
中文译为 Rust权威指南
深拷贝和浅拷贝
相关内容:
Go:
浅拷贝:
1 | a := []int{1,2,3} |
b和a指向同一内存地址,修改b也会修改a。
深拷贝:
1 | a := []int{1,2,3} |
b拷贝a值得副本,修改b不影响a。
Rust:
浅拷贝:
1 | let a = vec![1,2,3]; |
深拷贝:
1 | let a = vec![1,2,3]; |
用大白话说,只有这个数据类型的结构体中存在指针,才存在啥浅拷贝和深拷贝之说(如String,slice,map),像如int,float,bool,压根没啥指针,都是在栈上,可以认为都是深拷贝(没有拷贝指针,因为压根没有,直接拷贝的值)。



如果你在其他语言中听说过术语 **浅拷贝(shallow copy)**和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据可能听起来像浅拷贝。不过因为 Rust 同时使第一个变量无效了,这个操作被称为 移动(move),而不是浅拷贝。
这里还隐含了一个设计选择:Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何 自动 的复制可以被认为对运行时性能影响较小。
如果我们 确实 需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做clone的通用函数(这个对运行时性能就有影响了,涉及到新分配一块堆内存), 使用clone的话 堆上的数据 确实 会被复制,
故而当出现clone调用时,需要察觉到一些特定的代码被执行而且这些代码可能相当消耗资源。
引用和借用
变量的所有权总是遵循相同的模式:将值赋给另一个变量时移动它。当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有。
在每一个函数中都获取所有权并接着返回所有权有些啰嗦。如果我们想要函数使用一个值但不获取所有权该怎么办呢?如果我们还要接着使用它的话,每次都传进去再返回来就有点烦人了,除此之外,我们也可能想返回函数体中产生的一些数据。
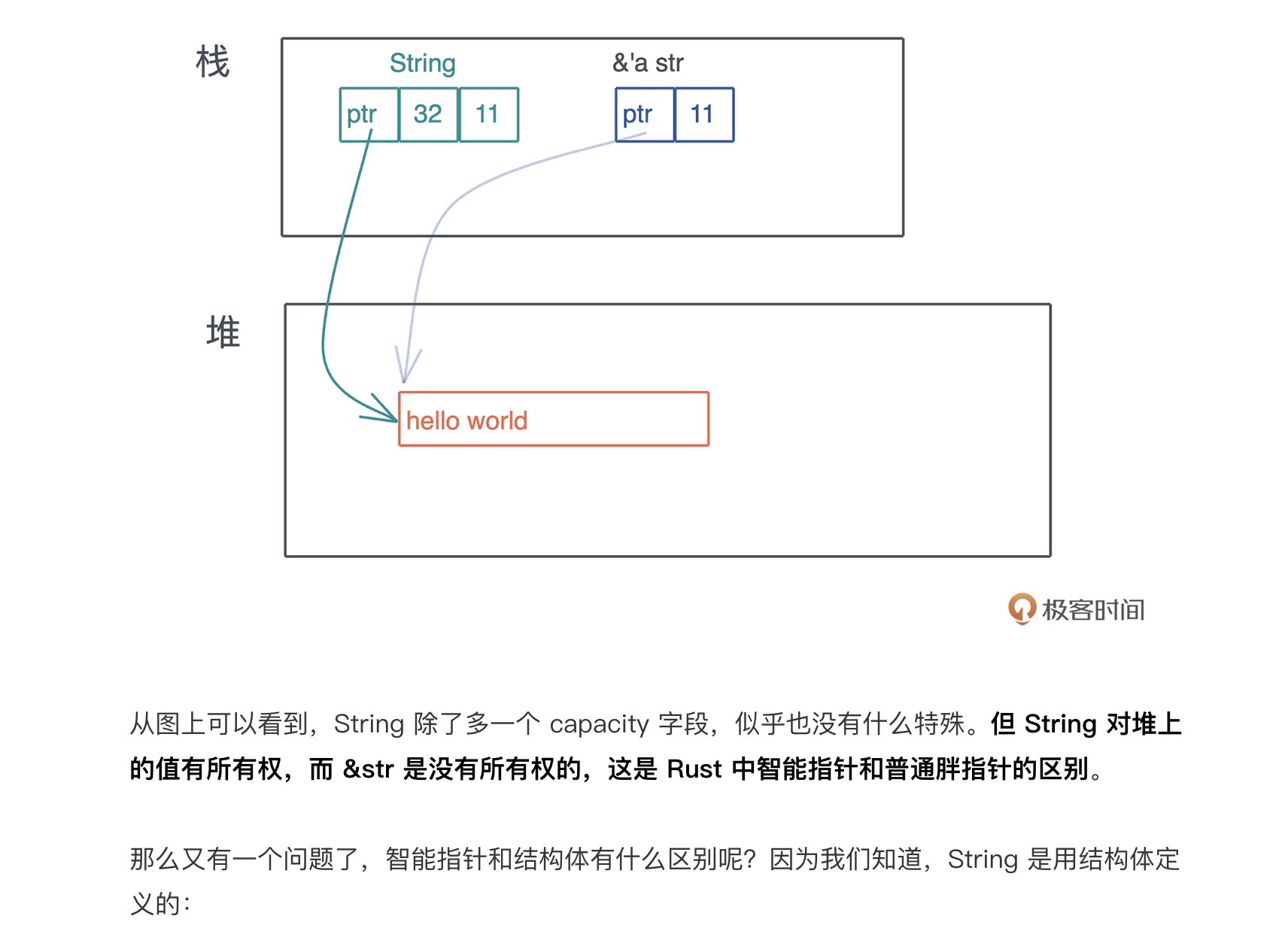
& 符号就是 引用,它们允许你使用值但不获取其所有权。图 4-5 展示了一张示意图
使用 & 引用相反的操作是 解引用(dereferencing),它使用解引用运算符,*。我们将会在第 8 章遇到一些解引用运算符,并在第 15 章详细讨论解引
引用和借用: 把引用作为函数参数这个行为叫做借用
即 传引用,就叫借用…
默认是不能修改,需要传 可变引用
