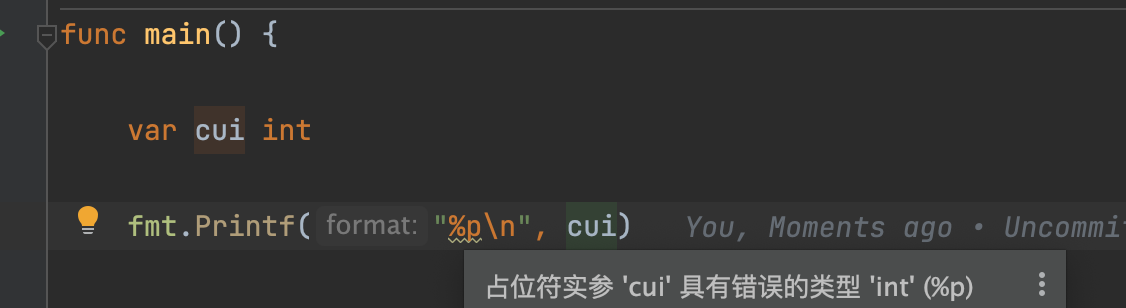
fmt.Printf(“%p\n”, &xxx)的打印问题
后面的参数必须为 指针类型,否则IDE会有提示,运行后打出来的是%!p(int=0)
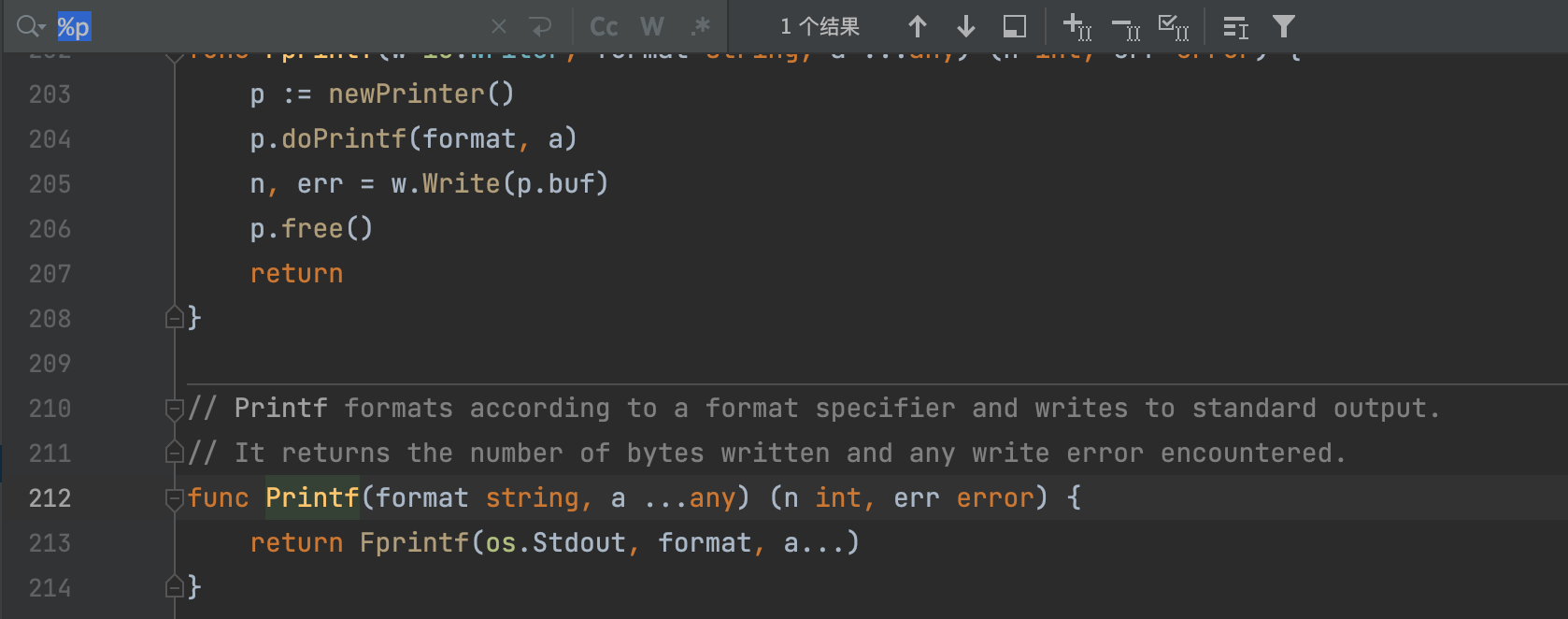
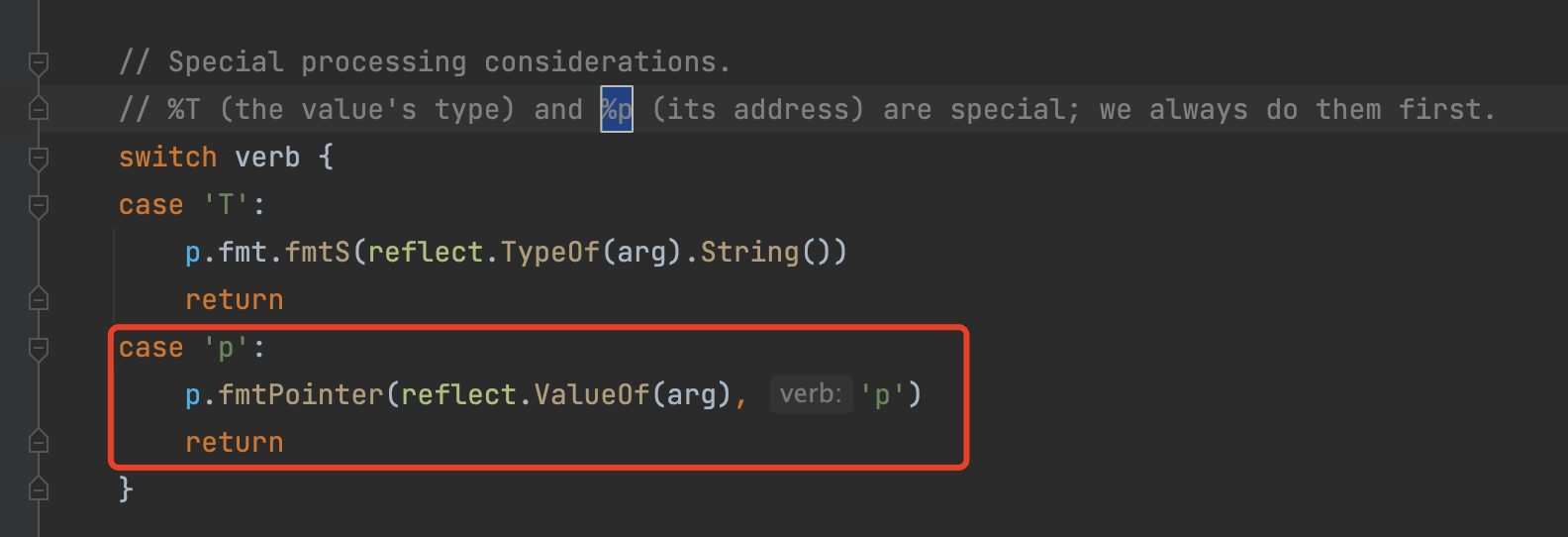
最后会到
1 | // fmt0x64 formats a uint64 in hexadecimal and prefixes it with 0x or |
https://github.com/golang/go/blob/2a8969cb365a5539b8652d5ac1588aaef78d3e16/src/fmt/print.go#L553
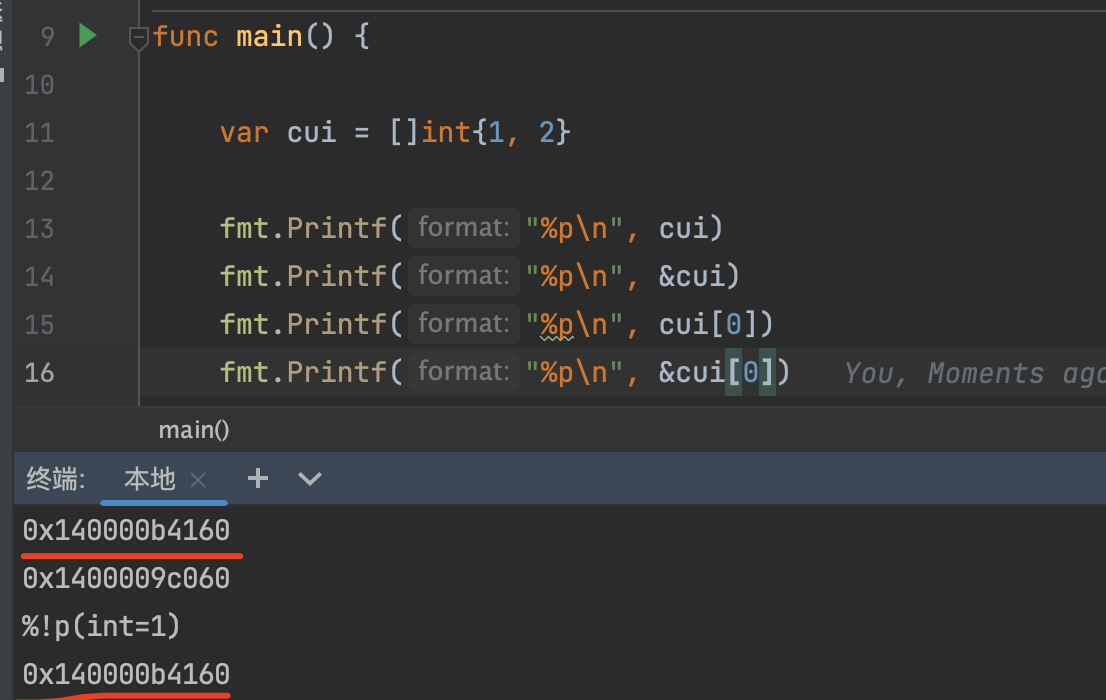
通过查看源码及试验可知,fmt.Printf(“%p”,&sli)得到的是sliceHeader的地址,
想获取切片底层数组的地址,要fmt.Printf(“%p”,&sli[0]),或者fmt.Printf(“%p”,sli)? (因为sliceheader的第一个字段是底层数组的pointer)
对任何变量x都可以&x,即这个变量在内存里的地址。但如果x本身就是指针类型,fmt.Printf(“%p”,x)打印的就是这个指针类型对应的内容,如果fmt.Printf(“%p”,&x),那就是获取这个指针类型在内存里的地址,结果也是一个指针类型
