、沃尔沃,已经非常流行了。这种趋势也逐渐蔓延到中国,特别是在一些新兴的造车势力中。因此,今天我想针对 Rust 在汽车行业中的解决方案,给大家做一个分享。
我的分享会分为四个方面:首先是 Rust 在汽车行业应用的背景。然后,我会介绍我们在汽车上使用 Rust 的解决方案。第三部分是关于我们基于特定芯片在汽车上应用 Rust 的情况。最后,我会展望一下 Rust 在汽车行业中的未来应用前景。
Rust 在汽车行业中的应用背景
首先,我们来看一下这两张图。我们知道 Rust 的应用最早是从微软和谷歌开始的,现在在这些公司中,Rust 的应用非常广泛。谷歌的 Android 系统中,接近一半的内核代码都是用 Rust 重新编写的。这是因为他们发现 Android 内核中 70% 的 bug 都与内存相关。谷歌做了个实验,在 128 个 bug 中,发现有 70 多个是与内存紧密相关的。于是他们用 Rust 重新编写这部分代码,结果上线后没有发现任何 bug。
这是一个非常重要的数据。在最新的 Android 13 中,从 21% 的代码比例开始,Rust 的应用比例逐渐提升,当前的比例应该更高。在微软内部,从 Windows 11 开始,很多服务和插件也都是用 Rust 重新编写的。这是在桌面系统中的应用情况。
那么在汽车领域,其实我们也面临同样的问题。统计显示,汽车领域中大约有 50% 的漏洞都是与内存相关的。这些常见的问题,例如空指针、越界访问、边界值错误,在静态代码编写或测试中很难被覆盖,因为它们是动态行为,可能在特定的汽车场景中才会出现。而一旦出现问题,可能会导致非常严重的后果。
谷歌也发现,70% 的漏洞都是与内存相关的。在汽车行业中,大家可能听过一个流行的词汇 “SDV”(软件定义汽车)。软件定义汽车对软件的要求非常高,首先是安全和可靠性。汽车行业的标准,比如 SAE 最新发布的 214 和 234 标准,要求所有联网的汽车必须具有信息安全的先验性。而针对汽车行业的 262 标准,要求所有代码工具链,包括编译器和调试器,都必须经过认证。
随着智能网联汽车的兴起,软件的复杂度也越来越高。过去一个控制器可能只有几百万行代码,现在增加了智能网联功能后,可能会有几亿行代码。Rust 恰好能够解决这些问题。因此,我们认为 Rust 在汽车行业中有很大的应用潜力。
在汽车领域,安全性至关重要。与消费电子不同,汽车是与人的生命息息相关的。如果汽车中出现与内存相关的致命 bug,可能会导致车毁人亡的惨剧。如果汽车厂商发现问题是由软件或零部件导致的,赔偿金额可能是以亿计的。所以,在早期发现 bug 比让问题出现在量产产品中要重要得多。
在汽车领域,80% 的代码是用 C 语言编写的,C++ 相对较少,因为 C++ 代码相对复杂,而 C 语言已经能够覆盖大多数的使用场景。我们认为 Rust 是汽车电子领域未来非常有潜力的语言。Rust 具有无垃圾回收机制,这保证了性能的稳定性。另外,它的运行效率与 C 和 C++ 基本一致,能够满足汽车行业对实时性的要求。
Rust 在底层访问寄存器时与 C 语言是一样的,这也是它在嵌入式系统中有良好应用前景的原因。很多汽车控制器频繁通过 C 语言访问寄存器,而 Rust 在这方面具备同样的能力。因此,Rust 在汽车行业中具有很大的应用潜力。
Rust 在汽车行业的解决方案
大家都知道 Rust 很好,但为什么在汽车行业中推不起来呢?原因有几个。
首先,Rust 需要针对特定芯片重写编译器。车上的编译器必须经过认证,不能直接使用开源编译器。同时,第三方的调试器目前基于 C 语言的比较成熟,而 Rust 在这方面还相对稀缺。不过,经过这几年的发展,主流调试器已经开始支持 Rust。
一个重要的问题是,汽车行业中遗留下来的 C 和 C++ 代码非常庞大,完全替换是不可能的。我们只能在某些领域,特别是与安全紧密相关的领域,使用 Rust 重新编写代码,而这部分代码必须与原有的 C 和 C++ 代码交互。
另外,汽车行业中会 Rust 的人才非常少。很多工程师可能用 C 或 C++ 写得很好,但让他们转换到 Rust 上非常困难。况且,很多项目的进度非常紧张,工程师更倾向于用熟悉的语言快速完成项目,而不是花大量时间学习新语言。
从欧洲和中国的现状来看,一些公司已经开始尝试使用 Rust。特斯拉在电池和摄像头驱动中大量使用了 Rust,沃尔沃也在一些控制器中采用了 Rust。在中国,理想和蔚来也有团队在智能座舱和自动驾驶领域使用 Rust。
我们公司专注于汽车行业的商业编译器,已经有 40 多年的历史。我们主要支持英飞凌和 ARM 架构的芯片。随着 Rust 在欧洲的兴起,我们也开始支持 Rust。我们开发的编译器是车规级的,通过了 262 标准认证,能够混合使用 C 和 C++ 代码。
我们支持将 Rust 代码与现有的 C 代码混合编译,通过链接器生成最终的可执行文件。目前,我们主要支持英飞凌的 TC3 和 TC4 系列芯片,并计划在未来几年支持更多的芯片。
在编译器认证方面,我们按照汽车行业的 V 模型进行开发,从需求架构设计、详细设计到测试,最终通过 ACLD 评估。认证成本和时间都非常高,目前我们支持的芯片包括英飞凌的 TC3 和 TC4 系列。
Rust 在汽车行业的前景
我们与英飞凌合作,发起了 Rust 在汽车行业中的应用模型。英飞凌作为芯片厂商发起了这个项目,而我们则负责编译器和操作系统的开发。
这是整理后的第一部分,接下来如果有第二部分我会继续保持相同的格式。
Rust 在汽车行业中的应用方案及演示
A4LD 评估和与英飞凌的合作
接下来我们做了一个 A4LD 的评估,第三部分是我们和英飞凌发起了一个 Rust 在汽车行业使用的小模型。这个模型是英飞凌作为发起人,因为他们是芯片厂商。我们的角色是负责编译器和操作系统 (OS) 的开发。
我们本身有一个 OS,叫做 PikeOS,这个 OS 已经开发了 20 年,主要应用在汽车行业。最早是用 C++ 编写的,但我们现在已经用 Rust 重新编写了一部分。最底层是英飞凌提供的硬件,使用的是英飞凌 TC3 系列芯片。再往上是英飞凌和另一家合作伙伴开发的驱动程序。这一层主要是芯片的访问层。
系统架构与分层设计
往上是我们的 OS 和编译器。最上层是应用层与底层之间的抽象层。这个层次在汽车行业中类似于 AUTOSAR 中的 RTE(Runtime Environment)概念。这个抽象层封装了底层驱动,应用层不能直接访问底层驱动,必须通过抽象层来实现。
这种设计严格遵循汽车行业的分层结构,分为四个层次。右侧是我们与合作伙伴的演示模型,展示了几个机构的合作成果。下方是我们使用的调试器,例如 Lauterbach 和 PLS,它们都是目前在汽车行业中支持我们 Rust 方案的工具。
纽伦堡展览与系统演示
在今年纽伦堡的嵌入式展会上,我们展示了这个方案。展示的内容包括一个大屏幕(Android 系统),中间是英飞凌的 TC375 芯片,带有一些外围驱动(例如 TCP)。整个系统安装在一个板子上,最底部是我们的模型车。
在这个三层结构中,橙色部分是 TCP 协议栈,位于存储层。以太网部分的代码还是用 C 编写的,但模型车上的代码是使用纯 Rust 编写的。这部分代码由我们和 PTA 提供。通过这个方案,我们可以在大屏幕上触发动作(比如开关车门),这些操作通过链路传递到模型车上。
多任务与代码设计
在整个系统中,我们设计了几个任务(Task)。其中一个任务是用 C 编写的,运行在英飞凌的三核架构上。每个内核运行不同的任务。在 Core 1 上运行的是 CAN Task,这是一个纯 Rust 编写的程序,用来接收上层命令并传递给模型车控制相应的指令。
在 Core 2 上,我们运行了一个 JavaScript 任务,用来触发车辆开关等指令。整个系统涵盖了车内的以太网、CAN 通讯协议栈、OS 启动和通讯等,形成了一个完整的车辆应用场景。
系统架构细节
我们展示的系统架构中,最底层是非安全的 C 代码,通过外部函数接口与应用层交互。上层的部分是我们的 OS,它经过 ISO 26262 认证,确保了系统的安全性。OS 内核负责管理外围的以太网和 CAN 协议栈,形成了完整的系统。
上层的紫色部分是纯 Rust 编写的代码,而底层的驱动和测试部分则是用 C 编写的。我们允许开发者自由选择使用 C 或 Rust 编写代码。如果遇到安全性高或容易出错的部分,可以使用 Rust 编写,并通过混合编译将代码烧入控制器中。
Rust 在汽车行业的未来展望
最后,我想展望一下 Rust 在汽车行业的未来前景。老外做了一张图,认为 Rust 是汽车行业的“游戏规则改变者”。在上次培训中,我们发现 Rust 在欧洲非常受重视。去年,我们在德国招募了十几名软件工程师,要求他们精通 Rust。这种情况在以前是没有的,以前大多数是要求精通 C 和 C++。但现在,Rust 作为汽车电子行业的门槛语言,三到五年内将成为汽车行业的标准技能。
Rust 在中国汽车行业的现状
在中国,理想汽车和蔚来汽车也在大量招聘会 Rust 的开发者,并提供了非常高的待遇。随着国内造车新势力趋于稳定,未来几年将是性能优化和安全性提升的关键时期。我们预计 Rust 在三到五年内将在中国的汽车电子行业大规模普及,特别是在智能座舱和自动驾驶领域。
目前,华为也在大量使用 Rust 开发控制器,只是没有公开报道。所以我们认为 Rust 在 10 年内,尤其是三到五年内,在中国的汽车行业必然会火爆。
观众提问与解答
关于 Rust 兼容性和版本更新
问题: 对于不同版本的 Rust(例如 V4 版本),API 兼容性和不稳定特性是如何处理的?新编译器对过往代码的兼容性如何?
解答: 我们从 1982 年成立以来,一直坚持用开源技术做商业编译器。我们基于 LLVM 技术构建 Rust 编译器,所以当社区代码有更新时,我们会及时同步。Rust 版本有稳定版和非稳定版,我们都会同步最新的社区版本,确保兼容性和新特性。
关于汽车标准和编译器认证
问题: 汽车标准对编译器有什么要求?Rust 编译器是如何通过汽车标准认证的?
解答: 我们开发的 Rust 编译器虽然基于开源项目,但经过了大量定制,特别是针对特定芯片的优化和认证。开源编译器虽然能用,但未经过车规认证的工具链是不能在车上使用的,因为一旦出现问题(如软件或编译器问题),车厂将承担巨大的风险。
我们经过了多次认证,包括功能安全认证(TCL 级别)。这些认证确保我们编译器的所有选项都经过严格测试,编译过程中的每一个步骤、每一个选项组合都经过故障注入分析,以确保编译结果的安全性和稳定性。
关于编译器的功能安全和置信度
问题: 汽车行业中,编译器如何满足功能安全标准?
解答: 在汽车行业中,工具链需要具备置信度(TCL)。所有的商业编译器都必须达到 TCL3 级别,意味着编译器必须经过严格的认证。我们在开发过程中,对每一个函数和边界值都进行了详细测试,并确保每一行代码都有注释。经过这些测试后,我们将结果提交给认证机构,如德国莱茵、SGS 等,确保工具链能通过功能安全认证。
总结
今天的分享就到这里。非常感谢大家参加 Rust China Post 会议,也感谢每位嘉宾的精彩分享,以及工作人员和组织者的辛勤付出。希望我们明年再见!
