杨波–理解K8s的NodePort Service(K8s反向代理)
杨波–理解K8s的ClusterIP Service(K8s内部的反向代理)
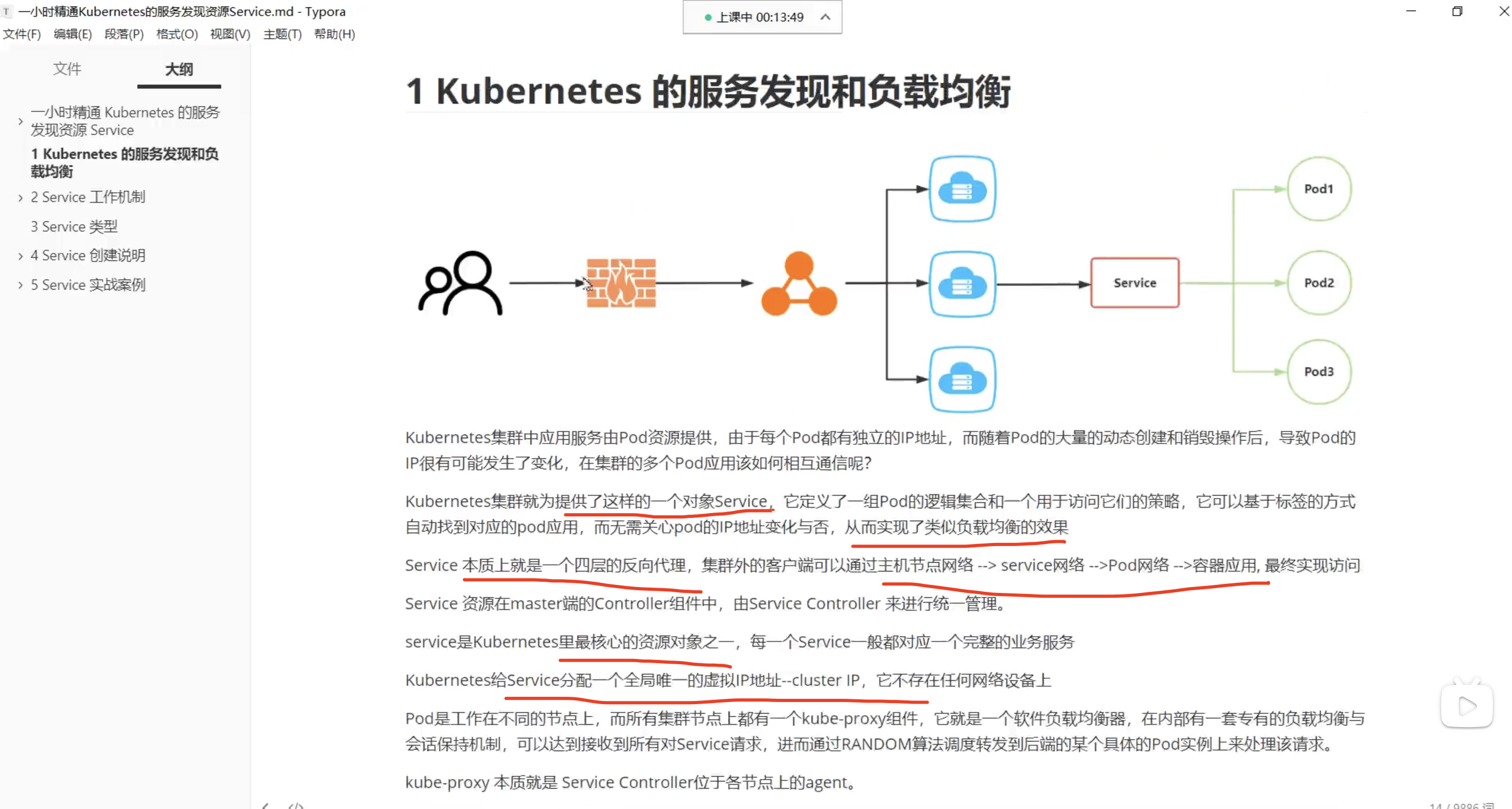
Service是K8s的核心,它是将应用程序暴露到网络中的一种最佳方式,通过为应用程序提供固定的IP地址和端口号,可以使得应用程序能够被其他服务或应用程序访问到。
作为K8s的重要组件,Service在K8s的应用中几乎无法避免,你甚至可以理解为:想从事K8s的相关工作,一定要会Service。
为什么这样说?因为K8s的核心功能之一就是管理容器化应用程序的网络通信,而Service是K8s中实现负载均衡和服务发现的重要组件。只有了解和掌握Service的相关知识,才能更好地进行K8s集群的管理和应用程序的配置,保证集群中各个服务的高可用和稳定性。
然而,Service却是K8s网络架构中一个比较复杂的组件,涉及微服务架构、服务发现、网络配置等,而且类型多种多样,每种类型都有各自的特点和应用场景
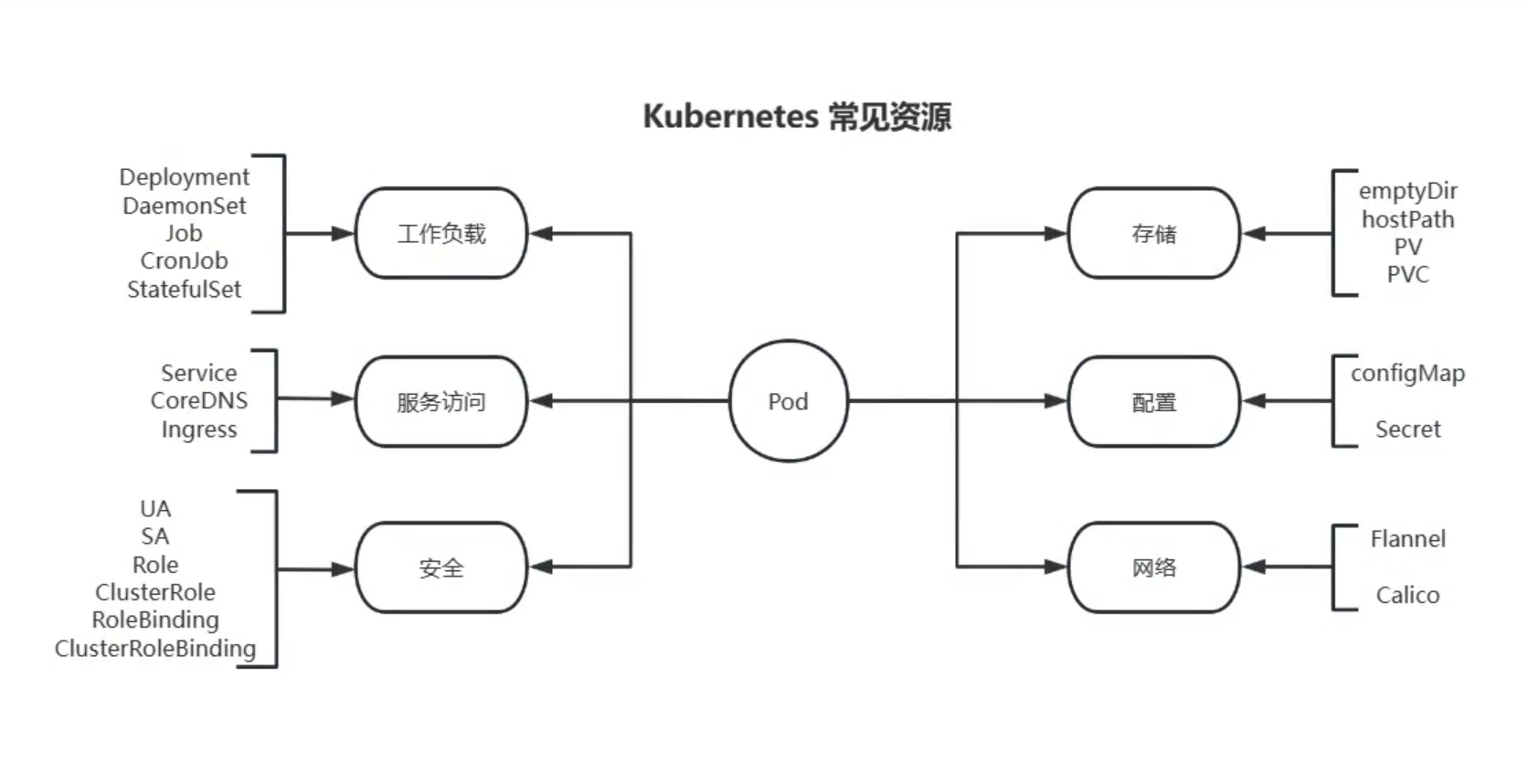
1、Kubernetes 的服务发现和负载均衡机制
2 、Kubernetes 的 Service 工作机制
3 、Kubernetes 的 Service 工作模式
4 、Kubernetes 的 Service 类型
5 、Kubernetes 的 Service 实现和管理方法
6 、Kubernetes 的 Service 实战案例
Pod有几种类型? (pod即豆荚,一个个豆子就可以理解为容器。pod和容器的关系是一个pod里面可以有一个或者多个容器。Pod是k8s部署的最小单位)
- 1、自主式 Pod
- 2、控制器管理的 Pod
pause是第一个被创建的容器,它的作用有两个:
初始化网络栈
挂载网络卷
Pause 容器,又叫 Infra 容器, 1. 其镜像非常小(目前在 700KB 左右); 2. 永远处于 Pause (暂停) 状态

Pod生命周期不咋长,一般单位可能是天。 Pod地址并不固定
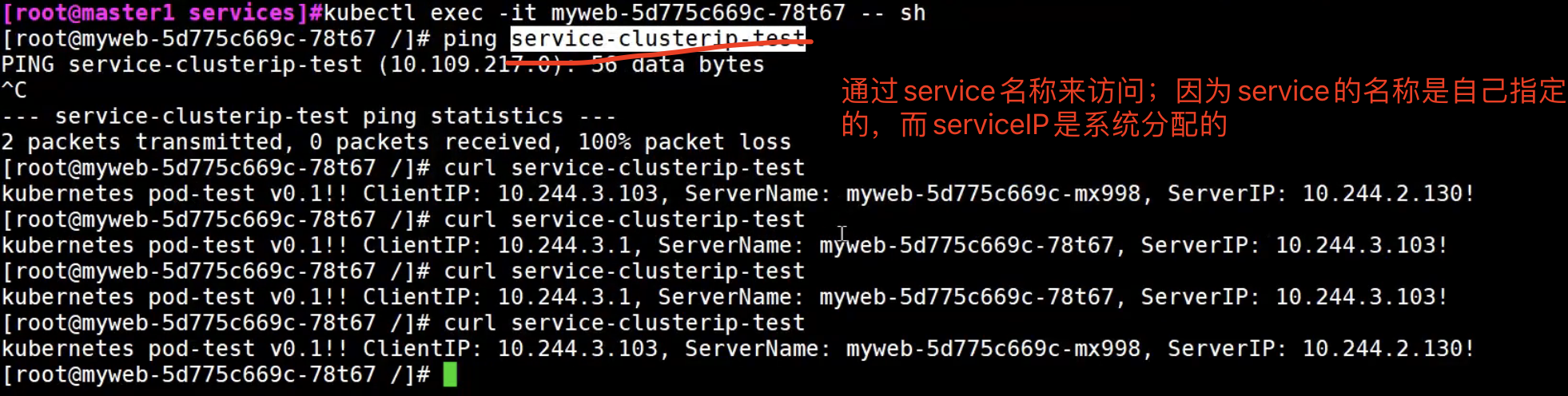
服务注册和服务发现机制

分从集群外访问和集群内部访问
k8s中的标签选择器是什么?