同期只能有一个 可变引用 (这样就保证不可能发生 数据竞争)


可变引用
胖指针和瘦指针
Fat Pointer 除了胖指针,也译为宽指针, 按照字面意思比正常我们理解指针要”宽”,其实本质上就是一个指针所占用的空间不再是通常的8个字节,而是用16个字节或者更多字节。
Go语言中好像不存在这种的指针,在Go中所有的指针大小都是8个Byte
宽指针在rust编程语言中应用广泛。例如trait、slice内部都是由宽指针实现。
https://stackoverflow.com/questions/57754901/what-is-a-fat-pointer
我已经在多个上下文中读过“胖指针”这个术语,但我不确定它到底意味着什么以及何时在 Rust 中使用它。该指针似乎比普通指针大两倍,但我不明白为什么。它似乎也与特质对象有关。顺便说一句,这个术语本身并不是 Rust 特有的。胖指针通常是指除了所指向对象的地址之外还存储一些额外数据的指针。如果指针包含一些标记位,并且根据这些标记位,指针有时根本不是指针,它被称为标记指针表示。 (例如,在许多 Smalltalks VM 上,以 1 位结尾的指针实际上是 31/63 位整数,因为指针是字对齐的,因此永远不会以 1 结尾。)HotSpot JVM 将其胖指针称为 OOP(面向对象指针) )。
术语“胖指针”用于指代对动态大小类型 (DST)(切片或特征对象)的引用和原始指针。胖指针包含一个指针加上一些使 DST“完整”的信息(例如长度)。
Rust 中最常用的类型不是 DST,而是在编译时具有已知的固定大小。这些类型实现 Sized 特征。即使管理动态大小的堆缓冲区的类型(例如 Vec
“胖指针”并不是真正的指针,只是一个内部带有指针的结构。
爽哥注:
所谓的胖指针,其实就是个结构体,其中一个字段是指针类型。类似Go的string或者slice,以slice为例,对应的结构体有3个字段,除了指针外,还有len和cap,这就是些额外信息,这个就叫做”胖指针”或者”宽指针”。。。
超哥和rongyi老哥差不多都这么认为
胖指针和瘦指针:
胖指针 存储地址和数据在同一位置:
Go:
1 | type Pair struct { |
Rust:
瘦指针只存储地址,数据位于其他位置:
1 | struct Pair { |
胖指针和瘦指针的区别:
胖指针(Fat Pointer):
胖指针同时存储数据和指针,即数据直接存储在结构体里面。
例如C/C++的结构体定义数据成员直接存储在结构体中。
访问数据直接通过指针访问结构体内的数据成员。
空间占用较大,但访问效率高。
瘦指针(Thin Pointer):
瘦指针只存储指针,数据单独分配存储空间。
