相关内容:
强烈推荐:
[TIR ] 01|启航Rust:跨越新手的所有权和内存管理障碍
陈吉米老师,坐标上海,十多年的Java开发,rust狂热学习者. 2024.06.30我参加了在微软孵化器那个Road to Rust的活动,吉米老师做了演讲,主题是 理解所有权和生命周期~ https://mp.weixin.qq.com/s/2qj-9mf3SXtIE8WimABKmA
完整视频: 如何一步一步推导出Rust所有权体、借用规则、引用类型以及秒懂生命周期标注
好的,我已经将您提供的视频文稿内容,整理成了一篇结构清晰、逻辑连贯的技术文章。文章保留了原作者从第一性原理出发,逐步推导Rust核心概念的精彩思路。
从零到一:为什么Rust需要所有权、借用与生命周期?
对于许多有经验的程序员来说,学习Rust的过程充满了挫败感。我本人(原作者)有近十年的编程经验,主要使用Java、Kotlin、Python等带垃圾回收(GC)的语言。通常,我只需要一周左右就能上手一门新语言,但学习Rust却花费了数月,感觉依然不顺畅。
这种巨大的差异让我开始思考:为什么我过往的经验在Rust面前似乎“失灵”了?为什么Rust与其他主流语言如此不同?
这篇文章的目的,就是为了回答这些问题。我们将进行一次思维实验,不直接抛出“所有权”、“生命周期”等令人费解的定义,而是从零开始,探讨为了实现Rust的设计目标,这些概念是如何一步步被“设计”出来的。
一、 思维的壁垒:GC语言的惯性
我们遇到的第一个障碍,源于对变量语义的思维定势。
在Java、Go、JS等GC语言中,变量语义符合我们的直觉:
基本类型 (如
int):1
2
3a = 123;
b = a;
a = 456; // b 仍然是 123a和b相互独立,赋值是值的拷贝。对象类型 (如
List):1
2a = [1, 2, 3];
b = a; // a 和 b 指向了同一个列表对象赋值行为导致
a和b两个变量 共享 同一个底层对象。
这种“共享”的思维模式,在我们学习的大多数语言中都是统一的。
然而,Rust彻底颠覆了这一点。在Rust中,变量默认 不可以共享 对象,赋值后会发生所有权的 “移动”(Move)。这好比一个习惯用右手写字几十年的人,突然被要求换用左手。过去的经验不仅没有帮助,反而成了障碍。这种变量语义的根本性转变,正是Rust学习曲线陡峭的根源。
二、 Rust的设计目标与核心矛盾
要理解Rust为何如此“特立独行”,我们必须先了解它的设计目标:
- 定位:系统编程语言(可以用来写操作系统,与C/C++类似)。
- 核心追求:极致的性能、内存安全、可靠性与现代化。
这里面存在一个核心矛盾:
系统编程语言 vs. 内存安全
- 系统编程语言 意味着追求高性能,因此 不能有GC(垃圾回收器)和庞大的运行时。GC会带来不可预测的暂停(Stop-The-World),这在系统级编程中是难以接受的。
- 内存安全 又要求堆(Heap)上的内存能被 自动管理,避免悬垂指针、二次释放等经典C/C++难题。
那么问题来了:如何在没有GC的情况下,实现安全、自动的内存回收?
三、 思维实验:从零设计一个无GC的自动内存回收方案
现在,让我们假设自己是Rust的设计者,来解决上述矛盾。
第1步:确定回收时机
没有GC来判断内存何时不再被使用,我们能利用的最明确的信号是什么?答案是 变量的作用域。当一个变量离开其作用域时,它就再也无法被访问了。
由此,我们定下第一条规则:
规则 1: 当变量离开作用域时,其拥有的内存必须被立刻回收。
第2步:解决共享难题与“所有权”的诞生
这条规则看似简单,却带来一个致命问题:变量之间无法再共享对象了。
想象一下,如果变量 A 和 B 指向了堆上的同一个对象。当 A 首先离开作用域时,它会根据规则1释放这块内存。此时,B 就成了一个指向无效内存的 悬垂指针。这是严重的内存安全漏洞。
为了解决这个问题,我们必须做出一个艰难但彻底的决定,于是有了第二条规则:
规则 2: 禁止变量共享对象。一个值(对象)在任何时候,只能与一个变量绑定。
这个“唯一绑定”的概念,就是 所有权(Ownership) 的核心思想。我们给这个变量起个名字,叫“所有者”(Owner)。
第3步:定义赋值行为——“移动”语义
有了所有权规则,那赋值操作(let p2 = p1;)该如何处理?为了维持“唯一所有者”的原则,我们只有一个选择:
规则 3: 赋值操作将导致所有权的 转移(Move)。当
p1的值赋给p2后,p1必须立即失效,不能再被访问。
这就像科幻电影里的“瞬间移动”:在目标星球根据原子信息重建一个人后,必须将原星球上的本体摧毁,否则世界上就会出现两个一模一样的人。在内存中,这个过程是按字节把栈上的数据从 p1 的位置拷贝到 p2 的位置,然后编译器在静态检查时将 p1 标记为“已移动”,阻止后续使用。
至此,通过这三条看似“不讲理”的规则,我们构建出了一套无GC的、安全的自动内存管理方案的雏形。这就是 所有权系统。
四、 让系统可用:引入“借用”与“引用”
虽然我们的方案保证了内存安全,但它几乎没有实用性。因为禁止共享,使得一个简单的函数调用都变得异常困难:
1 | fn print_data(data: Vec<i32>) { |
我只是想把数据传给函数打印一下,结果数据本身就没了!这显然无法编写复杂的程序。
怎么办?我们不能放弃所有权,但又需要一种“临时访问”数据的能力。于是,我们引入了一个新概念:引用(Reference),而创建引用的动作,就叫做 借用(Borrow)。
引用可以看作是一种受严格限制的“指针”,它必须遵守以下规则:
- 类型绑定:
&i32类型的引用只能指向i32数据。 - 不可修改地址:不能像C指针那样进行加减运算(指针运算)。
- 必须有效:必须由一个存在的变量通过
&操作符创建,杜绝空指针或野指针。
为了进一步保证安全,借用规则被设计得像一个 “读写锁”:
- 不可变借用 (
&T):相当于 读锁。你可以同时拥有任意多个不可变借用,因为只读不写是安全的。 - 可变借用 (
&mut T):相当于 写锁。在任何时候,你只能拥有一个可变借用,并且此时不能有任何不可变借用存在。它必须是独占的。
通过引用和借用,我们解决了在不转移所有权的情况下“共享”访问数据的问题。
五、 最后的防线:生命周期与悬垂引用
引入引用后,又出现了新的安全隐患——悬垂引用。看下面这个经典的例子:
1 | fn get_a_dangling_reference() -> &i32 { |
引用 r “活”得比它指向的数据 x 更长,这绝对是内存安全的大敌。为了杜绝这种情况,Rust的编译器——借用检查器(Borrow Checker)——需要最后一条规则:
生命周期规则: 引用的生命周期(Lifetime)不能长于其指向的数据的生命周期。
借用检查器会在编译时,像一个严苛的审计员,检查每一处借用是否都严格遵守了读写锁规则和生命周期规则。这也是为什么许多在其他语言里可以通过编译的代码,在Rust中却会被编译器拒绝。
六、 秒懂生命周期标注 ('a)
当函数签名涉及到引用时,有时编译器会无法判断生命周期的关系,比如:
1 | // 编译器会报错:无法确定返回的引用的生命周期 |
编译器看不懂函数体内的逻辑,它只看签名。它不知道返回的引用是来自 x 还是 y。为了通过编译,我们需要手动添加 生命周期标注:
1 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { ... } |
很多教程会解释说:“这表示 x、y 和返回值的生命周期至少要和 'a 一样长”,这种绕口令式的描述让人难以理解。
让我们用一种更简单的方式来解读:
生命周期标注 (
'a) 的本质,是程序员在给编译器提供信息,告诉它不同引用生命周期之间的“关联关系”。
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str 这行签名,我们其实是在告诉编译器:
“嘿,听着!我返回的那个引用,它的生命周期与输入参数 x 和 y 的生命周期都有关联。所以,在实际调用时,返回值的有效范围不能超过 x 和 y 中 较短 的那个。”
'a 只是一个占位符,一个名字,它本身没有意义,它的作用是建立连接。编译器得到这个关联信息后,就能在函数被调用的地方进行检查,确保不会产生悬垂引用。
总结
我们来回顾一下这条逻辑链:
- 为了实现 高性能与内存安全 的目标,Rust选择了 无GC。
- 为了实现无GC下的自动内存管理,引入了 所有权 机制(单一所有者,作用域结束时释放)。
- 所有权导致了 无法共享 数据的问题。
- 为了解决共享问题,引入了 借用与引用(受限的指针,遵守读写锁规则)。
- 引用又可能导致 悬垂引用 的问题。
- 为了解决悬垂引用,最终引入了 生命周期 的概念,并由 借用检查器 在编译期强制执行。
通过这样一步步的推演,Rust中那些看似怪异、复杂的规则,都变得合乎逻辑且必不可少了。它们不是被随意发明的,而是为了支撑起Rust最核心的承诺——在不牺牲性能的前提下,提供极致的内存安全。
假设你已对所有权和引用有所了解。简单来说,所有权确保变量独占对象,解决了对象回收时机的问题。
但它也给诸如函数传参等编程操作带来了困难。而引用允许变量间共享对象内容,暂时解决了传参问题。
然而,引用也引入了一个新风险:悬垂引用—-引用可能指向一个不再有效的对象。
为了解决悬垂引用的问题,编译器需要能够检测代码中是否存在悬垂引用的风险,并在检测到此类风险时拒绝编译。这就是引入生命周期标注的根本原因。
生命周期,就只是为了解决 悬垂引用的问题
所有权不针对基本类型,像int,bool,float,和其他语言一样,但是string,切片以及更复杂的类型,就要遵循所有权?? 是否正确? (看起来是对的…https://mp.weixin.qq.com/s?__biz=MzUzNTQ1NzA3Mg==&mid=2247483784&idx=1&sn=7ceb0edd9f109f97c50e1d7af9ad13d6&scene=19#wechat_redirect )
所以,Rust为了解决没有GC,又不需要手工清理内存这一目标, 引入了 所有权, 但又带来了函数传参等问题, 为解决该问题, 引入了引用…但又引入了新问题,悬垂引用, 为了解决这个问题,又引入了 生命周期…(编译器虽然智能,但其能力是有限的,它不能完全理解代码的逻辑含义。唯一能做的就是跟踪变量之间的关系。..所以需要手工标注一下)
像是撒一个谎,要用多个谎来圆….为了解决一个问题,需要引入新的规则,新规则又带来了新问题,于是…
生命周期:
我看不懂代码,因为找不到引用标注。。。你的代码可能没有悬垂信用等问题,但借用检查器不认识。。
借用检查器 会去找&符号
编译器确定关联关系只能通过&符号来发现
我们已经知道,未标注’a时编译器拒绝编译的原因是因为代码中没有明确的&来指示返回引用的来源,它没有阅读代码逻辑的能力来发现返回值和x、y有关联
以后借用检查器 可能会优化,减少生命周期的标注,更智能,能多读懂一些
进阶:
提升Rust技能:3个必知的’static生命周期用法
我的理解:
可以理解成很多人在一个公用厨房,共同合作一桌大餐.每个人自带一些东西,比如刀叉筷子,肉菜蛋奶等. 厨房空间非常有限,而且不通风,对垃圾的容忍度非常低, 垃圾太多就会OOM, 所以会要求公共厨房要尽可能随时保持干净(垃圾量不能超过2kg).这些人来来去去,人员流动和频次很高
如何处理产生的垃圾?
一种是C/C++这样的,完全由人员自己管理,不管是谁带来的东西,有没有变成垃圾,都可以回收.
一种是Java/Go或者PHP/Python/Swift,不管是标记清除还是引用计数,都是有一套规则,比如每隔一定时间,有第三方保洁进来打扫,保洁比较有经验,能识别出哪些是垃圾,哪些不是,来做饭的厨房用户不需要关心.坏处是保洁看到垃圾比较多了,或者隔了一定时长,会强行进来打扫,这个过程中大多数时间是可以人员一边做饭,保洁一边打扫的, 但有一小段时间需要拖地, 来厨房做饭的人啥事也不能做,要等地拖完了才能继续活动.
再一种就是Rust,给每一个资源---或者说最后的垃圾,都标识一个人员.是你带来的,你对其有所有权,你走的时候请也带走. 或者把所有权转到其他人名下