43-Async Rust 维测&定位的探索和思考-陈明煜
大家好,我是来自华为的陈明煜,今天我带来的议题是《Async Rust 维测与定位的探索与实践》。如果在座的各位有去年参加 Rust China Conference 的同学,可能对我还有印象。去年我介绍的是我们为 OpenHarmony 开发的 Rust 异步框架,叫“应龙”。今天的议题也是基于应龙框架展开的。
今天的主题会分为三个部分:
- Rust 异步的技术介绍,包括有栈线程和无栈线程的区别,以及为什么 Rust 异步调试难。
- 社区中常见的异步调试方案,探讨它们的使用方式。
- 我们在应龙异步框架上的调试增强,以及我们对比 Rust 异步底层机制的一些探索。
第一部分:Rust 异步的技术介绍
异步编程已经是一个非常常见的概念,很多语言都具备这样的能力,比如 Python、Go、C++。异步编程的工作方式类似于多线程编程,异步任务由多个工作线程执行。当异步任务未生成时,这些工作线程会获取任务并执行。
相比线程模型,异步框架的调度颗粒度更小,因为异步任务遇到阻塞时,并不需要阻塞自己来等待任务完成,而是可以将任务挂起并先去执行其他异步任务。这一做法可以更好地利用线程资源,在相同线程数下,异步框架可以调度更多的任务,同时线程数也更加可控。
此外,任务的创建相比线程创建,其内存开销从 KB 级别下降到 B 级别,任务切换的时间也从微秒级下降到纳秒级。
Rust 本身并没有原生的异步调度框架,而是提供了一些异步语言特性。比如 Future,它是 Rust 异步里最核心的机制,是一个 trait,提供了 poll 方法用于承载当前异步任务的核心逻辑。
async 是用于标记一段代码为异步的关键字,经过编译器编译后,它变成了一个返回实现了 Future 对象的函数。当我们对 Future 对象调用 .await,就是在异步等待任务完成,poll 方法则用于驱动该任务的执行。
Waker 是用来唤醒一个之前挂起的任务。我们可以看一个异步方法的示例:在 main 函数中依次对 mission1、mission2、mission3 进行了异步调用。经过 Rust 编译器编译后,它生成了一个实现 Future trait 的对象,作为异步任务的状态机。
在任务执行时,状态机会保持任务的当前执行状态。如果 mission1 执行返回 Pending,整个 main 函数就会退出,线程可以继续执行其他异步任务。当 mission1 返回 Ready 时,任务会继续执行 mission2,以此类推。Rust 的异步机制是无栈线程的实现,所有任务的执行都在工作线程上完成。
有栈线程 vs 无栈线程
Rust 的异步模型采用了无栈线程的方式,即每个线程并没有独立的栈空间,而是使用工作线程的栈。这种方式的优势在于执行效率高,内存更加节省。
相比之下,有栈线程拥有独立的栈空间。在 Go 语言中,每个 Goroutine 都有自己的栈,当发生线程切换时,直接从线程 A 跳到线程 B 的栈上。
无栈线程的缺点在于,Future 的 poll 方法执行完后,栈会被回收掉,用户无法通过线程栈感知异步任务的执行进度,也无法定位异步任务挂起的位置。这使得调试异步任务变得困难。
第二部分:常见的异步调试方案
Rust 社区提供了一些异步调试机制,主要包括:
tracing:由tokio提供的日志打点记录能力。用户可以手动或通过配置文件为异步函数增加日志信息,帮助追踪异步任务的执行过程。tokio-console:类似于 Linux 的top命令,它可以动态显示任务的执行状态,包括任务的阻塞时长、挂起时长以及任务的位置等信息。await-tree:由国内团队白森威夫开发,它可以维护一个树状的控制流,帮助用户了解异步任务的调用栈。
我们来看 tokio-console 的一个示例:左边的截图显示了异步框架下任务的执行状态,包括任务执行了多少次、阻塞时长、挂起时长等。右边的截图则展示了单个任务的调度信息,包括 Waker 的状态(如克隆了多少次、唤醒了多少次等)。这些信息有助于用户了解任务的性能瓶颈,方便后续优化。
然而,tokio-console 只能告诉用户任务挂起了,却无法定位挂起的具体原因。此外,它在运行时会引入一些额外的开销,通常只能在调试阶段使用。
相比之下,await-tree 更轻量化,它会为每个异步函数自动生成一个树状结构,显示异步任务的调用关系。不过,await-tree 需要手动为每个异步函数增加日志信息,且仍然会在运行时引入额外开销。
第三部分:应龙框架的调试增强
OpenHarmony 对异步调试有一些商用诉求,因此我们针对这些需求在应龙框架上进行了一些优化。
1. 跨语言异常处理
当 Rust 线程调用 C++ 的异常接口时,可能会导致栈丢失。Rust 线程在启动时会将所有执行逻辑封装在一个 catch_unwind 中,目的是防止线程 panic 导致进程崩溃。但由于它无法处理跨语言的异常,最终会导致栈信息丢失。解决方案是:避免使用 catch_unwind,改用 Linux 的 pthread 接口。
2. 无栈协程的栈回溯
无栈协程的一个问题是,挂起后无法获取线程栈信息,调试困难。为了解决这个问题,我们在应龙框架中引入了一些机制,允许用户在异步任务挂起时获取栈信息,以便更好地调试和定位问题。
接下来由我的同事楼智豪为大家介绍我们在应龙框架上对异步推栈处理的一些探索。
楼智豪:
大家好,接下来由我来介绍我们在应龙框架中对异步推栈处理的一些改进。
无栈协程的问题在于,当线程挂起时,无法直接查看任务的调用栈。在我们实际的开发过程中,这个问题非常重要,因为我们需要了解系统的健康状态。
我们可以通过一些机制来解决这个问题。比如,在执行异步任务时,每个 Future 都可以看作是一个树状结构。每次任务挂起后,栈信息会保存在叶节点中。通过观察 SP 和 FP 寄存器,我们可以获取到任务的上层栈信息。
这样一来,即使任务挂起,我们也可以通过这些信息来回溯任务的执行状态。
通过这些优化,我们在应龙框架中提升了异步任务的可调试性和可定位性,使得 Rust 的异步编程更加商用化。
我们称其为中间节点。在最后一层,它会实际返回一个 padding 或者 randy 的 imply future 函数,我们称之为叶节点。Future 间的嵌套可以吸收一个树状结构。比如说,当某一次从叶节点以 panic 状态退出协程时,下一次的执行也必定会从这个叶节点开始。
假如某个线程在某次运行到达了叶节点,我们可以像传统的线程那样,通过调用观察 SP(栈指针)和 FP(帧指针)寄存器,获取整个上层的栈信息。因此,在运行状态下,获取栈信息是相对容易的。
问题是,当它没有运行时该怎么办?一个直观的想法是,如果它没有运行,我们可以去运行它,从而获取栈信息。但这里又出现了新的问题:我们原本并不希望它运行。如果只是为了查看它的栈而把它运行起来,这并不是我们期望的行为。
因此,我们想出了一种新的办法,称之为“有限的 Future 执行”。怎么理解呢?当我们某个时间点希望去查看它的栈时,我们执行了这个 Future,它经过几个中间节点,最终到达叶节点。而这个叶节点是上一次返回的叶节点。在叶节点的入口处,有一个类似 if should 的伪代码判断,我们不需要过于在意细节。在这个叶节点的入口,我们打印出栈信息并保存下来,然后返回给外界。接着,我们不再做任何程序处理,直接退出这个无栈协程。
这个无栈协程刚才经历的那一长串部分其实相当于程序的序言部分,而接下来真正关乎程序运行的业务逻辑部分并没有执行。这次调用满足了我们的期望:我们既获取了栈信息,但没有对任务的实际运行产生影响。相当于它看似运行了,但实际上并没有真正运行。
刚才讲的是我们如何在 padding 状态下获取栈信息的一个方法。实际上,在更复杂的场景下,我们可能会遇到更多状态,比如 REI、panic 和 running 状态。我们会根据不同的状态组合,采取不同的操作。刚才讲的是一种实践中的异步推栈方法,接下来我会讲第二种方法。
第二种方法相比第一种稍微复杂一些,但也更加简洁。我们简单介绍一下无栈协程的定义:每个协程不具备独立的栈空间,而是共用一个线程栈。上文提到,每个无栈协程可以认为是一个状态机,本质上并没有栈。它有两个关键的数据位:一个是 data(用于保存相关数据,如变量或内存),另一个是 state(在编译器中生成的状态位)。
举个例子,假设一个 Future 中有三个异步任务 mission1、mission2 和 mission3,它们对应于三个叶节点。在状态位上,mission1 对应 suspend0,mission2 对应 suspend1,mission3 对应 suspend2。除此之外,还有两个固定的状态位:on_resume(初始状态)和 return(结束状态)。因此,它一共有五个状态,分别对应五行代码。我们只要找到 state 的值,便能知道当前正在执行哪一行代码。
假如我们找到了状态值为 2,这意味着正在执行 mission2 的代码行。然后可以进入 mission2 的代码中,重复上述过程,继续获取 state 的值。通过这种方式,我们可以逐层定位到异步任务的调用栈。
这是区别于第一种方法的第二种方法,它一步步地将整个异步调用栈抽丝剥茧地剥离出来。结合方法一和方法二,我们在应龙框架中实现了异步推栈的场景。
接下来是我们的工作线程和待运行队列。待运行队列中的协程可能处于 pending 状态或其他状态。无论处于何种状态,我们都会将它们统一在全局协程列表中管理。这种全局列表中的条目其实是协程的指针副本。当我们需要查询某个任务或一批任务的状态或备份栈时,可以通过句柄或字符串名称在全局协程列表中进行查找,以观察系统的运行状况。
再次回到异步推栈问题的核心:当我们编写代码时,协程的状态信息是可视化的函数调用。但在编译后,这些信息逐渐融合到代码程序中。我们的核心问题是如何将现有的信息转化为可视化的调用栈。
我们可以掌握的一些信息包括:运行时信息(如协程的指针地址)、编译时信息(如 IR 和 LLVM IR)以及编译后的信息(如 text 段)。第一种和第二种方法就是这些信息的组合与运用方式,最终将它们转化为可视化的调用栈。
我们当前在应龙框架上实现了这些方法。应龙框架目前在 OpenHarmony 上开源,大家可以在 GitHub 上找到我们的仓库,名称是 common library rust yinglong runtime。此外,还有 yinglong HTTP 和 yinglong JSON 等框架,基于应龙的调度器实现。我们在 OpenHarmony 上已有大量 Rust 代码,大家有兴趣可以关注我们的项目。
最后,简单打个广告:华为的 Rust 岗位非常欢迎大家加入,无论是新手小白还是资深专家,我们都非常需要你们。我们的工作地点在上海、杭州和东莞,欢迎有兴趣的同学联系我们。
接下来是提问环节。有位同学已经举手了,您先来吧。
提问 1:
你好,我有两个问题。第一个问题是,您刚才提到推栈时会再次执行协程。如果协程中有 sleep 或者一些随机的操作,怎么办呢?
回答:
这其实就是我刚才提到的,第二次执行协程时,执行是有限的。看似执行了,但实际上并没有真正运行。我们只执行了代码的序言部分,记录栈信息后便直接返回,并不会执行 sleep 或 rewrite 等实际逻辑。这样我们就能获取栈信息而不影响任务的状态。
提问 2:
大部分人使用 tokio,应龙框架和 tokio 之间是什么关系呢?如何转变呢?
回答:
我们虽然在机制上与 tokio 类似,但针对 OpenHarmony 场景(如移动设备)进行了优化。在功能和性能上,我们做了一些定制化的改进,尤其在资源开销和 RAM 占用上,做得比 tokio 更轻量化。
主持人:
因为时间关系,请每位同学只提一个问题哦。如果还有问题,可以会后与讲师交流。
提问 3:
你好,我想问一下,如果程序运行过程中没有捕获 backtrace,这个框架会带来多大的性能开销?
回答:
这也是我们为什么不采用 tokio 或 await_tree 的方式。它们的方式会带来较大的代码改动和运行时开销,我们无法接受。而我们介绍的这两种方法,不需要修改代码,并且在不触发的情况下不会带来任何性能开销。可能唯一的影响是打包体积稍微增大了一点。
提问 4:
我有两个问题。第一个问题是,尝试执行时是否需要在代码里加点标记?比如在 sleep 或 rewrite 之前加 if 判断?
回答:
是的,我们会在原有代码逻辑前加一个 if 判断,来记录 backtrace 并退出。
提问 5:
第二个问题是,能否在指令集层面加一条指令,跳到内核的 kprobes 或 ftrace?
回答:
指令集层面的修改不是我们轻量级框架能做到的。我们更倾向于通过软件方式实现这一功能。
提问 6:
请问全局协程列表是应龙独有的吗?还是所有 runtime 都有?
回答:
全局协程列表是应龙框架特有的。我们为了管理和调试协程,专门做了这样的设计。
提问 7:
我想问一下,如何在线上识别长时间阻塞运行的任务?比如由于输入参数不同而导致执行时间变长的 for 循环?
回答:
这是 CPU 密集型任务与 IO 密集型任务的场景。我们通过协程扩展等机制,避免两者之间的相互影响。这个问题超出了今天的异步调试主题,但我们在框架中也进行了考虑和优化。
主持人:
再次感谢陈明煜和楼智豪讲师的精彩演讲!
