https://blog.csdn.net/thebestleo/article/details/108126597
https://blog.csdn.net/legendaryhaha/article/details/106391112
https://www.geek-share.com/detail/2804377456.html
关键字: 字符集,utf8mb4,emoj
众所周知,mysql的utf8是假的utf8,没法存emoj等字符。要设置为utf8mb4…
问题
同事给了一段Update语句,更新某张表id=xxx的某个字段;
1 |
|
登陆跳板机,连接远程数据库后,执行sql,报错: ERROR 1366 (HY000): Incorrect string value: '\xF0\x9F\x93\xA3Ev...'
\xF0\x9F\x93\xA3恰好是转义之后的emoj
这张表所在的库的字符集是utf8,但是表指定了是utf8mb4,字段没有指定,仅指定了排序方式为utf8mb4_unicode_ci
据说,字符集规则会按照 字段设置>表设置>库设置的顺序。
此处 这个字段没有设置字符集,那应该用表的字符集即*DEFAULT CHARSET=utf8mb4 *
(且经过试验,如果COLLATE=utf8mb4_unicode_ci,那字符集不可能是utf8,只可能是utf8mb4,不然报错时会直接报错)
下面补充一些mysql字符集的知识
查看库级别的 字符集和编码设置
1 | SHOW VARIABLES LIKE 'character_set%'; |
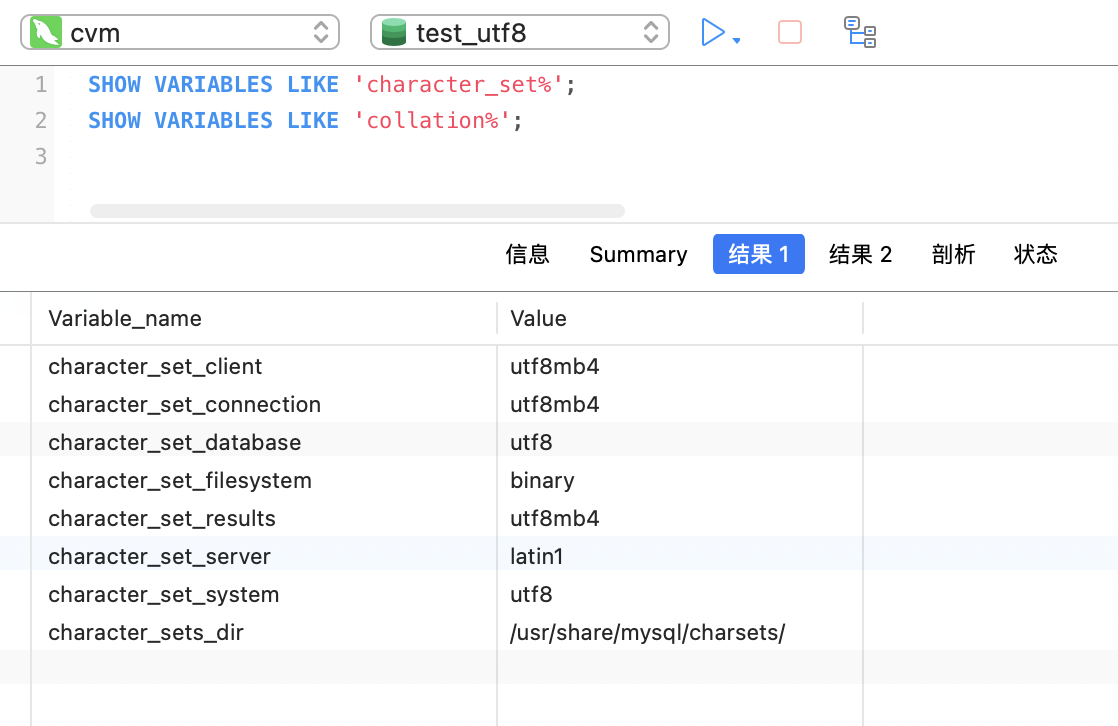

1 | Variable_name |
这都是干啥的?