在Kubernetes中,标签选择器(Label Selector)是一种用于筛选和选择具有特定标签的资源的机制。它允许你根据资源的标签来定义选择条件,以便对符合条件的资源进行操作或查询。
标签选择器使用标签键值对来进行匹配,常见的用法是在Pod、Service、ReplicaSet、Deployment等资源对象中使用。你可以根据自定义的标签键值对来对这些资源进行分类、组织和选择。
Kubernetes提供了几种标签选择器的类型:
Equality-Based(等值选择器):这是最简单的标签选择器类型,使用等于(=)操作符来匹配标签的键值对。例如,你可以使用
app=web来选择具有标签app=web的资源。Set-Based(集合选择器):集合选择器提供了更灵活的匹配方式。它支持使用集合操作符(如
in、notin、exists、does not exist)来匹配一组标签。例如,你可以使用environment in (production, staging)来选择具有environment标签值为production或staging的资源。Label Selector Requirement(标签选择器要求):标签选择器要求是一个由键、操作符和值组成的表达式,用于指定选择条件。你可以组合多个标签选择器要求来创建复杂的选择条件。
通过使用标签选择器,你可以根据资源的标签进行精确的选择和操作,例如选择特定环境下的Pod、选择属于某个应用的Service等。这为管理和操作Kubernetes中的资源提供了更大的灵活性和可扩展性。
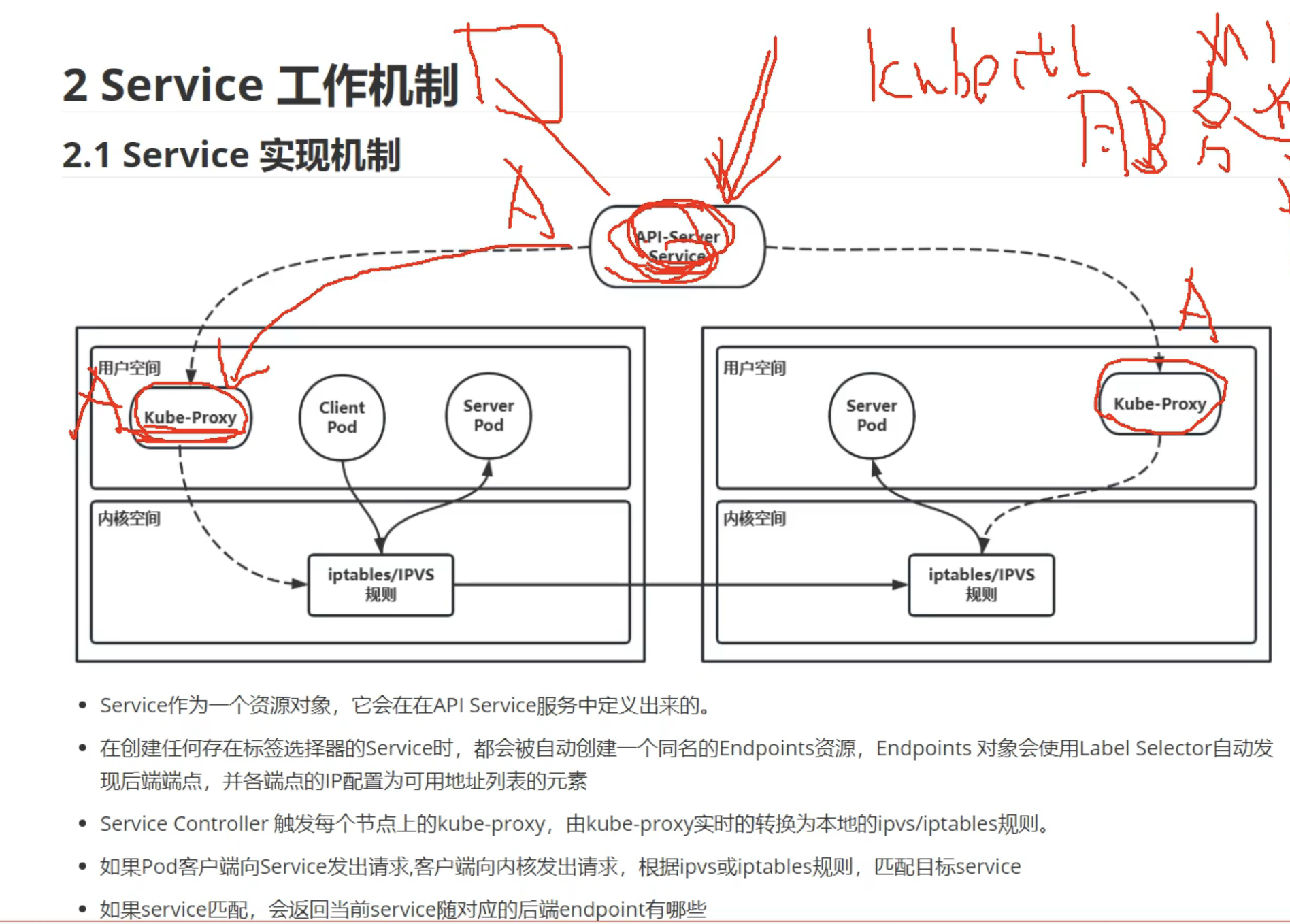
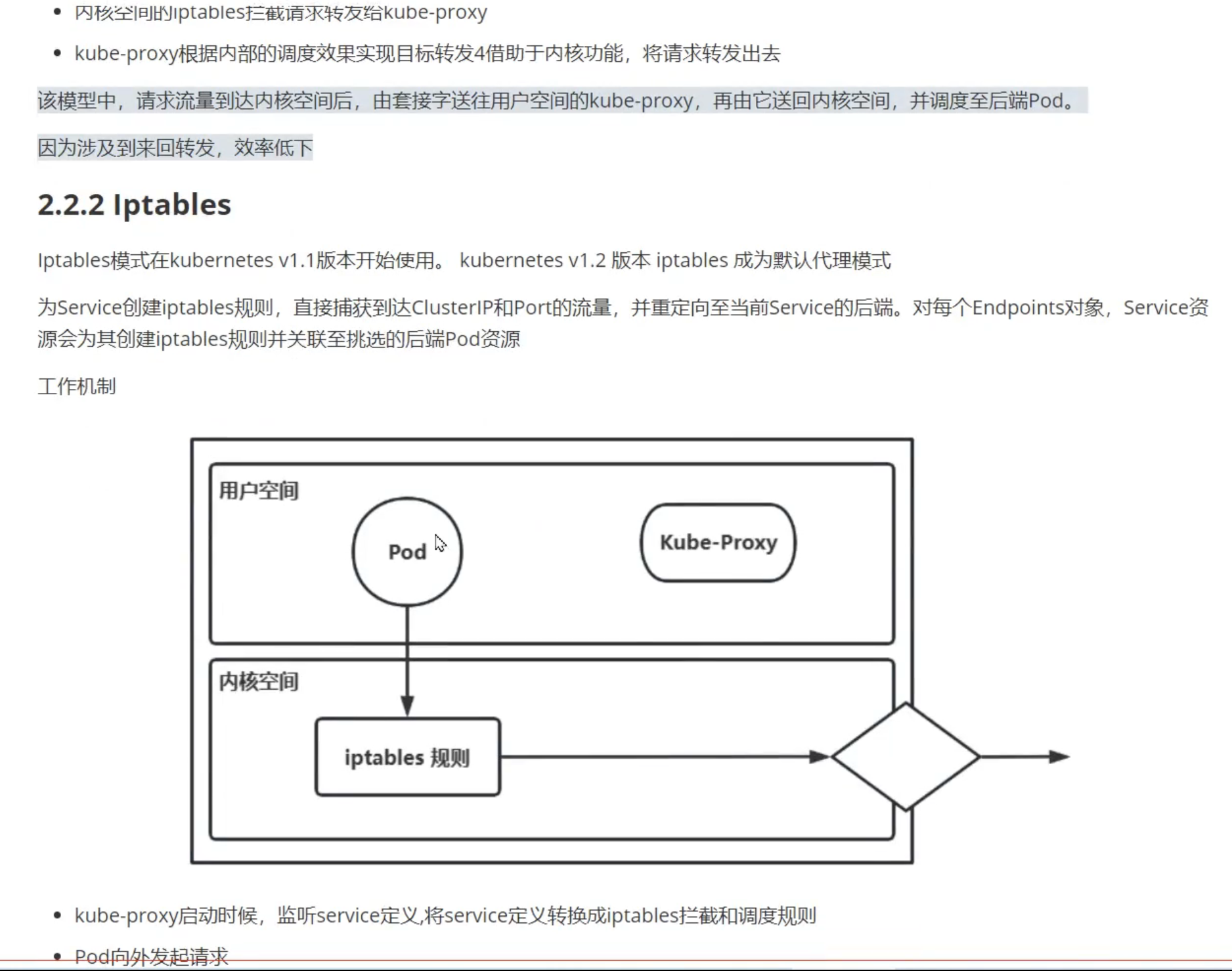
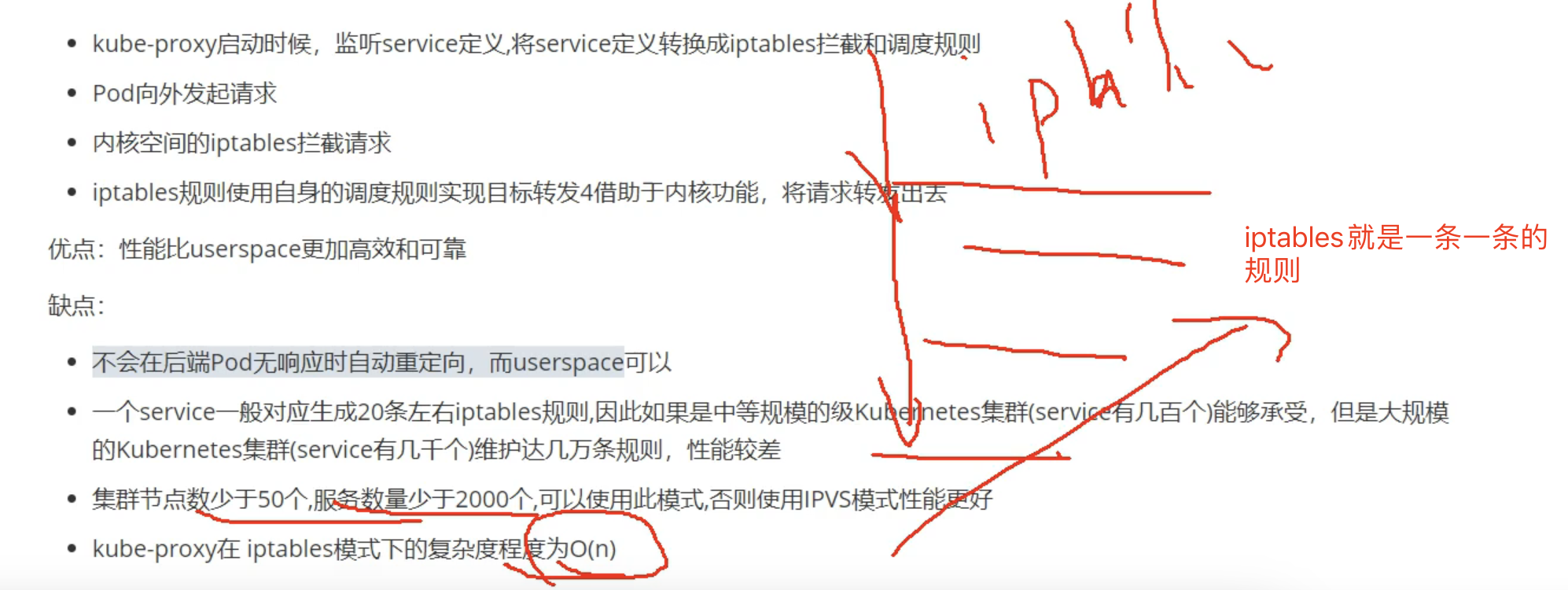
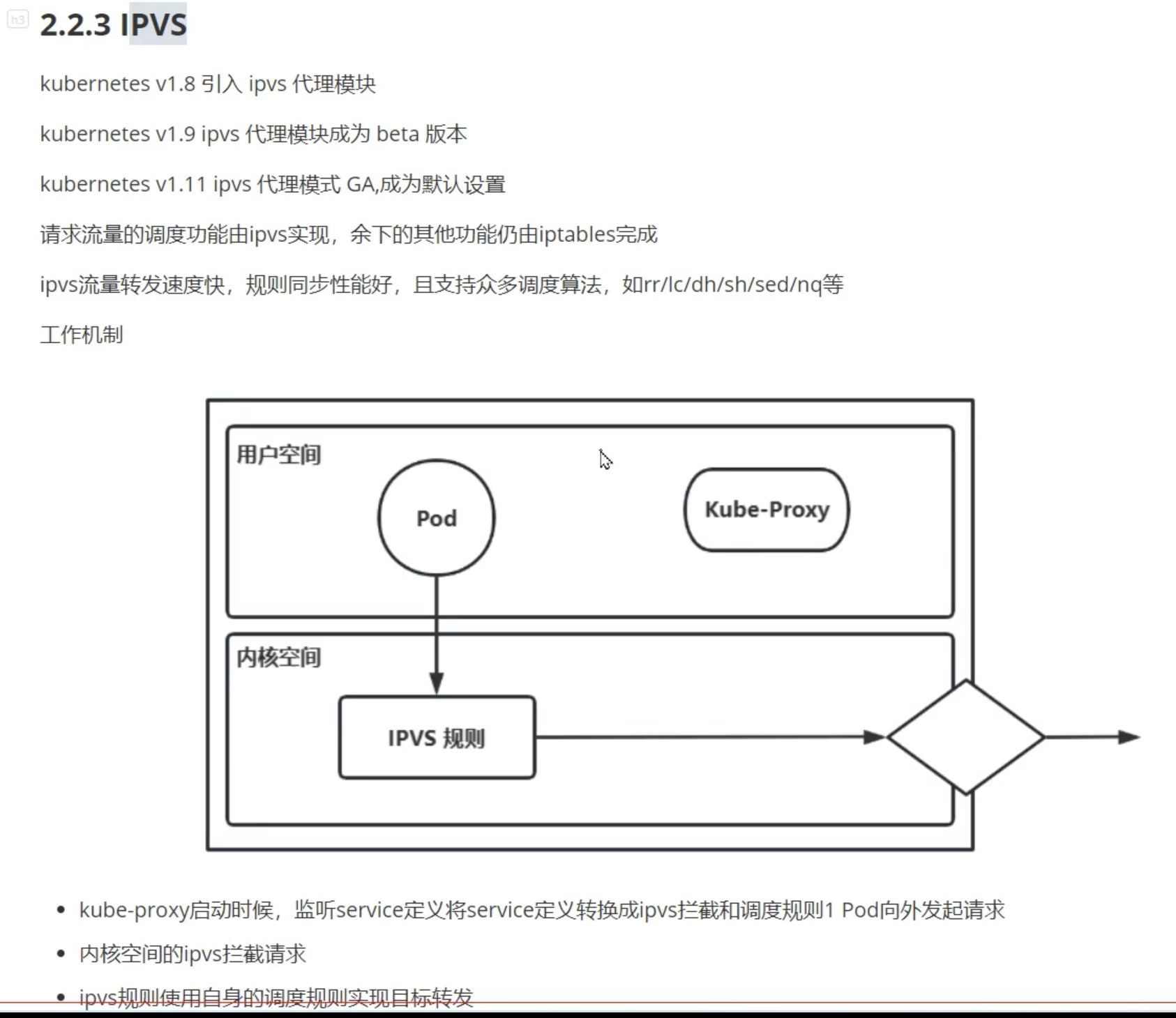
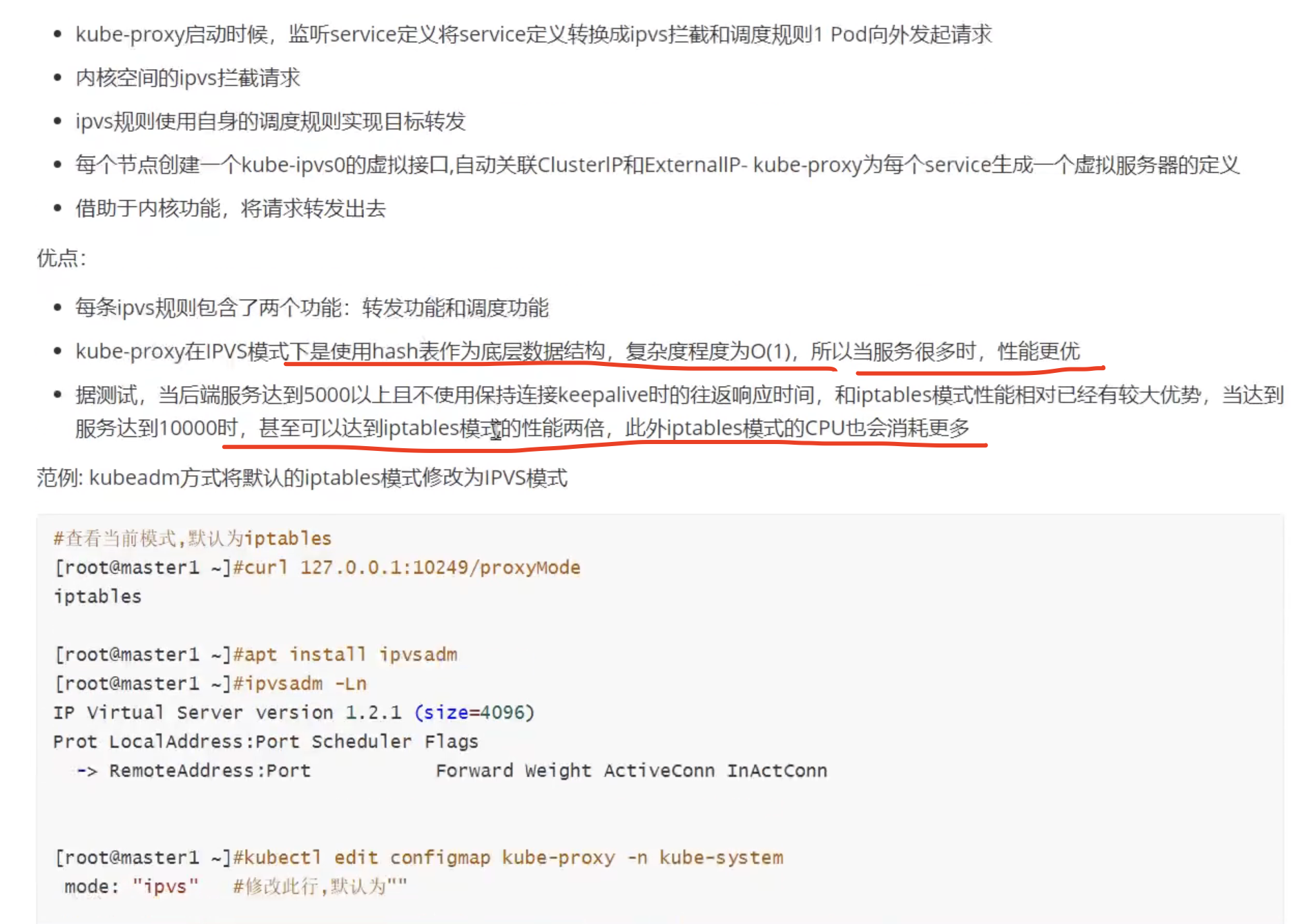