file:///Users/fliter/rust-in-databend/02-%E7%90%86%E8%A7%A3Rust%E7%9A%84%E6%89%100%E6%9C%89%E6%9D%83-%E8%8B%8F%E6%9E%97/%E7%90%86%E8%A7%A3Rust%E7%9A%84%E6%89%100%E6%9C%89%E6%9D%83-Datafuse.pdf
所有权实现了既要保障内存安全⼜要⽆GC,运⾏时⾼性能的⽬标
file:///Users/fliter/rust-in-databend/26-%E7%AC%AC%E4%B8%100%E8%AF%BE-rust%E5%85%A5%E9%97%A8%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86-2-rust%E6%89%100%E6%9C%89%E6%9D%83%E6%9C%BA%E5%88%B6-%E5%100%9F%E7%94%A8%E8%A7%84%E5%88%99/%E7%AC%AC%E4%B8%100%E8%AF%BE%20Rust%E5%85%A5%E9%97%A8%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86(2)%20.pdf
Rust的三大学习难点: 宏,所有权与借用,xxx
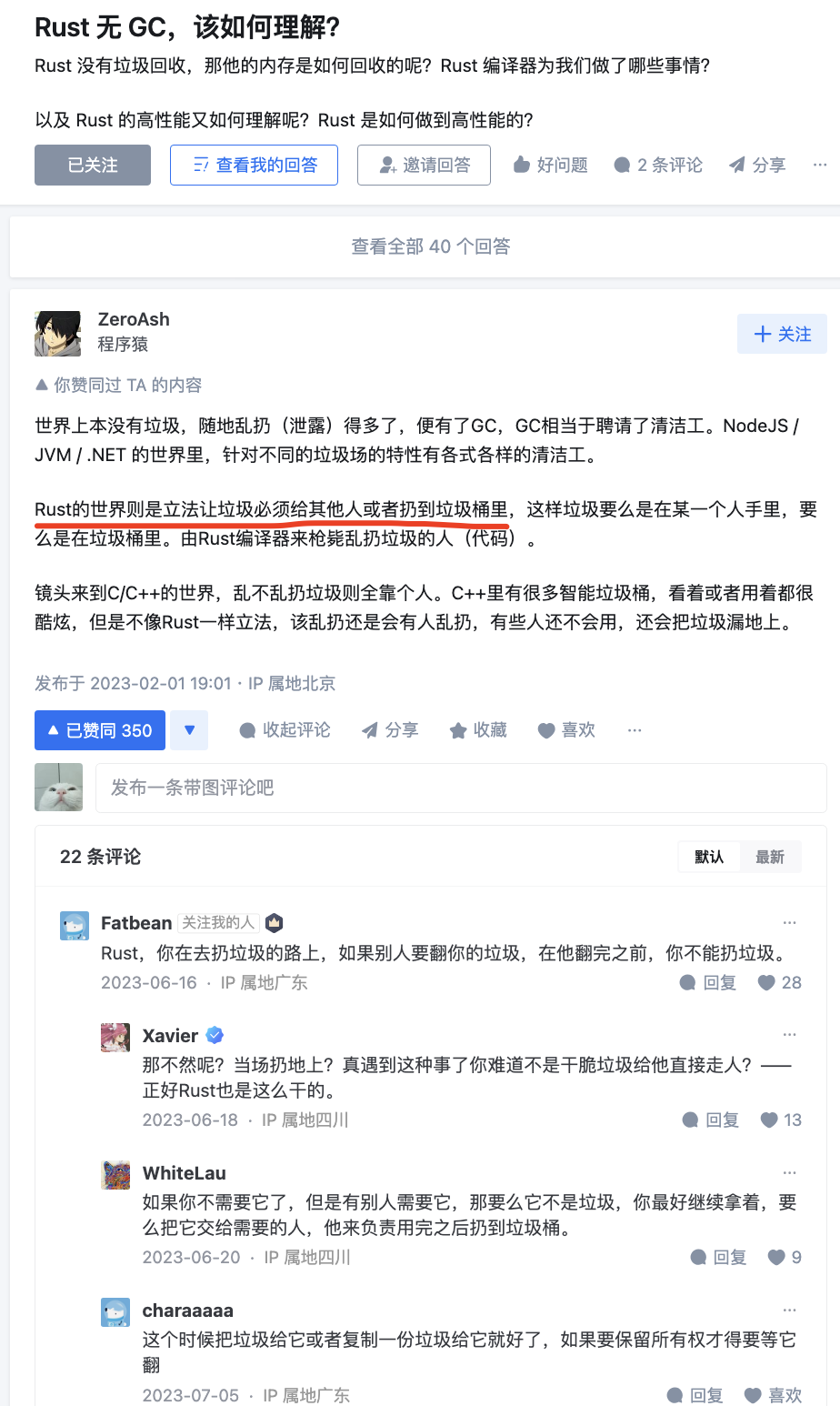
作⽤域:
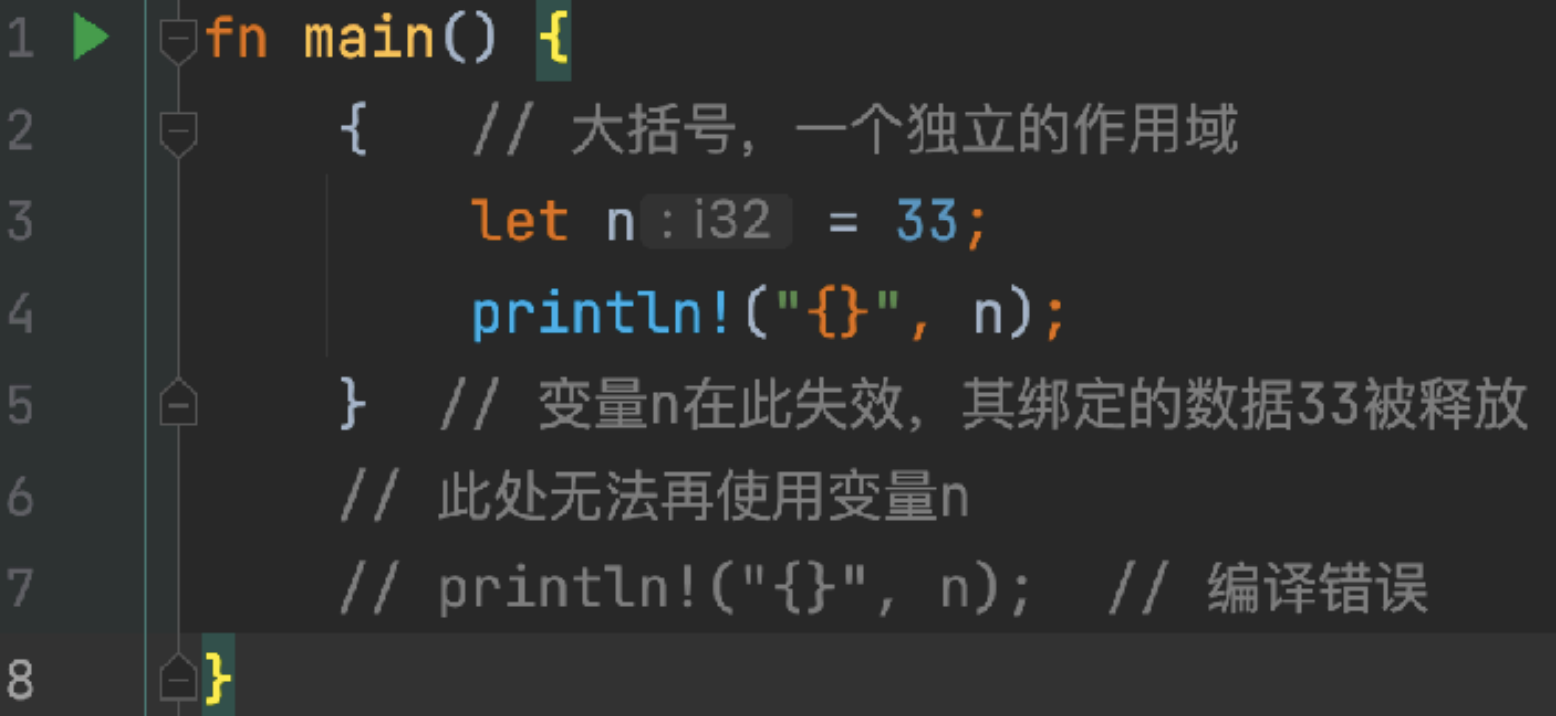
其实对于Go也是这样的
file:///Users/fliter/rust-in-databend/25-%E7%AC%AC%E4%B8%100%E8%AF%BE-rust%E5%85%A5%E9%97%A8%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86-1-rust%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/%E7%AC%AC%E4%B8%100%E8%AF%BE%20Rust%E5%85%A5%E9%97%A8.pdf


