背景: 网易工作总结–性能优化
另外年初还做过一个拍脑袋决定的KPI项目,配置下发2.0。属于彻头彻尾的领导在其上一级抢功现眼型的东西。本身和我所在组几乎毫无关系,硬要我来做。需求混乱不清,需要拉会去收集,劝服。工作这么多年没有体验过的各种心累。。。当然这话说早了,之后的花式PUA还可以再开眼界。
简而言之方案是把原来写死的内容,打散存放,每次根据条件去判断和拼接。
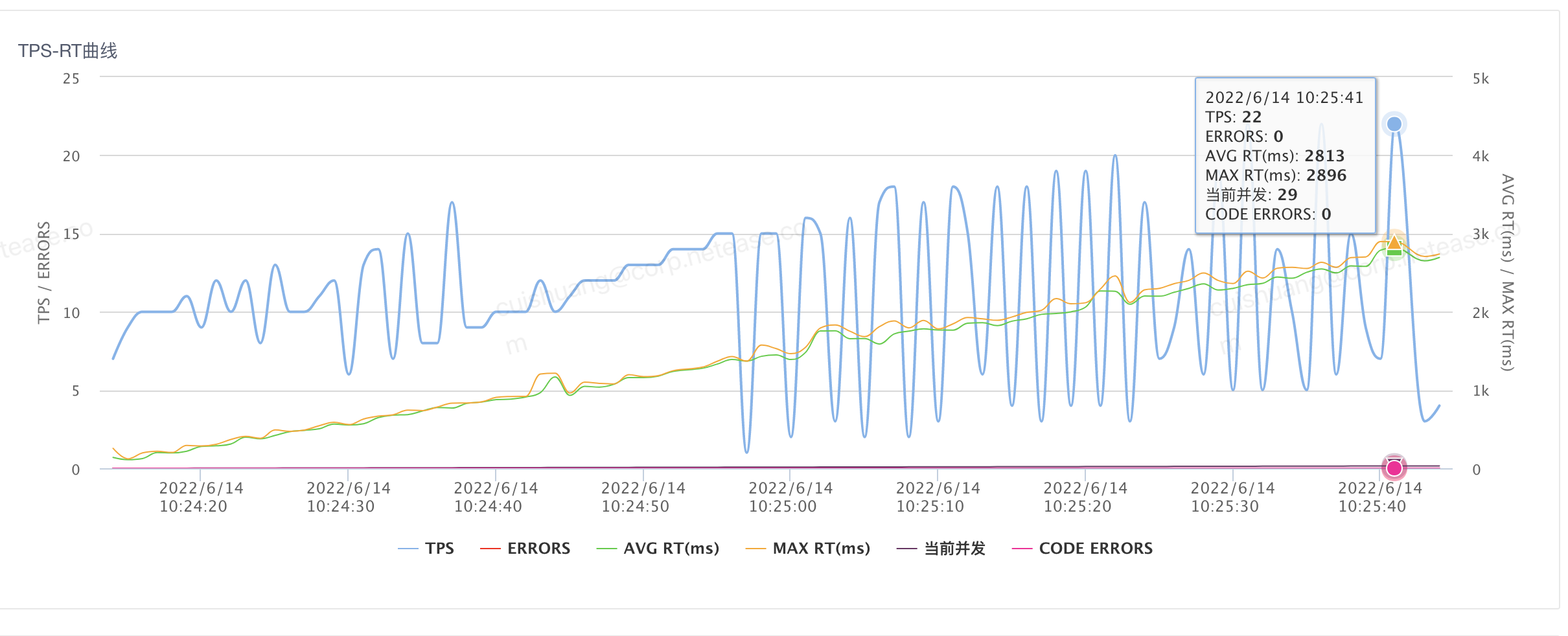
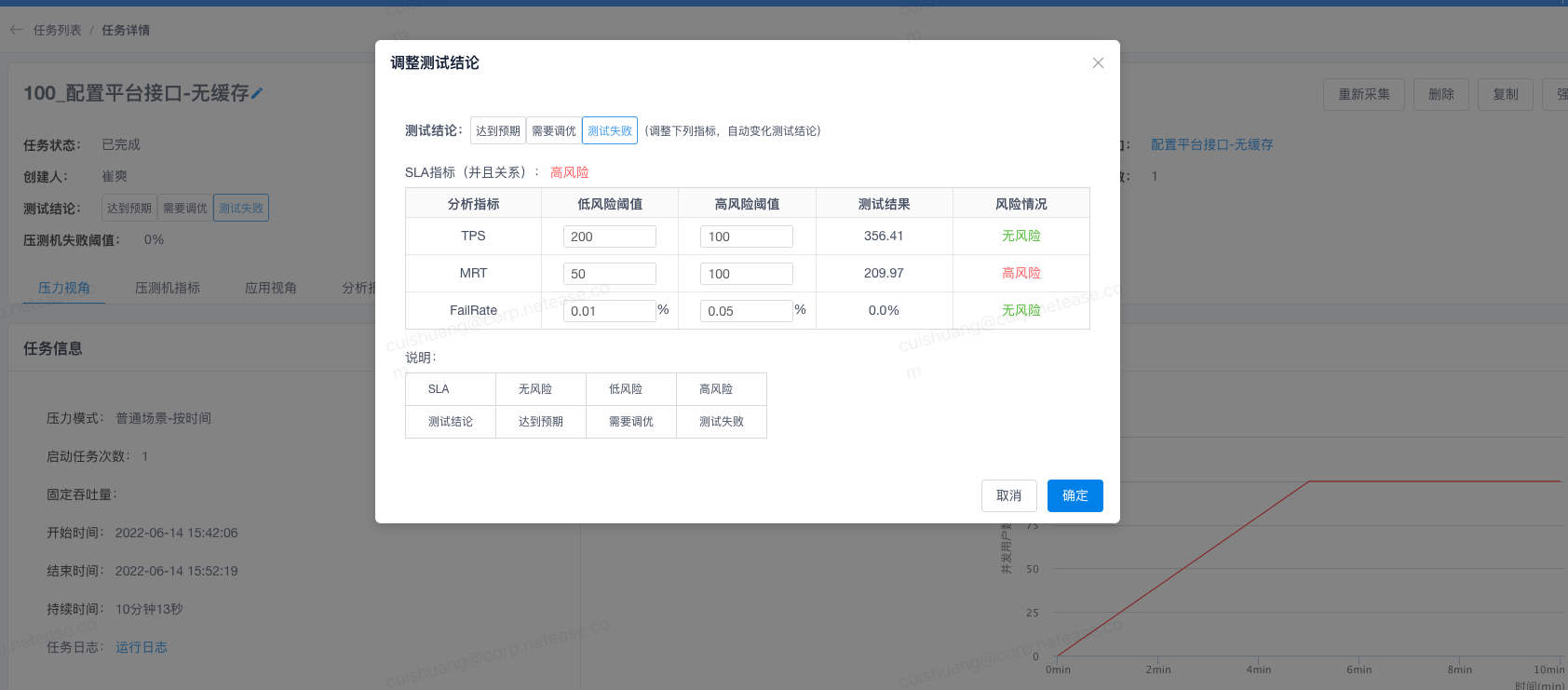
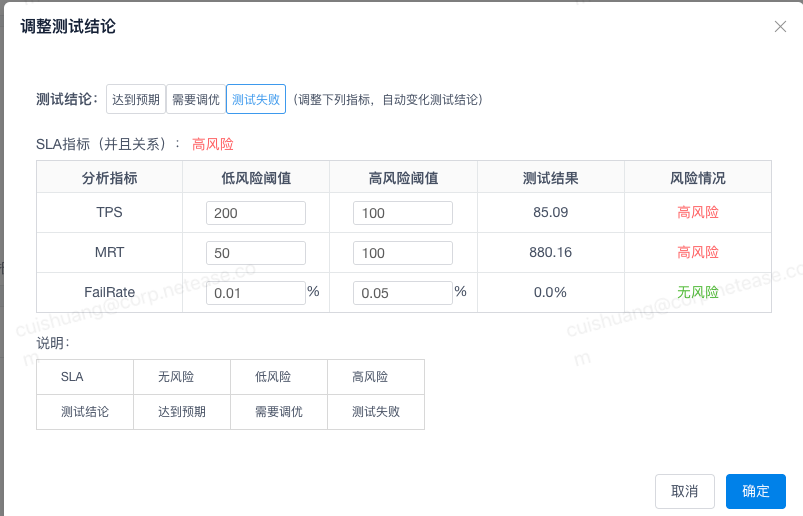
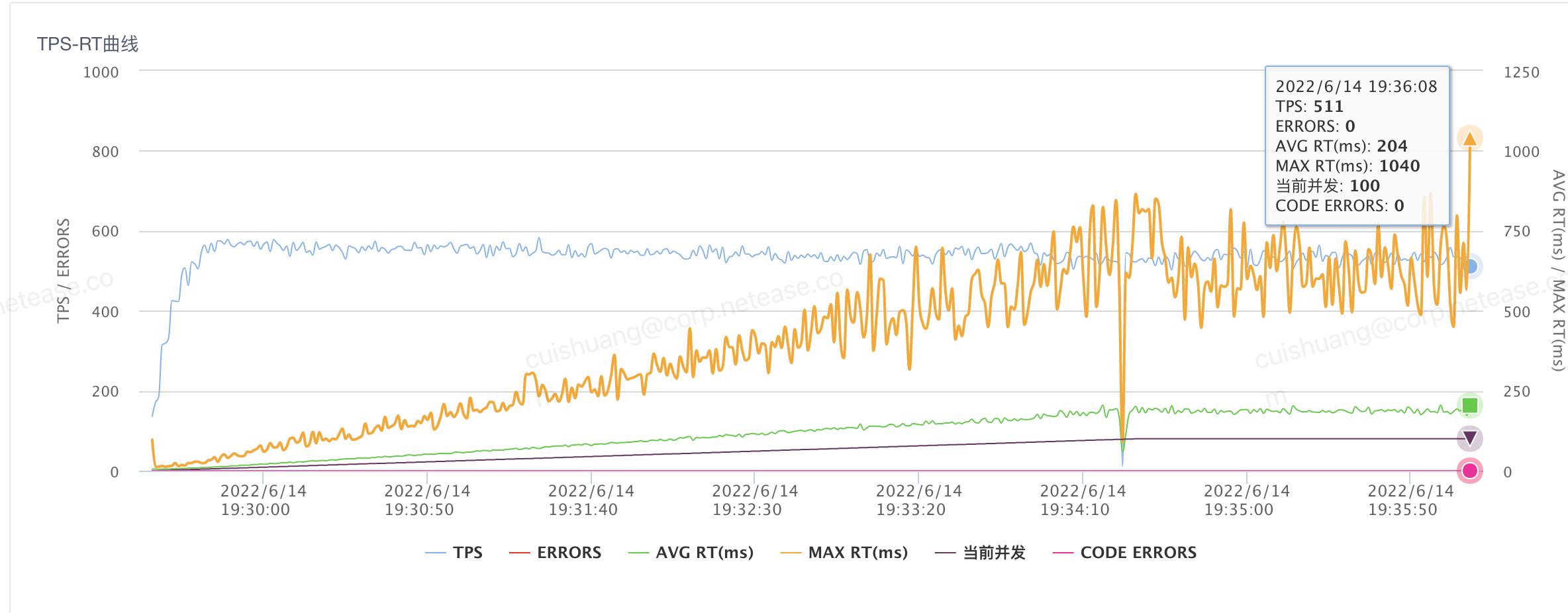
等开发完了,ld提要求说要20ms以内,开发前完全不提..