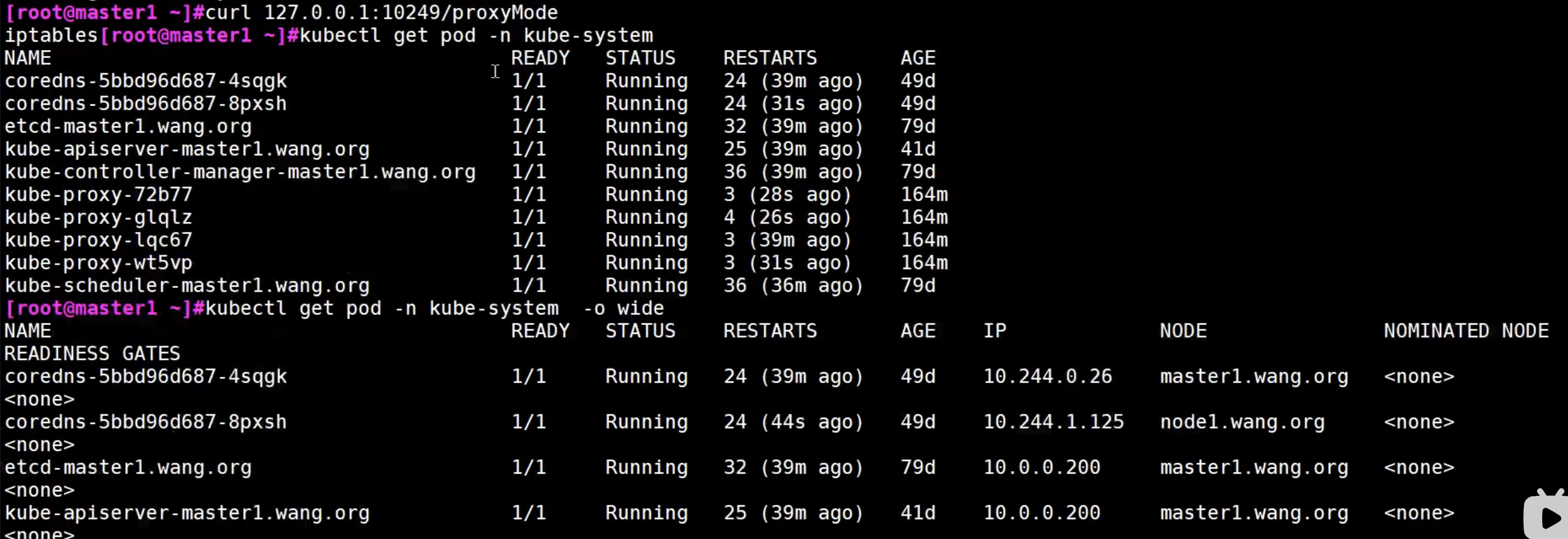
可以认为kube-proxy就是service的客户端;kube-proxy又像是一个管理iptable/IPVS的工具

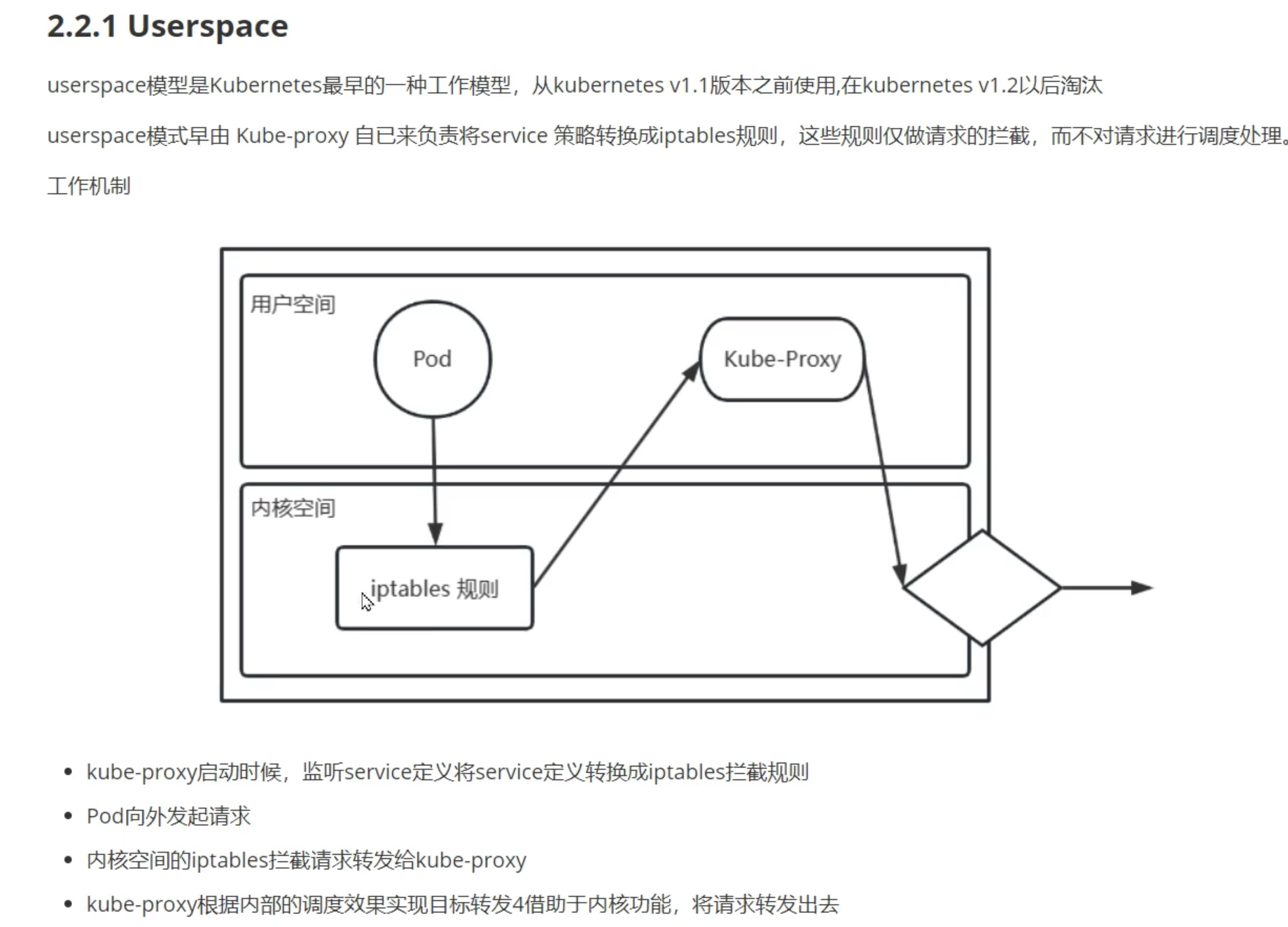
userspace用的很少了…
目前主要是iptables和IPVS
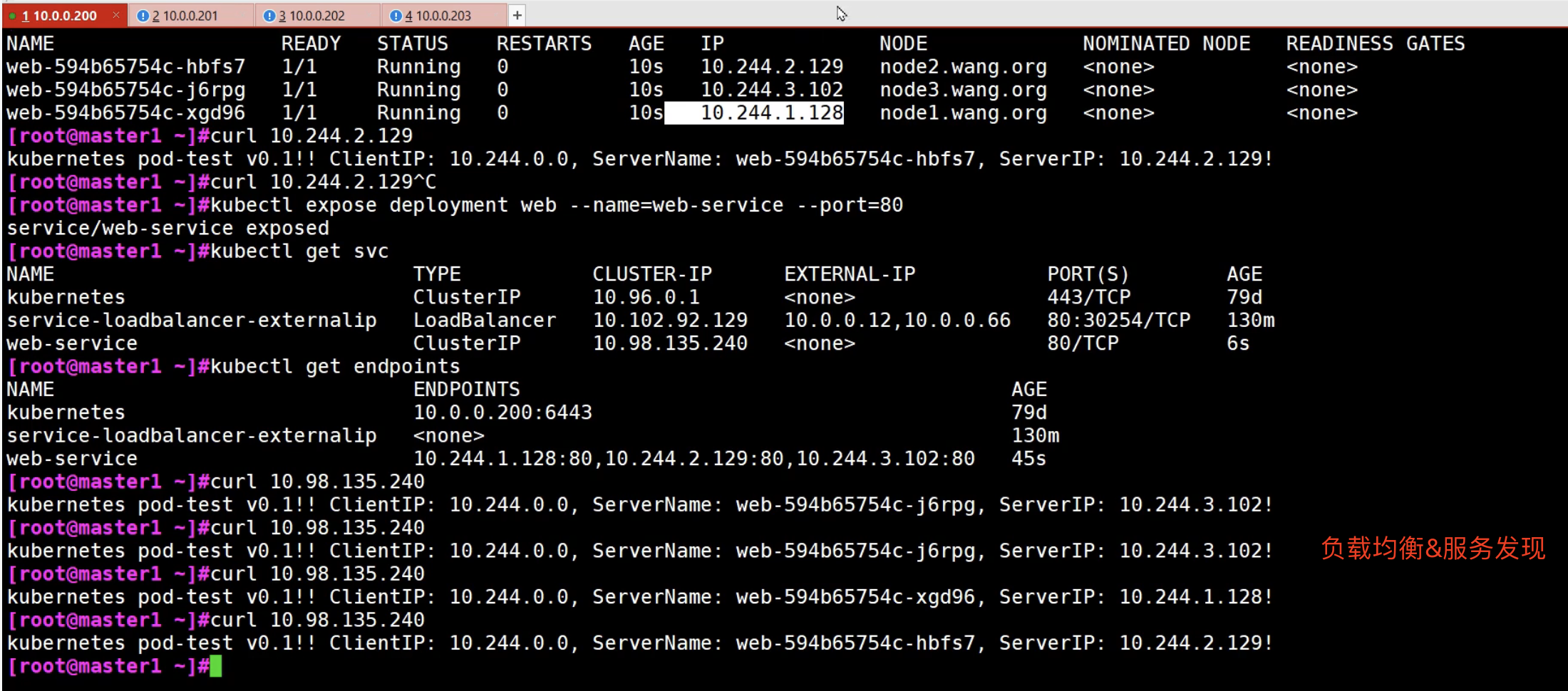
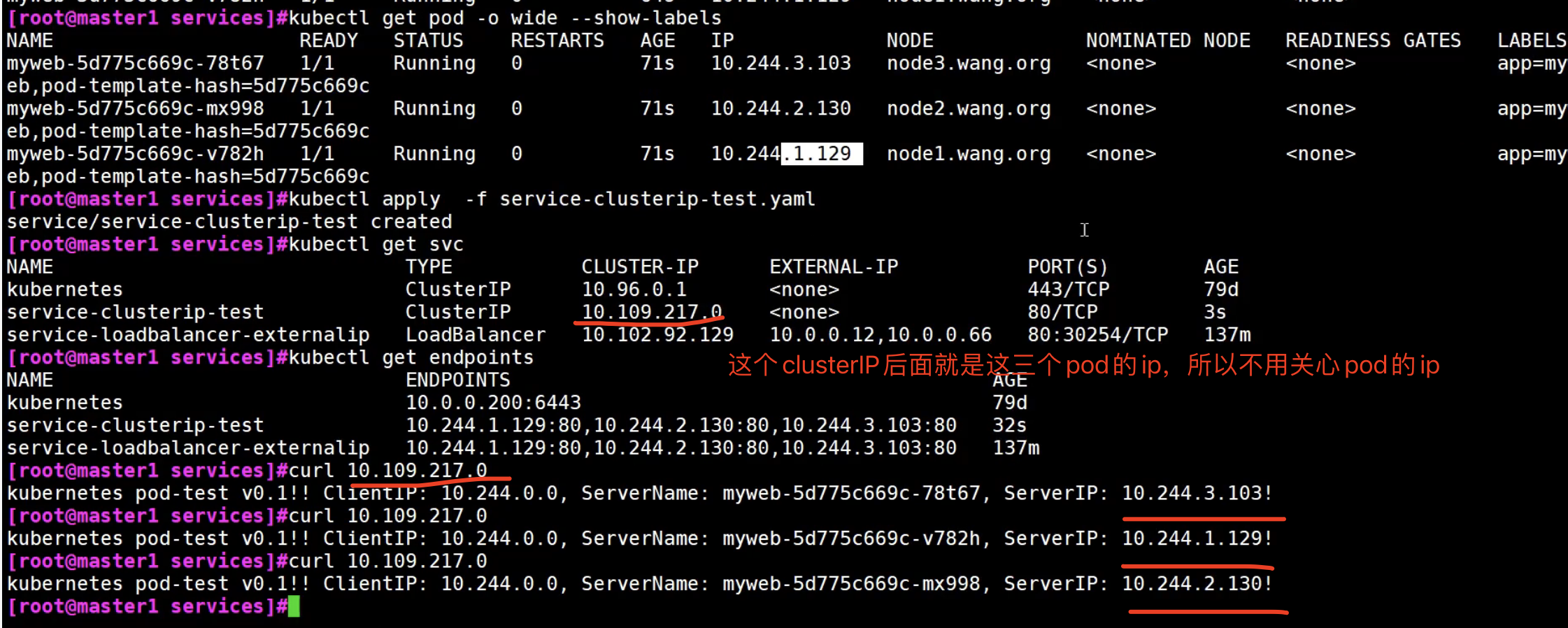
service的作用就是负载均衡和服务发现
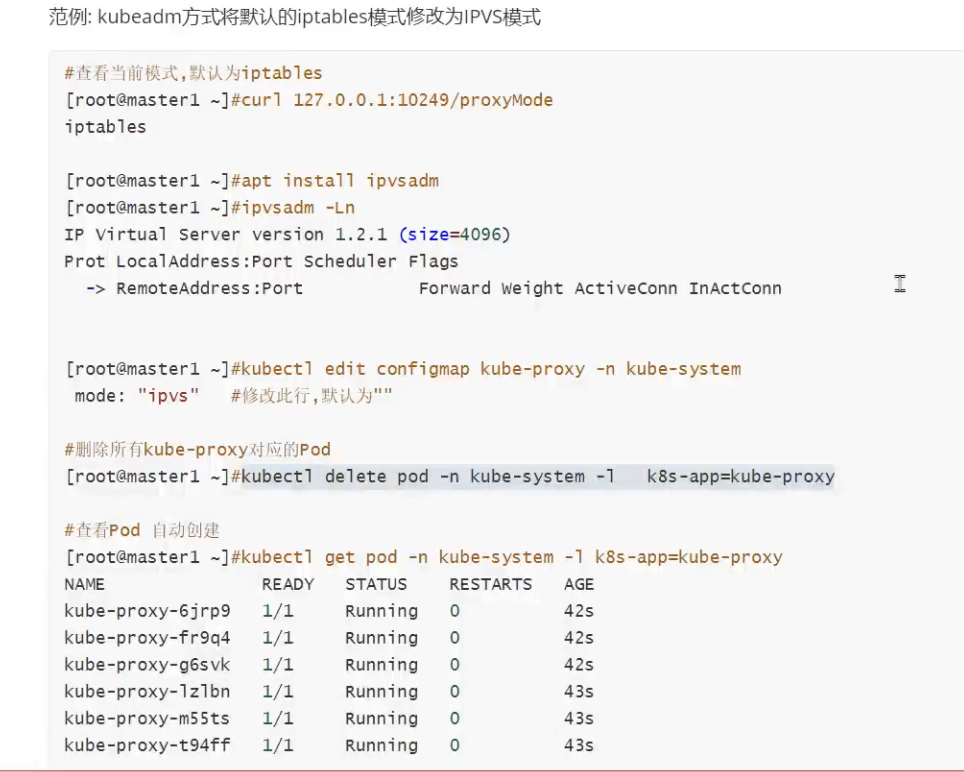
Service的类型
- ClusterIP(集群IP),就是为集群内部之间访问的(外部网络无法访问)
- NodePort,在物理节点上,暴露一个外部能访问的端口,可以做到从外部网络访问集群内部pod
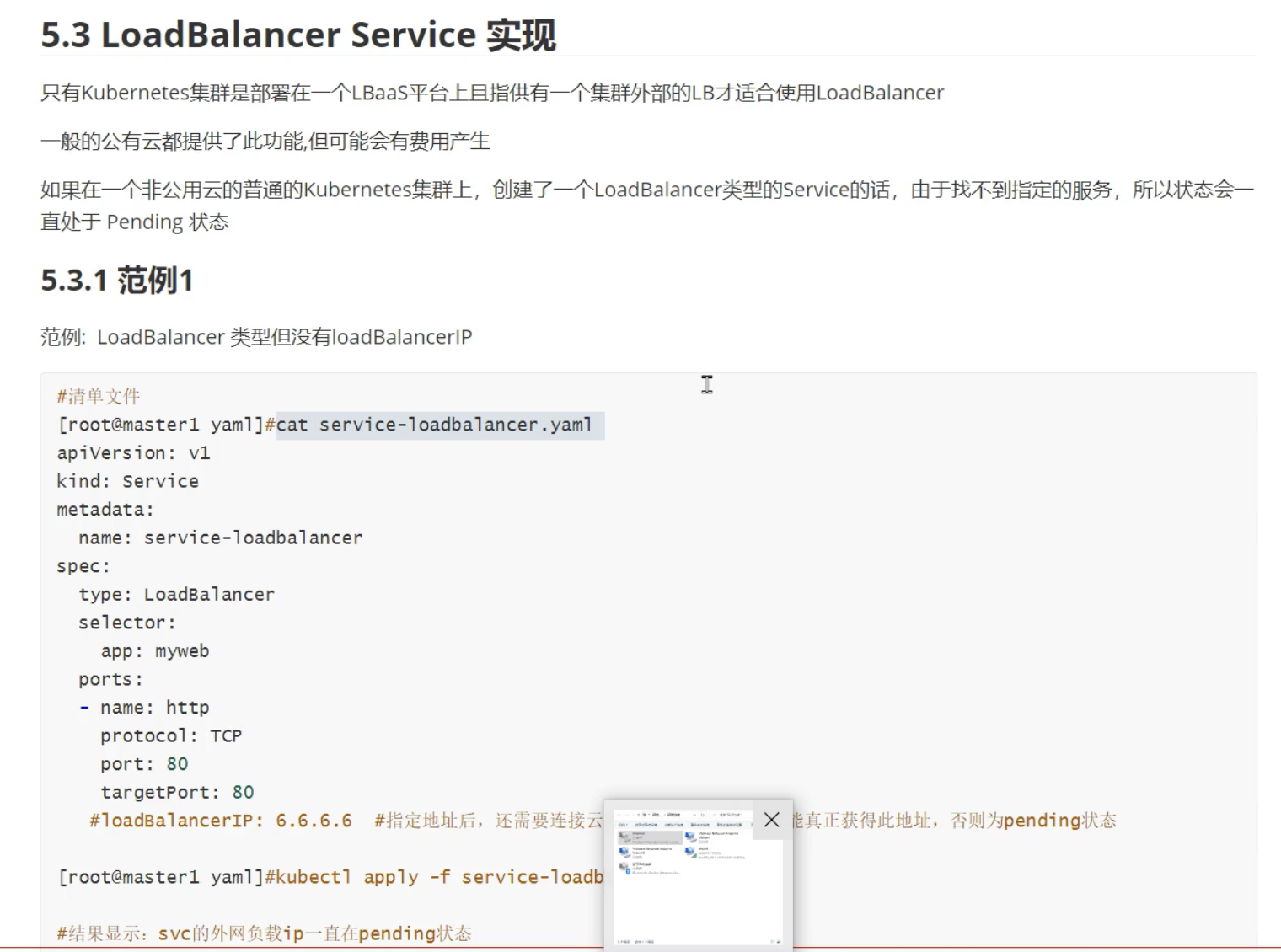
