Rust训练营:表格文件实战
有一个csv文件,找出某列包含特定关键字的行
此处特定关键字为Leader
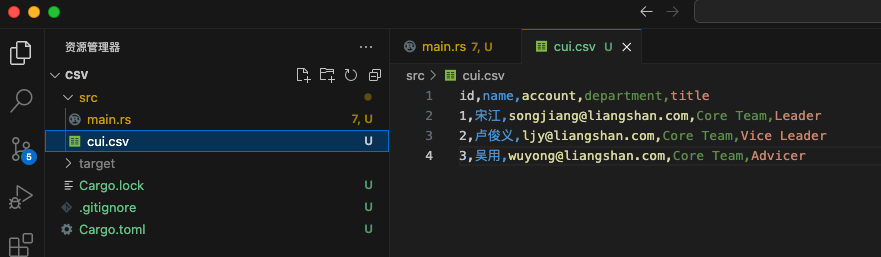
csv文件如下:
1 2 3 4 id,name,account,department,title 1,宋江,songjiang@liangshan.com,Core Team,Leader 2,卢俊义,ljy@liangshan.com,Core Team,Vice Leader 3,吴用,wuyong@liangshan.com,Core Team,Advicer
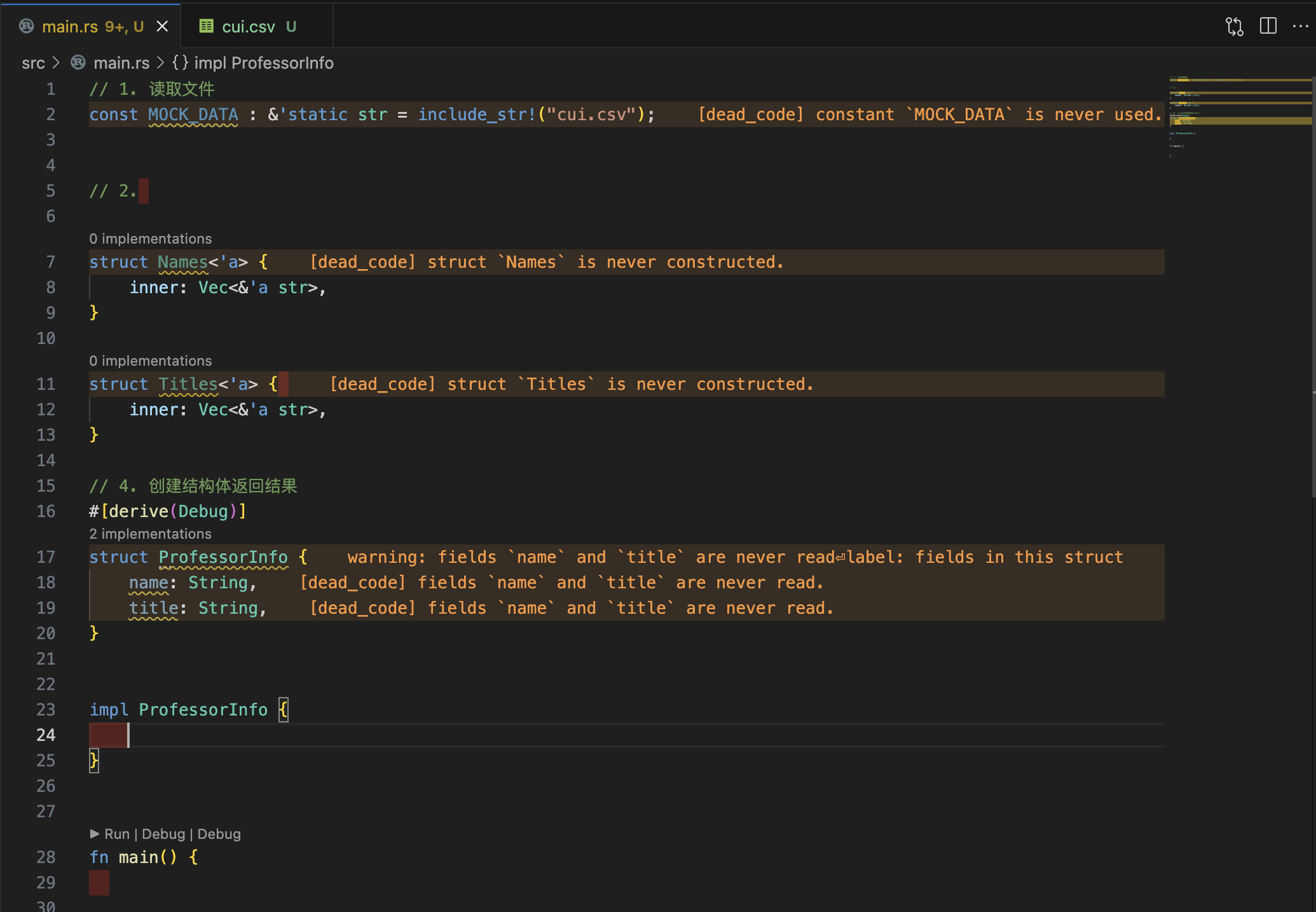
代码如下:
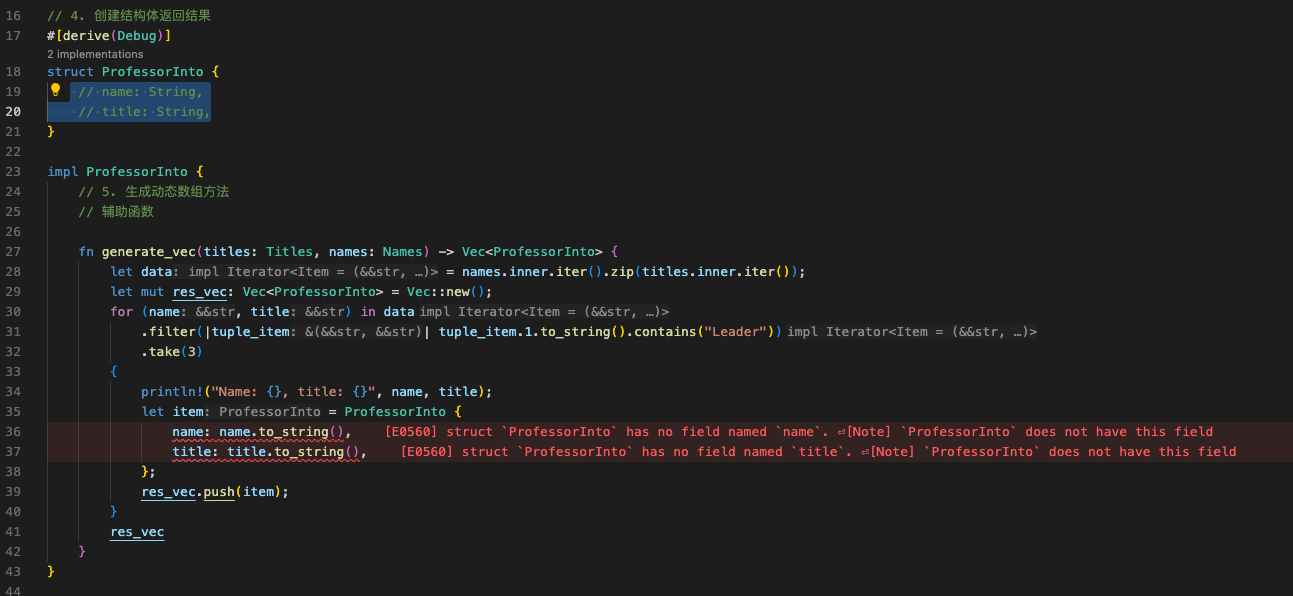
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 const MOCK_DATA: &'static str = include_str! ("cui.csv" );struct Names <'a > { inner: Vec <&'a str >, } struct Titles <'a > { inner: Vec <&'a str >, } #[derive(Debug)] struct ProfessorInto { name: String , title: String , } impl ProfessorInto { fn generate_vec (titles: Titles, names: Names) -> Vec <ProfessorInto> { let data = names.inner.iter ().zip (titles.inner.iter ()); let mut res_vec : Vec <ProfessorInto> = Vec ::new (); for (name, title) in data .filter (|tuple_item| tuple_item.1 .to_string ().contains ("Leader" )) .take (3 ) { println! ("Name: {}, title: {}" , name, title); let item = ProfessorInto { name: name.to_string (), title: title.to_string (), }; res_vec.push (item); } res_vec } } fn main () { let data : Vec <_> = MOCK_DATA.split ('\n ' ).skip (1 ).collect (); let names : Vec <_> = data .iter () .filter_map (|line| line.split (',' ).nth (1 )) .collect (); let names = Names { inner: names }; let titles : Vec <_> = data .iter () .filter_map (|line| line.split (',' ).nth (4 )) .collect (); let titles = Titles { inner: titles }; let back = ProfessorInto::generate_vec (titles, names); println! ("{:?}" , back); print! ("{}" , back.len ()); }
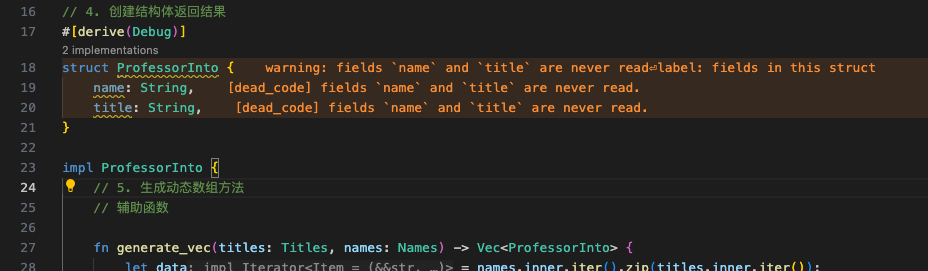