44- Rust HashMap:比看起来更复杂 - 曹瑞秋
视频链接
演讲内容
主持人:
如果有问题的话,可以加您微信。接下来让我们邀请蚂蚁集团高级开发工程师、Apache HoraeDB 核心开发者曹瑞秋老师来给我们带来“Rust HashMap:比看起来更复杂”的分享。
曹瑞秋:
大家好,我叫曹瑞秋,来自蚂蚁集团。今天来分享一个看似简单,但在实际使用中存在不少坑点的 Rust HashMap 的一些问题与解决方法。主持人刚才已经介绍了,今天我们会讨论 HashMap 的一些性能问题,特别是在 CPU 消耗和内存占用方面。
接下来我会简单地做个介绍,内容包括:
- 为什么我们会在时序数据库中遇到 HashMap 的问题;
- HashMap 在实际使用中的坑点;
- 以及相应的优化方法。
软广:
先简单介绍一下我们团队的项目。我们的 HoraeDB 于 2022 年 6 月开源,12 月捐献给 Apache 基金会,并改名为 HoraeDB,目前处于孵化期。感兴趣的朋友可以关注一下。
引入 HashMap 的背景:
我们开发时序数据库时遇到性能瓶颈,尤其是在开发针对监控场景的 Metric Engine 时,发现使用的 HashMap 存在一些性能问题。通过 POC(概念验证阶段)的测试和 Benchmark,我们注意到 HashMap 的性能不如预期,于是我们开始深入研究其问题。
HashMap 的历史:
HashMap 作为一种数据结构,最早在 1953 年由 IBM 提出,现在几乎每个项目中都会用到。我们在开发的 Metric Engine 的 Main Table 中依赖 HashMap 来存储时间序列数据。
时序数据的基本概念:
时间序列数据由唯一标识的时间线(TSID)和随时间变化的数据组成。例如,一个容器的 CPU 或内存占用随时间变化的数据点,都会被记录在时间线中。
HashMap 的第一个坑:分段问题:
虽然我们的 Main Table 本质上是一个 HashMap,但由于并发读写的需要,我们使用了加读写锁和分段优化的实现。参考了 Gorilla 的论文,我们将 HashMap 分为数千段,以减少冲突。
然而,时序数据的写入特性导致了性能问题。每个写请求可能涉及多个时间线,而这些时间线会分散到不同的 HashMap 段中,导致 CPU 缓存和 TLB 的局部性差,性能下降约 10%。
优化方法:
我们在每个 HashMap 段中增加了一个 Write Buffer(写缓冲区),使写入操作能够批量进行,从而减少了 CPU 缓存和 TLB 的 Miss 率。经过优化,TLB Miss 率降低了约 80%,性能提升显著。
内存问题:
除了 CPU 性能,HashMap 在内存占用上也存在问题。即便我们使用 with_capacity 方法预分配内存,实际分配的虚拟内存往往远超预期。通过研究 HashMap 的底层实现(hashbrown 库),我们发现 Rust 会根据建议的容量放大内存,具体的计算公式如下:
[
实际容量 = \left(建议容量 \times \frac{8}{7}\right) \text{向上对齐到2的幂} \times \text{key和value的大小} + \text{控制位}
]
例如,预分配 2000 万条数据的 HashMap,实际分配的虚拟内存为 544MB。再加上系统的内存对齐,最终实际分配了约 556MB 的内存。
物理内存占用:
我们还发现,尽管只插入了 1000 条数据,物理内存的占用却接近 3.86MB,相当于 25 万条数据所占的内存。这是因为 HashMap 的随机访问特性导致内存分布不均匀,进一步加剧了内存的浪费。
优化建议:
- 设定合理的
with_capacity,避免过度分配内存。 - 在 HashMap 中存放较小的 key,将大数据存放在其他地方,减少物理内存的浪费。
总结:
HashMap 在 CPU 和内存上的问题可以通过合理的优化手段得到改善。针对 CPU,我们可以增加 Write Buffer 来提高缓存命中率;针对内存,我们可以通过精确预估容量和优化数据存储结构,减少内存浪费。
提问环节:
问题1:
提问者:您提到的 Write Buffer 会不会带来内存序的问题?
曹瑞秋:我们在每个 HashMap 段上加了写锁,保证写操作的原子性,因此不会出现内存序的问题。问题2:
提问者:我们对比了 Rust 和 Java 的 HashMap,发现 Rust 在随机读性能上不如 Java。是否有针对读优化的哈希算法?
曹瑞秋:Rust 和 Java 使用的哈希算法不同,Rust 默认的哈希算法可以替换为更适合的算法,从而提高读性能。你提到的情况可能是由于哈希算法的差异导致的。问题3:
提问者:Rust 的并发 HashMap 是用锁还是其他机制实现的?
曹瑞秋:Rust 默认的 HashMap 是单线程的。并发版本可以使用dashmap,它通过更复杂的机制实现了更好的并发性能。问题4:
提问者:您提到的内存放大公式是否适用于 C++?
曹瑞秋:这个公式是针对 Rust 的 hashbrown 库实现的,其他语言的 HashMap 实现可能不同,因此不一定适用。
主持人:
感谢曹瑞秋老师的分享,今天的提问环节到此结束。
44- Rust HashMap:比看起来更复杂-曹瑞秋
如果有问题的话,可以加您微信。接下来让我们邀请蚂蚁集团高级开发工程师、Apache HoraeDB 核心开发者曹瑞秋老师,来给我们带来 “Rust HashMap:比看起来更复杂” 的分享。
曹瑞秋:
大家好,我叫曹瑞秋,来自蚂蚁集团。今天来分享一个看似简单,但在实际使用中存在诸多坑点的 HashMap,以及一些解决方法。刚才主持人也介绍了,今天的主题是 “Rust HashMap:比看起来更复杂”。这是我的一些个人信息,稍微看一下就可以。
今天的分享目录如下:
- 简单的介绍
- 软广
- 我们的时序数据库为什么会涉及到 HashMap
- 我们是如何踩坑的
- HashMap 的坑点以及相应的解决方法
首先,做一下软广。
其实,HoraeDB 的前身是我们每年都会讲的一个开源时序数据库 CeresDB。它的 4.0 版本于 2022 年 6 月开源,到了 12 月份捐献给了 Apache 基金会,因为合规方面的一些问题,内部改名的难度比较大,所以我们在外部开源版本里改了名字为 HoraeDB,目前处于孵化期。如果大家有兴趣,也可以关注一下。
接下来分享一下我们为什么在实际数据库开发中会涉及到 HashMap。最初,开源版本的 CeresDB 是比较关注实例分析,试图开拓新的领域。最近,我们打算回归老本行,继续开发 APM(应用性能管理)相关业务,强化 Metric Engine 的能力。Metric Engine 的核心模块 LOSM(Log-structured Merge Tree)中,Main Table 强依赖 HashMap。在 POC (概念验证) 阶段,我们跑 Benchmark 测试时,发现性能不如预期,经过分析后发现了很多坑点,这就是我们今天讨论的主题的由来。
HashMap 的历史:
HashMap 作为一种数据结构,历史比较悠久,最早在 1953 年由 IBM 提出,现在几乎所有项目里都会用到它。我们在 HoraeDB 这个新的 Metric Engine 中的 Main Table,实际上也是依赖于 HashMap。其 key 是时间线 (TSID),value 是时间线随着时间推移产生的时间序列数据。
时序数据的基本概念:
时间序列数据可以理解为某个数据实体的组件,它由一组唯一标识数据实体的标签组合而成。以容器为例,我们可以用 IP 和名称来指定容器,这个实体随着时间推移不断产生一系列数据,比如内存占用或 CPU 占用。下图展示了一个容器的 CPU 和内存占用随着时间推移的变化。
TSID (时间序列 ID) 是这些标签的哈希值,可以简单理解为传统数据库里的主键。开发 Metric Engine 时,我们遇到了一些坑点,发现 HashMap 并不像表面上看起来那么简单,存在不少隐藏的问题。
HashMap 的第一个坑:分段问题
Main Table 虽然本质上是一个 HashMap,但由于并发读写的需求,它并不能只是一个单纯的 HashMap 实现。在实际实现中,我们加了读写锁并进行分段优化。我们参考了 Gorilla 论文中的方法,通常会将 HashMap 分成几千段以减少冲突。下图展示了分段和加锁的示意图。
分段和加锁是常见的优化方法,但在时序数据写入场景中,它表现出了问题。时序数据的写入通常是由监控系统(如 Prometheus)在某个时间点采集多个实体的数据点,因此一次请求可能包含多个时间线的数据。当这些数据写入分段 HashMap 时,可能会涉及到几千段中的多段,导致每段只写入一个点,局部性非常差。每个写入点在不同段中的位置是不确定和离散的,这会导致 CPU 缓存和 TLB 的命中率非常低。我们在 Benchmark 中发现,这个问题导致了大约 10% 的性能下降。
优化方法:
为了缓解这个问题,我们在每个 HashMap 段中增加了一个 Write Buffer。Write Buffer 通过批量写入减少了 CPU 缓存和 TLB 的 Miss 率。具体来说,即使一个请求分散到几千个段中,它也会首先写入 Buffer 中,等到一定数据量后再一次性刷新到 HashMap 中。这样可以大幅减少随机写入,优化 CPU 缓存命中率。我们在开发机上测试的结果显示,TLB Miss 率下降了大约 80%,整体耗时减少了一半。
这是一个简单的示例,展示了分段 HashMap 在时序数据写入场景下的问题。通过增加 Write Buffer,我们显著改善了 CPU 性能,减少了缓存和 TLB Miss 率。
HashMap 的第二个坑:内存问题
HashMap 在内存占用方面也存在一些坑点。通常我们会使用 with_capacity 方法预分配内存,以避免在插入过程中频繁扩容,影响性能。接下来,我会举一个例子来说明 HashMap 的内存问题。
我们以 with_capacity(2000万) 初始化一个 HashMap<usize, usize>,从直觉上看,应该只需要分配 2000 万条数据所需的内存。但实际情况并非如此。通过分析 HashMap 的底层实现(hashbrown 库),我们发现它会根据建议的容量进行放大。
所以根据这个源码,梳理出了一个比较简单的公式。
虽然不是完全匹配,它大概会这样给你做一个 Key 和 Value 的放大。首先,它会将你建议的 capacity 乘以 8/7,然后再对齐到 2 的 n 次方。对齐后,它再将这个对齐后的大小乘以 key 和 value 的大小,并加上每个 8KB 的控制位,最终分配这么多的虚拟内存。通过这个简化的计算公式,对于 2000 万容量的 HashMap,key 和 value 都是 usize 类型,计算出来大概会分配 544MB 左右的虚拟内存。再加上公式中未涉及的边角料分配和操作系统在分配虚拟内存时的对齐,最终分配约 556MB 的虚拟内存。可以看到这两个数字非常接近,所以这个公式得出的结果可以大致匹配实际的分配情况,用来衡量实际的分配结果。
上面讲的是虚拟内存的放大,实际上在物理内存分配时也会有类似的放大。这涉及到操作系统分配物理内存时,按照页面分配的特性。这里以一个简单的例子来说明:
在刚才分配出来的 2000 万容量的 HashMap 中,插入 1000 条数据的话,它实际上会占用多少物理内存呢?直觉上,你可能认为插入 1000 条数据只会占用 1000 × 2 × usize 大小的物理内存,但实际情况并非如此。通过 ps 查看,插入 1000 条数据后,实际分配大概是 3.86MB 的物理内存,约等于 25 万条数据的大小。
为什么只插入了 1000 条数据,却占用了 25 万条数据的内存呢?这主要是因为 HashMap 使用 with_capacity 初始化时,分配的虚拟内存本身就比较大,再加上 HashMap 在插入和查询时,访问内存是随机的。在最极端情况下,1000 条数据可能会扩散到 1000 个不同的物理页面上。因此,插入 1000 条数据时,可能会导致物理内存的放大情况更严重。
我们在线上也遇到类似问题,在某些情况下指定的 capacity 很大,但实际使用却远远不到这个数值,导致物理内存水位居高不下。发现问题后,我们调整了 capacity 设置,使之更加合理,线上内存水位显著下降。
教训:
capacity的设置要谨慎,不能拍脑袋设定。最好是根据实际预测的使用量设置接近实际容量的capacity。HashMap最好作为索引使用,比如存一个较小的 key,再通过 offset 存储较大的 value 部分在外部存储中,尽量减少HashMap虚拟和物理内存的放大。
软广:
这是我们的项目公众号和微信群。最近也在针对监控场景优化 Metric Engine,正在推进两个大项目,一个是 达标 的重构,另一个是 Remote Compression。由于线上 compression 任务与读写任务抢资源的情况严重,我们正在优化这一部分。有兴趣的可以关注一下,欢迎参与项目的孵化。
谢谢大家!
现在是提问环节,大家可以举手示意。
提问 1:
听您的分享提到 vector buffer,它在 CPU 中类似于写缓冲区,但它有个问题,就是不能保证内存序。请问这会不会带来一些问题?
曹瑞秋:vector buffer 其实加了写锁,写入时会阻塞其他线程,理论上内存同步是可见的。
提问 2:
我们做了一个测试,发现 Rust 的 HashMap 在随机写入上比 Java 好,但在随机读取上,Java 的冲突处理机制效率更高。请问有没有针对随机读优化的方案?
曹瑞秋:
有篇文章提到,将 Rust 默认的哈希算法换成与 Java 一致的算法,随机读性能反而会更好。可能你们遇到的问题与此有关。
提问 3:
Rust 的 HashMap 在并发环境下是用锁还是 CAS?
曹瑞秋:
Rust 的并发 HashMap 通常是用锁实现的。我们这里是加了读写锁,分段数较多,冲突比较少。
提问 4:
为什么不直接使用 DashMap?
曹瑞秋:
我们之前在其他模块中使用过 DashMap,但线上出现了死锁问题,至今没有搞清楚原因,所以没有特别敢用。
提问 5:
刚看到您提到 HashMap 的内存占用公式,这个公式在 C++ 或其他语言里是否适用?
