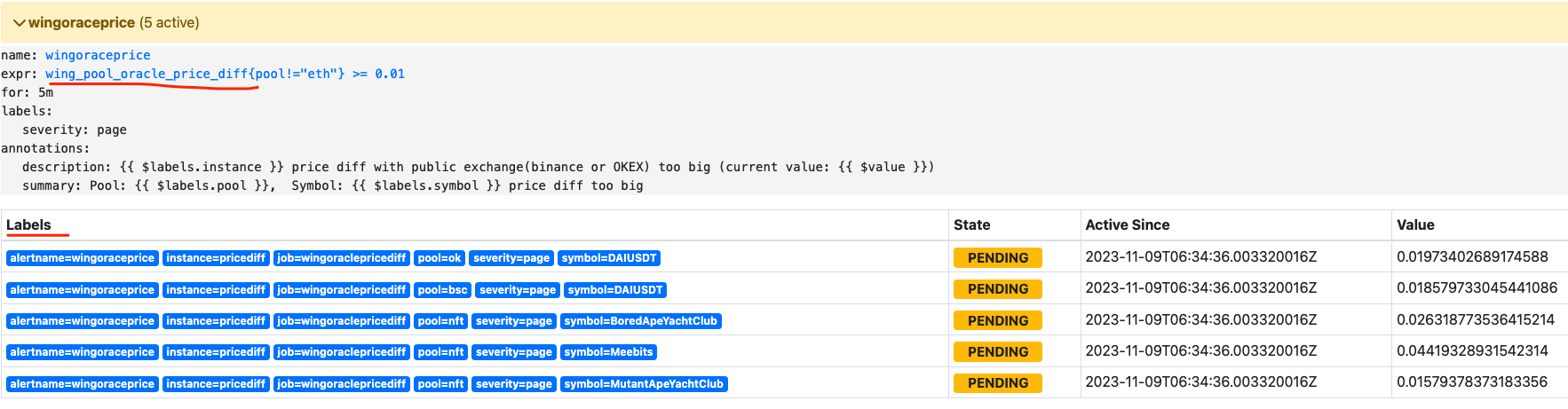
之前是 max( wing_pool_oracle_price_diff{pool!=”eth”}) >= 0.01
在summary和description中使用 $labels.pool,$labels.symbol时是空,这是因为,用了max, 这里全是空

去掉max就可以了~
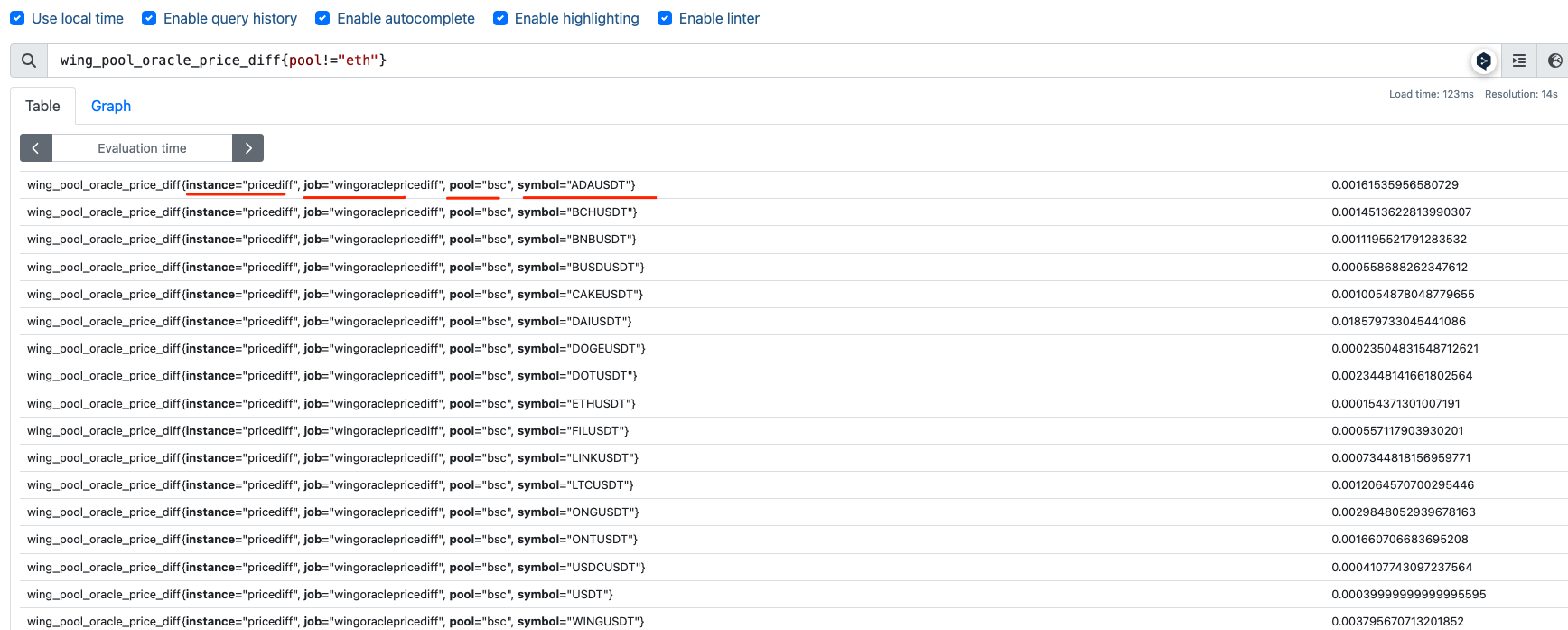