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 warning: fields `name` and `title` are never read --> src/main.rs:18:5 | 17 | struct ProfessorInto { | ------------- fields in this struct 18 | name: String, | ^^^^ 19 | title: String, | ^^^^^ | = note: `ProfessorInto` has a derived impl for the trait `Debug`, but this is intentionally ignored during dead code analysis = note: `#[warn(dead_code)]` on by default warning: `csv` (bin "csv") generated 1 warning Finished dev [unoptimized + debuginfo] target(s) in 0.00s Running `target/debug/csv` Name: 宋江, title: Leader Name: 卢俊义, title: Vice Leader [ProfessorInto { name: "宋江", title: "Leader" }, ProfessorInto { name: "卢俊义", title: "V
这个提示真的是…
说是这两个字段从来没被read。
注释掉,又会说没有这个字段。。
2024.07.02 记录:
Rust文件模块API入门
今天要介绍的是Rust的文件模块。这个模块包含了一些操作本地文件系统的基本方法。这个模块的所有方法都是跨平台的,意味着你可以在Windows、Mac、Linux等多个操作系统上使用该模块。
让我们直接进入正题:
如何创建文件夹
我们可以使用DirBuilder创建文件夹,代码如下:
1 2 3 4 5 6 use std::fs::DirBuilder;DirBuilder::new () .recursive (true ) .create ("path/to/directory" ) .unwrap ();
DirBuilder是文件模块提供的一个结构体。使用new函数创建一个DirBuilder结构体实例,调用实例的recursive方法并传入true,表示文件夹将采用递归的方式创建。如果父文件夹不存在,则会一并创建。最后调用create方法完成文件夹创建。
这里需要重点注意recursive方法的使用。recursive默认为false。如果recursive为false,当父文件夹不存在时,文件夹创建失败;且当要创建的文件夹已经存在时,文件夹创建也会失败。所以我们使用DirBuilder时,通常会将recursive设置为true。
除了使用DirBuilder结构体,你也可以使用模块提供的create_dir和create_dir_all方法。这两个方法封装了DirBuilder,所以本质上也是使用DirBuilder,但更为简洁。请看代码:
1 2 3 4 use std::fs;fs::create_dir ("path/to/directory" ).unwrap (); fs::create_dir_all ("path/to/directory" ).unwrap ();
类似的,当父文件夹不存在时,create_dir会报错,而create_dir_all则会把父文件夹一并创建。
如何读取一个文件夹里的文件列表
文件模块提供了read_dir函数。该函数接收一个文件夹路径,返回一个结构体,也就是ReadDir。它实现了迭代器,因此我们可以用for循环遍历该文件夹里的子文件和子文件夹。迭代器的元素类型为DirEntry,表示一个文件或文件夹。
1 2 3 4 5 6 use std::fs;for entry in fs::read_dir ("path/to/directory" ).unwrap () { let entry = entry.unwrap (); println! ("{:?}" , entry.path ()); }
读取文件或文件夹的元数据