很难编写内存安全的代码
很难编写线程安全的代码
Rust 中默认是是移动语义。C++ 默认则是 Copy语义,直到 C++ 11 才引入 Move 移义。复制语义意味着得到是值的副本,两个变量之间其实并没有联系。至于移动语义,并不进行拷贝,而是进行了所有权的转移。Rust 由于它的类型系统是仿射类型系统,默认具有移动语义。仿射类型系统的一个突出的特点就是值或者资源只能用一次。
如果 Rust 只有移动语义,有时就有一定的局限性。因此,Rust 提供了 Copy trait 来实现 Copy 语义。
Rust 借鉴了很多语言,比如Cyclone(一种安全的C语言方言)的基于区域的内存管理模型;C++ 的RAII 原理;Haskell 的类型系统、错误处理类型、typeclasses等等。Rust 有非常小的 runtime,不需要垃圾回收,默认情况下是在栈上进行分配内存,而不是堆上。Rust 的编译器 rustc,一开始使用 Ocaml (一种函数式语言)编写,后来在2011年 Rust 实现了自举。
版权声明:本文为CSDN博主「谷雨の梦」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/guyu2019/article/details/105132774
Rust 还有一个静态的生命周期,使用 ‘static 表示,Rust 中所有的字符串文本都是具有 static 的生命周期长度,意味着在程序的整个时间内都持续有效。
张汉东老师在 三万字 | 2021 年 Rust 行业调研报告中,
有Go基础:Go语言开发者比较容易理解Rust的类型和trait抽象模式,但Go也是GC语言,所以所有权机制和函数式语言特性是他们的学习重点。
1、Rust所有权机制,包括所有权的语义,生命周期和借用检查
所有权机制是Rust语言最核心的特性,它保证了在没有垃圾回收机制下的内存安全,所以对于习惯了GC的开发者,理解Rust的所有权是最关键的一环,切记这三点:
Rust中的每一个值都有一个被称为其所有者 (owner)的变量。
值有且只有一个所有者。
当所有者(变量)离开作用域,这个值将被丢弃。这其中又涉及到生命周期和借用检查等概念,是相对比较难啃的一块硬骨头。
https://www.bilibili.com/video/BV1564y1177A?t=2333
编程语言的变革者
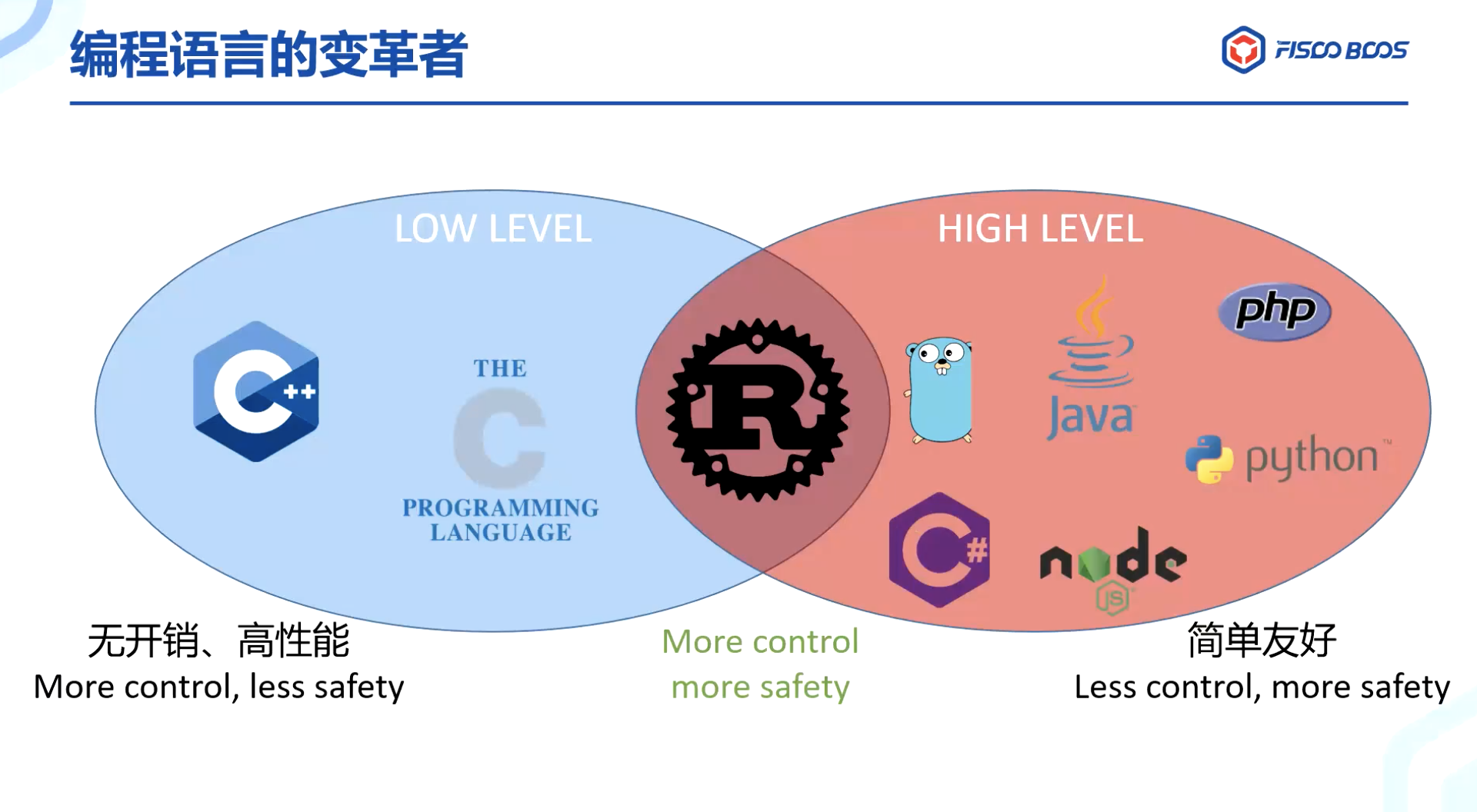
Ada语言,当时很先进,但没有流行起来
汲取百家之长, 近些年来, 所有编程语言思想的集大成者

编译期就能检测出大多数问题,而无需等到运行时才发现
锈菌,生命力顽强,5种孢子
Robust+Trust=Rust
设计

目前内存三大问题:
悬垂指针(野指针),Use after free,Double free
指一个指针指向一个已经释放的内存块– 依靠所有权和生命周期机制解决
RAII(资源获取即初始化),C缺少这种机制,C++有

Rust将堆上的数据视为资源,每个资源都只能拥有唯一的所有者 (解决了Double free问题)
能够从资源的所有者处借用资源 (只有使用权,没有所有权)
当资源被其他代码借用时,资源的所有者不可以释放资源或修改资源 (第2点和第3点结合,一定程度保证了不会有悬垂指针的问题,即指针不会指向无效区域)
(整数比较特殊)

-

借用规则:
可变借用&mut 和只读(共享)借用& (类似mysql的共享锁和排它锁)
彻底解决了悬垂指针的问题


可变借用 &mut:我能拿到你的指针,而且可以通过你的指针进行数据的修改. (去掉了Aliasing,保留了Mutation)

可变性:

生命周期
即 变量作用域的长度

和大多数语言不一样…
数据构建和析构的顺序
如果在同一样中声明两个变量,那它们的声明周期是一样的。但如果之间存在依赖关系,编译器会报错

拒绝迭代器失效


其实是一种误报

解决并发安全问题
借用 + 生命周期 = 痛苦之源

借用 + 生命周期 保证了程序不会有内存问题~
泛型与Trait
Trait的作用
接口抽象(类似Go的interface)
泛型参数约束 (传入了泛型,必须具有xx特征,起到泛型参数约束的效果。)
类型标签(Copy,Clone) (不关心具体类型,只要事现这个特征就行了~ 即鸭子类型)
抽象类型
数据竞争: 线程安全的一生之敌