符合预期
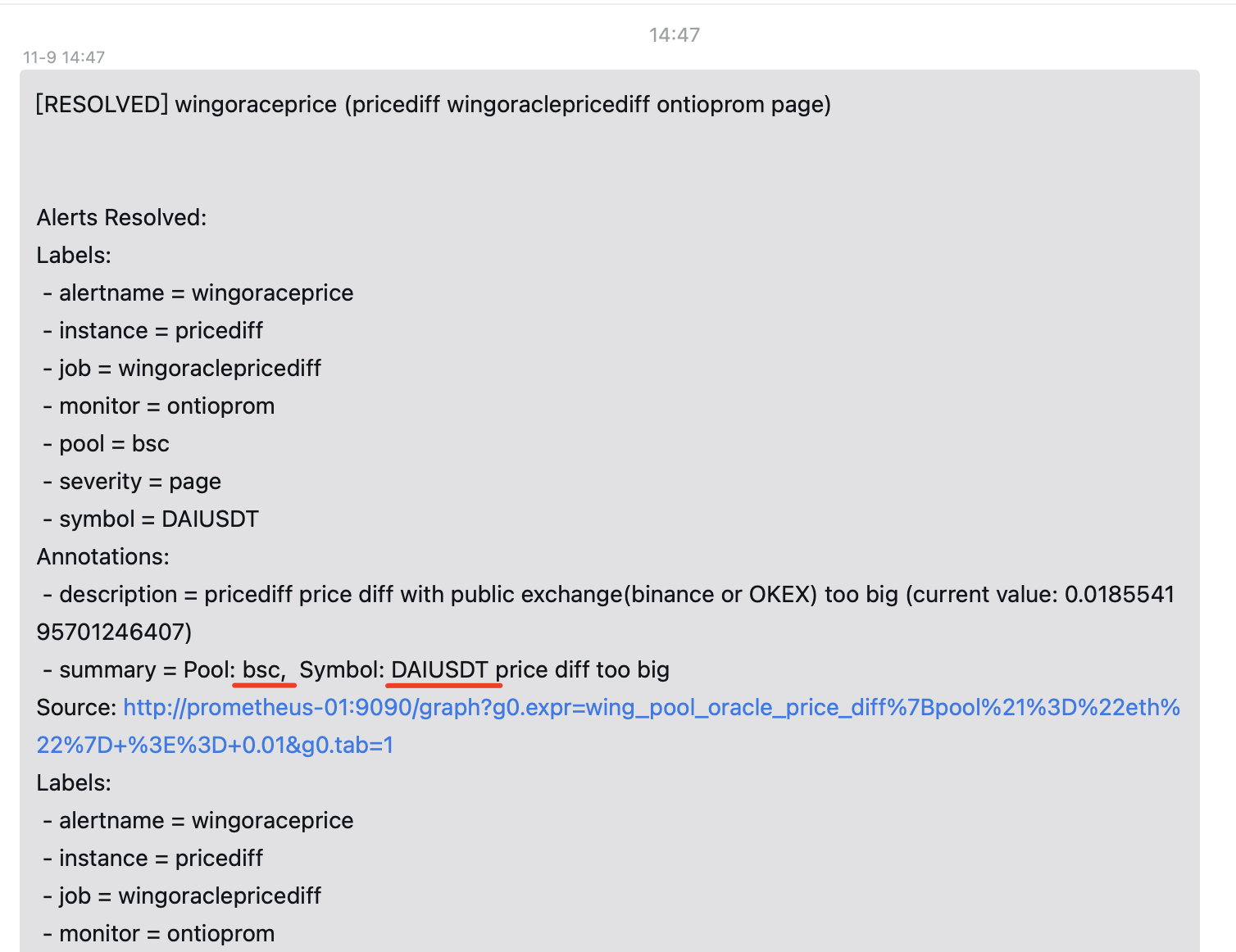
换言之,想要在summary和description中使用,上面的Labels中一定要有
https://zhuanlan.zhihu.com/p/434360311
Prometheus - SSL 证书过期监控
https://blog.rabcnops.cn/posts/articles/2f967c8.html
