sort.Search()
sort.Search() 提交于遥远的2010年11月11日,提交者是Go三位创始人之一的Robert Griesemer, 随Go第一个正式版本一起发布
从这个意义上说,是标准库元老级的函数了~
sort.Search() 用于在排序的切片或数组中查找元素
1 | // Search uses binary search to find and return the smallest index i |
这段代码是一个实现了二分查找算法的函数,名为 Search。这个函数用于在一个有序的范围内寻找满足特定条件的最小索引 i。以下是对这个函数的详细解释:
函数定义:
Search(n int, f func(int) bool) int定义了一个名为Search的函数,接收两个参数:一个整数n和一个函数f。n定义了搜索范围的大小(从 0 到n,不包括n),而f是一个接受整数输入并返回布尔值的函数。Search函数返回一个整数,表示满足f条件的最小索引。条件函数
f:f函数定义了查找的条件。对于索引i,如果f(i)为真,则对于所有j > i,f(j)也应为真。这意味着f在某点之前为假,之后变为真。Search函数查找的是这个转变发生的点。二分查找逻辑:
- 初始化两个指针
i和j,分别代表搜索范围的开始和结束。开始时,i为 0,j为n。 - 在
i < j的条件下循环执行。计算中点h,并判断f(h)的值。 - 如果
f(h)为假(false),则说明满足条件的索引在h的右侧,将i设置为h + 1。 - 如果
f(h)为真(true),则说明满足条件的索引可能是h或在h的左侧,将j设置为h。 - 这个过程不断缩小搜索范围,直到找到转变点,即
f(i-1)为假而f(i)为真的位置。
- 初始化两个指针
结果返回:当
i与j相遇时,i就是满足f(i)为真的最小索引。如果整个范围内没有找到满足条件的索引,则返回n。
这个 Search 函数的一个常见用途是在有序数组或切片中查找一个元素或查找满足某个条件的元素的插入点。例如,如果你有一个按升序排序的数组,并想要找到第一个大于等于某个值 x 的元素的索引,你可以将 x 的值和数组索引作为条件传递给 f 函数,并使用 Search 函数来查找。
这种类型的二分查找算法非常高效,时间复杂度为 O(log n),适用于大型数据集合。二分查找不仅可以用于查找元素,还可以用于确定元素的插入位置,以保持数据的有序性。
会在一个已排序的切片中进行二分查找(因此比线性搜索要快得多,尤其是在处理大型数据集时性能尤其明显), 最后返回一个索引,这个索引指向切片中第一个不小于指定值的元素。如果没有找到符合条件的元素,则返回的索引等于切片的长度。
使用时首先需要确保切片或数组已经是排序过的。其次需提供一个函数,这个函数定义了怎样判断切片中的元素是否满足自定义的查找条件。
如下,假设有一个整数切片,已经按升序排序,想找到第一个不小于某个给定值的元素的位置。
1 | package main |
输出:
1 | 找到了不小于 5 的元素,索引为 3,值为 6 |
上面代码中,sort.Search() 用于在 numbers 切片中查找第一个不小于 5 的元素。由于 4 后面的元素是 6,所以函数返回 6 的索引,即 3。
更多例子:
Go语言中sort.Search()的使用方法(数组中通过值来取索引)
golang 中sort包sort.search()使用教程
sort.Find()
而sort.Find() 则首次提交于2022年3月30日, 随2022年8月2号发布的Go 1.19一起发布
1 | // Find uses binary search to find and return the smallest index i in [0, n) |
这段代码是一个实现二分查找的算法函数,名为 Find。它的目的是在一个满足特定条件的有序集合中查找一个元素,并返回该元素的索引和一个布尔值,表示是否找到了该元素。以下是对该函数及其组成部分的详细解释:
函数定义:
Find(n int, cmp func(int) int) (i int, found bool)定义了一个名为Find的函数,它接受一个整数n和一个比较函数cmp作为参数。n表示搜索范围的大小,而cmp是一个用于比较元素的函数。函数返回两个值:i(找到的元素的索引)和found(一个布尔值,表示是否找到了元素)。比较函数