- LoadBalancer:云服务厂商用,普通公司不用管
- ExternalName: 从集群内部pod,去访问外部服务(如访问外部的数据库;很多重的服务,比如mysql,都不用k8s搭建,跑在集群外)
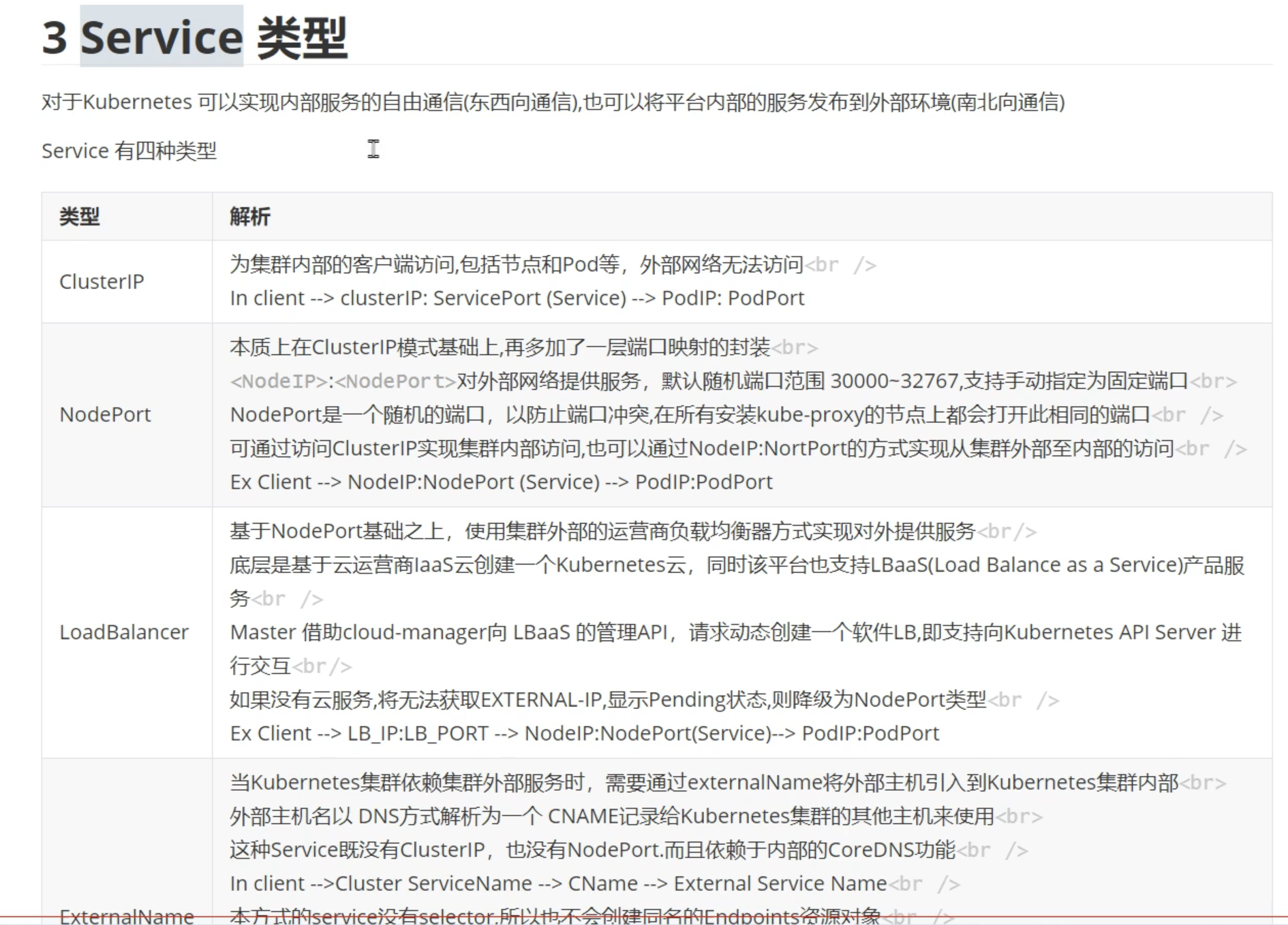

Service的类型最主要的就是ClusterIP
创建k8s集群时,3个网络: 节点网络,pod网络,service网络(如clusterIP)
阿里云,华为云的只有2个网络,节点网络和pod网络合并了(pod直连物理网络,性能更好~)
(这四种)Service的创建(办法)
命令行方式
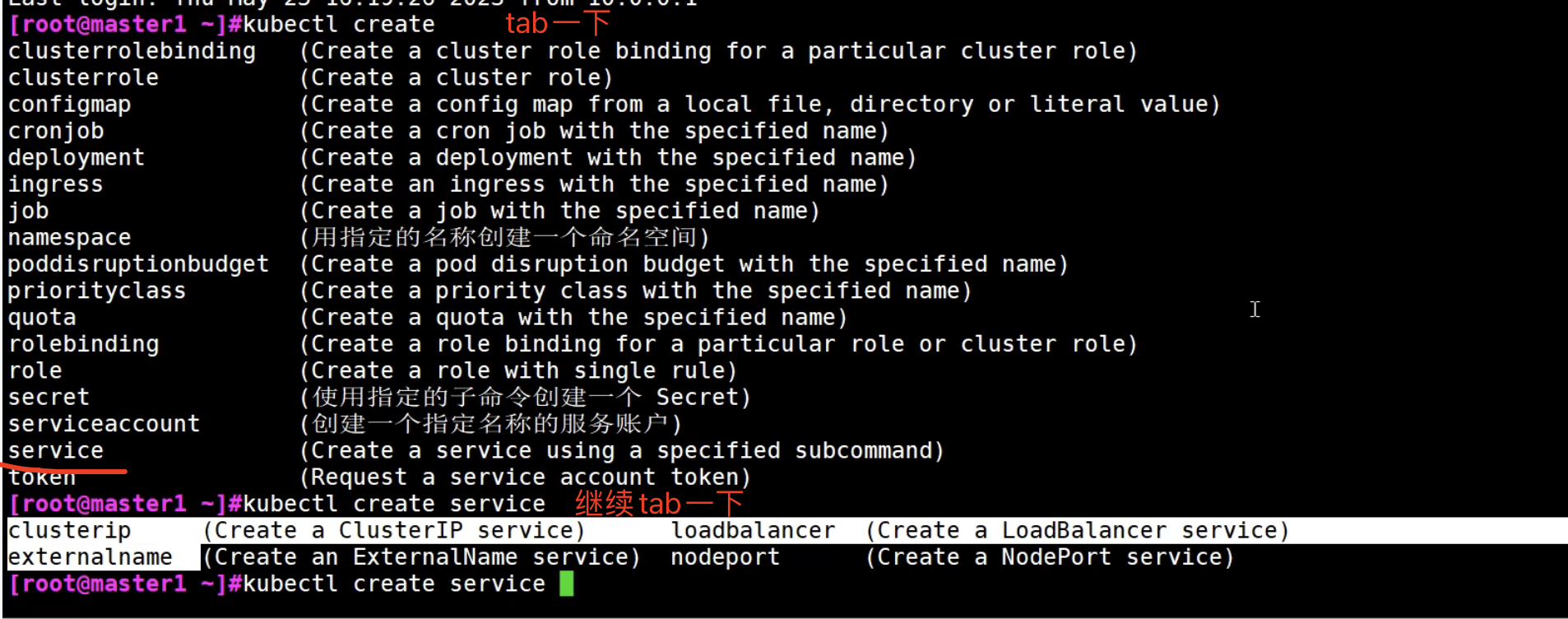
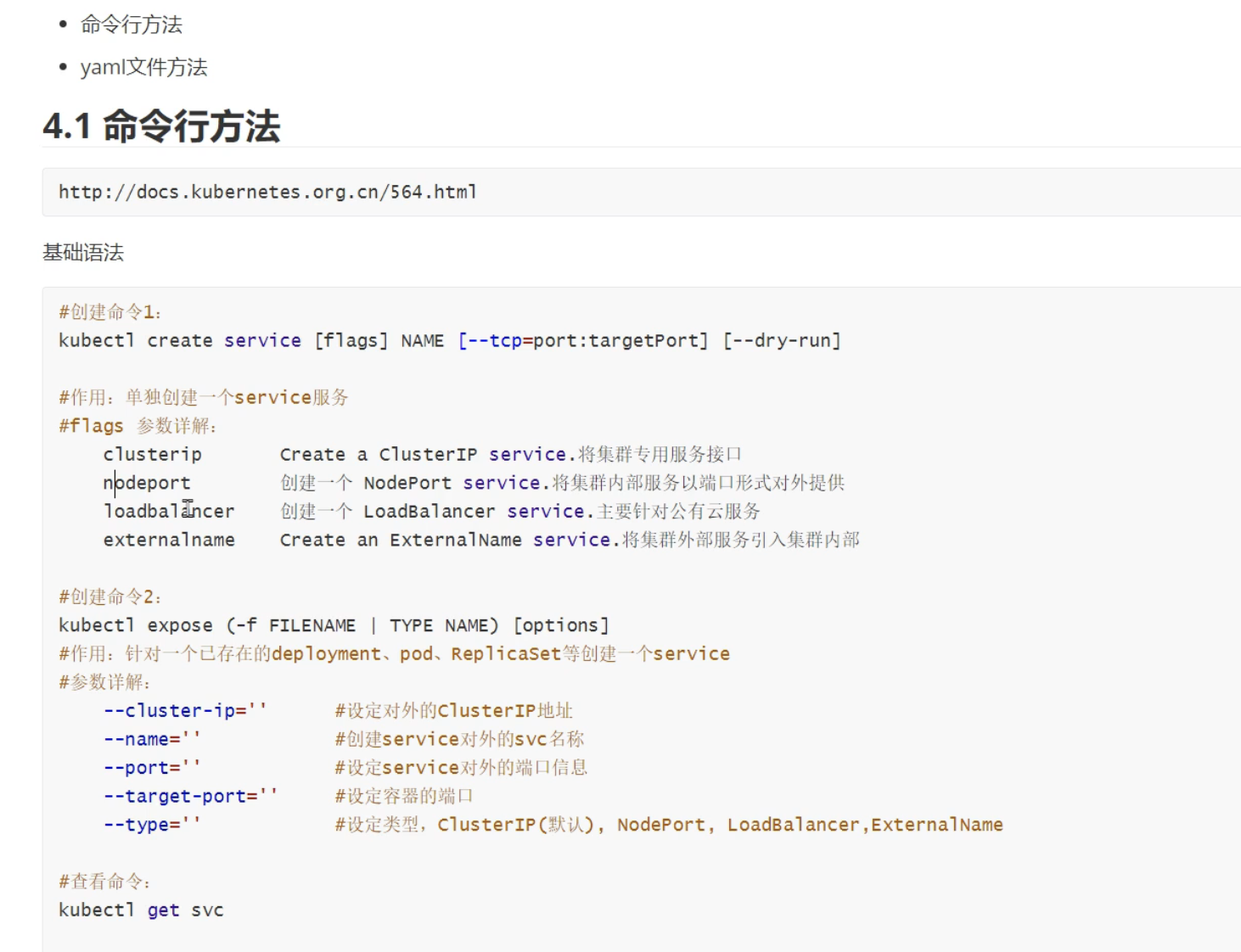
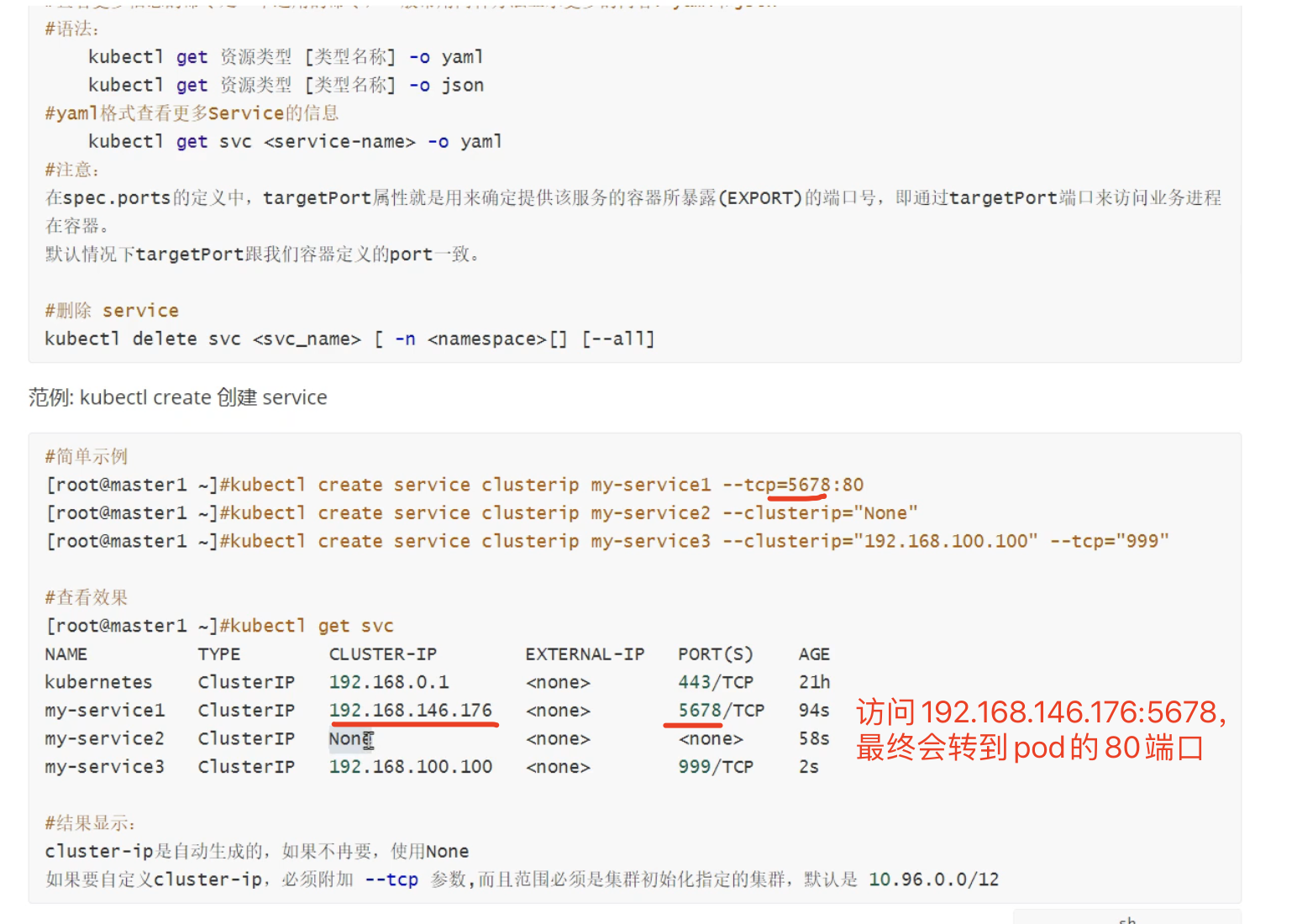
None的是无头服务
k8s中的无头服务是什么?