20240913
打不出具体哪个域名来,让我解决一下~
只能看出value,看不出具体哪个域名
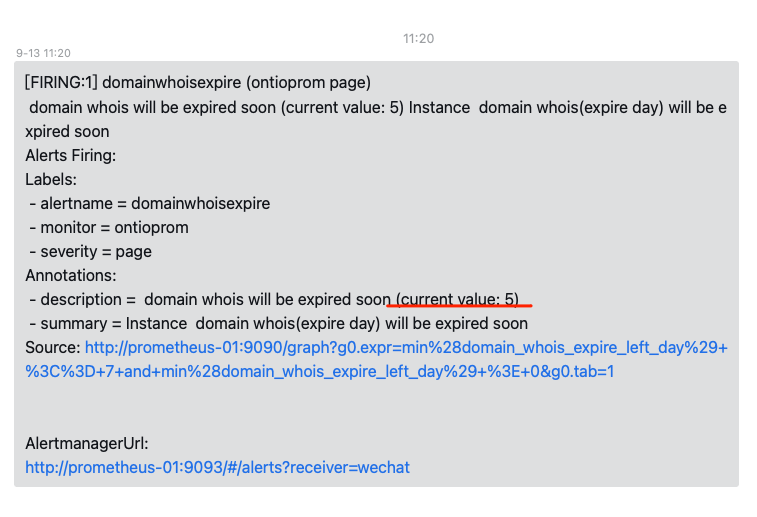
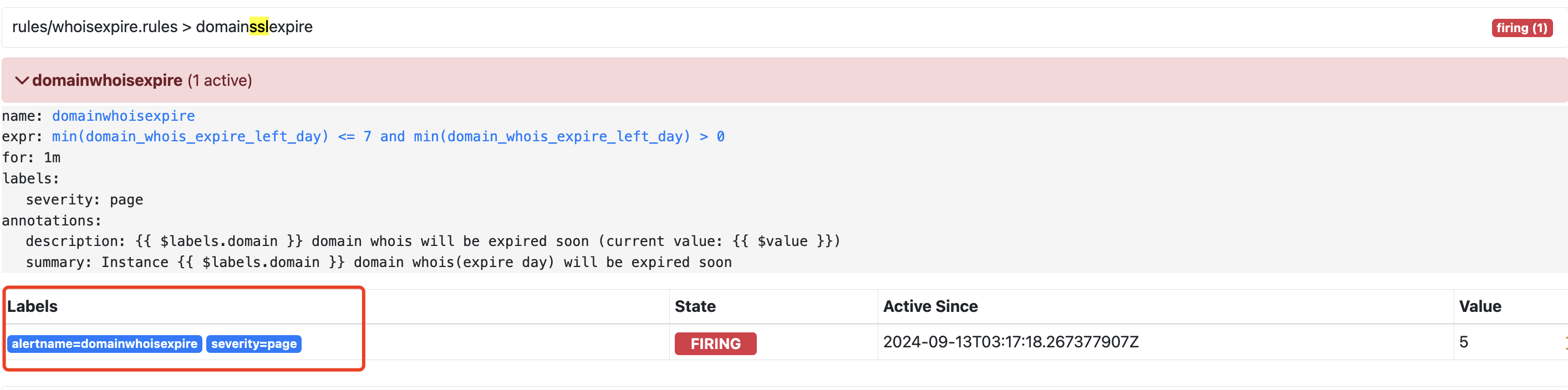
正常需要label这里有更详细的内容才对~
例如其他告警的:
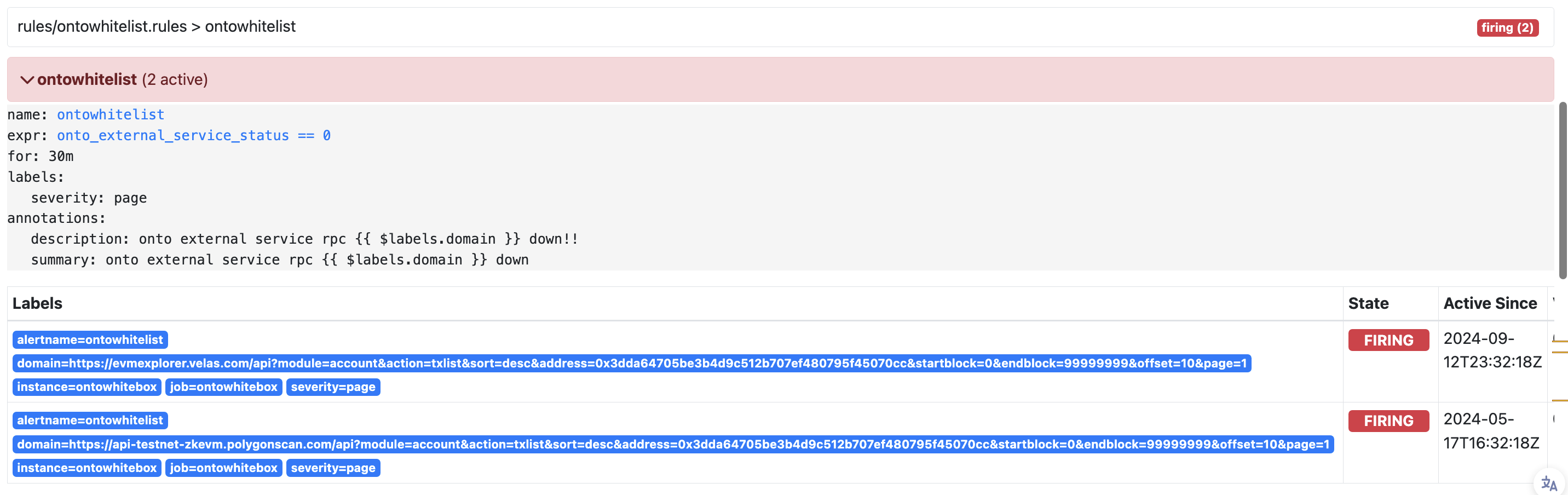
这是因为用了min….