曹瑞秋:
这个公式是基于 Rust HashMap 底层实现的 swiss table 算法,其他语言如果使用不同的实现方式,公式可能不适用。
结束语:
由于时间关系,提问环节到此结束。让我们再次感谢曹瑞秋老师!
45-Rust 和 C++ 互操作及交叉编译-朱树磊
谢谢介绍啊,我是朱树磊,今天分享的主题是 Rust 和 C++ 互操作及交叉编译。参加这次 Rust 大会,我发现大部分参加者都是年轻人,像我这样超过 35 岁的,life time 被设定为 static 的程序员还比较少。但我站在这里就表明了,我们这些老程序员并不抗拒 Rust,是吧?有些宗教你叫什么呢?那个 Rust 教不存在的嘛。嗯,不过我还是要感谢一下组委会,允许我在这里讲这样一个话题,因为这相当于在 Windows 下面讲 WSL,在 Emacs 上讲 evil,比如说 Email 里面有个 vi 插件,是吧?我们 Rust 世界还是非常开放的。
我目前就职于浙江大华技术股份有限公司,主要从事 AI 算法开发。过去我认为一个在工业界混得合格的 AI 算法工程师需要掌握三门语言,就是 Python 做训练,C++ 做开发和部署,TypeScript 做原型。但自从接触 Rust 之后,我发现年轻程序员不需要挣扎于 TypeScript 或 Python,可以直接上 Rust。我近年来也尝试使用 Rust 来做一些大规模数据处理以及大模型的部署。为什么做这些呢?因为在大模型部署中,历史包袱比较轻,可以使用一些微服务或模型积木进行较好的解耦。
但是,大华作为一家以视频互联为核心的计算和收费不联解决方案提供商,产品有上万款端面影产品,运行的大部分还是 C 和 C++ 代码,框架也是 C 和 C++ 开发的,所以 Rust 化是一件非常困难的事情。如果出现问题怎么办?我想没有哪个团队有那么硬的脊梁背得起那么一大口大铁锅。但还是有很多程序员采纳了 Rust 开发一些组件,来解决内存泄漏、内存竞争等问题。在这种情况下,C 和 C++ 与 Rust 的协同不可避免。我们这种公司,以及其他类似的公司,也面临着同样的情况。所以这就是我今天分享这个主题的动机。
我今天的分享主要分为三部分:首先讲互操作,然后讲代码构建以及交叉编译。
第一部分:为什么要进行 C 和 C++ 与 Rust 的互操作?
我要强调的是,我这里讲的是同一个进程中的两种语言交互。如果是不同进程的交互,比如使用 RPC,不管是 gRPC 还是 Swift,数据序列化后传给另一个服务,这是两个进程之间的交互,不在我们今天的讨论范围之内。
互操作的必要性
为什么要做互操作呢?
比如,想象一种情况:假如有一群勇士,非常彪悍的勇士,决定把一个 C++ 项目迁移到 Rust。这可能需要很长时间,无法一次完成。在此过程中,C 和 C++ 与 Rust 就需要协同工作。
还有就是 legacy code。在 IT 圈,legacy code 是个很有味道的词汇。你们懂的。在很多产品中,有很多资深的 C++ 程序员,使用了大量的编程第一法则开发了产品。你们知道编程第一法则是什么吗?就是:能跑就行。你要彻底 Rust 化这些代码是很困难的,所以 Rust 和 C++ 就不得不协同工作。
另外,我们在使用开源软件的时候,往往需要与 C 和 C++ 交互。很多开源框架,比如 CV、IPad,或者机器人操作系统 ROS,都是大型的 C 和 C++ 库或中间件。如果你想在 Rust 项目中使用它们,你就需要 Rust 的接口。非常幸运的是,像 ROS 这些系统,很多已经有 Rust 的接口。
还有一种情况,就是你可能对 C++ 难以割舍,同时又对 Rust 充满好奇。比如说像我这样的资深程序员,面对 C++ 和 Rust 这两种语言,就像面对林黛玉和薛宝钗。你就想双修。那在这种情况下,你可能在 Rust 中需要 C++ 的协程、内存管理器等功能,或者你想在 C++ 项目中使用 Rust 的 crates。这个时候,就需要交互。
最后,高性能计算领域,比如 CUDA、CORBA 这些框架,很多都是基于 C++ 的。如果你想做异构编程,就不得不进行语言的交互。
平台限制
大部分驱动程序基本上都是 C 写的,接口也是 C 的。如果你不想做逆向工程或者不想写 Rust 驱动程序,那你就只能和 C 打交道。
第二部分:Rust 和 C++ 互操作的工具
现在讲讲 Rust 和 C++ 互操作的工具。我们只讨论同一进程内部的交互。
首先,FFI(Foreign Function Interface)基本上是所有语言的底座。所有新语言都要向 C 致敬,它们都有一个 extern "C" 关键字。在写代码的时候,我们不会完全靠手写,往往会借助一些 like bindgen、cbindgen 这些工具来生成接口。然而,无论如何,boilerplate code 是不可避免的。
Bindgen 和 cbindgen 是两种工具,前者适用于 Rust 调用 C++,后者适用于 C++ 调用 Rust。Linux kernel 中大量使用了 bindgen 来生成接口,但这些工具只有限支持 C++。
另外还有 rust-cpp 这个 crate。假如你想在 Rust 项目中调用 C++ 的接口,比如 Qt,你可以使用 cpp! 宏。但这仅适用于少量代码。如果整个项目到处都是 cpp! 宏,那项目就会很难维护,调试和构建也会很麻烦。
除此之外,还有 Google 的 autocxx 和 cxxbridge 工具,它们可以解决一些 Rust 和 C++ 互操作的问题。不过像 autocxx 可能只适用于 monorepo 的代码管理方式。
今天我主要介绍的是 David Tolnay 开发的 cxx crate,这个工具号称是安全的防具,因为它不仅像胶水一样把两个语言粘合在一起,还像齿轮一样嵌入到对缝中间。它可以在边界处进行静态检查,保证函数签名一致,并确保共享数据类型的 ABI 兼容。当然,它改变不了 C++ 是不安全语言的本质,C++ 还是 unsafe 的。
cxx crate 还支持两种语言中关键的数据结构,比如智能指针、Rust 中的 slice、vector 和 string 等。我们还可以通过一些技巧,用 Rust 异步调用 C++ 的协程。例如,我们可以用 folly 库中的协程来实现异步调用。
在 cxx 官方 demo 中有一个叫 Blog Series 的项目,它提供了 Rust 和 C++ 的接口示例,其中有一个 put 的同步接口。
整理后的文本如下:
一个放在一个三角形上面,实际上大部分语言都是通过 C 来转移到,但 C++ 的话,它直接构建了 Rust 和 C 之间、C 和 C++ 之间的桥梁。这是它与其他语言不一样的地方。另外,大部分的工具都支持 Rust 调用 C++,反过来 C++ 调用 Rust 的情况则比较少见。C++ 和我刚才提到的 Z 高、CCCBENJIN 是目前可能仅有的选择。
我们已经有了这样一个混合两种语言的项目,那么我们该如何去构建呢?
接下来我要讲的是构建部分。假如你没有用 C++,你可以用 c secret。如果我们使用了 C++,也有一个叫做 cxc-build 的 crate。我们在依赖 depend of development 时依赖这个 crate,然后我们可以在 build.rs 里面去指定一些环境变量,比如编译参数、编译选项。
另外,我们还要给这个 crate 添加一个叫 staticlib 的类型。如果不想在命令行里指定环境变量和编译参数,我们可以通过项目的 .cargo/config.toml 文件去指定这些编译参数和环境变量。
这里,我希望大家记住两点:
- 如果是 Rust 调用 C++,你继续使用原来的 Cargo 和构建工具。
- 如果是 C++ 调用 Rust,你原来用什么就继续用什么,比如 CMake、Bazel、Buck 等。
可能有一些 Rust 洁癖的人喜欢用 Bazel,因为 Buck 也是用 Rust 编写的。在 CMake 中,我们会创建一个 custom command,让我们的 target 去依赖于这个 custom command。这个 custom command 实际上是调用 Cargo 来构建 Rust 部分的函数。通过这种方式,我们可以指定编译选项和环境变量,这样就能通过编程的方式统一两种语言的编译参数。否则,你可能会需要维护两套构建工具,进而引发很多问题。
我们也可以使用 cc, cxx, cross, 或 cross-cmake 这些 crate 来帮助构建。有兴趣的话可以去了解一下。关于 Rust 和 C++ 构建部分,我反复强调这两点:
- 如果是 Rust 调用 C++,使用 Cargo。
- 如果是 C++ 调用 Rust,使用原来的构建工具,比如 CMake 或 Bazel。
Bazel 和 Buck 里会有一些内置的 Rust 编译命令。我知道可能很多人和我一样,讨厌 C++ 的一个重要原因就是它的构建系统实在让人头疼,特别是涉及到交叉编译的时候。
交叉编译是指你在一个平台上开发,然后编译出可以在另一个平台上运行的程序。例如,我的开发机器是一台 MacBook Pro,一台号称地表最强的 ARM 开发板,我安装的操作系统是 Linux,而不是 macOS。所以它的处理器是 ARM 的 R764,triple 是 aarch64-unknown-linux-gnu。如果我想在这台开发机上编译一个能在 Windows 上运行的程序,而且不想用 MinGW,因为它速度较慢,而是想用原生的 MSVC,该怎么办?
过去,大家可能会在 GitHub 的工作流中搞一台虚拟机或者独立主机,安装 Visual Studio 和 Clang,然后编译出 Windows 下的程序。Rust 则不存在这种问题,我们可以直接通过 rustup 添加一个 Windows 的 triple,比如 x86_64-pc-windows-msvc,然后就可以编译 Windows 的程序了。
那 VC++ 是否也可以像 Rust 一样呢?Rust 的编译器 Rustc 是基于 LLVM 开发的,它和 Clang++ 都是 LLVM 的前端。能否基于 LLVM 打造一个通用的交叉编译器,像 Rust 一样在一台主机上编译一切?答案是可以的。我们可以构建一个通用的脚本编辑器。
这个交叉编译器有四部分组成:
- 编译器。比如 Clang、Clang++,以及一些辅助工具,比如 archiver、linker 和 compiler-rt(编译器运行时)。
- 标准库。包括 libc++、libc++abi、libunwind 等,甚至 OpenMP。
- 系统工具链。比如 Linux 上的 glibc、musl,还有 Android 的 NDK,iOS 的 SDK 等。
- 构建工具。比如我们可以通过
build.rs指定编译选项和环境变量。还可以在.cargo/config.toml中指定这些配置。
交叉编译时,我们需要通过内置的环境变量来指定编译哪个平台的代码以及编译选项是什么。通过这种方式,我们可以在 Rust 项目中编译 C++,并且可以跨平台编译 C++。
在 .cargo/config.toml 中指定环境变量时,Rust 的 config.toml 有个不便之处,就是它不能展开变量,所以经常会看到冗余的代码,比如版本信息等。
如果我们使用 CMake,和之前一样,可以通过调用 custom command 来指定编译选项和参数。
Rust 的环境变量有时是小写加下划线,有时是大写加下划线,非常不方便。
集成到 CI/CD 中时,我们可以写一个 shell 脚本,或者直接在 GitLab CI 或 GitHub Actions 中编译各个平台的程序。我们适配了很多国产 AI 芯片,每个版本的 SDK 都不同。所以,如果你的 AI 算法也需要适配这些编译器的话,会有大量的适配代码。这种情况下,有了通用工具链后,可以统一交叉编译,特别是在 Rust 和 C++ 混合编译时,补齐 C++ 的短板。
如果要在 Linux 上编译 Windows 程序,还要注意一些细节,比如多线程库(MT/MD)的选择,名字大小写问题等。编译 macOS 或 iOS 程序时,可能还会用到 lld64 或 ld64,不过这些链接器兼容性不一定很好。可以使用 lld 工具来解决这些问题。
这样的话,我们可以简化 CI 部署。在跨平台测试时,虽然可以使用 Rosetta、Box64 或 QEMU,但它们无法支持所有指令集,比如 AVX-512,因此有些优化后的程序还是需要在目标平台上测试。
总结一下,我们可以基于 LLVM 实现一个通用的交叉编译器,Rustc 能做到的,Clang 也能做到。今天我主要介绍了一个可以实现 Rust 和 C++ 互操作、异步调用的 crate jc_extension。
记住两点:
- Rust 调用 C++ 时,使用 Cargo。
- C++ 调用 Rust 时,使用原来的构建工具。
我们可以基于 LLVM 打造一个通用的交叉编译器,补齐 C++ 的短板,让 C++ 和 Rust 更好地协同工作。
谢谢大家!现在进入提问环节。
46-MoonBit:Rust移除 lifetime 并增加更多优点后的技术演进 - 张宏波
张宏波:粤港澳大湾区数字经济研究院(IDEA研究院)基础软件中心讲席科学家,MoonBit平台负责人,ReScript编程语言作者,OCaml前核心开发人员。本科毕业于清华大学电子系,博士期间曾在宾夕法尼亚大学从事函数式语言编译器开发工作。
演讲主题:Rust移除lifetime并增加更多优点后的技术演进
主持人:接下来让我们有请基础软件中心讲席科学家,MoonBit平台负责人张宏波老师,他将给我们带来“Rust移除lifetime并增加更多优点后的技术演进”。大家欢迎!
