官方在线文档: https://pkg.go.dev/strings
同时推荐使用Dash查阅文档
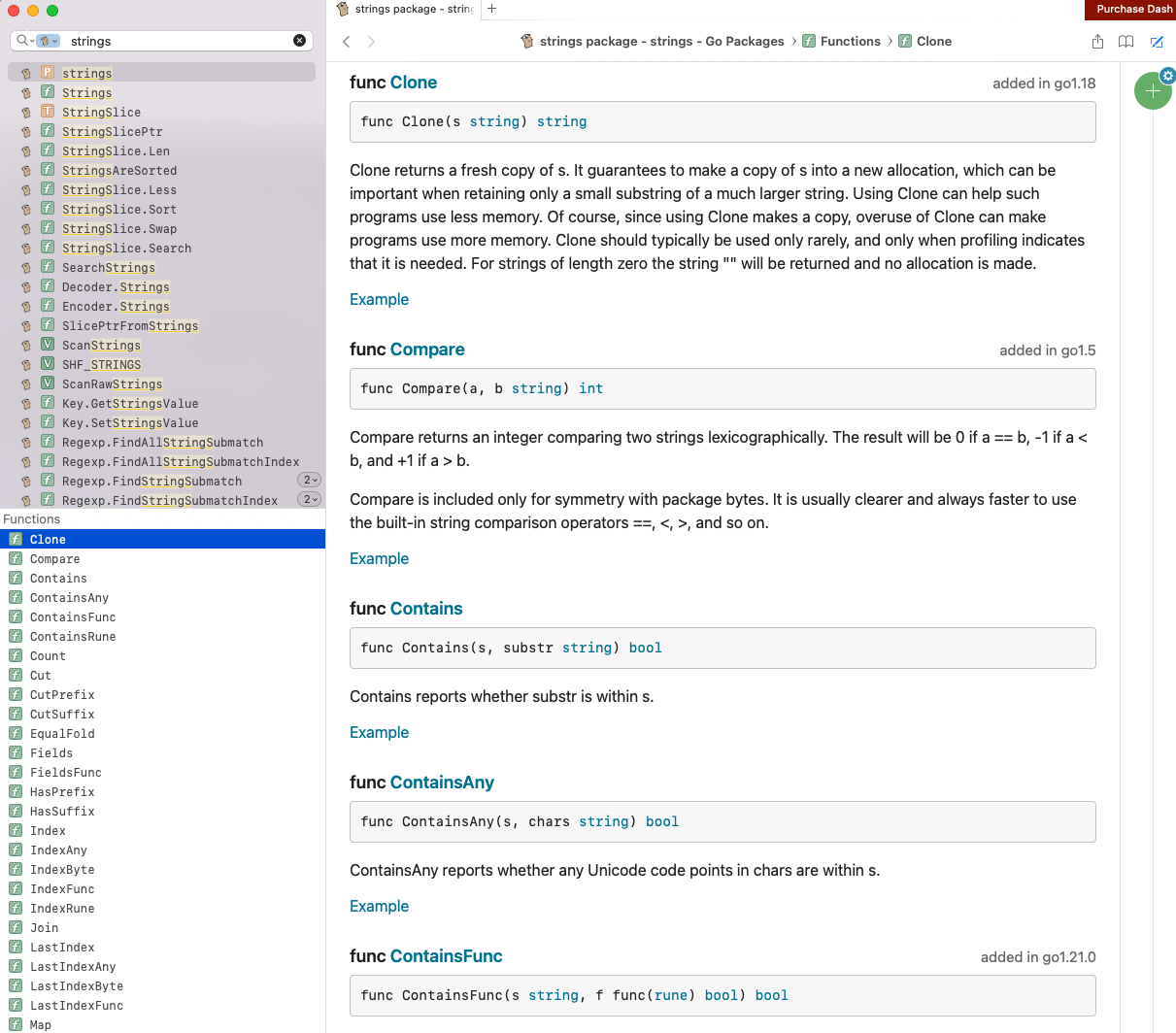
Clone
克隆返回 s 的新副本。它保证将 s 的副本复制到新的分配中,这在仅保留更大字符串的一小部分子字符串时可能很重要。使用克隆可以帮助此类程序使用更少的内存。当然,由于使用克隆会制作副本,因此过度使用克隆会使程序使用更多内存。克隆通常只应很少使用,并且仅在分析表明需要克隆时才使用。对于长度为零的字符串,将返回字符串 “”,并且不进行分配。
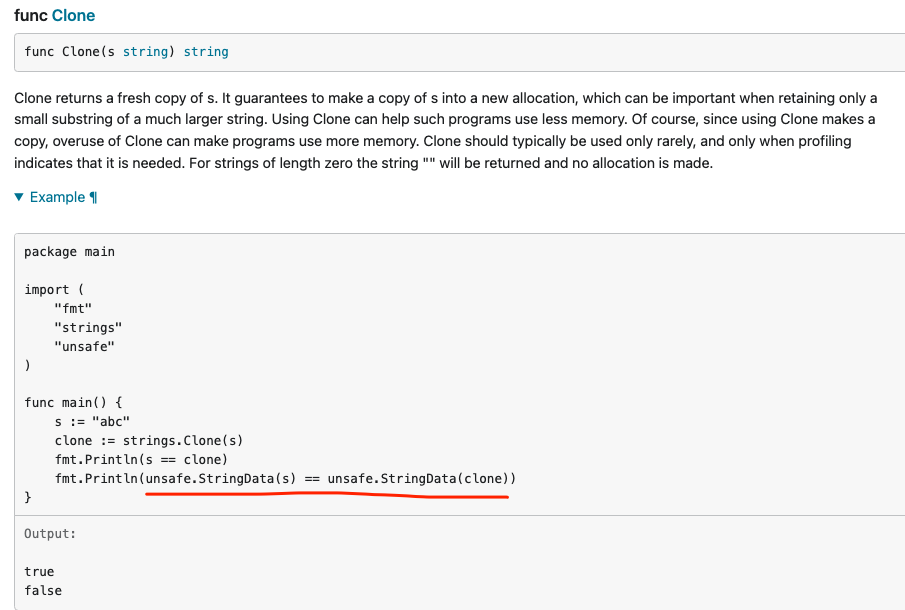
golang中unsafe.StringData有何作用?如何使用
unsafe.StringData在Go语言中是用于访问字符串内部数据结构的。
一个字符串在Go内部是以byte slice加上字符串长度来表示的。unsafe.StringData提供了一种低层次的方式来访问这些内部信息:
1 | type StringHeader struct { |
unsafe.StringData包含字符串的底层header和容量信息:
- Data字段保存字符串内容的地址
- Len字段存储字符串长度
- Cap字段存储字符串容量
一般不推荐直接使用unsafe.StringData,但它可以用于一些特殊场景:
- 读取字符串只读内容而不做复制
- 构建非常量字符串而避免额外分配
- 与Cgo交互中转换Go字符串
例如:
1 | s := "hello" |
总体来说,unsafe.StringData提供了查看和操控字符串内部表示的低级接口,需要格外小心避免造成不稳定甚至崩溃的 bug。
unsafe.StringData可以用来修改字符串的内容吗?