在Kubernetes中,”无头服务”(Headless Service)是一种特殊类型的服务,它与普通服务(ClusterIP类型)有所不同。无头服务的主要特点是不分配ClusterIP,也就是没有虚拟IP地址,因此它没有默认的负载均衡功能。
正常的服务(ClusterIP类型)会为服务提供一个虚拟IP地址,并自动在后端的Pod之间进行负载均衡,将请求均匀地分发给Pod。这对于大多数服务是很有用的,因为它们通常只需提供一个稳定的访问终结点。
然而,有些场景下,我们需要直接访问后端Pod的个体实例,而不是通过负载均衡的方式。这时就可以使用无头服务。无头服务通过设置clusterIP: None来定义,它会为服务的每个后端Pod创建一个DNS记录,这样就可以通过DNS解析直接访问每个Pod的网络地址。
无头服务在以下情况下特别有用:
- StatefulSet:当使用StatefulSet来管理有状态的应用时,每个Pod都具有唯一的标识符和稳定的网络标识。无头服务可以为StatefulSet中的每个Pod提供唯一的DNS记录,使得可以直接访问每个有状态Pod的网络地址。
- 数据库集群:在数据库集群中,每个数据库实例通常具有自己的唯一标识符和网络地址。无头服务可以为每个数据库实例提供唯一的DNS记录,便于直接连接到特定的数据库实例。
总结来说,无头服务是一种没有ClusterIP的服务,它提供了直接访问每个后端Pod的能力,适用于需要直接连接到个体实例的场景,如StatefulSet和数据库集群。
这些ip会变。。
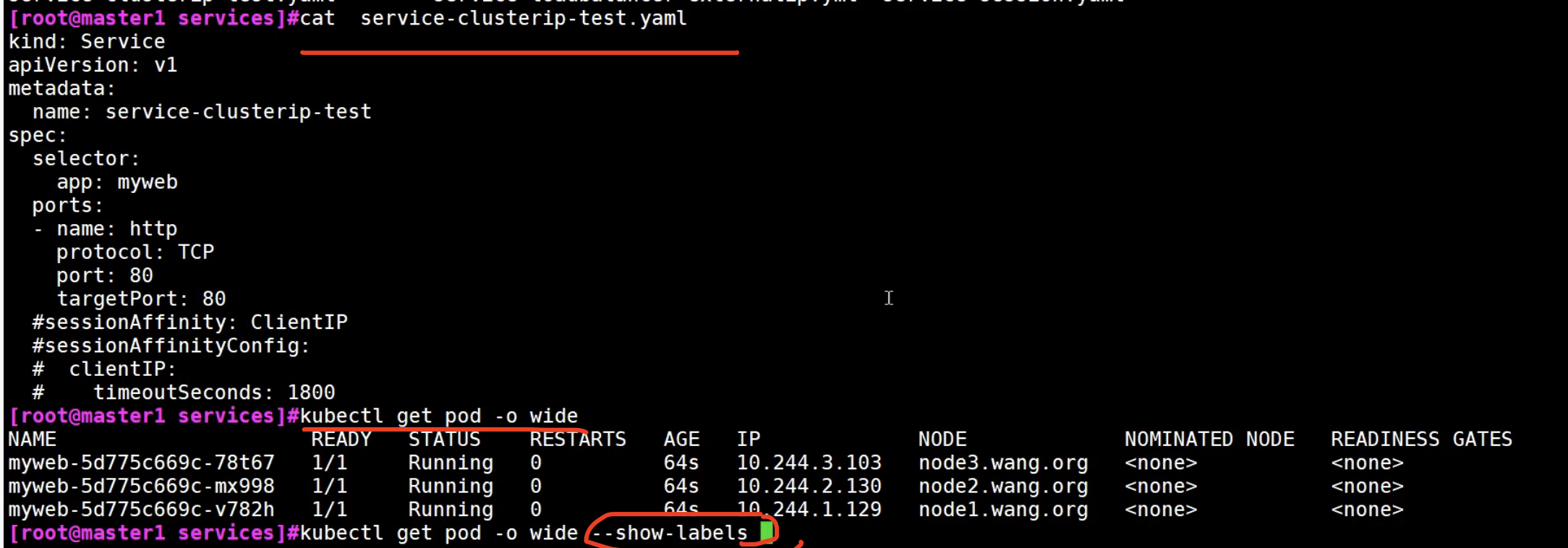
创建一个service,
kubectl get svc命令
默认是ClusterIP类型
文件方式
命令行方式 不利于复用..最好还是用文件方式
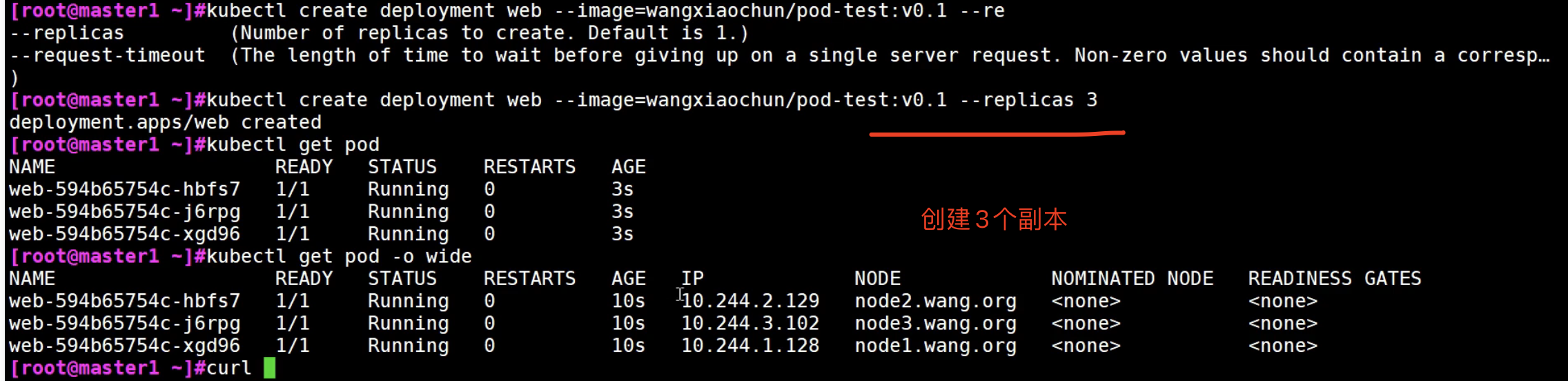
Service实战案例
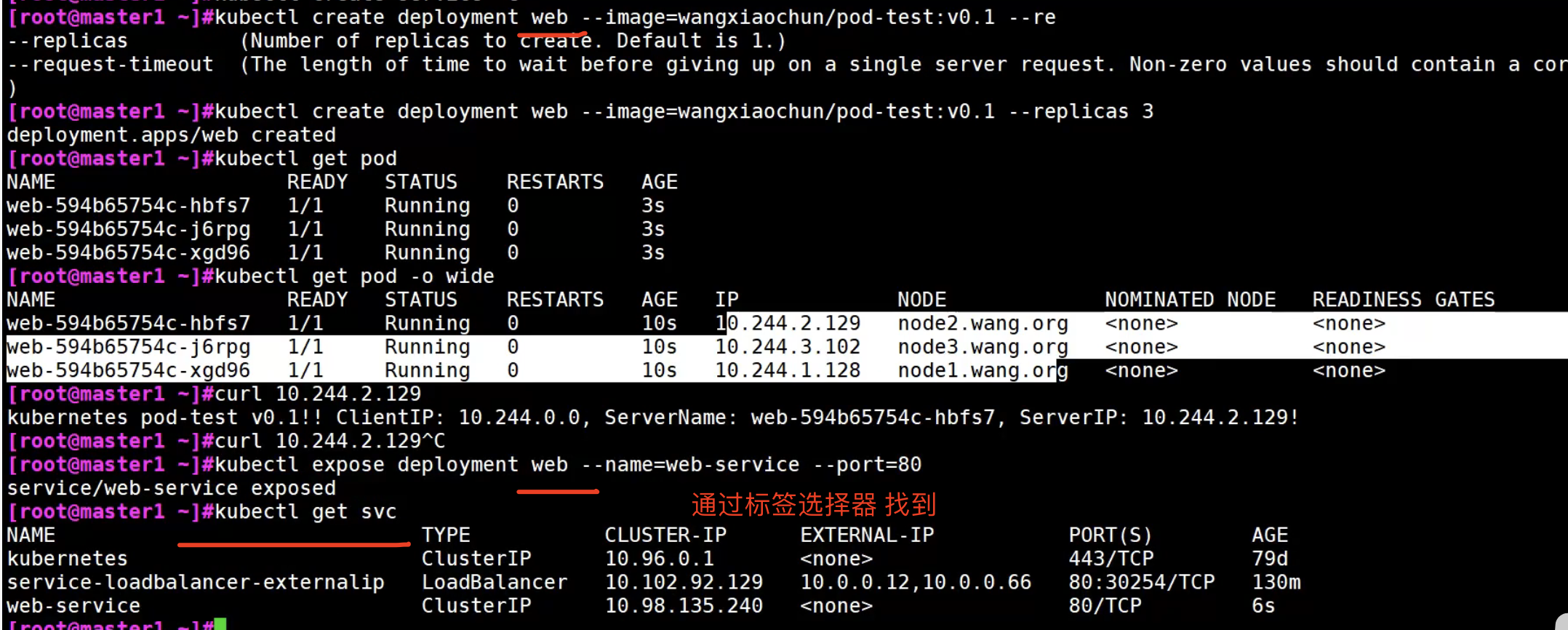
NodePort用的是DNAT技术
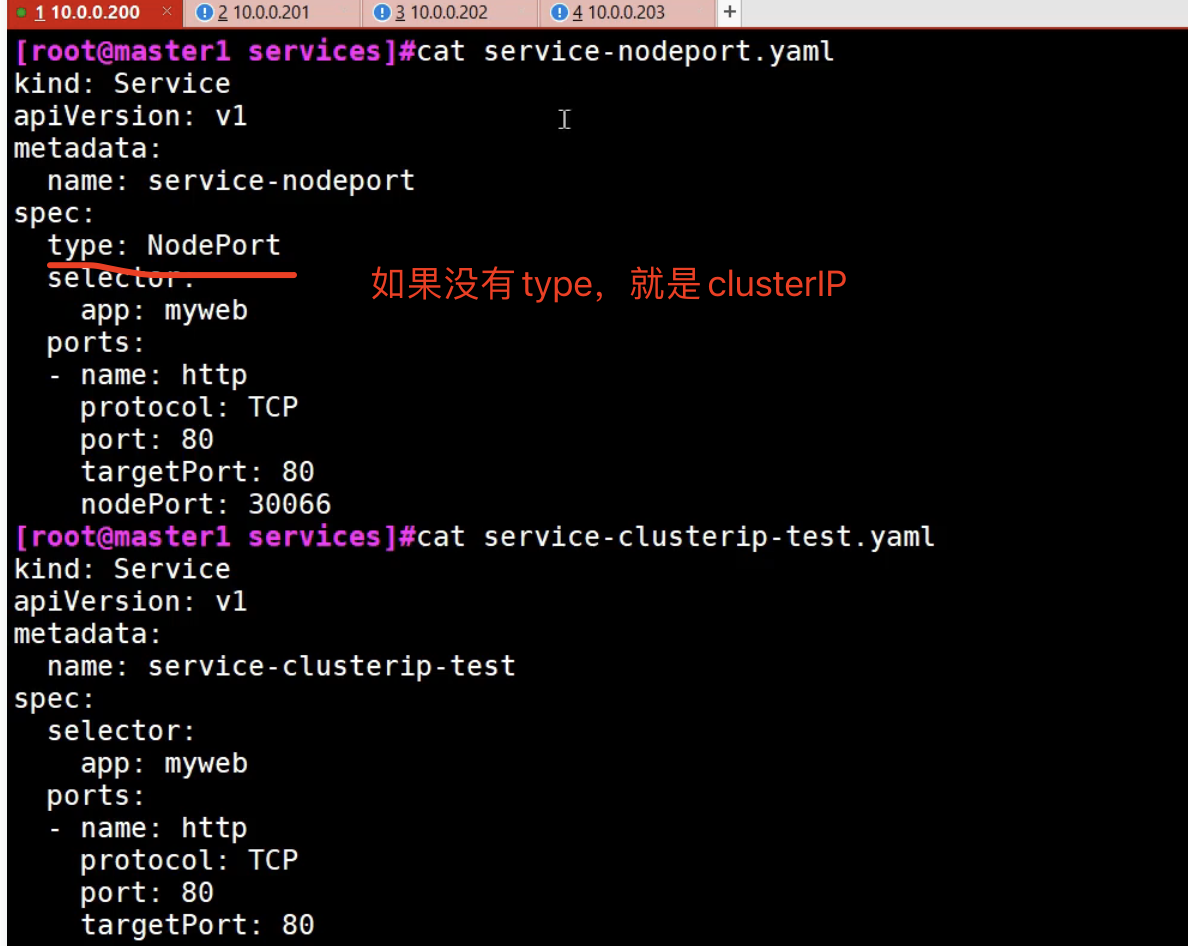
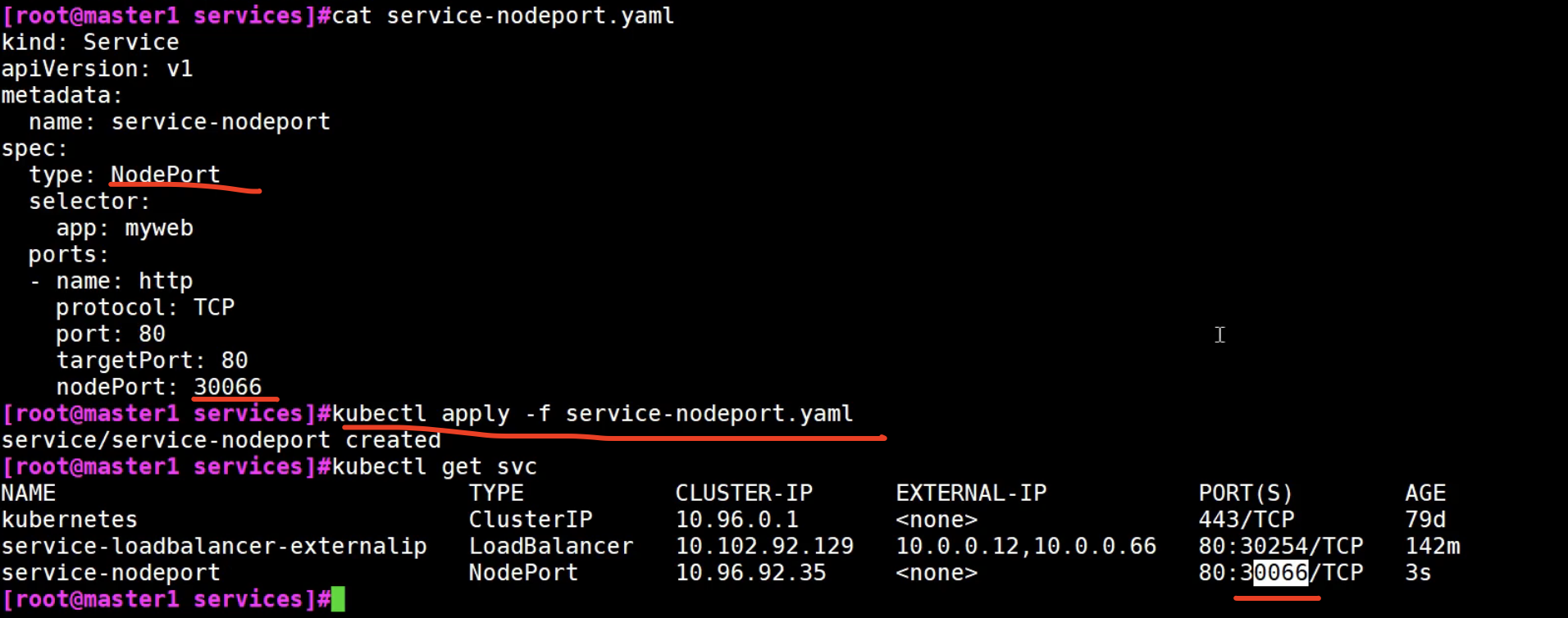
是用iptables或ipvs
这样就可以从集群外部,去访问任何一个pod
LoadBalancer类型:
用于公有云,局域网不用
ExternalName类型:
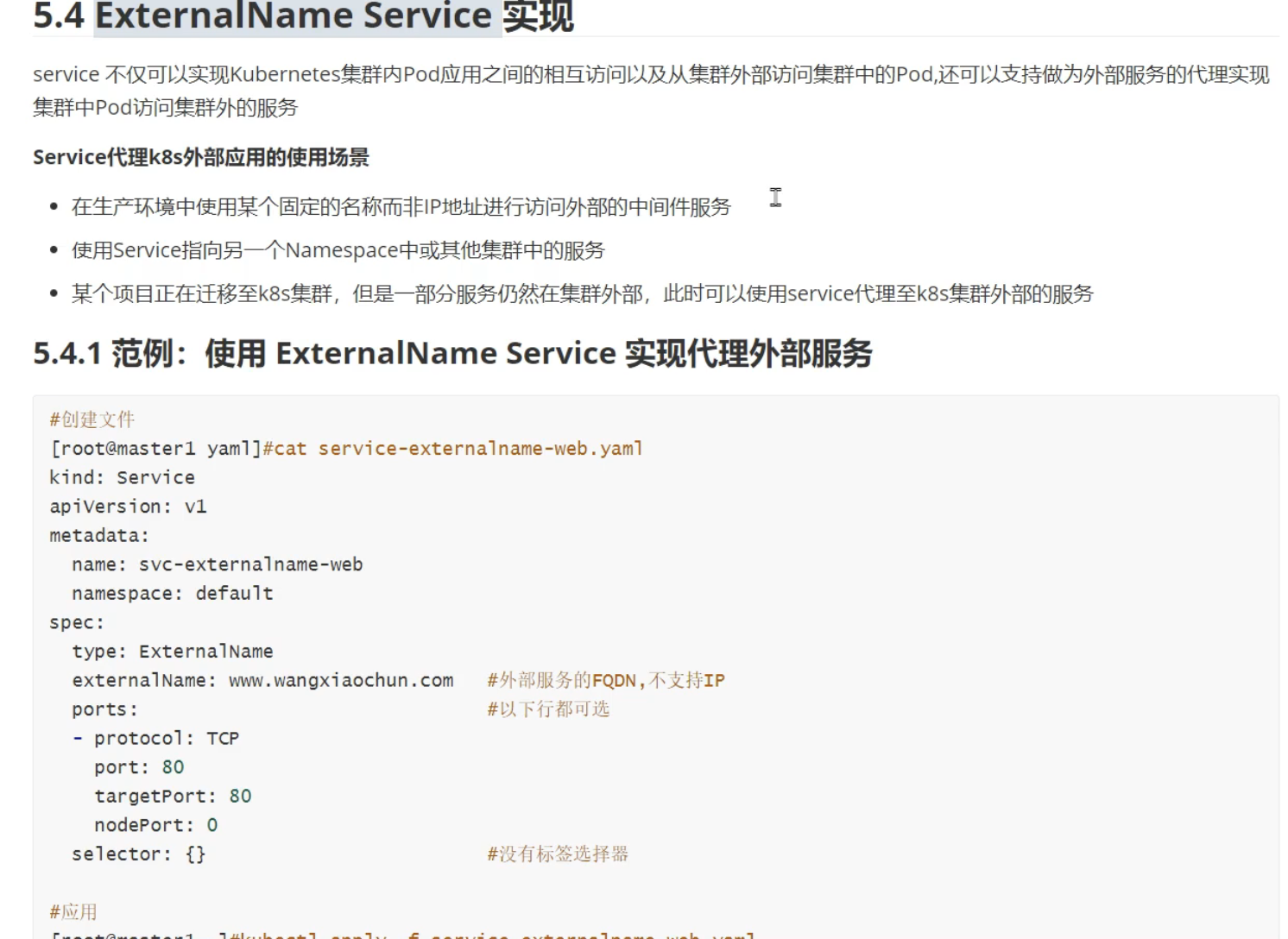
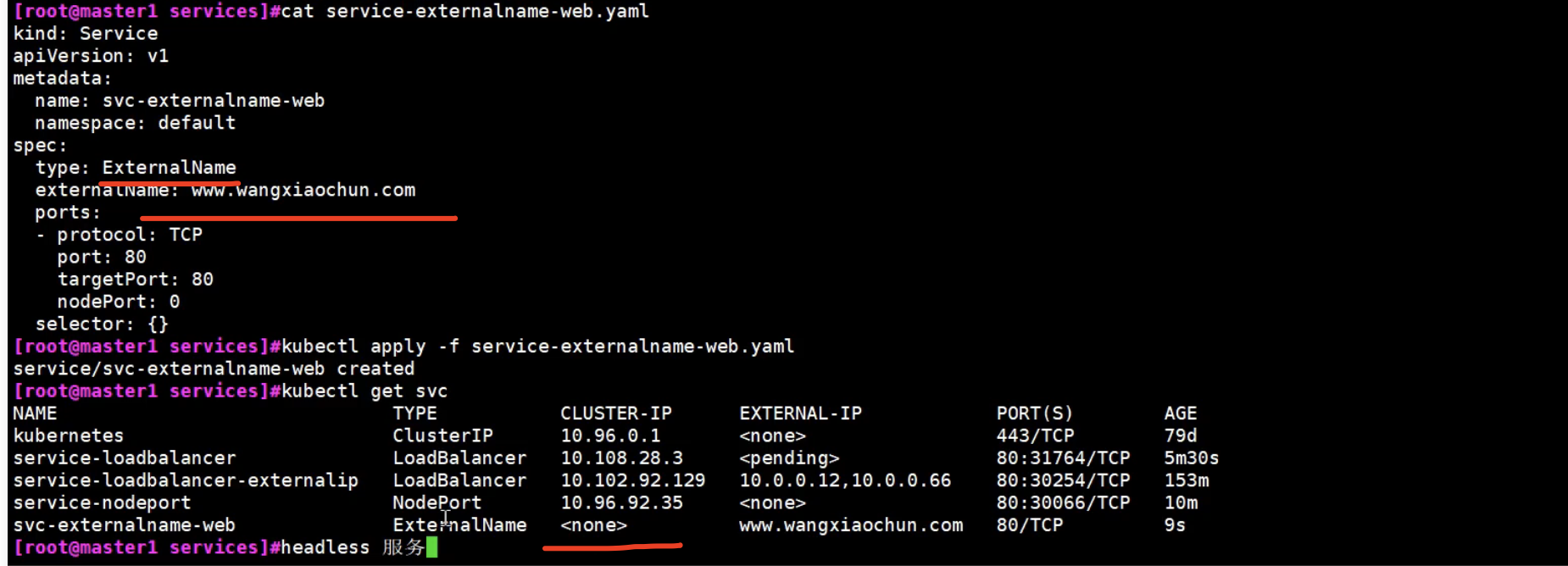
ExternalName就是一种无头服务
调度的策略问题
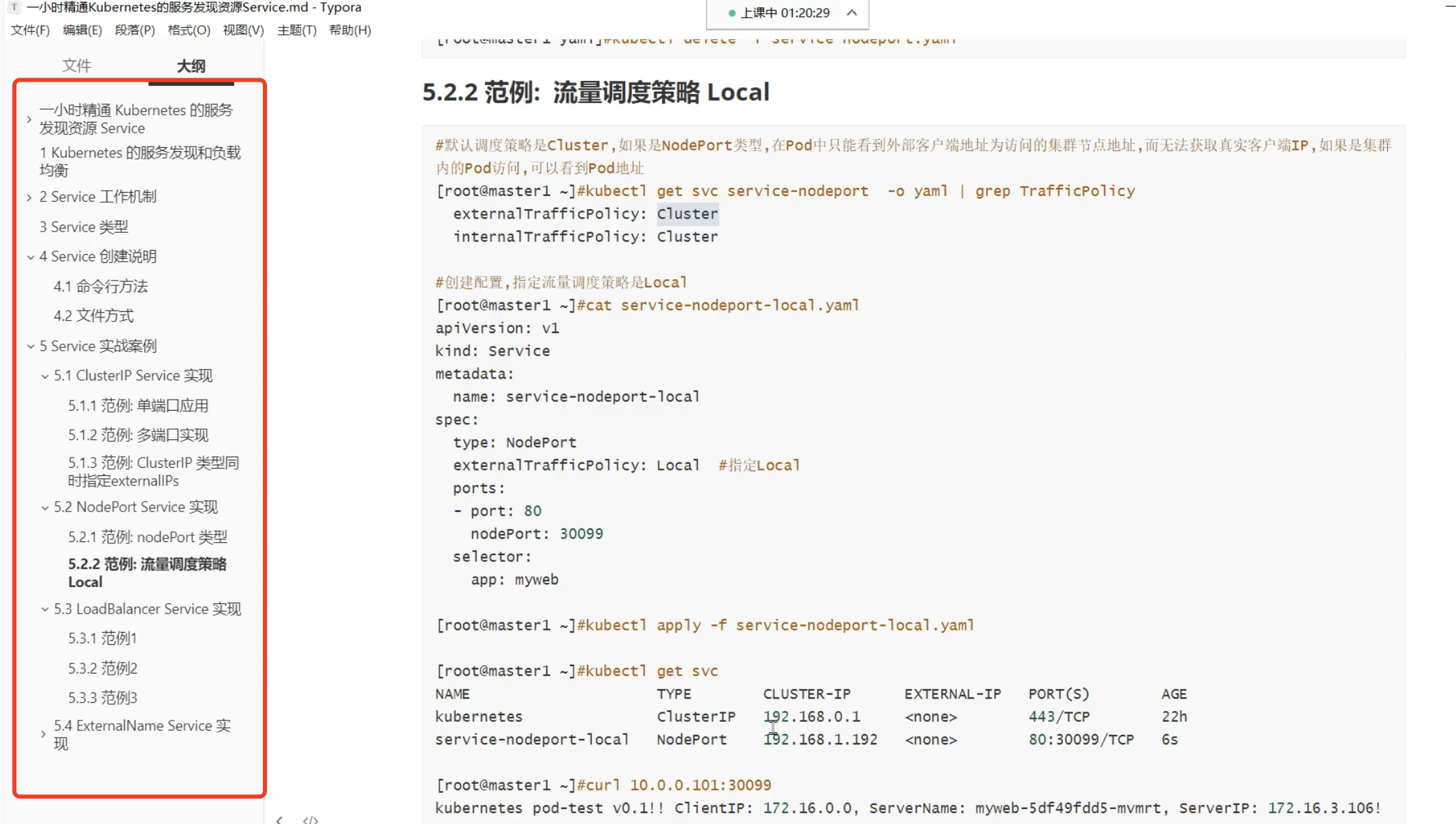
Local策略
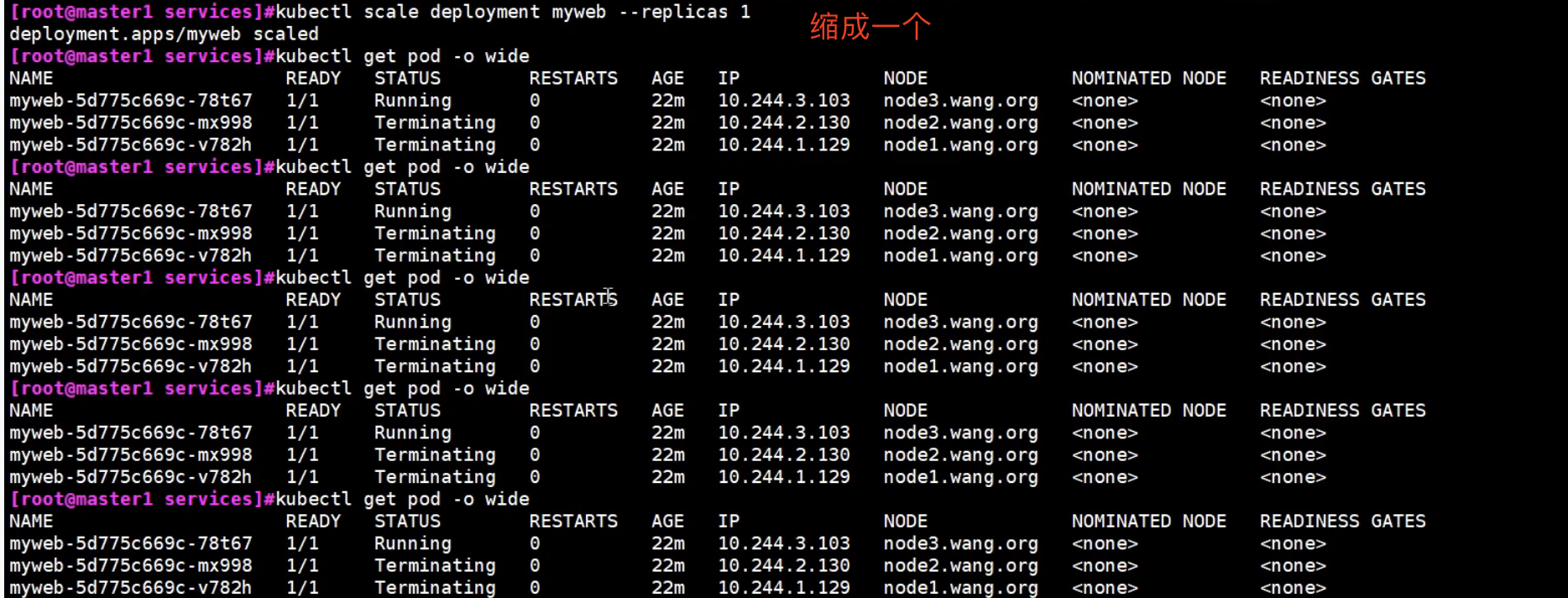
Local能记录客户端的真实ip地址,cluster策略记录不了(记录的会是节点的物理地址)
k8s的local策略是什么?
Kubernetes中的”local”调度策略是一种节点选择策略,用于在容器调度时优先选择已经运行有该容器镜像的节点。当使用”local”调度策略时,调度器会尝试将容器调度到已经运行相同镜像的节点上,以充分利用节点上已经存在的缓存和状态,从而提高性能和效率。