其实完全没必要用min

将/data/prom/rules里的对应规则,
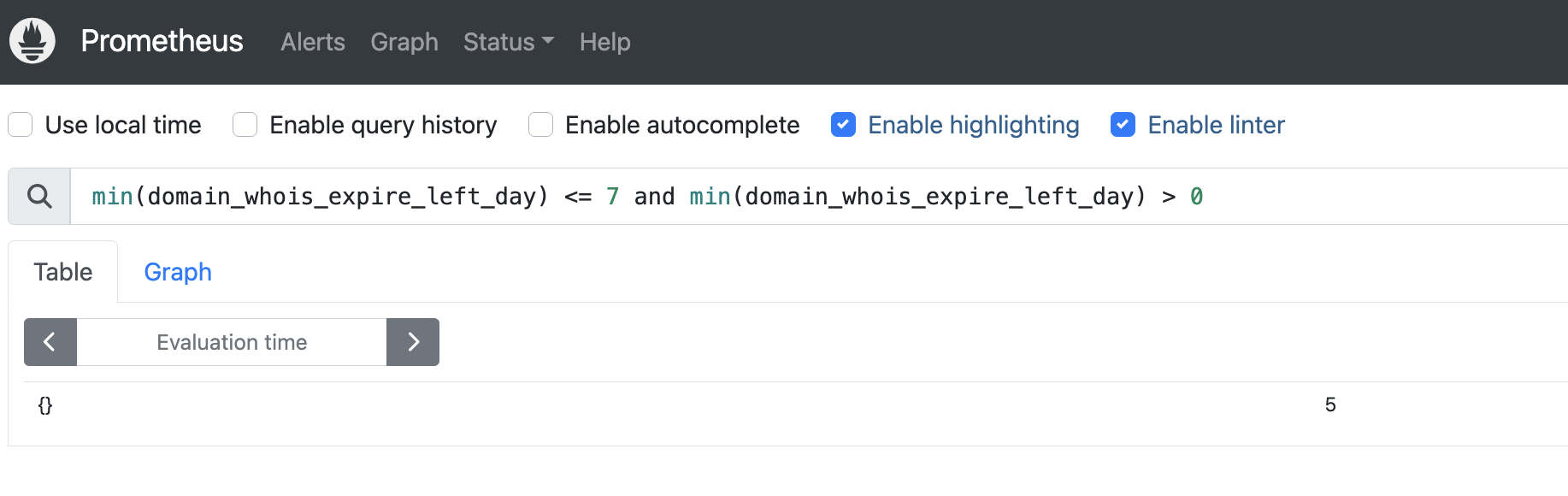
从 min(domain_whois_expire_left_day) <= 7 and min(domain_whois_expire_left_day) > 0
改成即可
domain_whois_expire_left_day <= 7 and domain_whois_expire_left_day > 0
然后重启prom
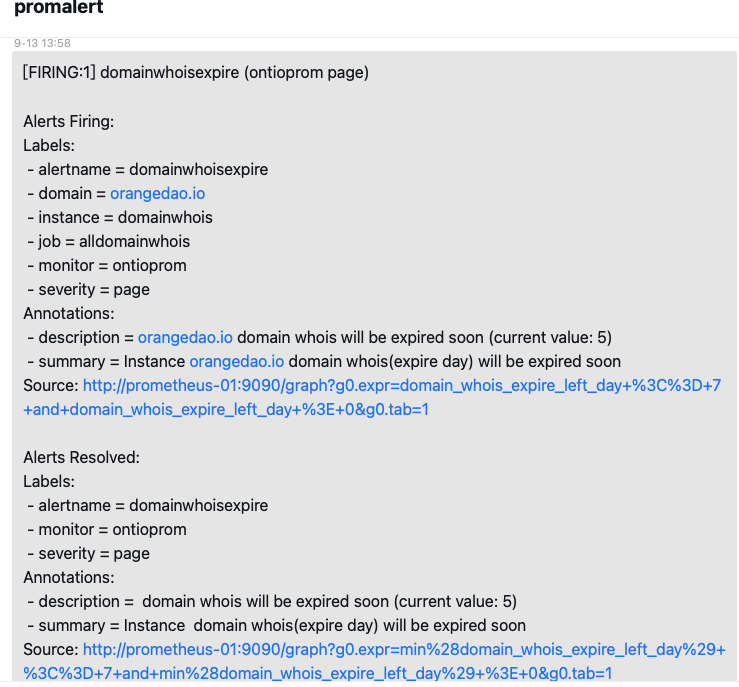
之后:
20241028 自我驱动!
我有一个k8s集群,如何用kube-state-metrics监控其各种指标?