是的,通过unsafe.StringData我们可以修改字符串的内容,但是这是非常不安全的操作,一般不推荐做。
我们可以通过修改StringData的Data字段来修改字符串底层的字节数据:
1 | s := "hello" |
通过修改Data指向的内存,我们改变了字符串的内容。
但是这种直接修改内存的方式很容易导致各种问题:
- 可能会造成冲突,改写错误位置
- 字符串可能在堆外分配,破坏内存布局
- 修改后字符串长度未同步更新可能导致问题
- 内容改写后GC行为变化难以预测
所以一般不建议通过unsafe.StringData直接修改字符串内容。
如果确实需要修改字符串,应该采用如下安全方法:
- 将字符串转成字节切片修改
- 重新构建字符串
- 使用strings.Builder等安全API
总之,unsafe.StringData提供低级访问能力,但直接修改内容是非常不推荐和不安全的。
有没有其他方法可以访问字符串的内部数据结构而不使用unsafe.StringData?
对,除了使用unsafe.StringData直接访问字符串内部结构外,还有其他一些方法可以访问到字符串相关的数据,而不需要使用unsafe操作:
- strings.Reader
strings.Reader可以当做io.Reader来读取字符串,它会返回字符串的内容而不做复制:
1 | s := "hello" |
- reflect
使用reflect获取字符串值,可以访问到字符串的Len属性:
1 | s := "hello" |
- strconv.Unquote
反引号字符串会以byte slice存储内容,可以直接访问内容而不是字符串值本身:
1 | s := `hello` |
- bytes.Buffer
将字符串写入bytes.Buffer后可以访问其内部数据:
1 | var b bytes.Buffer |
- strings包函数
如strings.Index、strings.Contains等函数会直接使用字符串内部数据而不是值本身。