张宏波:嗨,下午好!非常感谢Rust组委会的邀请,今天很高兴与大家分享MoonBit项目。MoonBit和Rust有很深的渊源,稍后我会在开头的几张PPT中为大家讲解。
个人经历介绍
我先简单介绍一下自己。我本科毕业于清华大学电子工程系,之后去宾夕法尼亚大学攻读博士学位,主要研究方向是编程语言。在博士期间,我参与开发了OCaml编译器,成为其核心开发人员之一。如果大家熟悉Rust的历史,就知道Rust的第一个编译器是用OCaml写的,这也是我和Rust的渊源之一。
在博士毕业后,我加入了Bloomberg,在那里我开发了一个叫ReScript的编程语言,它是将OCaml编译成可读的JavaScript。这个项目很快成为了Bloomberg最受欢迎的开源项目之一。
2017年,我决定回国,继续维护ReScript,并且参与了其他编程语言的开发工作,比如Facebook的Flow。可以说,我在编程语言领域已经有了十几年的经验。
MoonBit与Rust的渊源
MoonBit项目和Rust有千丝万缕的联系。Rust的第一个版本的编译器是用OCaml编写的,而我曾是OCaml的核心开发人员之一。此外,我在学生时期就认识了Rust的作者Graydon Hoare,当时他写了一篇很有名的文章《One Day Compiler》,讲述如何在一天内用一些工具快速写出一个编译器,其中用到的工具之一就是OCaml。
MoonBit的设计理念与Rust的早期版本非常接近。Rust最早的版本是带有垃圾回收机制的,但在1.0之前的某个时间点,他们移除了这个机制。MoonBit的一个目标就是在保留类似Rust的内存安全和高性能的情况下,重新引入垃圾回收。
为什么需要MoonBit?
MoonBit不仅仅是一个带有垃圾回收的Rust,它还致力于解决一些Rust的痛点,比如lifetime机制。lifetime机制虽然强大,但对很多开发者来说并不直观,尤其是当你不经常使用Rust的时候,可能会需要频繁地重新学习这一部分。
因此,MoonBit的一个目标就是移除lifetime机制,同时保持与Rust类似的性能和内存安全。我们希望通过引入一些新的内存管理技术,来简化开发者的使用体验。
WebAssembly 与 AI 集成
MoonBit不仅仅是一个编程语言,它是一个完整的平台,包含编译器、调试器、测试工具、部署工具等。我们还特别关注WebAssembly和AI的集成。
WebAssembly现在已经有两个标准,一个是不带有GC的WebAssembly 1.0,另一个是带有GC的新版标准。MoonBit同时支持这两个标准,这让我们在WebAssembly上的表现比Rust更好,尤其是在浏览器开始支持WebAssembly GC后,我们可以利用浏览器自带的GC机制,生成更小的二进制文件。
此外,MoonBit还特别关注AI的集成。当我们看到像ChatGPT这样的工具生成代码时,意识到未来很大一部分代码可能是由AI生成的。因此,我们希望构建一个对AI友好的编程语言,能够更好地进行静态分析,验证AI生成代码的正确性。
MoonBit 的开发工具链
MoonBit不仅仅是一个编译器,它包含一个完整的开发工具链,包括自己的IDE、调试器、包管理器等。我们的目标是让这一套工具能够快速、稳定地运行在浏览器上,提供优秀的用户体验。
我们还引入了多层次的IR(中间表示),并提供多个后端支持,包括WebAssembly、加速后端以及X86汇编后端。我们希望通过这些优化,让MoonBit在编译速度和生成代码的性能上都能表现出色。
性能对比
在性能方面,我们与Rust、Go等语言进行了对比。MoonBit在WebAssembly上的性能略逊于Rust,但优于Go。而在代码体积方面,MoonBit生成的二进制文件比Rust还要小一倍多。
张宏波:最后,我想说MoonBit是一个雄心勃勃的项目,我们希望它不仅仅是一个编程语言,而是一个强大的开发平台。非常感谢大家的聆听,也欢迎大家体验我们的平台!
编译时间的表现
编译时间和运行速度是我们最看重的几个指标。我们可以对比一下 Rust 和 Go 的情况。在 WebAssembly 后端上,我们的编译时间略微比 Rust 慢一点点,但这是可以接受的,因为 Rust 的速度非常快,是其核心优势之一。不过相比于 Go,我们的编译速度要快很多。大家可以自己测试,看看快了多少倍。
在体积方面,MoonBit 生成的 WebAssembly 文件比 Rust 生成的要小一半。实际上,在某些小项目中,我们的编译速度只比 Rust 快 9 倍,但在实际的项目中,MoonBit 的速度应该比 Rust 快一个数量级以上。总的来说,MoonBit 的编译速度比 Rust 要快得多。
加速后端
我们刚才提到了 MoonBit 的加速后端,这部分学习了 Rust 的许多优化模式。例如,我们也使用了全局优化。在 Rust 中,有一个著名的 Iterator,它是一个零成本抽象(zero-cost abstraction)。当你对数据进行迭代处理时,比如 .iter().map().filter().fold(),Rust 最终会将这些操作编译成一个完整的循环。
MoonBit 也是如此。我们在加速后端可以将这些迭代优化成没有额外内存分配的循环,性能几乎不逊于加速后的 Rust,甚至在某些情况下比 Rust 快 26 倍。我们通过全局优化对内存布局进行了处理,类似于 Rust。例如,如果我们有一个 char 或 Option<char> 类型的值,我们会将它编译成一个整数类型,这样就避免了内存分配。
语言设计原理
接下来,我来讲讲 MoonBit 的几个关键设计原则:
静态分析:我们设计的语言非常适合做静态分析。我们从一开始就考虑到这点,吸取了 Rust 的教训。Rust 有一个
rust-analyzer和rustc(Rust 编译器),rust-analyzer基本上重新实现了编译器的部分功能,因为它需要接受不完整或不正确的代码,并进行语义分析。而在 MoonBit 中,我们的分析工具从一开始就是容错的。如果语法不正确,我们依然可以继续解析;如果语义不正确,我们还能继续进行静态检查。因此,MoonBit 的 IDE 可以重用同一份代码,而不像 Rust 那样需要两份代码,导致同步困难。全局编译和内存布局:决定程序性能的关键更多在于内存布局,而不是后端优化。比如,在 Java 中,如果一个
ArrayList<Integer>是一个对象数组,其中每个元素都是指针,那么再怎么优化性能也不会有很大提升。我们希望通过全局优化让内存布局更加高效。比如说,如果我们有一个double[],我们就确保数组中的每个元素都是一个浮点数,而不是通过指针引用。这点和 Rust 的全局优化思路类似。此外,我们在全局优化时尽量并行处理,以减少编译时间。模块化设计:MoonBit 的编译过程非常模块化。我们有多个后端,比如加速后端、C 语言后端等。模块化设计使得我们可以快速实现新的后端。比如,我们的加速后端只花了几周时间,而 C 语言后端也只用了不到一个月。这样的设计让大量工作可以重用。
简单但不简陋:我们的目标是让语言尽可能简单,便于更多人学习和使用。相比 Go,MoonBit 的设计甚至可能更简单,但我们不会为了简化而去掉必要的特性。比如,Go 在早期版本中移除了泛型和模式匹配,而这些在 MoonBit 中是保留的。我们认为这些功能非常有用,需要留在语言中。
语言特色
接下来我来介绍一下 MoonBit 的一些语言特色。
首先,MoonBit 的数据定义和操作非常简单。熟悉 Rust 的同学会发现,我们的 enum 和 Rust 的非常相似。比如,我们可以简单地描述 JSON 数据结构,并且可以对其进行模式匹配,语法简洁且类型安全。我们还支持对 JSON 进行原生的模式匹配,并且支持嵌套和异常检查。
在 Rust 中,你可以对 slice 进行模式匹配,但不能对 Vec 进行匹配。而在 MoonBit 中,我们对 Vec 提供了类似 slice 的模式匹配功能。比如,我们可以通过模式匹配实现一个回文检查的函数。如果数组为空,返回 true;如果有一个元素,也返回 true;否则,我们可以通过模式匹配提取出中间的元素进行处理。
MoonBit 也是一种表达式导向的语言。相比 Rust,MoonBit 对表达式的支持更加极致。例如,Rust 中的 for 循环不是表达式,但在 MoonBit 中,for 循环是一个表达式。你可以通过 break 返回值,而不需要像 Python 那样使用标记位。
此外,MoonBit 的 for 循环是函数式的。也就是说,循环变量是不可变的,每次循环都会生成一个新的变量。这种纯函数式编程的方式和 C 语言的效率一样高,但更容易进行静态分析,检测出数组越界等问题。
错误处理
MoonBit 的错误处理也非常独特。Rust 使用 Result 类型来处理错误,而 MoonBit 通过静态分析来处理错误。你只需在函数签名中加一个感叹号,表示该函数可能抛出错误。与 Rust 不同的是,MoonBit 的错误处理是静态的。如果一个函数声明了错误处理但没有实际抛出任何异常,编译器会发出警告。
MoonBit 的错误处理非常高效,本质上相当于一个 goto 语句,跳转到错误处理代码。而且,错误处理是全静态的,不涉及堆分配,所有的内存分配都在栈上进行。
实例应用
最后,我来介绍一个 MoonBit 的实际应用案例。我们使用 MoonBit 开发了一个 AI 代理,并将其部署到 Web3 云端。这个代理可以帮助开发者对代码进行 AI 审核,每次提交代码时,代理会通过推送通知来提示开发者。我们使用了 WebSocket 组件,将其部署到云端,并通过标准的 WebAssembly API 与云端进行通信。
这个应用展示了 MoonBit 在数据处理方面的优势。我们可以轻松处理 JSON 数据,并通过模式匹配简化代码。在 MoonBit 中,JSON 处理是原生支持的,并且可以高效地进行静态分析。
时间线
MoonBit 项目的时间线非常紧凑。我们在 2021 年 10 月启动项目,去年正式对外发布了第一个版本。今年 3 月,我们开源了标准库,7 月开源了构建工具,前几周进入 beta 阶段。预计在今年 11 月,我们将开源编译器。
问答环节
提问:MoonBit 可以直接生成 JavaScript 代码吗?它的三个后端是什么?
回答:是的,MoonBit 支持直接生成 JavaScript 代码。我们有三个后端:WebAssembly、JavaScript 和 C 语言。如果你需要操作 DOM,可以通过 FFI 调用实现。如果你是开发工具库,则无需修改任何代码,直接导出即可。MoonBit 生成的 JavaScript 代码性能比手写的还要好。
提问:MoonBit 的定位是系统级编程语言,还是像 Go 这样的应用层编程语言?
回答:MoonBit 的定位在应用层编程语言,类似于 Java 和 Go。我们希望它能用于日常的应用开发,但在业务层面也能有很好的表现。
提问:MoonBit 的生态建设如何?是否会继承其他语言的生态?
回答:生态建设对我们来说非常重要。目前 MoonBit 已经有超过一万名用户,预计明年会达到十万用户,2025 年底可能会有一百万用户。我们非常重视包管理系统,并且已经有很多用户在帮助我们搭建生态。至于继承其他语言的生态,我们已经支持通过 WebAssembly 组件模型(component model)与其他语言进行交互,比如调用 Python 或 Rust。
提问:MoonBit 的编译速度比 Rust 快十倍,这个是指到 x86 的编译,还是到 WebAssembly?
回答:我们提到的编译速度比 Rust 快十倍,这个数字并不是高估。实际上,在某些情况下,MoonBit 的速度比 Rust 快 10 到 100 倍。Rust 的编译速度确实较慢,尤其是在大型项目中。
提问:MoonBit 的错误处理是如何实现的?它的效率如何?
回答:我们的错误处理机制是原创的,通过静态分析实现。它的效率和 C 语言的 goto 类似,错误处理跳转非常高效,堆栈分配也非常少。
提问:MoonBit 项目是如何保证持续发展的?