1 |
|
如果对编译器编译的过程了解,&slice 是sliceheader的地址,&slice[0]是底层数组这个知识点会是显而易见的
case1: 当作为参数传递
共享底层数组,修改后会影响原值
1 | package main |
输出:
1 | slice is: [宋江] |
再如:
1 | package main |
输出:
1 | [main]原始sli为[]string{"宋江"},长度:1,容量:1,底层数组的内存地址的两种表示方式应该一致:0x14000010230=0x14000010230,sliceheader的地址0x1400000c048 |
通过索引修改切片元素会影响原切片,但通过append追加元素,则不会(改变原切片的长度和容量)
Go中参数传递都是值传递,但当参数为引用类型如slice等时需要注意
1 | package main |
添加一些调试代码:
1 | package main |
输出为:
1 | [main] i: [0 0 0 0 0 0 0 0 0 0] len:10 cap:12 ptr:0x1400010e060 sliceheader的地址0x1400011a030 |
只能说,通过索引修改切片元素,和通过append追加元素,表现完全不同:
因为append一定至少改变了长度(甚至也改了容量),这种操作只会影响子方法中的,不会影响原值
但如果是修改,子方法修改了某个索引下元素的值,父方法也会受到影响
case2: 扩容
通过 append 操作,可以在 slice 末尾,额外新增一个元素. 需要注意,这里的末尾指的是针对 slice 的长度 len 而言. 这个过程中倘若发现 slice 的剩余容量已经不足了,则会对 slice 进行扩容
当 slice 当前的长度 len 与容量 cap 相等时,下一次 append 操作就会引发一次切片扩容
切片的扩容流程源码位于 runtime/slice.go 文件的 growslice 方法当中,其中核心步骤如下:
• 倘若扩容后预期的新容量小于原切片的容量,则 panic
• 倘若切片元素大小为 0(元素类型为 struct{}),则直接复用一个全局的 zerobase 实例,直接返回
• 倘若预期的新容量超过老容量的两倍,则直接采用预期的新容量
• 倘若老容量小于 256,则直接采用老容量的2倍作为新容量
• 倘若老容量已经大于等于 256,则在老容量的基础上扩容 1/4 的比例并且累加上 192 的数值,持续这样处理,直到得到的新容量已经大于等于预期的新容量为止
• 结合 mallocgc 流程中,对内存分配单元 mspan 的等级制度,推算得到实际需要申请的内存空间大小
• 调用 mallocgc,对新切片进行内存初始化
• 调用 memmove 方法,将老切片中的内容拷贝到新切片中
• 返回扩容后的新切片
以上内容来自 你真的了解go语言中的切片吗?