所以在不少场景,我们可以避免直接使用unsafe手段,而是采用上述方式间接访问字符串相关信息,从而避免潜在的内存安全问题。
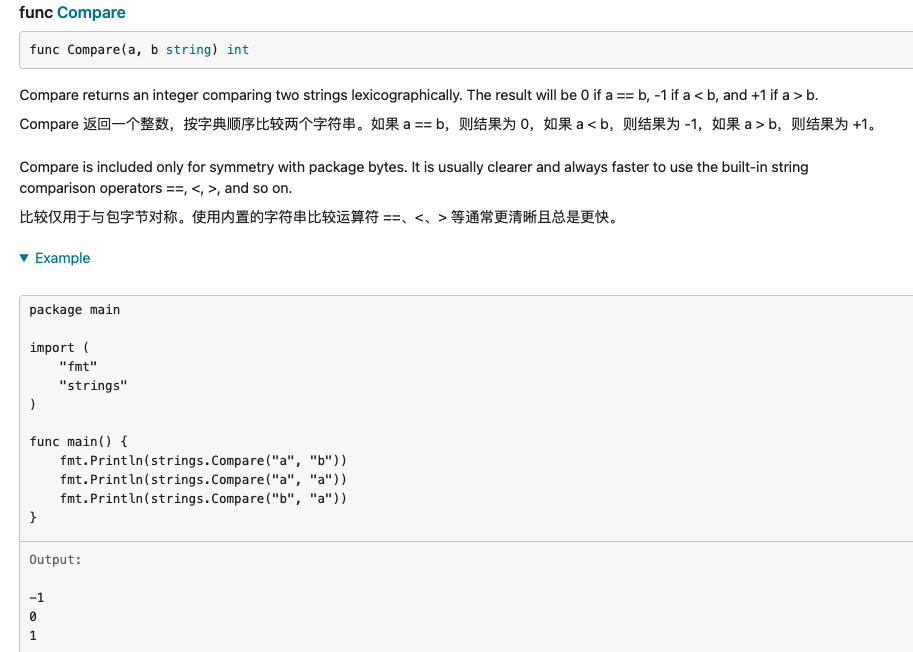
Compare
较好理解
Contains,ContainsAny,ContainsFunc,ContainsRune 以及 Index,IndexAny,IndexByte,IndexFunc,IndexRune,还有LastIndex,LastIndexAny,LastIndexByte,LastIndexFunc
strings.Contains调用的是strings.Index,底层最复杂情况用的是Rabin-Karp算法
- ContainsAny: 要检索的子字符串有多个元素,只要其中一个在字符串中,则为true
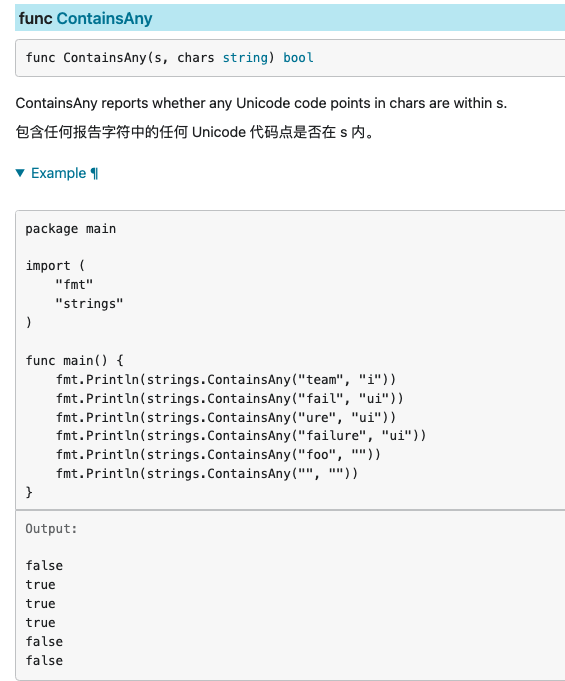
- ContainsFunc: ContainsFunc 报告 s 中的任何 Unicode 码位 r 是否满足 f(r)
可以提个CL,为ContainsFunc加一个Example
strings.ContainsFunc是Go语言标准库strings包中的一个函数,用于检查字符串是否包含某个函数匹配的内容。
它的函数签名是:
1 | strings.ContainsFunc(s string, f func(rune) bool) bool |
比如:
1 | func isVowel(r rune) bool { |
这里定义了一个isVowel函数来匹配元音字母,然后通过ContainsFunc来检查字符串s是否包含任何匹配的字符。
功能是:
- strings.ContainsFunc函数会遍历字符串每个字符
- 字符传入匹配函数f进行校验
- 如果有任何字符匹配则返回true
它可以用来做灵活的字符串匹配,比如字母、数字、特殊字符等。
比起Contains更加通用,能够实现定制化的匹配逻辑。常用在需要校验格式的场景。