cmp:这个函数接受一个整数索引作为输入,并返回一个整数。返回值的意义是基于目标值t与索引i处元素的比较:如果t小于元素,则返回小于 0 的值;如果t等于元素,则返回 0;如果t大于元素,则返回大于 0 的值。二分查找逻辑:
- 初始化两个指针
i和j,分别指向搜索范围的开始和结束。i初始化为 0,j初始化为n。 - 循环执行,直到
i不小于j。在每次迭代中,计算中点h,并使用cmp函数比较中点处的元素。 - 如果
cmp(h)的结果大于 0,说明目标值t在中点的右侧,因此将i更新为h + 1。 - 如果
cmp(h)的结果不大于 0,说明目标值t在中点或中点的左侧,因此将j更新为h。 - 这个过程不断缩小搜索范围,直到
i和j相遇。
- 初始化两个指针
结果返回:当循环结束时,
i和j相等。这时,如果i小于n且cmp(i)等于 0,则说明找到了目标元素,函数返回i和found为true。否则,表示没有找到目标元素,函数返回i(此时i表示目标值应该插入的位置,以保持序列的有序性)和found为false。
这段代码的实用性在于,它不仅能够用于查找元素,还能够通过返回的索引 i 提供有关元素应该插入的位置的信息,这对于维护有序集合非常有用。二分查找的效率很高,时间复杂度为 O(log n),适用于大型数据集合的查找操作。
Find uses binary search to find and return the smallest index i in [0, n) at which cmp(i) <= 0. If there is no such index i, Find returns i = n. The found result is true if i < n and cmp(i) == 0. Find calls cmp(i) only for i in the range [0, n).
To permit binary search, Find requires that cmp(i) > 0 for a leading prefix of the range, cmp(i) == 0 in the middle, and cmp(i) < 0 for the final suffix of the range. (Each subrange could be empty.) The usual way to establish this condition is to interpret cmp(i) as a comparison of a desired target value t against entry i in an underlying indexed data structure x, returning <0, 0, and >0 when t < x[i], t == x[i], and t > x[i], respectively.
Find 使用二分查找来查找并返回 [0, n) 中 cmp(i) <= 0 的最小索引 i。如果不存在这样的索引 i,Find 将返回 i = n。 如果 i < n 且 cmp(i) == 0,则找到的结果为 true。Find 仅针对 [0, n) 范围内的 i 调用 cmp(i)。
为了允许二分搜索,Find 要求 cmp(i) > 0 作为范围的前导前缀,cmp(i) == 0 在中间,cmp(i) < 0 作为范围的最后后缀。 (每个子范围可以为空。)建立此条件的常用方法是将 cmp(i) 解释为所需目标值 t 与基础索引数据结构 x 中的条目 i 的比较,返回 <0、0 和 > 当 t < x[i]、t == x[i] 和 t > x[i] 时,分别为 0。
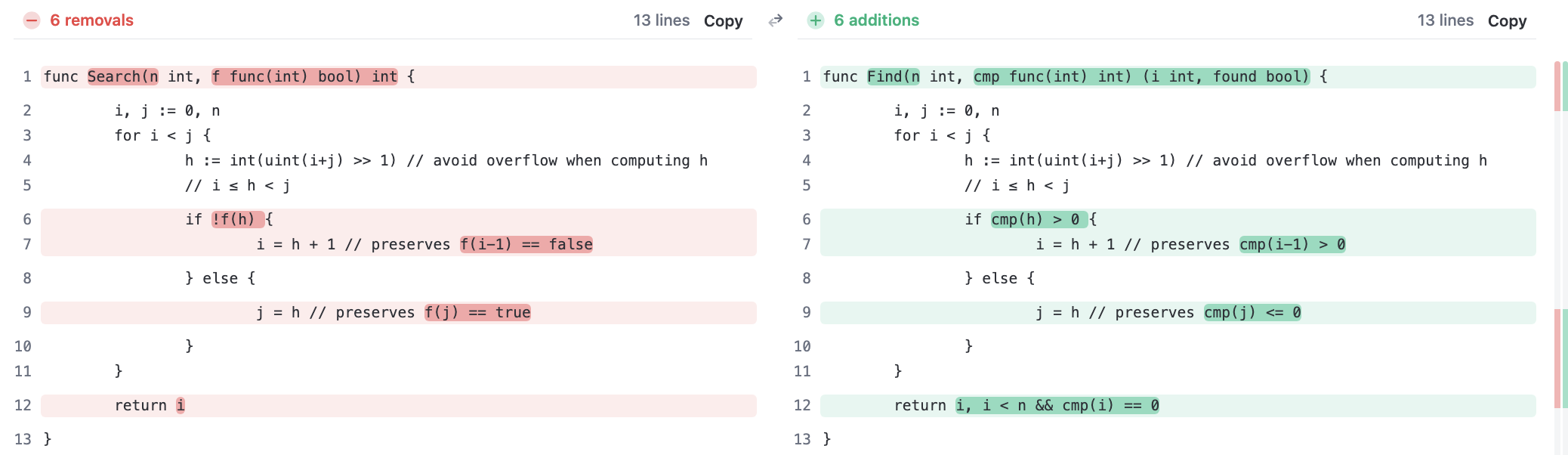
二者实现非常相近,都有用二分搜索
Find的第二个入参,也是一个func,但要求这个func的返回值是int而不是bool.另外Find的返回值有两个,第二个返回值是bool,代表没有找到指定元素
sort.Find() 看起来和sort.Search()很像,为什么有了Search还需要Find?二者有什么不同?