例如C/C++的指针变量只存储地址值。
数据通过指针间接访问,首先要根据指针取地址,再访问数据。
空间占用小,但访问效率较低。
举例说明:
C++胖指针:
1 | struct Node { |
数据成员data直接存储在结构体中。
Rust瘦指针:
1 | struct Node { |
使用Box将Node置于堆中,next成员只存储指针而非数据本身。
所以简单来说,胖指针直接包含数据,瘦指针仅包含指针地址需要再进行一次访问。
能不能用Go和Rust,来解释 胖指针和瘦指针?
Go版本的胖指针和瘦指针解释:
胖指针(Fat pointer) in Go:
1 | // 存储数据和指针在同一个结构体中 |
- Pair结构体包含数据字段X和指针字段P
- 数据和指针都直接保存在Pair类型的值p中
- 直接通过P访问内嵌的数据X
瘦指针(Thin pointer) in Go:
1 | // 数据和指针分开存储 |
- 数据x和指针p分开定义
- p仅保存数据x的地址
- 需要通过*运算符根据p取地址,再访问实际数据x
Rust版本的胖指针和瘦指针解释:
胖指针(Fat pointer) in Rust:
1 | // 没有实现,Rust中没有直接嵌入指针的概念 |
瘦指针(Thin pointer) in Rust:
1 | struct Point { |
- Point使用Box置于堆中
- p仅包含指向Box的指针
- 通过指针访问实际的数据结构Point
总之,Go支持胖指针,Rust天生只支持瘦指针的概念。
Rust中有胖指针吗
Rust中实际上没有真正意义上的”胖指针”。
理由如下:
Rust不支持直接在结构体中嵌入指针成员,这与Rust倾向安全防止资源泄露的设计理念不符。
但是,Rust提供了一些类似胖指针的语言功能:
引用(&) - 可以理解为只读胖指针,直接引用数据而不是复制。
可变引用(&mut) - 可变引用,相当于可写胖指针。
动态分配(Box) - 可以在堆上分配数据结构,Box指针包含引用计数等元数据。
自定义指针类型 - 可以定义包含附加数据的指针类型,但不推荐直接内联数据。
所以总体来说:
Rust标准库没有真正意义上的”胖指针”数据结构。
但提供了引用、Box等功能来近似实现胖指针行为,保证内存安全。
可以根据需要定义自定义指针类型,但不建议内联实际数据,以免影响内存模型和安全性。
所以在语义上,Rust没有胖指针,但提供了类似功能的安全替代品。
确定Rust没有胖指针吗…不对啊
智能指针一定是一个胖指针,但胖指针不一定是一个智能指针。
https://time.geekbang.org/column/article/422182
确定rust中没有胖指针吗??