- ContainsRune: 报告 Unicode 码位 r 是否在 s 内
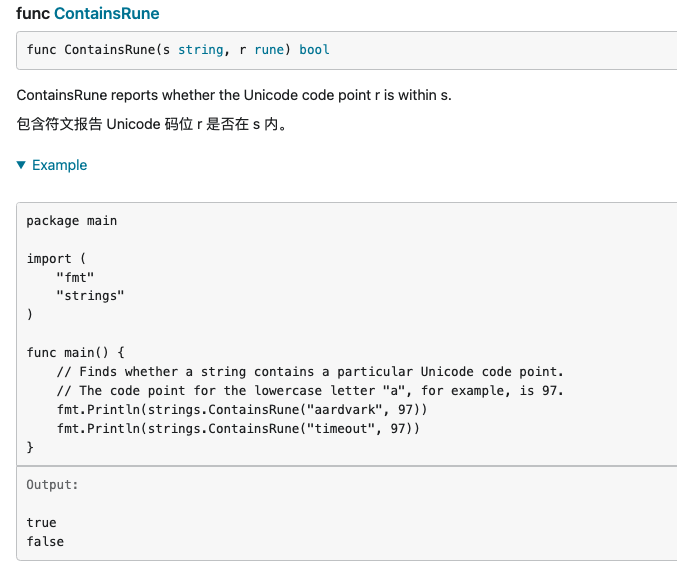
- IndexAny
strings.IndexAny在Go语言中的strings包中,它是用来在一个字符串中查找给定字符集合中任意一个字符的首次索引。
它的使用方式如下:
1 | strings.IndexAny(s, chars string) int |
参数:
- s: 待查找的源字符串
- chars: 包含可能匹配字符的字符串
返回值:
查找到的第一个匹配字符在源字符串s中的索引,如果没有匹配则返回-1。
使用示例:
1 | s := "hello world" |
这里,给出一个子字符串”owe”,它会查找s中针对 o或w或e的第一个匹配字符的索引。很显然,在s中首先匹配到的是e,在s中的索引为1
strings.IndexAny使用 binary search 的方式查找,效率很高,常用于需要查找指定字符集合的场景。
- IndexByte和IndexRune,差不多
- IndexFunc: IndexFunc 返回满足 f(c) 的第一个 Unicode 代码点的索引,如果没有满足则返回 -1

Count
好理解。
但需要注意,如果 substr 为空字符串,则 Count 返回的是 1 + 以 s 为单位的 Unicode 码位数,或者可以简搭记为 1+len(s)
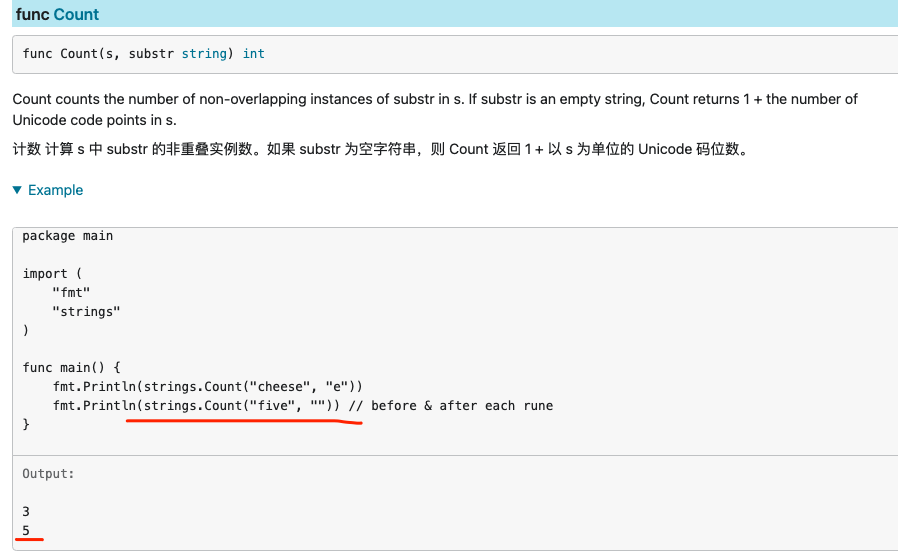
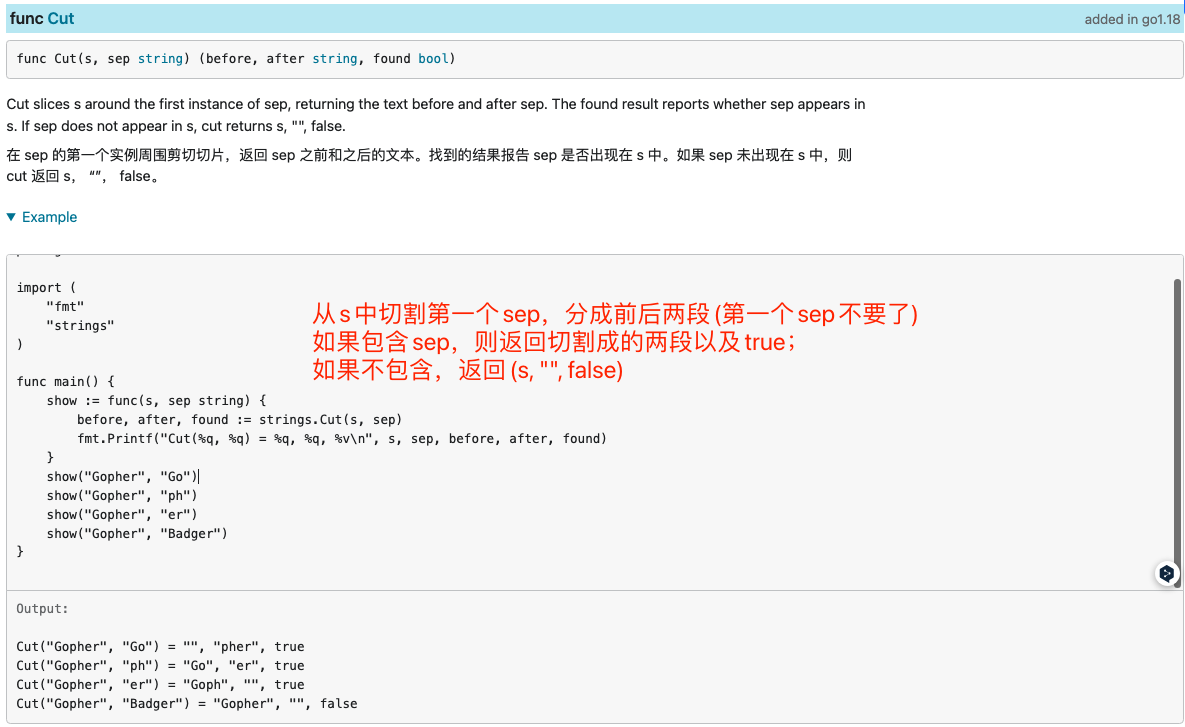
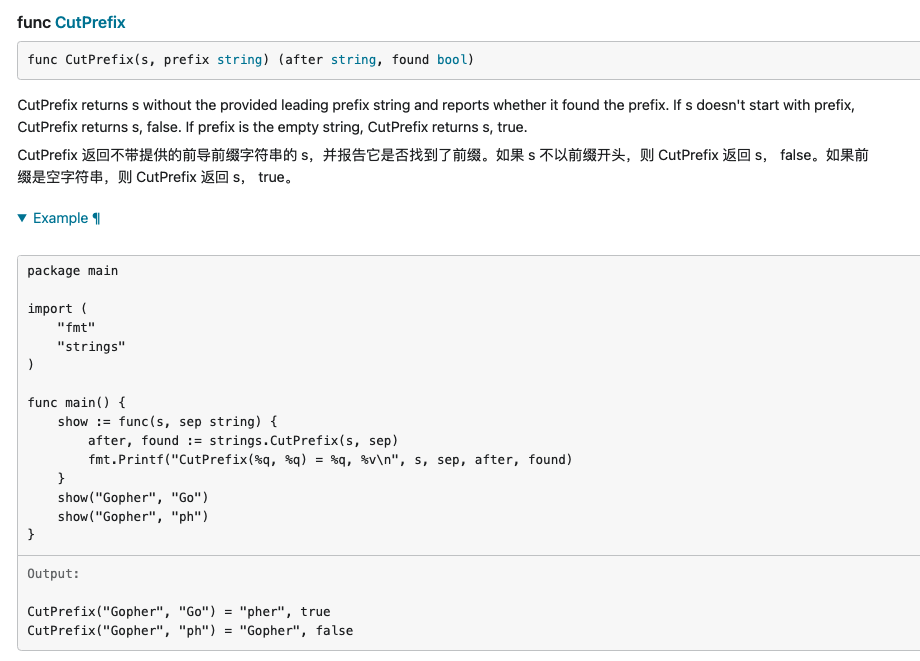
Cut,CutPrefix,CutSuffix
EqualFold
strings.ToLower(name1) == strings.ToLower(name2) 和 strings.EqualFold(name1, name2)哪个性能更好?