回溯一下Find的历史, 提案sort: add Find #50340是Go三位创始人之一的另一位Rob Pike提出
从讨论中:
It sounds like we agree that sort.Search is hard to use, but there’s not an obvious replacement. In particular, anything that can report an exact position has to take a different function (a 3-way result like strings.Compare, or multiple functions).
“听起来我们都同意 sort.Search 很难使用,但没有明显的替代品。 特别是,任何可以报告精确位置的东西都必须采用不同的函数(3 路结果,如 strings.Compare 或多个函数)”
slices: add Sort, SortStable, IsSorted, BinarySearch, and func variants #47619
The difference between Search and Find in all cases would be that Find returns -1 when the element is not present,whereas Search returns the index in the slice where it would be inserted.
“在所有情况下,Search 和 Find 之间的区别在于,当元素不存在时,Find 返回 -1,而 Search 返回要插入元素的切片中的索引”
之所以Search大家感觉不够好用,是因为 如果要查找的元素没在slice里面,Search会返回要插入元素的切片中的索引(并不一定是slice的长度,只有当元素比切片最后一个元素还大时,此时返回值才正好等于切片长度),而绝对不是-1, 这样就没法判断某个元素是否在切片中, 可看下面的例子:
1 | package main |
正如Rob Pike所说,他想用sort.Search来做搜索,判断某个元素是否在(已排序的)切片中,但实际上,如target2的6, sort.Search()得到结果4, 是说如果把这个元素插入这个有序切片,需要插入在data[4]这个位置,并不一定是说data[4]=6
即通过sort.Search无法直接判断某个元素是否在切片中,还需要补一个 data[index]和target是否相等的判断
而Find则不然,
1 | package main |
输出:
1 | found e at entry 1 |
即 不光返回了应该插入到哪个位置,还把目标元素是否在切片中也返回了~
目前sort.Frid()没有example,可以把上面这段代码提交上去..
一定程度上,Find似乎放在slices包更合适:
https://github.com/golang/go/issues/50340#issuecomment-1034071670
https://github.com/golang/go/issues/50340#issuecomment-1034341823
我同意将 sort 和 slices 包的接口解耦。前者适用于抽象索引,而后者适用于实际切片
sort.Find 和 slices.BinarySearchFunc
其实,我觉得很大程度,是因为slices.Contains性能不够好(调用了slices.Index,即遍历检测), 而用sort.Find前提是一个已排序的切片,即可以用二分查找,肯定比用现在的slices.Contains暴力遍历要好
但其实,Contains不需要知道index,只需要知道在不在,有没有…可以考虑用map,虽然map的创建等需要一定的开销,但是对于元素数量非常多的case,hash查找的O(1)的优势就体现出来了~而且不需要切片的有序的
我应该提一个提案,来优化现有的slices.Contains
原文链接: https://dashen.tech/2020/05/29/Go-sort-Search-和sort-Find/
版权声明: 转载请注明出处.