你提出了一个好问题。我重新查阅了一下文档,发现Rust中确实有实现胖指针的语法:
Raw指针(Raw pointers)可以看做是Rust中的胖指针:
Raw指针允许直接引用内存而不进行借用检查,这与胖指针的定义更符合。
例如
*mut T和*const T类型的数据指针。它们直接包含了指向值的指针,不进行管理或自动清理。
比如:
1 | let x = 5; |
这里raw_ptr可以看做胖指针,直接包含数据指针。
所以您提出的观点是正确的,Rust标准库中通过Raw指针提供了胖指针的语法功能。
我前面揭述Rust没有胖指针的是不完整的。非常感谢您指出,这对我深入掌握Rust也很有帮助!
那Rust中的胖指针和普通指针有什么区别?
Rust中的胖指针(Raw指针)与普通指针的主要区别有:
- 可借用检查
普通指针隐式增加&生命周期,对其进行借用检查,避免破坏引用关系。
胖指针则不进行借用检查,可以直接引用已被引用的内存区域。
- 功能
普通指针可以安全的读/写被引用数据。
胖指针需要在unsafe块内使用,只能用于读存取数据,不能进行任何会破坏内存正确性的操作。
- 类型
普通指针类型如&’a T,通过生命周期进行引用关系检查。
胖指针类型直接使用mut T和const T表示可写和只读指针。
- 内存管理
普通指针自动管理引用计数和生命周期。
胖指针不进行任何内存管理,完全依赖程序员手动处理。
- 语法位置
普通指针是Rust主要指针类型,支持所有地方使用。
胖指针需要在unsafe块内使用,以Highlight潜在风险。
所以总体来说,胖指针相比普通指针可以直接引用内存但功能更有限,需要开发者自行确保内存安全。
golang的slice是胖指针还是瘦指针
Golang的slice可以看作是一种”胖指针”。
理由如下:
Slice被设计成一个结构,包含三个字段:指向底层数组的指针、长度和容量。
这三个字段直接作为成员存在于slice值里,不需要额外取地址就可以访问。
例如可以直接通过s.len获取slice的长度,不需要通过指针访问底层结构体的长度字段。
Slice有自己的值语义,支持直接赋值和传参等操作,而不仅仅是一个指针。
相比Go中的指针:
指针只是一个简单的地址值,没有附加信息。
必须通过*运算符根据指针访问实际数据。
所以Go中的slice可以看做是一个”轻量级”的胖指针实现:
内嵌必要的指针和长度/容量信息方便直接操作。
但不像C++那样内嵌完整的底层数据结构,仅包含必要metadata。
仍然需要通过指针访问底层数组存储的实际元素。
总之,相比普通指针,Go的slice具备了类胖指针的行为和优点。
胖指针与智能指针
智能指针一定是一个胖指针,但胖指针不一定是一个智能指针
https://time.geekbang.org/column/article/422182
在 Rust 中,凡是需要做资源回收的数据结构,且实现了 Deref/DerefMut/Drop,都是智能指针。 (析构)
析构函数什么作用,rust中有吗?
析构函数的作用和在Rust中是否存在:
析构函数的作用:
析构函数(destructor)是在对象被删除或超出范围时自动调用的函数。
主要用来执行对象析构相关的清理工作,如释放堆上分配的内存、关闭文件描述符等。
能确保对象释放资源时执行必要的清理代码,防止资源泄漏。
Rust中是否有析构函数:
Rust没有传统C++语义下的析构函数概念,析构行为是通过Drop特trait自动实现的。
实现Drop特性的类型在被移出作用域或清除时,其drop方法会被自动调用进行清理。
例如为Smart Pointers如Box、Vec实现Drop来执行内存清理。
Rust总是在堆区数据离开作用域时自动调用drop以执行清理代码,无需手动调用。
所以总体来说:
Rust没有叫做析构函数的概念,但通过Drop特性实现了类似析构功能。
对象超出作用域时,Rust会自动调用实现了Drop的类型的drop方法进行资源释放。
这与C++手动定义析构函数的概念不同,但都能达到自动清理对象的目的。
在Rust中,如何实现Drop特性来执行对象的清理工作?