https://github.com/kubernetes/kube-state-metrics
https://docker.aityp.com/image/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
使用 kube-state-metrics 监控 Kubernetes 集群的各种指标是一个常见的做法。以下是设置 kube-state-metrics 的步骤:
1. 安装 kube-state-metrics
你可以通过 Helm 或直接使用 Kubernetes 清单文件来安装 kube-state-metrics。
使用 Helm 安装
如果你已经安装了 Helm,可以运行以下命令:
1 | helm repo add kube-state-metrics https://kubernetes.github.io/kube-state-metrics |
直接使用 Kubernetes 清单文件
你也可以直接使用 kube-state-metrics 的 Kubernetes 清单文件进行安装:
1 | kubectl apply -f https://raw.githubusercontent.com/kubernetes/kube-state-metrics/master/examples/standard/deployment.yaml |
2. 配置 ServiceMonitor(可选)
如果你使用 Prometheus Operator,可以创建 ServiceMonitor 来自动发现 kube-state-metrics 服务。
1 | apiVersion: monitoring.coreos.com/v1 |
3. 查看指标
kube-state-metrics 会暴露 Kubernetes 对象的状态指标。你可以通过以下命令查看可用的指标:
1 | kubectl port-forward svc/kube-state-metrics 8080:8080 |
然后在浏览器中访问 http://localhost:8080/metrics,你将看到所有暴露的指标。