回答:MoonBit 不是一个个人项目,而是由一个团队开发的。我们团队有十名全职开发者,都非常年轻且有活力。我们目前不担心资金问题,项目由深圳的一个研究院支持。对我个人而言,我非常重视这个项目,并且会一直持续做下去。
主持人:时间有限,提问就先到这里。再次感谢张宏波老师的精彩分享,也感谢各位的参与。现在是 25 分钟的茶歇时间,下午 4:05 下半场正式开始。
47-深入揭秘 Rust Unstable Features起源、影响、缓解、延申-李程浩
所以我想分三个方面来看。第一个就是它是什么。我们可能用过它,但并不完全了解它到底是什么情况。这个”unstable”是什么意思?作为开发者,我们应该如何尽可能避免编译器中unstable特性的不稳定性对生产环境的业务造成影响?比如,两年后编译器出现问题时,已经无法回头解决。因此,我们首先要介绍一下背景。
Unstable Features 背景
Unstable Features 是 Rust 编译器提供的实验性功能。虽然名字叫”unstable”(不稳定),但它们在业界仍然被广泛使用。在大多数关于 Rust 安全性和可靠性的讨论中,焦点往往集中在 Rust 代码本身。然而本次议题转向 Rust 编译器,探讨其中的 Rust Unstable Features——这一被广泛使用的功能,探讨其问题及如何限制其影响。
和其他编译语言类似,Rust 编译器在早期可能不够完备,因此需要引入一些 Unstable Features。你可以告诉编译器开启这些新的功能,比如使用新的语法。这个语法可能不够健全,但通过启用不稳定特性,你可以使用这些新的功能。例如,我们熟悉的过程宏(procedural macros)最开始就是不稳定的。
但问题是,这些功能不一定会稳定下来。它们的 API 可能会变动,甚至会引发各种 bug。然而,编译器对此不负责,因为你是自愿使用它们的。
编译器中的 Unstable Features
Unstable Features 可以分为两个部分:
- Language Features:语言特性,比如新的语法、新的功能、过程宏等,这些都是由编译器提供的。
- Library Features:标准库中的特性。比如,早期 Rust 不支持
i32的锁,都是以 unstable 的形式提供的。
未来这些特性是否能够稳定下来,就要看运气了。它们可能会有 bug,甚至可能导致安全问题。举个例子,曾经有一个特性在引入态度(attitude)时出现了问题,导致编译器在稳定版本发布一周后就出 bug,爆出了一个严重的 CVE,后续不得不紧急撤销该特性。
两类问题
功能开启问题:你可以主动通过命令行参数开启这些 unstable features,但实际上,它们可能已经在代码中写好了,即使你不开启,也可能会出问题。这是一个很常见的现象。
特性生命周期问题:特性可能在某个版本中稳定了,过一段时间又被撤销。使用这些 feature 的包也就废掉了。
Unstable Features 的影响
总结起来,有三个主要影响:
- 特性废除:当某个 feature 被废除时,相关的包就无法再使用。
- API 变动:API 随时可能变动,参数、类型、并发控制等都可能不再被保证。
- 生态传递问题:由于依赖关系,整个生态都会受到影响。Rust 的 API 不稳定会导致所有 crates 都需要重新编译。如果有一个编译不过,整个编译过程就会失败。
Rust Unstable Features 的起源
Rust Unstable Features 随着编译器的演进可能会变成 stable,也可能会被移除。它们的生命周期并不遵循我们对稳定性的期望。有些特性可能从 stable 变成 unstable,甚至直接被移除,而且没有任何通知。
下面是一张图表展示了 1000 多个 Unstable Features 的生命周期。横轴代表不同版本的 Rust 编译器,从旧版本到新版本。蓝色代表 unstable,绿色代表 stable,红色代表 removed,灰色代表从未出现。纵轴代表不同版本中的状态。
Unstable Features 的生命周期
通过我们的工具分析,这些 unstable features 的生命周期非常短暂。大约 15% 的 Unstable Features 会表现出非常不稳定的行为,甚至可能在几个版本后被直接移除。
经过多年的发展,47% 的 Unstable Features 仍未稳定下来,甚至 stable 版本的特性也会出现问题。
Unstable Features 的生态影响
虽然理论上 Unstable Features 应该只被少数人使用,但实际上,Rust 生态中有 12% 的 crates 使用了 unstable features。GitHub 上 star 数最高的 100 个项目中,平均每个项目使用了 4.3 个 Unstable Features。
越大的项目,越依赖这些 Unstable Features。比如,在 Rust for Linux 项目中,我们发现了 95 个 unstable features。Android 项目中有 321 个,Firefox 中有 64 个。大型项目离不开 unstable features,这也会对安全性和稳定性造成很大的影响。
Unstable Features 的 API
我们还分析了 Unstable Features 在编译器中的 API。我们发现,编译器中有 15% 的 API 是 unstable 的,并且这个比例一直在上升。这意味着编译器中的不稳定代码越来越多,稳定下来的可能性越来越小。
Unstable Features 的修复周期
即使一个 Unstable Feature 出现问题,开发者一般也不会主动去修复它,除非编译器废除了这个 feature。即便如此,修复一个包的周期也要长达 300 天。在此期间,生态的影响会通过依赖关系不断传播。
依赖传播
依赖传播指的是 unstable features 对整个生态的影响。举个例子,在不同平台(X86 或 ARM)上,特性可能会不一样。44% 的不稳定特性会通过依赖关系传播,有 12% 的项目可能无法编译,因为 unstable features 被移除。
安全问题
Unstable Features 可能造成安全隐患。即使你使用的是 safe Rust,编译器中的不稳定行为仍然会对你的项目产生影响。例如,在开发操作系统内核时,我遇到过编译器因为不稳定特性而进行意外优化的问题,导致一些参数没有成功传递,内核在调度时出现问题。这些问题很难发现,因为每个版本的实现不一样。
总结
通过这个讨论,我并不能帮大家彻底解决问题,但希望能够让你们意识到这个问题的存在。接下来我们要讨论的是如何管理这些 Unstable Features。我们已经证明了这是一个问题,接下来要做的是如何检查并缓解这个问题。
修复这些问题非常困难。
下面是您提供的内容的整理版本,保持了原文的完整性和主要思想,确保逻辑清晰、流畅:
比如说,你开启了一个新的语法,那么你就会使用这个新的语法。当这个语法被移除时,难道你要修改所有代码吗?这非常困难。所以,你可能会选择不升级编译器,保持它的现状。但这就意味着随着时间推移,这些问题会积累。等到三四年后,当编译器出现问题时,你就会像那些大公司一样,仍然使用旧版本的操作系统或内核。比如现在,内核可能已经出到6.x或者更高版本,但你可能还在用 CentOS 7,或者更早期的 Linux 内核2.x或4.x版本。这种情况很常见,因为升级的代价太高。
但是,越往后推迟,修改就越难。因此,尽早发现问题非常重要。这也是编译器难以前进的一个重要原因。因此,我们需要检查和管理这些问题。
我们团队的尝试是什么呢?虽然这里没有具体代码,但实际上,我们写了很多代码。其中一项工作就是通过修改编译器,使其在编译过程中帮你抓取整个编译链条中所使用的 unstable features。比如在 X86 环境下,我们能够检测出你到底使用了哪些 unstable features。
我们是怎么做到的呢?我们通过 cargo 的管理,设置了一些 Rust 编译器的 wrapper 参数。当你执行 cargo build 时,首先会进入我们改造过的 Rust 编译器。这样,我们就能抓取并管理你代码中使用的不稳定特性。我们提取了编译器中的所有 unstable features 的生命周期信息,这些信息可能大家并不掌握。而我们通过这些数据,能够截获实时的编译器参数,知道你使用的 unstable features 以及它们在未来的版本中会被移除、稳定,或是发生其他变化。这样,你就可以提前预知项目在哪些编译器版本下可能无法编译。这是我们的第一个尝试:检测和告警。
第二个尝试是自动修复。这项尝试还不够完善,因为真正的 unstable features 修复往往需要开发者自己修改代码,这在实际操作中几乎不可能。我们多年开发 Rust 项目,不可能手动废除掉所有使用 unstable features 的依赖包。但有时候我们又需要继续使用这些包。我们的尝试是通过更改编译器版本来解决问题,因为我们知道哪些编译器版本中的 unstable features 是可以正常工作的,并且没有生命周期异常。我们还了解生态系统中依赖的传播方式,并能分析这些数据。这样,我们可以为你提供一个合适的编译器版本,至少可以让你继续使用,但我们认为这并不是生产环境的最终解决方案。最终,开发者还是需要自己修改代码,才能彻底解决问题。
因此,最后一步仍然要回到编译器的规范和管理上。我设想了几种可能的解决方案。这个问题实际上应该由整个生态系统来管理,而不仅仅是开发者。当前,编译器对 unstable features 没有一个统一的管理机制。从长远来看,当你上传一个包到 crates.io,或者更新了一个新的 Rust 编译器版本时,应该对生态系统中的所有 crates 进行检查。因为我们现在有技术手段,可以检测出哪些包使用了哪些 unstable features,并对整个生态进行一定的管理。
实际上,Rust 编译器本身有一个自动化的 CI/CD 流程,可以扫描 API 的变化,并检测这些变化是否对生态中的包产生破坏性影响。这是一个自动化管理的问题。我认为开发者很难做到这一点,但开发者必须意识到这个问题。Rust 项目可能并不会持续很多年,但当 unstable features 引发问题时,往往已经很难解决了。
例如,Rust for Linux 项目中,社区的态度是:到2024年或2025年,所有的 unstable features 必须被彻底移除。因为它们有特权,可以直接与编译器社区沟通,逐个废除那些特性。但普通开发者没有这样的权限。因此,我们需要更加自动化的检测工具。
这就是我今天想传达的全部内容。请大家随时提问。
观众提问:
问题1:你们通过编译器检查代码中的 unstable features 时,是只检查自己写的代码,还是也能检查依赖包中的 unstable features?
回答:可以检查依赖包的。因为我们修改的是 cargo 的 wrapper,所有经过 Rust 编译器的代码都必须经过我们的 wrapper。这样,整个编译流程中的 unstable features 都会被检查到。
问题2:你提到的告警系统是如何做到的?是通过社区的建议还是你们自己的测试?
回答:这是我们的一项尝试。虽然社区还没有真正推进类似的功能,但我们通过自己的工具证明了这一点是可行的。我们现在能够获取生态系统中的数据,知道项目的依赖关系是如何传播的,哪些代码行受到影响。这些数据让我们可以证明这条路是可行的,但最终产品还需要社区来完成。
问题3:你觉得将这个功能集成到 CLI 中,对开发者的体验是不是会更好?
回答:这是一个很好的问题,我们也在考虑这个方向。现在我们做的工作是对 Rust 编译器有侵入式的修改,但我们已经尝试将一些代码移出 Rust 编译器,集成到 cargo 的命令行工具中。这需要复用一些语法解析的代码,虽然有些难度,但确实是一个值得探索的方向。
问题4:在你理想的情况下,应该如何平衡 unstable 和 stable features 的共存?特别是考虑到开发者的惰性,代码一旦写完,如果没有出问题,开发者可能就不愿意再改了。
回答:这是一个很复杂的问题,涉及到人的因素。我们不能期望开发者总是主动去适应变化。实际上,我们已经用数据证明了,如果没有任何强制措施,开发者不会主动去修改代码。因此,社区需要统一管理,并且告知开发者可能遇到的 breaking changes。未来,我们应该有一个反向通知机制,比如当你上传一个 crate 到 crates.io 时,系统会通过邮件通知你可能的变化,就像 GitHub 会在有新的 CVE 时发邮件提醒一样。
问题5:你们检测 unstable features 时,如何确保结论的完备性?比如,如何确保你们的工具能覆盖所有可能的使用场景?
回答:这是一个非常复杂的问题。我们通过解析 cargo 中的依赖关系和代码中的条件编译语句(如 cfg 属性)来确定哪些 features 被启用了。我们可以提供两种类型的影响分析:一种是可能的影响,另一种是确定的影响。对于确定的影响,我们可以通过真实的编译环境来确定哪些 unstable features 被使用了。这两种方法结合起来,可以给出最准确的结果。
问题6:你提到可以通过某种检测机制来扫描代码,这是否可以集成到 cargo 中,作为一种扩展命令?
回答:是的,这是可以实现的。我们可以通过扩展 cargo 的命令来实现实时检查,虽然理论上的检测比较简单,但要做到实时检查,需要将代码跑一遍才能得到准确的结果。
问题7:你提到在 Rust for Linux 项目中,部分 unstable features 被拆分为多个特性。这些变化会不会提前通知开发者?
回答:实际上,很多时候这些变化并不会提前通知开发者。举个例子,有些静态分析工具在编译器 API 发生变化时会直接失效,但社区并不会主动通知你。因此,开发者需要更加关注这些变化。
48 - Rust 异步 FFI 系统—— 以 Rust2Go 为例 - 茌海
接下来让我们有请字节跳动的 Rust 高级开发工程师 —— 茌海。今天上午如果大家有看主论坛的分享,就会了解到抖音直播业务的一部分是用 Rust 重写的,而在这个过程中,就使用到了茌海讲师即将分享的 Rust2Go。现在请让我们有请茌海讲师!
开场介绍
大家好!这次我来为大家分享一下我做的一个工作。这个工作的目的是让大家能够在 Rust 中以异步的形式调用 Go。首先,我先自我介绍一下,我叫茌海,字比较难认,它念作“茌”。我毕业于复旦大学,不过读研读到一半就“跑路”了。我非常喜欢 Rust 语言,也喜欢开源,我的 GitHub 上有一些自己做的有趣的项目。后来我加入了字节跳动,现在已经在字节跳动工作了五年。目前,我主要负责内部的高性能网关方向。之前我还做过一个 Rust 的底层运维工具——Monal,不知道大家是否了解,现在知道了吧!