使用”local”调度策略可以减少在不同节点之间迁移容器所带来的网络传输和磁盘I/O的开销,尤其是对于需要频繁读取大量数据的应用程序而言。例如,在机器学习训练任务中,容器可能会使用相同的训练数据集,因此将它们调度到同一节点上可以避免重复加载数据集,提高训练速度。
要使用”local”调度策略,可以通过在Pod的调度器名称字段中指定”local”来进行配置。例如:
1 | apiVersion: v1 |
需要注意的是,”local”调度策略需要确保节点上已经有相应的镜像运行。如果节点上没有满足条件的容器镜像,则该Pod可能无法被调度,或者会等待直到有满足条件的节点可用。
请注意,”local”调度策略在Kubernetes中属于实验性功能,具体行为和效果可能会受到不同版本和配置的影响。在使用之前,建议在测试环境中进行充分的验证和评估,确保它适用于你的特定用例和需求。
还有什么其他策略?
除了”local”策略之外,Kubernetes还提供了其他一些调度策略。以下是其中几种常见的策略:
“Spread”策略:该策略旨在将Pod均匀地分散在集群的不同节点上,以避免单个节点上的过度负载。调度器会尽量选择已经拥有较少Pod的节点来运行新的Pod,以实现负载均衡。
“Least-Loaded”策略:这个策略会将新的Pod调度到当前资源利用率最低的节点上,以确保资源分配更加均衡。它考虑节点的资源使用情况,并将Pod调度到最空闲的节点上。
“Node Selector”策略:这是一种基于节点标签的策略,可以根据节点的标签选择合适的节点来运行Pod。你可以为Pod定义一个或多个节点选择器,调度器会选择与节点选择器匹配的节点来运行Pod。
“Taints and Tolerations”策略:这个策略用于设置节点的容忍性和容忍规则。通过给节点添加污点(Taints)和为Pod添加容忍规则(Tolerations),可以控制Pod是否可以被调度到具有特定污点的节点上。这可以用于实现节点的分级、隔离和限制。
“Custom Scheduler”策略:Kubernetes还允许你编写自定义的调度器来实现特定的调度逻辑和策略。你可以开发自己的调度器插件,并将其配置为Kubernetes集群中的默认调度器,以根据自定义的规则进行容器的调度。
这只是一些常见的Kubernetes调度策略,还有其他更高级和定制化的策略可供选择。根据你的具体需求,你可以选择适合的策略或结合多个策略来实现更复杂的调度逻辑。
没有cluster策略吗?
抱歉,我之前的回答中确实遗漏了一种常见的调度策略,即”Cluster”(集群)策略。在Kubernetes中,”Cluster”策略也被称为”Default”策略,用于将Pod调度到任意可用的节点上。
当未指定特定的调度策略时,Kubernetes将使用”Cluster”策略作为默认策略。它会简单地将Pod调度到集群中的任意可用节点上,以实现简单的负载均衡。
使用”Cluster”策略的示例Pod定义如下:
1 | apiVersion: v1 |
在这个示例中,没有指定任何调度器或调度策略,因此默认会使用”Cluster”策略将Pod调度到可用节点上。