没办法硬着头皮去搞,以压榨机器学习提升心态,这样就能稍稍忽略这边10来年不干啥事的管理者,对下属的压榨。
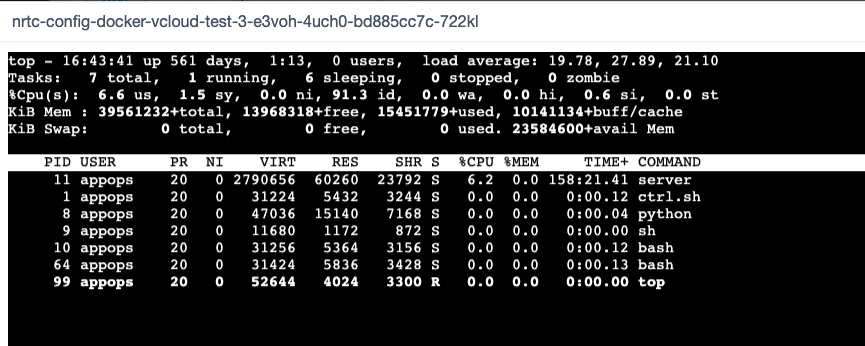
大致发生在2022年6月下旬
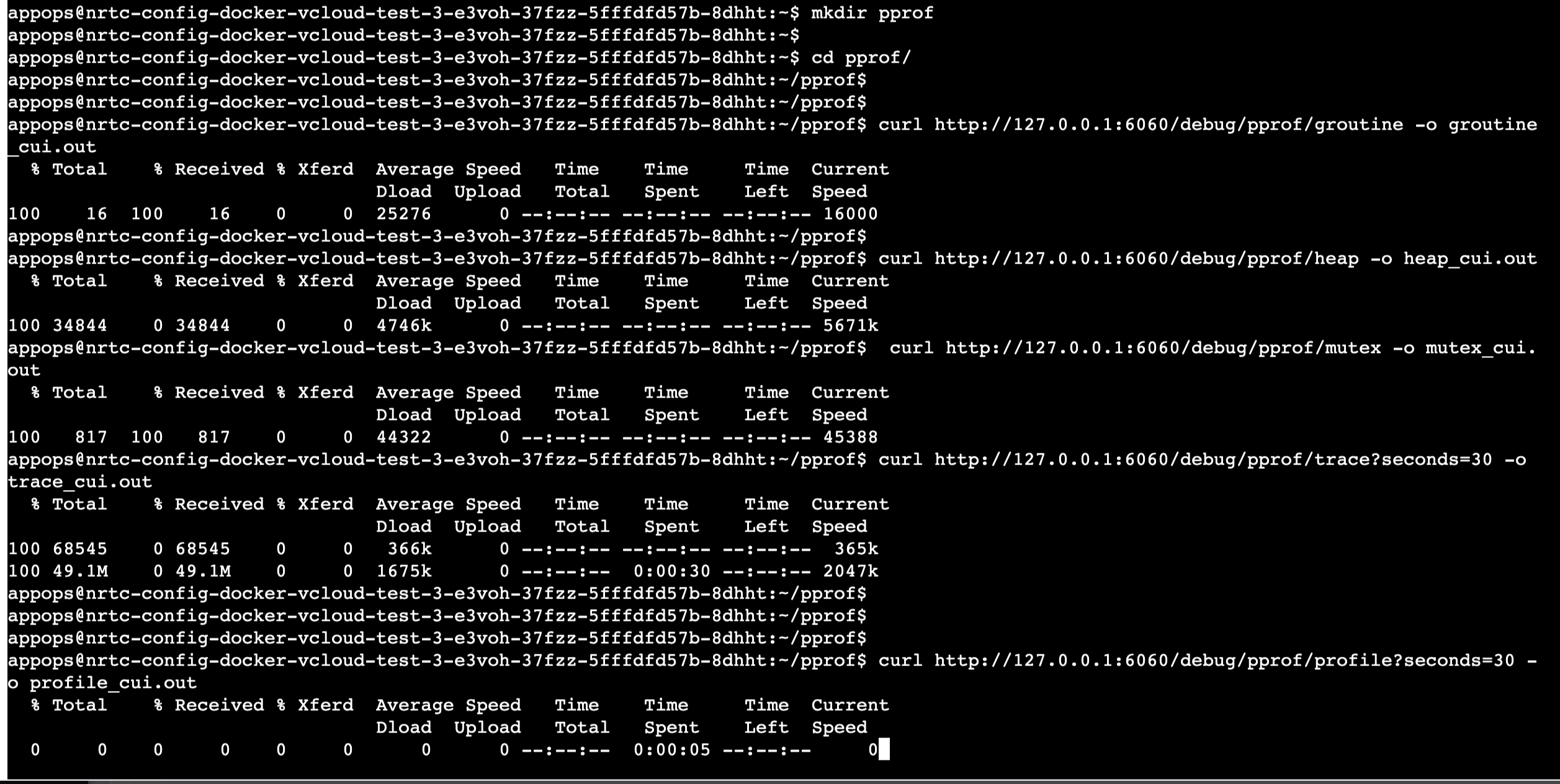
pprof占用的空间很小,几十k,几百k,最多几M.
但是trace占用的空间很大,一般都100M起步
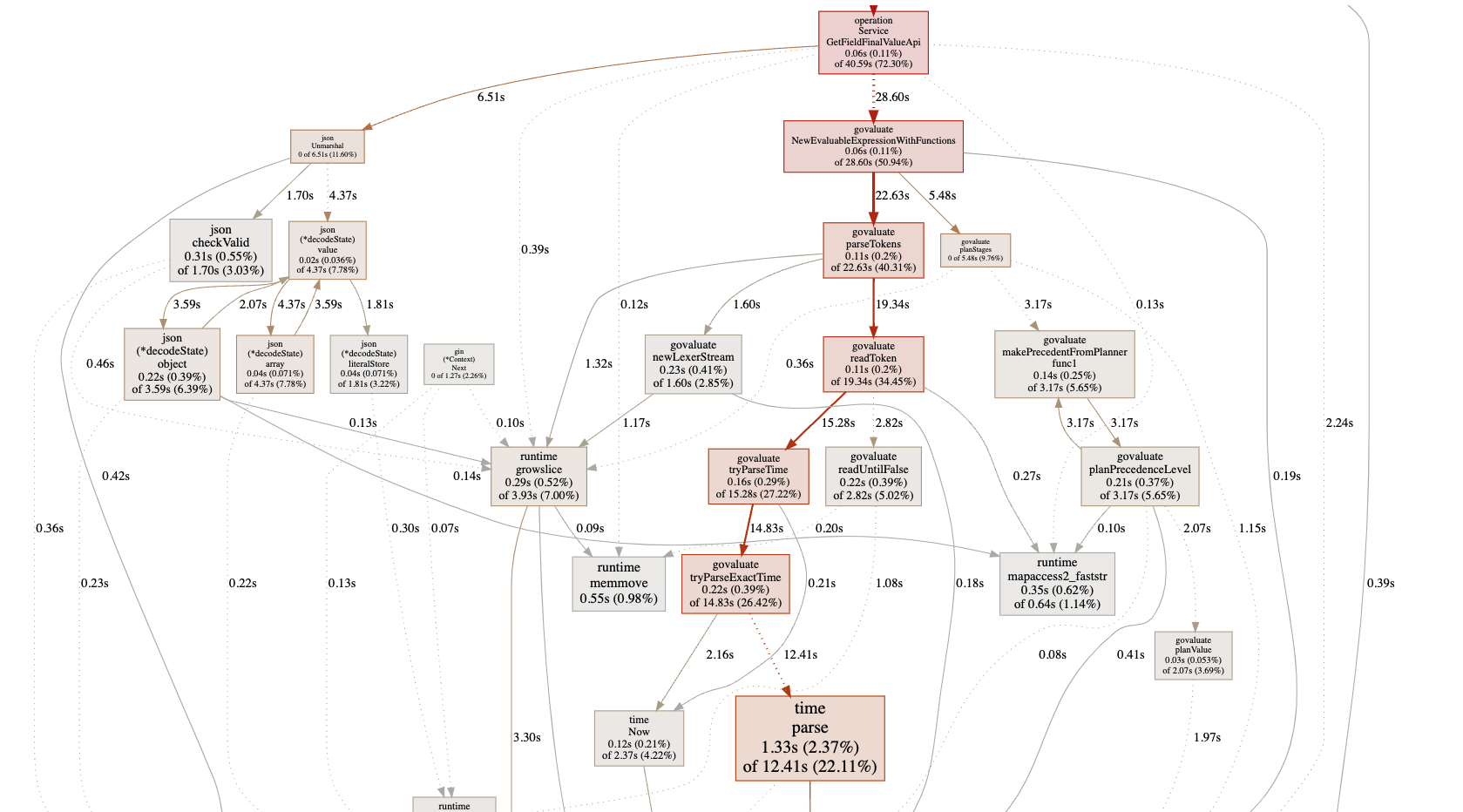
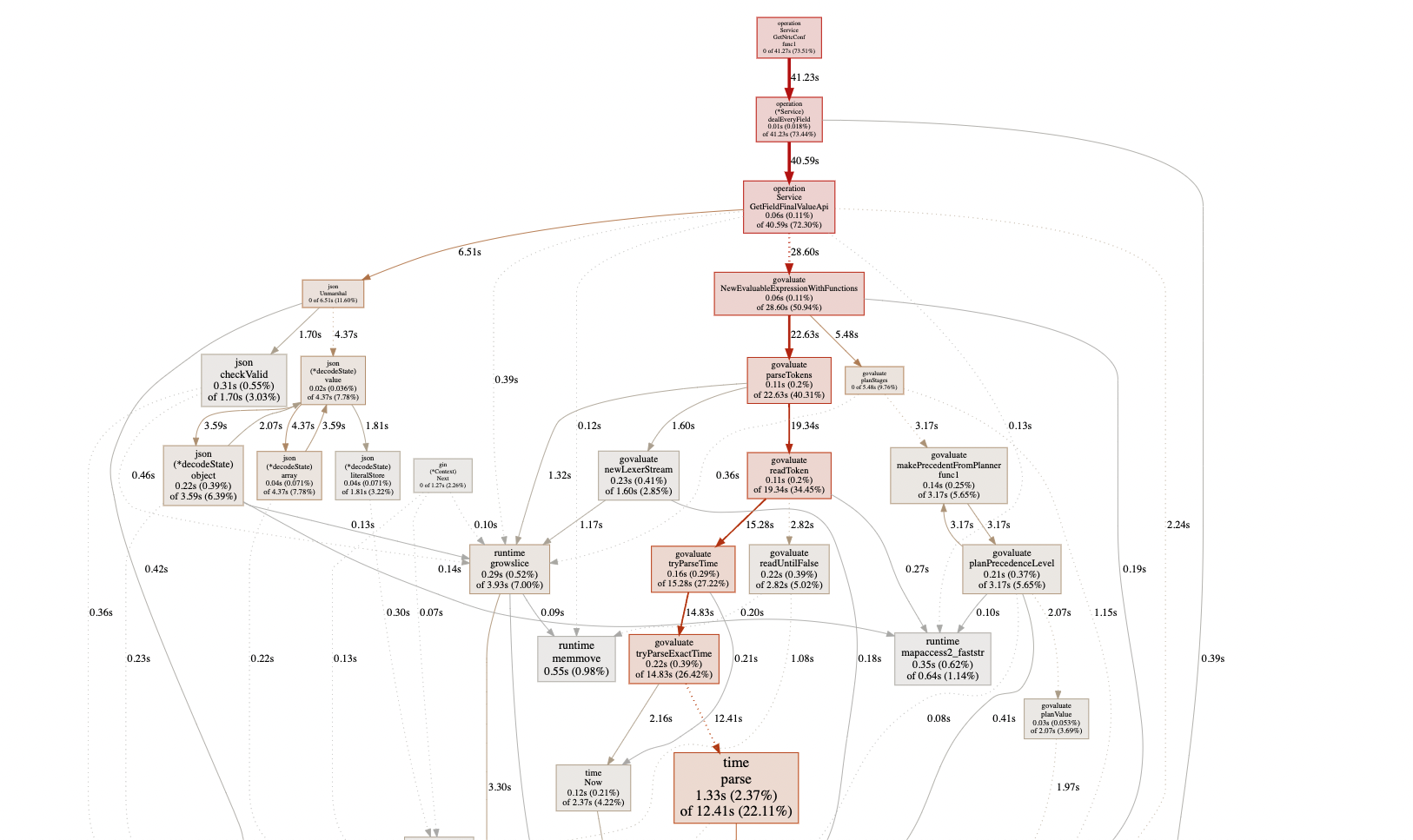
完整图片及pprof资料,见 https://github.com/cuishuang/performance-netease
因为好几个trace超过了100M, 无论github还是gitee,单个文件都不能超过100M
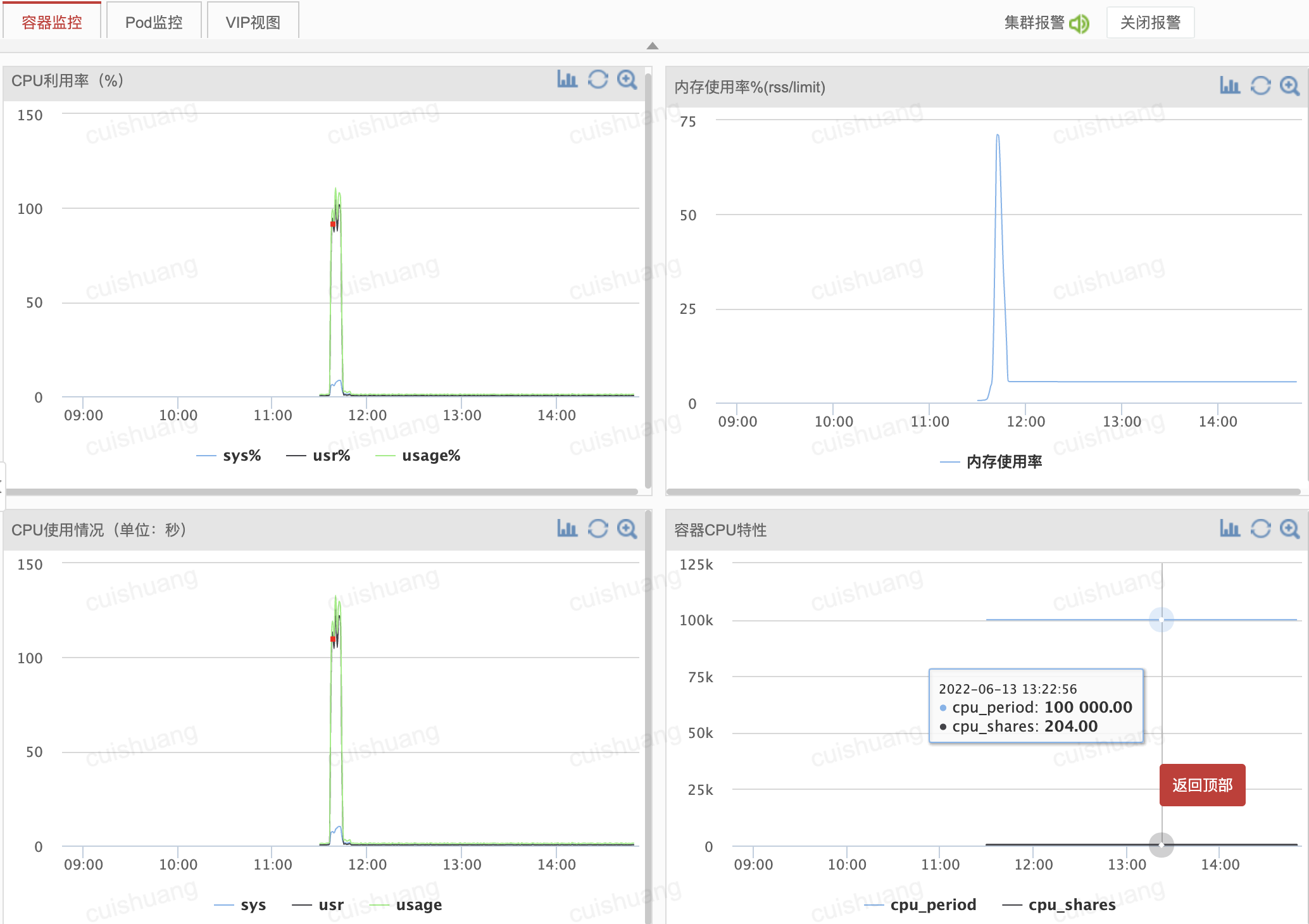
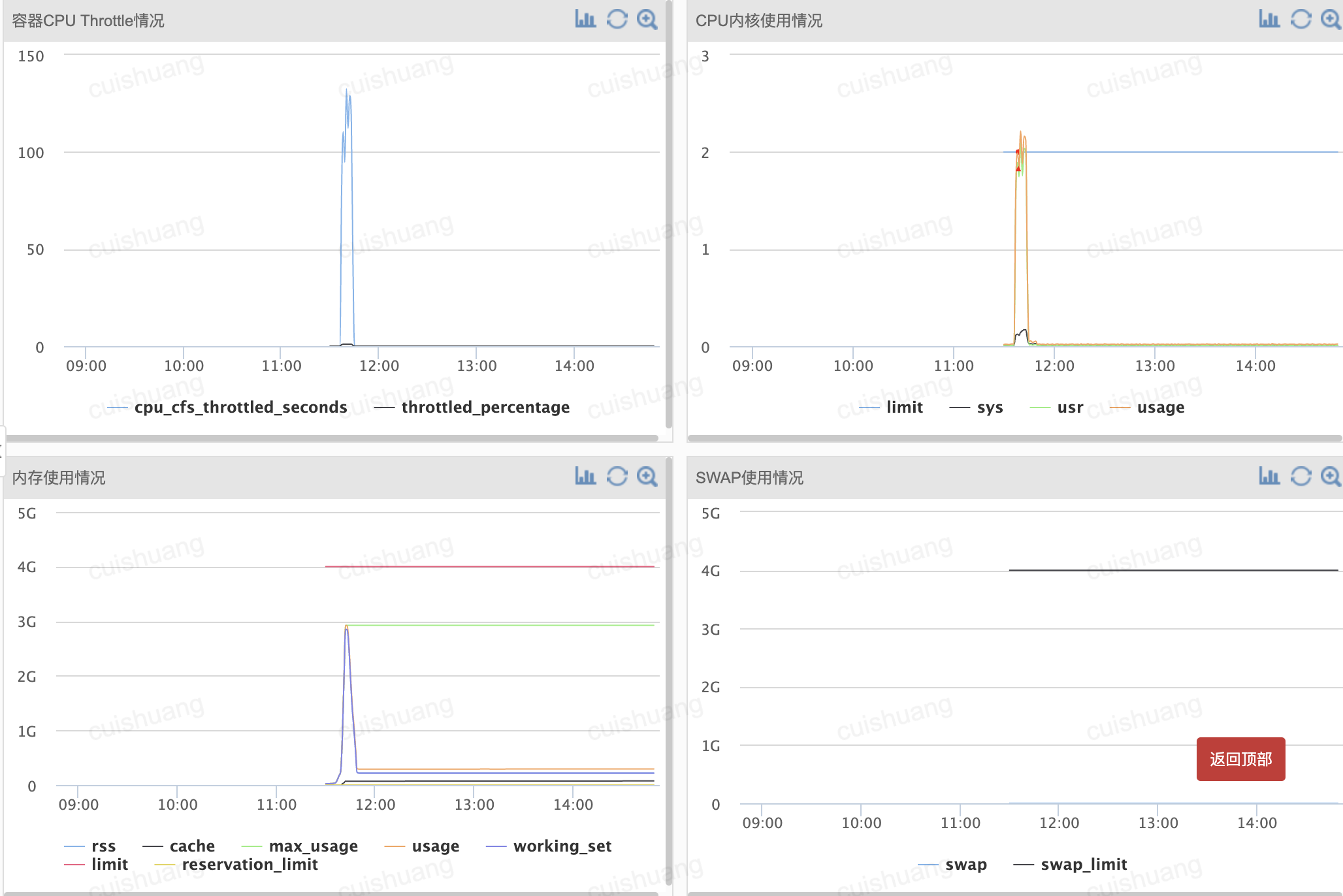
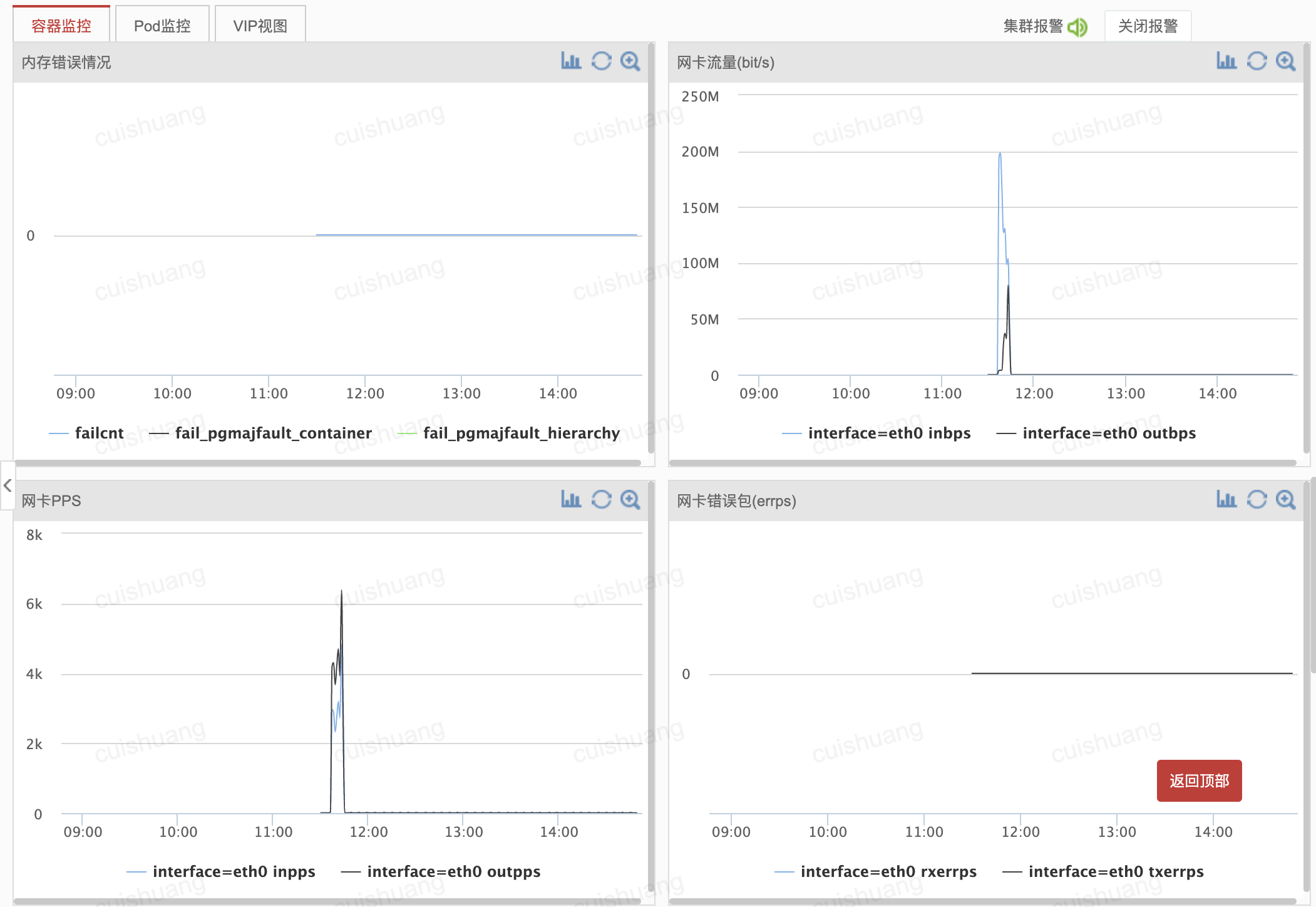