这些变量是 MySQL 中与字符集相关的变量,用于控制不同环境中的字符集设置。以下是对每个变量的简要说明:
character_set_client: 客户端连接到 MySQL 服务器时所使用的字符集。character_set_connection: 当前连接的默认字符集。它可以在客户端连接时通过SET NAMES命令来设置。character_set_database: 默认数据库的字符集。在创建数据库时设置,新创建的表将继承该字符集。character_set_filesystem: 文件系统的默认字符集。用于存储文件名和路径的字符集。character_set_results: 返回给客户端的结果集的字符集。character_set_server: MySQL 服务器的默认字符集。用于新建数据库、表和列的默认字符集。character_set_system: MySQL 系统数据字典和内部字符串的字符集。character_sets_dir: MySQL 字符集定义文件的目录路径。
这些变量的设置是相互关联的,通过调整它们的值可以控制 MySQL 在不同环境中的字符集行为。确保这些变量的值一致并与你的应用程序和数据的字符集一致,可以确保正确地存储、传输和显示数据。
注意:在修改这些字符集相关的变量之前,请确保了解其含义和影响,并在备份数据的情况下谨慎操作。修改字符集设置可能会对现有数据和应用程序产生影响。
一般说的字符集和排序规则,应该主要看
1 | SHOW VARIABLES LIKE 'character_set_database'; |
查看表级别的字符集和编码设置
1 | SHOW CREATE TABLE `your_table_name`; |
能得到建表语句,看最后的DEFAULT CHARSET
具体到table的column的字符集如何查看?
1 | SHOW FULL COLUMNS FROM your_table_name; |
在查询结果中,查找 “Collation” 列。该列显示每个列(字段)的字符集和排序规则。
请注意,”Collation” 列中的值表示字符集和排序规则的组合。常见的字符集包括 UTF-8(如 utf8mb4)和 Latin1(如 latin1)。

Collation 本意是校勘,校对之意,在数据库中 是排序规则
这个字段的第一部分,其实已经指明了字符集…所以SHOW FULL COLUMNS没有必要再多一个字符集列
那么,问题何在呢?
起初搜到,需要在连接时指定为utf8mb4才可以
即 mysql --default-character-set=utf8mb4 -u root -h xxx.xxx.xx.xx -p密码
但还是不行…
最后发现执行 SET NAMES utf8mb4后再执行更新语句,成功!
根据报错信息,看起来在尝试更新xxxxx表中的xxxxxxx字段时遇到了错误。报错信息是ERROR 1366 (HY000): Incorrect string value: '\xF0\x9F\x93\xA3Ev...' for column 'xxxxxxx' at row 1,这表明在该字段中插入了无效的字符。
尽管您已经将该字段的字符集设置为utf8mb4,支持存储四字节的UTF-8字符,但有可能连接或会话的字符集设置仍然不兼容。为了确保字符集一致,您可以尝试执行以下操作:
- 在更新语句之前,执行以下SQL语句设置会话字符集为
utf8mb4:
1 | SET NAMES utf8mb4; |
- 然后,再执行更新语句:
1 | UPDATE `xxxxx` SET `xxxxxxx` = '...' WHERE (`id` = 5136); |
通过这样的设置,会话的字符集将与字段的字符集一致,可以正常存储包含四字节UTF-8字符的字符串。
如果问题仍然存在,请确保数据库连接和客户端工具的字符集设置与字段的字符集设置一致。另外,您还可以检查MySQL服务器的全局字符集设置,以确保它也是utf8mb4。
SET NAMES utf8mb4什么?
“SET NAMES utf8mb4” 是一个MySQL命令,用于设置数据库连接的字符集编码为utf8mb4。在MySQL中,字符集决定了数据库如何存储和处理数据。
utf8mb4是一种字符集编码,支持Unicode字符集的全部字符,包括一些较早版本的utf8字符集无法表示的一些字符。utf8mb4编码可以处理各种语言的文字和符号,包括一些较为特殊的字符,如表情符号和特殊符号等。
通过将数据库连接的字符集编码设置为utf8mb4,可以确保数据库可以正确地存储、检索和显示各种字符,避免出现乱码或字符丢失的问题。这在处理多语言或包含特殊字符的应用程序中特别重要。
只对当前连接有效吗?
