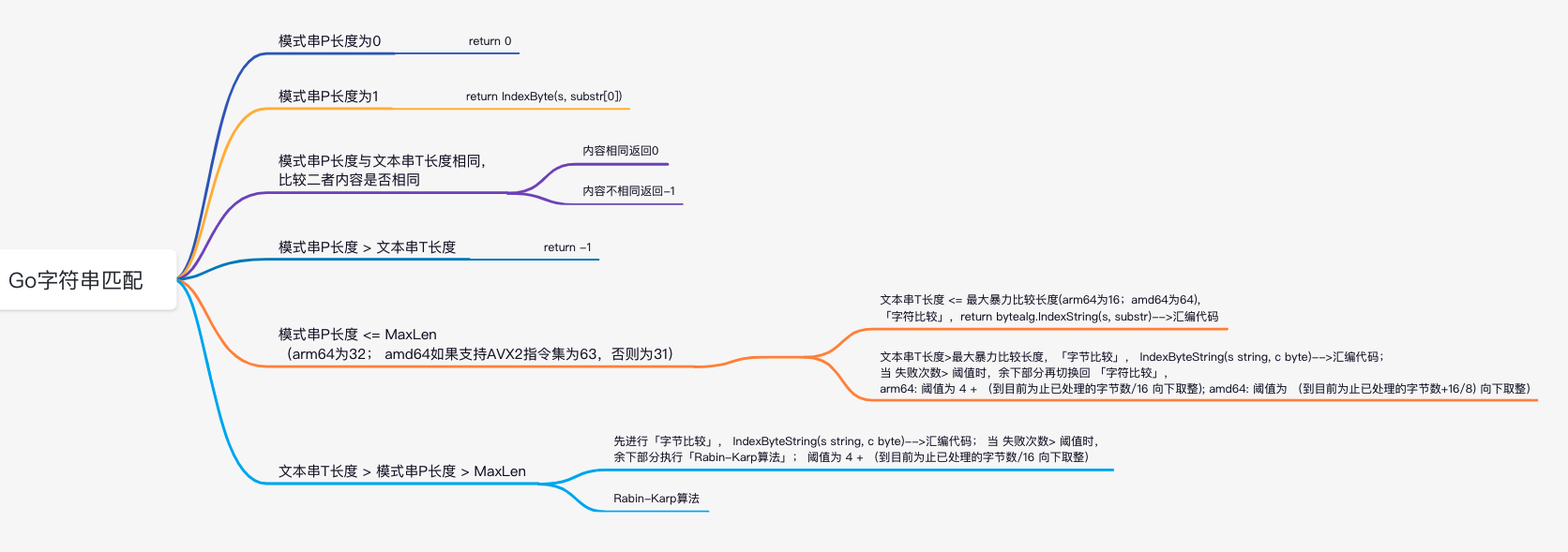
// Index returns the index of the first instance of substr in s, or -1 if substr is not present in s. funcIndex(s, substr string)int { n := len(substr) switch { case n == 0: return0 case n == 1: return IndexByte(s, substr[0]) case n == len(s): if substr == s { return0 } return-1 case n > len(s): return-1 case n <= bytealg.MaxLen: // Use brute force when s and substr both are small iflen(s) <= bytealg.MaxBruteForce { return bytealg.IndexString(s, substr) } c0 := substr[0] c1 := substr[1] i := 0 t := len(s) - n + 1// 滑动窗口,如s长度为100,substr长度为7,那完成整个比较过程,最多仅需要滑动 100-7+1=94 次(此处并不是每次+1比较,所以需要的次数实际会更少) fails := 0 for i < t { if s[i] != c0 { // IndexByte is faster than bytealg.IndexString, so use it as long as // we're not getting lots of false positives.
// IndexByte 比 bytealg.IndexString 快,所以只要我们没有收到很多误报,就尽可能去使用IndexByte o := IndexByte(s[i+1:t], c0) if o < 0 { return-1 } i += o + 1 } if s[i+1] == c1 && s[i:i+n] == substr { return i } fails++ i++ // Switch to bytealg.IndexString when IndexByte produces too many false positives. // 当IndexByte有太多误报时,切回到bytealg.IndexString // 失败次数> 阈值时,余下部分再切换回 「字符比较」; 对于arm64: 阈值为 4 + (到目前为止已处理的元素数/16 向下取整); 对于amd64: 阈值为 (到目前为止已处理的元素数+16/8) 向下取整) if fails > bytealg.Cutover(i) { r := bytealg.IndexString(s[i:], substr) if r >= 0 { return r + i } return-1 } } return-1 } c0 := substr[0] c1 := substr[1] i := 0 t := len(s) - n + 1 fails := 0 for i < t { if s[i] != c0 { o := IndexByte(s[i+1:t], c0) if o < 0 { return-1 } i += o + 1 } if s[i+1] == c1 && s[i:i+n] == substr { return i } i++ fails++
// 当 失败次数> 阈值时,余下部分执行「Rabin-Karp算法」; 对于arm64和amd64,阈值均为 4 + (到目前为止已处理的元素数/16 向下取整) // 好奇:为何和上面bytealg.Cutover(i)的阈值逻辑不一样? if fails >= 4+i>>4 && i < t { // See comment in ../bytes/bytes.go. j := bytealg.IndexRabinKarp(s[i:], substr) if j < 0 { return-1 } return i + j } } return-1 }
// IndexByte returns the index of the first instance of c in s, or -1 if c is not present in s. // IndexByte 返回 s 中 c 的第一个实例的索引,如果 c 不存在于 s 中,则返回 -1。 // 即给一个字符串和单个”字符“,返回这个字符在字符串中第一次出现的位置。汇编代码,暴力比较 funcIndexByte(s string, c byte)int { return bytealg.IndexByteString(s, c) }
// IndexString returns the index of the first instance of b in a, or -1 if b is not present in a. // Requires 2 <= len(b) <= MaxLen. //IndexString 返回 a 中 b 的第一个实例的索引,如果 b 不存在于 a 中,则返回 -1。 需要 2 <= len(b) <= MaxLen。 // 即给两个字符串a和b,返回字符串b在字符串a中第一次出现的位置。汇编代码,暴力比较 funcIndexString(a, b string)int
// Copyright 2018 The Go Authors. All rights reserved. // Use of this source code is governed by a BSD-style // license that can be found in the LICENSE file.