闭包,静态生命周期:
Unsafe

 所有权:Rust 语言内存安全机制
所有权:Rust 语言内存安全机制
Rust 的设计深深地吸取了关于安全系统编程的学术研究的精髓。特别是,与其他主流语言相比,Rust 设计的最大特色在于采用了所有权类型系统(在学术文献中通常称为仿射或子结构类型系统36[10])。
所有权机制,就是Rust 语言借助类型系统,承载其“内存安全”的思想,表达出来的安全编程语义和模型。
所有权机制要解决的内存不安全问题包括:
引用空指针。
使用未初始化内存。
释放后使用,也就是使用悬垂指针。
缓冲区溢出,比如数组越界。
非法释放已经释放过的指针或未分配的指针,也就是重复释放。
注意,内存泄露不属于内存安全问题范畴,所以 Rust 也不解决内存泄露问题。
为了保证内存安全,Rust 语言建立了严格的安全内存管理模型:
所有权系统。每个被分配的内存都有一个独占其所有权的指针。只有当该指针被销毁时,其对应的内存才能随之被释放。
借用和生命周期。每个变量都有其生命周期,一旦超出生命周期,变量就会被自动释放。如果是借用,则可以通过标记生命周期参数供编译器检查的方式,防止出现悬垂指针,也就是释放后使用的情况。
其中所有权系统还包括了从现代 C++ 那里借鉴的 RAII 机制,这是 Rust 无 GC 但是可以安全管理内存的基石。
建立了安全内存管理模型之后,再用类型系统表达出来即可。Rust 从 Haskell 的类型系统那里借鉴了以下特性:
没有空指针
默认不可变
表达式
高阶函数
代数数据类型
模式匹配
泛型
trait 和关联类型
本地类型推导
为了实现内存安全,Rust 还具备以下独有的特性:
仿射类型(Affine Type),该类型用来表达 Rust 所有权中的 Move 语义。
借用、生命周期。
借助类型系统的强大,Rust 编译器可以在编译期对类型进行检查,看其是否满足安全内存模型,在编译期就能发现内存不安全问题,有效地阻止未定义行为的发生。
内存安全的 Bug 和并发安全的 Bug 产生的内在原因是相同的,都是因为内存的不正当访问而造成的。同样,利用装载了所有权的强大类型系统,Rust 还解决了并发安全的问题。Rust 编译器会通过静态检查分析,在编译期就检查出多线程并发代码中所有的数据竞争问题。
请问Rust的所有权和借用系统是如何确保内存安全的?
Rust 的所有权和借用系统是其核心特性之一,它们共同努力确保内存安全性。下面是 Rust 的所有权和借用系统如何工作的概述:
所有权(Ownership):在 Rust 中,每个值都有一个所有者。所有权规则确保每个值只有一个有效的所有者,并负责在其所有者范围结束时自动释放该值所占用的内存。当所有权被转移或值超出范围时,内存将被自动释放,避免了内存泄漏。
移动语义(Move Semantics):Rust 的所有权规则使得所有权可以被移动,而不是简单地进行复制。当将一个值赋给另一个变量或传递给函数时,所有权会从一个所有者转移到另一个所有者,原来的所有者将不再有效。这种机制避免了多个指针同时访问同一块内存,从而避免了悬垂指针和数据竞争等内存安全问题。
借用(Borrowing):Rust 的借用机制允许临时地借用一个值的引用,而不转移其所有权。借用规则确保借用引用的有效性,并在编译时检查借用的生命周期是否正确。借用可以是不可变的(immutable)或可变的(mutable),这取决于对借用引用的可变性的限制。借用规则避免了数据竞争和多个可变引用同时访问相同数据的问题。
通过所有权和借用系统,Rust 在编译时进行严格的静态检查,以确保以下方面的内存安全:
- 悬垂指针(Dangling Pointers):Rust 禁止存在悬垂指针,即指向已释放的内存的指针。
- 野指针(Null Pointers):Rust 禁止存在空指针,即指向无效内存地址的指针。
- 数据竞争(Data Races):Rust 在编译时通过借用规则和所有权规则来避免多个线程同时访问和修改相同数据的问题,从而消除了数据竞争。
通过这些机制,Rust 的所有权和借用系统提供了内存安全性的保证,使得开发者可以编写更可靠和高效的代码,而无需依赖运行时的垃圾回收机制。
能否举个例子来说明Rust的所有权和借用系统是如何工作的?
当一个值被传递给函数或赋值给另一个变量时,Rust 的所有权和借用系统会确保内存安全。下面是一个简单的例子来说明这个过程:
1 | fn main() { |
在这个例子中,首先创建了一个 String 类型的值 s1,它拥有 "hello" 字符串的所有权。然后,通过将 s1 赋值给 s2,发生了所有权的转移。现在,s2 拥有了 "hello" 字符串的所有权,而 s1 不再有效。
如果你尝试在 println!("{}", s1); 行打印 s1,编译器会报错,因为 s1 不再拥有有效的值。
另外,Rust 的借用系统允许创建临时的借用引用,而不转移所有权。例如:
1 | fn calculate_length(s: &String) -> usize { |
在这个例子中,calculate_length 函数接收一个对 String 的借用引用 &String,而不是获取所有权。通过使用借用引用 &s 将 s 的引用传递给 calculate_length 函数,函数可以访问 s 的值,并返回其长度。
Rust 的借用规则确保了借用引用的有效性。在该示例中,借用引用的生命周期在 calculate_length 函数内部,因此在函数外部无法访问 s 的可变性或释放它的内存。
这些例子展示了 Rust 的所有权和借用系统如何确保内存安全性:所有权转移和借用引用的创建都受到编译时的静态检查,防止悬垂指针、空指针和数据竞争等内存安全问题的出现。
在Rust中,如何处理可变借用和不可变借用的生命周期问题?
在 Rust 中,可变借用和不可变借用的生命周期问题通常由 Rust 的借用检查器在编译时进行自动检查和解决。Rust 的借用规则确保了可变借用和不可变借用之间的正确使用,以避免数据竞争和悬垂引用等问题。
借用检查器会根据变量的生命周期来确定借用的有效范围,以确保借用的引用不会越过其有效期。在编写 Rust 代码时,需要按照借用规则进行操作,以避免编译错误。
下面是一些处理可变借用和不可变借用生命周期的常见情况:
同一作用域内的不可变借用和可变借用:在同一作用域内,不可变借用和可变借用不能同时存在。这是因为可变借用要求独占访问,而不可变借用允许共享访问。如果需要在同一作用域内同时使用可变借用和不可变借用,可以使用
RefCell、Mutex或RwLock等内部可变性机制。可变借用的有效范围不能超过不可变借用的有效范围:当存在一个不可变借用时,不能创建一个可变借用,因为可变借用要求对数据的独占访问。不可变借用的生命周期必须覆盖任何可能创建可变借用的代码路径。
不可变借用的有效范围可以超过可变借用的有效范围:当存在一个可变借用时,可以创建一个不可变借用。不可变借用只需要对数据的共享访问,不会对可变借用造成干扰。
不可变借用和可变借用的嵌套:可以在同一作用域内嵌套使用不可变借用和可变借用。嵌套的借用生命周期不能相互重叠,以避免悬垂引用的问题。
需要注意的是,这些只是一些常见情况的概述,实际的借用关系可能更复杂。在编写 Rust 代码时,建议遵循借用规则并使用适当的所有权和借用模式,如果编译器报告了借用检查错误,可以根据错误信息进行调整,以确保借用的正确使用。
Rust 的借用系统和生命周期规则是保证内存安全和线程安全的重要机制,它们在编译时提供了静态的安全保证,帮助开发人员避免常见的内存错误和并发问题。
悬垂指针和野指针 是一回事吗?
悬垂指针(Dangling Pointer)和野指针(Wild Pointer)虽然都是指针相关的错误类型,但它们指代的是两种不同的情况:
悬垂指针 (Dangling Pointer)
- 悬垂指针是指向已释放内存的指针。当内存(如堆分配的内存)被释放或删除后,指向该内存的指针仍然存在。如果程序后续尝试通过这个指针访问内存,就会发生未定义行为,因为该内存可能已被操作系统回收或重新分配给其他用途。
- 悬垂指针的产生通常是由于程序中的内存管理错误,例如在释放了动态分配的内存后没有将指针置为空,或者是在局部对象的生命周期结束后仍然保留了指向它的指针。
野指针 (Wild Pointer)
- 野指针是指未初始化的指针或指向随机内存地址的指针。这种指针的值是不确定的,通常是垃圾值。尝试通过野指针访问或修改数据可能会导致程序崩溃或产生不可预测的行为。
- 野指针的产生通常是由于指针声明后未被初始化,或者指针初始化时被赋予了随机值。
总结
- 悬垂指针:指向了已经释放的内存。
- 野指针:未被初始化,指向了不确定的内存地址。
两者都是编程中需要避免的危险情况,因为它们都可能导致程序的不稳定和安全漏洞。正确的内存管理和初始化是防止这些问题的关键。在现代编程语言中,如Rust,通过所有权和借用规则,可以有效避免这类问题。在C或C++等语言中,开发者需要更加小心地管理内存和指针的使用。
请问Rust的所有权和借用系统如何处理可变引用?
在 Rust 的所有权和借用系统中,可变引用是一种特殊类型的借用引用,允许对值进行修改。可变引用与不可变引用的主要区别在于是否允许修改被引用的值。
下面是一些关于可变引用的要点:
不可变引用与可变引用的共存性:在 Rust 中,同一作用域中可以同时存在多个不可变引用,但不可同时存在多个可变引用。这是为了避免数据竞争,确保在给定时间只有一个引用可以修改数据。
可变性的借用规则:可变引用的创建受到一些借用规则的限制。例如,如果存在可变引用,则不能再创建对同一数据的不可变引用,以防止并发修改。这种限制确保了数据的唯一性,并防止悬垂指针的出现。
可变引用的生命周期:可变引用的生命周期受到与不可变引用相同的规则限制。当一个可变引用存在时,原始所有者无法修改或销毁与之相关的值,直到所有可变引用都离开作用域。
下面是一个简单的示例来说明可变引用的使用:
1 | fn add_one(nums: &mut Vec<i32>) { |
在这个例子中,add_one 函数接收一个可变引用 &mut Vec<i32>,并在循环中修改被引用的值。在 main 函数中,通过创建可变引用 &mut numbers,将 numbers 的可变引用传递给 add_one 函数。函数内部的循环逐个增加了 numbers 中的元素。最后,打印 numbers 的值,可以看到它已经被修改为 [2, 3, 4, 5, 6]。
通过使用可变引用,Rust 的所有权和借用系统在编译时确保了对数据的安全修改。在给定时间,只有一个可变引用可以访问和修改数据,避免了数据竞争和悬垂指针等内存安全问题。
能否举个例子来说明Rust的所有权和借用系统如何处理多个借用引用的情况?
当涉及到多个借用引用时,Rust 的所有权和借用系统会确保不会出现数据竞争、悬垂引用或其它不安全的情况。下面是一个示例来说明这一点:
1 | fn main() { |
在上面的示例中,首先创建了一个可变的 data 向量,然后通过两个不可变借用 borrow1 和 borrow2 分别引用了 data。随后,创建了一个可变借用 borrow3,用于修改 data 向量中的元素。
Rust 的借用规则确保了以下情况:
不可变借用
borrow1和borrow2可以同时存在,因为它们只是共享访问数据,不会引起竞争问题。可变借用
borrow3在存在不可变借用的同时是不允许的,因为可变借用要求对数据的独占访问。在创建borrow3之前,必须确保borrow1和borrow2的引用范围已经结束。
在尝试修改 borrow1 引用的值时,编译器会报错,因为这违反了不可变借用的规则。这是 Rust 借用系统的静态检查所发现的错误。
通过 Rust 的所有权和借用系统,可以在编译时捕获潜在的错误情况,避免了数据竞争和悬垂引用等常见的内存安全问题。通过借用检查器的工作,确保了借用引用的生命周期正确、不重叠和不冲突,从而保障了 Rust 代码的安全性和可靠性。
请问Rust的所有权和借用系统如何处理引用的生命周期?
在 Rust 中,生命周期是用于描述引用的有效范围的一种机制。它是一种静态的、编译时的概念,用于确保引用是有效的,以避免悬垂引用和数据竞争等问题。