是的,”SET NAMES utf8mb4” 命令只对当前数据库连接有效。这意味着只有在执行该命令后建立的数据库连接会使用 utf8mb4 字符集编码。
如果你在程序中使用了多个数据库连接,每个连接都需要单独执行 “SET NAMES utf8mb4” 命令来设置字符集编码。
另外,如果你希望永久地将数据库的字符集编码设置为 utf8mb4,你需要修改数据库的默认字符集配置。这样,在新建的数据库连接中不需要再手动执行 “SET NAMES utf8mb4” 命令,因为连接会默认使用数据库的字符集配置。请注意,在修改数据库的默认字符集之前,请确保备份数据和相应的预防措施。
结论
可能是:数据库是utf8,即便我在连接时指定--default-character-set=utf8mb4,依然会用utf8,必须要通过SET NAMES utf8mb4 再设置一次
为了验证,通过 mysql --default-character-set=utf8mb4 -u root -h xxx.xxx.xx.xx -p密码连接mysql,select 刚才更新成功的那条记录,发现emoj无法正常显示; 执行SET NAMES utf8mb4 后,再select能正常看到emoj
设置mysql数据库的字符集和编码设置(谨慎操作,一般不要乱改)
要设置 MySQL 数据库的字符集和编码设置,你可以采取以下步骤:
登录到 MySQL 数据库服务器,可以使用以下命令:
1
mysql -u your_username -p
替换
your_username为你的数据库用户名。在登录后,可以执行以下命令来查看当前的字符集和编码设置:
1
2SHOW VARIABLES LIKE 'character_set%';
SHOW VARIABLES LIKE 'collation%';这将显示当前的字符集和编码设置。
若要修改数据库的字符集和编码设置,可以执行以下命令(以utf8mb4为例):
1
ALTER DATABASE your_database_name CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
替换
your_database_name为你要修改的数据库名称。如果需要修改特定表的字符集和编码设置,可以执行以下命令(以utf8mb4为例):
1
ALTER TABLE your_table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
替换
your_table_name为你要修改的表名称。如果你希望新创建的表默认采用特定的字符集和编码,可以在创建表时指定:
1
2
3CREATE TABLE your_table_name (
...
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;替换
your_table_name为你要创建的表名称,并根据需要修改其他表的列和选项。重启 MySQL 服务以使更改生效,具体的重启方式取决于你的操作系统和安装方式。
请注意,修改字符集和编码设置可能会影响现有数据和应用程序,因此在进行任何更改之前,请确保备份数据库并谨慎操作。
如何 修改数据库的默认字符集配置
要修改数据库的默认字符集配置,你需要执行以下步骤:
- 登录到你的MySQL数据库服务器。
- 执行以下命令来打开MySQL的配置文件(通常是my.cnf或my.ini):如果你使用的是Windows系统,则路径可能是
1
sudo nano /etc/mysql/my.cnf
C:\ProgramData\MySQL\MySQL Server X.X\my.ini,其中X.X代表你的MySQL版本号。 - 在配置文件中找到
[mysqld]部分。 - 添加或修改以下两行来设置默认字符集编码为 utf8mb4:上述配置将字符集设置为 utf8mb4,同时使用了
1
2
3[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ciutf8mb4_unicode_ci校对规则。你也可以选择其他适合你的校对规则。 - 保存并关闭配置文件。
- 重新启动MySQL服务以使配置生效,可以使用适合你的操作系统的命令,例如:
- 在Linux上使用:
1
sudo systemctl restart mysql
- 在Windows上使用:
1
2net stop MySQL
net start MySQL
- 在Linux上使用:
- 现在,新建的数据库连接将默认使用 utf8mb4 字符集编码。
请注意,修改数据库的默认字符集可能会对现有的数据库和数据产生影响。在执行这些步骤之前,请确保备份数据并采取相应的预防措施。
mysql set names 命令和 mysql 字符编码问题
可以从库,表,字段维度设置utf8mb4
将 MySQL 数据库的编码从 utf8 更改为 utf8mb4 是一个常见的操作,因为 utf8mb4 支持完整的 Unicode 字符集,包括表情符号等四字节字符。以下是更改编码的基本步骤:
检查当前编码:
首先,确认当前的编码设置:1
2SHOW VARIABLES LIKE 'character_set%';
SHOW VARIABLES LIKE 'collation%';修改数据库编码:
对于每个需要修改的数据库,执行:1
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
修改表编码:
对每个表执行:1
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
修改列编码:
如果需要,可以单独修改列的编码:1
ALTER TABLE table_name MODIFY column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
更新 MySQL 配置文件:
在 my.cnf 或 my.ini 文件中添加或修改以下设置:1
2
3
4
5
6
7
8
9[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci重启 MySQL 服务以应用配置更改。
验证更改:
再次运行步骤 1 中的命令来确认编码已更改。
注意事项:
- 更改编码可能会影响索引长度,特别是对于使用 utf8mb4 的 VARCHAR 列。
- 在执行这些更改之前,请务必备份您的数据库。
- 某些应用程序可能需要更新以支持新的编码。
20250227
wangbing 改了代码,发现taskon-server启动非常慢,要20s.