append可能引发扩容,如果发生扩容(即cap发生变化),slice底层数组的内存地址就变了~
1 | package main |
输出:
1 | 切片为:[]int{0, 0, 0},长度为3,容量为3,底层数组的内存地址的两种表示方式应该一致0x14000130000=0x14000130000,sliceheader的地址0x14000114030 |
case3:由一个数组得到一个切片,以及两个切片之间更复杂的引用
1 | ppackage main |
输出:
1 | 数组为:[4]int{0, 1, 2, 3},长度为4,容量为4,该数组的内存地址为:0x140000280e0 |
由最后一步的输出,能否认为append(sli1,sli2...),并不等价与sli1 = append(sli1,sli2[0],sli2[1]..,sli2[最后一个元素]),而是类似(无论从最后切片的容量,还是append进去的元素的值)? 即类似
1 | for _,ele := range sli2 { |
写demo试一下:
1 | package main |
输出: []int{0, 1, 6, 7, 8},cap:6
看起来又是和sli1 = append(sli1,6,7,8)结果一致的
其实,问题出在第一次x = append(x, y...)这一步
此时x没有扩容,和y共用一个底层数组a。 这一步把a改成了 [0 2 3 3],y也因此变成了 [3 3]
所以再第二次x = append(x, y...)前,y就已经是 [3 3]了
所以 append(sli1,sli2…),还是等价于append(sli1,sli2[0],sli2[1]..,sli2[最后一个元素])的