4. 配置 Prometheus
如果你还没有 Prometheus,可以使用 Helm 安装:
1 | helm install prometheus prometheus-community/prometheus |
配置 Prometheus 以抓取 kube-state-metrics 的指标。在 prometheus.yml 中添加以下配置:
1 | scrape_configs: |
5. 查看监控数据
安装 Grafana(如果尚未安装),并通过 Prometheus 数据源配置 Grafana。然后你可以用 Grafana 创建仪表盘,使用 kube-state-metrics 提供的指标进行可视化。
6. 常见监控指标
以下是一些常见的 kube-state-metrics 指标,你可能会想监控:
kube_pod_info:有关 Pod 的信息。kube_deployment_status_replicas:Deployment 状态下的副本数。kube_node_status_ready:节点是否准备好。kube_namespace_status_phase:命名空间状态。
总结
通过以上步骤,你可以在 Kubernetes 集群中成功安装和配置 kube-state-metrics,并使用 Prometheus 和 Grafana 监控集群的各种指标。这将帮助你更好地了解集群的健康状况和性能。
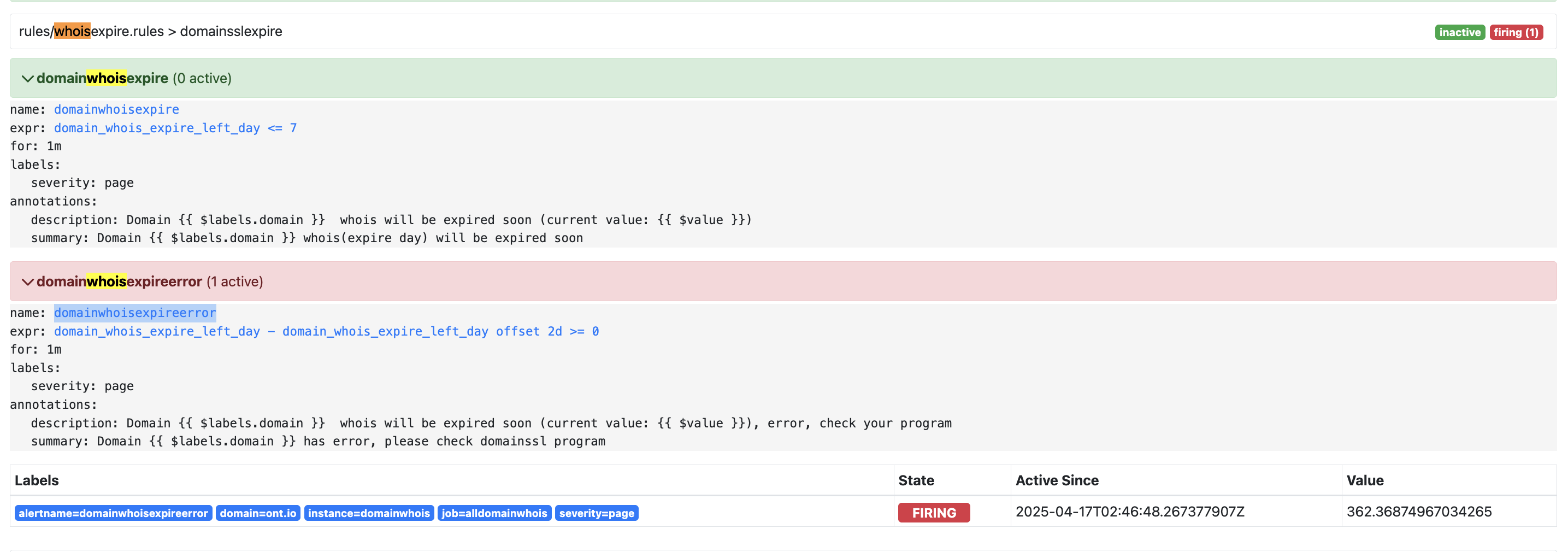
domainwhoisexpireerror
20250417
解决刚续费后,出现364天告警的情况
最初这个告警之所以添加,是怕whoisexpire程序宕了, 几天都没变化, 我们没有感知? ( 正常 domain_whois_expire_left_day 是需要每天降低一天的,要没降低,就是有问题. domainwhoisexpireerror就是解决这个问题的
但引来了新问题,就是刚续费的域名,天数也是有剧烈变动的~
关于
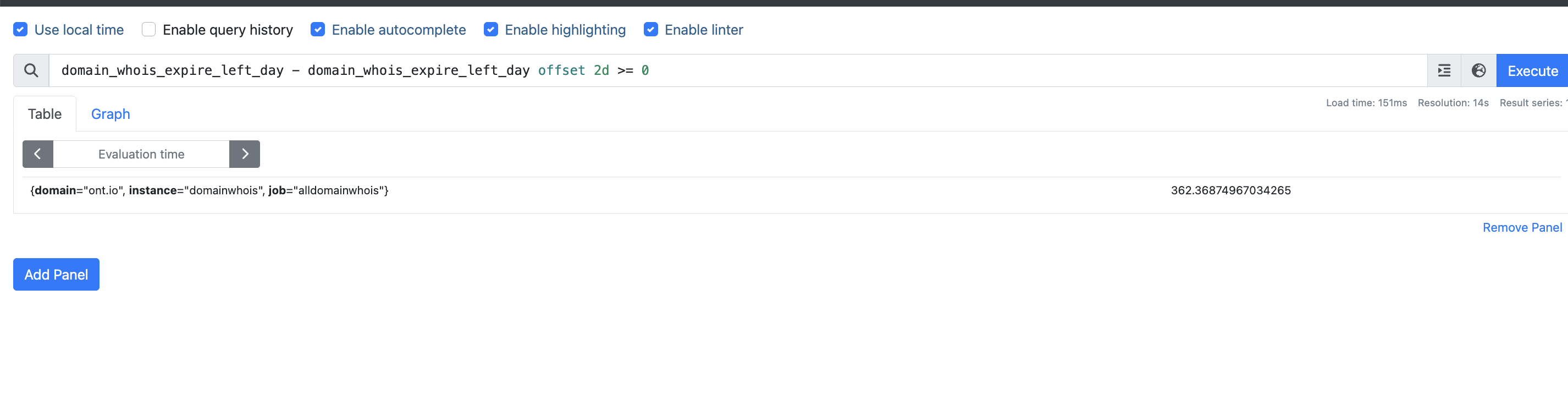