Rust 的借用检查器使用生命周期来推断引用的有效范围,并根据生命周期规则进行验证。这些规则确保了引用在其引用的数据有效存在的情况下进行操作。
在函数签名、结构体定义和方法定义中,可以使用生命周期参数来标注引用的生命周期。生命周期参数使用撇号(’)后跟标识符的方式表示,如 'a、'b 等。
下面是一个简单的示例来说明生命周期参数的使用:
1 | fn main() { |
在上面的示例中,calculate_length 函数接受一个引用 s,该引用具有生命周期标注 'a,表示它的有效范围。
在主函数中,我们创建了一个 String 类型的变量 s1,然后将它的引用传递给 calculate_length 函数。在函数内部,我们可以使用引用 s 访问 String 类型的数据,并返回它的长度。
Rust 的借用检查器会根据生命周期参数 'a 推断 s 引用的有效范围。在这个例子中,s 引用的有效范围是函数调用期间,即从函数调用开始到函数返回为止。
通过生命周期参数的使用,Rust 的借用检查器可以进行静态的生命周期检查,确保引用的有效性,并在编译时捕获潜在的错误。这有助于避免悬垂引用、数据竞争和其他生命周期相关的问题,提高了代码的安全性和可靠性。
能否举一个更复杂的例子来说明生命周期参数的使用?
当涉及到更复杂的情况时,生命周期参数的使用可以帮助我们明确引用之间的关系和有效范围,以便进行正确的借用。
以下是一个示例,展示了生命周期参数在结构体和方法定义中的使用:
1 | struct Context<'a> { |
在上面的示例中,我们定义了一个名为 Context 的结构体,它具有一个生命周期参数 'a。结构体内部的 data 字段是一个引用,其生命周期与结构体的生命周期相关联。
在 Context 结构体的实现中,我们定义了一个 new 方法,它接受一个引用 data,并使用生命周期参数 'a 来标注引用的生命周期。在方法内部,我们创建了一个 Context 结构体并返回。
print_data 方法接受 self 的不可变借用,并打印 data 字段的值。
在 main 函数中,我们创建了一个 String 类型的变量 data。然后,我们在一个作用域内创建了一个 Context 结构体的实例 context,并将 data 的引用传递给它。
在作用域内,我们调用了 context 的 print_data 方法,打印了 data 字段的值。在这个作用域结束后,context 的生命周期也结束,因此它不再持有对 data 的引用。
最后,我们尝试打印 data 的值。由于 context 的生命周期已结束,data 不再被借用,因此可以正常地打印出其值。
通过使用生命周期参数,我们可以明确引用的生命周期关系,以及在不同作用域中进行正确的借用和释放。这有助于避免悬垂引用和生命周期相关的错误,并确保代码的安全性和正确性。
你能解释一下生命周期参数的悬垂引用问题吗?
当涉及到生命周期参数时,理解和避免悬垂引用是非常重要的。
悬垂引用是指在程序中持有对已被释放的数据引用的情况。当一个引用的生命周期超过了其引用的数据的生命周期时,就会出现悬垂引用问题。
Rust 的生命周期参数可以帮助编译器分析和验证引用的生命周期,以确保不会产生悬垂引用。
下面是一个示例,展示了悬垂引用问题以及如何使用生命周期参数来解决它:
1 | fn main() { |
在上面的示例中,我们定义了一个函数 dangling_reference,它创建了一个 String 类型的变量 data,并返回对它的引用 &data。
然而,由于data是在函数内部创建的,当函数返回后,data 将被释放,而返回的引用 &data 将成为悬垂引用。这是因为引用的生命周期超过了 data 的生命周期。
为了解决这个问题,我们可以使用生命周期参数来明确引用的生命周期,以确保引用不会超过其引用的数据的生命周期。
以下是修复悬垂引用问题的示例代码:
1 | fn main() { |
在上面的示例中,我们将函数 dangling_reference 改为返回 String 类型的值而不是引用。这样,函数返回的是拥有所有权的 String 值,而不是对已释放数据的引用。这样就避免了悬垂引用问题。
总之,生命周期参数在 Rust 中用于明确引用的有效范围,帮助编译器进行静态生命周期检查,以确保不会出现悬垂引用问题。通过正确使用生命周期参数,可以保证引用在其引用的数据有效存在的情况下进行操作,从而提高代码的安全性和可靠性。
请问Rust的所有权和借用系统对于多线程编程有什么影响?
Rust 的所有权和借用系统在多线程编程中起到了关键的作用,帮助开发者编写安全且无数据竞争的并发代码。
在传统的多线程编程中,共享的可变数据可能导致数据竞争,即多个线程同时读写同一块数据,从而导致未定义行为。为了避免这种情况,传统的编程语言通常使用锁(如互斥锁)来保护共享数据,但这种方式容易引入死锁、竞争条件等问题。
Rust 的所有权和借用系统通过在编译时强制执行规则,确保多线程代码的安全性。以下是 Rust 的一些特性和机制对多线程编程的影响:
Send 和 Sync trait:Rust 中的类型需要满足 Send 和 Sync trait 才能在多线程间进行安全的共享。Send trait 表示类型可以安全地在线程间传递所有权,Sync trait 表示类型可以安全地被多个线程引用(不可变借用)。这些 trait 的约束确保了在多线程环境中不会发生数据竞争。
线程安全的标准库:Rust 的标准库提供了许多线程安全的数据结构和同步原语,如原子类型(Atomic types)、互斥锁(Mutex)和条件变量(Condvar)。这些工具可以帮助开发者编写并发代码,保证数据的安全性和正确性。
原生线程支持:Rust 提供了原生的线程支持,可以创建和管理线程。通过使用 Rust 的线程 API,可以安全地在多个线程之间传递所有权,并进行数据共享和通信。
消息传递和通道:Rust 的通道(channel)机制允许线程之间通过发送和接收消息来进行通信。通过通道,可以实现多个线程之间的同步和数据传递,而无需显式地使用锁和共享数据。
综上所述,Rust 的所有权和借用系统为多线程编程提供了安全、高效的解决方案。它通过在编译时进行静态分析和检查,确保线程间的数据共享和操作是正确的、无数据竞争的。这使得开发者能够编写高性能、可靠的并发代码,而不必担心常见的多线程问题。
请问在Rust中,可变引用和不可变引用的创建和使用有哪些具体的规则?
在 Rust 中,可变引用和不可变引用的创建和使用受到一些具体的规则限制,以确保内存安全。以下是关于可变引用和不可变引用的创建和使用的一些规则:
不可变引用规则:
- 在给定作用域中,可以同时存在多个不可变引用。
- 不可变引用与其他不可变引用之间可以共存。
- 不可变引用与可变引用之间不能共存,以防止数据竞争。
可变引用规则:
- 在给定作用域中,只能存在一个可变引用。
- 可变引用与不可变引用之间不能共存,以防止数据竞争。
- 可变引用不允许进行其他引用(无论是可变引用还是不可变引用)直到其生命周期结束。
引用的生命周期规则:
- 引用的生命周期是指引用的有效期限,它受限于引用的创建和使用的作用域。
- 引用的生命周期必须与被引用的数据的生命周期相匹配,以确保引用不会引用无效的数据。
- 引用的生命周期也受限于引用的包含作用域,不能超出其作用域范围。
值得注意的是,Rust 的所有权和借用系统在编译时静态检查这些规则,以保证代码的内存安全性。如果违反了这些规则,编译器将产生错误并拒绝编译代码。
这些规则确保在给定时间段内,对于特定的数据,只有一个可变引用或多个不可变引用存在,以防止数据竞争和悬垂指针问题。这使得 Rust 能够提供内存安全性和线程安全性,而无需使用垃圾回收或运行时开销。
在Rust中,可变引用和不可变引用的生命周期是如何确定的?
在 Rust 中,可变引用和不可变引用的生命周期是由引用的作用域和引用的创建方式确定的。Rust 的借用检查器会在编译时进行静态分析,以确保引用的有效性和生命周期的正确性。
下面是一些确定可变引用和不可变引用生命周期的原则:
引用的作用域:引用的生命周期受限于引用的作用域。引用只在其作用域内有效,超出作用域后引用将不再有效。作用域可以是函数、代码块或函数参数等。
引用的创建方式:引用的生命周期取决于引用的创建方式。引用可以通过函数参数传递、赋值操作或方法调用等方式创建。
引用与被引用数据的生命周期关联:引用的生命周期必须与被引用数据的生命周期相匹配。引用不能超过被引用数据的生命周期,以防止引用无效的数据。
- 对于不可变引用,它可以与具有更长生命周期的数据一起存在,因为不可变引用不会修改数据。
- 对于可变引用,它必须是数据的唯一可变引用,因为同时存在的可变引用可能导致数据竞争。
Rust 编译器会根据这些原则进行借用检查,确保引用的有效性和生命周期的正确性。如果引用的生命周期不符合这些原则,编译器会产生错误,阻止代码的编译。
通过这种方式,Rust 的所有权和借用系统能够在编译时保证引用的安全性,避免了悬垂指针、数据竞争和其他内存安全问题的出现。
在Rust中,可变引用和不可变引用的生命周期有什么具体的例子吗?
在 Rust 中,可变引用和不可变引用具有不同的生命周期限制。下面是一些具体的例子,用于说明可变引用和不可变引用的生命周期。
- 可变引用的生命周期限制:
1 | fn main() { |
在上面的示例中,我们创建了一个 String 类型的变量 data,然后在一个作用域内创建了一个可变引用 reference 来借用 data。在 reference 的作用域内,我们可以通过 reference 修改 data 的值。
- 不可变引用的生命周期限制:
1 | fn print_data(reference: &str) { |
在上面的示例中,我们定义了一个函数 print_data,它接受一个不可变引用 reference 来借用一个字符串切片。在 main 函数中,我们创建了一个 String 类型的变量 data,并将其不可变引用传递给 print_data 函数。
在 print_data 函数的作用域内,我们可以使用不可变引用 reference 访问 data 的值,但不能修改它。在函数调用结束后,reference 的生命周期结束,data 可以再次被借用。
这些示例说明了可变引用和不可变引用的生命周期限制。可变引用允许对数据进行修改,但在引用的作用域内是独占的。而不可变引用允许共享访问数据,但不能修改数据。在 Rust 中,生命周期参数帮助编译器验证引用的有效性和正确性,以避免悬垂引用和数据竞争等问题。
在Rust中,如果我同时需要可变引用和不可变引用,该怎么处理?
在 Rust 中,同时需要可变引用和不可变引用是一个潜在的危险操作,因为它可能导致数据竞争。为了确保内存安全,Rust 的借用规则禁止在同一作用域中同时存在可变引用和不可变引用。
如果确实需要同时使用可变引用和不可变引用,并且可以确定它是安全的,Rust 提供了一种叫做RefCell的标准库类型来实现内部可变性(Interior Mutability)。
RefCell 允许在运行时进行借用检查,而不是在编译时。它使用了运行时的借用规则追踪引用的借用和释放,从而允许在运行时动态地检查借用规则。使用 RefCell,可以在同一作用域内同时存在可变引用和不可变引用,但是在运行时会进行动态的借用检查。
下面是一个使用 RefCell 的示例:
1 | use std::cell::RefCell; |
在这个示例中,通过 RefCell::new 创建了一个包含可变数据的 RefCell 对象 shared_data。然后,使用 borrow 方法获取了不可变引用 immutable_ref 和可变引用 mutable_ref,并分别进行了打印和修改操作。
需要注意的是,如果在同一作用域内获取了可变引用,就不能再获取不可变引用,否则会在运行时产生 panic。这是因为 RefCell 在运行时动态检查借用规则,如果违反了规则,会导致程序崩溃。