package bytealg
// Empirical data shows that using Index can get better // performance when len(s) <= 16. const MaxBruteForce = 16
funcinit() { // Optimize cases where the length of the substring is less than 32 bytes MaxLen = 32 }
// Cutover reports the number of failures of IndexByte we should tolerate // before switching over to Index. // n is the number of bytes processed so far. // See the bytes.Index implementation for details.
//Cutover 报告在切换到 Index 之前我们应该容忍的 IndexByte 的失败次数。 //n 是到目前为止处理的字节数。 //有关详细信息,请参阅 bytes.Index 实现。 funcCutover(n int)int { // cutover 切换;转换,和switch一个意思 // 1 error per 16 characters, plus a few slop to start. //每 16 个字符有 1 个错误,加上开始时的一些错误。 // 即 n/16向下取整,再+4 return4 + n>>4 }
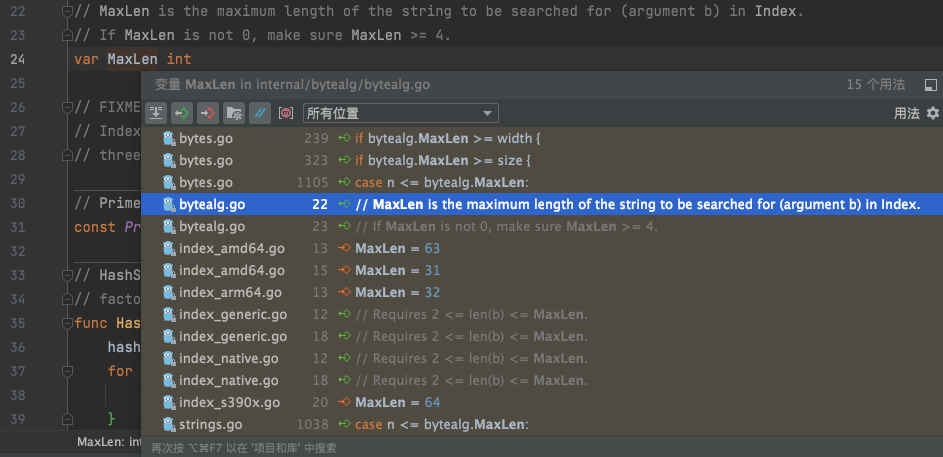
// MaxLen is the maximum length of the string to be searched for (argument b) in Index. // If MaxLen is not 0, make sure MaxLen >= 4. var MaxLen int
// PrimeRK is the prime base used in Rabin-Karp algorithm. // primeRK相当于进制 (直译为 素数基) const PrimeRK = 16777619
// IndexRabinKarp uses the Rabin-Karp search algorithm to return the index of the // first occurrence of substr in s, or -1 if not present. // IndexRabinKarp 使用 Rabin-Karp 搜索算法返回 substr 在 s 中第一次出现的索引,如果不存在则返回 -1。 funcIndexRabinKarp(s, substr string)int { // Rabin-Karp search // 返回待匹配字符串(模式串)的哈希值(即P串),以及pow (为PrimeRK的n-1次方,n为模式串的长度) hashss, pow := HashStr(substr) n := len(substr) var h uint32 for i := 0; i < n; i++ { h = h*PrimeRK + uint32(s[i]) } if h == hashss && s[:n] == substr { return0 } for i := n; i < len(s); { h *= PrimeRK h += uint32(s[i]) h -= pow * uint32(s[i-n]) i++ if h == hashss && s[i-n:i] == substr { return i - n } } return-1 }
// HashStr returns the hash and the appropriate multiplicative // factor for use in Rabin-Karp algorithm. //HashStr的两个返回值,hashss即9图中P模式串的哈希值,pow为PrimeRK的n-1次方(n为模式串P的长度) funcHashStr(sep string) (uint32, uint32) { hash := uint32(0) for i := 0; i < len(sep); i++ { // 当某个运算后发生溢出,将结果对uint32的上限即(1<<32 - 1,也就是4294967295)取模;而后再进行后面的运算 // 类似于一个时钟表盘,从现在开始3小时和27小时后,指针都在相同位置 hash = hash*PrimeRK + uint32(sep[i]) } var pow, sq uint32 = 1, PrimeRK for i := len(sep); i > 0; i >>= 1 { // i >>= 1 即 i = i >> 1 if i&1 != 0 { pow *= sq } sq *= sq } return hash, pow }