文件模块提供了metadata函数,用于读取指定文件或文件夹的元数据。如代码所示:
1 2 3 4 5 6 7 8 9 use std::fs;let metadata = fs::metadata ("path/to/file" ).unwrap ();println! ("Is directory: {}" , metadata.is_dir ());println! ("File size: {} bytes" , metadata.len ());println! ("Permissions: {:?}" , metadata.permissions ());println! ("Created: {:?}" , metadata.created ());println! ("Modified: {:?}" , metadata.modified ());println! ("Accessed: {:?}" , metadata.accessed ());
读取文件的元数据包括但不限于:判断一个文件是文件还是文件夹、文件大小、文件权限信息、创建时间、修改时间和最近一次访问时间等。
如何创建文件
创建文件有多种方式,OpenOptions结构体可以提供更精细的控制。其他方式也是对OpenOptions方式的封装。OpenOptions一共有六种Option,分别是read、write、append、truncate、create、create_new。使用new函数创建OpenOptions实例时,所有的option都被初始化为false。
1 2 3 4 5 6 7 8 use std::fs::OpenOptions;let file = OpenOptions::new () .read (true ) .write (true ) .create (true ) .open ("path/to/file" ) .unwrap ();
代码通过OpenOptions的new函数创建一个实例,并将read、write、create都设置true。read和write分别表示如果文件被打开,则可以读取或写入。create表示如果文件不存在,则创建。
接下来介绍一种更简洁的方式。正如之前说过,其他方式是对OpenOptions的封装。调用File结构体的create函数,如代码所示:
1 2 3 use std::fs::File;let file = File::create ("path/to/file" ).unwrap ();
这种方式虽然更简洁,但我们仍然需要关注其内部是如何调用OpenOptions的。create函数创建OpenOptions时打开了write、create、truncate三个选项。前两个很容易理解,毕竟我们想要创建并写入文件。但是truncate选项要注意了,如果文件已经存在,则文件会被重新创建,文件里面的内容会全部丢失。所以create函数虽然简洁,但请确保他的行为是符合你的预期的,尤其是已存在文件或truncate的行为。
如何读取文件
读取文件时,首先我们需要先打开文件。在文件已经存在的情况下,使用File结构体的open函数以只读的方式打开指定文件。为什么是只读呢?因为该方式下的OpenOptions实例中仅read属性被设置为true。
1 2 3 4 5 6 7 use std::fs::File;use std::io::Read;let mut file = File::open ("path/to/file" ).unwrap ();let mut contents = String ::new ();file.read_to_string (&mut contents).unwrap (); println! ("File contents: {}" , contents);
打开成功后返回一个File结构体。File结构体实现了Read trait。Read trait是Rust标准库中的一个trait,它提供了从输入流中读取数据的方法。这个trait被广泛应用于文件、网络连接和其他IO操作中。