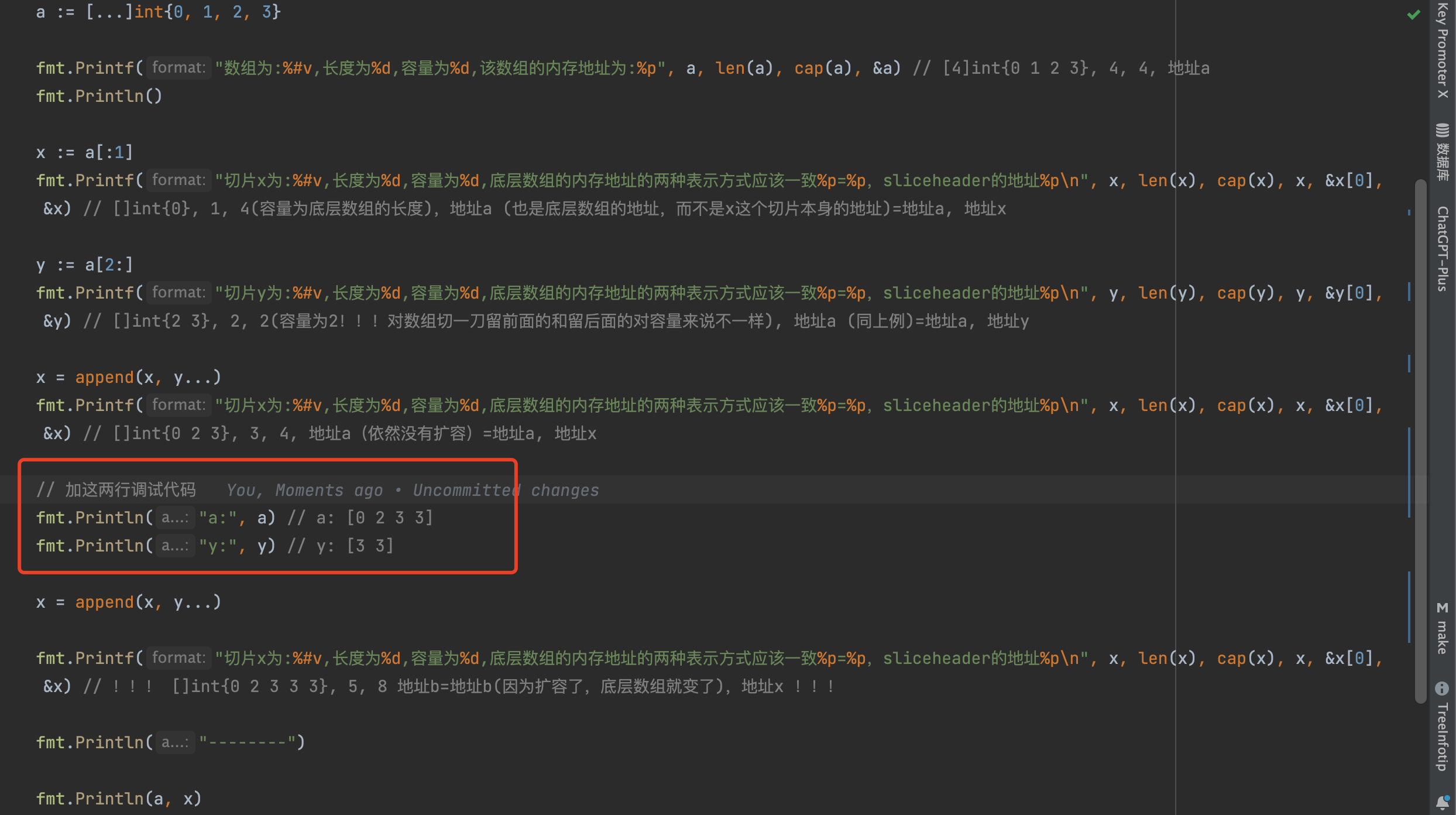
1 | package main |
输出: [0]
1 | package main |
输出: [0 3] [0] [0 3]
1 | package main |
输出:
1 | a为[]int{0},长度:1,容量:10,底层数组的内存地址的两种表示方式应该一致0x1400009e000=0x1400009e000,sliceheader的地址0x14000098018 |
1 | package main |
输出:
1 | a为[]int{0},长度:1,容量:1,底层数组的内存地址的两种表示方式应该一致0x140000200c8=0x140000200c8,sliceheader的地址0x1400000c048 |
case4: 一次压入多个 与 多次压入一个;元素类型对扩容的影响
为什么不同类型的切片,append之后的len和cap不一样?
1 | package main |
输出:
1 | len(s1):3,cap(s1):3 |
为什么不同类型不一样?
1 | package main |
输出:
1 | 长度:0 容量:0 底层数组的内存地址:0x0,sliceheader的地址0x1400000c048 |
1 |
|
fmt.Println("cap of m is ", cap(m)) //! 6 如果要的容量是原来容量的两倍还要多, 那新的容量就是所要求的容量大小?(那为何是6而不是 这一步是为什么?
输出:
1 | len of old m is 2 |
再如:
1 | package main |
为什么不同类型的切片,append之后的len和cap不一样?