使用 RefCell 需要谨慎,需要确保在运行时的借用检查中不会出现数据竞争。否则,如果存在数据竞争,程序仍然会产生未定义行为或崩溃。因此,只有在确保安全的情况下才应该使用 RefCell 来同时使用可变引用和不可变引用。
我可以在同一作用域内同时获取多个不可变引用吗?
在 Rust 中,可以在同一作用域内同时获取多个不可变引用,前提是这些引用不会同时修改数据。
这是因为 Rust 的借用规则允许多个不可变引用同时存在,因为不可变引用本身并不会引起数据竞争。多个不可变引用可以同时读取数据,因为读取操作是安全的,不会改变数据的状态。
以下是一个示例:
1 | fn main() { |
在上面的示例中,我们创建了一个 String 类型的变量 data,然后同时创建了两个不可变引用 reference1 和 reference2,它们都指向 data。
这是安全的,因为这两个引用都是只读的,不会修改数据。它们可以同时存在于同一作用域中。
然而,需要注意的是,当存在不可变引用时,不能同时存在可变引用,因为可变引用是独占访问,不允许其他引用同时存在。
以下是一个不允许的示例:
1 | fn main() { |
在上面的示例中,我们尝试同时创建一个不可变引用 reference1 和一个可变引用 reference2,这是不允许的,会导致编译错误。
总结起来,Rust 允许在同一作用域内同时获取多个不可变引用,因为不可变引用之间的读取操作是安全的。这种机制使得多个引用可以同时访问共享数据,而不会引起数据竞争。
RefCell在运行时如何检查借用规则?
抱歉,我在之前的回答中有误导性的描述。实际上,RefCell 并不是在运行时进行借用检查的,而是在运行时进行借用检查的追踪和错误处理。Rust 的借用检查是在编译时进行的,而不是在运行时。
RefCell 提供了两个方法用于获取引用:borrow 和 borrow_mut。这两个方法在运行时进行了借用规则的追踪,但并没有动态地检查借用规则。相反,它们使用了内部的借用计数和运行时的错误处理机制来确保借用规则的正确性。
具体来说,当调用 borrow 或 borrow_mut 方法时,它们会检查 RefCell 的内部状态。如果已经存在可变引用或在不可变引用的情况下尝试获取可变引用,borrow 和 borrow_mut 方法会引发运行时错误,即 panic。这是由 RefCell 的实现在运行时进行的检查,而不是编译时的静态检查。
这种运行时的错误处理机制允许在某些情况下同时使用可变引用和不可变引用,但在违反借用规则的情况下,会在运行时产生 panic。
总结起来,RefCell 通过使用运行时的错误处理机制来追踪和处理借用规则的违反,但并不动态地检查借用规则。Rust 的借用检查是在编译时进行的,而 RefCell 提供了一种在特定情况下绕过编译时借用检查的机制。但是,使用 RefCell 仍然需要谨慎,以确保在运行时的借用追踪中不会出现数据竞争或其他错误。
除了RefCell,还有其他方法可以实现同时使用可变引用和不可变引用吗?
除了 RefCell,还有一种在某些情况下可以实现同时使用可变引用和不可变引用的方法,那就是使用 Mutex 或 RwLock。
Mutex:std::sync::Mutex是 Rust 标准库中提供的互斥锁类型,用于实现在多线程环境中对共享数据的访问控制。它允许在同一时刻只有一个线程持有锁,并可以获取可变引用或不可变引用。获取可变引用时,其他线程将被阻塞,直到该线程释放锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16use std::sync::Mutex;
fn main() {
let shared_data = Mutex::new(vec![1, 2, 3]);
{
let immutable_ref = shared_data.lock().unwrap();
println!("Immutable reference: {:?}", immutable_ref);
}
{
let mut mutable_ref = shared_data.lock().unwrap();
mutable_ref.push(4);
println!("Mutable reference: {:?}", mutable_ref);
}
}在上面的示例中,通过
Mutex::new创建了一个包含可变数据的Mutex对象shared_data。使用lock方法获取锁,并分别获取了不可变引用immutable_ref和可变引用mutable_ref,然后进行了打印和修改操作。``Mutex
在获取可变引用时会阻塞其他线程的访问,以确保数据的独占访问。这样可以在同一作用域内同时获取可变引用和不可变引用,但需要注意在使用lock` 方法时要处理可能的错误。RwLock:std::sync::RwLock是 Rust 标准库中提供的读写锁类型,用于实现在多线程环境中对共享数据的读写控制。它允许多个线程同时持有读锁(不可变引用),但只允许一个线程持有写锁(可变引用)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16use std::sync::RwLock;
fn main() {
let shared_data = RwLock::new(vec![1, 2, 3]);
{
let immutable_ref = shared_data.read().unwrap();
println!("Immutable reference: {:?}", immutable_ref);
}
{
let mut mutable_ref = shared_data.write().unwrap();
mutable_ref.push(4);
println!("Mutable reference: {:?}", mutable_ref);
}
}在上面的示例中,通过
RwLock::new创建了一个包含可变数据的RwLock对象shared_data。使用read方法获取读锁(不可变引用)并获取不可变引用immutable_ref,使用write方法获取写锁(可变引用)并获取可变引用mutable_ref。然后进行了打印和修改操作。``RwLock` 允许在同一作用域中同时获取多个读锁,但只允许一个写锁。这样可以在某些情况下实现同时使用可变引用和不可变引用。
需要注意的是,Mutex 和 RwLock 是用于多线程环境的同步原语,适用于在多线程环境中控制对共享数据的访问。在单线程环境下,使用 RefCell 是更常见的选择。同时,在使用 Mutex 或 RwLock 时,需要注意正确处理可能的错误和锁定时间过长的问题,以避免潜在的性能问题或死锁情况的发生。
在Rust中,有没有什么常见的错误会导致引用的生命周期不匹配?
在 Rust 中,有一些常见的错误会导致引用的生命周期不匹配。这些错误可能导致编译时错误或悬垂引用,从而导致程序的行为不正确或崩溃。以下是一些常见的错误情况:
- 引用的作用域超出变量的生命周期:
这种情况发生在将引用传递到超出其引用的变量有效的作用域的函数或代码块中。这将导致编译时错误,因为引用的生命周期超过了被引用变量的生命周期。
1 | fn get_reference() -> &String { |
在上面的示例中,函数 get_reference 尝试返回对局部变量 data 的引用,但 data 的生命周期在函数结束后就结束了,因此返回的引用会导致悬垂引用错误。
- 引用的生命周期不足以满足需求:
这种情况发生在引用的生命周期不足以满足其使用的需求,例如,将引用传递给一个拥有更长生命周期的函数或数据结构。
1 | struct Example<'a> { |
在上面的示例中,我们尝试将一个临时字符串 temporary 的引用传递给结构体 Example 的字段,但是 temporary 的生命周期在创建 Example 实例后就结束了,无法满足结构体字段的要求。
- 引用的生命周期不正确地延长:
这种情况发生在错误地延长引用的生命周期,例如,将引用存储在持有更长生命周期的数据结构中。
1 | fn main() { |
在上面的示例中,我们将局部变量 data 的引用存储在 reference 中,但是在 reference 被使用时,data 已经超出了作用域,引用的数据不再有效,会导致悬垂引用错误。
这些是一些常见的错误情况,可能导致引用的生命周期不匹配。Rust 的借用检查器会在编译时检测这些错误,并阻止代码编译通过,确保引用的生命周期满足正确的规则,从而避免悬垂引用和其他相关问题。
在Rust中,可变引用的生命周期受到哪些限制?
在 Rust 中,可变引用的生命周期受到以下限制:
- 可变引用的生命周期不能超过其所借用的变量的生命周期:
可变引用必须在其借用的变量仍然有效的情况下使用。如果可变引用的生命周期超过了借用变量的生命周期,将导致编译时错误。
1 | fn main() { |
在上面的示例中,我们尝试将可变引用 reference 指向临时字符串 temporary。然而,temporary 的生命周期在包含它的代码块结束后就结束了。因此,将 reference 用于修改数据是不允许的,会导致编译时错误。
- 可变引用的生命周期与其他引用之间存在互斥关系:
在同一作用域内,可变引用与任何其他引用(包括不可变引用)不能同时存在。这是因为可变引用的目的是独占地修改数据,而其他引用可能会读取或写入数据,这可能导致数据竞争。
1 | fn main() { |
在上面的示例中,我们尝试同时创建多个引用,其中包括不可变引用 reference1 和 reference2,以及可变引用 reference3。然而,这违反了 Rust 的借用规则,因为可变引用与其他引用之间存在互斥关系。
通过这些限制,Rust 的借用检查器确保了可变引用的正确使用。这有助于避免数据竞争和悬垂引用等问题,并提供了内存安全和线程安全的保证。
Rust的标准库中还有哪些线程安全的数据结构和同步原语?
Rust 的标准库提供了许多线程安全的数据结构和同步原语,以支持并发编程。以下是一些常见的线程安全数据结构和同步原语:
Arc<T>:Arc<T>(原子引用计数)是一个线程安全的智能指针,用于在多个线程之间共享所有权。它允许多个线程同时访问相同的数据,提供了引用计数的功能。Arc<T>通过原子操作追踪引用计数,确保线程安全。Mutex<T>:Mutex<T>(互斥锁)是一种同步原语,用于实现数据的互斥访问。它允许多个线程并发地访问数据,但一次只有一个线程可以拥有锁并修改数据。其他线程必须等待锁被释放后才能继续访问。RwLock<T>:RwLock<T>(读写锁)是一种同步原语,允许多个线程同时读取数据,但只有一个线程可以拥有锁并进行写操作。多个线程可以同时获取读锁,但只有当没有线程持有写锁时,才能获取写锁。Condvar:Condvar(条件变量)是一种同步原语,用于在线程之间进行条件等待和唤醒。它通常与Mutex<T>或RwLock<T>一起使用,用于实现复杂的线程同步和通信模式。Barrier:Barrier是一种同步原语,用于在多个线程之间进行同步。它允许多个线程在到达一个屏障点之前等待,并在所有线程都到达后同时继续执行。Atomic*类型:标准库还提供了一系列原子类型,如AtomicBool、AtomicIsize、AtomicUsize等。这些类型通过原子操作提供了线程安全的原子更新和访问,用于实现高效的并发编程。
这只是一小部分 Rust 标准库中的线程安全数据结构和同步原语。除了这些,还有其他许多用于并发编程的工具和数据结构,如信号量、通道(channel)、线程池等。Rust 的标准库提供了丰富的工具和抽象,使得编写线程安全的并发代码更加方便和可靠。
有没有其他的同步原语可以用于实现复杂的线程同步和通信模式?
除了 Rust 标准库提供的同步原语之外,还有其他的同步原语可以用于实现复杂的线程同步和通信模式。以下是一些常见的同步原语:
信号量(Semaphore):信号量是一种同步原语,用于控制对共享资源的访问。它可以用于限制同时访问某个资源的线程数量,并提供了计数机制来跟踪资源的可用性。