后面发现不是代码问题,而是字符集问题
因为修改mysql字段编码以及排序规则导致的一次线上生产故障
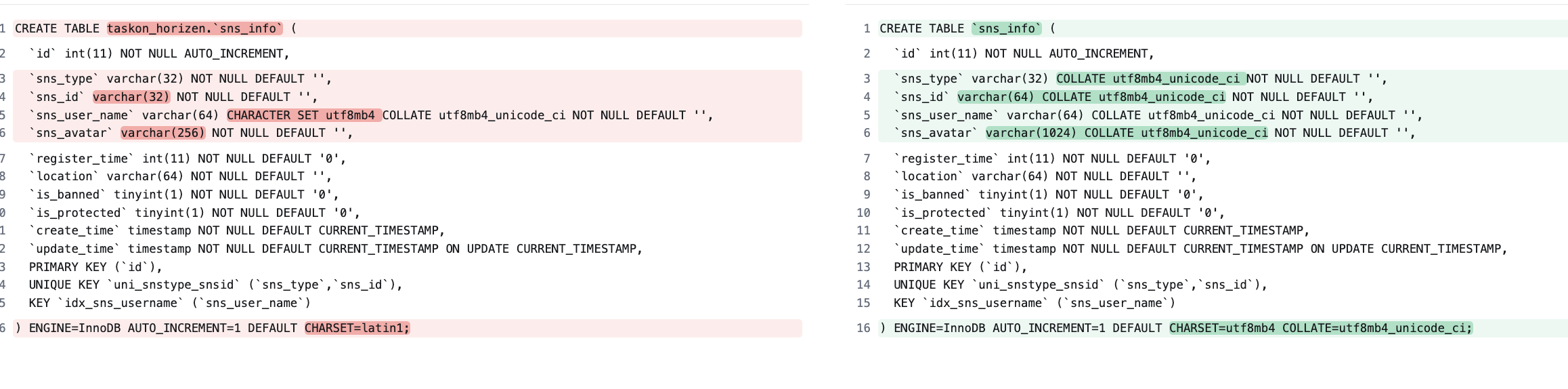
最初的建表语句:
CREATE TABLE taskon_horizen.sns_info (
id int(11) NOT NULL AUTO_INCREMENT,
sns_type varchar(32) NOT NULL DEFAULT ‘’,
sns_id varchar(32) NOT NULL DEFAULT ‘’,
sns_user_name varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’,
sns_avatar varchar(256) NOT NULL DEFAULT ‘’,
register_time int(11) NOT NULL DEFAULT ‘0’,
location varchar(64) NOT NULL DEFAULT ‘’,
is_banned tinyint(1) NOT NULL DEFAULT ‘0’,
is_protected tinyint(1) NOT NULL DEFAULT ‘0’,
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY uni_snstype_snsid (sns_type,sns_id),
KEY idx_sns_username (sns_user_name)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
fix后的建表语句:
CREATE TABLE sns_info (
id int(11) NOT NULL AUTO_INCREMENT,
sns_type varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’,
sns_id varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’,
sns_user_name varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’,
sns_avatar varchar(1024) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘’,
register_time int(11) NOT NULL DEFAULT ‘0’,
location varchar(64) NOT NULL DEFAULT ‘’,
is_banned tinyint(1) NOT NULL DEFAULT ‘0’,
is_protected tinyint(1) NOT NULL DEFAULT ‘0’,
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY uni_snstype_snsid (sns_type,sns_id),
KEY idx_sns_username (sns_user_name)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
当表格的字符集从 latin1 改为 utf8mb4 后性能提升,这可能由几个原因造成:
索引使用效率:latin1 和 utf8mb4 对于同样的字符数据占用空间不同,这会影响索引的结构和效率。utf8mb4 虽然每个字符最多可占用4字节(比latin1的1字节多),但在某些查询模式下,可能让索引更高效。
字符转换开销:如果您的应用程序默认使用 UTF-8 编码(现今很常见),而数据库表使用 latin1,每次查询都需要进行字符集转换,产生额外开销。改为 utf8mb4 后,可能减少了这种转换。
排序规则优化:不同字符集关联的排序规则(collation)效率不同。utf8mb4 的某些排序规则可能对您的数据模式更优化。
数据分布变化:改变字符集时可能重建了表,导致数据物理分布更优,暂时提高了性能。
字符级别操作:如果查询中有字符串比较、排序或模糊搜索,不同字符集处理效率会有差异。
缓存效果:系统缓存状态可能在变更前后不同,影响了性能测试结果。
具体分析需要了解:
- 查询的具体模式是什么
- 表的大小和结构
- 是否使用了索引
- 应用程序使用的字符集
您可以通过查看查询执行计划(EXPLAIN)来进一步诊断性能差异的原因。
原文链接: https://dashen.tech/2020/07/05/MySQL中的字符集和排序规则/
版权声明: 转载请注明出处.