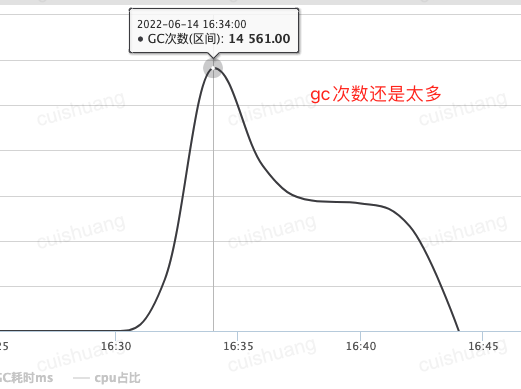
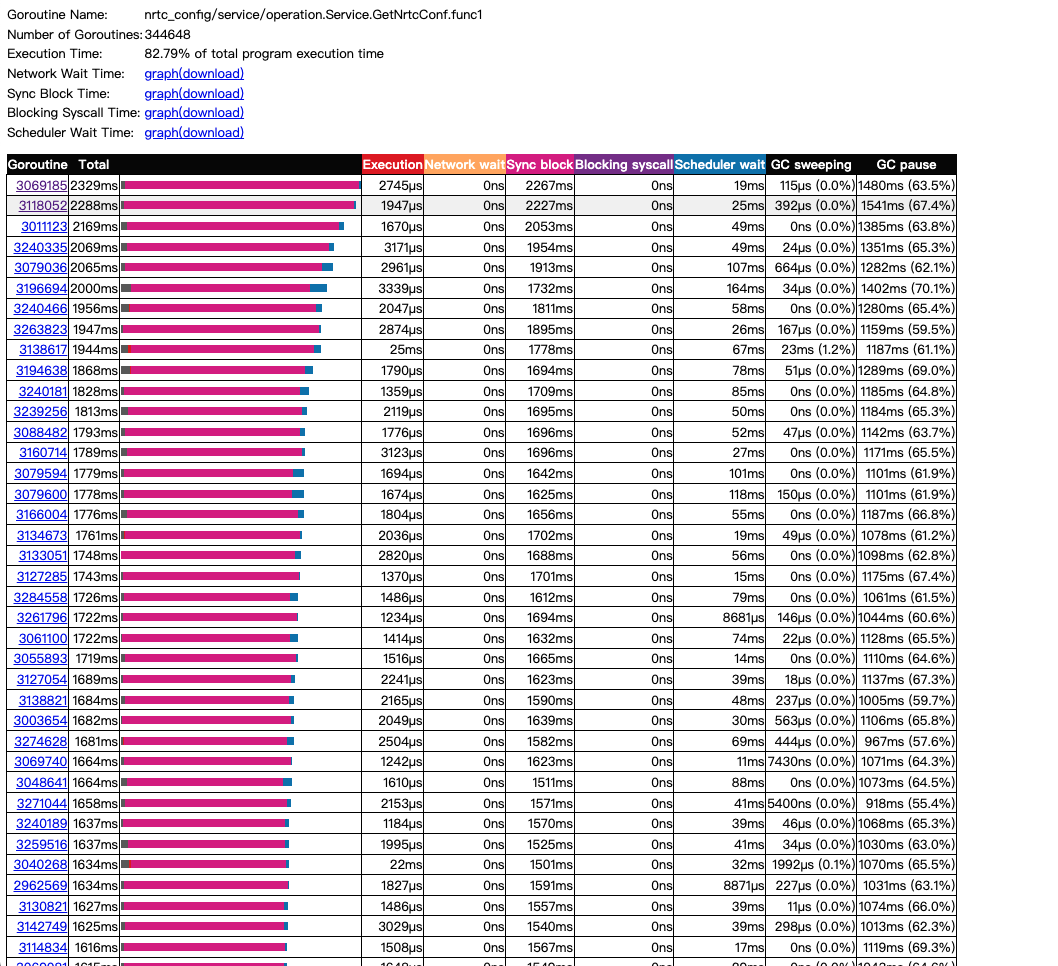
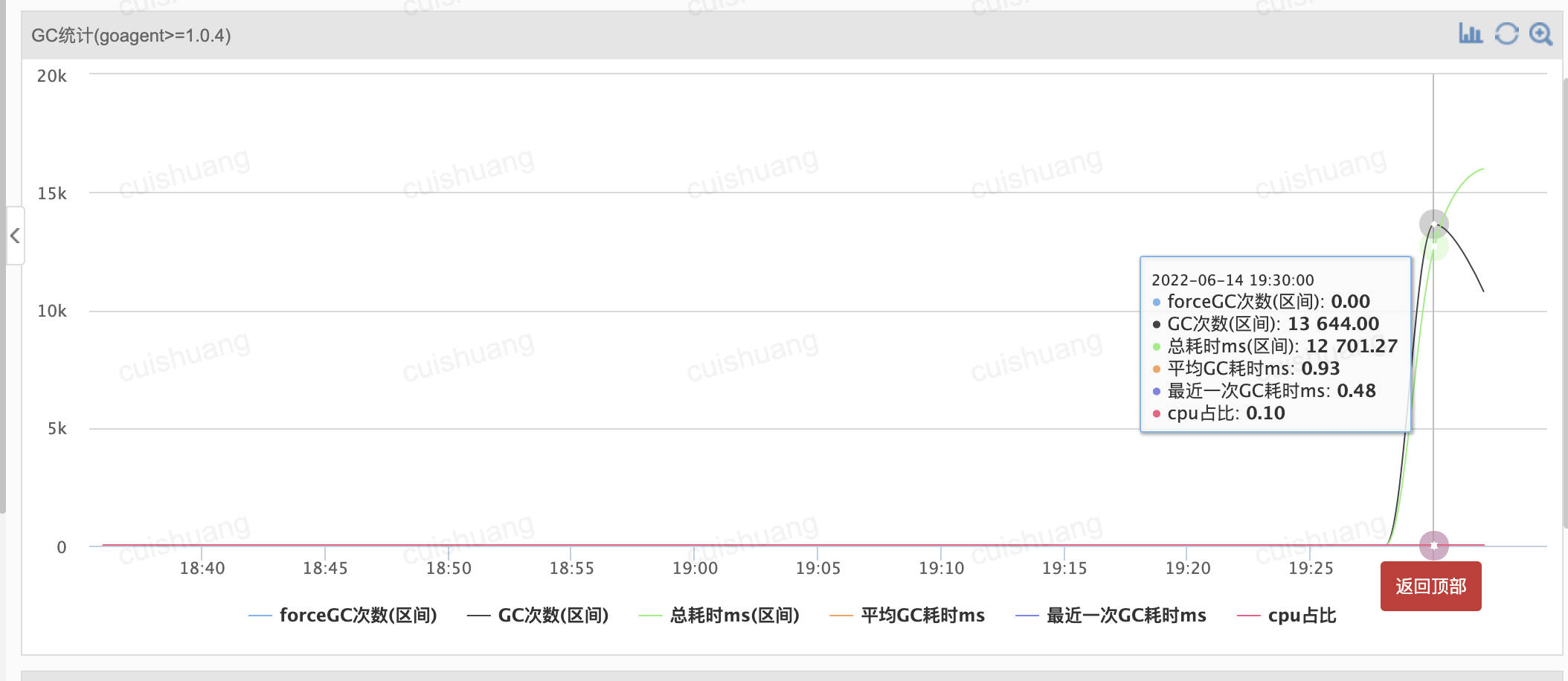
2分钟内gc占了20多秒: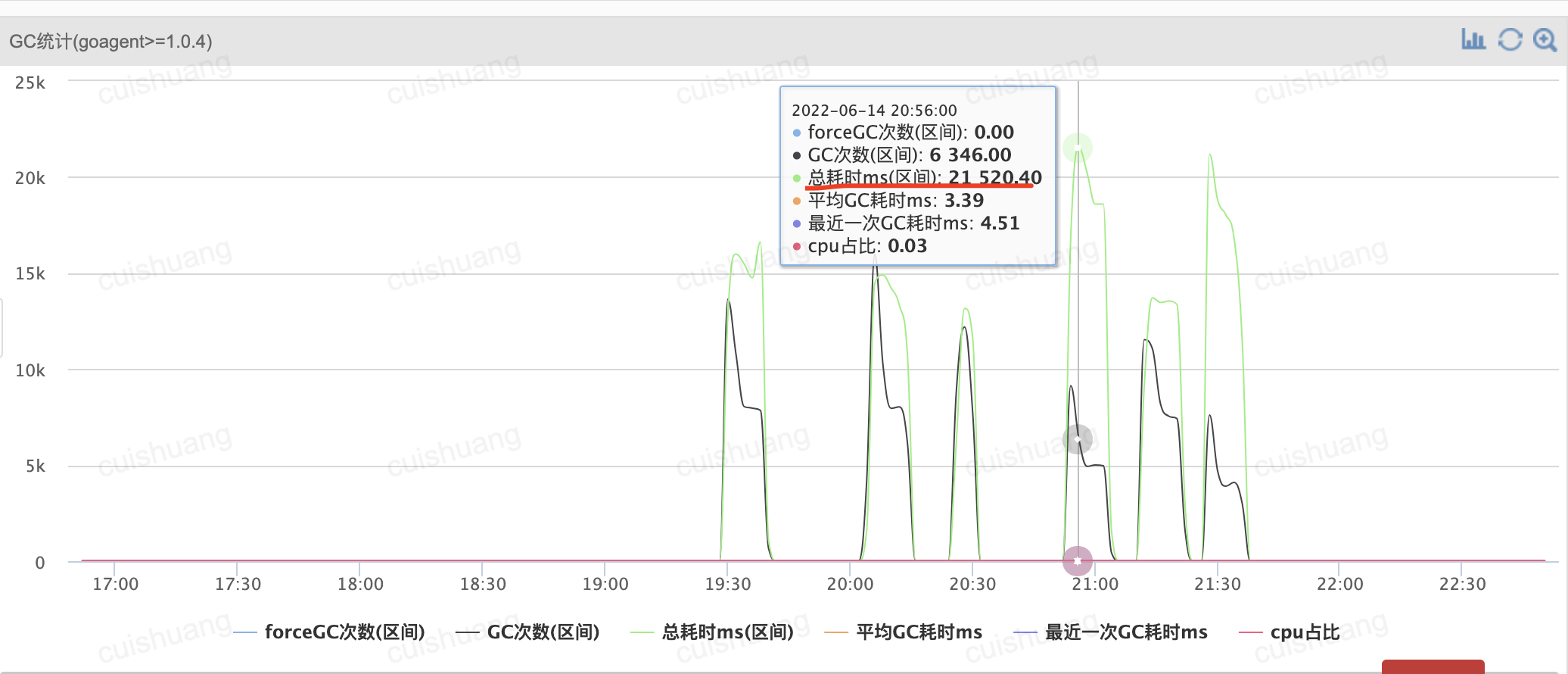


8核心:
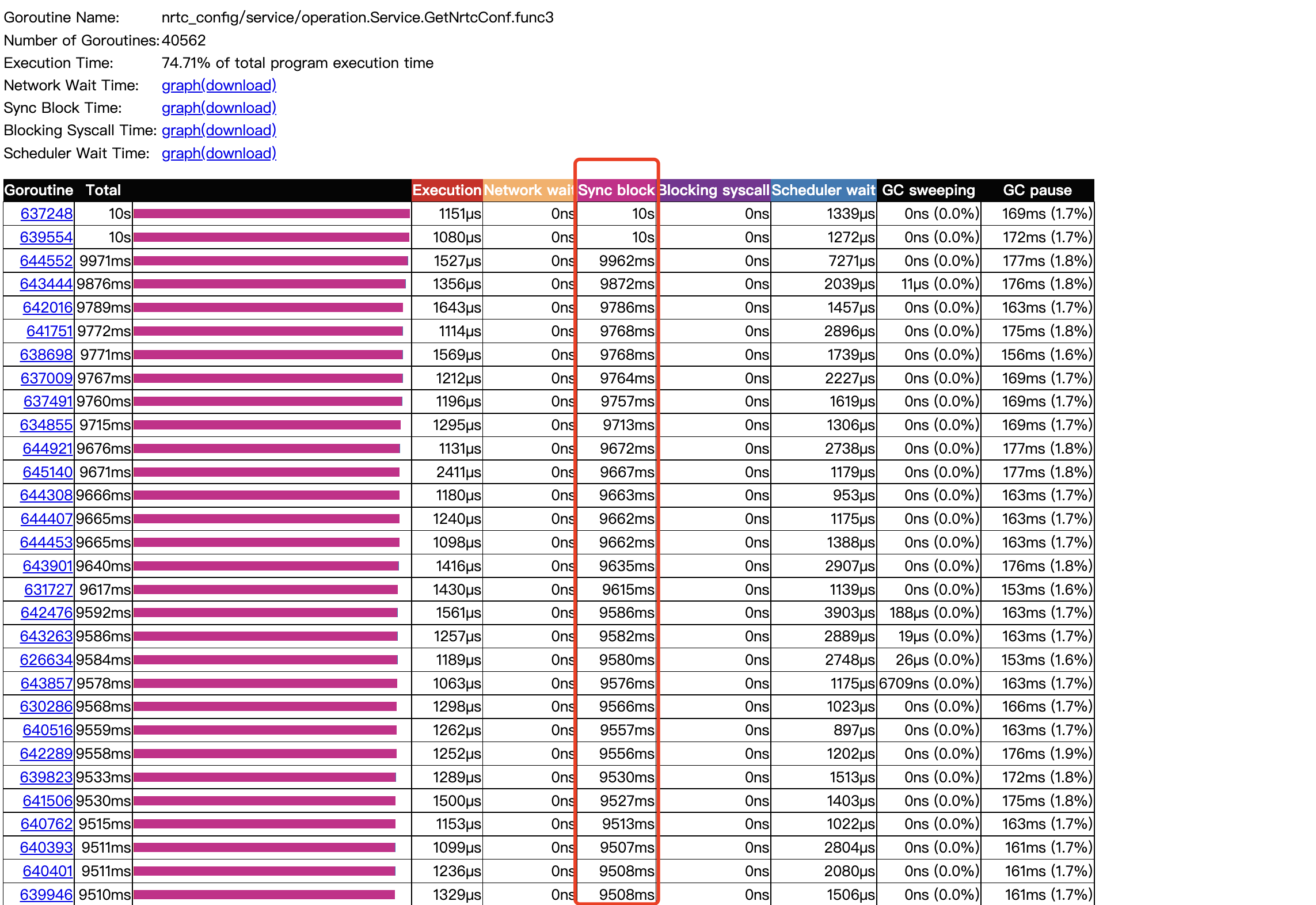


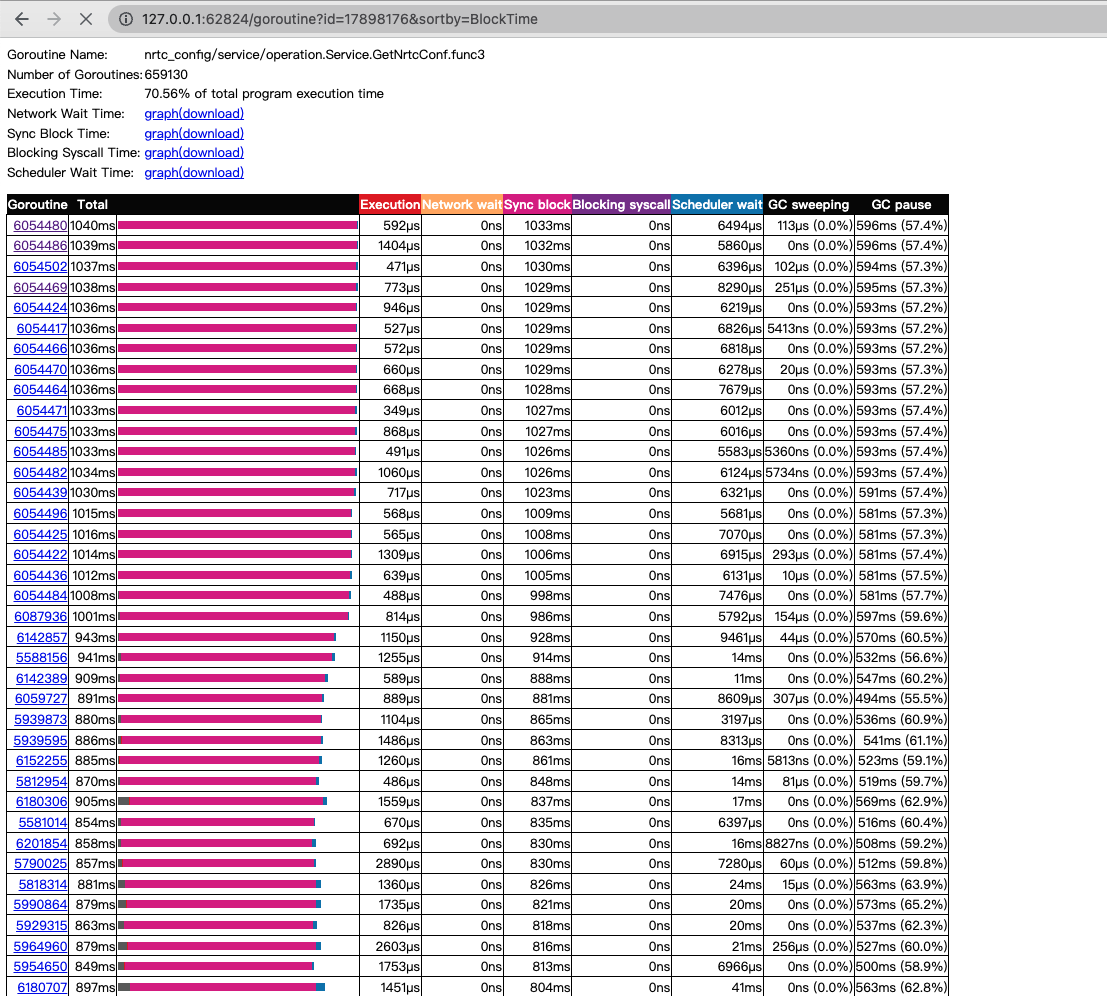
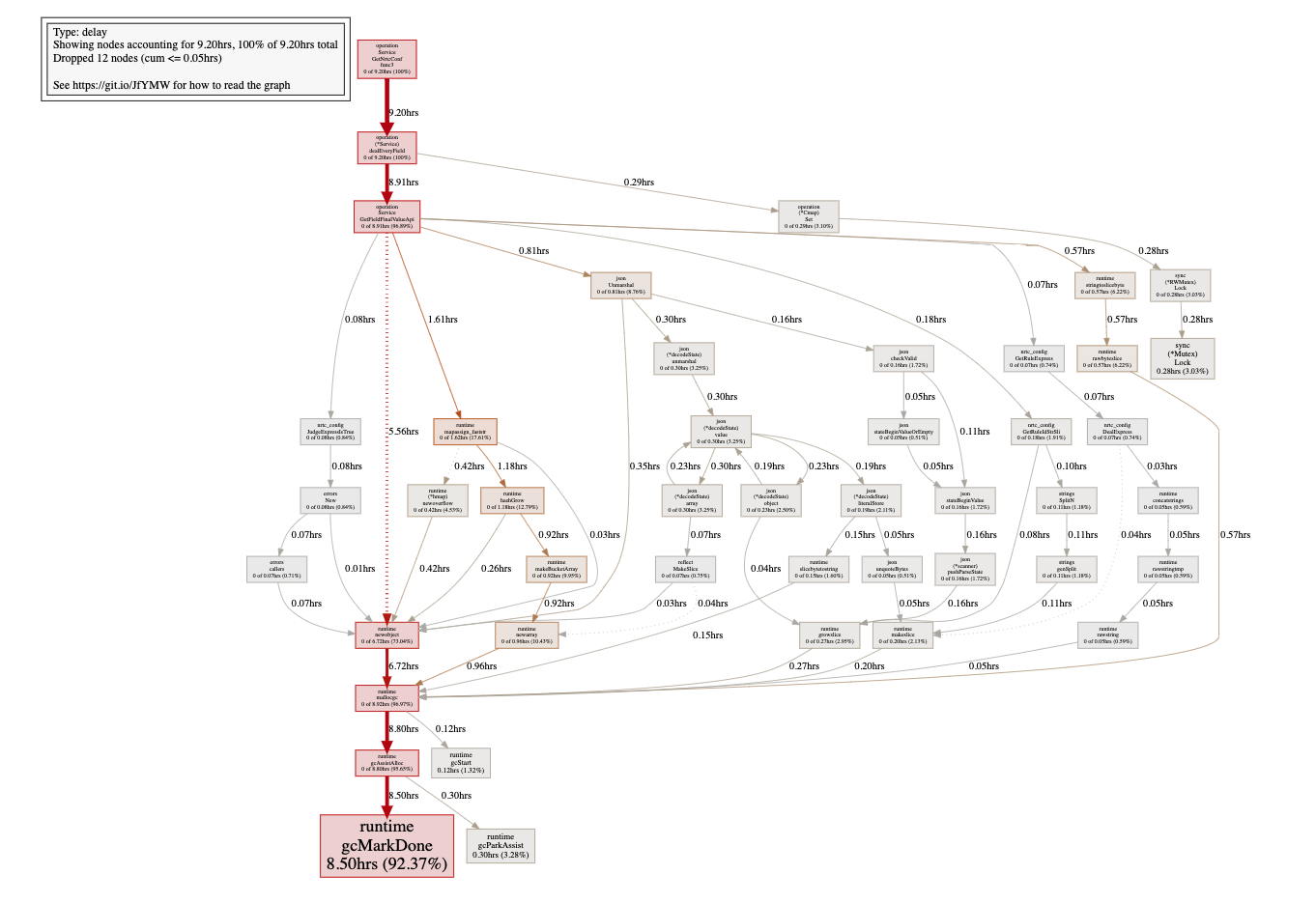
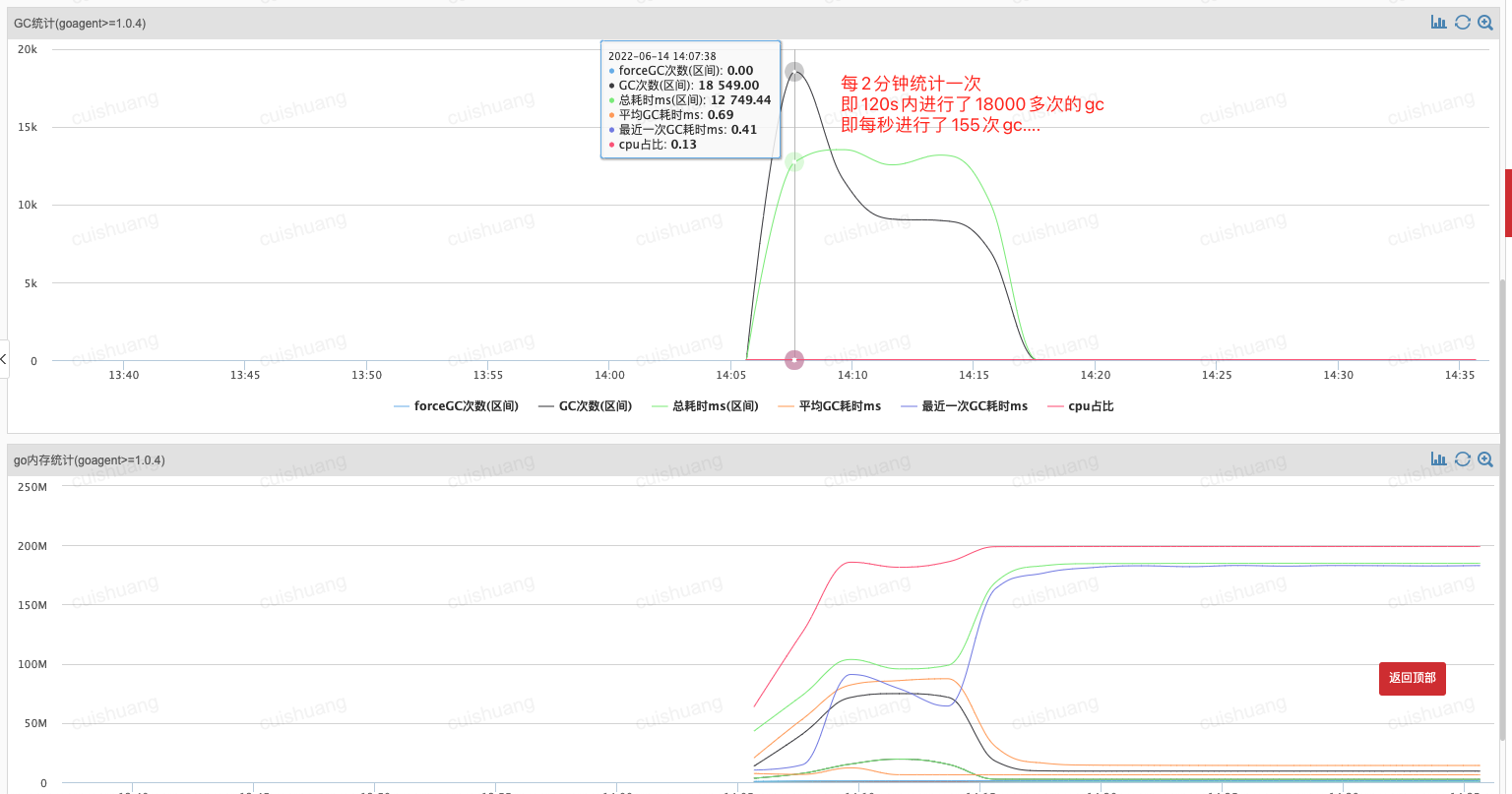
24核心:


在垃圾收集中有一些比较重要的全局变量,在分析其过程之前,我们会先逐一介绍这些重要的变量,这些变量在垃圾收集的各个阶段中会反复出现,所以理解他们的功能是非常重要的,我们先介绍一些比较简单的变量:
runtime.gcphase 是垃圾收集器当前处于的阶段,可能处于 _GCoff、_GCmark 和 _GCmarktermination,Goroutine 在读取或者修改该阶段时需要保证原子性;