目前我们正在开发一个 Rust 通用网关框架,叫做 Mono Lake,预计两个月内开源。它基于 Model O,是一个高性能的网络框架,用户可以在它的基础上构建高性能的模块化服务。
Rust 异步 FFI 系统的背景
在字节跳动的 Rust 方向发展初期,我们遇到了大量的挑战。这次我要讲的主题就是异步 FFI 系统。首先,我们来讨论一下跨语言通信的方案。如果不使用 FFI,还有哪些方式可以实现跨语言调用呢?这里列了三种方案。
方案一:跨线程通信
第一种方案是基于跨线程通信的手段,在同一个进程中实现跨语言调用。虽然我们在同一个进程中,但可以借助跨进程的手段来实现调用。具体做法是,将调用请求和参数序列化,通过 socket 发送给对端。其实,这就是一种 RPC(远程过程调用)方式。这种方法的开销主要体现在序列化和反序列化上,因为这些过程涉及到数据拷贝,并且还会引入系统调用(syscall)。
方案二:共享内存通信
第二种方式是借助跨线程通信的手段,比如 Rust 端和 Go 端共享内存。Rust 端可以将请求和参数打包到 Buffer 中,通过某种方式传递给 Go,Go 端直接读取 Buffer 中的数据。这种方式减少了一次数据拷贝,但仍然需要精细的内存管理。
方案三:FFI
第三种方式就是今天重点介绍的 FFI(外部函数接口)。FFI 的优势在于它不需要对参数或返回值进行序列化和反序列化,从而减少了开销。然而,FFI 也有它的代价,比如需要确保内存布局对齐。Rust 和 Go 中的同一个结构体在内存中的表现形式可能完全不同,因此需要约定统一的内存表示。
另一个好处是,FFI 调用可以在同一个线程中执行,比如 Rust 直接调用 Go 的代码,执行完毕后直接返回,不涉及跨线程。然而,是否跨线程的讨论稍后会深入。
如何在 Rust 中使用 FFI 调用 Go
实现一个简单的 FFI 调用其实很容易。下面是一个简单的例子,我们可以看到在 Rust 中调用 Go 的代码。首先,在 Go 中,我们需要定义一个函数,并使用 //export 声明将其暴露出来。接下来,通过特定的编译方式将 Go 代码编译为可链接的目标文件。
然后,在 Rust 中,通过 extern "C" 声明该函数的外部链接,就可以直接调用了。而在 build.rs 文件中,我们可以使用 go build 命令生成目标文件,并告诉 Cargo 如何链接这些文件。最终,Rust 和 Go 的代码就可以无缝地协同工作了。
FFI 的挑战
虽然 FFI 的实现看似简单,但在面对复杂需求时,仍然会遇到许多挑战。比如,如何传递复杂类型的参数和返回值?如何支持异步调用?如何处理内存安全问题?接下来,我会逐个讨论这些问题。
参数和返回值的传递
首先,当传递基础类型参数(如数字或布尔值)时,直接传递即可,按照 C ABI 的约定放置参数即可,这很简单。然而,当传递字符串时,情况就变得复杂了。我们可以有两种方式:序列化或者引用传递。
- 序列化方式:先写入字符串的长度,再写入对应的数据。这个方式虽然简单,但效率低,尤其是当字符串很长时。
- 引用传递方式:可以通过指针加长度的方式传递字符串,这种方式效率更高,但需要妥善管理指针的生命周期。
生命周期管理
接下来是生命周期管理的问题。当 Rust 调用 Go 时,参数的生命周期该如何管理?显然,当 Go 端调用结束后,参数可以被释放。但返回值的生命周期该如何处理呢?Go 生成的返回值指针不能直接返回给 Rust,因为一旦返回,Go 端的变量可能会被垃圾回收(GC),Rust 再访问这个指针就会导致崩溃。
为了解决这个问题,我们引入了一个机制:在 Rust 调用 Go 的 FFI 过程中,Go 执行完毕后,会再次调用 Rust 的 FFI 完成返回值的处理。这样,Rust 端可以在 Go 调用结束后安全地管理返回值,避免内存问题。
异步调用
在讨论异步调用时,首先我们要明确问题所在。比如,当 Rust 调用 Go 时,Go 端可能包含一个耗时操作(如 HTTP GET 请求),可能需要等待 10 秒钟。那么在这段时间内,Rust 的线程就会被阻塞,完全浪费了线程资源。
在异步运行时(如 Tokio)中,这个问题会更加严重。如果 Tokio 中的某个线程被 FFI 调用阻塞,那么这个线程上的所有任务都会受到影响,导致严重的延迟。因此,我们需要确保 FFI 调用不会占用线程资源。
为了解决这个问题,我们可以将 FFI 调用设计成一个纯粹的发起动作,线程执行权能够及时归还运行时,避免阻塞。通过这种方式,FFI 调用可以在异步环境中高效运行。
结语
FFI 的实现虽然简单,但在面对复杂场景时仍然充满挑战。通过合理的生命周期管理和异步设计,我们可以在 Rust 和 Go 之间无缝地进行跨语言调用,实现高效的异步通信。
48 - Rust 异步 FFI 系统—— 以 Rust2Go 为例 - 茌海
接下来让我们有请字节跳动的 Rust 高级开发工程师 —— 茌海。今天上午如果大家有看主论坛的分享,就会了解到抖音直播业务的一部分是用 Rust 重写的,而在这个过程中,就使用到了茌海讲师即将分享的 Rust2Go。现在请让我们有请茌海讲师!
开场介绍
大家好!这次我来为大家分享一下我做的一个工作。这个工作的目的是让大家能够在 Rust 中以异步的形式调用 Go。首先,我先自我介绍一下,我叫茌海,字比较难认,它念作“茌”。我毕业于复旦大学,不过读研读到一半就“跑路”了。我非常喜欢 Rust 语言,也喜欢开源,我的 GitHub 上有一些自己做的有趣的项目。后来我加入了字节跳动,现在已经在字节跳动工作了五年。目前,我主要负责内部的高性能网关方向。之前我还做过一个 Rust 的底层运维工具——Monal,不知道大家是否了解,现在知道了吧!
目前我们正在开发一个 Rust 通用网关框架,叫做 Mono Lake,预计两个月内开源。它基于 Model O,是一个高性能的网络框架,用户可以在它的基础上构建高性能的模块化服务。
Rust 异步 FFI 系统的背景
在字节跳动的 Rust 方向发展初期,我们遇到了大量的挑战。这次我要讲的主题就是异步 FFI 系统。首先,我们来讨论一下跨语言通信的方案。如果不使用 FFI,还有哪些方式可以实现跨语言调用呢?这里列了三种方案。
方案一:跨线程通信
第一种方案是基于跨线程通信的手段,在同一个进程中实现跨语言调用。虽然我们在同一个进程中,但可以借助跨进程的手段来实现调用。具体做法是,将调用请求和参数序列化,通过 socket 发送给对端。其实,这就是一种 RPC(远程过程调用)方式。这种方法的开销主要体现在序列化和反序列化上,因为这些过程涉及到数据拷贝,并且还会引入系统调用(syscall)。
方案二:共享内存通信
第二种方式是借助跨线程通信的手段,比如 Rust 端和 Go 端共享内存。Rust 端可以将请求和参数打包到 Buffer 中,通过某种方式传递给 Go,Go 端直接读取 Buffer 中的数据。这种方式减少了一次数据拷贝,但仍然需要精细的内存管理。
方案三:FFI
第三种方式就是今天重点介绍的 FFI(外部函数接口)。FFI 的优势在于它不需要对参数或返回值进行序列化和反序列化,从而减少了开销。然而,FFI 也有它的代价,比如需要确保内存布局对齐。Rust 和 Go 中的同一个结构体在内存中的表现形式可能完全不同,因此需要约定统一的内存表示。
另一个好处是,FFI 调用可以在同一个线程中执行,比如 Rust 直接调用 Go 的代码,执行完毕后直接返回,不涉及跨线程。然而,是否跨线程的讨论稍后会深入。
如何在 Rust 中使用 FFI 调用 Go
实现一个简单的 FFI 调用其实很容易。下面是一个简单的例子,我们可以看到在 Rust 中调用 Go 的代码。首先,在 Go 中,我们需要定义一个函数,并使用 //export 声明将其暴露出来。接下来,通过特定的编译方式将 Go 代码编译为可链接的目标文件。
然后,在 Rust 中,通过 extern "C" 声明该函数的外部链接,就可以直接调用了。而在 build.rs 文件中,我们可以使用 go build 命令生成目标文件,并告诉 Cargo 如何链接这些文件。最终,Rust 和 Go 的代码就可以无缝地协同工作了。
FFI 的挑战
虽然 FFI 的实现看似简单,但在面对复杂需求时,仍然会遇到许多挑战。比如,如何传递复杂类型的参数和返回值?如何支持异步调用?如何处理内存安全问题?接下来,我会逐个讨论这些问题。
参数和返回值的传递
首先,当传递基础类型参数(如数字或布尔值)时,直接传递即可,按照 C ABI 的约定放置参数即可,这很简单。然而,当传递字符串时,情况就变得复杂了。我们可以有两种方式:序列化或者引用传递。
- 序列化方式:先写入字符串的长度,再写入对应的数据。这个方式虽然简单,但效率低,尤其是当字符串很长时。
- 引用传递方式:可以通过指针加长度的方式传递字符串,这种方式效率更高,但需要妥善管理指针的生命周期。
生命周期管理
接下来是生命周期管理的问题。当 Rust 调用 Go 时,参数的生命周期该如何管理?显然,当 Go 端调用结束后,参数可以被释放。但返回值的生命周期该如何处理呢?Go 生成的返回值指针不能直接返回给 Rust,因为一旦返回,Go 端的变量可能会被垃圾回收(GC),Rust 再访问这个指针就会导致崩溃。
为了解决这个问题,我们引入了一个机制:在 Rust 调用 Go 的 FFI 过程中,Go 执行完毕后,会再次调用 Rust 的 FFI 完成返回值的处理。这样,Rust 端可以在 Go 调用结束后安全地管理返回值,避免内存问题。
异步调用
在讨论异步调用时,首先我们要明确问题所在。比如,当 Rust 调用 Go 时,Go 端可能包含一个耗时操作(如 HTTP GET 请求),可能需要等待 10 秒钟。那么在这段时间内,Rust 的线程就会被阻塞,完全浪费了线程资源。
在异步运行时(如 Tokio)中,这个问题会更加严重。如果 Tokio 中的某个线程被 FFI 调用阻塞,那么这个线程上的所有任务都会受到影响,导致严重的延迟。因此,我们需要确保 FFI 调用不会占用线程资源。
为了解决这个问题,我们可以将 FFI 调用设计成一个纯粹的发起动作,线程执行权能够及时归还运行时,避免阻塞。通过这种方式,FFI 调用可以在异步环境中高效运行。
第二部分 - 异步 FFI 的实现与问题
因为这时候你就不得不等待其他的 worker 来救你,当所有的 worker 都被你耗尽的时候,谁都救不了了。这时候所有的任务延迟都会爆炸。所以说我们一定要让它能够在发起 FFI 之后,不要占用线程,把线程的执行权要回来。
那么这时候其实 FFI 就变成了一个纯发起动作,我们就需要一个 bolt,有点像是 post task 的语义行为。在 Go 里面,这个行为很简单,就是大家所熟知的 go 关键字。例如,当我们执行一个函数时,我可能需要等待它返回,但如果我们希望它在后台执行,只需要在前面加上 go,这个问题就解决了。
这里的发起 FFI 并立刻结束,意味着我们将原本执行的函数勾出去执行就好了。这时候执行流就变成了:发起 FFI,立刻结束,Go 执行,执行完之后,Go 再调 set_result_ffi,去设置 Rust 这边的一个 slot(槽),随后触发 task 的 wakeup,这时候就可以安全地返回了。Rust 这边的 task 被 wakeup,于是类似 .await 的逻辑就会返回,这样就完成了一个正常的调用。
Go 的实现方法其实就是这样,把原来的函数包一层就好了。但是在这个过程中,当我们把同步改成异步,会引入一些问题。
问题一:Future 提前释放
如果 Future 被提前释放了怎么办?例如,如果 Future 提前被释放,那么我的参数也可能被 drop。这时 Go 端还在使用这个参数,因为它抓的是 Rust 这边的引用,这样就会崩溃。所以我们需要确保生命周期是 OK 的。
问题二:Result Slot 的并发读写
第二个问题是,Rust 这边会去尝试读 result slot,Go 这边会去写 result slot。之前是同步调用,不存在并发问题,但现在是异步调用,两边都有执行权,可能会导致内存同时被读写。因此,我们需要确保内存的并发安全。
我的解决办法是使用 Atomic 来表示状态,并通过 CAS(Compare-And-Swap)来确保内存安全。
问题三:复杂类型的传递
第三个问题是复杂类型的传递。传递 U8 和 bool 没有问题,但传递 string 会更复杂。简单情况下,传递指针和长度就好了,但如果传递的是 Vec
为了解决这个问题,我提出了一种新的抽象,将内存类型分为三种:primitive、simple wrapper 和 complex。对于 complex 类型,在完成转换时需要 buffer,这有点像序列化,但实际上还是引用了大部分数据。
当我们完成 Vec