在Rust中,可以通过实现Drop特质来为自定义类型添加清理行为(执行析构函数功能):
1 | struct CustomResource { |
实现Drop特质的重要步骤:
- 定义drop方法,它会在对象离开作用域时调用
- drop方法的参数是可变引用到self,以能访问结构体成员
- 在drop方法中执行任何清理工作,如打印日志,释放资源等
此外,一些智能指针如Rc、Arc等也实现了Drop:
- Box和Vec在drop中会调用堆中数据的drop清理内存
- Rc/Arc在drop中会递减RefCount countdown到0
所以通过为自定义类型实现Drop,可以在Rust中定义对象的清理行为,达到C++析构函数的效果。Rust会在对象超出作用域自动调用drop方法。
除了Box和Vec,还有哪些类型需要实现Drop特性来进行资源清理?
除了Box和Vec外,还有一些常用类型也需要实现Drop特质进行资源清理:
Rc/Arc - 使用Drop释放引用计数资源
MutexGuard - 解锁互斥锁资源
Barrier - 同步待清理操作
Socket - 关闭套接字文件描述符
File - 关闭文件描述符
Process - 回收子进程资源
Channel - 关闭通道endpoints
Logger - 刷新日志,关闭句柄
DatabaseConnection - 关闭连接池连接
NetworkConnection - 关闭 socket
Timer - 取消计时器任务
HashMap - 清理KV对资源
PersistentDb - 提交事务,清理连接
WebSocket - 关闭连接
OsString - 释放字节数组资源
Regex - 释放编译正则表达式
Url - 释放解析url组件
Atomics - 清理原子类型状态
总之,任何包含数据以外的额外系统资源,如文件句柄、连接、锁等,都需要通过Drop来确保资源被正确回收释放。
这可以有效避免发生资源泄漏bug。
在Rust中,对象超出作用域时会自动调用drop方法,那么如何手动调用drop方法呢?
在Rust中,对象通常在超出作用域时会自动调用drop方法进行清理。但是在某些情况下,我们也可以手动调用drop方法:
- 调用
std::mem::drop函数:
1 | fn main() { |
- 调用引用的drop方法:
1 | fn main() { |
- 通过其他语法手动调用:
1 | fn main() { |
所以在Rust中,我们可以通过上述方式手动调用对象的drop方法,进行资源释放,这与自动释放在析构时的效果是一样的。
主要是在一些需要主动释放资源或者调试Drop时机的场景下使用。
能否给出一个使用Rc或Arc实现Drop特质的例子?
这里给一个使用Rc实现Drop特质的示例:
1 | use std::rc::Rc; |
在这个示例中:
- 定义链表节点
Node结构体,使用Rc存储引用计数指针 - 实现
Drop特质对Node进行自定义清理 - 主函数中使用
Rc对节点进行引用计数管理 - 当节点离开作用域时,
drop函数会打印日志进行清理
这里通过为Node实现Drop,让链表在解引用时能执行清理操作。
如果使用Arc,实现方法类似,主要区别是Arc在多线程环境下线程安全。
该示例演示了如何结合Rc/Arc和Drop特质来对引用计数类型添加清理行为。
语言层面杜绝数据竞争


防止同一时间对同一数据进行多个可变引用的限制允许可变性,不过是以一种受限制的方式允许。新 Rustacean 们经常难以适应这一点,因为大部分语言中变量任何时候都是可变的。
这个限制的好处是 Rust 可以在编译时就避免数据竞争。数据竞争(data race)类似于竞态条件,它由这三个行为造成:
• 两个或更多指针同时访问同一数据。
• 至少有一个指针被用来写入数据。
• 没有同步数据访问的机制。
译注:以上三个行为同时发生才会造成数据竞争,而不是单一行为。
数据竞争会导致未定义行为,难以在运行时追踪,并且难以诊断和修复;Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!
想起了B站那个问题…如果用Rust,就可以直接避免..
宏与元编程
声明宏简单一点,过程宏需要了解一点编译原理
原文链接: https://dashen.tech/2020/10/19/The-Rust-Programming-Language-阅读摘要/
版权声明: 转载请注明出处.