runtime.gcBlackenEnabled 是一个布尔值,当垃圾收集处于标记阶段时,该变量会被置为 1,在这里辅助垃圾收集的用户程序和后台标记的任务可以将对象涂黑;
runtime.gcController 实现了垃圾收集的调步算法,它能够决定触发并行垃圾收集的时间和待处理的工作;
runtime.gcpercent 是触发垃圾收集的内存增长百分比,默认情况下为 100,即堆内存相比上次垃圾收集增长 100% 时应该触发 GC,并行的垃圾收集器会在到达该目标前完成垃圾收集;
runtime.writeBarrier 是一个包含写屏障状态的结构体,其中的 enabled 字段表示写屏障的开启与关闭;
runtime.worldsema 是全局的信号量,获取该信号量的线程有权利暂停当前应用程序;
除了上述全局的变量之外,我们在这里还需要简单了解一下 runtime.work 变量:
gcTriggerHeap — 堆内存的分配达到控制器计算的触发堆大小;
gcTriggerTime — 如果一定时间内没有触发,就会触发新的循环,该触发条件由 runtime.forcegcperiod 变量控制,默认为 2 分钟;
gcTriggerCycle — 如果当前没有开启垃圾收集,则触发新的循环;
用于开启垃圾收集的方法 runtime.gcStart 会接收一个 runtime.gcTrigger 类型的谓词,所有出现 runtime.gcTrigger 结构体的位置都是触发垃圾收集的代码:
runtime.sysmon 和 runtime.forcegchelper — 后台运行定时检查和垃圾收集;
runtime.GC — 用户程序手动触发垃圾收集;
runtime.mallocgc — 申请内存时根据堆大小触发垃圾收集;
go tool pprof http://127.0.0.1:8081/debug/pprof/heap //查看堆的使用,即内存使用情况
go tool pprof http://127.0.0.1:8081/debug/pprof/profile //查看cpu耗时,会详细列出每个函数的耗时
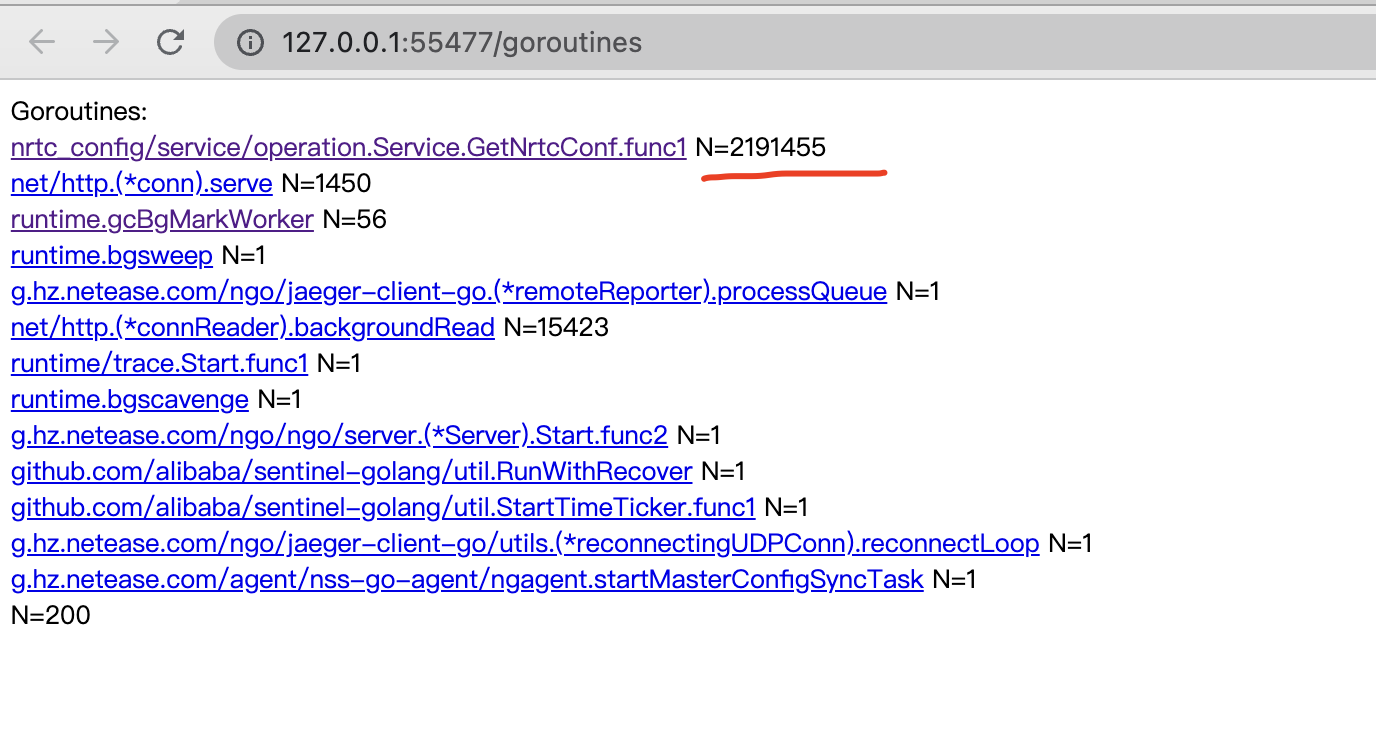