https://go-review.googlesource.com/c/go/+/530635/2/src/slices/example_test.go#54
在 Go 语言中,EqualFold 是一个字符串比较函数,用于比较两个字符串是否相等,而忽略它们的大小写
EqualFold 的函数签名如下:
1 | func EqualFold(s, t string) bool |
该函数接受两个字符串参数 s 和 t,并返回一个布尔值。如果 s 和 t 相等(忽略大小写和地区设置),则返回 true;否则返回 false。
例如,下面的代码演示了如何使用 EqualFold 函数来比较两个字符串:
1 | package main |
在上面的示例中,EqualFold 函数被用于比较字符串 str1 和 str2,以及 str1 和 str3。由于在比较时忽略了大小写,所以两个字符串被认为是相等的,函数返回的结果都是 true。
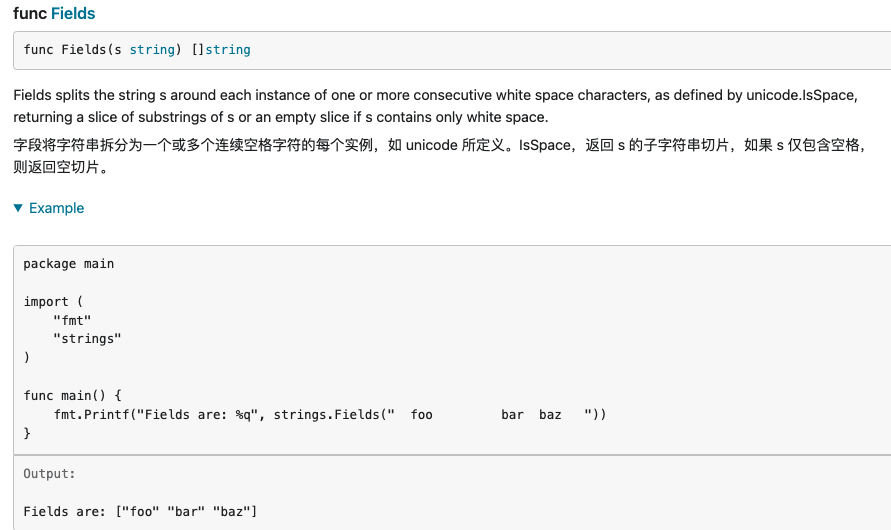
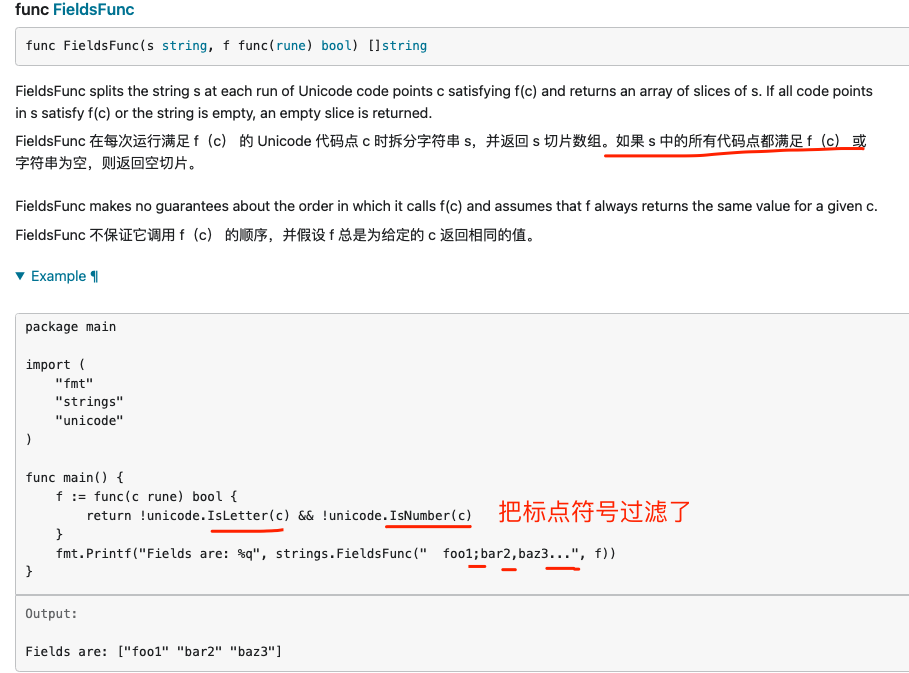
Fields,FieldsFunc
Fields 将字符串 s 围绕一个或多个连续空白字符的每个实例进行拆分(如 unicode.IsSpace 所定义),返回 s 的子字符串切片,如果 s 仅包含空白,则返回空切片。
HasPrefix,HasSuffix
字符串 s 是否以 某 前缀开头/后缀结尾
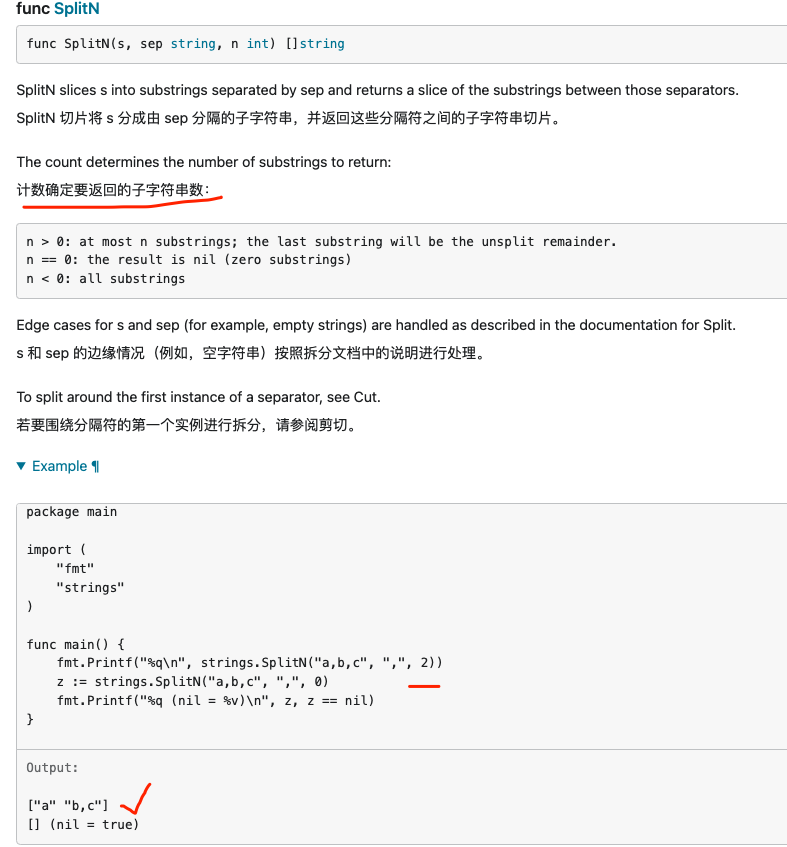
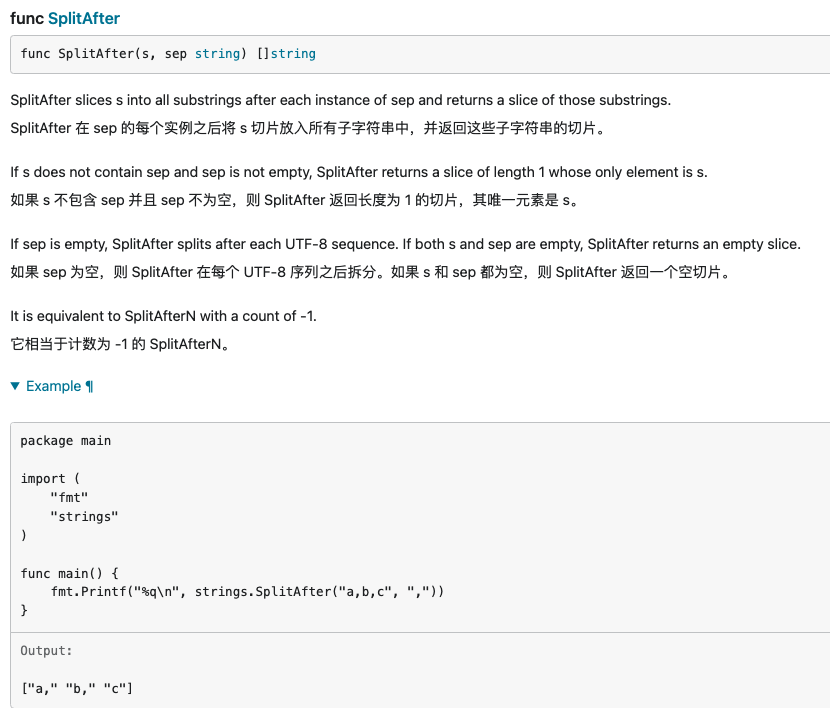