条件变量(Condition Variable):条件变量是一种同步原语,用于在线程之间进行条件等待和唤醒。它允许线程等待某个条件变为真,并在条件满足时进行通知或唤醒。
读写锁(Read-Write Lock):读写锁是一种同步原语,用于在读和写操作之间提供更细粒度的并发控制。它允许多个线程同时读取数据,但只有一个线程可以进行写操作。
事件(Event):事件是一种同步原语,用于线程之间的通信和同步。它可以用于线程等待某个事件的发生,并在事件发生时进行通知或唤醒。
互斥量(Mutex)的变体:除了标准库中的
Mutex<T>,还有其他类型的互斥量可以实现不同的同步和并发模式。例如,读写锁(RWLock)是一种与标准库的RwLock<T>类似的互斥量,但可能具有不同的性能特征或语义。
这些同步原语可以用于实现更复杂的线程同步和通信模式,例如生产者-消费者模式、多线程任务调度、并行算法等。具体使用哪种同步原语取决于程序的需求和所需的同步和并发模式。
能否举个例子来说明Rust的通道机制如何实现线程间的同步和数据传递?
当涉及线程间的同步和数据传递时,Rust 中的通道(channel)机制是一个强大的工具。通道提供了一种安全且高效的方式,用于在线程之间传递消息,并确保正确的同步。
下面是一个简单的示例,展示了如何使用 Rust 的通道来实现线程间的同步和数据传递:
1 | use std::sync::mpsc; |
在上面的示例中,我们首先使用 mpsc::channel 函数创建了一个通道。mpsc 是多个生产者(multiple producers)单个消费者(single consumer)的缩写,表示可以有多个线程向通道发送消息,但只有一个线程可以接收消息。
然后,我们创建了一个发送线程,通过调用 sender.send 方法将消息发送到通道中。在这个例子中,我们发送了一个字符串消息。
接下来,在主线程中,我们使用 receiver.recv 方法从通道接收数据。这个方法会阻塞主线程,直到有数据可用。一旦接收到数据,我们将其打印出来。
最后,我们使用 join 方法等待发送线程完成,以确保所有线程执行完毕。
通过通道,发送线程和接收线程可以在不共享内存的情况下进行安全的消息传递。通道提供了隐式的同步,确保发送线程和接收线程之间的顺序一致性。
需要注意的是,通道机制还提供了其他方法,如 send、try_send、recv_timeout、try_recv 等,用于满足不同的需求,并提供了更灵活的线程间通信方式。
通过使用通道,Rust 提供了一种简单且安全的方式来实现线程间的同步和数据传递,避免了数据竞争和共享内存带来的问题。
我可以使用通道机制在多个线程之间传递不同类型的数据吗?
是的,你可以使用通道机制在多个线程之间传递不同类型的数据。Rust 的通道(channel)机制是类型安全的,可以通过指定通道的类型来指定可以发送和接收的数据类型。
通道的类型由发送端(Sender)和接收端(Receiver)共同确定。发送端和接收端可以使用泛型来指定数据类型。例如,你可以创建一个通道,用于在不同线程之间传递整数和字符串:
1 | use std::sync::mpsc; |
在上面的示例中,我们使用 mpsc::channel 函数创建了一个通道,并通过泛型参数 Either<i32, String> 指定了可以发送和接收的数据类型。这里使用了 Either 枚举类型,它允许发送和接收整数或字符串。
发送线程将一个整数包装在 Either::Left 枚举变体中发送到通道,而接收线程从通道接收数据,并根据接收到的值进行模式匹配,打印出整数或字符串。
通过在通道的泛型参数中指定不同的数据类型,你可以在多个线程之间安全地传递不同类型的数据。通道机制会确保类型安全和线程间的同步。
需要注意的是,在接收端,你需要使用模式匹配或其他方式来处理不同类型的数据。你可以选择使用 Rust 提供的枚举类型、trait 对象或其他适合的方法来处理多态的数据传递。
聊⼀聊Rust⽣命周期参数
苏林
Datafuse
学习⽣命周期参数的意义是: 避免出现悬垂指针
file:///Users/fliter/rust-in-databend/22-%E8%81%8A%E4%B8%100%E8%81%8ARust%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F/%E8%81%8A%E4%B8%100%E8%81%8ARust%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F.pdf
什么是⽣命周期参数? 什么是晚限定和早限定?
生命周期参数在 Rust 中是一个重要的概念,用于管理内存和避免数据竞争。生命周期参数是用在函数和结构体上的,以表明引用在内存中保持有效的时间长短。生命周期参数是一种编译时机制,帮助 Rust 保证引用的有效性,防止悬挂引用或者数据竞争等问题。
例如,以下函数签名中的 'a 就是一个生命周期参数:
1 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str |
这个函数签名的意思是:有一个生命周期 'a,并且输入参数 x 和 y 的生命周期不得短于 'a,返回的字符串引用的生命周期也不得短于 'a。
至于晚限定(Late Binding)和早限定(Early Binding),这是在面向对象编程中经常遇到的一种概念,主要涉及到多态性和动态分派的实现方式。
早期绑定(Early Binding):也称为静态分派或静态绑定,是在编译时确定对象的方法或属性的。因为在编译阶段就确定了,所以可以优化性能,但它可能缺乏灵活性。C++ 和 Java 中的方法重载就是早期绑定的例子。
晚期绑定(Late Binding):也称为动态分派或动态绑定,是在运行时确定对象的方法或属性的。晚期绑定增加了程序的灵活性,因为可以在运行时动态地更改对象的行为。然而,这可能会带来一定的性能损失。C++ 和 Java 中的虚函数或接口方法就是晚期绑定的例子。
rust为什么需要生命周期? 编译器不能推断出来的吗?举个例子说明
Rust 的生命周期(Lifetime)是一种编译时检查,确保引用始终指向有效的内存。生命周期对于防止悬垂指针和确保内存安全非常关键,尤其是在多个引用和复杂作用域的情况下。
Rust 编译器确实会尝试推断引用的生命周期,但并非所有情况都能自动推断。特别是在涉及多个引用时,编译器可能无法确定哪个引用的生命周期应该被用来约束其他引用的生命周期。在这些情况下,Rust 需要显式的生命周期注解来帮助编译器理解引用之间的关系。
为什么需要生命周期
- 避免悬垂引用:确保引用不会指向已经被释放的内存。
- 多引用场景:在函数或结构体中使用多个引用时,需要清楚地表达它们之间的关系。
- 泛型代码的正确性:在泛型代码中,生命周期参数确保代码在不同的使用场景中仍然安全。
示例
假设有一个函数,它接受两个字符串切片的引用,并返回其中一个:
1 | fn select<'a>(first: &'a str, second: &'a str) -> &'a str { |
在这个例子中,select函数需要生命周期参数'a。这是因为它返回的引用可能是first或second中的一个,而编译器需要确保返回的引用不会比传入的任一引用活得更久。
不使用生命周期注解的话,编译器无法确定返回的引用与传入的两个引用之间的生命周期关系,因此可能无法保证返回的引用总是有效的。
通过显式指定生命周期'a,我们告诉编译器:所有这些引用都应具有相同的生命周期,并且返回的引用不能比任何一个参数的引用活得更长。
生命周期注解不会改变任何引用的实际生命周期,而是用于帮助编译器理解并验证引用的合法性。这是 Rust 静态借用检查的核心部分,是其能够提供内存安全保障的关键原因之一。
请举几个rust为什么需要生命周期更容易理解的例子
Rust 的生命周期(lifetime)是一个相对复杂但极其重要的概念,它有助于确保内存安全和避免悬挂引用(dangling references)。生命周期在 Rust 中用于追踪引用的有效期。理解生命周期的关键在于理解 Rust 如何通过编译时检查来管理内存和引用。以下是几个使生命周期更容易理解的例子:
函数中的引用参数:
设想一个函数,它接受两个字符串引用并返回其中一个。Rust 需要使用生命周期来确保返回的引用在函数外部仍然有效。1
2
3fn choose<'a>(first: &'a str, second: &'a str) -> &'a str {
if first.len() > second.len() { first } else { second }
}在这个例子中,
'a指示了first、second和返回值之间的生命周期是相同的。结构体中的引用:
当结构体中包含引用时,Rust 需要知道这些引用的生命周期,以确保结构体不会比其内部的引用存活得更久。1
2
3
4struct Book<'a> {
name: &'a str,
author: &'a str,
}这里,
'a保证了Book实例不会比它所引用的name和author存活得更久。生命周期省略规则(Lifetime Elision Rules):
Rust 有一些默认的生命周期推断规则。例如,如果一个函数有一个输入生命周期和一个输出生命周期,Rust 会假设它们是相同的。1
fn get_first_word(s: &str) -> &str { /*...*/ }
在这里,Rust 推断输入和输出引用具有相同的生命周期。
结构体方法中的生命周期:
当结构体方法使用了结构体中的引用时,生命周期参数确保方法的使用不会导致悬挂引用。1
2
3
4
5impl<'a> Book<'a> {
fn get_author(&self) -> &'a str {
self.author
}
}get_author方法返回一个与Book实例相同生命周期的引用。
通过这些例子,你可以看到 Rust 中生命周期的用途是确保引用在使用它们的上下文中保持有效,从而避免悬挂引用和其他常见的内存安全问题。这是 Rust 强大的内存安全保证的核心部分。
详细一点的完整的例子呢
当然可以。让我们通过一个更详细的例子来探索 Rust 中生命周期的概念。这个例子将包括定义结构体、实现方法,并在其中使用生命周期注解。
示例:图书管理系统
假设我们正在为一个图书管理系统编写代码。我们有一个 Book 结构体,其中包含书名和作者名,这两个字段都是字符串切片(&str)。我们还想实现一个函数,该函数接受两本书作为参数,并返回其中作者名字较长的那本书的引用。
步骤 1: 定义带有生命周期的结构体
首先,定义一个包含引用的 Book 结构体。由于结构体包含引用,我们需要为这些引用指定生命周期。
1 | struct Book<'a> { |
步骤 2: 实现比较书籍作者名长度的函数
接下来,我们实现一个函数,它比较两本书的作者名长度,并返回作者名较长的那本书的引用。
1 | fn longer_author<'a>(book1: &'a Book, book2: &'a Book) -> &'a Book<'a> { |
在这个函数中,'a 生命周期参数确保返回的 Book 引用不会超出 book1 和 book2 输入参数的生命周期。
步骤 3: 使用这些定义
最后,让我们看看这些定义是如何在实践中被使用的。
1 | fn main() { |
在这个例子中,我们创建了两个 Book 实例,并使用 longer_author 函数来确定哪个书的作者名字更长。由于 Rust 的生命周期注解,编译器能够确保在 longer_author 函数中返回的 Book 引用在 main 函数中仍然有效。
这个例子展示了如何在结构体、方法和函数中使用生命周期来确保内存安全。生命周期注解帮助 Rust 编译器理解不同引用之间的关系,以防止悬挂引用和其他内存安全问题。
太复杂了,不要用struct,用字符串或者向量,举一个完整的例子呢
了解了,让我们用一个简单的例子来解释 Rust 中生命周期的概念。我们将使用字符串切片(&str)作为参数的函数来展示生命周期的应用。
