图片来自 图解redis五种数据结构底层实现,版权原作者所有
Redis五种数据结构的底层实现
Redis是一款基于内存的高性能键值存储数据库,支持多种数据结构。下面是Redis五种数据结构的底层实现:
字符串(string):Redis字符串是二进制安全的,可以存储任何类型的数据,最大可以存储512MB。Redis使用简单动态字符串SDS(Simple Dynamic String)来实现字符串,SDS是Redis为了解决C语言字符串常见问题而开发的一种字符串表示方式。SDS内部维护了字符串的长度信息,这使得Redis可以快速计算字符串长度,而不需要像C语言字符串那样每次都要遍历一次字符串。
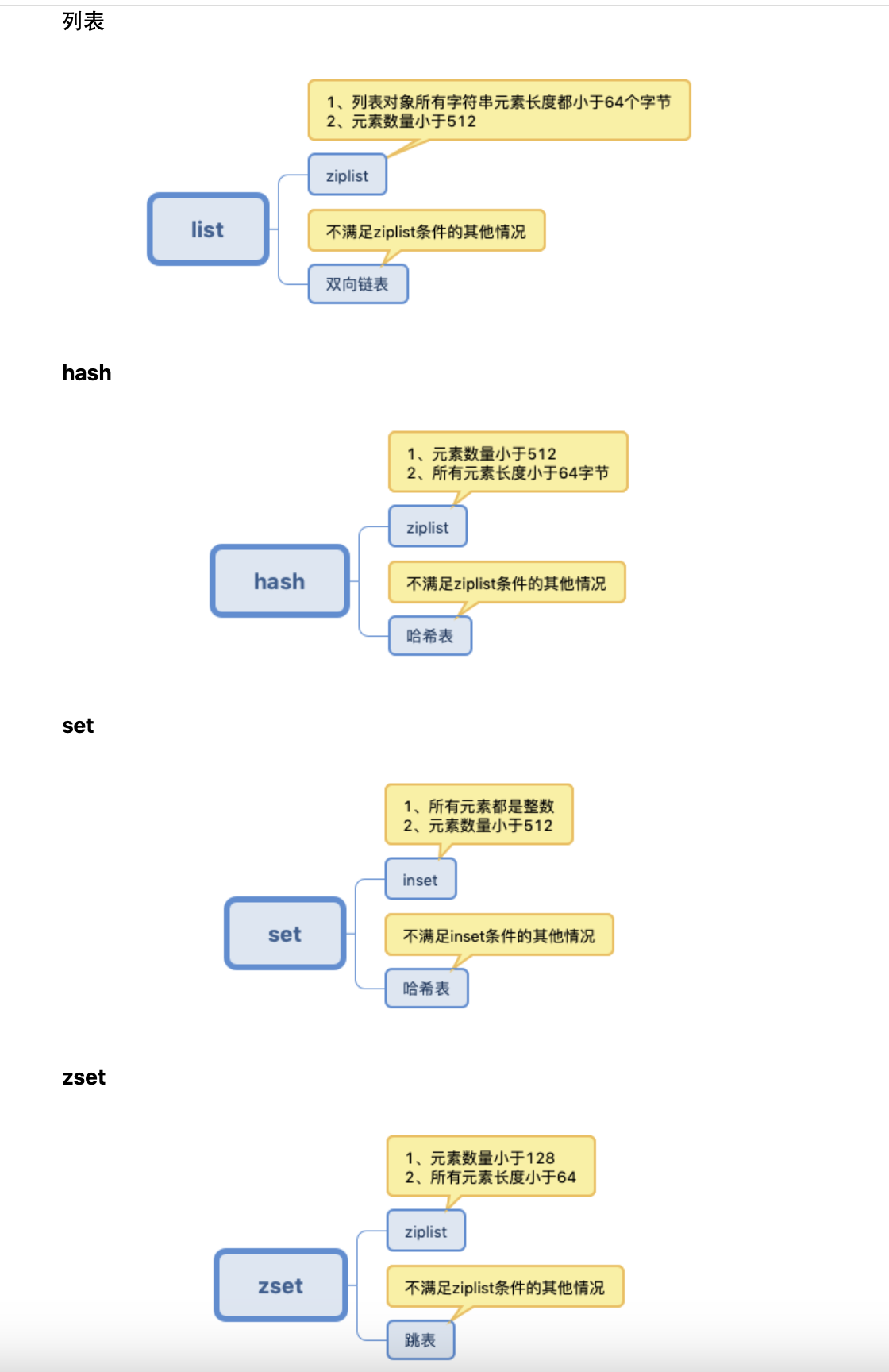
列表(list):Redis列表是一个双向链表,链表中的每个节点包含一个指向前一个节点的指针、一个指向后一个节点的指针,以及一个指向列表元素的指针。Redis还实现了一个ziplist结构,ziplist是一种紧凑型的、压缩的列表结构,适用于小规模的列表。
哈希表(hash):Redis哈希表是一种键值对存储结构,使用哈希表实现。每个哈希表节点都包含一个指向下一个节点的指针,这使得Redis可以高效地遍历哈希表。
集合(set):Redis集合是一个无序的、唯一的元素集合,使用哈希表实现。当集合元素较少时,Redis还可以使用intset结构实现,intset是一种紧凑型的、压缩的整数集合结构,适用于小规模的集合。
有序集合(sorted set):Redis有序集合是一个有序的、唯一的元素集合,使用跳跃表和哈希表实现。跳跃表是一种类似于平衡树的数据结构,可以快速地进行查找、插入和删除操作,同时具有较低的空间复杂度。哈希表用于存储元素到分值的映射关系。
String
使用SDS
List
根据数据量多少,底层使用 ziplist和双向链表
新版本改为ziplist和quicklist
Hash
Set
Zset
根据数据量多少,底层Key使用 ziplist和跳表
跳表也称为跳跃表,高端面试很容易问到,Redis底层数据问这块能问的也就是跳表,所以几乎是明牌
这篇很不错,非常详细:
Redis 为什么用跳表而不用平衡树?
skiplist本质上也是一种查找结构,用于解决算法中的查找问题(Searching),即根据给定的key,快速查到它所在的位置(或者对应的value
这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半
大致思想是先大步走(一步抵过去两步,或者更多步,取决于层数,即跨多少个节点增加一个指针),超过了再往回退一下
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)
这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案
除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
空间换时间~
平均时间复杂度为O(log n)
1 | zset-max-ziplist-entries 128 |
这个配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成zset(具体的触发条件参见t_zset.c中的zaddGenericCommand相关代码):
- 当sorted set中的元素个数,即(数据, score)对的数目超过128的时候,也就是ziplist数据项超过256的时候。
- 当sorted set中插入的任意一个数据的长度超过了64的时候。

作者: William Pugh,对Java语言当前内存模型的开发有很大影响
pdd二面被问到了跳跃表
原文链接: https://dashen.tech/2022/01/06/Redis五种数据结构的底层实现/
版权声明: 转载请注明出处.