Join / Split,SplitN,SplitAfter,SplitAfterN
Join 将切片转为字符串
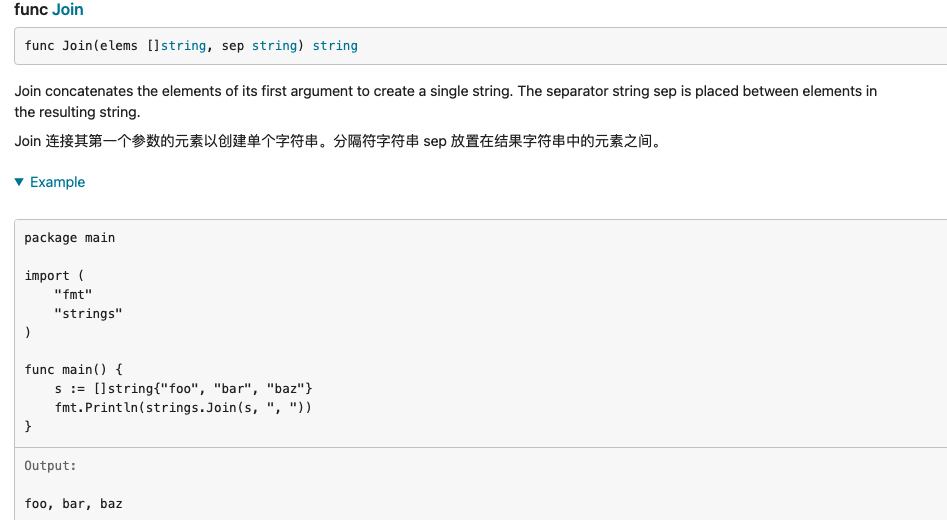
Split 将字符串转为切片

Map
Map 返回字符串 s 的副本,其中所有字符根据映射函数进行修改。 如果映射返回负值,则该字符将从字符串中删除而不进行替换。
映射,有点函数式编程的意思
strings.Map是Go语言中strings包中的一个函数,用于根据映射规则替换字符串中的字符。
它的使用方式是:
1 | strings.Map(mapping func(rune) rune, s string) string |
参数:
- mapping: 字符映射函数,用于根据每个字符返回需要替换的字符
- s: 源字符串
返回替换后的新字符串。
一个例子:
1 | func toLower(r rune) rune { |
这里定义了一个字符映射函数toLower,用于将’A’-‘Z’范围内的字符都转为小写。
然后通过strings.Map根据这个映射函数,循环替换源字符串s中的每个字符,得到新的小写字符串s2。
strings.Map通常用于根据定制规则批量替换字符,比如大小写转换、过滤特殊字符等场景。
Repeat
很容易理解
将字符串s重复指定的次数
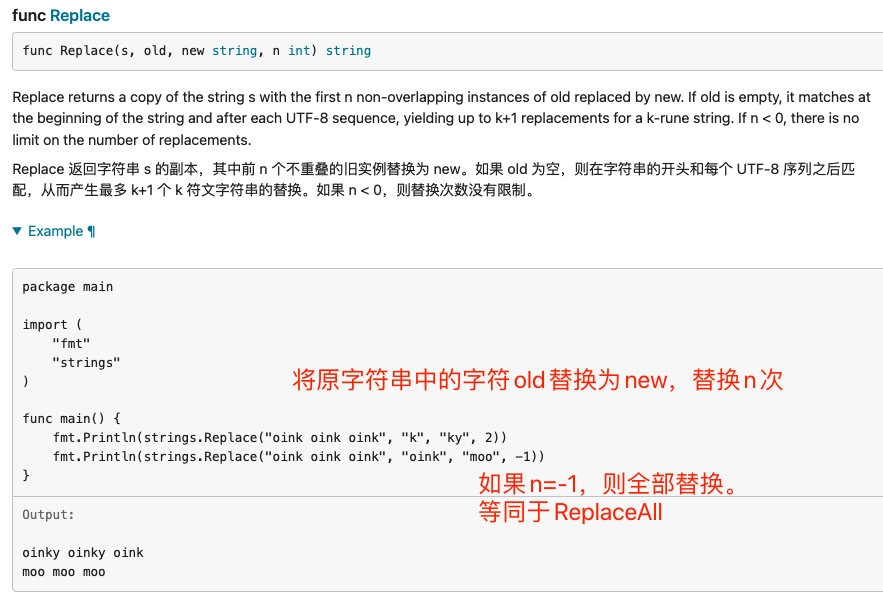
Replace,ReplaceAll
Title(已废弃),ToLower,ToLowerSpecial,ToTitle,ToTitleSpecial,ToUpper,ToUpperSpecial,ToValidUTF8
strings.ToLowerSpecial是Go语言标准库strings包中一个用于特定语言环境下大小写转换的函数。