这个trait提供了多种读取方法,适应不同的读取需求。常用的读取方法如下:
read:尝试读取一些字节到缓冲区buf中,返回成功读取的字节数。
read_to_end:读取所有字节,直到EOF,并将其追加到缓冲区buf中。
read_exact:完全填充缓冲区buf,读取的字节数必须等于缓冲区的长度。
read_to_string:读取所有字节,直到EOF,并将其追加到字符串buf中。
如代码所示,我们这里使用read_to_string读取文本文件。如果你正在读取图片等其他非文本格式文件,你可以使用其他方法,如read_to_end等,将数据读取到一个u8向量中,然后做后续操作。
如何使用缓冲区提升读取性能
直接使用Read trait进行IO操作时,有以下几个缺点:
每次读取操作都会触发一次系统调用。系统调用是昂贵的,因为它涉及用户模式和内核模式之间的切换,以及可能的上下文切换。
如果每次读取的数据量很小(如逐字节读取),每个系统调用只能读取很少的数据。这种情况下,大部分时间会花费在系统调用上,而不是实际的数据传输。
频繁的系统调用会消耗更多的CPU资源和系统资源,导致整体性能下降。
BufReader通过引入内部缓冲区,优化了IO操作,克服了直接使用Read trait的缺点。BufReader提供了一个缓冲区,用于暂时存储从底层读取器(如文件、网络连接等)中读取的数据。这使得读取操作更加高效,并减少了系统调用的次数。
BufReader会一次性从底层读取器读取大块数据到内部缓冲区中,这通常只需要一次系统调用。随后对数据的读取操作都是在用户空间的缓冲区中进行,直到缓冲区耗尽为止。
例如,假设缓冲区大小为8KB,每次系统调用读取8KB数据,然后在用户空间处理这8KB数据。这与每次读取一字节进行一次系统调用相比,系统调用次数大大减少。
通过批量读取数据到缓冲区中,可以充分利用底层读取器的吞吐量,并减少每次读取的数据量对性能的影响。内部缓冲区的读取操作是快速的,用户空间操作不涉及系统调用,从而减少了延迟。只有在缓冲区耗尽时,才会进行新的系统调用来填充缓冲区,整体延迟显著降低。
示例代码比较:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 use std::fs::File;use std::io::Read;let mut file = File::open ("path/to/file" ).unwrap ();let mut buffer = [0 ; 1 ];while file.read_exact (&mut buffer).is_ok () { println! ("{}" , buffer[0 ] as char ); } use std::fs::File;use std::io::{BufReader, Read};let file = File::open ("path/to/file" ).unwrap ();let mut reader = BufReader::new (file);let mut buffer = String ::new ();reader.read_to_string (&mut buffer).unwrap (); println! ("{}" , buffer);
在第一个例子中,每次读取一个字节都会触发一次系统调用,系统调用次数与文件字节数成正比,效率低下。在第二个例子中,BufReader会一次性读取大块数据到内部缓冲区,随后对数据的读取操作都在缓冲区中进行,大大减少了系统调用的次数,提高了效率。
文件模块还提供了其他操作,比如删除文件、重命名文件等。另外,标准库的Path模块和文件模块紧密结合,提供了强大的文件系统操作功能。Path模块处理路径的创建和操作,而文件模块则负责文件和目录的具体操作。通过结合使用这两个模块,可以方便地进行各种文件系统操作。具体可查看标准库文档,文档里解释说明和示例都很详细。
原文链接: https://dashen.tech/2023/11/01/Rust操作文件/
版权声明: 转载请注明出处.