1 | package main |
扩容相关的逻辑肯定和 go/src/runtime/slice.go中的func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice有关,
但更换版本试了下,和从1.18版本开始的cap策略变更没关系
(用1.17和1.21运行,结果是一样的)
和element size有关,跟防止overflow以及memory alignment 。ele size 还会影响new cap
不在这里roundup 到tcmalloc的块大小,其他内存也是浪费的。
感谢cwx老哥一起研究
1 | // Specialize for common values of et.Size. |
这段注释解释了针对常见的 et.Size 值进行特殊处理的原因。
在这段代码中,et.Size 是一个表示大小的整数值。注释中提到了三种常见的情况:
当
et.Size为 1 时,不需要进行除法或乘法运算。这是因为在计算机中,将一个数左移一位相当于乘以 2,右移一位相当于除以 2。因此,对于大小为 1 的情况,可以直接使用移位操作来处理,避免了除法或乘法的开销。当
et.Size等于当前架构的指针大小(goarch.PtrSize)时,编译器会将除法或乘法运算优化为一个常数的位移操作。这是因为指针大小通常是2的幂次方,所以可以通过移位来进行高效的除法或乘法运算。对于其他大小为2的幂次方的情况,使用一个可变的位移操作。这意味着将一个数左移或右移的位数是可变的,取决于
et.Size的具体值。这种处理方式仍然利用了位移操作的高效性。
总之,这段注释是解释了为什么针对不同的 et.Size 值采取了不同的优化策略,以提高计算效率。这些优化措施是为了充分利用位移操作和特定的数学性质,从而减少除法或乘法的开销。
et.Size_不同,影响到最后cap的计算:如果是8字节的数据类型比如int,newcap = int(capmem / goarch.PtrSize); 如果是2的指数倍的,比如string(占16字节),newcap = int(capmem >> shift)
et.Size_ 即元素类型占用的内存空间,常见的如 int32,存储大小:4; int64,存储大小:8; string,存储大小:16 // string类型底层是一个指针(8字节),和一个长度字段(8字节)
通过在源码中添加print,大致捋清了脉络:
基于1.21版本,switch case有四个优先级:
- 尺寸为1的(布尔值类型)
- 尺寸为8的(64位机器;32位的话为4,在此不考虑)如int64类型;
- 尺寸为2的指数倍的,如string类型
- default兜底
最后必然还和内存分配有关系,多级 mheap,mcentral(类似于全局队列),mcache(类似于本地队列),mspan(各种尺寸的内存各有一块)
很多个级别,涉及到向下取整,有一部分内存碎片
相关调试代码:
1 | func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice { |
1 | package main |
输出:
1 | 爽哥调试-未根据元素类型做处理前的newcap值为: 1 |
和 你真的了解go语言中的切片吗? 最后 3.12 问题12差不多
case5: 初始容量的确定
通过
s := make([]int,10)这种方式,如果没有指定cap的值,则默认与len相同也可以显式指定,可以很大,但不能比len小,否则会报