它的用法是:
1 | strings.ToLowerSpecial(s string, locale unicode.Locale, _ rune) string |
参数:
- s: 源字符串
- locale: 语言环境,比如”tr-TR”表示土耳其语
- _: 保留参数,可以传nil
这个函数比strings.ToLower会考虑不同语言环境下的大小写映射规则,实现更准确的转换。
例如:
1 | s := "Iß" // I with dot above |
这里”Iß”在德语环境下转换为小写的还是”iß”,因为ß在德语中就是小写形式。
而strings.ToLower可能直接转换成”iss”会失真。
一些其他语言如土耳其语、法语等,大小写转换也需要考虑其特定规则。
strings.ToLowerSpecial可以很好地支持多种语言环境下正确的大小写转换。
strings.ToTitle在Go语言标准库strings包中,它的函数签名是:
1 | strings.ToTitle(s string) string |
它用于将字符串按照标题格式(Title case)转换,也就是每个单词首字母大写,其余字母小写。
如:
1 | s := "hello world" |
这里源字符串每个单词首字母被转换为大写。
它还支持一些语法分析,例如:
1 | s := "hello-world,javascript" |
会正确识别连字符“-”和逗号“,”之间作为一个单词处理。
此外,它会忽略非字母的首字符,例如:
1 | s := "123 hello" |
字符串“123”开头的数字不会被转换。