请注意,当集群中存在多个可用节点时,”Cluster”策略不会考虑节点的资源使用情况或其他因素,而是简单地选择任意一个可用节点来运行Pod。如果你需要更精确的调度策略,例如基于资源需求、亲和性或其他规则,你可以使用前面提到的其他调度策略来配置Pod的调度行为。
cluster策略能记录真实的客户端ip吗?
在Kubernetes中,默认的集群策略(Cluster Strategy)无法直接记录真实的客户端 IP 地址。这是由于 Kubernetes 中的网络设计所致。
在 Kubernetes 集群中,Pod 被分配一个唯一的 Cluster IP(虚拟 IP),而集群中的每个节点都具有自己的物理 IP。当流量到达节点后,它会通过 NAT(Network Address Translation)从客户端 IP 转换为节点的 IP,然后再转发到相应的 Pod。
因此,在 Pod 中看到的客户端 IP 是转发流量的节点 IP,而不是真实的客户端 IP。这对于一些应用程序(如 HTTP 服务)需要获取真实客户端 IP 地址的情况可能是不够理想的。
然而,有一些方法可以解决这个问题:
使用反向代理:通过在集群外部使用反向代理(如 Nginx、HAProxy 等),可以将客户端的真实 IP 传递给后端 Pod。反向代理可以在请求中添加特定的标头(如 “X-Forwarded-For”)来传递真实 IP。Pod 内的应用程序可以读取这些标头来获取真实客户端 IP。
使用特定的网络插件:某些网络插件(如 Calico)可以配置为将真实客户端 IP 传递给 Pod。这可以通过特定的配置和注解来实现。不过,这需要你的 Kubernetes 网络插件支持并正确配置此功能。
需要注意的是,这些方法可能需要一些额外的配置和调整,并且取决于你所使用的 Kubernetes 部署环境和网络配置。因此,在实施之前,建议仔细阅读相关文档并进行充分的测试和验证。
那记录的是谁的ip?
在Kubernetes中,记录的是集群中运行的服务或应用程序的来源IP,而不是特定用户的IP。由于Kubernetes是一个容器编排平台,它主要用于管理和调度容器化的应用程序。
当请求到达Kubernetes集群中的服务或应用程序时,Kubernetes会将请求路由到相应的Pod上。在Pod内部,可以通过查看传入请求的源IP地址来确定请求的来源。
然而,需要注意的是,该IP地址是指请求流量所经过的最后一个代理的IP地址,而不是最初发起请求的终端用户的真实IP地址。这是因为在Kubernetes集群中,通常会存在代理或负载均衡器,它们在将请求转发给Pod之前会进行网络地址转换(NAT)。
如果你希望记录特定用户的真实IP地址,需要考虑在集群外部设置反向代理或负载均衡器,并确保它们将真实IP地址作为请求的头部信息传递给Kubernetes服务或应用程序。然后,你可以在服务或应用程序中获取该头部信息以记录用户的真实IP地址。
需要注意的是,记录用户真实IP地址需要适当的配置和设置,并取决于你的网络架构和使用的工具。确保在实施之前仔细阅读相关文档,并进行适当的测试和验证。
阿里技术大牛 30 分钟讲透 Kubernetes Service
原文链接: https://dashen.tech/2024/12/01/一小时精通Kubernetes的服务发现资源Service/
版权声明: 转载请注明出处.