这些结构都是 C 内存布局的,用 #[repr(C)] 标记,因此 Go 端可以理解。
内存安全
当我们定义 trait 时,前几个调用是异步调用,传递的是引用,后面两个调用传递的是所有权。如果传递所有权,我们可以将参数放在堆上,通过引用计数来管理它们。
但如果传递的是引用类型的参数,Rust 端可以提前 drop future 和参数,这会导致 Go 端访问异常。为了解决这个问题,我们只能将这种引用类型暴露为 unsafe。
框架实现
为了让大家更直观地理解,我展示了框架的最终效果。使用起来非常简单:
- 定义参数和返回值时,使用过程宏自动生成参数和引用结构的互转实现。
- 定义调用的方法时,支持同步和异步调用。如果是异步调用,简单地实现
impl Future即可。过程宏会自动为你生成实现。 - Go 端的代码可以通过 CI 工具根据 Rust 代码自动生成,只需要将生成的代码拷贝到 Go 项目中。
- 在 Rust 侧添加
build.rs,完成代码生成后,直接运行即可。
这样就可以在 Rust 中自由地使用这些调用,尤其是异步调用时,可以直接 await。
这是第二部分的整理,确保所有内容清晰、完整且通顺。
49-简单高效的 Web 后端框架 SALVO-杨学成
https://www.bilibili.com/video/BV1nwshegEwu/
我们还有最后一场分享,大家千万不要走啊。接下来让我们有请 Salvo 框架的作者杨学成,来为我们分享简单高效的 Web 后端框架 Salvo。这个框架在社区应该也蛮有名的,欢迎大家鼓掌欢迎杨老师。
大家好,我是 Salvo 的作者杨学成,可能很多人在 QQ 或者微信群里面经常见到我。我经常在里面收集大家的各种反馈,然后对框架进行改进。这个框架其实是我在 2019 年开始开发的。那个时候我之前是用 Node.js,但在使用过程中遇到了一些问题,比如说用 Node.js 重构时感觉像是噩梦——变量名忘记改了,可能会出现各种问题。后来我转向 Go,但也遇到了一些问题,包括包管理问题。当时我用了一个叫 GOM 的工具,曾经差点让我删库跑路,因为它有个问题:如果你误删了一个表,整个数据库的数据都可能被清空。当时吓得我不轻。
后来我发现了 Rust 语言。Rust 是一种非常安全的语言,效率高,并发性能也很好。对于我们做 Web 后端框架来说,这种语言非常适合。Web 后端需要的特性 Rust 都具备。那时 Rust 的 Web 框架还不多,我只知道一个叫 Rocket 的框架。我自己当时学 Rust 其实水平很菜,像张汉东老师的那本书《Rust 程序设计》我都没看完,官方的 Rust Book 也没看完,甚至《Rust 编程之道》也没看完。就在这种情况下,我开始边学边做,从 BGO 的一些代码包入手,把它们改成 Rust 写的框架。
Salvo 是基于 Hyper 和 Tokio 构建的,和其他主流框架比如 Axum 等是类似的。但我们主打的是人性化。我认为很多 Rust 框架现在走的方向是追求性能,比如 Hyper 的作者最近做了另一个高性能框架,但我觉得 Rust 本身已经是一个高性能语言了,更重要的是易用性。很多框架对新手不友好,很难上手。我做 Salvo 的一个很大的原因是,我学不会其他框架,像 Axum 等对我来说太难用了。
我们的框架已经维护了将近 5 年。我们一直在吸收新的特性,比如我们已经支持 HTTP/3,其他框架基本上还没集成这个功能。我们也支持 WebTransport,还有像从 Let’s Encrypt 自动获取和更新 HTTPS 证书的功能。我们整个项目的维护非常活跃。有人曾经同时向多个框架提交过同样的 issue,比如一个问题是 SS1 和 compress 中间件一起使用时会导致数据不会立即返回,而是突然一下子返回很多数据。我们当时很快就解决了这个问题,但我不确定其他框架是否解决了。
我们的社群也很活跃。微信群现在有 400 多人,QQ群是今年暑假才建的,也有 100 多人。SAF 这个云平台很早就支持部署 Rust 的 Web 应用,并且在 2023 年我们还获得了 DT 的 GVP 这个项目的支持。
接下来我讲一些 Salvo 框架的特色功能。首先是路由系统,我们的路由系统是一个链式的图形结构,整个路由是嵌套的,不需要声明变量。其他框架可能会有 group 或者 nest 这样的函数,但我们没有。你只需要不停地往里面 push,形成一个树状结构。像 path、host、method 这些东西在我们这里被抽象为 filter。所以对于一个路由节点,路径并不是必须的。你可以只定义 host,然后往里面添加路由节点,这样就能很方便地实现类似 Nginx 的虚拟主机效果。
另外,我们的路由系统允许在任意位置通过 hoop 方法添加中间件,这些中间件会影响它以及所有子路由。比如你可以把需要用户验证的路由放在带有验证中间件的路由节点下,不需要验证的路由则可以放在其他节点下。这样,你的路由结构更具灵活性。
我们的路由匹配支持更多的方式。你可以自己定义匹配规则,比如身份证号码的验证规则,并把它添加进来,这样你在需要的地方可以直接使用。我们也支持自定义 filter,你可以把它添加到路由中。
这是一个简单的中间件示例,代码非常简单,大家只要学过编程应该都能看得懂。你不会看到泛型、关联类型或者生命周期的概念。我觉得只要你学过代码都能理解。
这个中间件实现了一个简单的功能:检测请求的体积。如果请求体积超过一定大小,就会返回一个错误响应。代码中,我们首先定义了一个结构体 BodyLimit,里面包含限制的大小。然后我们实现了 handle 方法,handle 方法接受一个请求对象 Request,处理过程中我们检查请求体积是否超过限制,如果超过就返回错误,并中止后续处理。
相比之下,大家可以去看 Axum 的类似功能实现,你会发现它定义了很多层次的 layer,还需要实现 Future,对新手来说非常难。
接下来讲一下数据提取器(extractor)。Salvo 的数据提取器可能与其他框架不太一样。我们的核心思想是:将请求中的所有数据(包括请求头、URL、查询字符串、表单数据、JSON 数据等)都当作数据源,然后通过类似 Serde 的反序列化方法,把它们填充到你期望的类型中。比如我们定义一个 User 结构体,id 是从路径参数中获取,username 可以从表单数据中获取,而 pet_id 是从查询字符串中获取。
值得注意的是,pet_id 是一个 u32 数组类型。查询字符串传进来的数据默认是字符串,但我们会自动将其转换为数组。如果你只需要单个值,也可以定义为 u32,它会自动取第一个值。
定义好数据结构后,你可以直接在处理函数中将其作为参数传入。我们上面提到的 handle 方法就是一个例子。
好的,我会按照您的要求,原原本本地整理内容,确保其合理通顺,并且不会遗漏任何信息。以下是整理后的版本:
那么这个时候,你可能定义了一个 u32,第一个值会起作用,并且会自动复制进去。比如说,如果你在这个地方定义的是 String,那也没有问题,它同样可以自动复制。这整个过程我称之为自然的赋值过程。
这个数据结构定义好了之后,你可以看到在下面的代码中,你可以直接把它作为函数的参数传进去。也就是说,上面我们加了一个 handle 宏,它会识别你传入的变量,这个变量可能就是从提取器中获取的。于是,它会自动帮你完成提取过程并传递给函数,你就可以在函数中直接使用它。
这个宏非常智能。比如说,上面的 handle 实现中包含了多个参数,但这个宏允许你省略掉不需要的参数。你只需要写出函数中需要的参数,其他不需要的参数可以省略,它会自动补全。在这个示例中,后面的参数都不需要,所以我们可以不写,它会自动完成。
接下来是我们去年才加入的 OpenAPI 支持。我认为相比其他框架,我们的实现是最好的。像 Axum 这些框架,它们主张不用宏,对于不使用宏的实现而言,这实际上是非常困难的。我看到过 Hyper 的作者曾经尝试为 OpenAPI 做一个分支,试图支持它,但最后还是删掉了。他们依赖于社区开发的 utoipa,而且需要大量的注释。
我们的实现也是从 utoipa 集成进来的,但集成度更高,因为我们不需要为函数参数和返回信息添加注释。系统会自动识别,比如 User 是怎么来的,自动为你生成文档。我们的文档生成机制非常灵活,它直接从代码扫描所有的 endpoint。我们有一个和 handle 类似的宏,能够自动扫描到所有的 endpoint 及其相关信息,然后生成文档。只有使用到的类型才会被放入 OpenAPI 文档中。
我们支持多种主流的 OpenAPI 文档显示界面,比如官方的 SwaggerUI,以及一个我认为非常酷炫的新界面 Redoc。我们的框架非常灵活,即使你有一个非常大的项目,你也可以逐步地为部分代码增加 OpenAPI 支持。你只需要为需要支持的部分使用 OpenAPI 的写法,不需要支持的部分仍然可以保持原来的写法,这样它们就不会被扫描到文档中。
接着是一个非常简单的 OpenAPI 示例。我们把 handle 换成了 endpoint,这里 name 是从查询字符串里获取的,并且它是可选的。第二个参数 false 表示 name 不是必须的,因此它可以为空。如果这个 endpoint 存在,它会自动扫描并提取数据。
然后我们来看如何把它变成一个界面。我们声明了一个叫 OpenAPI 的文档对象,把上面定义的 root 扫描的结果传递进去,系统会自动扫描这些信息,并把生成的文档变成 root,再添加一个界面,设置文档的路径。这样你就可以看到一个专业的 OpenAPI 文档界面了。
今天我大概准备了这些内容,没有特别多的东西。总体来说,我们的框架相比 Axum 要简单得多。Axum 的中间件部分用到了很多泛型和关联类型,导致它的实现非常复杂,不仅是计算量大,错误处理也很麻烦。今天我没有详细讲错误处理的部分,但你可以看到,我们的处理方式更加优雅。更详细的内容可以在我们官网的文档中找到。
现在大家可能更多地使用 Axum,但有些人觉得 Axum 好用。如果你是大佬,可能觉得花点时间也能搞定,没问题。但即便你是大佬,你也不可能每次写中间件都发大招,对吧?这样会对身体不好,脑袋和头发都会受影响。你看看张老师翻书的时候就知道了。所以我觉得,如果能用简单的方法解决问题,就没有必要选择复杂的方式。
关于性能,可能有人会关心。实际上,在 Benchmark 跑分中,我们的性能与其他框架,比如 Axum 基本相当,没有明显差距。唯一一项跑分是 plaintext 的分数比较低,但我也不确定具体原因。其他有负载的测试中,我们的性能并不比其他框架低,基本上处于同一水平。但在易用性上,我们比其他框架强很多。官方支持的中间件功能和数量也比 Axum 多得多。
使用 Axum 的人应该知道,Axum 本身没有官方支持的中间件。它的路由使用了 tower,中间件也是用 tower 实现的,更多是数据解析和一些宏的写法。有人可能觉得这些宏看起来有点魔法的感觉。
今天我大概讲这么多,大家有什么问题可以问。
提问环节:
提问者 1: 杨老师您好,我想问一下入参那边有没有一些校验的方式?
杨学成: 校验的话,目前没有做这个验证方面的功能。验证我本来是想做的,但后来想,验证其实就是一句话,比如 validate,只是你进来之后进行验证。所以我考虑更多的是错误处理的问题。我们的 server 其实是可以完全自定义的,没有任何限制。包括错误处理、错误页面,你都可以完全控制。所以 validate 之后的错误处理并不是问题,暂时我没有去支持这个功能。
提问者 2: 老师好,我记得你这个框架我以前体验过一下,不过我做 Go 语言比较多,Rust 只是看了看。我对比过 Go 的一些框架,发现它们有类似 AOP(面向切面编程)的设计,比如执行时有前置、后置的拦截器。Rust 不支持反射,这个在 Rust 中好做吗?
杨学成: AOP 确实是 Java 的一个常见思想,像 Spring 这些框架大量使用 AOP。但我个人认为,现在的流行趋势已经不是这种大框架的方向了。我们不会内置 ORM,因为 ORM 不仅仅是 Web 开发需要,几乎所有软件开发都会使用它。所以我们不会内置这些东西。
Rust 的设计理念不同于 Java,它鼓励你自己搭建积木,而不是提供一个大而全的模板,让你只需填充一些业务代码。Rust 的框架更偏向于灵活的组件组合,而不是一整套封装好的解决方案。
关于模板引擎的支持,每个人的需求和喜好都不同。模板渲染最终只是生成字符串,所以我们不会限制你使用哪种技术。我们会提供一些例子,但不会强制你使用某种方案。
如果没有其他问题的话,再次感谢杨老师的分享,也希望大家继续关注 Salvo 框架的发展。我们今天的大会到此正式结束,感谢大家的坚持!
原文链接: https://dashen.tech/2018/09/23/RustConf2024学习记录/
版权声明: 转载请注明出处.