所以strings.ToTitle可以方便地将字符串转换为标题格式,用于文本标题化等场景。
strings.ToValidUTF8函数用于将一个字符串转换成有效的UTF-8编码格式。
它的使用方法:
1 | strings.ToValidUTF8(s string) string |
参数:
- s: 源字符串
返回转换后的有效UTF-8字符串。
示例:
1 | s := "Hello\xffWorld" |
这里源字符串包含一个无效UTF-8编码\xff,strings.ToValidUTF8会将其转换为空字符。
它会执行以下操作:
- 检查每个字节是否符合UTF-8编码规范
- 将非法字节序列替换为UTF-8代理错误代理(byte 0xFFFD)
- 去除超出范围的字节
所以可以用于:
- 修正非法 UTF-8字符串
- 清理或格式化来自非UTF-8源的数据
- 从BINARY/ASCII转换到UTF-8编码
使用这个函数可以方便地从非法字符串转换为合法的UTF-8格式输出。
Trim,TrimFunc,TrimLeft,TrimLeftFunc,TrimPrefix,TrimRight,TrimRightFunc,TrimSpace,TrimSuffix,
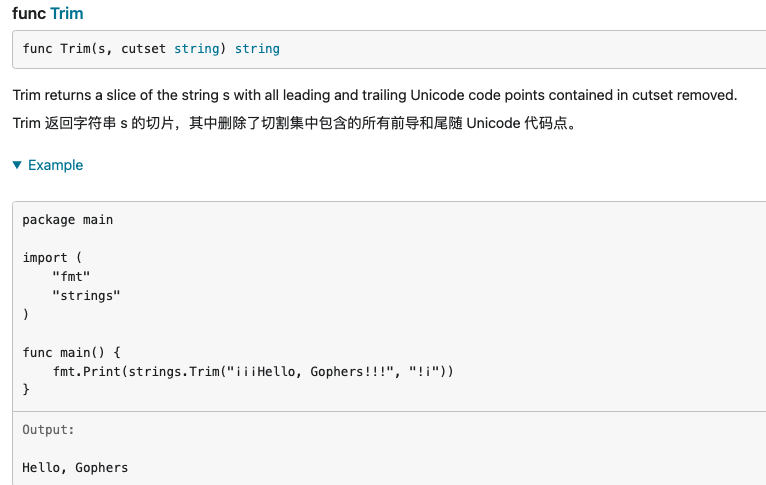
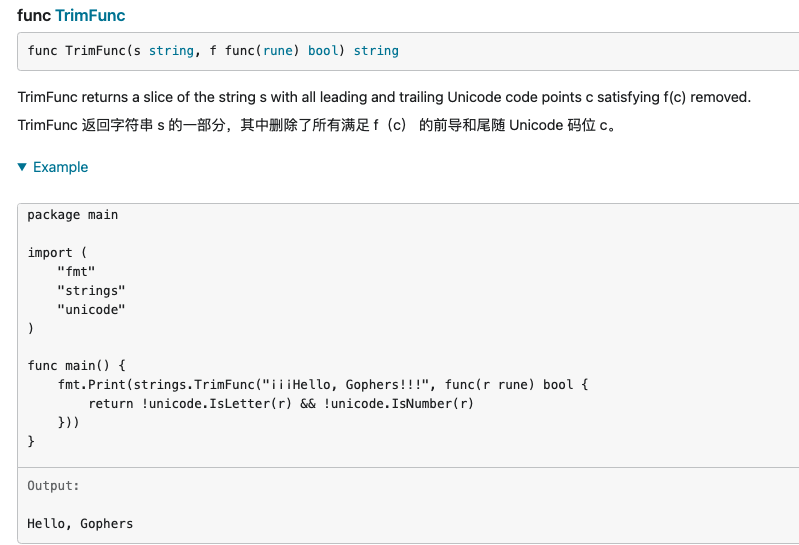
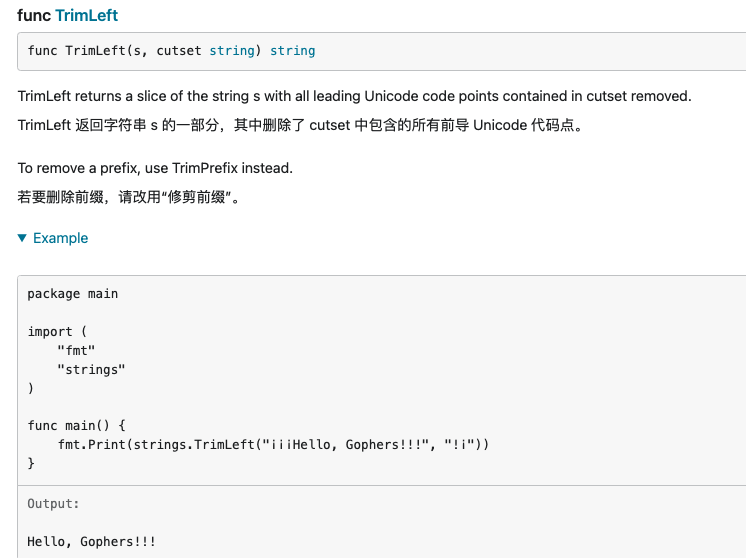
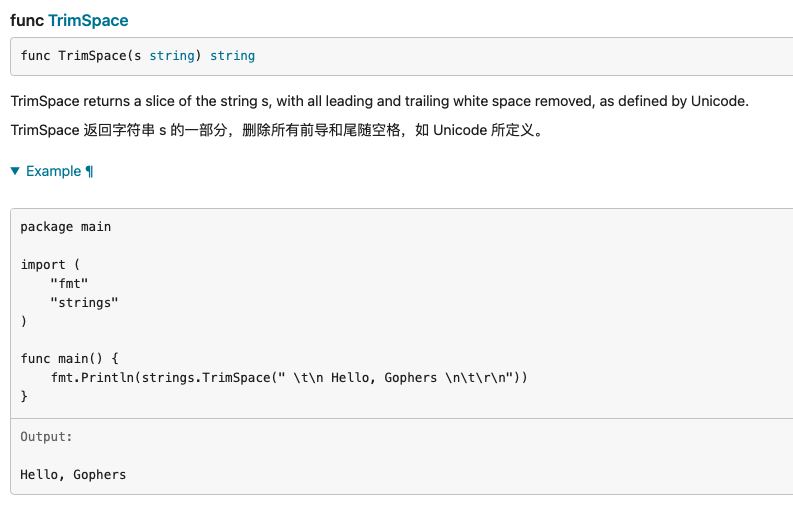
原文链接: https://dashen.tech/2020/10/07/Go-strings库中的方法/
版权声明: 转载请注明出处.