len larger than cap in make([]int)
1 | package main |
输出:
1 | 切片demo为:[]int{0, 0, 0, 0, 0, 0, 0, 0, 0},长度为9,容量为9,底层数组的内存地址为0x140000260f0,sliceheader的地址为0x1400000c048 |
为什么初始容量为9?
为什么后面扩容是18而不是16?
通过 append 操作,可以在 slice 末尾,额外新增一个元素. 需要注意,这里的末尾指的是针对 slice 的长度 len 而言. 这个过程中倘若发现 slice 的剩余容量已经不足了,则会对 slice 进行扩容
当 slice 当前的长度 len 与容量 cap 相等时,下一次 append 操作就会引发一次切片扩容
切片的扩容流程源码位于 runtime/slice.go 文件的 growslice 方法当中,其中核心步骤如下:
• 倘若扩容后预期的新容量小于原切片的容量,则 panic
• 倘若切片元素大小为 0(元素类型为 struct{}),则直接复用一个全局的 zerobase 实例,直接返回
• 倘若预期的新容量超过老容量的两倍,则直接采用预期的新容量
• 倘若老容量小于 256,则直接采用老容量的2倍作为新容量
• 倘若老容量已经大于等于 256,则在老容量的基础上扩容 1/4 的比例并且累加上 192 的数值,持续这样处理,直到得到的新容量已经大于等于预期的新容量为止
• 结合 mallocgc 流程中,对内存分配单元 mspan 的等级制度,推算得到实际需要申请的内存空间大小
• 调用 mallocgc,对新切片进行内存初始化
• 调用 memmove 方法,将老切片中的内容拷贝到新切片中
• 返回扩容后的新切片
runtime/slice.go:
1 | newcap := oldCap |
newcap 经过如上逻辑后,还要再根据元素类型,做一次处理。详见case4中的源码调试
1 | package main |
输出:
1 | 切片demo为:[]int{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},长度为10,容量为10,底层数组的内存地址为0x140000ba000 |
1 | package main |
输出为:
1 | [1] len:1 cap:1 ptr:0x140000200c8 |
两种不同的声明方式,对初始容量的影响

1 | package main |
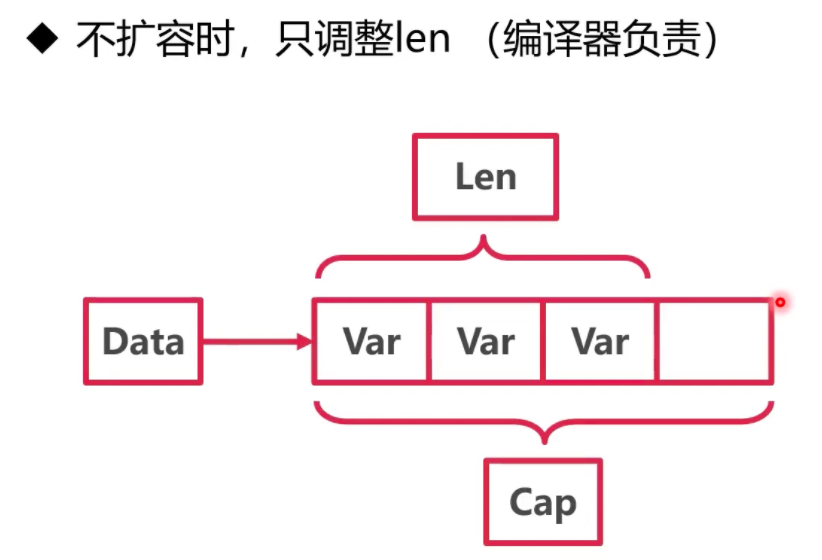
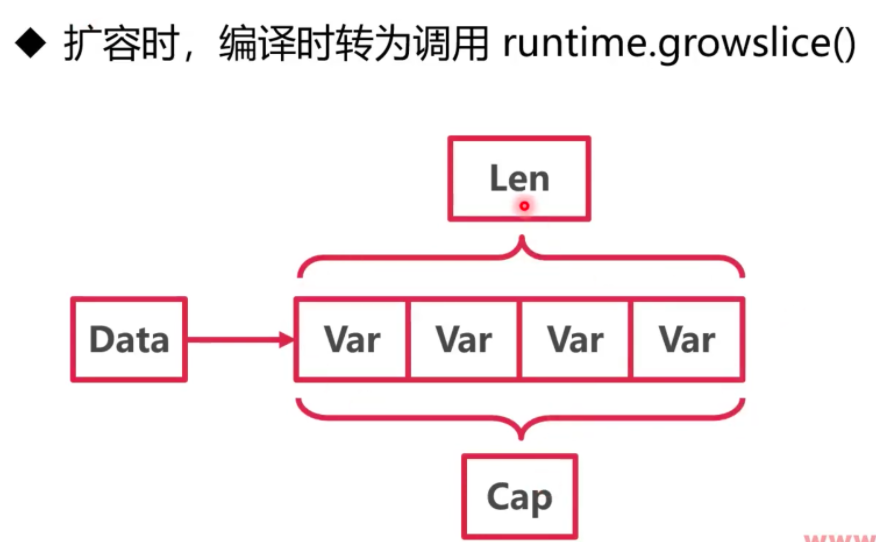

另外与append无关的一些case:
迭代过程中修改切片的值
1 | package main |
输出: 189
并发写入
1 | package main |
加锁后:
1 | package main |
1 | package main |
把锁初始化的操作放在循环内是不行的,最后的结果一定小于100.
要放到全局,或者循环体外,只初始化一把锁,而不是n把
interface 类型的切片可能出错的点
1 | package main |
泛型切片
1 | package main |
原文链接: https://dashen.tech/2020/06/05/Go-slice扩容N连问/
版权声明: 转载请注明出处.