示例:比较两个字符串切片的长度
假设我们想编写一个函数,该函数接受两个字符串切片作为参数,并返回长度较长的那个字符串切片。
定义带有生命周期参数的函数
首先,我们定义一个函数,它比较两个字符串切片的长度,并返回长度较长的那个。为了保证返回的字符串切片在函数外部仍然有效,我们需要使用生命周期参数。
1 | fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str { |
在这个函数中,生命周期参数 'a 表示 s1 和 s2 的生命周期,并且返回值的生命周期也与 'a 相关联。这意味着返回的字符串切片不会比 s1 或 s2 存活得更久。
使用这个函数
现在我们可以使用这个函数来比较两个字符串切片的长度了。
1 | fn main() { |
在这个例子中,我们创建了两个 String 对象,然后将它们转换为字符串切片(&str)并传递给 longer 函数。由于我们使用了生命周期参数,编译器可以确保 result 变量在其使用范围内引用的字符串切片是有效的。
通过这个简单的例子,您可以看到 Rust 中生命周期参数是如何用来确保引用的有效性,从而避免内存安全问题,如悬挂引用。这是 Rust 强大内存安全保证的重要组成部分。
为什么需要<’a>? 不加会怎么样呢
在 Rust 中,生命周期参数(如 <'a>)用于指定引用的有效期。这是 Rust 为了确保内存安全和防止悬挂引用而引入的一项特性。当我们在函数签名中使用生命周期参数时,我们实际上是在告诉编译器:这些参数和返回值之间有某种生命周期的关系。
在您给出的例子中:
1 | fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str { |
生命周期注解 <'a> 表明了参数 s1 和 s2 以及返回值都共享同一个生命周期 'a。这意味着返回的字符串切片将不会比输入的字符串切片存活得更久。
不使用生命周期参数会怎样?
如果我们不在 longer 函数中使用生命周期参数,编译器将无法理解返回的引用(字符串切片)与输入参数的生命周期之间的关系。这可能会导致编译错误,因为 Rust 无法保证返回的引用在其使用上下文中是有效的。
尤其是在处理引用时,如果 Rust 无法确定引用的有效性,它会默认阻止可能存在的不安全操作。
举个不使用生命周期参数的例子:
1 | fn longer(s1: &str, s2: &str) -> &str { |
这段代码会导致编译错误。Rust 编译器无法推断返回的引用与输入参数的生命周期关系,因此无法保证返回的引用在使用时仍然有效。编译器需要明确的生命周期注解来保证代码的内存安全。
总结来说,Rust 中的生命周期注解不是多余的,而是为了确保代码的内存安全性和避免悬挂引用。这是 Rust 语言设计中的核心特性,用于保护程序在运行时不会遇到由于错误的内存访问引起的未定义行为。
为什么Rust要人为指明生命周期?
这个问题源自一个有趣的问答。提问者想知道为什么Rust需要开发者明确指定变量的生命周期,而不能由编译器自行推断。他理解生命周期的概念,但认为应用起来非常复杂。
提问者困惑的是:如果人可以根据给定的输入判断出生命周期,为什么Rust的编译器不能做到?特别是在一些看似显而易见的情况下,比如一个字符串切片来自另一个字符串切片时。
后续,提问者又补充了一个问题:为什么需要指定生命周期是Rust独有的?这是否与Rust使用所有权模型,而不是像其他语言那样使用垃圾回收有关?
这个问题引发了社区的热烈讨论,得到了许多回答。提问者对社区的支持表示感谢,并表示需要一些时间来消化这些信息,说明这个问题确实不太容易理解。
一个高赞回答简洁地指出:编译器在决定省略生命周期时,并不关心函数体的内容,只关注函数签名。这是设计上的选择,因为函数签名原则上应该涵盖函数的所有行为。
提问者对此表示理解,认为这类似于在函数签名中定义类型。但他仍然疑惑为什么只有Rust需要这样做,而其他语言不需要。他猜测这可能与Rust选择了所有权模型有关,在这种模型中,内存会在变量操作范围结束时立即释放,而不是使用垃圾回收。
另一个较长的回答对比了不同语言的内存管理方式:
C++具有类似的生命周期要求,但是隐式的。违反这些要求会导致未定义行为。
C#、Java等使用垃圾回收的语言倾向于将引用限制在堆上。由于堆上的内容只要存在引用就会一直存在,所以这是安全的。
Rust采用所有权模型,要求开发者显式指定变量的生命周期。编译器会严格检查生命周期是否正确,以防止悬垂指针等内存安全问题。
这个回答还指出,Rust明确避免跨函数边界隐式确定生命周期。虽然技术上可以进行整个系统的生命周期验证,但这会带来一些问题:
- 不可用于动态行为或未知生命周期的场景
- 验证通常需要在模块边界停止,难以涵盖程序全局
- 可能导致难以追踪的错误,看似无关的改动可能会引起其他地方的编译错误
回答还提到了生命周期省略这个例外情况。如果生命周期可以被编译器推断出来,就不需要显式标注。
最后一个回答补充了一个重要原因:如果Rust可以自动从函数体推断生命周期,那么函数体的任何改动都可能导致函数签名的改变。这意味着重构一个函数时,可能需要调整所有调用者,这会导致到处都是生命周期相关的问题。
总的来说,Rust要求人为指明生命周期是一种设计选择,旨在提高代码的安全性和可维护性,尽管这可能增加了一些复杂性。
20250810
好的,这是对视频《Rust 所有权精讲 (The Hard Way)》内容的详细整理,已为您转换成通顺的中文和 Markdown 格式。
Rust 所有权精讲笔记 (The Hard Way)
本笔记详细记录了视频中关于 Rust 核心概念——所有权的讲解,涵盖了其三大规则、内存管理机制(栈与堆)、以及所有权如何与数据移动、函数、引用和借用等概念相互作用。
1. 什么是所有权 (What is Ownership)?
所有权是 Rust 最核心和最独特的功能。它是一套 在编译期管理内存 的规则,旨在实现内存安全,而无需像 C++ 那样手动管理内存,也无需像 Java 或 Python 那样依赖垃圾回收器 (Garbage Collector)。
核心优势:
- 内存安全:从根本上杜绝了悬垂指针、数据竞争等常见的内存错误。
- 性能:由于内存管理在编译期完成,运行时没有垃圾回收带来的性能开销。
2. 内存基础:栈 (Stack) 与 堆 (Heap)
理解所有权,首先需要理解 Rust 如何组织内存:
- 栈 (Stack):
- 特点:后进先出 (LIFO),内存分配和释放非常快速。
- 存储内容:所有存储在栈上的数据都必须拥有 在编译期已知的、固定的大小。例如:整数 (
i32)、浮点数 (f64)、布尔值 (bool)、字符 (char)、元组 (如果其元素都是固定大小)。
- 堆 (Heap):
- 特点:内存分配和释放相对较慢,操作系统需要寻找一块足够大的空间来存放数据。
- 存储内容:存储 在编译期大小未知或可能发生变化 的数据。例如
String类型,因为字符串的长度可以动态改变。 - 工作方式:当向堆上请求内存时,系统会返回一个指向该内存地址的 指针 (Pointer)。这个指针本身是固定大小的,存储在栈上,它“指向”堆上的实际数据。
3. 所有权的三大规则
Rust 的所有权系统遵循以下三个核心规则:
- 每个值都有一个所有者 (Owner)。
- 一个值在同一时间只能有一个所有者。
- 当所有者离开其作用域 (Scope) 时,它所拥有的值将被丢弃 (Dropped),其占用的内存也会被自动释放。
4. 所有权转移 (Move Semantics)
这是理解所有权的关键。对于存储在 堆 上的数据(如 String),当它被赋给另一个变量时,并不会发生数据的“深拷贝”,而是 所有权的转移。
示例:
1 | let s1 = String::from("hello"); // s1 是 "hello" 的所有者 |
- 内存结构:
String类型包含三部分信息(都存储在栈上):指向堆上实际字符串内容的指针、长度 (len)、容量 (capacity)。 - 转移过程:当
s2 = s1时,仅仅是栈上的这三部分信息被按位复制给了s2。堆上的字符串数据本身没有被复制。为了防止“二次释放”(即s1和s2在离开作用域时都尝试释放同一块堆内存),Rust 会让s1立即失效。
5. 克隆 (Cloning):显式地创建深拷贝
如果你确实需要复制堆上的数据,而不是转移所有权,可以使用 .clone() 方法。
示例:
1 | let s1 = String::from("hello"); |
.clone()操作会在堆上分配新的内存,并将s1的内容完整地复制过去。这是一个相对耗费性能的操作。
6. 栈上的数据:拷贝 (Copy)
对于完全存储在 栈 上的数据(如 i32),情况则有所不同。
示例:
1 | let x = 5; // x 是 5 的所有者 |
CopyTrait:如果一个类型实现了Copy这个特殊的 Trait,那么在赋值时,它的值会被简单地复制,而不会发生所有权的转移。- 哪些类型实现了
Copy?- 所有的整数、浮点数、布尔值、字符类型。
- 只包含
Copy类型的元组。
- 注意:
String没有实现CopyTrait。任何需要分配堆内存的类型通常都不能实现Copy。
7. 所有权与函数
将值传递给函数,或从函数返回值,同样遵循所有权规则。
- 传值给函数:
- 对于实现了
Copy的类型,是 按值拷贝。 - 对于没有实现
Copy的类型(如String),是 所有权转移。
1
2
3
4
5
6
7fn takes_ownership(some_string: String) { // some_string 获得所有权
println!("{}", some_string);
} // some_string 离开作用域,内存被释放
let s = String::from("hello");
takes_ownership(s); // s 的所有权被转移到函数内
// println!("{}", s); // 编译失败,s 已失效 - 对于实现了
- 从函数返回值:函数可以将其创建的值的所有权返回给调用它的作用域。
8. 借用与引用 (Borrowing and References)
如果我们希望在不转移所有权的情况下,让函数或其他变量能够访问某个值,就可以使用 引用 (References),这个过程被称为 借用 (Borrowing)。
- 不可变引用 (
&):允许你“借用”一个值来读取它,但不能修改它。
1 | fn calculate_length(s: &String) -> usize { // s 是一个对 String 的引用 |
9. 可变引用 (Mutable References)
如果你需要修改被借用的值,可以使用 可变引用 (&mut)。
1 | fn change(some_string: &mut String) { |
10. 借用的规则 (The Rules of Borrowing)
为了防止数据竞争,Rust 对借用设置了严格的规则,这些规则在编译期被 借用检查器 (Borrow Checker) 强制执行:
- 在任何给定的作用域内,对于一个特定的值,你只能拥有以下两种情况之一:
- 一个可变引用 (
&mut)。 - 任意数量的不可变引用 (
&)。
- 一个可变引用 (
- 引用必须始终有效。
示例:
1 | let mut s = String::from("hello"); |
11. 悬垂引用 (Dangling References)
借用检查器的一个重要作用是防止 悬垂引用 —— 即一个指向已经无效(被释放)的内存地址的指针。
1 | /* |
正确的做法:直接返回 String 本身,转移其所有权。
1 | fn no_dangle() -> String { |
http://googleusercontent.com/youtube_content/5
原文链接: https://dashen.tech/2020/10/01/Rust的所有权与生命周期/
版权声明: 转载请注明出处.