1 | domain_whois_expire_left_day - domain_whois_expire_left_day offset 2d >= 0 |
这条规则是比较域名的 WHOIS 到期剩余天数与 2 天的阈值。让我来解释一下:
domain_whois_expire_left_day是一个变量,表示域名的 WHOIS 记录还有多少天到期domain_whois_expire_left_day offset 2d表示将原始值减去 2 天后的结果>= 0表示这个偏移后的值必须大于或等于零
简单来说,这条 Prometheus 告警规则是检查域名的 WHOIS 注册是否还有超过 2 天才过期。当域名距离过期还有至少 2 天时,这条规则会评估为真,这可能被用来为接近过期日期但仍有最小缓冲期的域名触发告警。
如果你在监控系统中使用这条规则,它的设计目的可能是在域名过期之前给你提前警告,这样你就有时间在域名变得不可用之前续费。
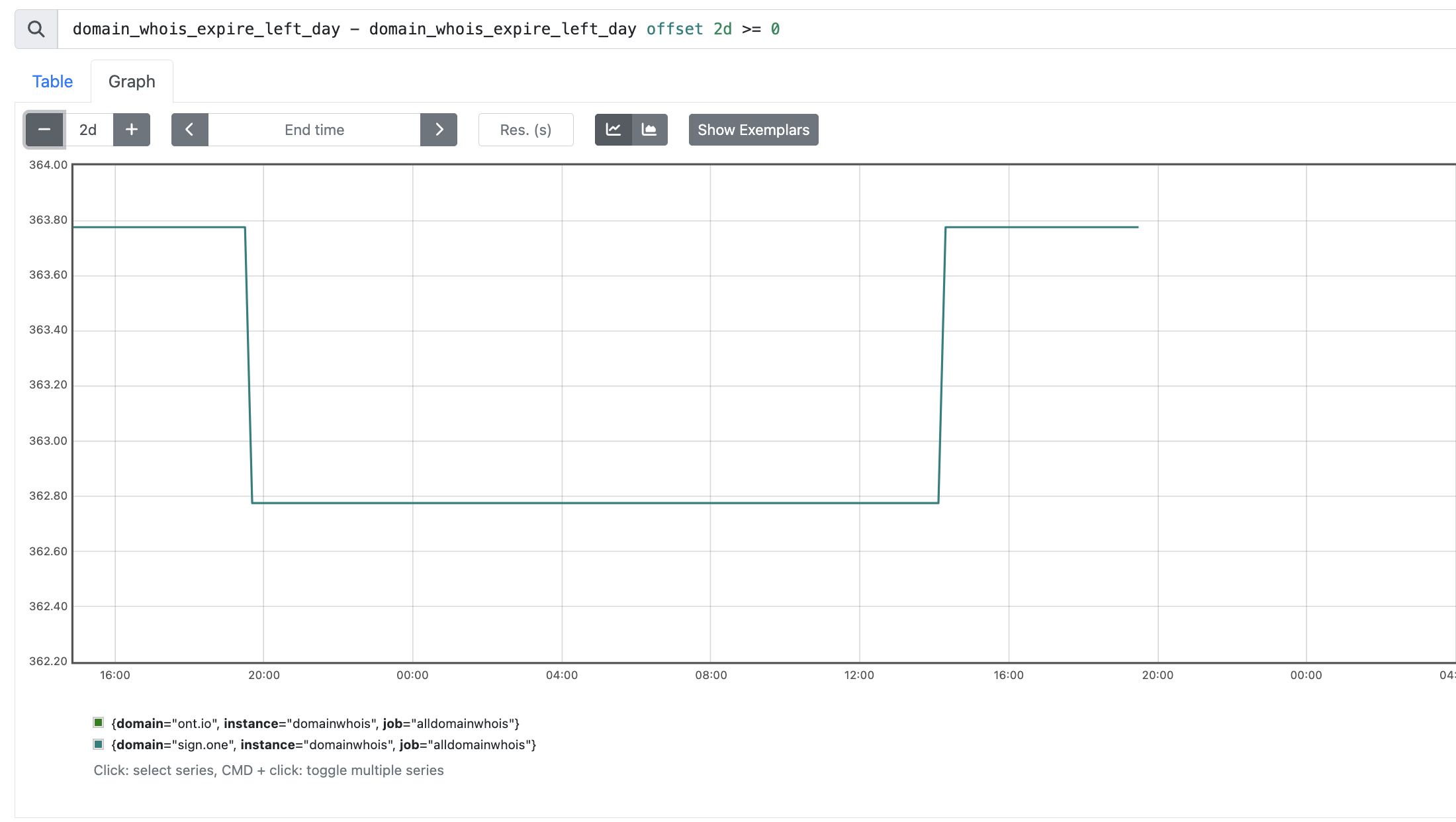
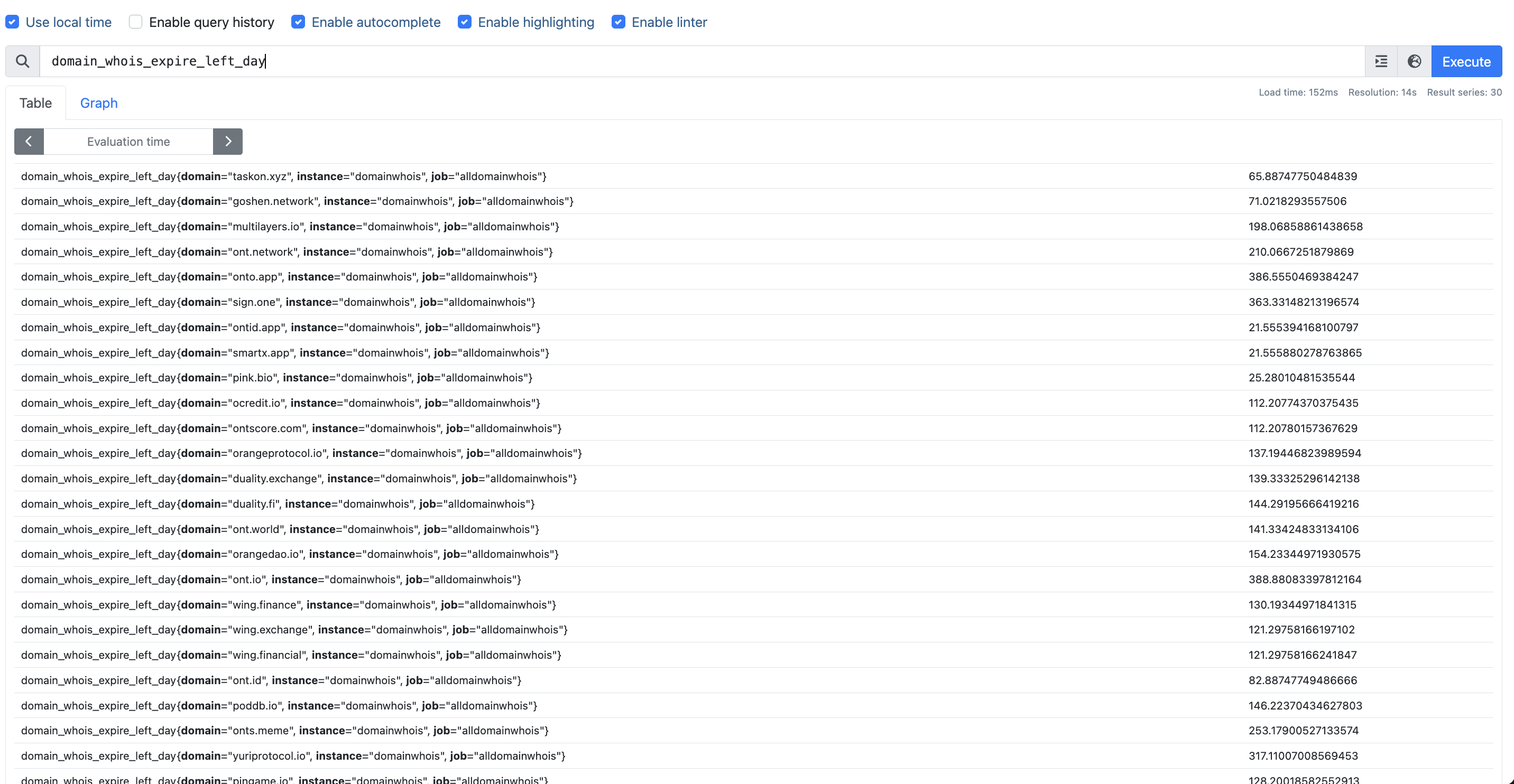
本来如果某个域名, 如taskon.xyz 还有65天到期,那 domain_whois_expire_left_day就是65.88,
domain_whois_expire_left_day offset 2d 是 68.51 (即两天前这个指标的值)
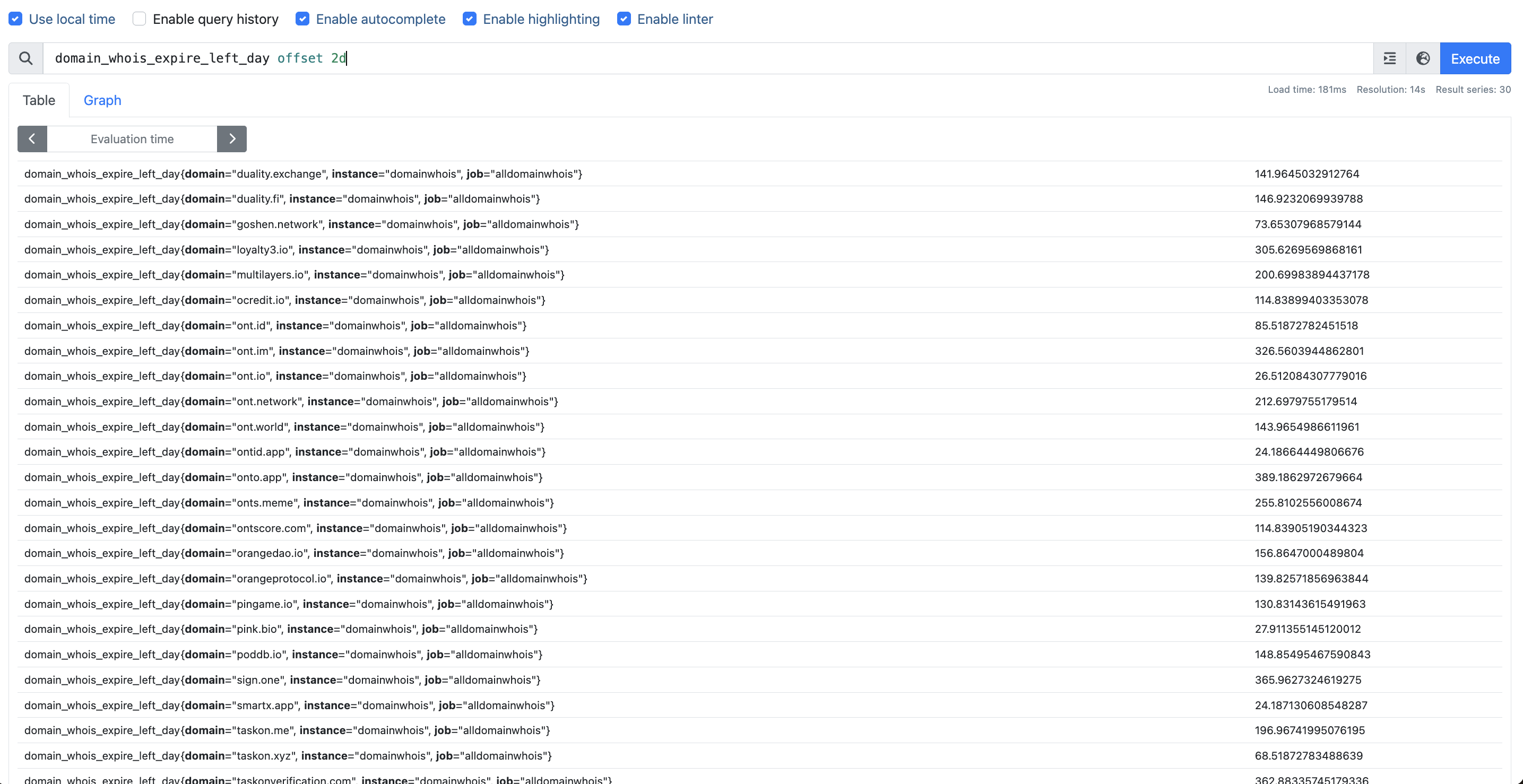
正常如果每天扣减, 那 domain_whois_expire_left_day 永远 > 其两天前的值(因为每天都减少)
如果停了,那就会相等,会告出来
但是如果续费了一年,那domain_whois_expire_left_day 凭空多了365,这样肯定也满足触发告警的条件了…
您分析得很对,这个规则存在一个问题:当域名续费后,当前的剩余天数会远大于两天前的值,这样也会错误地触发告警。
我们需要修改规则,使其在域名续费时不触发告警。一个方法是添加条件,确保当前值比两天前的值小,但差值不超过特定范围。以下是改进后的规则:
