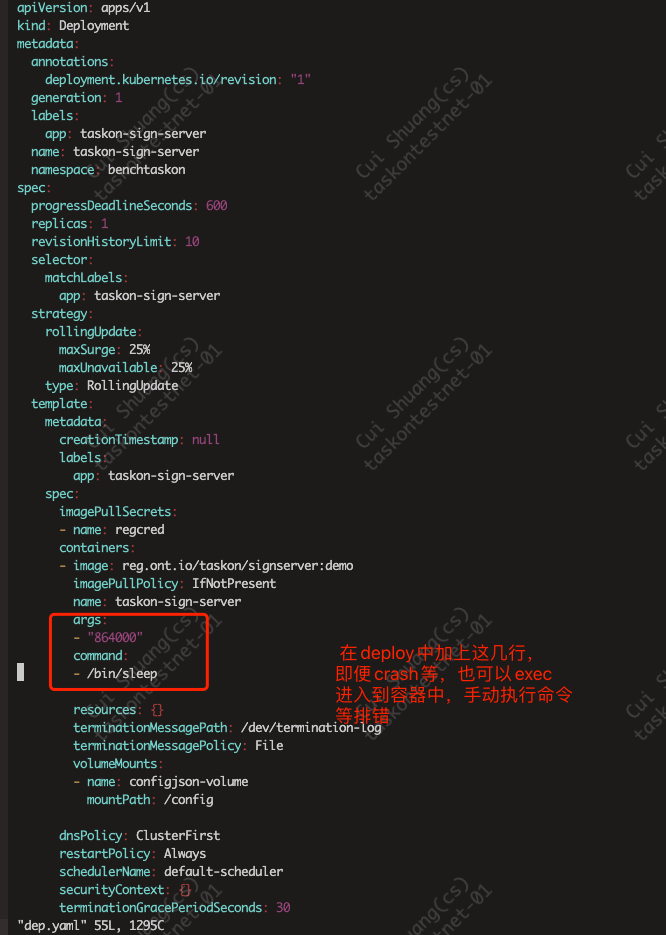
此时进入到pod中,ps aux会看到sleep 86400的进程
注意,这样会一定只执行 sleep 86400,真正的应用程序无法得到执行。仅用于进入pod调试,如果容器中ps aux发现服务能正产运行了,需要将这几行注释掉,重新apply deploy.yaml
运行命令看报错
k -n namespace describe pod taskon-sign-server-55f47bcdfd-z9sh9
当然也可以 k -n namespace logs pod名称 查看日志
如何创建一个cm?
k -n 命名空间 create cm cm的名称 --from-file=文件名
即 k -n benchtaskon create cm taskon-sig-key --from-file=your-data-file
然后在deploy.yaml的volumeMounts:和volumes: 处新增:
1 | volumeMounts: |
K8S排障系列 | 如何正确排查NodexxxPressure这类故障呢?
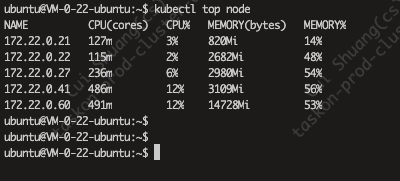
kubectl top node
今天我们来聊一个node层面的故障案例。大家是不是也在日常的工作当中遇到过,例如pod无法调度、pod被无故驱逐、pod调度失败?针对这些问题点,我们今天通过这三个案例来给大家做一个解答。
我们先来看第一个案例:Node CPU Pressure案例。这个案例表明,当前pod所在的node节点已经出现了性能问题。在这种情况下,节点上的pod开始出现一系列的性能下降,响应时间也会相应增加。那么这个时候我们该如何去排查它呢?