go tool pprof http://127.0.0.1:8081/debug/pprof/goroutine //当前在运行的goroutine情况以及总数
https://gitee.com/mirrors/ants#-%E6%80%A7%E8%83%BD%E5%B0%8F%E7%BB%93
https://segmentfault.com/a/1190000040117561
https://www.tbray.org/ongoing/When/202x/2022/06/10/Quamina-Optimizing
https://eli.thegreenplace.net/2022/performance-of-coroutine-style-lexers-in-go/
指标采集
在main.go中添加:
1 | // 需要导入 _ "net/http/pprof"包 |
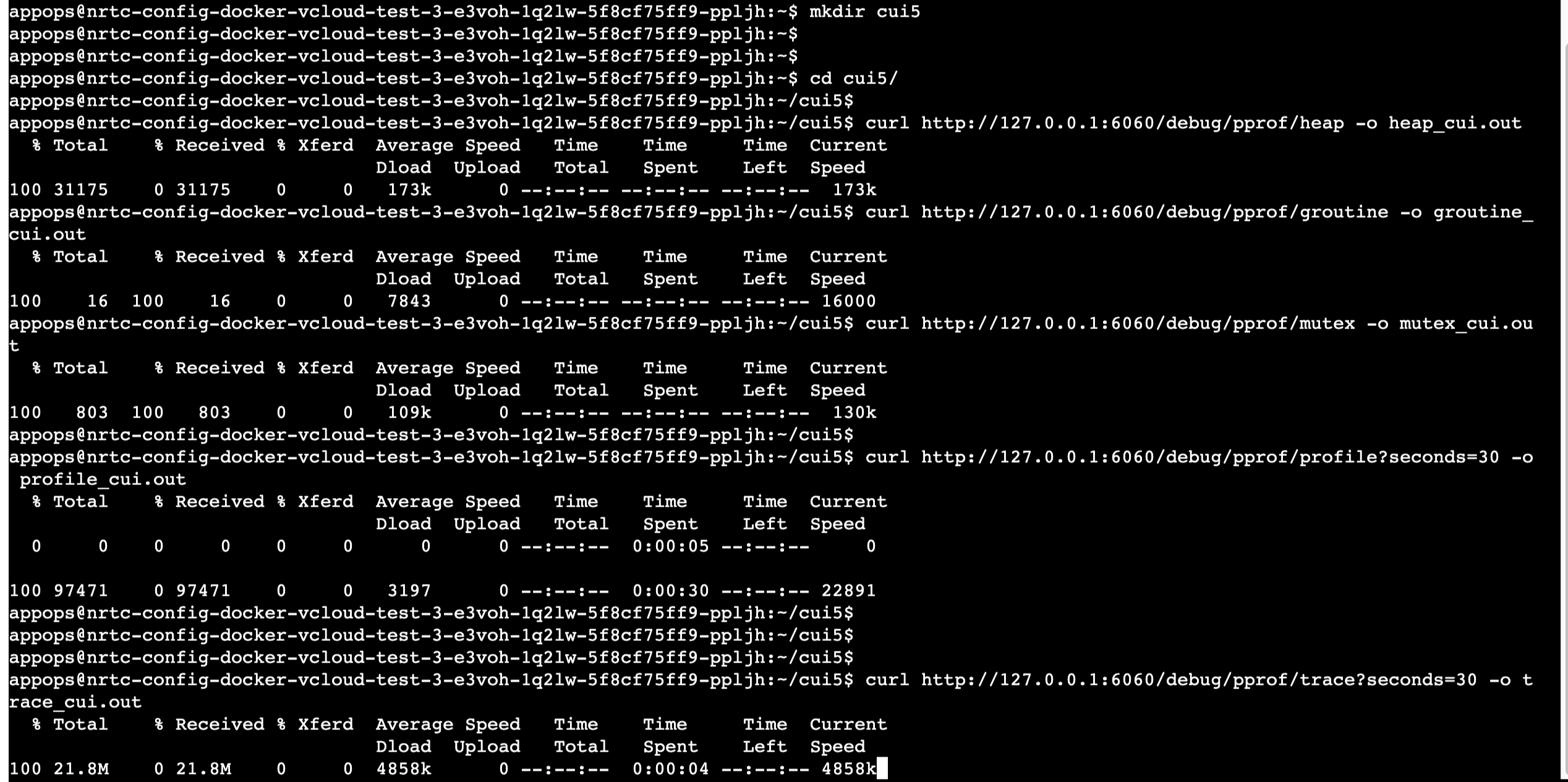
在压测时保存下各种指标信息:
1 | curl http://127.0.0.1:6060/debug/pprof/heap -o heap_cui.out && curl http://127.0.0.1:6060/debug/pprof/goroutine -o goroutine_cui.out && curl http://127.0.0.1:6060/debug/pprof/mutex -o mutex_cui.out && curl http://127.0.0.1:6060/debug/pprof/profile?seconds=30 -o profile_cui.out && curl http://127.0.0.1:6060/debug/pprof/block -o block_cui.out |
一般很少用到trace,且trace文件体积会比较大,上百M(另外几个指标的文件大小都是几百k到几M级); 可以通过curl http://127.0.0.1:6060/debug/pprof/trace?seconds=30 -o trace_cui.out来采集
指标分析
以分析内存分配为例:
go tool pprof heap_cui.out ,而后在交互式的命令行中输入web,可以查看内存分配信息
但这种方式无法查看更详细的内容,更建议通过指定在浏览器中打开这种方式查看: go tool pprof --http :9091 heap_cui.out
可以有各种选择
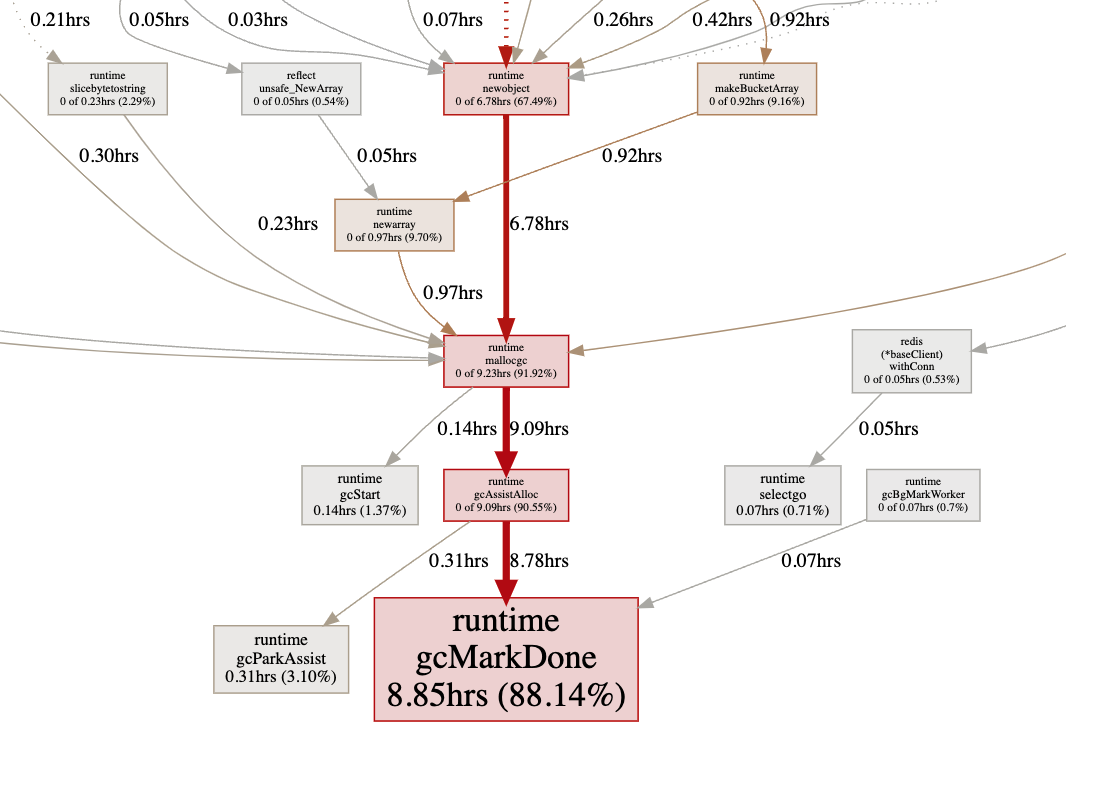
其中Flame Graph即火焰图形式展现, 在最下方一行,占据越多宽度的,就是内存分配最多的点;
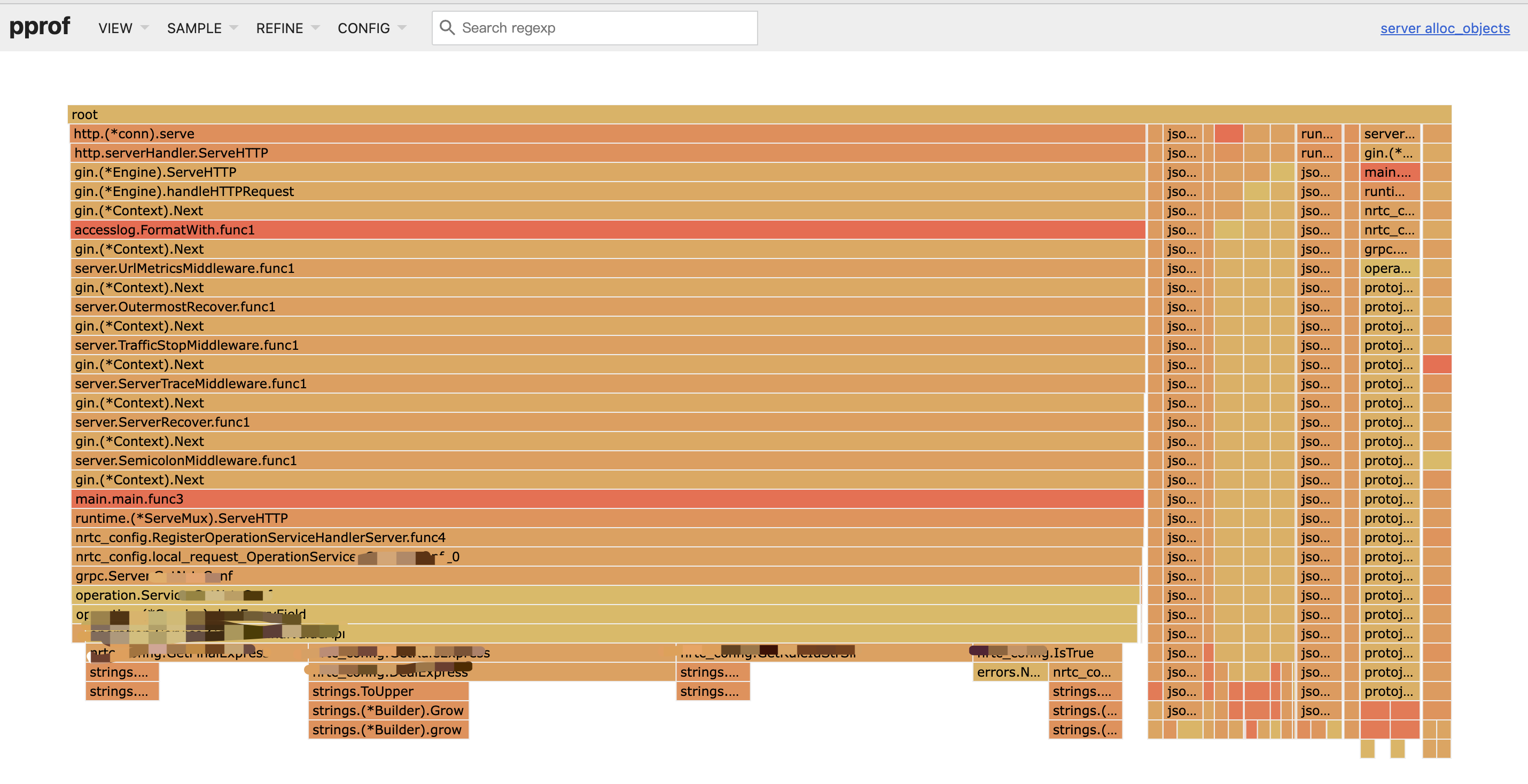
下一步就可以根据这些信息进行定位,进而优化
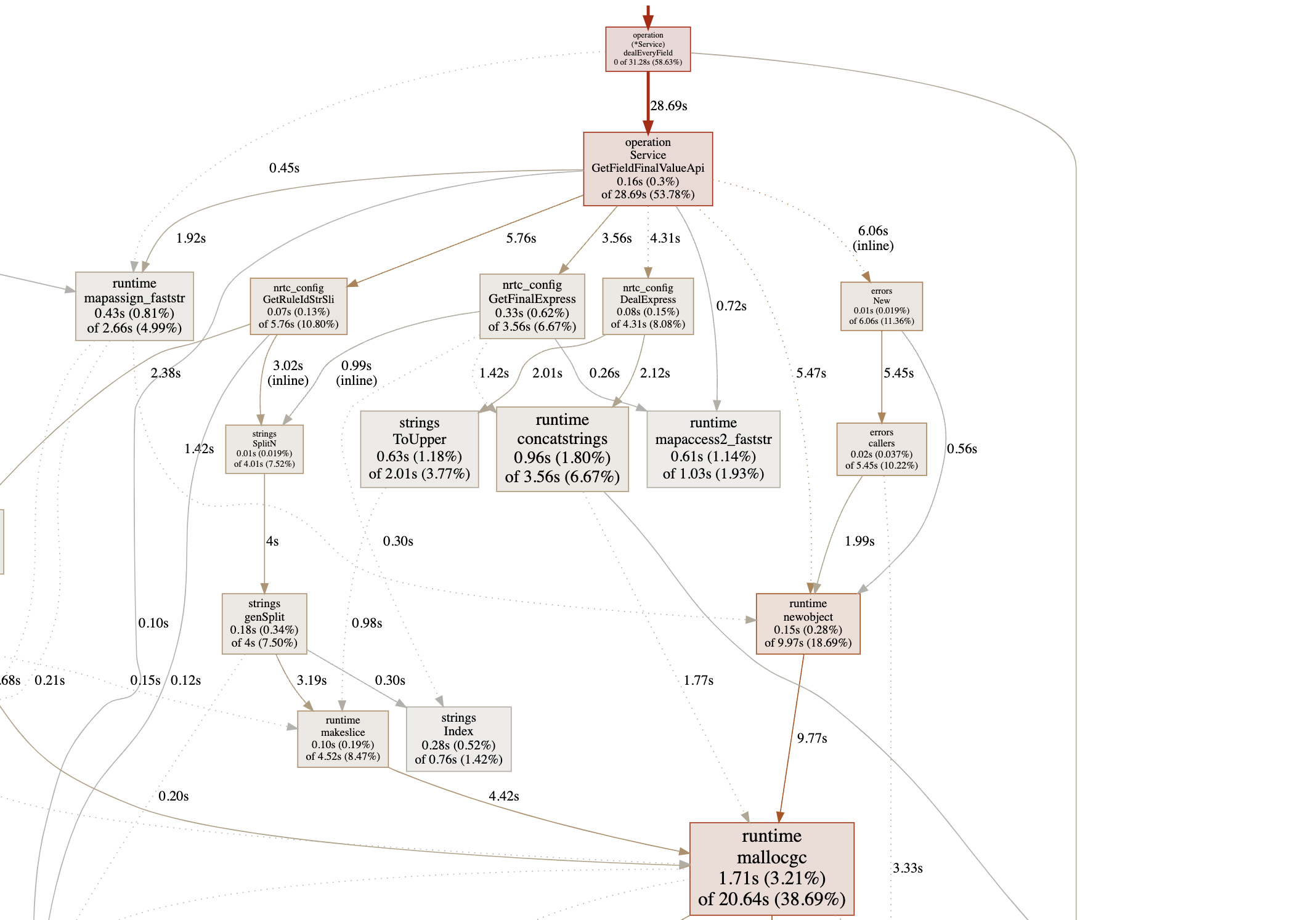
看起来“人畜无害”的Go官方库提供的一些字符串操作方法,如 strings.ToUpper,strings.ToLower,strings.SplitN, errors.New 为什么会成为性能瓶颈?
分析一下不难发现,这几个方法都有内存分配
1 |
Go memory ballast: How I learnt to stop worrying and love the heap
https://blog.csdn.net/wohu1104/article/details/113795455
原文链接: https://dashen.tech/2022/06/30/一次性能优化实战/
版权声明: 转载请注明出处.