1 | (domain_whois_expire_left_day - (domain_whois_expire_left_day offset 2d)) < 0 |
这个规则的含义是:
- 当前剩余天数应小于两天前的值(正常衰减)
- 但减少的天数不应超过2天(基本对应每天减少1天的情况,添加一些容错)
- 两天前的剩余天数至少为0(域名未过期)
如果域名续费,当前值会远大于两天前的值,第一个条件就不满足,因此不会触发告警。
如果您使用的是 PromQL 格式的更复杂规则,可以这样写:
1 | domain_whois_expire_left_day < (domain_whois_expire_left_day offset 2d) |
这样当域名正常计时减少时会满足条件,但续费后值突然增大就不会触发告警了。
感觉太麻烦了,domain_whois_expire_left_day - domain_whois_expire_left_day offset 2d >= 0 同时小于300行不行?
您的想法很好,这个方案简单有效。使用一个上限值来避免续费导致的告警确实更简洁。可以这样写规则:
1 | domain_whois_expire_left_day - domain_whois_expire_left_day offset 2d >= 0 |
或者更简化为:
1 | 0 <= domain_whois_expire_left_day - domain_whois_expire_left_day offset 2d <= 300 |
这个规则的含义是:
- 当前天数与两天前的差值不小于0(允许有一些误差)
- 但差值不超过300(避免续费导致的大幅增加)
这样设计,正常计时减少时不会告警,域名停止更新时会告警(因为差值接近0),而当域名续费后天数突增(比如增加365天)时也不会触发告警,因为超过了300的上限。
这种方法确实比前面的方案简单,而且同样能满足您的需求。

原文链接: https://dashen.tech/2023/11/24/Prometheus常用监控/
版权声明: 转载请注明出处.