排除数据集层面,我们从Kubernetes层面来给大家聊一下:
- 我们可以通过kubectl top node来监控当前节点的资源使用情况。
- 我们也可以通过kubectl top pod来查看pod的资源使用率。
- 当然,我们也可以查看pod的资源请求和限制,看是否所有的pod都有足够的资源分配,或者是否所有的pod都已经配置了limit。
- 最后,我们也可以查看节点层面的系统日志,检查有无异常的进程占用大量资源。
- 或者,我们要检查kubelet的日志,来看是否有异常的pod或者其他方面的异常程序。
我这边也给大家举了一个例子:在一个多租户的web应用中,由于用户量比较大,经常出现CPU使用率增高,就会导致应用性能波动。针对这一块,我这边也给大家介绍了如何避免在我们企业当中出现这种情况。
我们的前端应用和计算型应用一般都会在同一个namespace里面。有些时候,这些应用并没有完整地配置它的resource,例如limit或者request。这个时候如果资源出现了紧张的情况,大家就会争抢资源。为了在某个层面保证所有应用的存活,我们可以基于Kubernetes配置一些资源配额(Resource Quota)和限制范围(Limit Range),来限制每个命名空间内的资源消耗,避免单个应用或多个应用占用过多资源。
第二个案例是Node Memory Pressure。这个代表着当前node节点上面出现了内存层面的压力。有些时候,我们通过kubelet的日志或者是message的日志,就可以看到有些pod被OOM(Out of Memory)掉了。这个时候我们就可以:
- 通过describe命令去查看当前node节点的使用情况和当前状态。
- 根据当前我们筛选出来的pod,检查当前pod里面的内存请求和限制,确保pod没有超出分配的内存限制。
- 结合系统日志来查找OOM的进程记录。
我这边也给出了一个错误案例:节点在kubelet回收内存之前遇到内存不足的事件。我们可以依赖OOM来进行响应。kubelet会根据pod的服务质量(QoS)为每个容器设置不同的OOM评分。如果你全部配置了resource的limit以及request,这个时候pod的QoS服务质量是比较高的。如果这个时候你的pod没有配置任何层面的resource值,那么一旦出现资源紧张的情况,这个pod就会被优先杀掉。
那么我们如何去避免呢?
- 我们一定要为pod设置合理的内存请求和限制,避免内存超用。
- 同时,我们也要考虑实施内存回收策略和监控性能。
- 一旦出现这种类似的情况之后,如果我们有了一个完整的监控告警方案,那这个时候我们就可以提前收到这部分告警,手动地去干预这部分问题点。
第三个案例是Node Disk Pressure。这一点的故障现象主要是由于磁盘不足,无法写入日志或者拉取新的镜像,影响pod正常运行。有些时候大家可能会有一个疑问:当出现这个问题的时候,小伙伴登录到机器上,你可以看到当前node节点里面的磁盘容量还没有真正使用到100%,那为什么会报这样一个错误呢?
这个时候我们可以结合Kubernetes的资源保留来看一下。默认情况下,系统会针对性地保留一定的资源,目的就是一旦出现资源紧张的情况下,系统有足够的资源来杀掉这些异常的程序。同样,磁盘也是如此,kubelet不会让所有的pod使用全量的磁盘。
一旦出现了这类情况之后,我们首先要通过命令去检查一下节点使用的情况。如果已经到达了Kubernetes设置的阈值,这个时候我们要做一些例如脏数据的处理或者磁盘的扩容。我们就可以:
- 检查是否有大的文件或者日志,或者一些脏数据占用了过多的空间。
- 检查pod的存储请求,确认存储是否按需进行了分配。
这边我也举了一个例子:有些时候,pod的日志是落到数据盘层面的。这个时候,如果应用没有使用日志清理框架,那么长期就会导致日志大量占用磁盘的可用空间,导致未来新的pod无法被调度,或者现有的pod无法写入新的数据到当前的node节点里面去。
这个时候,我们可以:
- 通过应用层面的日志框架,配置日志保留的天数。
- 通过Kubernetes的动态存储来保证存储资源的按需分配。
这样就不会导致当前node节点的磁盘压力。
原文链接: https://dashen.tech/2020/10/24/K8s排错-调试技巧/
版权声明: 转载请注明出处.